{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于可见-近红外光谱和深度森林的蓝莓成熟度判别
[王宏恩 , 冯国红
, 冯国红* , 徐华东, 张润泽]
, 冯国红, 徐华东, 张润泽]
|
|


作者简介: 王宏恩, 2000年生, 东北林业大学机电工程学院工业工程系硕士研究生 e-mail: 1718442562@qq.com
为快速准确对蓝莓果实成熟程度进行分类, 采用近红外光谱检测技术和深度森林算法, 建立了蓝莓成熟度的判别模型。 采用LabSpec 5000光谱仪采集了三种不同成熟程度的蓝莓标准样品, 共获取了150组光谱样本。 为确定最佳输入模型特征数目, 对原始光谱数据进行SavitzkyGolay卷积平滑处理, 采用主成分分析将平滑处理后的数据降至4个主成分, 并采用多项式特征衍生方法对每个主成分进行2、 3、 4、 5阶的特征衍生, 最终在深度森林中确定最佳的特征衍生阶数为4。 为检验深度森林的成熟度判别效果, 将其与随机森林、 极端梯度提升树算法(xgboost)及stacking融合模型进行了对比, 对各模型确定了最佳超参数组合, 深度森林和stacking融合模型采用了手动调参, 随机森林和xgboost采用了贝叶斯优化算法进行了超参数寻优。 模型评估指标采用准确率、 混淆矩阵、 受试者工作特征曲线(ROC)、 AUC度量及抗噪能力。 研究结果表明, 在测试集上, 深度森林和stacking融合模型的准确率均为95.56%, 随机森林和xgboost的准确率为93.33%; 深度森林的AUC值为1, 随机森林、 stacking融合模型、 xgboost的AUC值分别为0.99、 0.98、 0.96, 深度森林和stacking融合模型的抗噪能力优于随机森林和xgboost。 该研究的深度森林模型整体上判别效果优于其他三种模型, 为蓝莓成熟程度判别提供了技术支持。
To quickly and accurately classify the maturity of blueberries, this study established a discriminant model for blueberry maturity based on near-infrared spectroscopy detection technology and deep forest algorithms. A LabSpec 5000 spectrometer was used to collect three different maturity levels of blueberry standard samples, and a total of 150 spectral samples were obtained. To determine the optimal number of input model features, the original spectral data was subjected to SavitzkyGolay convolution smoothing, and then principal component analysis was used to reduce the smoothed data to 4 principal components. The polynomial feature derivation method derived 2nd, 3rd, 4th, and 5th order features for each principal component. The optimal feature derivation order in the deep forest was considered 4th order. To test the maturity discrimination effect of the deep forest, it was compared with random forest, extreme gradient boosting tree algorithm (xgboost), and stacking fusion model. In the comparison, the optimal hyperparameter combination for each model was determined. The deep forest and stacking fusion model used manual parameter tuning, while random forest and xgboost used a Bayesian optimization algorithm for hyperparameter optimization. The model evaluation indicators were accuracy, confusion matrix, receiver operating characteristic (ROC) curve, AUC measurement, and anti-noise ability. The results showed that on the test set, the accuracy of the deep forest and stacking fusion model was 95.56%, while that of random forest and xgboost was 93.33%. The AUC value of deep forest was 1, while that of random forest, stacking fusion model, and boost were 0.99, 0.98 and 0.96, respectively. The anti-noise ability of deep forest and stacking fusion model was better than that of random forest and xgboost. Overall, the deep forest model in this study had a better discrimination effect than the other three models and provided technical support for blueberry maturity discrimination.
蓝莓是一种杜鹃越橘属多年生灌木, 其果实富含各种营养成分, 深受大众喜爱。 成熟度对水果品质至关重要, 决定了蓝莓的采收时间和加工方法[1]。 过早或过晚采摘都会影响蓝莓的产量、 口感和营养价值[2]。 因此构建蓝莓果实成熟度的判别模型对合理规划蓝莓的采收和加工有重要意义。
传统检测技术主要依靠经验或者通过各类分析仪器检测果实的硬度、 淀粉、 可溶性固形物等理化指标来评估其成熟程度[3], 这些方法存在缺点, 如对果实造成破坏、 耗时过长和准确度不够高。 光谱技术具有检测速度快、 操作简单等特点, 大量研究已证实其可用于果实营养成分含量和成熟度的检测[4, 5]。 Pu等采用光谱技术建立了荔枝成熟度检测的分类模型, 并证明近红外技术能够实现荔枝成熟度的分类[6]。 马鑫等采用中红外和远红外光谱数据, 结合支持向量机算法成功实现了油茶籽成熟度的鉴别[7]。 刘金秀等采用高光谱成像技术实现了小白杏成熟度的检测[8]。 杨圣慧等基于无人机近地面多光谱图像实现了蛇龙珠葡萄成熟度的判别。 上述研究较好的促进了光谱技术在果蔬领域的应用, 但前人研究所采用的传统检测模型(如支持向量机等)框架大多相对简单, 学习能力弱, 容易造成欠拟合; 而采用的深度神经网络由于线性层的原因, 容易导致参数过多, 学习过程强烈依赖对参数的调整, 耗时耗力。
为解决上述问题, 本文采用了一种基于决策树的非神经网络深度学习方法— — 深度森林。 深度森林是一种深度学习模型, 该模型采用多粒度扫描提取输入样本特征并采用级联结构集成多个森林, 其具备传统神经网络的三个特点: 逐层处理、 模型内特征转换以及足够的复杂度。 相较于传统神经网络, 深度森林具有不需要大量的超参数、 模型复杂程度可根据输入特征矩阵自适应调整和对超参数的设置具有鲁棒性等优点。 深度森林已经广泛应用于故障诊断、 恶意代码识别等分类领域, 并取得了一定的研究成果。 邵怡韦等设计了基于主成分分析(principal component analysis, PCA)特征提取的深度森林模型, 解决了原始数据计算繁杂的问题[9]。 杨静等基于深度森林成功实现了可见光通信网络恶意代码的识别[10]。
本研究采用可见-近红外光谱技术结合深度森林算法对蓝莓成熟度进行了判别。 对光谱数据进行SavitzkyGolay卷积平滑和PCA降维, 以深度森林准确率确定最优多项式特征衍生阶数; 分别建立经贝叶斯优化后的随机森林、 极端梯度提升树算法(extreme gradient boosting, xgboost)以及stacking融合模型, 将深度森林与上述三种主流集成模型进行对比, 其中模型评估指标采用准确率、 混淆矩阵、 受试者工作特征曲线(receiver operating characteristic, ROC)、 AUC度量; 添加噪声, 比较了各模型的抗噪能力。 以此检验深度森林的效果, 旨在为蓝莓成熟度分级提供方法。
实验材料: 选取绿宝石品种的蓝莓, 2022年5月中旬采摘于辽宁省丹东市, 当天迅速带回实验室。 将形状外观一致、 大小均匀的蓝莓分为150组, 每组5个, 贮藏到5 ℃的恒温箱中。 从贮藏当天开始计算, 每天选取15组蓝莓进行光谱数据的采集和理化指标的同步测量。
实验器材: PX-70BⅢ 型生化培养恒温箱, 天津泰斯特公司; LabSpec 5000光谱仪, 美国ASD公司; LYT-330型手持式折光仪, 上海淋誉公司; LT202C电子天平, 常熟市天量仪器有限责任公司; UniversalTA质构仪, 上海腾拔仪器科技有限公司; 酸度计S210, 梅特勒-托利多公司。
1.2.1 光谱采集
采用LabSpec 5000光谱仪对蓝莓样本进行光谱数据的采集, 波长范围为350~2 500, 采样波长精度为1 nm。 每次扫描前进行空白校准, 随后对蓝莓样本进行扫描, 运用两分叉光纤探头在蓝莓样品的赤道处垂直采集可见-近红外光光谱(visible-near infrared), 每个单果样本的光谱图取5次扫描的平均结果, 以每组样本中5个单果的平均光谱作为该组样本的最终光谱。
1.2.2 可溶性固形物测定
将蓝莓样品用研钵捣碎, 用滤纸过滤出2~3滴浆液于检测棱镜上, 缓慢合上盖板使待测浆液均匀浸润在棱镜表面。 手持折光仪将光板对准光源, 透过目镜观察视场, 缓缓转动手轮调节目镜, 待视场内能清楚观测到白蓝分界线, 读取此时分界线刻度值, 同时用蒸馏水做空白对照。 以上操作重复3次取均值。
1.2.3 硬度测定
将蓝莓样品放置于质构仪测试平板上, 使用圆柱形探头对单个浆果进行全质构分析(texture profile analysis, TPA)测试。 测前、 测试和测后上行速度均为1 mm· s-1, 果肉变形30%, 两次压缩停顿时间均为5 s, 以双峰曲线中首峰的最大值表示硬度。
1.2.4 总酸测定
取5 mL的蓝莓浆液于50 mL的容量瓶中, 加入无二氧化碳的蒸馏水定容, 将混合物均匀搅拌后, 放入沸水浴中煮沸30 min, 然后取出冷却至室温。 用滤纸过滤, 收集滤液。 取上述滤液, 用氢氧化钠标准溶液滴定至pH值为8.2, 记录消耗的氢氧化钠溶液体积。 同时用无二氧化碳的蒸馏水进行空白实验。 以上操作重复3次取均值。
根据《食品安全国家标准食品中总酸的测定》(GB 12456— 2021)[11], 总酸的计算公式为
式(1)中: X为蓝莓样品中总酸的含量(以乙酸计), g· L-1; c为氢氧化钠标准滴定溶液的浓度, mol· L-1; V1为滴定滤液时消耗氢氧化钠标准滴定溶液的体积, mL; V2为空白实验时消耗氢氧化钠标准滴定溶液的体积, mL; k为乙酸的换算系数; F为滤液的稀释倍数; 1 000为换算系数。
1.2.5 成熟度指数计算方法
张志刚等[12]根据转黄率来判定杏果实的成熟度, 得出伴随果实的成熟, 总糖含量增加、 硬度下降的结论, 黄敏敏等[13]以黄金百香果为研究对象, 结果表明随贮藏时间的延长, 百香果的柠檬酸呈现下降趋势, 本分级标准参考Mahayothee等[14]研究芒果所提出的成熟指数, 计算公式为
式(2)中: F为硬度, gf; TA为总酸, g· L-1; TSS为可溶性固形物, g· L-1。
数据预处理: 对光谱数据进行SavitzkyGolay卷积平滑处理, 以此消除杂散光、 噪声、 基线漂移等因素的影响, 减少其对后续模型的影响。
特征筛选: 对经预处理后的光谱数据进行主成分分析(PCA), 按照累计贡献率大于85%的原则选取适当主成分数[15]。
特征衍生: 又称特征构建, 从业务和数据的角度出发, 采用原始数据进行某种重构以生成新特征的过程[16]。 采用多项式特征衍生的方法, 对主成分进行特征衍生, 进一步挖掘主成分所蕴含的信息。
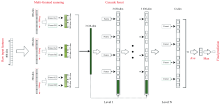
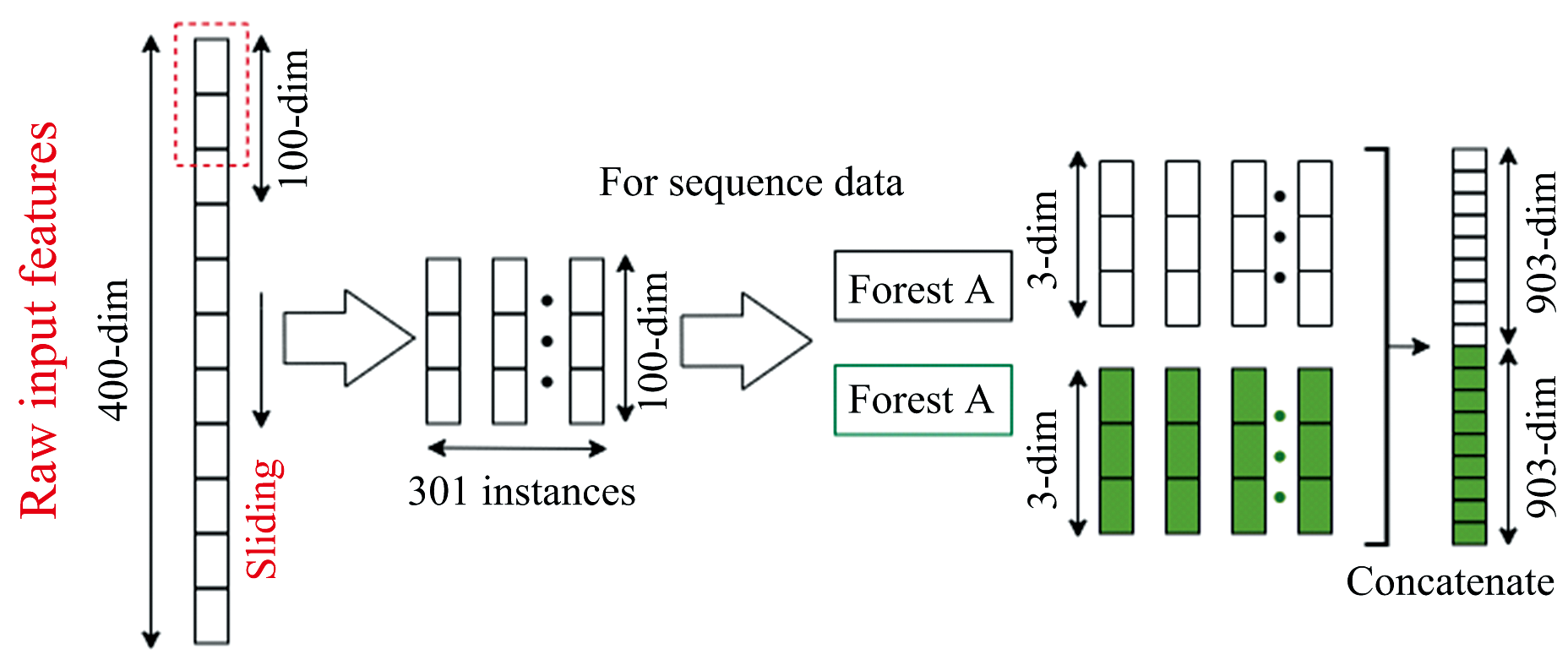
如图1所示, 深度森林[17]由多粒度扫描和级联森林构成。 多粒度扫描将高维样本分解为多个低维样本; 级联森林将上一层的输出和多粒度扫描的输出作为输入, 用随机森林和完全随机森林进行处理。
 | 图1 深度森林结构Fig.1 Deep forest structure |
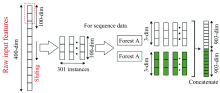
1.4.1 多粒度扫描
滑动窗口用于扫描输入的原始特征, 如图2所示。 假设输入原始特征为n维, 滑动窗口为w。 对于所输入的每一条n维的原始特征向量, 可转化为(n-w+1)条w维的特征向量, 由输入样本经窗口滑动提取的所有特征向量均被视为实例。 假设有c类, 将这些实例特征向量输入随机森林和完全随机森林, 每个森林输出(n-w+1)条c维的类向量, 将两个森林所得到的类向量拼接到一起, 得到2c(n-w+1)维特征向量。 通过设置不同的滑动窗口, 将生成不同维度的特征向量, 用于级联层的输入。
 | 图2 多粒度扫描Fig.2 Multi granularity scanning |
1.4.2 级联森林
深度神经网络的表征学习依赖于对原始特征的表征处理, 深度森林采取图1右半部分所示级联结构, 前一层处理的特征信息作为当前级联层的输入, 后一层的输入作为当前级联层的输出。 所使用随机森林和完全随机森林两种, 每种两个, 每个森林有500棵决策树。
对于c分类问题, 每个森林将输出一个c维类向量, 将四个森林的输出拼接到一起则得到一个4c维类向量。 因此, 下一层级联将在原有经多粒度扫描所得到的特征向量额外增加4c个特征。 通过设置L种不同的扫描方式, 可分别训练L个不同的级联森林, 最终模型为一个级联森林的级联, 级联中的每一层都由L个级别的级联森林组成, 每个级别都对应某一确定粒度的扫描。
1.5.1 混淆矩阵
混淆矩阵又被称为误差矩阵, 可以可视化分类模型性能[18], 如表1所示。 该矩阵的每列是预测值, 每行是真实值, TP是真正例被正确分类的数目, TN是真负例被正确分类的数目, FP是真负例被错误分类的数目, FN是真正例被错误分类的数目, 混淆矩阵可以全面反映模型在每一类别下的分类效果。
| 表1 混淆矩阵 Table 1 Confusionmatrix |
1.5.2 ROC曲线与AUC度量
ROC曲线, 又称受试者工作特征曲线, 根据多个不同的分类分界值, 以假阳性率(false positive rate, FPR)为横坐标, 真阳性率(true positive rate, TPR)为纵坐标, 绘制出的曲线。 与传统方法不同, 它联合多个决策提供了一个更加精准、 合理的度量指标, 曲线越靠近左上角, 分类效果越好。 AUC是ROC曲线下的面积, 取值在0到1之间, 其值越大, 性能越好。
将所测理化指标按照式(2)计算成熟度指数, 并将150组蓝莓样本划分为成熟末期、 成熟中期、 成熟早期。 成熟度指数小于350的为成熟末期, 介于350和700之间的为成熟中期, 大于700的为成熟早期, 分别贴上0、 1、 2的数字标签, 用于后续的建模。 最终被归为成熟末期、 成熟中期、 成熟早期的样本个数分别为42、 58、 50。 用train_test_split函数按照7∶ 3将样本划分为训练集和测试集, 结果表明, 训练集共105组样本, 成熟末期、 成熟中期、 成熟早期的样本组数分别为28、 37、 40; 测试集共45组样本, 成熟末期、 成熟中期、 成熟早期的样本组数分别为14、 21、 10。
2.2.1 光谱波段选取
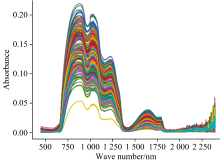
采用LabSpec 5000光谱仪获得的光谱数据范围为350~2 500 nm, 建立模型时去掉样本光谱首尾噪声处, 选取450~2 400 nm光谱波段进行后续分析, 所选波段如图3所示。
 | 图3 光谱Fig.3 Spectrogram |
2.2.2 特征选取
原始光谱含有较多的噪声, 为提升后续建模效果, 对光谱数据进行PCA, 经降维后的光谱前4主成分累计方差贡献率达到了91.2%。 在此基础上对前四主成分进行多项式特征衍生, 将衍生后的特征用于深度森林的建模, 依据5折交叉验证下的判别准确率选出最优多项式阶数。 同时单独采取PCA, 选取前1至前10主成分进行对照。 如表2所示, 先选取前4主成分, 然后对其进行4阶和5阶多项式特征衍生均可以达到95.56%的准确率, 而由于阶数为5阶时, 衍生后的特征维度达到了126, 远远大于4阶时的70维, 会使模型运行的时间更长, 因此选取前4主成分并选择4阶多项式特征衍生的方法。
| 表2 不同特征下模型运行最优准确率 Table 2 The optimal accuracy of model operation under different characteristics |
2.3.1 深度森林效果
由于深度森林具有超参数少、 能根据输入数据自动确定级联层层数的优点, 对其滑动窗口长度进行手动调参即可, 调参范围下限为输入特征数目的1/16, 上限为1/4。 如表3所示, 深度森林在训练集上均有不错的准确率, 但当窗口长度过小时会使模型学习的过于具体, 模型此时在训练集表现效果很好, 却在测试集上略差, 此时模型过拟合; 当窗口长度过大时, 模型则在训练集和测试集表现很差; 当深度森林多粒度扫描部分滑动窗口长度设置为8时, 模型在训练集和测试集均有不错的准确率。
| 表3 不同窗口长度下深度森林的表现 Table 3 The accuracy of deep forest at different window lengths |
2.3.2 模型对比
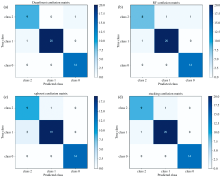
为深入探究深度森林和其他三种集成模型的差异及优缺点, 使用经PCA和多项式特征衍生后的样本, 带入到深度森林、 经贝叶斯优化后的随机森林和xgboost、 stacking融合模型。 运用贝叶斯优化算法对随机森林中n_estimators、 max_features、 max_depth分别在0~100、 0.1~9.9、 1~10搜索最优组合超参数, 分别取34、 1、 2时, 随机森林效果最优。 采用贝叶斯优化算法对xgboost中n_estimators、 learning_rate、 max_depth分别在1~1000, 0.01~0.3、 1~10搜索最优组合超参数, 分别取878、 0.13、 2时, xgboost效果最优; 在stacking融合模型中, 以K近邻(k-nearest neighbor, KNN)、 支持向量机(support vector machine, SVM)、 高斯朴素贝叶斯(Gaussian naive bayes, GaussianNB)为基础学习器, 逻辑回归(logistic regression, LR)为元学习器构成集成模型, 其中KNN超参数n_neighbors=2, SVM选取rbf核函数, GaussianNB使用默认参数, LR惩罚项为L2。 各个集成模型分类器所对应的混淆矩阵以及ROC曲线如图4和图5所示。
 | 图4 不同判别模型的混淆矩阵 (a): 深度森林模型混淆矩阵; (b): 随机森林模型混淆矩阵; (c): xgboost模型混淆矩阵; (d): stacking模型混淆矩阵Fig.4 Confusion matrix of different discriminant models (a): Deepforest confusion matrix; (b): RF confusion matrix; (c): xgboost confusion matrix; (d): Stacking confusion matrix |
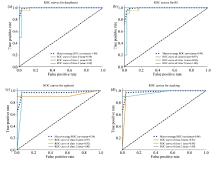
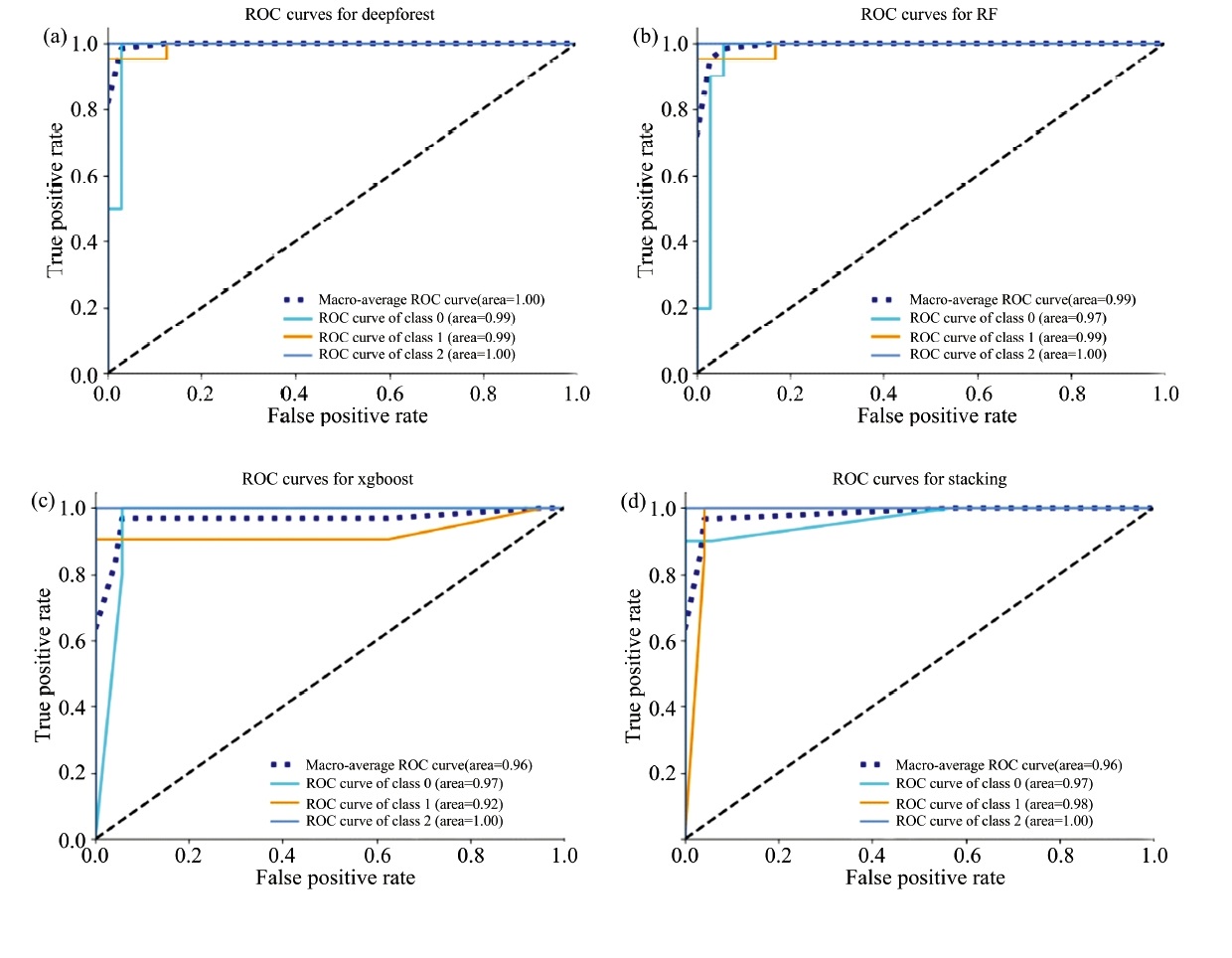 | 图5 不同判别模型的ROC曲线 (a): 深度森林模型ROC曲线; (b): 随机森林模型ROC曲线; (c): xgboost模型ROC曲线; (d): stacking模型ROC曲线Fig.5 ROC curves of different discriminant models (a): ROC curves for deepforest; (b): ROC curves for RF; (c): ROC curves for xgboost; (d): ROC curves for stacking |
由图4可以看出, 深度森林和stacking融合模型在测试集的表现优于随机森林和xgboost, 测试集准确率均达到了95.56%, 4种判别模型在对过成熟蓝莓样本的准确率均为100%, 但对成熟蓝莓样本都有被误判为未成熟的情况。 图5(a— d)中, ROC曲线越靠近左上方越好, 对比不同判别模型下的ROC曲线, 可以看出深度森林下的ROC曲线最好, 其次是随机森林, xgboost最差, stacking融合模型虽然在准确率上的表现优于随机森林, 但在ROC曲线的效果确不如随机森林, 可能是样本的类不平衡所导致; 通过比较AUC的大小, 深度森林的AUC值为1, 随机森林、 stacking融合模型、 xgboost的AUC值分别为0.99、 0.98、 0.96, 可以看出在模型泛化能力上, 深度森林明显优于xgboost和stacking融合模型, 略高于随机森林。
2.3.3 抗噪性能分析
实验时所采集到的数据难免因人为因素造成一定偏差[19]。 为分析各个模型抗噪声能力, 在数据集中加入一定程度的噪声, 构造方法如式(3)
式(3)中: X为原始数据; X'为处理后的数据; Y为服从高斯分布的噪声矩阵; α 为噪声幅值。
在加入噪声的数据上测试各个模型的判别效果, 其中所加入的噪声幅值分别为0.5, 1, 1.5。 如表4所示, 尽管噪声不断增强, 深度森林和stacking融合模型依旧保持较高的准确率, 仅在噪声幅值为1.5时下降为93.33%, 此为深度森林可以根据输入数据自适应调整本身级联森林的层数, 相比随机森林和xgboost优势明显, 体现了深度森林良好的抗噪性能。
| 表4 不同噪声幅值下各个模型在测试集上的最优准确率 Table 4 The optimal accuracy of each model on the test set under different noise amplitudes |
采用可见-近红外光谱检测系统测得采摘后不同贮藏时间段蓝莓标准样品的光谱数据, 通过SavitzkyGolay卷积平滑处理原始光谱数据, 在利用PCA对处理后的数据进行降至4个维度, 最大限度保留了信息的同时又加快运算速度, 在阶数为4的多项式特征衍生下进一步挖掘4个主成分所蕴含的信息。 将衍生后的特征矩阵输入到深度森林, 通过手动调参确定在滑动窗口长度为8时模型效果最优, 训练集和测试集准确率分别达到了98.10%和95.56%, 将深度森林与经贝叶斯优化后的随机森林和xgboost, stacking融合模型进行对比, 通过分析各个模型在混淆矩阵、 ROC曲线和ACU度量的表现以及抗噪能力, 结果表明, 深度森林在蓝莓成熟度判别上整体性能优于其他三种, 为实现快速判别蓝莓成熟度提供技术支撑。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|