


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱图谱结合策略检测小麦单粒种子活力
[石睿1, 2  , 张晗
, 张晗2 , 王成1, 2 , 康凯2 , 罗斌1, 2, * ]
, 张晗]
|
|


作者简介: 石 睿, 1998年生, 江苏大学农业工程学院硕士研究生 e-mail: 13921125861@163.com
小麦是我国主要的粮食作物, 在国民经济发展中扮演至关重要的角色。 种子是一切农业活动的基础, 种子活力是种子最重要的评价指标之一, 高活力的种子拥有良好的田间表现及耐储能力, 因此准确鉴别小麦种子活力对我国农业生产具有重要意义。 传统种子活力检测技术耗时、 对操作人员要求高, 且会对种子造成不可逆的损伤。 以往利用高光谱成像技术检测种子活力, 通常是针对种子批检测, 且仅仅利用图像数据或光谱数据中的一种, 很少将图谱数据结合用于单粒种子活力检测。 为了更深入了解种子活力与光谱的内在联系, 高光谱成像的小麦单粒种子快速无损检测研究颇具学术价值。 以210粒经人工老化处理过的小麦种子(105粒有活力, 105粒无活力)为研究对象, 采集种子400~1 050 nm波段内的高光谱数据, 随后进行标准发芽试验, 确保高光谱数据与发芽实验结果一一对应, 按照4∶2∶1的比例将数据集划分为训练集、 测试集和真实数据集。 利用竞争自适应重加权(CARS)算法选择特征波段, 最终得到了30个特征波段, 且所选特征波段对应了引起种子活力变化的蛋白质、 淀粉和脂类等种子内部营养物质。 为挑选出最优分类模型, 对于全波段和特征波段光谱数据, 利用训练集和测试集数据基于SVM、 KNN、 1DCNN和改进的ECA-CNN机器学习算法分别建立了小麦种子活力预测模型。 结果表明, 使用特征波段数据建立的模型性能均优于使用全波段数据建立的模型, 其中使用特征波段数据建立的ECA-CNN模型性能最好, 在避免过拟合的情况下, 训练集整体准确率为99.17%, 测试集准确率为80%。 为避免建模过程对比较分类策略造成影响, 利用真实数据集对比整体法和像素法两种分类策略。 结果表明, 像素法相比于整体法拥有更好的检测效果, 整体准确率为86.67%, 精确率为92.31%, 召回率为80%, 均优于像素法。 该研究可为快速无损检测单粒小麦种子活力提供科学依据。
Wheat is a primary staple crop in China and is pivotal in the nation's economic development. Seeds form the foundation of all agricultural activities, with seed vigor being one of the most crucial evaluation indicators. Seeds with high vigor exhibit superior field performance and storage resilience. Thus, accurately identifying wheat seeds' vigor is paramount to China's agricultural production. Traditional seed vigor detection techniques are time-consuming, demand expertise, and can irreversibly damage the seeds. Previous attempts to detect seed vigor using hyperspectral imaging technology typically focused on batch testing of seeds, utilizing either image data or spectral data, but rarely combining both for single seed vigor detection. This study explores the potential of hyperspectral imaging technology for rapid, non-destructive detection of individual wheat seeds. A total of 210 manually aged wheat seeds (105 viable, 105 non-viable) were studied. Hyperspectral data within the seeds' 400~1 050 nm band were collected, followed by a standard germination test to ensure a one-to-one correspondence between the hyperspectral data and germination results. The dataset was divided into training, testing, and real datasets in a 4∶2∶1 ratio. The Competitive Adaptive Reweighted Sampling (CARS) algorithm was employed to select feature bands, resulting in 30 feature bands corresponding to seed nutrients like proteins, starch, and lipids influencing seed vigor. To identify the optimal classification model, prediction models for wheat seed vigor were established using support vector machine (SVM), k-nearestneighbor (KNN), one-dimensional convolutional neural network(1DCNN), and the improved ECA-CNN machine learning algorithms, based on both full-band and feature-band spectral data from the training and testing sets. The results indicated that models built using feature-band data outperformed those using full-band data. The ECA-CNN model, constructed with feature band data, exhibited the best performance, achieving an overall accuracy of 99.17% for the training and 80% for the testing sets. The overall method and pixel method classification strategies were compared using the real dataset to negate the influence of modeling processes on comparison strategies. The findings revealed that the pixel method surpassed the overall method in detection efficacy, with an overall accuracy of 86.67%, a precision of 92.31%, and a recall rate of 80%. This research offers theoretical support for the rapid, non-destructive detection of individual wheat seed vigor.
小麦是我国主要粮食作物之一, 2022年小麦产量占我国当年粮食总产量约20%, 在国民经济发展中扮演着至关重要的角色[1]。 种子作为一切农业生产活动的基础, 其好坏直接影响农业生产的所有环节。 活力是种子重要的评价指标, 其最先由国际种子检验协会(ISTA)定义为: 决定种子和种子批在发芽和出苗期间的活性水平和行为的那些种子特性的综合表现[2]。 高活力种子有着良好的田间表现及耐储藏能力, 因此挑选出高活力的小麦种子对我国小麦产业有着重要意义。
传统的种子活力检测方法, 如加速老化测定、 电导率测定和四唑(TTC)染色测定等, 这些方法不仅对操作人员专业能力要求高, 而且实验周期长, 同时会对种子造成不可逆的损害, 因此亟需寻找一种快速、 无损检测种子活力的方法。 高光谱成像技术不仅可以表征待测物品的外部形态信息, 也可以反映其内部组成信息, 因此凭借这一特点, 高光谱成像技术被广泛应用于种子品质检测, 例如种子纯度检测[3]、 品种鉴别[4]、 产地预测[5]和主要营养物质测定[6]等方面, 同时在种子活力检测方面也有一定的研究成果。 丁子予等[7]将三个波段的高光谱图像合成假彩色图像, 通过提取的纹理特征建立了MobileNet模型, 该模型可以完成对三个活力梯度的玉米种子批检测, 分类准确率达到99.5%。 Wu等[8]针对样品不平衡的问题, 利用光谱数据建立了一种有关水稻种子的加权损失CNN网络模型, 该模型对三批不同人工老化时间的种子分类准确率为97.69%。 Yang等[9]直接将高光谱图像作为模型的输入, 建立的CNN模型可以完成对两个收获年份水稻种子批的分类, 分类准确率为99.5%。 上述研究中, 大部分都是针对种子批进行活力检测, 并且高光谱数据利用方式较为单一, 没有很好地发挥高光谱成像技术“ 图谱合一” 的优势。 目前针对单粒种子, 特别是小麦种子进行活力检测的研究仍较少, 同时利用图像信息及光谱信息进行单粒种子活力检测的研究更少见报道。
本研究以单粒小麦种子为研究对象, 基于高光谱成像和机器学习算法, 利用光谱数据分析对比了多种建模方法, 确立了小麦种子活力的最优检测模型, 并结合图像信息对比了不同分类策略对最终检测效果的影响, 得到了最优的单粒小麦种子活力检测策略, 以期为小麦种子活力检测提供一种快速无损的方法。
选用的小麦种子品种为京麦17, 此品种由北京市农林科学院杂交小麦研究所提供, 收获时间为2020年至2021年间。 将种子样本等分成五份并分别放入尼龙袋中。 取一组种子作为对照组放置在室温条件下, 将其余四组种子分别放入老化箱内进行2、 4、 6、 8 d的人工老化处理, 设置的老化条件为温度41 ℃、 湿度98%。 最后将老化箱内的种子全部取出, 并置于室温条件下2 d以使其含水率恢复至老化前水平, 随后放入低温箱中储存备用。
采用美国SOC公司的SOC710VP高光谱仪采集高光谱图像, 光谱范围为350~1 050 nm, 光谱分辨率2.1 nm, 图像分辨率696× 520, 波段数为512。 选用两个角度可调节的100 W卤素灯作为光源。 将小麦种子按照7行5列的方式摆放在黑色纸板上采集高光谱图像。 在得到高光谱图像后, 使用灰度标准板进行反射率校正。
为了获取有效的光谱信息, 将单粒小麦种子全部区域作为感兴趣区域, 提取单粒种子的光谱信息。 选择种子区域反射率和背景区域反射率差值最大波段处的图像作为待处理图像, 使用OTSU算法对待处理图像进行二值化处理, 经过膨胀和腐蚀操作后得到最终的掩膜图像。 将掩膜图像应用到原始高光谱图像上, 将种子区域从背景区域中分离, 得到种子区域中的光谱数据。
依据《农作物检验规程》 (GB/T3543.4— 1995) 标准发芽试验法进行发芽实验。 将种子浸泡于1%的NaClO溶液中消毒10 min, 用蒸馏水清洗三次。 采用纸上(TP)发芽法, 发芽盒底部放置1层饱含水分的发芽纸, 每25粒种子为一组, 将种子按照5× 5的排列方式摆放至发芽盒内, 种子的腹股沟朝下, 种胚朝上。 置于光照培养箱内, 温度设置为25 ℃, 光照为750~1 250 LX, 12 h~12 h。 以根长达到种子大小、 芽长超过种子大小的一半作为发芽标准, 第7天检查所有种子发芽情况。 随机选取发芽和未发芽种子各105粒, 共210粒种子作为样本集, 按照4∶ 2∶ 1的比例划分成训练集、 测试集和真实数据集。
高光谱数据作为高维数据集, 光谱波段间相关性较强, 且存在大量干扰和冗余信息, 这会大大延长建模时间同时影响模型效果, 因此, 通过算法选择特征波段是提高模型效果的关键。 采用竞争性自适应重加权(competitive adaptive reweighting algorithm, CARS)算法提取特征波段, 运行5次, 选取出建模效果最好的特征波段。
1.5.1 传统机器学习模型
传统机器学习算法在处理复杂、 高维度数据方面具有优势, 目前已广泛应用于高光谱数据处理。 K近邻(K-nearest neighbor, KNN)是一种较为成熟的机器学习分类算法, 其核心思想是通过计算欧氏距离确定最近的k个样本, 并通过它们的类别确定待分类样本的类别。
支持向量机(support vector machine, SVM)是一种经典的监督学习算法, 其核心思想就是寻找唯一的、 具有最大边界的超平面来完成对数据集的分类, 因此SVM算法在解决非线性和高维数据问题方面有着巨大优势。 选择RBF核函数作为核函数, 惩罚系数和核函数系数均选择默认值。
1.5.2 一维卷积神经网络分类模型
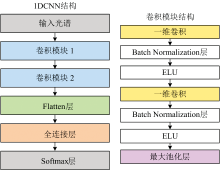
为了区分不同活力的小麦种子, 参考现有网络采用了一种一维卷积神经网络[8]。 如图1所示, 该网络由两个卷积模块、 Flatten层、 全连接层和Softmax层组成。 每个卷积模块有两个卷积层, 模块1的卷积核个数、 卷积核大小和步长分别为16/32、 3/3和1/1, 模块2的卷积核个数、 卷积核大小和步长分别为64/128、 3/3和1/1。 每个卷积层后, 都设置一个BN层和ELU激活函数, 目的是加快模型收敛速度以及避免过拟合。 每个卷积模块的最后都设置一个最大池化层(窗口大小为2, 步长为1), 作用是简化网络复杂度, 防止或缓解过拟合。 最后经由Softmax层输出分类值。
 | 图1 1DCNN模型结构图Fig.1 Structure diagram of the 1DCNN model |
1.5.3 ECA注意力机制模块
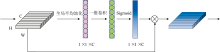
ECA模块的结构如图2所示。 首先, 使用全局平均池化对输入特征数据降维; 然后通过一个卷积核大小为k的一维卷积捕捉局部跨通道交互信息, 使用sigmoid函数确定每个通道的权重; 最后将权重与原始光谱数据相乘得到具有通道注意力的特征数据。 该模块显著增强了模型的性能, 同时还保持了较少参数的增加。 k值决定了跨通道交互的覆盖区间, k值可以通过通道数自适应决定, 计算公式如式(1)
式(1)中, c为通道维数, |t|odd为距离是t的最近的奇数, γ 和b分别设置为2和1。
 | 图2 ECA模块结构图Fig.2 Structure diagram of ECA module |
1.5.4 ECA-CNN分类模型
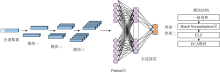
高光谱数据中存在大量冗余信息, 特征波段提取方法对数据进行了一定程度的降维, 传统的CNN可以进一步提取光谱特征, 但无法抑制模型带来的通道间冗余信息, 模型性能提升效果有限。 针对这一问题, 将ECA模块引入到CNN中, 对上述1DCNN网络进行了改进, 构建了ECA-CNN模型, 结构如图3所示。 该模型由三个模块、 Flatten层、 全连接层和Softmax层组成。 每个模块包含一个一维卷积层, 三个卷积层的卷积核个数、 卷积核大小和步长分别设置为16/32/64、 3/3/3和1/1/1。 在每个卷积层后依次设置BN层、 ELU激活函数和ECA模块, 加速模型收敛, 在保证性能的同时降低模型复杂度。 最后经由Softmax层输出分类值。
 | 图3 ECA-CNN模型结构图Fig.3 Structure diagram of ECA-CNN model |
高光谱图像作为立方体数据, 图像中每一个像素都存在一条光谱。 选取整个种子作为感兴趣区域, 将感兴趣区域内的每条光谱称为像素光谱数据, 将感兴趣区域内所有光谱取平均得到的一条平均光谱称为平均光谱数据。
采用整体法和像素法两种策略对种子进行分类。 整体法即将平均光谱数据作为分类依据, 整个种子对应一个分类值; 像素法即将像素光谱数据作为分类依据, 种子感兴趣区域内每个像素都对应一个分类值, 根据不同分类值的个数设置合适的阈值, 确定整个种子的分类值。 上述两种方法训练集和测试集均采用平均光谱数据, 即使用平均光谱数据建模, 整体法的真实数据集仍采用平均光谱数据, 但像素法的真实数据集采用像素光谱数据。
为了评估各模型的性能及不同分类策略的效果, 采用整体准确率、 精确率和召回率作为主要的评价的指标, 定义公式为
式(2)— 式(4)中, TP(true positive)代表样本实际是正样本, 预测结果为正样本; TN(truenegative)代表样本实际是负样本, 预测结果为负样本; FP(false positive)代表样本实际是负样本, 预测结果为正样本; FN(false negative)代表样本实际是正样本, 预测结果为负样本。 正样本代表有活力样本, 负样本代表无活力样本。
试验模型在64位windows操作系统下运行, 处理器为Intel(R) Core(TM) i7-12700H@2.30 GHz, 内存为16 G, 显示适配器为NVIDIA GeForce RTX3060 Laptop GPU, 软件选用PyTorch框架、 PyCharm编辑器和Python编程语言。 深度学习模型训练采用Adam优化器, 学习率设置为0.000 1, 批处理样本数目(Batchsize)设为30, 训练迭代次数设置为500。
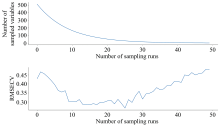
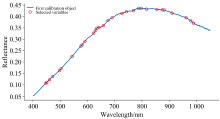
图4为利用CARS算法选择特征波段的过程, 其中迭代次数为25次时, RMSECV值最小, 从第26次迭代之后RMSECV值逐渐增大, 因此将第25次迭代得到的变量作为特征波段。 图5为选择特征波段的结果, 共有30个特征波段; 从图中可以发现选择的特征波段主要集中在几个特定的范围内, 这与不同活力种子的内部组成及理化特性有关。 在600 nm处附近选择的特征波段与O— H键的第四泛音和第五泛音密切相关[5], 650~700 nm范围内的波段与O— H键的第三泛音有关[10], 800~900 nm范围内选取的特征波段数量是最多的, 它们对应N— H键的第三泛音区[11], 950 nm附近的特征波段对应O— H键的第二泛音区[12]和C— H键的第三泛音区[13]。 这些化学键在蛋白质、 淀粉和脂类中很常见, 同时这些物质也是小麦种子的主要化学组成。 蛋白质功能丧失、 脂质过氧化和淀粉水解被认为是导致种子活力降低的主要原因[14], 因此选择与蛋白质、 脂质和淀粉相关的波段是区分种子活力的基础。 上述分析结果表明, 所选的特征波段与种子内部情况密切相关, 具有一定的解释力。
 | 图4 基于CARS算法筛选变量过程Fig.4 Process of screening variables based on CARS algorithm |
 | 图5 基于CARS算法筛选的特征变量Fig.5 Feature variables screening using CARS algorithm |
表1展示了不同建模方法搭配特征提取方法的分类效果。 分析可知, 使用CARS算法提取的特征变量为30, 远低于全光谱的变量个数。 除了KNN算法, 其余三种方法使用特征变量建立的模型分类准确率都较使用全波长建立的模型有不同程度的提升, 表明特征波段选择大大减轻了原始高光谱数据中干扰和冗余信息对建模的影响, 降低了模型的复杂度, 提高了分类效率; 同时所选的特征波段与小麦种子中的蛋白质、 脂质和淀粉等直接影响种子活力的营养物质密切相关, 增强了模型的可解释性。 图6为使用两种光谱数据分别建立的两种深度学习算法的四个模型的训练集和测试集准确率曲线, 从图中不难发现四个模型准确率曲线在经过500次迭代后都趋于收敛, 模型趋于稳定。 对比四种不同建模方法, 不难发现深度学习算法分类效果均明显优于传统机器学习算法, 这是因为光谱数据中包含很多深层特征, 深度学习算法较传统的浅层分类算法有着更强的特征提取和学习能力, 可以从光谱数据中学习到更多有关种子活力的有用信息。 1DCNN算法较传统机器学习算法有着更好的性能, 但观察训练集和测试集准确率, 不难发现两者有着较大的差距, 说明此时模型出现了过拟合现象, 这是因为模型通道间的冗余信息对模型性能产生了较大的影响, 所以在加入了ECA模块后, 得到的新ECA-CNN模型性能有了一定程度的提高, ECA-CNN模型拥有最优秀的性能; 因此选用ECA-CNN模型进行分类策略的比较。
| 表1 不同模型分类效果 Table 1 Classification effects of different models |
 | 图6 基于不同光谱数据建立的深度学习模型准确率变化曲线 (a): RAW+1DCNN; (b): CARS+1DCNN; (c): RAW+ECA-CNN; (d): CARS+ECA-CNNFig.6 The accuracy curves of the deep learning models based on different spectral data (a): RAW+1DCNN; (b): CARS+1DCNN; (c): RAW+ECA-CNN; (d): CARS+ECA-CNN |
2.3.1 整体法分类结果
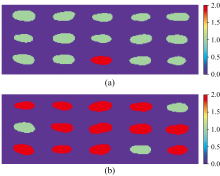
为避免建模过程对分类策略的比较产生影响, 挑选出30粒未参与建模的种子数据作为真实数据集用于分类策略比较。 如图7所示为整体法的预测结果可视化图像, 其中每个种子对应一个分类值, 绿色代表分类值1, 即种子有活力, 红色代表分类值2, 即种子无活力。 图7(a)中的种子都具有活力, 但其中有四个种子被误分类为无活力; 图7(b)中的种子都无活力, 但其中有两个种子被误分类为有活力种子。 分析可知, 整体法的整体准确率为80%, 与建模过程得到的训练集准确率相同, 精确率为84.62%, 召回率为73.33%。 这就导致其识别的有活力种子中会存在一定数量的无活力种子, 如果将这一批种子投入生产中, 会对整体发芽率及后续生长造成一定的影响; 同时部分有活力种子因被识别为无活力种子而无法投入实际生产, 会给农民及企业带来一定的经济损失。
 | 图7 整体法分类结果可视化图像 (a): 有活力种子; (b): 无活力种子Fig.7 The visualization images of the holistic classification method (a): Viable seeds; (b): Non-viable seeds |
2.3.2 像素法分类结果
图8给出了像素法分类结果的可视化图像。 图8(a)中的种子都具有活力, 图8(b)中的种子都无活力。 从图中可以发现种子的每个像素都有一个分类值, 每个种子图像都由红色和绿色像素组成, 其中绿色代表分类值1, 即种子有活力, 红色代表分类值2, 即种子无活力。 仔细观察每个种子的红色、 绿色像素分布情况, 不难发现红色像素主要集中在种子的中心区域, 即胚乳区域, 这和小麦种子的结构有关。 小麦种子主要由胚、 胚乳和种皮组成, 其中胚乳是最大的组成部分, 占据种子内的大部分区域, 储存了小麦种子发芽及前期生长所需的主要营养物质, 如蛋白质、 淀粉和脂类。 蛋白质功能丧失、 淀粉水解和脂质过氧化被认为是导致种子活力降低的主要原因, 因此胚乳是判断种子是否具有活力最主要和最敏感的区域, 红色像素也更集中在胚乳区域。 实际农业生产中往往需要挑选出更多具有活力的种子, 因此计算单个种子中绿色像素个数占所有像素个数的百分比并确定合理阈值, 判断整个种子的活力性状, 计算结果如图9所示。 从图中可以发现前十五个种子大部分都集中在整个图片的上半部分, 即代表每个种子图像中有更多的像素分类值为1, 这是因为前十五个种子为有活力种子。 通过比较两类种子分类值为1的像素个数, 确定分类阈值为0.53, 可以发现有三个有活力种子被误分为无活力种子, 但仅有一个无活力种子被误分为有活力种子, 整体准确率为86.67%, 精确率为92.31%, 召回率为80%。 采用像素法预测种子活力, 三项评价指标均优于整体法, 被识别为有活力的种子中大部分都是有活力的种子, 混杂的无活力种子很少。 实际农业生产中优先实现的目标是挑选出尽可能多的有活力种子, 确保挑选出的种子有着良好的田间出苗及生长情况, 同时尽可能将有活力种子全部投入生产, 减少经济损失; 因此相比于整体法, 使用像素法判别小麦种子活力可以更好地满足实际农业生产的需求。
 | 图8 像素法分类结果可视化图像 (a): 有活力种子; (b): 无活力种子Fig.8 The visualization image of the pixilation classification method (a): Viable seeds; (b): Non-viable seeds |
 | 图9 类别1像素个数百分比Fig.9 The percentage of pixels of category 1 |
以单粒小麦种子为研究对象, 通过人工老化获得不同活力的小麦种子, 使用高光谱仪获得其400~1 050 nm的高光谱数据, 使用CARS算法选取特征波段, 基于光谱数据建立了SVM、 KNN、 1DCNN和ECA-CNN四种小麦种子活力检测模型, 并分析对比了整体法和像素法两种分类策略的分类效果。 主要结果如下:
(1)利用CARS算法获得的30个特征波段对应小麦种子内部的蛋白质、 淀粉和脂类等营养物质, 且这些营养物质与小麦种子活力的变化息息相关, 因此CARS选择的特征波段具有一定的解释力。 同时基于特征波段光谱数据建立的分类模型性能均优于基于全波段光谱数据建立的分类模型。
(2)基于特征波段的模型分类, 深度学习模型有着更好的特征提取和学习能力, 性能皆优于传统机器学习模型; 建立的ECA-CNN模型能有效抑制通道间冗余信息对模型性能造成的影响, 分类准确率较一般CNN模型提高了约7%。
(3)相比于整体法, 像素法有效地将高光谱数据的图像信息与光谱信息相结合, 可以更好地反应不同活力种子的内部情况, 拥有更好的分类准确率、 精确率和召回率, 可以更好地满足实际农业生产需求。
综上所述, 利用高光谱成像技术搭配机器学习算法实现单粒小麦种子活力检测是可行的, 可应用于大规模、 成批量的小麦单粒种子活力检测, 为研发在线式小麦单粒种子活力检测设备提供了科学依据。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|