





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于微焦级高重频激光诱导击穿光谱的铜合金分类方法研究
[曲东明 , 张子怡, 梁俊轩, 廖海文, 杨光
, 张子怡, 梁俊轩, 廖海文, 杨光* ]
, 张子怡, 梁俊轩, 廖海文, 杨光]
|
|


作者简介: 曲东明, 1997年生, 吉林大学仪器科学与电气工程学院博士研究生 e-mail: qudongming_jlu@163.com
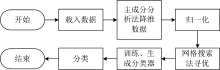
针对废弃铜合金回收分类的工业应用场景, 采用基于微焦级高重频激光诱导击穿光谱技术(MH-LIBS)结合人工神经网络(ANN)和支持向量机(SVM)两种机器学习算法, 分别对定点模式和运动模式下采集的7种铜合金样品(H59、 H62、 H70、 H85、 H96、 HPb59-1、 HPb62)进行分类识别。 结果显示, ANN和SVM对于定点模式下采集的铜合金能够实现100%精确分类, 而对于运动模式下采集铜合金的分类精度分别为100%和99.86%。 由此可见, 微焦级高重频激光诱导击穿光谱系统结合机器学习算法能够实现铜合金的精细分类, 适合应用于废弃铜合金的现场快速分析。
For the industrial application scenario of waste copper alloy recycling and classification, two machine learning algorithms based on microjoule high-frequency laser-induced breakdown spectroscopy (MH-LIBS) combined with artificial neural network (ANN) and support vector machine (SVM) are used. Seven copper alloy samples (H59, H62, H70, H85, H96, HPb59-1, HPb62) collected in point and motion modes were classified and recognized, respectively. The results show that ANN and SVM can achieve 100% accuracy in classifying the copper alloys collected in point mode. The classification accuracy for the copper alloys collected in motion mode is 100% and 99.86%, respectively. It can be seen that the microfocus high-frequency laser-induced breakdown spectroscopy system combined with machine learning algorithms can realize the fine classification of copper alloys, which is suitable for the rapid analysis of waste copper alloys on site.
随着近年来工业领域和制造业的迅速发展, 我国对铜及其合金的需求日益增加, 但铜矿储量仅占全球的3%。 截止至2020年10月, 中国铜的消费量已占全球比例超六成, 其中铜精矿的进口量为2197万吨, 过度依赖进口[1]。 由于我国铜矿资源形势严峻, 再生铜成为了铜合金的重要来源, 而目前的金属材料制造企业将不同牌号的铜合金直接融为铜锭, 这样会使铜合金中各种元素成分混杂, 降低再生铜的等级。 因此, 建立一种铜合金的高效分类方法, 既能够缓解矿产资源短缺, 减少资源浪费, 还能提高再生铜的等级和企业的经济效益, 减少对环境的影响[2], 具有十分重要的现实意义。
激光诱导击穿光谱(laser-induced breakdown spectroscopy, LIBS)技术是一种原位、 在线、 快速、 全元素分析的检测技术[3], 广泛应用于钢铁、 食品、 塑料、 宝石鉴定等众多领域。 LIBS技术无需严苛的实验条件和复杂的样品制备[4], 适用于现场快速检测[5], 结合机器学习算法在合金的分类识别领域具有很好的发展前景[6]。 周中寒[7]等结合主成分分析(principal component analysis, PCA)和支持向量机(support vector machine, SVM)算法, 实现了铝合金分类准确率99.83%; Campanella等[8]提出LIBS同“ 模糊化” 的人工神经网络(artificial neural network, ANN)相结合, 使ANN不受LIBS光谱信号强度低等问题的影响, 实现对铝合金的有效分类; 潘立剑等[9]利用PCA降维数据, 结合极限学习机算法实现了不同牌号的铝合金精细分类, 平均分类准确率为98.01%。 Zhang等[10]提出GA-PCA-ANN模型通过对废钢中Fe、 Cr、 Ni等元素的特征谱线进行降维后, 减少分析工作量, 实现对废钢的100%分类。 以上研究都将LIBS技术与机器学习算法相结合, 在合金材料的分类研究上取得了很好的结果, 但采集光谱数据时样品处于静止最优激发位置, 而在实际废铜自动快速回收的工业场景中, 铜合金形态各异, 进行分类检测时往往处于运动状态, 这对铜合金的准确识别提出了挑战。 同时, 传统的LIBS系统体积较大, 结构复杂, 需要更便携的装置以适用于废铜的现场分析。
本文采用微焦级高重频激光器作为激发源, 与传统激光器相比其体积大大减小, 在保证脉冲能量达到铜合金激发阈值的同时, 通过高频脉冲输出提高光谱强度和稳定性, 实现LIBS系统的便携化。 利用ANN、 SVM两种机器学习算法建立分类模型, 实现了在定点模式和运动模式下对不同牌号铜合金的快速分类。
系统结构如图1所示。 采用调Q开关的小型激光器(长春新工业光电技术有限公司)作为激光光源, 波长为1 064 nm, 重复频率9.96 kHz, 脉冲能量100 μ J, 脉冲宽度10 ns。 激光通过平凸透镜(50 mm焦距)垂直聚焦在样品表面, 产生的等离子体通过焦距为50 mm的平凸透镜与光纤耦合, 传输至光纤光谱仪(AvaSpec-Mini2048, Avantes)。 该光谱仪支持在220~400 nm波长范围内提供0.20~0.29 nm的光谱分辨率。 此外, 通过LabVIEW软件控制样品台在X方向电动位移, 最大移动距离为30 mm, 最大速度为10 mm· s-1, 分辨率为0.625 μ m, 用以控制样品移动速度。 同时, 可在Z方向手动微调样品台, 使样品表面与焦平面重合, 最大移动距离为13 mm, 精度为0.005 mm。
 | 图1 LIBS系统结构图Fig.1 Schematic setup of LIBS experimental system |
实验针对七种不同牌号的铜合金样品进行分类研究。 购买牌号为H59、 H62、 H70、 H85、 H96、 HPb59-1、 HPb62的铜合金样品各一块, 每块样品体积为60 mm× 60 mm× 10 mm。 为了减少样品表面粗糙度对光谱的影响, 用相同类型的砂纸对样品表面进行抛光。 根据国标《GB/T 5231— 2022》
得到7种铜合金的主要成分, 如表1所示。
| 表1 铜合金元素含量表 Table 1 Table of copper alloying element content |
实验在标准大气压和室温25 ℃中进行。 我们基于所搭建高重频LIBS, 将光谱采集方法规范化为定点模式与运动模式, 并在前期的工作中优化了两种采集模式的积分时间、 延时时间、 运动速度等实验参数[11]。 我们将这两种采集模式命名为: 定点模式和运动模式, 并标准化了这两种模式的过程: (1)定点模式: 控制激光聚焦在样品表面, 同时样品保持静止光谱仪收集在焦点处产生的等离子体。 (2)运动模式: 控制样品以稳定的速度移动, 激光在样品移动过程中照射样品, 光谱仪用于收集激光焦点处产生的等离子体。
在定点模式下, 延迟时间和积分时间均为80 ms[11], 每个铜合金样品测得200张光谱, 定点模式下所采集光谱图像如图2(a)所示。 在运动模式下, 控制二维移动样品台以5 mm· s-1的速度移动[11], 当运动速度稳定后, 光谱仪进行连续积分, 积分时间为36 ms[11], 每个铜合金样品测得200张光谱, 运动模式下所采集光谱图像如图2(b)所示。 在两种模式下所采集光谱图像较为相似, 但采集效率差异较大, 运动模式下采集光谱数据的效率远高于定点模式, 因此使用分类算法模型对两种模式所采集光谱数据进行分类, 从而比对两种模式下所采集光谱质量。
 | 图2 铜合金样品光谱图 (a): 定点模式下所采集光谱; (b): 运动模式下所采集光谱Fig.2 Spectrogram of copper alloy samples (a): Spectrogram acquired in point mode; (b): Spectrogram acquired in motion mode |
在这项工作中, 使用反向传播神经网络(back-propagation artificial neural network, BP-ANN)、 支持向量机(SVM)两种分类模型[6], 并在定点模式和运动模式下将所采集的光谱数据打乱后随机筛选, 其中定点模式下: 训练集1光谱数量为700, 预测集1光谱数量为700; 运动模式下: 训练集2光谱数量为700, 预测集2光谱数量为700。 通过对比对数据集1和数据集2在两种分类模型下的分类准确率, 从而分析不同采集模式所采集数据的优劣, 同时验证分类模型对铜合金光谱数据的适用性。
BP-ANN是一种多层前馈型神经网络[12], 采用基于多层感知权值训练的误差反向传播算法, 一般组成结构为一层输入层, 一个输出层和一个或多个隐藏层, 每一层包含一个或多个神经元, 相邻两层神经元间可设定不同权重值相连, 权重随训练次数不断优化。 BP-ANN的基本结构如图3所示。 通过调节BP-ANN的参数, 构建训练集和预测集两者之间的非线性关系, 最终可以进行铜合金牌号的分类预测。
 | 图3 BP-ANN网络结构图Fig.3 Structure diagram of BP neural network |
激活函数是一种添加到人工神经网络中的函数, 旨在帮助网络学习数据中的复杂模式。 在网络的隐含层、 输出层中, 每个神经元都将以设定的激活函数对数据进行计算与判定。 神经元类似于人类大脑中基于神经元的模型, 激活函数最终决定了是否激活信号以及要发射给下一个神经元的内容。 激活函数可以分为线性函数和非线性函数, 在Matlab中提供使用的激活函数共有十一种, 我们将对隐含层、 输出层这两层神经元的激活函数进行组合与遍历, 从而找到适用于高重频LIBS系统的BP-ANN模型参数。
支持向量机是建立在统计学习理论和结构风险最小化原理基础上的一种机器学习方法, 能够处理模式识别、 分类以及回归分析等问题, 并可推广到预测等领域[13]。 SVM的提出一开始是为了解决二分类问题, 通过训练得到一个超平面, 使得两类数据尽量被超平面分割开, 同时最大化离超平面最近点到超平面的距离。 而SVM处理多分类问题的实质便是通过训练构造多个二值分类器并将它们组合起来实现多分类。 多分类问题处理如图4所示。
 | 图4 多分类问题中的超平面Fig.4 Hyperplane in multiclassification problems |
本研究基于Matlab平台和LIBSVM工具包对700组光谱信号数据样本训练生成分类器, 每组样本具有2 048个特征分量。 并结合主成分分析法(PCA)对每组样品的2 048个数据进行降维处理, 通过对光谱数据的变量贡献度进行筛选, 筛选出少量贡献度最大的数据, 并使用筛选后的数据结合SVM进行分类计算。 本研究采用RBF核函数。 具体使用步骤如图5所示。
 | 图5 支持向量机分类流程图Fig.5 Support vector machine classification flow chart |
实验过程中, 受到铜合金自身产生的基体效应、 激光诱导过程中产生的背景噪声辐射以及光纤探头采集噪声等影响, LIBS光谱中夹杂了大量噪声信息, 影响光谱峰值强度和波长位置的准确性, 所以需要对光谱数据进行预处理, 获得准确的光谱信息, 有助于提高分类模型准确率。
采用特征值提取法对全谱数据进行基线校正, 消除线性或低频非线性的光谱漂移, 首先提取各组光谱强度最小数值
将每组数据中的最小值点连接起来, 得到光谱基线。 再用每一组原始光谱数据减去该组数据特征值, 即得到基线校正后的光谱
随后采用小波阈值降噪法消除光谱数据中的背景噪声, 首先对基线校正后的光谱数据进行小波分解, 获得小波系数, 将小于阈值的小波系数视为噪声进行去除, 随后进行小波重构, 得到降噪后的光谱信号, 实验中小波基为sym2, 分解层数为2, 阈值计算方法选择sqtwolog。 以H59铜合金样品光谱为例, 基线校正及小波降噪后的光谱数据如图6所示, 处理后的光谱基线稳定在0附近, 毛刺噪声减少, 信号较强的谱峰得到突出。
 | 图6 数据预处理前后光谱图Fig.6 Spectrogram before and after data preprocessing |
神经网络的隐含层层数过多将会增大计算量和模型训练时间, 而一般单隐层足够获取较高的精度, 所以实验采用三层感知器BP-ANN模型。 在对两种模式下7种铜合金共2 800组数据预处理的基础上, 分别将训练集1与训练集2输入BP-ANN, 训练两个分类模型, 并分别使用预测集1和预测集2进行预测。
BP-ANN的激活函数、 隐含层节点个数、 激活函数以及训练次数都会对网络的性能产生很大影响, 需要对这些参数进行优化。 首先采用四种训练函数Traingd, Traingdx, Traingrp, Trainrp分别建立网络模型, 每种模型在相同参数下进行1 000次训练, 由于每次建模时设定的权重为随机值, 所以重复仿真60次取平均分类准确率作为模型性能的衡量标准, 最终确定最佳训练函数为动量及自适应lrBP的梯度递减训练函数traingdx。
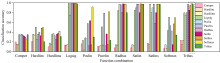
由于需要将700张光谱分类成7类铜合金, 所以网络输出层神经元个数为7, 随后将隐含层神经元个数由1增加至30, 重复建模60次后比较平均分类准确率, 最终确定最优网络预测模型为2048-8-7三层感知器网络结构。 在此结构的基础上, 优化隐层与输入、 输出层的激活函数, 进一步提高分类精度。 对11种激活函数Compet、 Hardlim、 Hardlims、 Logsig、 Poslin、 Purelin、 Raebas、 Satlin、 Satlins、 Softmax、 Tribas组成的121种组合分别进行建模, 每个模型训练1 000次, 取60次建模的平均分类准确率作比较。 最终结果显示, 定点模式下有8组激活函数组合都能够达到100%的分类精度, 分别是“ logsig& logsig” “ purelin& logsig” “ radbas& satlins” “ satlin& satlin” “ satlin& satlins” “ satlins& satlin” “ softmax& satlins” “ tribas& softmax” 。 运动模式下只有一组激活函数使ANN分类精度达到100%, 为“ tribas& softmax” 。
 | 图7 不同激活函数组合的分类精度Fig.7 Classification accuracy of different activation function combinations |
为了排除网络模型的过拟合, 我们分别对定点模式下和运动模式下的BP-ANN模型进行了10折交叉验证, 交叉验证的实验结果如表2所示。 由于训练集与预测集在分类测试中是完全独立的, 在3.1部分的分类模型类似于2折交叉验证。 当我们混合所有数据并进行10折交叉验证时, 一部分原始的预测集变成了训练集, 这增加了训练集的数据量, 因此对网络模型的分类能力有了小幅提高, 并验证了网络模型没有过拟合。
| 表2 BP-ANN模型10折交叉验证的分类准确率 Table 2 Classification accuracy of BP-ANN model with 10-fold cross-validation |
本研究采用的是核函数为RBF的支持向量机, 需要观察误差惩罚参数C和核函数参数γ 两个参数同时对分类准确率的影响来进行参数优化, 因此支持向量机存在训练速度慢的缺陷, 而本研究的数据量较大, 为了能提高训练速度的同时提高分类准确率, 本研究采用主成分分析(PCA)对数据进行降维处理, 并采用改进的网格搜索法(grid search, GS)和交叉验证优化参数[14]。 本实验中定点模式下测得的700× 2 048个数据经降维后变为700× 7个数据, 运动模式下测得的700× 2 048个数据经降维后变为700× 8个数据, 降维过后的数据能对原始数据达到95%的解释程度。 与此同时我们分别对定点模式下和运动模式下的SVM模型进行了7折交叉验证, 从而有效地避免欠学习和过学习两种情况的发生[11]。
网格搜索法是一种穷举搜索方法, 给惩罚参数C和核函数γ 分别设置一个范围和步长, 将其划分成一个个网格, 通过遍历网格中所有的点, 比较各个点的分类准确率找出一个最优解。 分类准确率为7折SVM模型计算得到的分类准确率平均值。 虽然此方法是通过牺牲分类准确度来减少搜索时间, 只能搜索到局部最优参数组合, 但仍可能基于经验合理地设置取值范围得到全局最优解。 具体步骤如下:
(1)为了缩减搜索最优参数组合的时间, 设置惩罚参数C和核函数参数γ 的取值范围为[2-10, 210], 步长为10, 以大范围和大步长先找出最优参数组合的大致范围。
(2)根据第(1)步得到的最优参数组合, 重新设置惩罚参数C和核函数参数γ 的取值范围, 并将步长由原来的10改为0.1, 以小范围小步长进行二次精搜, 从而搜索出最优的参数组合。
参数寻优结果如图8所示, 由于惩罚参数C和核函数参数γ 的取值为2的指数, 所以x、 y轴为以2为底的对数, 这样x、 y轴上的点则显示为整数, Z轴为分类准确率, 取惩罚参数C最小的点作为最优参数, 本实验中最优参数为(4, -2, 100)。
 | 图8 不同参数下的训练器的分类准确率Fig.8 The classification accuracy of the trainer using different parameters |
在不同采集模式下不同牌号的铜合金结合SVM的预测结果如表3所示。 在定点模式下SVM可以100%区分铜合金, 在运动模式下SVM仅将一个H85的光谱识别为H70。 对于实验过程和样品光谱进行分析后, 猜测实验能够得到较高分类准确率的原因可能为: (1)通过PCA算法对光谱数据进行降维后去除了大量的冗余信息, 提高了分类准确率; (2)铜合金的光谱数据特征差异较为明显, 在数学上能得到较好区分; (3)由于每次放置样品后需要对位移平台进行上下微调以完成对焦, 可能会造成样品与光谱仪光纤之间距离的微小差异, 对光谱数据产生影响, 从而提升了分类准确率。
| 表3 SVM对不同模式下铜合金光谱预测结果 Table 3 SVM prediction results of copper alloy spectra in different modes |
在BP-ANN模型中, 我们分别对定点模式和运动模式下所采集的光谱数据进行分类, 首先通过对隐含层神经元数量进行优化, 确认了网络的基本结构为2048-8-7, 并对BP-ANN模型中隐含层、 输出层11种激活函数进行组合和重复训练, 实验结果表明当隐含层与输出层的激活函数组合为“ tribas& softmax” 时, 定点模式与运动模式都可以取得较好的分类准确率。
在SVM模型中, 我们首先使用PCA对定点模式和运动模式下所取得的光谱数据进行降维处理, 通过筛选光谱中贡献度最大的部分数据, 将定点模式下所采集的700× 2 048光谱数据降维至700× 7, 运动模式下所采集的700× 2 048光谱数据降维至700× 8, 降维后的数据能对原始数据达到95%的解释程度。 同时对SVM中的惩罚参数C和核函数参数γ 进行了系统性的优化, 实验结果表明, 在设定参数为(4, -2, 100)时分类准确率最高。 两种分类模型的最优分类结果如表4所示。
| 表4 不同模型的分类准确率 Table 4 Classification accuracy of different models |
采用微焦级高重频激光器搭建LIBS系统, 在定点模式和运动模式下对7种不同牌号的铜合金进行光谱采集, 将LIBS技术与人工神经网络、 支持向量机两种算法相结合, 建立了铜合金在定点采集模式和运动采集模式下的分类模型。 结果表明, 微焦级高重频LIBS系统结合机器学习算法能够实现对铜合金牌号的高精度分类。 由于大量废铜由不同制造商生产, 即使同种牌号的铜合金也可能存在元素含量的差异, 降低模型分类准确率。 下一步工作将会以不同制造商生产的铜合金为研究对象, 继续优化BP-ANN和SVM分类模型, 使系统更加适合应用于废铜的回收分类。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|