

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外光谱和XGBoost的流化床干燥过程水分含量在线检测
[何帅 , 周杰, 张福林, 穆国庆
, 周杰, 张福林, 穆国庆* ]
, 周杰, 张福林, 穆国庆]
|
|


作者简介: 何 帅, 1988年生, 青岛理工大学信息与控制工程学院副教授 e-mail: heshuai@qut.edu.cn
含水量对化学和制药颗粒产品的属性(例如稳定性和可压缩性)具有重要影响。 传统的流化床干燥过程水分检测是采用传统仪表检测过程中的湿度、 温度等表征变量进而推测水分含量, 这种方法常存在检测不准确、 具有滞后性等, 已经很难满足现代生产的需求。 近红外(NIR)光谱作为一种新型传感器技术可以从分子层面获取过程信息, 操作简单, 分析速度快, 无需对样本预处理等优点被广泛应用于很多领域。 目前NIR光谱分析方法主要基于采集样本做离线检测, 难以体现生产过程的实时状态。 多数情况下采集的NIR光谱的吸收峰严重重叠, 导致NIR 光谱的有效信息被各种噪声掩盖。 需要采用合适的分析工具进行近红外数据分析和有效信息的提取。 传统的算法模型多采用线性或单模型方法, 难以有效解决NIR光谱有效信息提取。 采用批次颗粒流化床干燥(FBD)过程为检测对象, 将近红外光谱应用于流化床制粒干燥过程中, 联合XGBoost算法建立颗粒含水量在线测量模型。 通过白鲸优化算法获得了模型的最佳参数, 进而通过真实的流化床干燥实验验证了该方法的有效性。 验证实验中, 选取包括水分特征峰且信号较为稳定的波数(4 798~9 423 cm-1)进行建模。 采集的4个批次数据中3个独立批次数据作为训练集来训练模型, 第4个批次数据用于测试模型。 以均方根误差(RMSE)和决定系数( R2)两个指标评价对建立的模型并进行评估, 结果表明优化后的XGBoost模型在各项指标上表现优于PLS和BP-ANN算法建立的模型。 所提出的基于近红外光谱和XGBoost的水分含量在线检测模型为流化床干燥过程水分含量的在线检测提供了新思路。
Moisture content significantly impacts the properties (e.g., stability and compressibility) of chemical and pharmaceutical granular products. The traditional fluidized bed drying process moisture detection uses traditional instrumentation to detect the process of humidity, temperature, and other characterization variables and then infer the moisture content; this method often produces inaccurate detection, has a lag and other shortcomings, it has been difficult to meet the needs of modern production. Near-infrared (NIR) spectroscopy, as a new sensor technology, can be obtained from the molecular level of process information; its operation is simple, has fast analysis speed, and there is no need for sample pre-processing and other advantages, so it is widely used in many fields. However, existing NIR spectroscopic analysis methods are mainly based on offline detection of collected samples, which makes it difficult to reflect the real-time status of the production process. At the same time, in most cases, the absorption peaks of the collected NIR spectra overlap severely, resulting in the effective information of the NIR spectra being masked by various noises. Therefore, it is necessary to use suitable analysis tools for NIR data analysis and effective information extraction. Traditional algorithmic models mostly use linear or single-model methods, which makes it difficult to effectively solve the problem of effective information extraction from NIR spectra. Thus, in this paper, the fluidized bed drying (FBD) process of batch particles is used as the detection object, and near-infrared spectroscopy is applied to the fluidized bed granulation and drying process, which is combined with the XGBoost algorithm to establish an on-line measurement model of moisture content of particles. The Beluga whale optimization obtained the optimal parameters of the model, and then the validity of this approach was verified by the real fluidized bed drying experiments. For the validation experiments, the wave numbers (4 798 to 9 423 cm-1), which include the characteristic peaks of moisture and have more stable signals, are selected for modelling. Three independent batches of data out of the four batches collected are used as training sets to train the model, and the fourth batch is used to test the model. The models are evaluated in terms of Root Mean Squared Error (RMSE) and Coefficient of Determination R2 (R-Square), which show that the optimized XGBoost model outperforms the models built by PLS and BP-ANN algorithms in all the metrics. The online moisture content detection model based on near-infrared spectroscopy and XGBoost proposed in this paper provides a new approach for online moisture content detection in the fluidized bed drying process.
水分含量对药品的质量和稳定性有着重要影响。 流化床干燥过程是去除药品水分的有效方法, 但缺乏有效的在线检测干燥过程水分含量的技术。 近年来, 色谱、 质谱等技术在制药领域得到了广泛应用, 可以实现对药品中各种成分的快速、 准确的分析, 以保证药品的质量标准达到更高水平[1]。 这些方法大都是在线采用, 离线检测, 难以实现在线实时检测。
近红外(near infrared, NIR)光谱分析作为新型传感器技术被引入干燥工业的在线检测中, 使干燥过程可以实现在线检测的无损、 快速和经济[2]。 但对于NIR光谱技术乃至整个过程分析技术在干燥工业的在线分析仍处在发展阶段。 主要由于近红外光谱本身易受到流化床干燥过程不稳定气流的影响, 附加光谱维度大, 各物质的特征峰互相重叠导致有效光谱信息提取困难。 需要借助分析方法进行光谱数据分析并提取有效光谱信息, 以便准确稳定地将NIR技术应用于干燥过程水分含量在线检测。
将近红外技术用于各种过程的实时检测对实时检测流化床干燥过程的水分含量提供了启发。 Kazumitsu等研究了近红外光谱技术在聚合物加工中的应用前景和以神经网络为模型的聚合物的实时质检手段[3]。 Benoî t 等使用支持向量机回归(SVM-R)方法, 优化了近红外光谱分析中药片组分检测的准确性和稳定性[4]。 Romana等采用近红外光谱分析乙醇部分氧化反应中水分含量的可行性, 并采用偏最小二乘回归(PLSR)建立水分含量定量分析模型[5]。 罗琪等运用FT-NIR与PLSR技术优化黄水酒精含量检测模型, 提高模型精度与效率[6]。 上述均为简单的单模型方法, 对于流化床干燥过程NIR光谱和水分含量表现出的非线性特征难以有效提取。
XGBoost(eXtreme gradient boosting)是基于梯度提升(gradient boosting tree)的机器学习算法。 刘宇等采用聚类和XGboost方法提高了心脏病预测的准确性[7]。 张美志等通过结合可见-近红外光谱与IPLS-XGBoost算法, 显著提升了鸡蛋新鲜度评估的效率和准确性[8]。 尽管XGBoost表现出很强的泛化能力和鲁棒性, 但XGBoost的超参数调节是一项具有挑战性的任务, 因其涉及到理解每个超参数的功能和对模型性能的影响, 需要一定的实践和经验。 采用白鲸优化算法优化XGBoost模型, 提出基于XGBoost和近红外光谱的流化床干燥(fluidized bed drying, FBD)过程水分含量在线检测模型, 以实时在线测量干燥过程的水分含量。
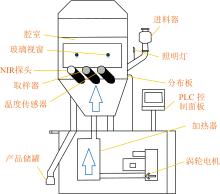
颗粒产品的含水量对产品质量有重要影响[9], 因此开发了一套基于近红外光谱技术的流化床干燥过程检测系统(如图1所示)。 FBD检测系统采用一个容积为5 L的方形腔室作为流化干燥的场所。 为了实现流化干燥, 需要使用功率为3 kW的鼓风机和6 kW的加热器。 同时系统还配备有照明灯、 取样器和进料器等设备, 以确保对干燥过程的全面检测和控制。 近红外光谱部分配备了浸入式NIR漫反射探头和传递光纤, ABB牌NIR仪。 完整的系统配备有数据分析处理系统, 维系设备运转的电机及PLC控制面板和人机交互界面。
干燥过程通过热空气对分布板上的颗粒进行加热, 热空气通过装置顶部排出。 实验设置进气流量为0.556 4 m3· s-1。 装置箱内温度由热电偶测量并由PLC控制器进行调节, 实验中将温度控制在30~70 ℃之间。 腔室内分布板上方放置焦距为250mm的漫反射式NIR探头, 进行光谱数据采集。
二氧化硅硅胶颗粒作为干燥材料模拟药物晶体。 由于二氧化硅密度适中且粒度分布较窄, 能够保证颗粒不发生粘连又可以产生均匀气流, 保证干燥效果, 二氧化硅机械强度高, 不易散落。 实验中硅胶颗粒平均直径为100 μ m, 在干燥时使用电动混合器将含水量为2%的1 650 g硅胶颗粒与450 g 蒸馏水混合, 调整颗粒含水量至约40%。
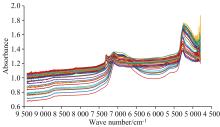
实验过程中将光谱仪分辨率设置为8 cm-1, 每次近红外光谱采样时间约为23 s。 为了消除环境误差, 采取32次独立扫描的结果取平均值。 根据前期工作[10], 将过程中的异常值剔除, 选择包含水分特征峰的4 798~9 423 cm-1光谱波段用于建模。 通过观察图2的光谱, 发现在此波数范围, 光谱具有明显的波峰和波谷, 且噪声相对较小, 因此该范围内包含着丰富的组分信息有利于建立光谱检测模型。
 | 图2 流化床干燥硅胶颗粒过程的近红外光谱图Fig.2 Near-infrared spectra of the process of fluidized bed drying with silica gel particles |
XGBoost是Chen于2014年提出的机器学习算法, 基于梯度增强框架使用决策树优化目标函数, 通过不断迭代提高预测性能。 XGBoost与传统GBDT算法相比其对损失函数采用二阶泰勒展开, 使得损失函数近似更加精准、 在损失函数中加上叶子节点权重和树的深度等正则项来控制模型的复杂度和稳定性, 对决策树的生长加以合理的限制。
损失函数L可由预测含水量 $\hat{y}$与真实含水量y表示
$S=\sum_{i=1}^{n} L\left(y_{i}, \hat{y}_{i}\right)$(1)
式(1)中, n为样本的数量, S为误差损失项。
模型的预测精度由模型的偏差和方差共同决定, 损失函数代表了模型的偏差, 若要方差小则需要在目标函数中添加正则项, 用于防止过拟合。 式(2)和式(3)中目标函数由模型的损失函数
$\mathrm{Obj}=\sum_{i=1}^{n} L\left(y_{i}, \hat{y}_{i}\right)+\sum_{i=1}^{t} \Omega\left(f_{i}\right)$(2)
在XGBoost每棵树需逐个加入, 使其效果能够得到提升, 如式(4)所示, 其中
将正则化项进行拆分, 由于前棵树的结构已经确定, 前棵树的复杂度之和可以用一个常量constant表示, 如式(5)所示
由式(2), 式(4)和式(5)可推测目标函数等价为式(6)
对损失函数采用二阶的泰勒展开, 其中gi为损失函数的一阶导数, hi为损失函数的二阶导数。
式(7)中常量constant对目标函数的解不产生影响, 目标函数最优解为
式(8)中, Ij是第j个叶子节点的样本集合, 目标函数式(8)获得越小树的结构越好, 但分裂后的结果小于给定参数的最大所得值或达到树最大深度(该参数通过白鲸优化算法得到)将停止增长子叶深度。
由于目标函数不能枚举所有的树结构, 因此引入增益函数Gain进行分裂节点的划分, 其值越大说明目标函数最优解减少越多, 结构越好。
式(9)中, IL为分裂结点左侧样本的集合, IR为分裂结点右侧样本的集合。
白鲸是高度社会化的动物, 白鲸优化算法由钟昌廷等于2022年提出, 算法模拟了白鲸游泳(勘探)、 觅食(开发)和鲸落行为[11]。 BWO算法根据平衡因子Bf实现前两个阶段过渡
式(10)中, t为当前迭代次数, T为总的迭代次数, B0是(0, 1)内随机值, 随迭代改变。 Bf> 0.5表示为勘探阶段, Bf≤ 0.5表示为开发阶段。 由式(10)发现, 随迭代增加Bf波动范围由(0, 1)减到(0, 0.5)。
(1)勘探阶段
用于描述白鲸社会性行为的位置, 表示为
式(11)中,
(2)开发阶段
白鲸通过分享彼此的位置觅食, 考虑最佳个体和其他个体对位置更新的影响, 设白鲸采用Levy飞行策略捕猎, 表达式为
式(12)中,
(3)鲸落阶段
白鲸迁移到别处或发生鲸落, 为保证种群大小不变, 使用白鲸的当前位置和鲸落下坠的步长来建立位置更新公式
式(13)—式(16)中, r5, r6, r7∈ (0, 1), 为随畸数, Lb, Ub分别为优化问题的下界和上界, N为种群数量。
| 表1 BWO算法示意 Table 1 Schematic diagram of BWO algorithm |
通过BWO算法对XGBoost的最大迭代次数、 树的深度和学习率进行调节, 以进一步提高XGBoost的性能。 传统上需要一定的经验并手动调节不同的参数并比较性能指标, 此为一项耗时且繁琐的任务。 使用BWO算法, 可以在搜索空间内快速定位最佳值, 使得模型能够充分收敛并取得更好的性能。 虽然BWO算法的参数也需要手动调节, 而这些参数通常是范围性的设定或可以通过一些启发式规则来设定。 因此与手动调节XGBoost的参数相比, 通过手动调节BWO的参数更为快捷和简便。 为了确定BWO算法的最佳参数设置, 通过研究BWO相关文献并结合实际数据和XGBoost特性进行多次调试, 最终确定一组最优参数。 WBO的参数设置及XGBoost最优参数如表2所示, 种群数量表示BWO算法中得到解的数量, 并在其中选择得到最优解, 优化目标的上下限数值分别为XGBoost的最大迭代次数、 树的深度和学习率上下限。
| 表2 BWO参数和优化结果 Table 2 BWO parameters and optimization results |
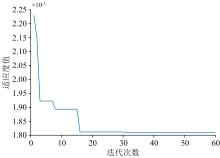
适应度表示白鲸算法中每个候选解的优良程度。 在优化问题中, 适应度函数衡量了候选解对于解决问题的质量或效能。 在本研究中适应度越低, 表示解越接近最优解。 图3为白鲸算法的适应度变化曲线, 可以看出随着迭代次数增加, 模型的适应度在降低后达到稳定, 说明所获得最佳参数是稳定可靠的。
 | 图3 适应度变化曲线Fig.3 Graph of adaptation change |
为了评估水分含量检测模型的性能, 采用均方根误差(root mean squard error, RMSE)和决定系数R2(R-Square)两个指标评价。
式(17)和式(18)中, yi是离线化验获得的真实水分含量, $\hat{y}_{i}$是通过检测模型获得的预测水分含量, m是测试集的样本数。
采集4个批次流化床干燥过程光谱数据和水分含量数据, 并进行归一化处理。 3个独立批次数据作为训练集, 第4个批次数据用于测试集来验证模型的优势。 经典的PLS和BP-ANN 算法模型分别用于建立水分含量检测模型用于与XGBoost模型对比。 表3为XGBoost与PLS、 BP-ANN建模结果。 由表3可以看到XGBoost算法在各个评价指标上都优于PLS和BP-ANN算法预测。 由于PLS主要通过将原始特征进行变换, 将非线性特征转化为线性相关特征, 忽略了其非线性信息。 BP-ANN方法由于其特征提取能力有限, 也不能很好的反映过程的非线性特性。 XGBoost则是通过集成多个决策树模型处理非线性关系, 具有较强的预测能力和鲁棒性。 由表3可以看出, 各模型在训练集和测试集上的RMSE存在显著差距。 即使采用了BWO优化参数的XGBoost或多次手动调整了BP-ANN、 PLS模型的参数, 也无法完全消除这种差距。 主要是由于在数据的采集过程中, 初始条件和操作条件有所变化, 导致训练集和测试集之间无法保持完全一致。
| 表3 XGBoost与PLS、 BP-ANN建模结果比较 Table 3 Comparison of XGBoost with PLS and BP-ANN modeling results |
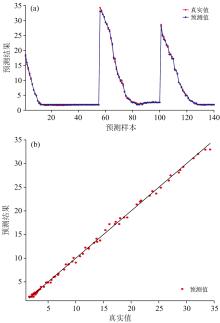
为了可视化展示基于XGBoost建立NIR光谱检测模型的预测能力, 图4(a, b)和图5(a, b)分别给出了训练集和测试集的预测结果。 从训练集的趋势图中, 可以清晰地看到预测曲线与实际值曲线高度一致, 表明XGBoost算法在训练阶段对数据分布的精准把握和强大的拟合能力。 训练集的线性参考图进一步验证了这一点, 其中绝大多数数据点紧密围绕对线分布, 表明预测值与实际值之间的偏差较小。 在测试集, 由于初始条件和过程操作条件可能存在的变化, 训练集和测试集数据之间无法保持完全一致。 尽管如此, XGBoost仍然展现出了稳健的预测性能。 由趋势图可以明显看出, XGBoost模型能够较好地表现出水分变化趋势。 证明了模型在未知数据上具有良好的泛化能力。 从线性参考图中可以看出, 预测值较为紧密地围绕对角线分布, 进一步验证了本方法的有效性。
 | 图4 XGBoost训练集预测结果图 (a): 趋势图; (b): 线性参考图Fig.4 Plot of XGBoost training set prediction results (a): Trend plot; (b): Linear reference plot |
 | 图5 XGBoost测试集预测结果图 (a): 趋势图; (b): 线性参考图Fig.5 Plot of XGBoost test set prediction results (a): Trend plot; (b): Linear reference plot |
针对流化床干燥过程的水分含量在线检测, 提出一种基于近红外光谱在线测量方法。 针对近红外光谱本身易受到流化床干燥过程不稳定气流的影响, 光谱维度大, 特征峰互相重叠难以提取有效信息难题, 提出白鲸优化算法优化的XGBoost方法优化数光谱检测模型的参数, 以提高检测模型泛化能力和鲁棒性。 真实流化床干燥实验测试结果表明, 所提出基于NIR和XGBoost的流化床干燥水分含量在线检测, 可以准确预测该过程的水分含量。 为流化床干燥过程水分含量的在线检测提供了一种新思路, 有望应用于实际场景的在线水分含量测量。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|