


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
IPSO-BPNN: 一种结合粒子群优化的BP神经网络透射光谱水质亚硝酸盐含量定量化模型
[王彩玲 , 张国浩]
, 张国浩]
, 张国浩]
|
|


作者简介: 王彩玲, 女, 1984年生, 西安石油大学计算机学院副教授 e-mail: azering@163.com
亚硝酸盐是一种常见的水质污染物, 主要来源为废水、 肥料和污水处理厂等。 水质中亚硝酸盐浓度大小是评估水体健康程度的一个重要指标, 但传统的亚硝酸盐浓度检测方法操作复杂且容易受到检测环境的干扰, 无法直观和准确的反映出水质健康程度。 为了探究一种新的方式来评估水体的健康程度, 使用IPSO-BPNN模型对亚硝酸盐透射光谱数据进行浓度预测。 首先选择10种浓度的亚硝酸盐标准溶液(0.02、 0.04、 0.06、 0.08、 0.10、 0.12、 0.14、 0.16、 0.18和0.20 mg·L-1, 使用OCEAN-HDX-XR微型光谱仪在相同的时间间隔下对十个浓度的亚硝酸盐溶液进行扫描, 并通过白板校正得到光谱数据的光谱透射率值。 使用最大最小归一化、 均值中心化两种预处理方法将光谱数据进行维度和中心点的统一, 使得不同样本之间的光谱数据具有可比性和可解释性。 由于原始光谱数据维度较高, 采用核主成分分析进行数据降维, 选择代表原始数据97.94%信息的6个主成分进行IPSO-BPNN模型的训练。 在预测亚硝酸盐浓度时, 对原始粒子群优化算法进行了改进, 引入了自适应学习因子和惯性权重更新公式以及粒子种群多样性引导策略, 并在BP神经网络的基础上引入了学习率自适应公式, 提高了算法的性能。 通过比较不同粒子数进行迭代的函数适应度值变化曲线, 选择使用100个粒子进行30次迭代来寻找最优权重和偏置组合。 结果显示, IPSO-BPNN预测模型的决定系数为0.984 360, 均方根误差为0.006 920, 平均绝对误差为0.004 103, 与当前预测性能较好的随机森林模型、 线性回归模型、 BP-ANN模型、 PSO-BPNN模型和PSO-SVR模型相比, 该模型的拟合效果更好, 精确度更高。 基于以上结果, 提出了一种基于IPSO-BPNN模型的高光谱水质亚硝酸盐浓度预测方法, 为水体健康程度的评估提供了新的思路。
Nitrite is a common water quality pollutant and is the main source of wastewater, fertilizer, and sewage treatment plants. The size of nitrite concentration in water quality is an important indicator to assess the health of water bodies. Still, the traditional method of nitrite concentration detection is complicated to operate. It easily interferes with the detection environment, which can not intuitively and accurately reflect the health of water quality. To explore a new way to assess the health of water bodies, this paper uses the IPSO-BPNN model to predict the concentration of nitrite transmission spectral data. Ten concentrations of nitrite standard solutions (0.02, 0.04, 0.06, 0.08, 0.10, 0.12, 0.14, 0.16, 0.18, and 0.20 mg·L-1) are first selected, and the ten concentrations of nitrite solutions are scanned at the same time intervals by using the OCEAN-HDX-XR micro spectrometer, The spectral transmittance of the spectral data is obtained by white board calibration to obtain spectral transmittance values for the spectral data. Two preprocessing methods, maximum-minimum normalization, and mean-centering, are used to unify the spectral data into uniform dimensions and centroids, making the spectral data comparable and interpretable among different samples. Due to the high dimensionality of the original spectral data, kernel principal component analysis is used for data dimensionality reduction, and six principal components representing 97.94% of the original data information are selected for the training of the IPSO-BPNN model. When predicting nitrite concentration, the original particle swarm optimization algorithm is improved by introducing adaptive learning factor and inertia weight updating formulae and particle population diversity guiding strategy, and learning rate adaptive formulae are introduced based on the BP neural network to improve the algorithm's performance. By comparing the change curves of function fitness values for iterations performed under different particles, 30 iterations using 100 particles are chosen to find the optimal weight and bias combinations. The results show that the coefficient of determination of the IPSO-BPNN prediction model is 0.983 760, the root-mean-square error is 0.007 320, and the average absolute error is 0.004 705, which is a better fit compared with the current Random Forest, Linear Regression, BP-ANN, PSO-BPNN, and PSO-SVR models that have better prediction performance and higher accuracy. Based on these results, a hyperspectral water quality nitrite concentration prediction method based on the IPSO-BPNN model is proposed, providing a new idea for assessing water body health.
随着当前社会的快速发展, 水资源的保护是当今社会的一个热点问题。 准确的对水质中污染物的检测是治理和保护水资源的前提。 目前主要的检测方法有分光光度法、 化学发光法、 电化学发光法和色谱法等, 但这些检测方法不适合在线监测、 对技术要求较高、 操作时间长、 容易受到环境等诸多因素影响使其不能实时和准确的对水质中污染物的含量进行检测分析[1]。
随着国内外机器学习技术和优化算法的不断发展, 机器学习算法和优化算法的结合被广泛应用于很多回归和分类问题。 在机器学习算法中, BP神经网络算法对于回归问题具有十分优秀的性能; 而在优化算法中, 粒子群优化算法对于参数寻优也有着强大的性能。 因此, 探讨粒子群优化算法的BP神经网络算法在水质检测中的应用具有重要的意义。 汪伟等提出的PSO-BPNN煤炭自燃预测模型有很好的性能[2]; 刘丹等构建的MIV-PSO-BPNN模型, 基于Rapid Miner数据挖掘实现了光伏出力短期预测的功能[3]; 凌晓等通过改进PSO-BPNN模型, 避免了算法出现陷入局部最优的问题, 在对输油管道内腐蚀速率的预测方面有十分优秀的表现[4]; 黄晋在现有改进PSO算法的基础上, 着重对保持PSO算法中粒子初始化、 参数的自适应更新以及更新公式等问题上提出了改进, 提高了粒子群的搜索性能[5]; 范勇等在改进粒子群算法和BP神经网络的基础上, 对神经网络的初始权值和阈值进行优化, 为工程中爆破振动速度峰值的预测提供了借鉴[6]。
许多学者使用不同的机器学习算法对水质中的亚硝酸盐含量进行估算。 亚硝酸盐是判断水体健康程度的一个重要指标, 掌握水体中亚硝酸盐的含量变化对于水资源的保护和水污染治理具有重要意义。 在现有的文献报告中, 利用高光谱检测技术和机器学习算法相结合实现水质中亚硝酸盐含量检测的报告较少; 因此, 本实验利用不同浓度下的高光谱数据来探讨水体中亚硝酸盐含量的检测的可行性。 首先使用光谱仪扫描不同浓度下的亚硝酸盐数据, 后进行不同的预处理以统一数据维度; 使用核主成分分析进行数据降维, 将降维后的数据输入至IPSO-BPNN模型中进行预测模型的训练; 将预测性能较好的几种模型进行比较, 选出更加适合对亚硝酸盐浓度进行预测的模型。 探究使用高光谱数据对水体亚硝酸盐的含量进行检测的可行性并选择最佳方法, 为水体污染物的检测提供了新思路。
1.1.1 亚硝酸盐溶液配制
从含有0.492 8 g亚硝酸钠(NaNO2)的1 000 mL溶液中取出20.00 mL, 并将其稀释至1 000 mL, 得到了含有0.2 mg· L-1亚硝酸盐离子(NO2-N)的溶液。 然后, 分别使用该方法配制0.02、 0.04、 0.06、 0.08、 0.10、 0.12、 0.14、 0.16、 0.18和0.20 mg· L-1的亚硝酸盐标液[1]。
1.1.2 光谱数据获取
选择0.02、 0.04、 0.06、 0.08、 0.10、 0.12、 0.14、 0.16、 0.18和0.20 mg· L-1十种浓度的亚硝酸盐溶液。 使用型号为OCEAN-HDX-XR的微型光纤光谱仪(美国Ocean Optics公司)对亚硝酸盐溶液进行光谱数据的采集。 该光谱仪具有高分辨率、 高灵敏度、 紧凑便携和宽波长范围等特点, 被广泛应用于化学、 环境监测等领域。 使用DH2000光源, 该光源结合了氘灯和钨卤素灯两种光源, 可提供宽波长范围的光照, 同时具有较高的光强稳定性。 当进行光谱数据采集时, 光源预热时间为5 min, 光谱仪狭缝为10 μ m、 环境温度保持在0~40 ℃, 在相同的时间间隔下对每个浓度的亚硝酸盐溶液进行10次数据采集, 共计得到100条光谱数据。 后通过白板校正得到所采集的100条光谱数据下的光谱透射率值[7], 白板数据是指利用光谱仪对去离子水(纯水)下的背景光谱进行测量所得到的信息。 校正计算公式如式(1)所示
式(1)中, M0为原始光谱数据; Mw为白板数据。
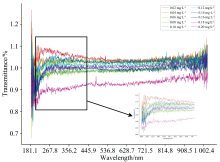
图1为白板校正后亚硝酸盐原始透射光谱图, 通过对该图进行分析可知, 不同浓度的亚硝酸盐光谱数据曲线存在细微的差异但趋势相似, 在光谱波段190~300 nm范围内, 光谱曲线呈上升趋势, 在300~800 nm范围内, 光谱曲线相对平稳, 图中220 nm波长周围处有极大的吸收峰, 不同浓度下的吸收峰之间存在差异, 主要表现为亚硝酸盐浓度越高, 该吸收峰处光谱透射率值越低。
 | 图1 原始透射光谱Fig.1 Original transmission spectra |
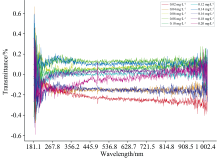
在进行光谱数据的采集时, 由于数据之间的量级、 均值点存在差异, 可能会导致模型性能和预测效果变差, 因此使用最大最小归一化和均值中心化两种数据预处理方法对原始透射光谱进行处理。 使用最大最小归一化将数据缩放到一个固定的范围中, 使不同特征的权重更加平等, 降低模型过拟合风险, 提高模型的收敛速度。 使用均值中心化将每组数据的中心点都位于原点附近, 从而消除不同特征之间由于均值不同导致的平移差距。 原始光谱数据进行最大最小归一化和均值中心化后的数据如图2所示。
 | 图2 预处理数据透射光谱图Fig.2 Preprocessed transmission spectra |
实验测得数据的光谱范围为181.1~1 002.4 nm, 具有很高的维度, 并且数据中不同信息对模型的影响存在差异, 有些信息对模型的影响较大, 能直接反映不同浓度下亚硝酸盐之间的差异, 但有些信息可能会对模型训练造成干扰, 影响预测性能。 因此在模型训练前应选择合适的方法对原始数据进行降维处理, 保留数据中的关键信息。
核主成分分析(kernel principal component analysis, KPCA)是一种常用的对高维数据进行降维的方法[8]。 与传统的主成分分析将高维数据映射到低维线性子空间不同, 该方法是一种基于核技巧的主成分分析方法, 是将数据映射到更高维的特征空间中, 后通过求解该高维空间中的主成分来实现降维和特征提取的目的[8]。 使用KPCA对预处理后的光谱数据进行降维, 图3为使用KPCA后两个主成分数据的二维分布图。 通过观察图3可知, 不同浓度的亚硝酸盐光谱数据区域划分明显, 表明KPCA对于本实验数据具有良好的效果。
 | 图3 主成分数据二维分布图Fig.3 Two-dimensional distribution of principal component data |
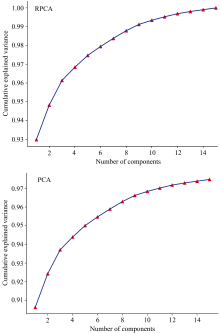
为了进一步探究使用KPCA操作的可行性, 将预处理过后的数据分别进行KPCA和PCA处理。 图4为分别进行KPCA和PCA操作后的主成分对原始数据的方差解释率, 通过图4对比可知, KPCA中3个主成分可以解释数据中96.1%的信息, 同时随着主成分个数的增加, 所能解释的数据比例也在增高, 当主成分数量为14时, 便能解释数据中99.99%的信息; 在PCA中3个主成分只能对数据中的92.53%信息进行解释, 当主成分个数为14时, 只能解释原始数据中的97.68%的信息。 即KPCA操作下更少的主成分可以代表更多的数据, 因此选择KPCA对光谱数据进行降维处理, 同时选择能代表原始数据97.94%信息的前六个主成分进行模型的训练。
 | 图4 方差解释率曲线Fig.4 Variance explanation rate curve |
粒子群算法(particle swarm optimization, PSO)是一种基于群体智能的优化算法, 其基本思想是通过模拟自然界中群体行为的方式来寻找最优解, 在粒子群算法中的每个粒子都代表一个解向量, 每个粒子的好坏根据适应度值进行判断, 并不断更新粒子的速度和位置, 使粒子能够向更优的解移动[9]。 通过不断迭代更新, 最终找到全局最优解。 但由于该算法依赖粒子之间的信息传递和合作来找到最优解, 因此对于较为复杂的问题, 粒子群算法可能会受到束缚, 从而存在容易陷入局部最优解的缺点。
1.4.1 自适应学习因子和惯性权重
粒子群算法在对粒子进行更新迭代的过程中, 个体学习因子c1、 社会学习因子c2以及惯性权重ω 通常是固定的常数, 为了更好适应问题的非线性特点以及优化过程的动态变化过程, 引入自适应学习因子和惯性权重对PSO进行改进[11]。 即每次根据当前粒子的适应度值和所有粒子的平均适应度值的大小对c1、 c2和ω 进行更新, 当粒子的适应度值比粒子种群中平均适应度值大时, 表明当前粒子距离全局最优解较远, 此时应更多的探索搜索空间, 故应增大c1, 减小c2和ω 的值从而增加算法的全局搜索能力; 当粒子的适应度值比粒子种群中平均适应度值小时, 表明当前粒子距离全局最优解较近, 应该利用历史的信息进行搜索, 故应减小c1, 增大c2和ω 的值从而加速算法的收敛速度。 式(2)、 式(3)、 式(4)分别为个体学习因子、 社会学习因子及惯性权重更新的方式。
式(2)— 式(4)中, ω max、 ω min、 c1max、 c1min、 c2max和c2min分别表示惯性权重ω 、 个体学习因子c1和社会学习因子c2的最大值和最小值, fi表示当前粒子的函数适应值, fmin表示粒子群体中最小的函数适应值, 相当于此时粒子群中的全局最优粒子, fmax表示粒子群体中最大的函数适应值, favg表示粒子群中的所有粒子的平均适应值, m1、 m2和m3为0~1范围内的随机数。
1.4.2 粒子种群多样性引导策略(diversity guidance strategy)
自适应拓扑与探索丰富度(adaptive topology and exploration richness, ATER)多样性引导策略是一种用于增强粒子多样性和避免陷入局部最优解的策略。 该策略在每次迭代时都会计算粒子群多样性值, 该值的大小反映了整个粒子群中解的分布情况, 较高的多样性值表示种群分布比较均匀, 较低的多样性值表示种群分布集中在某个局部区域[11]。 后根据粒子种群多样性值的大小来选择合适的速度更新方式, 该引导策略能够在保持种群多样性的同时, 增强粒子的全局搜索能力, 从而避免了粒子群陷入局部最优解。 粒子群Xn的多样性值是由种群中每个粒子与所有粒子平均位置的距离平均值来衡量的, 计算公式如式(5)所示:
式(5)中, N为种群中的粒子个数, d为搜索空间的对角线长度, 代表搜索区域的大小,
基于ATER策略的PSO算法速度更新规则为: 通过式(5)计算粒子群多样性值后, 当该值低于事前设定的多样性值下界dlow, 则代表当前种群多样性较低, 无法保证PSO算法的全局搜索能力, 因此切换到“ 排斥阶段” , 让种群中的粒子向着搜索区域的边界运动, 增大种群中的多样性值; 当该值大于事前设定的多样性值上界dhigh, 则代表当前种群过于发散, 则切换到“ 吸引阶段” , 进而防止种群的粒子过于发散; 当该值在dlow和dhigh之间时则切换到“ 中间阶段” , 在此阶段中的粒子受到自身的历史最优解吸引但被全局最优解排斥, 从而加强算法摆脱局部最优解的能力[12]。 ATER策略下粒子速度更新规则如式(6)所示
式(6)中, ω 位惯性权重, c1、 c2为个体学习因子和社会学习因子, r1、 r2为0~1范围内的随机数,
BP神经网络是一种基于人工神经网络的反向传播算法, 主要由输入层、 隐含层和输出层三部分组成, 用于训练多层前馈神经网络, 显著特点是输入样本信息正向传播, 输出误差信息反向传播, 并根据误差调整权重和偏置的值, 以提高模型的准确率, 当输出误差达到设定范围内或迭代次数达到设定值时算法结束。
学习率是神经网络算法中的一个重要的参数, 用于指定在反向传播过程中, 每次更新权重和偏置的调整步长大小。
学习率越大, 模型参数更新越快, 但可能会使模型不稳定; 学习率越小, 模型的参数更新越慢, 可能会导致训练的收敛速度过慢。
基于以上分析, 引入学习率自适应的神经网络算法, 利用sigmoid函数非线性的特点, 并结合损失函数的变化值, 使学习率自适应的增大或减小, 用来提高神经网络的性能和稳定性。 学习率自适应公式如式(7)、 式(8)所示
式(7)和式(8)中, r为学习率, ft-ft-1表示t时刻与上一时刻损失函数的变化值。
根据式(7)可知, 当损失函数由大变小时, 表明模型性能有明显的提升, 学习率会自适应增大, 加快模型的收敛速度; 当损失函数变化较小时, 学习率以原步长速度收敛; 当损失函数由小变大时, 表明模型已接近局部最优解, 学习率会自适应减小, 让模型可以更加精确的收敛到最优解。
1.6.1 IPSO-BPNN模型
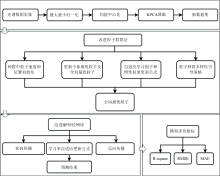
用IPSO-BPNN算法进行预测模型构建。 该预测模型的流程为: 使用IPSO算法在给定的搜索空间中寻找神经网络算法中权重和偏置的最优组合, 并将结果输出至BP神经网络模型中, 之后BP神经网络模型使用输出的最优组合进行预测模型的训练并输出预测结果的大小。
模型评价方面, 通过决定系数(R2)、 均方根误差(RMSE)和平均绝对误差(MAE)来评定模型的稳定与预测能力。 整个预测模型的流程图如图5所示。
 | 图5 模型流程图Fig.5 Model flow chart |
1.6.2 粒子数和迭代次数的选择
使用IPSO算法寻找最优组合时, 需要选择合适的粒子数目和迭代次数。 图6为选择不同粒子数进行30次迭代的函数适应度值变化曲线, 从图中可以看出当迭代次数在25~30次时, 适应度值减小幅度很小, 说明算法已经收敛到了比较稳定的状态。 因此, 选择迭代30次便可满足本实验的需求。 同时, 粒子数目为70、 100和130时最终适应度值接近且比40个粒子的最终适应度值都要小, 为了算法的稳定性, 选择使用100个粒子进行30次迭代来对神经网络权重和偏置的最优组合进行寻找。
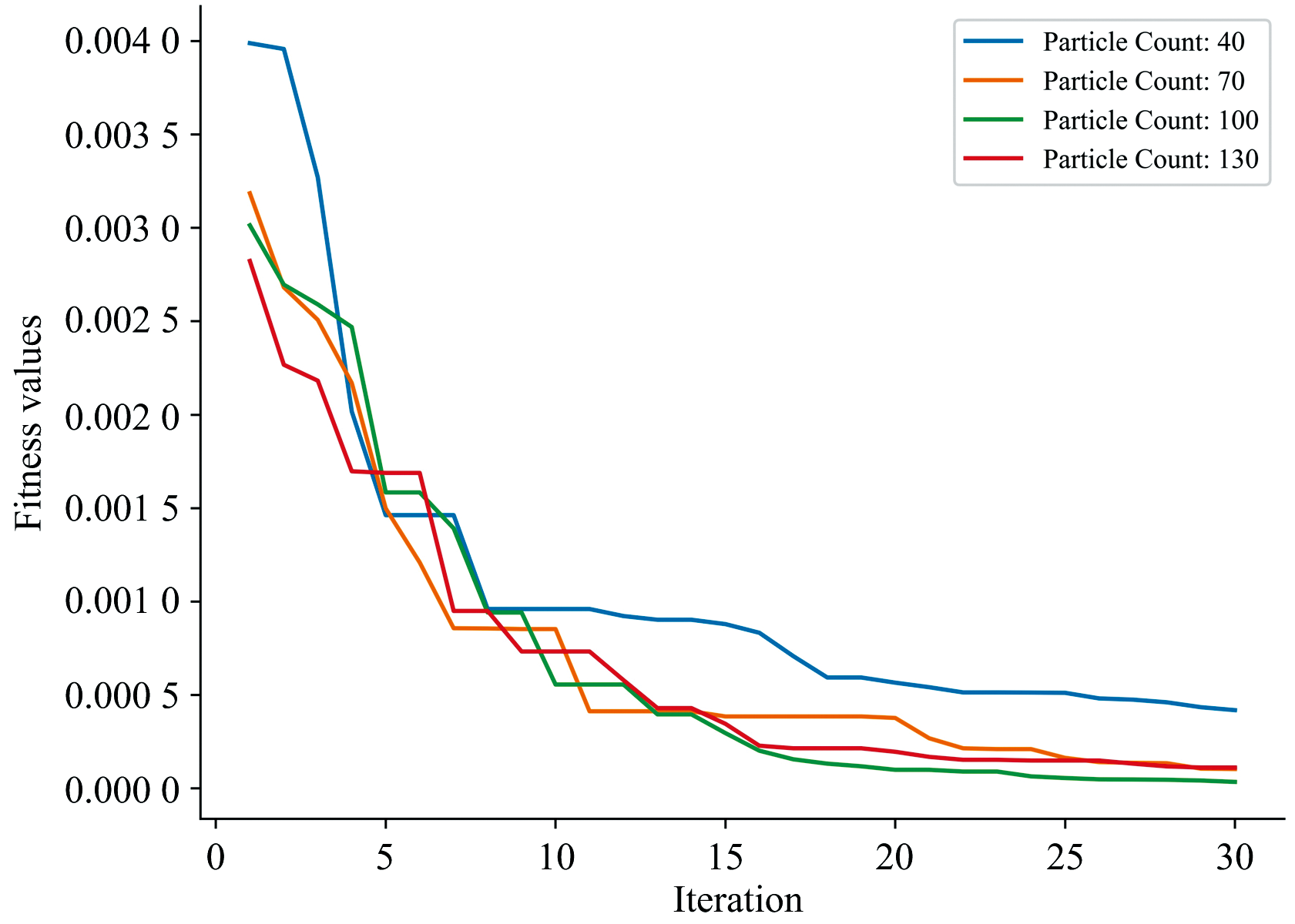 | 图6 适应度值对比Fig.6 Comparison of fitness values |
将使用KPCA降维后能代表原始数据97.94%信息的主成分数据代入IPSO-BPNN模型进行训练, 模型的参数设置如表1所示。
| 表1 IPSO-BPNN模型参数 Table 1 IPSO-BPNN model parameters |
其中, ω max、 ω min、 c1max、 c1min、 c2max和c2min分别为惯性权重、 个体学习因子和社会学习因子取值区间的最大值和最小值, r为神经网络中的初始学习率大小。
模型训练结果如图7所示, 预测模型的R2为0.984 360, RMSE为0.006 920, MAE为0.004 103, 说明IPSO-BPNN模型对于预测水体中亚硝酸盐的含量具有很好的效果。
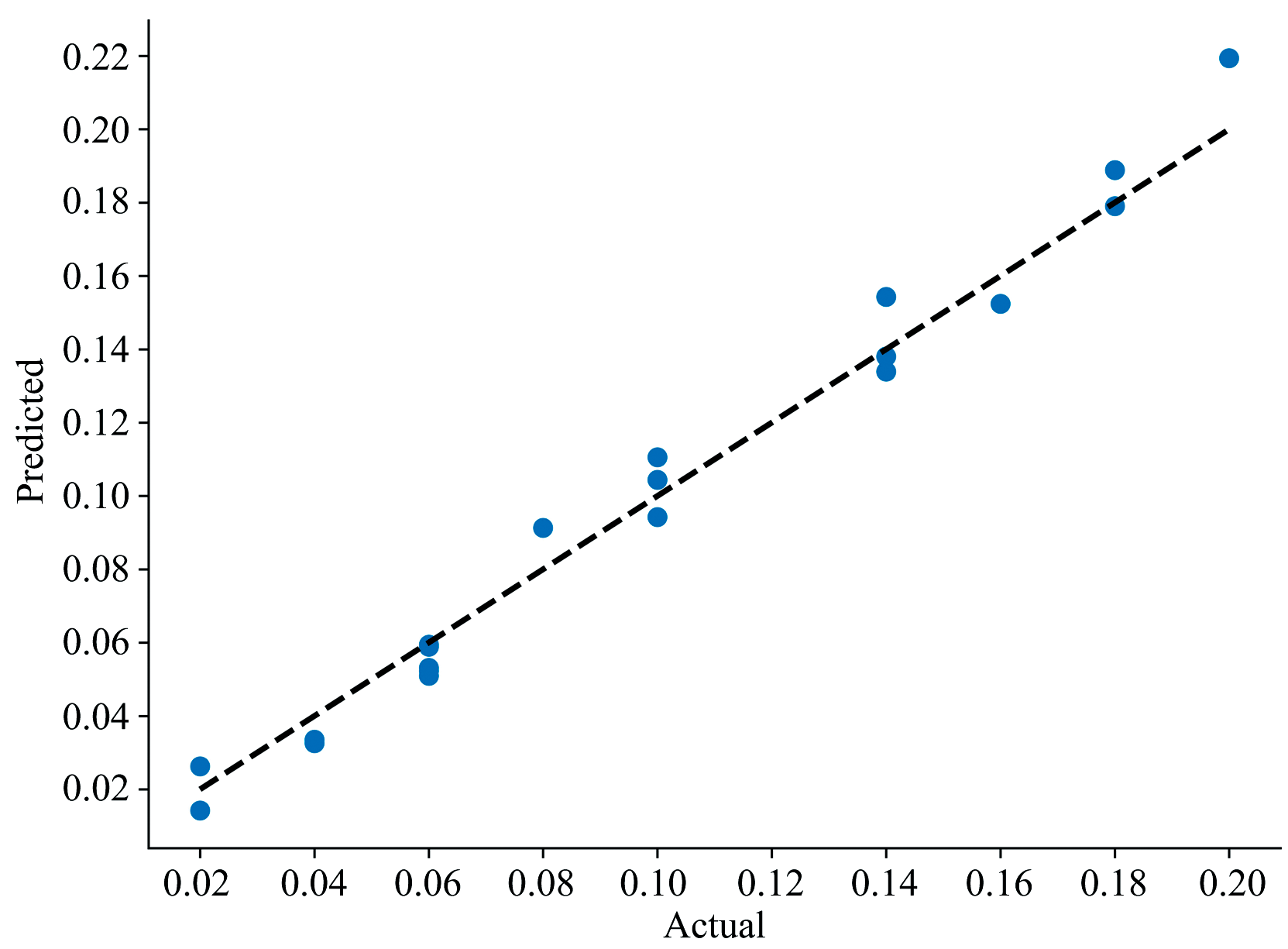 | 图7 模型预测结果Fig.7 Model prediction results |
将构建的IPSO-BPNN模型同当前预测性能较好的随机森林(RF)模型、 线性回归(LR)模型、 粒子群优化算法下的支持向量回归(PSO-SVR)模型、 反向传播神经网络(BPNN)模型以及粒子群优化算法下的神经网络(PSO-BPNN)模型的R2、 RMSE和MAE三个参数作对比, 如表2所示。
| 表2 模型预测性能对比 Table 2 Comparison of model prediction performance |
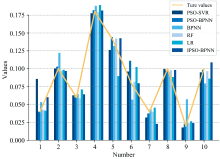
从上述模型的预测结果中随机抽取十个浓度的预测数据同真实值进行比较, 结果如图8所示。
 | 图8 模型预测结果比较Fig.8 Comparison of model prediction results |
通过观察表2、 图8可知, 使用粒子群算法进行参数寻优后的BPNN模型比只使用BP-ANN模型进行浓度预测的性能有了显著的提升, 同时预测效果也优于其他模型, 说明在进行BP神经网络的训练前先进行参数寻优是可行的。 此外, 优化后粒子群算法的模型性能比未经优化的粒子群算法模型性能也有一定程度上的提升, 表明优化过后的粒子群算法可以更好地搜索参数空间, 找到更优的模型参数组合, 提高模型的拟合优度和预测精度。
对不同浓度的亚硝酸盐透射光谱数据在预处理操作的基础上使用核主成分分析进行数据降维, 选择代表原始数据97.94%信息的主成分进行IPSO-BPNN模型的训练, 预测水体中亚硝酸盐的浓度。 相比于使用RF、 LR、 PSO-SVR等方法, 本模型在原粒子群优化算法和BP神经网络的基础上进行了改进, 引入了新的参数更新方式和粒子种群多样性引导策略, 进一步提高了模型的性能。 结果表明, 本文提出的IPSO-BPNN模型R2为0.984 360, RMSE为0.006 920, MAE为0.004 103, 相比于其他模型, 该模型的拟合效果更好, 精确度更高, 在物质的浓度预测方面有较高的精度和应用价值, 为水体健康程度的评估提供了新的思路和方法。
然而, 水体污染物的变化会受采集时间, 区域和季节等多个因素的影响, 因此未来研究的重点是利用真实样本对本模型和思路进行验证和改进, 以提高模型的性能, 为水资源保护提供科学的方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|