






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于反射率、 吸光度和Kubelka-Munk光谱的贡梨不同损伤程度检测
[李斌1, 2  , 卢英俊
, 卢英俊2 , 苏成涛2 , 刘燕德1, 2 ]
, 卢英俊|
|


作者简介: 李 斌, 1989年生, 华东交通大学智能机电装备创新研究院副教授 e-mail: libingioe@126.com
贡梨在收获、 运输和销售过程中容易发生机械损伤, 加速果实腐烂, 降低贡梨品质。 快速判别贡梨的不同损伤程度, 进而采取不同的处理措施, 以降低经济损失。 以往运用高光谱技术研究水果的损伤程度, 通常仅用反射率光谱。 该研究运用高光谱技术获取贡梨的反射率( R)、 吸光度( A)、 和Kubelka-Munk(K-M)变换光谱结合3种深度学习算法对健康和不同损伤程度的贡梨进行判别。 首先, 选取60个新鲜无损伤贡梨作为健康样品, 再利用自由落体碰撞装置制备出Ⅰ级损伤、 Ⅱ级损伤、 Ⅲ级损伤贡梨样品各60个。 通过高光谱成像系统采集这240个贡梨样品的光谱数据, 对采集的光谱进行黑白校正, 以获得贡梨的反射率( R)、 吸光度( A)、 和Kubelka-Munk(K-M)变换光谱, 然后用基准线校准(Baseline)、 去趋势(De-Trending)、 移动平均(MA-S)、 乘法散射校正(MSC)、 卷积平滑(SG-S)、 标准正态变量变换(SNV)共6种预处理方法对3种原始光谱数据进行预处理, 并建立BP神经网络(BP)、 极限梯度提升(XGBoost)和随机森林(RF)判别分析模型对贡梨不同损伤程度进行判别。 根据模型对贡梨损伤程度的判别结果显示, 基于反射率、 吸光度、 K-M变换光谱的BP模型判别准确率较好, 整体准确率达到了85%及以上, 且发现经过Baseline预处理后的反射率光谱建立的BP模型比未经预处理的反射率光谱谱建立的BP模型有较大的提升, 判别准确率达到了93.33%。 为了提升BP模型的精准度和运行效率, 对3种原始光谱和Baseline预处理后的光谱利用竞争性自适应重加权(CARS)和无信息变量消除(UVE)方法筛选出特征波段光谱信息, 用筛选后的特征光谱数据来建立BP模型, 其判别结果显示A-RAW-CARS-BP模型具有最佳的判别准确率, 整体准确率达到了96.66%。 结果表明, 采用3种原始光谱对贡梨的损伤程度进行判别具有可行性, 为高光谱技术检测贡梨的不同损伤程度提供了理论依据。
Gong pear is prone to mechanical damage during harvesting, transportation, and sales, accelerating fruit decay and reducing its quality. Different treatment measures were taken to quickly distinguish the different degrees of damage to the gong pear and reduce economic loss. In the past, hyperspectral technology was used to study the damage degree of fruits. Usually, only the reflectance spectrum was used for thestudy. In this study, the reflectance ( R), absorbance ( A), and Kubelka-Munk (K-M) spectra of Gong pears were obtained by hyperspectral technology and combined with three deep learning algorithms to distinguish healthy and different damage degrees of Gong pears. Firstly, 60 fresh and undamaged Gong pears were selected as healthy samples, and 60 samples of Ⅰ, Ⅱ, and Ⅲ damaged Gong pears were prepared by free fall collision device. The spectral data of these 240 Gong pear samples were collected by hyperspectral imaging system, and the acquired spectra were corrected in black and white to obtain the original spectra of reflectance ( R), absorbance ( A), and Kubelka-Munk (K-M) of Gong pear. Then, three kinds of original spectral data were preprocessed by Baseline calibration, De-Trending, moving average (MA-S), multiple-scattering correction (MSC), convolution smoothing (SG-S), and standard normal variable transformation (SNV). BP neural network (BP), Limit gradient lift (XGBoost), and random forest (RF) discriminant analysis models were established to distinguish different damage degrees of Gongli. According to the discrimination results of the model on the damage degree of Gong pear, the accuracy of the BP model based on reflectance, absorbance, and K-M spectrum is better, with the overall accuracy reaching 85% or more. Itwas found that the BP model established by the baseline reflectance spectrum after pretreatment showed a greater improvement than that established by the unpretreated reflectance spectrum. The accuracy of discrimination reached 93.33%. To improve the accuracy and operation efficiency of the BP model, competitive adaptive reweighting (CARS) and no-information variable elimination (UVE) methods were used to screen out the spectral information of characteristic bands for the 3 kinds of original spectra and Baseline pre-treated spectra, and the BP model was established with the filtered characteristic spectral data. The discrimination results show that the A-RAW-CARS-BP model has the best discrimination accuracy, and the overall accuracy reaches 96.66%. The results show that it is feasible to discriminate the damage degree of Gong pear by using three kinds of original spectra, which provides a theoretical basis for detecting different damage degrees of Gong pear by hyperspectral technology.
贡梨原产于陕西砀山, 作为人们日常水果贡梨因果肉白嫩、 皮薄多汁、 口感清脆味甜等特点深受人们喜爱。 贡梨从成熟到售卖需经历采摘、 包装、 和运输过程, 由于皮薄、 果肉较脆, 在此过程中不可避免地会发生机械损伤。 碰伤、 擦伤等轻度损伤的贡梨可以用于制作冰糖雪梨原料; 损伤程度略重的贡梨去除受损部位制作罐头进行销售; 重度损伤的贡梨可以切碎作为有机肥料混合到土壤中。 因此对不同损伤程度的贡梨进行分级进而选择不同的处理方式, 可极大提升整体的商业价值。
目前, 对损伤贡梨的分选主要依靠肉眼和经验, 此方法受个人主观因素和环境因素影响较大, 需要探索出一种精准、 快速的检测方案。 Liao[1]等用拉曼光谱结合级联森林(CForest)算法对损害的苹果进行快速分类, 结合不同的建模方法与各种预处理和降维方法构建识别模型, 发现采用S-G(savitzky golay smoothing, S-G)平滑处理的全光谱构建的CForest模型性能最好, 判别准确率为92.80%。 Yang[2]等应用电子鼻技术对黄桃压缩损伤水平进行无损预测。 对基于损坏后不同时间的样本建立的模型进行了比较。 结果表明: 在损伤后24 h, 损伤果实识别的正确率为93.33%。 Santana[3]等采用生物散斑技术对芒果在不同成熟阶段的机械损伤进行鉴别, 芒果未受损区域的生物斑点活性高, 受损区域显示出较低的生物斑点活性。 上述研究均具有一定的局限性。 由于拉曼光谱信号强度较低, 为了获得足够的信噪比需要较长时间, 无法满足快速检测的需求。 电子鼻技术适用范围有限, 在一些低浓度的气体检测中可能无法准确地检测到目标气体, 导致检测结果不准确。 生物散斑图像容易受到来自环境光、 光源不稳定性和光电探测器等因素的噪声干扰, 从而对结果准确性和可靠性产生不利影响。
为解决上述检测技术的局限性, 提出用高光谱无损检测技术检测贡梨的损伤。 Sun[4]等采用高光谱技术检测跌落损伤造成瘀伤的西红柿, 分析果实大小、 落高和检测时间点对高光谱特性的影响, 准确率达到了90.93%。 段洁利[5]等利用高光谱技术, 通过建立(backpropagation neural network, BP)神经网络检测模型区分青香蕉早期轻微碰伤, 总体识别准确率达到了95.06%。 上述研究表明, 利用高光谱技术检测水果碰伤具有可行性, 并且都是运用反射率光谱建立分析模型[6], 目前对于利用其他类型光谱进一步提升贡梨损伤程度判别的准确率鲜有报道。 因此, 本研究在反射率(reflectance, R)光谱的基础上加入吸光度(absorbance, A)光谱和Kubelka-Munk(K-M)变换光谱, 比较3种原始光谱及其6种预处理后的光谱数据建立的随机森林[7](random forest, RF)、 BP神经网络[8](BP)、 极限梯度提升[9](extreme gradient boosting, XGBoost)模型。 旨在探究对贡梨不同损伤程度判别效果最优的分类模型, 为高光谱成像技术应用于无损检测贡梨碰伤中提供科学依据。
采用贡梨作为实验样品, 购于江西省南昌市某水果市场。 挑选出大小尺寸、 成熟度相近且新鲜无损的贡梨样本, 共计240个, 将样本表面清洁并逐个编号后分为实验组(180个)和对照组(60个), 并放置在室温25℃, 相对湿度为45%的条件下12 h。
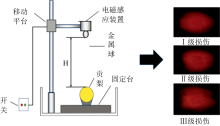
利用图1所示的自由落体碰撞装置制备表面碰伤贡梨样品。 将直径30 mm、 质量100 g的金属球, 在距离贡梨赤道表面0.4、 0.8和1.2 m三个高度进行释放, 并且定义0.4、 0.8和1.2 m三个高度造成的损伤分别为Ⅰ 级损伤、 Ⅱ 级损伤和Ⅲ 级损伤[10](图1)。 如图1自由落体装置, 当开关打开时, 电磁感应装置附近产生一个较强的磁场将铁球吸附, 当开关闭合时, 磁场消失, 金属球自由下落对贡梨样本进行碰撞。 碰撞过后的贡梨样本放置在室温25 ℃, 相对湿度为45%的条件下, 等待后续数据采集[11]。
 | 图1 自由落体碰撞装置贡及梨不同损伤程度样品Fig.1 Free-fall collision device and gong pear samples with different damage levels |
采用盖亚(Gaia Sorter)高光谱仪器(图2), 光谱波长范围390.2~1 014.0 nm, 采集贡梨样本数据。 该系统主要由计算机、 光谱仪(ImSpector V10E型, Specim, 芬兰)、 相机(C8484-05G型, Hamamastu, 日本)、 4盏卤素灯(DECOSTAR51 MR16型, OSRAM, 德国, 20 W)、 成像光谱仪、 光源、 电控位移平台等组成, 软件采用SpectralView。 在采集数据之前, 需要将高光谱仪器预热30 min。 通过SpectralView软件调整高光谱系统参数, 设置参数后每次采集一个贡梨样品, 将贡梨放在位移平台上, 在平台的带动下移动到采样位置, 通过计算机软件处理图像采集。
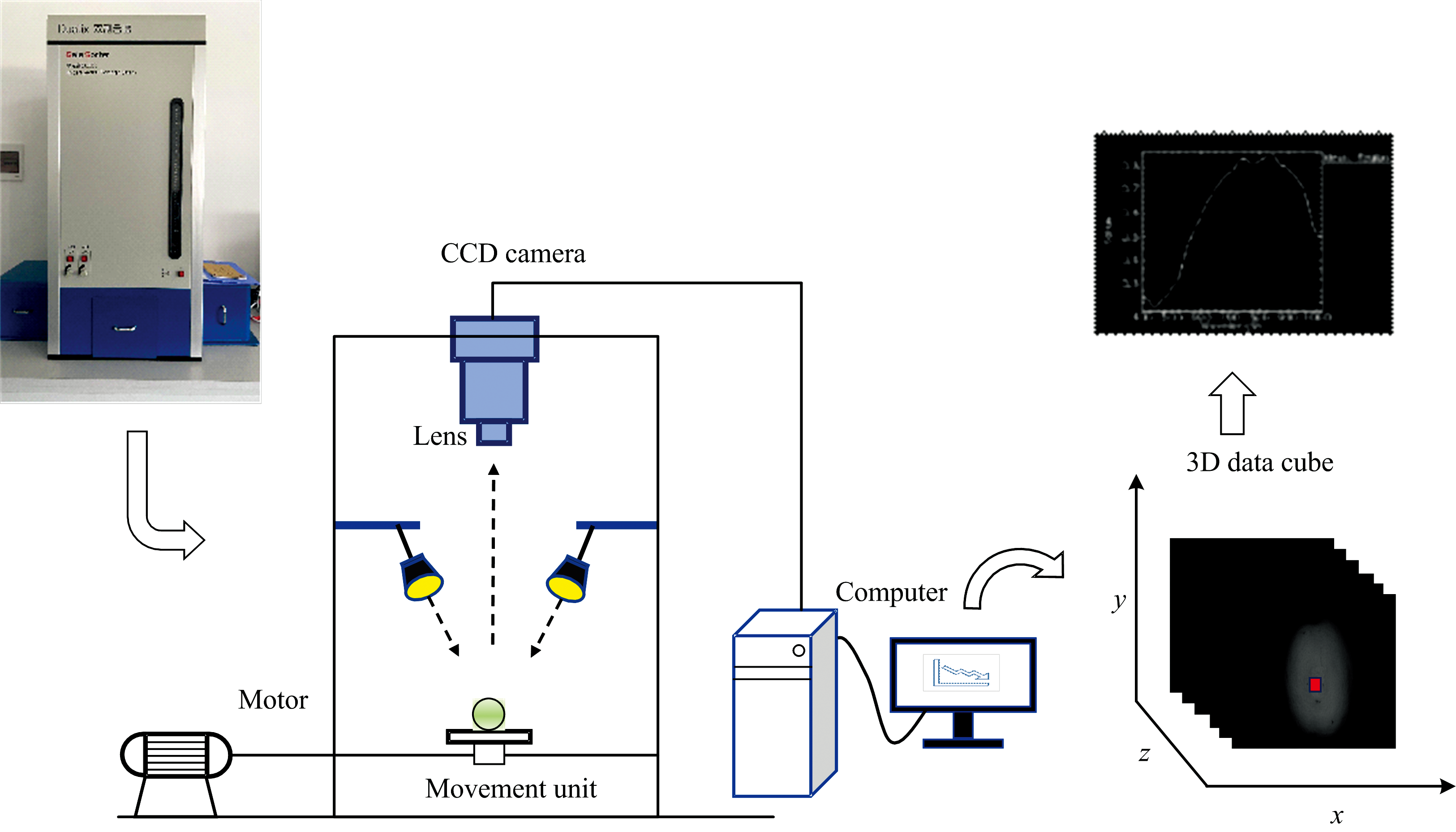 | 图2 高光谱采集系统Fig.2 Hyperspectral acquisition system |
由于CCD相机中暗电流的干扰以及相机传感器在不同波长可能存在一定的偏差, 需要对采集的贡梨原始光谱图像进行黑白校正[12]。 首先调整高光谱参数使其与采集样本时一致, 用镜头盖遮住镜头, 采集出一张全黑的参考图像; 将镜头盖取下, 再对聚四氟乙烯白板进行图像采集, 得出一张全白参考图像。 利用两张黑白图像对贡梨样本的原始图像进行校正, 校正公式如式(1)
式(1)中: Ir为原始图像数据; Iw为全白参考图像数据; Id为全黑参考图像数据; I为校正后的样本图像数据。 然后通过ENVI 5.3软件对校正后的高光谱图像的感兴趣区域(ROI)进行光谱提取, 确定感兴趣区域(ROI)约为1 100个像素点左右的矩形区域, 对于健康的贡梨样品选取正对镜头的赤道区域, 对于碰伤的贡梨样品选择正对镜头的碰伤区域[13]。 提取出每幅图像ROI的平均光谱作为贡梨样本的反射率光谱, 用式(2)和式(3)对反射率光谱进行转换, 将贡梨样品的反射率(R)光谱转化为吸光度(A)光谱和K-M光谱, 用于贡梨损伤程度的判断。
采集的光谱数据中不仅包含检测样本信息, 还包含噪声和背景信息, 需对原始光谱数据进行预处理。 采用基准线(baseline)、 去趋势(de trending, DT)、 标准正态变量变换(standard normal variate, SNV)、 多元散射校正(multiplicative scatter correction, MSC)、 卷积平滑(Savitzky-Golay smoothing, SG-S)和移动平均(moving average smoothing, MAS)对反射、 吸收和K-M变换光谱数据进行预处理[14], 比较不同预处理后的模型判别准确率, 选出最适合贡梨损伤程度判别的预处理方式。
在大量波段情况下, 可能存在高度相关的波段, 其中一些波段提供的信息与其他波段相似或重复, 需要对光谱数据进行波段筛选, 从中选择一部分最具代表性和信息丰富的波段进行后续分析。 采用无信息变量消除(uninformative variable elimination, UVE)算法和竞争性自适应重加权(competitive adaptive reweighted sampling, CARS)算法对数据进行降维处理。 CARS算法是一种结合蒙特卡洛采样与PLS模型的特征变量选择方法, 通过自适应加权采样保留PLS模型中回归系数权重较大的变量所为新子集, 去掉权重较小的点, 利用交互验证选出交叉验证均方差(RMSECV)最低的子集中的变量作为特征波长。 UVE算法是通过利用噪声的无关变量信息统计去选择光谱自身的特征变量, 再计算各个波段与目标变量之间的相关性, 评估波段的重要性进而排除对目标变量无关或相关性较弱的波段。
利用Kennard-Stone(KS)算法分别将240个贡梨样本的反射、 吸收和K-M变换光谱数据进行分类(校正集∶ 测试集=3∶ 1), 校正集180个和测试集60个。 分别建立基于原始光谱及其各种预处理后光谱的随机森林、 BP神经网络和极限梯度提升模型, 对不同损伤程度的贡梨进行判别, 分类结果在预测集中得到。 随机森林(RF)是一种机器学习算法, 利用多个决策树来做出预测, 结合了决策树的预测能力和随机性, 因此具有高度的灵活性和鲁棒性。 BP神经网络(BP)包括输入层、 隐藏层和输出层, BP神经网络具有较强的非线性拟合能力和适应性, 能解决复杂问题。 极限梯度提升(XGBoost)算法引入了L1正则化(Lasso)和L2正则化(Ridge)提高了模型泛化能力, 并内置特征重要性评估提高了模型性能。
对健康、 Ⅰ 级损伤、 Ⅱ 级损伤和Ⅲ 级损伤样品反射、 吸收和K-M变换光谱求平均值并绘制光谱曲线。 如图3所示, 健康贡梨和不同损伤程度的贡梨所有光谱具有相似的特征趋势。 从图3(a)中可知, 在平均反射率光谱强度方面, 健康的贡梨样品明显高于损伤贡梨样品, 原因可能是冲击损伤导致贡梨细胞膜破裂, 一定的细胞质流失, 从而导致反射率减小。 在S1区域(692.0~727.0 nm)存在1个比较明显的吸收谷, 吸收谷随着贡梨的损伤程度增大逐渐增大, 其影响因素可能与叶绿素有关[15], 由于外力对贡梨的冲击造成叶绿素的分解, 产生一些分解产物抑制酶的活性。 从图3(b)和图3(c)可知健康贡梨谱线均低于损伤贡梨谱线, 对于吸光(A)度光谱, Ⅱ 级损伤和Ⅲ 级损伤的光谱曲线较为接近, 并在397.5~665.0 nm近乎重叠, 对于K-M变换光谱4个类别光谱曲线在545.0 nm波段之后相互重叠。
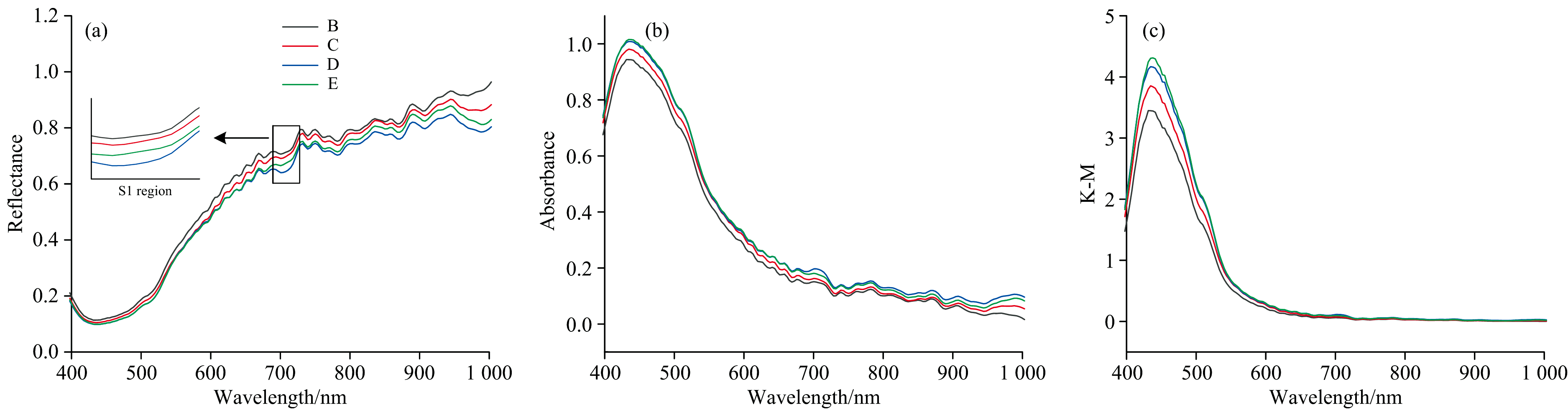 | 图3 平均光谱曲线 (a): 反射率光谱曲线; (b): 吸光度光谱曲线; (c): K-M变换光谱曲线Fig.3 Original spectra (a): Reflectance spectra; (b): Absorbance spectra; (c): K-M transformation spectra |
利用反射、 吸收、 K-M变换光谱的原始光谱以及Baseline、 DT、 MAS、 SG-S和SNV预处理后的光谱分别建立RF、 XGBoost、 和BP模型。 表1所示模型为对贡梨不同损伤程度预测准确率, 三种原始光谱及其6种预处理后的光谱数据建立的RF和XGBoost模型预测准确率在70%~83.33%, 效果一般; BP模型总体判别准确率在80%~93.33%, 对贡梨损伤程度判别效果较好。 结果表明, BP模型与RF模型和XGBoost模型相比, 整体表现出较高的判别准确率, 更加适合对贡梨不同损伤程度进行分类研究。
| 表1 RF、 XGBoost和BP模型对贡梨不同损伤程度预测准确率(%) Table 1 Prediction accuracies of RF, XGBoost and BP models for different damage degrees of Gong Pear (%) |
由表1可知, 吸收光谱的Baseline-BP模型A-Baseline-BP是基于3种原始光谱及其所有预处理后光谱建立的模型中判别效果最优的模型, 对贡梨损伤程度的总体判别准确率高达93.33%, 图4(a)为4个损伤程度样品的A-Baseline-BP模型的混淆矩阵。 基于未经预处理的反射率和K-M光谱建立的BP模型具有较好的建模效果, 整体判别准确率均达到了91.66%, 图4(b)所示为R-RAW-BP模型的混淆矩阵, 1例Ⅰ 级损伤样本被误判为Ⅲ 级损伤, 2例Ⅱ 级损伤样本误判为Ⅲ 级损伤, 2例Ⅲ 级损伤样本误判为二级损伤。 图4(c)为K-M-RAW-BP模型的混淆矩阵, 对于Ⅱ 级损伤判别中, 存在2例样本误判为Ⅰ 级损伤2例样本误判为Ⅲ 级损伤, Ⅲ 级损伤判别中, 1例样本判别为Ⅰ 级损伤, 3个模型对健康样本的判断准确率均达到了100%。
 | 图4 基于A、 R和K-M光谱的最优BP模型预测混淆矩阵 Sound: 健康样品; Ⅰ 、 Ⅱ 和Ⅲ : Ⅰ 、 Ⅱ 和Ⅲ 级损伤; (a): A-Baseline-BP模型预测结果混淆阵; (b): R-RAW-BP模型预测结果混淆矩阵; (c): K-M-RAW-BP模型预测结果混淆矩阵Fig.4 Optimal BP model prediction confusion matrix based on A, R and K-M spectra Sound: Healthy sample; Ⅰ , Ⅱ and Ⅲ : Ⅰ , Ⅱ and Ⅲ injuries; (a): Confusion matrix of A-Baseline-BP model prediction results; (b): Confusion matrix of R-RAW-BP model prediction results; (c): Confusion matrix of K-M-RAW-BP model prediction results |
通过波段筛选, 可以降低数据维度, 减少冗余信息, 并提高数据分析的效率和准确性。 由表1可知, 基于三种原始光谱建立的BP模型整体准确率较好, 并且经过Baseline预处理后的反射光谱建立的BP模型比原始反射光谱建立的BP模型有较大的提升。 为提高模型的运行速度, 对全波段光谱数据建模效果较好的3种原始光谱和经过Baseline预处理后的光谱, 利用CARS和UVE算法进行特征波段筛选。 以原始收度光谱特征波长筛选过程为例介绍CARS和UVE筛选波段的原理。 CARS算法挑选特征波长过程如图5所示, 首先设置CARS算法的采样次数为100次, 在这过程中变量数量逐渐减少, 减少速度由快到慢近似指数。 特征波长由采样期间最小的RMSECV确定, 在采样次数为55次时RMSECV达到最低, 此时取得最小值为0.414 6随后快速上升。
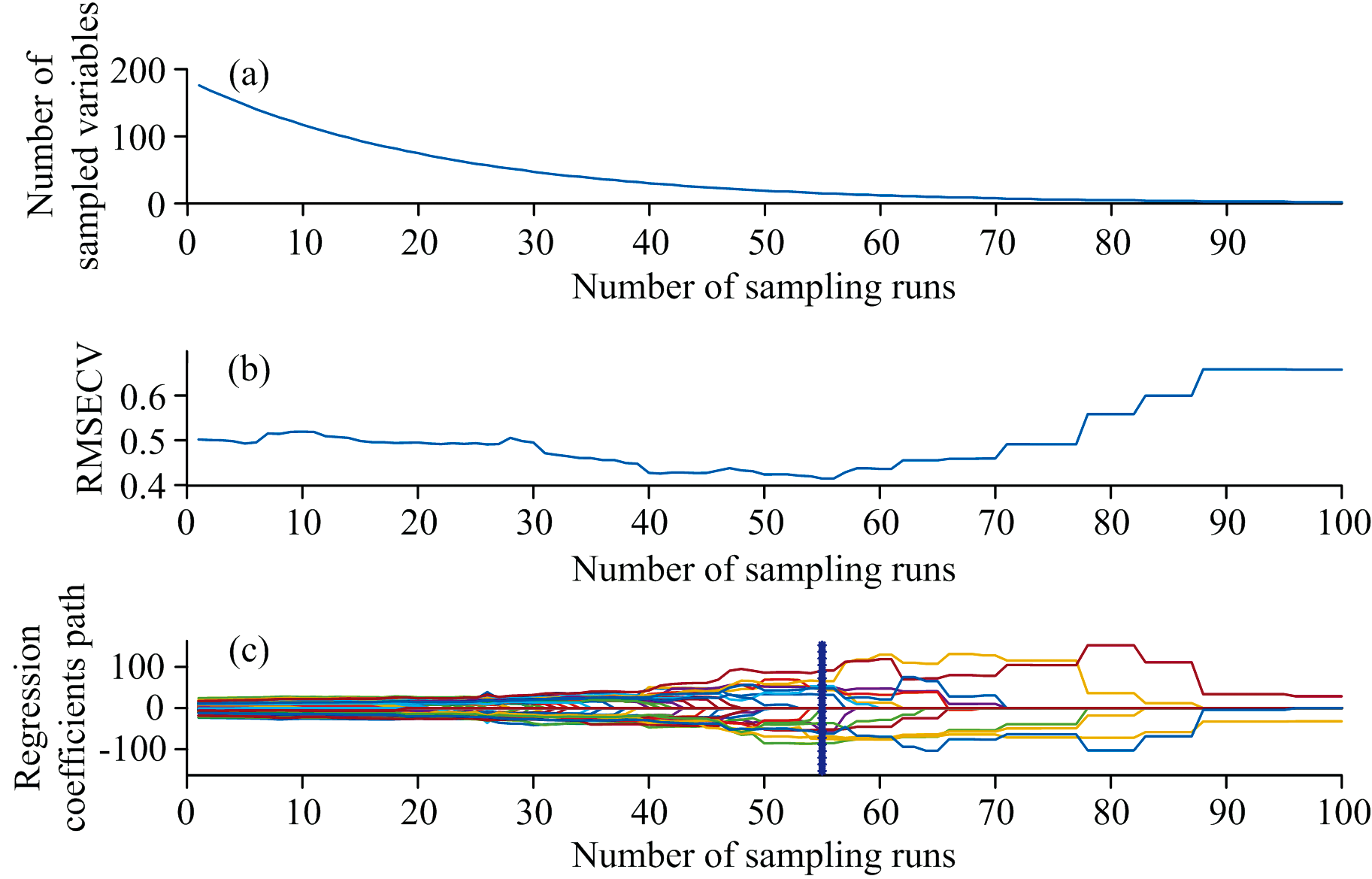 | 图5 CARS算法筛选特征波长过程Fig.5 Process of screening feature wavelength by CARS algorithm |
UVE算法的核心是根据光谱变量加噪声组成自变量矩阵, 对目标变量的回归系数的统计分布进行变量判断[15], 如图6所示, 蓝线左侧是需要进行筛选的176个光谱变量, 虚线为噪声域的上下界作为筛选光谱变量的阈值为± 30.88。
 | 图6 UVE算法筛选特征波长过程Fig.6 UVE algorithm screening feature wavelength process |
剔掉蓝色虚线区域内的光谱变量, 虚线外的光谱变量为挑选出的特征波长。
如图7所示, 为反射、 吸收和K-M变换光谱原始光谱及其Baseline预处理后光谱经CARS算法所挑选特征波长。 图7(a)为通过CARS算法筛选出R-RAW光谱的13个特征波长, 占总波长的7.39%; 图7(b)为R-Baseline光谱通过CARS算法筛选出21个特征波长, 占总波长的11.93%; 图7(c)为A-RAW光谱通过CARS算法筛选出15个特征波长, 占总波长的8.52%; 图7(d)为A-Baseline光谱通过CARS算法筛选出22个特征波长, 占总波长的12.50%; 图7(e)为K-M-RAW光谱通过CARS算法筛选出5个特征波长, 占总波长的2.84%; 图7(f)为K-M-Baseline光谱通过CARS算法筛选出12个特征波长, 占总波长的6.82%。
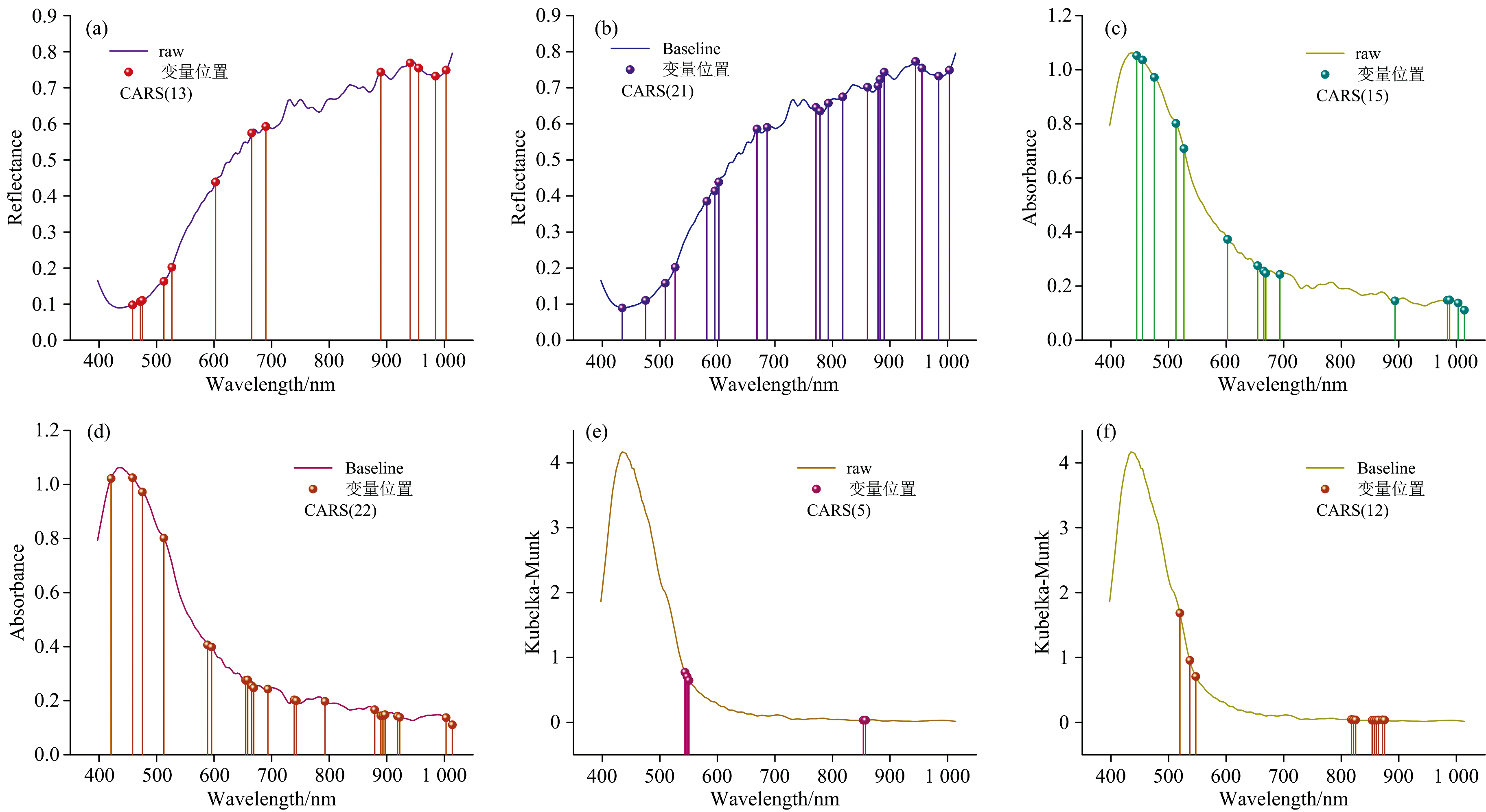 | 图7 CARS算法挑选变量过程 (a): 反射光谱-原始光谱R-RAW; (b): 反射光谱-基准线校准R-Baseline; (c): 吸收光谱-原始光谱A-RAW; (d): 吸收光谱-基准线校准A-Baseline; (e): Kubelka-Munk光谱-原始光谱K-M-RAW; (f): Kubelka-Munk光谱-基准线校准K-M-BaselineFig.7 CARS algorithm selection of variables (a): R-RAW; (b): R-Baseline; (c): A-RAW; (d): A-Baseline; (e): K-M-RAW; (f): K-M-Baseline |
如图8所示, 为反射、 吸收和K-M变换光谱原始光谱及其Baseline预处理后经UVE算法挑选的特征波长, 图8(a)为通过UVE算法筛选出R-RAW光谱的136个特征波长, 占总波长的77.27%; 图8(b)为R-Baseline光谱通过UVE算法筛选出114个特征波长, 占总波长的64.77%; 图8(c)为A-RAW光谱通过UVE算法筛选出128个特征波长, 占总波长的72.73%; 图8(d)为A-Baseline光谱通过UVE算法筛选出39个特征波长, 占总波长的22.16%; 图8(e)为K-M-RAW光谱通过UVE算法筛选出113个特征波长, 占总波长的64.20%; 图8(f)为K-M-Baseline光谱通过UVE算法筛选出109个特征波长, 占总波长的61.93%。
 | 图8 UVE算法挑选变量过程 (a): 反射光谱-原始光谱R-RAW; (b): 反射光谱-基准线校准R-Baseline; (c): 吸收光谱-原始光谱A-RAW; (d): 吸收光谱-基准线校准A-Baseline; (e): Kubelka-Munk光谱-原始光谱K-M-RAW; (f): Kubelka-Munk光谱-基准线校准K-M-BaselineFig.8 Variable selection using UVE algorithm (a): R-RAW; (b): R-Baseline; (c): A-RAW; (d): A-Baseline; (e): K-M-RAW; (f): K-M-Baseline |
将三种原始光谱和经Baseline预处理后的光谱, 利用CARS和UVE算法筛选出特征光谱, 利用筛选后的特征波长建立BP模型, 由于光谱数量的减少提高了模型的运行速度[16]。 如表2所示, 为CARS和UVE挑选后的特征光谱建立的BP模型预测结果。 由表2可知, 经过UVE算法筛选后的特征波长建立的模型, 除R-Baseline-UVE-BP模型有1.66个百分点的提升外, 其余均有一定程度的下降, 原因可能为UVE算法挑选的特征波段无法反映贡梨碰伤程度的数据集的规律和特征。 从表1和表2可知, 经过特征波段筛选后的K-M-RAW和K-M-Baseline光谱建立的BP模型准确率下降较大, 可能是CARS算法对K-M光谱和K-M-Baseline光谱在筛选特征波长时, 不仅删除了无关变量也剔除了一部分有关信息。 A-RAW-CARS-BP模型和R-Baseline-CARS-BP模型与全光谱建立的模型相比准确率得到提升, A-RAW-CARS-BP模型在特征波段建立的BP模型中准确率最高, 准确率达到了96.66%, R-Baseline-CARS-BP模型准确率提升至90%。 结果表明, 吸收光谱数据建立的模型, 能更好的判别贡梨的损伤程度, 原因可能是贡梨在吸收光谱的特征峰的强度和位置更能反应贡梨的损伤信息。
| 表2 基于特征波长建立的BP预测模型 Table 2 BP prediction model based on characteristic wavelengths |
利用高光谱技术对贡梨的不同损伤程度的判别进行了探究, 为提升对贡梨损伤程度判别准确率, 引入了吸收和K-M变换光谱, 与反射光谱判别效果进行了比较, 主要结论如下: (1)基于全波段光谱建立的模型中BP模型效果较好, 与原始光谱相比经过Baseline预处理后的吸收光谱建立的BP模型提升较为明显, 准确率达到了93.33%。 (2)基于CARS算法挑选的特征波段建立的BP模型效果有所提升, 其中A-RAW-CARS-BP模型准确率相比于全波段光谱A-RAW-BP模型提升尤为明显, 对贡梨损失伤程度整体判别准确率达到了96.66%, 判别准确率最优。 (3)利用UVE算法挑选特征波段建立BP模型, 发现波段筛选后的光谱数据所建立的BP模型效果变差, 因此UVE算法不适用于贡梨碰伤的光谱波段筛选。 (4)通过各个模型的结果分析可知, Ⅱ 、 Ⅲ 级损伤程度的贡梨样本容易出现误判, 原因可能是Ⅱ 、 Ⅲ 级损伤样本之间的损伤程度差异太小。 研究表明高光谱成像技术可以对贡梨损伤程度进行判别, 并且基于吸收光谱全波段建立的BP模型能够有效的对贡梨的损伤进行判别, 为贡梨不同损伤程度的无损检测提供了科学依据。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|