







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于空洞卷积神经网络的红壤有机质含量预测研究
[邓昀1, 2  , 吴蔚
, 吴蔚1, 2 , 石媛媛3 , 陈守学1, 2, * ]
, 吴蔚]
|
|


作者简介: 邓 昀, 1980年生, 桂林理工大学信息科学与工程学院教授 e-mail: 574359451@qq.com
土壤有机质(SOM)含量是衡量土壤肥力的重要指标之一, 从高光谱遥感图像中有效预测SOM含量具有重要意义。 传统的机器学习方法需要复杂的特征工程且精度不高, 而以卷积神经网络(CNN)为代表的深度学习方法在土壤高光谱领域研究较少, 且对小样本数据建模精度较差, 光谱数据的空间特征提取不足。 因此, 提出了一种使用通道注意力机制的一维空洞卷积网络模型(SE-DCNN)。 以广西国有黄冕林场和国有雅长林场采集的207个土壤样本为研究对象, 对比分析了3种机器学习方法和4种深度学习方法在不同光谱预处理下的建模效果。 结果表明, SE-DCNN模型因为使用了空洞卷积和通道注意力机制, 扩大感受野并提取多尺度特征, 有较好的建模精确度和泛化拟合能力。 最佳预测模型是基于S-G降噪(SGD)和一阶微分(DR)的光谱预处理方式建立的SE-DCNN模型, 验证集的决定系数(R2)为0.971, 均方根误差(RMSE)为2.042 g·kg-1, 相对分析误差(RPD)为5.273。 因此, 使用SE-DCNN能够对广西林地红壤有机质含量进行准确预测。
Soil Organic Matter (SOM) content is one of the important indicators used to measure soil fertility, and it is of great significance in accurately predicting SOM content from hyperspectral remote sensing images. Traditional machine learning methods require complex feature engineering. Still, they are not highly accurate, while deep learning methods represented by Convolutional Neural Networks (CNNs) are less studied in soil hyperspectral, and the modeling accuracy of small sample data is poor. The spatial feature extraction of spectral data is insufficient. This paper proposes a one-dimensional convolutional network model using a channel attention mechanism (SE Dilated Convolutional Neural Network, SE-DCNN). Taking 207 soil samples collected from Guangxi State-owned Huangmian Forest Farm and State-owned Yachang Forest Farm as research objects, this paper compares and analyzes the modeling effects of 3 machine learning and 4 deep learning methods under different spectral preprocessing. The results show that the SE-DCNN model, because of the use of dilated convolution and channel attention mechanism, expands the receptive field, extracts multi-scale features, and has good modeling accuracy and generalization fitting ability. The best prediction model in this paper is the SE-DCNN model established based on the spectral preprocessing method of Savitaky-Golay denoising (SGD) and first-order derivative (DR), the determination coefficient ( R2) of the validation set is 0.971, the root mean square error (RMSE) is 2.042 g·kg-1, and the relative analysis error (RPD) is 5.273. Therefore, SE-DCNN can accurately predict the organic matter content of red soil in Guangxi forest land.
土壤有机质(soil organic matter, SOM)是反映土壤质量和生态环境的重要指标。 它是植物重要的营养来源, 还是陆地生态系统中的重要碳储存库, 对维持全球碳循环的平衡有重要的作用[1]。 快速、 准确获取SOM含量, 掌握它的动态变化对于农业发展和全球碳循环的平衡具有重要的意义[2]。 传统SOM含量测定主要依靠取样和化验分析来实现, 这种方法虽然精度较高, 但操作繁琐, 周期长, 成本高, 无法快速有效监测土壤的退化状况[3]。 高光谱遥感技术的发展为SOM的含量快速测定提供了有效手段[4]。 但通过高光谱仪得到的数据容易受到一些不确定的环境因素的影响并引起光谱噪声, 导致建模效果不佳。 对此需要使用降噪和数学转换等方法提取光谱特征, 并使用多种建模方法进行对比。 2019年, 包青岭[5]等使用S-G降噪(Savitzky-Golay denoising, SGD)煌小波分解, 结合RF进行建模, 有效减少了噪声波段的干扰, 提高了特征波段分类预测的精度。 2020年, Shen[6]等使用小波去噪和主成分分析(PCA)降维, 通过偏最小二乘法(PLSR)建模, 取得了较高的建模精度。 Xu[7]等使用SGD, 对光谱数据进行分数阶微分结合PCA, 有效提高了SOM含量预测的准确性。 2021年, 尚天浩[8]等使用倒数的对数(RL)建立的PCA-SVM建模效果较好, 建模精度R2为0.78。 2022年, Carvalho[9]等使用标准正态变化(SNV)预处理结合SVM建模, 取得了较好的预测效果。
然而, 大多采用机器学习方法对高光谱数据进行建模, 需要进行复杂的特征工程, 且灵活性较差, 建模精度不佳[10]。 近年来, 深度学习方法凭借强大的特征学习能力, 在图像识别、 自然语言处理等领域取得广泛的应用, 但在土壤高光谱遥感领域研究较少, 同时在小样本数据集上建模精度较差。 此外, 不同的研究者对土壤样本的处理方式和光谱数据的预处理方式不同, 很难比较所得的结果。
因此, 选取常见的3种降噪方式和6种数学变换方式进行组合, 对原始光谱数据进行预处理, 再使用3种传统机器学习方法(PLSR、 SVM、 RF)和4种深度学习方法(TCN、 ResNet-18、 VGGNet-7、 SE-DCNN)对处理后的数据建模。 通过分析建模效果, 探究出一种精度高, 能快速预测SOM含量的模型。 为广西林地红壤基于光谱数据快速预测SOM含量的建模提供参考。
研究区位于广西国有黄冕林场(109° 43'— 109° 58'E, 24° 37'— 24° 52'N)和国有雅长林场(106° 08'— 106° 26'E, 24° 37'— 25° 00'N), 都属于亚热带气候, 年均降雨量分别为1 750和1 058 mm, 年均蒸发量分别为1 426和1 484.7 mm, 年平均温度分别为19和16.8 ℃。 本区土地利用类型为林地, 土壤主要以砂页岩发育而成的山地红壤为主, 主要种植桉树、 杉树和松树。 由于缺乏有效土壤养分检测以进行合理施肥, 加上树种和品种结构单一, 导致林地土壤肥力下降, 影响森林的生长和健康。
根据研究区内的林地面积和林木分布情况, 采用S型取样法在0~20 cm土层中收集了207个土壤样本, 采样点的分布情况如图1所示。 所有样本于实验室经过自然风干和研磨后, 一部分样本通过0.2 nm的筛网过滤, 采用重铬酸钾氧化法测定其SOM含量; 另一部分样本通过0.149 nm的筛网过滤, 采用ASD FieldSpec1 4 Hi-Res地物光谱仪测光谱。 为了提高光谱数据的精度, 每个样本的光谱数据重复采集10次, 并取其算数平均值作为该样本最终的光谱曲线。 为了消除传感器、 大气、 光照变化等环境因素对光谱曲线的影响, 剔除了每个样本中噪声较大的边缘波段350~399和2 401~2 500 nm, 保留了400~2 400 nm波段进行分析。 同时, 为了降低数据维度和冗余度, 采用每10 nm间隔取平均值的方法对光谱数据进行了重采样处理。
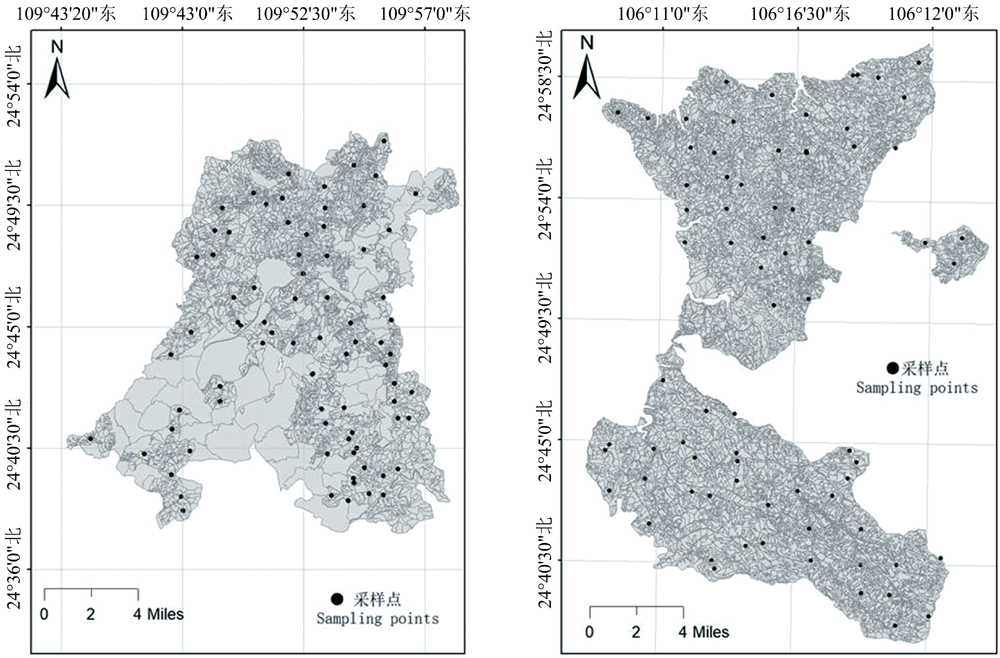 | 图1 研究区域采样点分布Fig.1 Sampling point distribution |
共进行了126组实验, 利用光谱数据预测SOM含量。 首先, 对原始土壤光谱数据进行了预处理, 包括降噪和数学变换。 其中降噪方式有3种, 分别是: 不降噪(ND)、 S-G平滑滤波降噪(SGD)、 离散小波变换(DWT)降噪。 数学变换方式有6种, 分别是: 原始数据R、 一阶微分DR、 对数log(R)、 对数的一阶微分 (log(R))'、 倒数1/R、 倒数的一阶微分(1/R)'。 然后, 采用了7种建模方法, 其中3种机器学习方法(偏最小二乘回归PLSR、 支持向量机SVM、 随机森林RF), 4种深度学习方法[时序卷积网络TCN、 VGGNet-7、 残差网络ResNet-18、 使用通道注意力机制的空洞卷积神经网络(SE dilated convolutional neural network, SE-DCNN)]。 通过对不同预处理方式的相关性分析, 以及对不同建模方法的SOM含量预测精度分析, 选出了最佳的预处理方式和最佳的建模方法。 本研究的方法流程如图2所示。
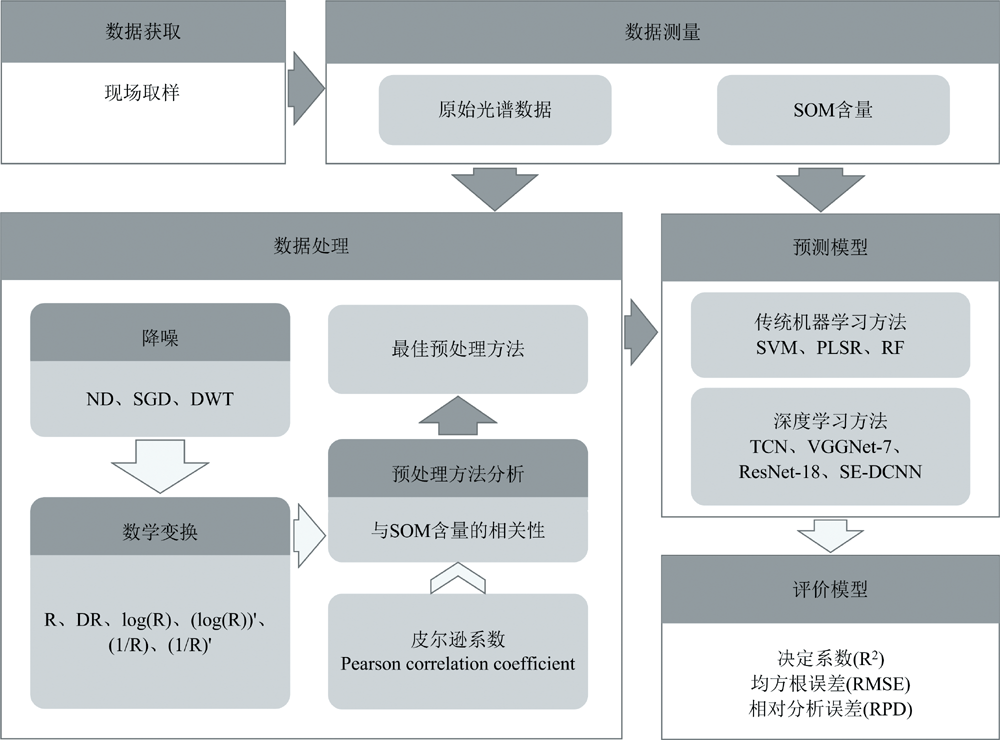 | 图2 方法流程图Fig.2 Method flowchart |
2.2.1 S-G滤波降噪
S-G滤波器(Savitzky-Golay denoising, SGD)是一种常用于预处理土壤光谱的低通滤波器, 它的原理是通过最小二乘法拟合曲线局部多项式, 使用滑动窗口的加权平均算法, 从而消除高频噪声, 平滑频谱, 保留低频信号。 表达式如式(1)
式(1)中, Yj是原始光谱的数据,
2.2.2 离散小波变换(DWT)降噪
离散小波变换(discrete wavelet transform, DWT)降噪是一种利用小波函数对信号进行多尺度分解的降噪方法。 它能够有效地提取各个频带中的有用信息, 从而降低高光谱数据中的噪声干扰[11]。 采用了Donoho提出的基于小波变换的阈值降噪方法[12], 阈值的计算公式如式(2)
式(2)中, σ 为小波系数的标准差的估计值, 由小波系数的绝对值的中位数除以0.674 5得到, N为小波系数的个数。 降噪阈值设定为threshold/2, 使用db4(Daubechies4)作为小波函数, 设置3层小波变换。
2.2.3 数学变换
为研究不同数学变换对光谱数据特征表达能力的影响, 采用6种方法对数据进行处理, 包括: 原始数据R、 一阶微分DR、 对数log(R)、 对数的一阶微分(log(R))'、 倒数1/R、 倒数的一阶微分 (1/R)'。
SPXY算法是一种基于联合x-y距离的样本集划分方法, 它是在KS算法的基础上发展而来的[13]。 SPXY算法的原理是将基于光谱的距离和基于目标成分的距离相结合, 以选择一个具有代表性的校准集。 为了给x空间和y空间的分布赋予相等的重要性, 可以计算归一化的XY距离。 其距离公式为式(3)
式(3)中, dx(p, q)是样本p和q之间的光谱欧氏距离, dy(p, q)是样本p和q之间的SOM含量欧氏距离,
2.4.1 空洞卷积神经网络(dilated convolutional neural network, DCNN)
卷积神经网络(convolutional neural network, CNN)是一种常用的深度学习模型, 它由输入层、 卷积层、 池化层、 全连接层和输出层构成。 卷积层利用一个或多个卷积核提取光谱数据的局部特征, 实现光谱数据的卷积运算; 池化层通过下采样降低特征图长度; 全连接层将各层提取的特征进行融合; 输出层由多个神经元组成; 它们根据全连接层的输出对输入数据进行回归。 DCNN是CNN的一种改进形式[14]。 它采用带空洞率的空洞卷积层来增强网络性能。 空洞率控制卷积核元素之间的间隔, 增加感受野并捕捉多尺度信息。 DCNN在处理序列数据和图像分割等任务上表现较好, 能捕捉长程依赖关系[15]。
2.4.2 SE-block模块
传统CNN在处理光谱数据时存在一定的局限性, 主要体现在: 没有充分利用光谱中与SOM含量相关的光谱特征, 易受噪声干扰; 没有考虑波段间的相关性和冗余性, 空间特征不足; 对不同噪声水平下的数据缺乏适应性。 为解决上述问题, 本研究引入了使用通道注意力机制的SE-block结构。 SE-block通过通道注意力机制计算每个波段的重要性权重, 用权重动态调整每个波段的输出特征, 同时可以减少空间维度, 增强特征的全局性。 一维卷积SE-block的结构如图3所示, 运行主要分为Squeeze和Excitation两个步骤。
 | 图3 一维卷积的SE-block结构Fig.3 SE-block structure of 1D convolution |
步骤1: Squeeze的目的是生成通道统计信息, 对每个特征的Embedding(将特征映射到连续的向量空间)向量进行数据压缩与信息汇总, 通过使用全局平均池生成通道统计信息, 如式(4)
式(4)中, k为维度大小, vi为一个特征。 Squeeze步骤将每个k维特征压缩成单个数值zi, 即该特征所有k维数字的平均值。 假设特征Embedding层有f个特征, 则形成的Squeeze向量Z, 大小为f。
步骤2: Excitation的目的是通过两层MLP动态计算每个特征的重要性, 从而加强有用的特征, 抑制无用或噪声的特征, 化如式(5)
式(5)中, S表示输出, Fex表示Excitation模块, Z表示输入, W1和W2分别表示两层MLP的权重矩阵, δ 表示激活函数。 输入Z分别经过两层MLP(权重矩阵分别为W1和W2)和激活函数δ 的计算, 得到最终输出S。
2.4.3 改进的空洞卷积网络(SE-DCNN)模型
SE-DCNN在DCNN模型基础上, 加入了SE-block模块单元。 模型的结构如图4所示。 模型首先通过卷积层提取输入光谱的特征, 然后将这些特征输入到全连接层。 接下来, SE-block使用全局平均池化层对卷积层的输出进行池化, 以提取全局信息。 再通过两层全连接层和激活函数进行计算, 对特征通道之间相互依赖关系进行建模。 最后通过Reshape层将输出调整为与输入数据相同的形状并将它们相乘, 实现了对输入数据的加权。 SE-block的加入使得DCNN模型能够更好地建模特征通道之间的依赖关系, 具有自适应通道选择的能力, 并增强了模型的表达能力。
 | 图4 SE-DCNN模型结构Fig.4 SE-DCNN model structure |
2.5.1 PLSR
偏最小二乘回归(partial least squares regression, PLSR)是一种利用偏最小二乘回归算法对高光谱数据进行分析和预测的算法。 它融合了多元线性回归分析、 典型相关分析和主成分分析的优势, 在处理自变量和因变量之间存在多重共线性或样本数量不足的问题方面具有优势。
2.5.2 SVM
支持向量机(support vector machine, SVM)是一种监督学习算法。 它基于统计学理论, 通过监督学习在特征空间中寻找最大间隔的分类超平面, 从而实现非线性问题的有效求解。 它具有良好的泛化能力, 能够有效地处理高维、 小样本和非线性问题。
2.5.3 RF
随机森林(random forest, RF)是一种利用决策树集成进行分类与回归分析的算法。 通常采用投票或平均法对决策树结果进行集成。 它通过随机选取样本和特征, 构建多棵决策树, 并对各树的预测结果进行综合, 得到最终的预测结果。
2.5.4 TCN
时序卷积网络(temporal convolutional network, TCN)是一种利用时序建模的深度学习算法。 TCN算法通过因果卷积提取短期特征, 通过扩张卷积建模长期依赖性。 它通过组合因果卷积和扩张卷积, 构建了一个能够捕捉长期依赖关系的深度网络结构。
2.5.5 VGGNet-7
VGGNet-7算法是VGGNet(visual geometry group network)系列中较浅的一种。 它由7个卷积层和3个全连接层组成, 共10层。 VGGNet-7算法的特点是使用了小尺寸(3× 3)的卷积核, 以及较多的卷积层和池化层, 来增加网络的深度和感受野, 增强模型的学习能力。
2.5.6 ResNet-18
残差网络(residual network, ResNet-18)是一种由18个带有权重的层组成的深度神经网络。 深度神经网络中, 随着网络层数的增加, 训练误差反而增大, 存在退化问题。 ResNet采用残差模块可以有效地缓解梯度消失或爆炸的问题, 增强网络的训练效率和稳定性。
采用多个指标评价模型的性能, 包括决定系数(R2)、 均方根误差(RMSE)和相对分析误差(RPD)。 其中, R2用于评价模型的精度, RMSE评价模型的预测误差, RPD评价模型的可信度。 R2表示模型的拟合程度, R2值越大, 模型的精度越高。 RMSE表示模型中SOM含量的真实值与预测值之间的误差, 训练集和验证集的RMSE的值越小且越接近, 模型的估计精度和稳定性越高。 RPD表示模型性能与偏差之间的比值。 计算公式如式(6)— 式(8)
$ \text { RMSE }=\sqrt{\frac{1}{n} \sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}}$ (6)
$ R^{2}=1-\frac{\sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}}{\sum_{i=1}^{n}\left(y_{i}-\bar{y}\right)^{2}}$ (7)
式中, n表示样本的数量, yi和$\hat{y}_{i}$分别表示第i个样本的SOM含量的实测和预测值, SD表示实测值的标准差。
研究区内共采集了207个样本, SOM的取值范围为4.26~80.04 g· kg-1, 平均值为25.62 g· kg-1, 标准差为13.58 g· kg-1。 通过SPXY算法, 按照4∶ 1将样本划分为训练集和验证集。 土壤SOM含量统计特征见表1。 训练集的SOM含量的平均值为25.91 g· kg-1, 标准差为13.77 g· kg-1, 验证集的SOM含量蹬平均值为24.43 g· kg-1, 标准差为12.71 g· kg-1。 两个数据集的SOM变异系数均在53%左右, 表明数据存在一定的离群值。 因此, 在建立预测模型时, 需要考虑数据的非线性和非均匀性特征, 选择合适的预处理方式, 评估各种模型的泛化能力和准确性, 以提高预测效果。
| 表1 土壤有机质含量统计特征 Table 1 Statistical characteristics of SOM content |
高光谱反射率的大小和变化速度与SOM含量有着密切联系。 如图5所示, 在可见光波段(400~800 nm), 由于土壤中有机质对可见光有较强的吸收作用, 反射率随着SOM含量的增加而逐渐降低。 在近红外波段(800~1 400 nm), 由于SOM对近红外光有较强的反射作用, 反射率随着SOM含量的增加而逐渐增加。 在中红外波段(1 400~2 400 nm), 反射率随着SOM含量的增加波动幅度逐渐减小。 此外, 在中红外波段还存在一些与土壤中其他成分有关的特征波段, 主要表现为一些吸收峰。 在1 420和1 930 nm处的吸收峰表现为反射率随着水分含量的增加而降低[16]。 在2 290 nm处, 通过比较不同SOM含量的样本在这个波段处的反射率, 可以发现反射率随着SOM含量的增加而降低, 说明这个吸收峰与SOM含量具有强相关性。
 | 图5 不同SOM含量土壤样本的高光谱曲线Fig.5 Spectral curves of soil samples with different SOM contents |
相关分析是分析自变量和因变量之间相关性的经典可靠的方法[17]。 对经过不同预处理的光谱数据进行相关性分析。 预处理组合共有18种, 如表2所示。
| 表2 本研究使用的不同预处理组合 Table 2 Different combinations of pretreatments used in this study |
图6展示了相邻波段的相关系数与SOM含量的相关度情况。 可以看出, R的相邻波段之间呈现负相关性, log(R)与1/R的相邻波段之间呈现正相关性, 这三种数学变换方式呈现出的相关性比较单一。 而经过DR、 (log(R))'和 (1/R)'变换后, 相邻光谱之间呈现多样化的相关性关系。
 | 图6 不同预处理方法下SOM含量与光谱波段之间的相关性Fig.6 Correlation between SOM content and spectral bands under different preprocessing methods |
图7展示了相关系数随波长变化的情况。 可以看出, 在400~2 400 nm范围内, SOM含量与R之间存在着显著的负相关关系, 相关系数的变化很小。 这意味着对应的相邻波段之间的相关系数是相似的, 与图6得到的结论一致。 SOM含量与log(R)的相关度曲线的趋势和R的情况相似。 SOM含量和1/R的相关度曲线几乎是SOM含量和R的曲线关于x轴对称的镜像, 相邻波段之间的相关系数变化较小。 SOM含量与DR之间的相关度曲线在整个波长范围内有明显的变化, 在700~850和1 050~1 350 nm波段呈现出上升趋势, 在850~1 050 nm波段呈现下降趋势。 这些线条的斜率较为陡峭, 表明SOM含量与DR之间存在着强相关性。 同样的, SOM含量与(1/R)'、 (log(R))'之间的相邻波段之间的相关系数随着波长的增加而发生明显变化, 相关性也比较强。 SGD-DR的相邻波段之间的相关系数分布多样化, 既有正相关的区域, 也有负相关的区域, 充分展现了高光谱数据的特征, 是较好的预处理方式。
 | 图7 在ND、 SGD和DWT条件下, 经过六种不同转换的波长为400~2 400 nm的SOM含量和光谱数据之间的相关系数曲线Fig.7 Correlations between SOM content and spectral data subjected to six different transformations under ND, SGD, DWT at wavelengths of 400~2 400 nm |
采用PLSR、 SVM和RF三种机器学习方法进行建模, 以比较本方法在建模效果上的差异, 以及在不同光谱预处理方式下的预测效果。 机器学习的模型均采用了网格搜索(GridSearch)结合交叉验证(CV), 获取最佳参数。 模型的精度如表3所示。 可以看出, 在不同预处理方式下, SVM建模方法都表现出了最佳的数据拟合和泛化能力。 使用SGD-DR作为预处理方式的SVM建模达到了最好的预测精度(R2=0.937, RPD=3.98), 与Zhang[18]等的结论一致。 说明SGD-DR的预处理方式能够提取光谱数据特征, 有助于提高模型的泛化能力, 与Qiao[19]等的结论一致。 不同的预处理方式和机器学习方法对高光谱数据建模的效果有所影响, 有些组合存在明显的过拟合问题, 说明这些组合在新数据上缺乏泛化能力。
| 表3 基于机器学习的不同预处理方法的SOM含量预测模型 Table 3 SOM content prediction model based on different preprocessing methods of machine learning |
为了研究SE-DCNN与其他CNN模型的建模效果的差异, 选取了TCN、 VGGNet-7和ResNet-18作为对比方法。 TCN和SE-DCNN都可以有效地处理序列数据, VGGNet-7和SE-DCNN都可以在小数据集上实现高精度的建模, ResNet-18则使用了残差结构和通道注意力机制进行对比。 为了具有可比性, 所有CNN模型均采用相同的超参数设置: ElasticNet正则化、 Adam优化器、 学习率0.001、 全连接层的参数分别为200和100, Dropout层的参数为0.2。 根据实验结果, 选取效果最好的SGD作为降噪方式建立的模型精度表, 如表4所示。
| 表4 基于卷积神经网络的不同预处理方法的SOM含量预测模型 Table 4 SOM content prediction model based on different preprocessing methods of convolutioral neural network |
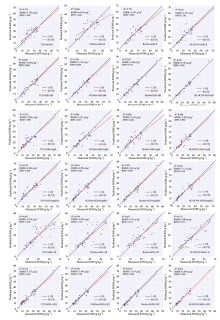
根据实验结果绘制了实测值与预测值的散点图, 如图8所示。 可以看出不同的数学变换方法对CNN建模有较大影响, 使用SGD-DR的CNN模型, 都有较高的建模精度, R2平均值为0.943, RMSE平均值为3.006 g· kg- 1, RPD平均值为4.378。 其次是SGD-(1/R)'。 使用SGD-R1D的建模效果最差, R2平均值为0.673, RMSE平均值为4.769 g· kg- 1, RPD平均值为1.78。 可以看出, 建模中效果最好的预处理方式为SGD-DR, 与使用机器学习建模得到的结论一致。 基于SGD-DR预处理的CNN模型训练和验证精度曲线如图9所示。 其中, SE-DCNN模型在所有预处理方式下都能较好地拟合真实值, 表现出较高精度和稳定性。 其次是ResNet-18, 因为它利用残差连接增强升读和非线性, 具有较好的泛化能力。 而TCN和VGGNet-7模型则表现出不同程度的偏差和波动。 SE-DCNN使用空洞膨胀函数扩大了感受野, 能提取光谱数据的空间信息和通道信息, 动态调整注意力权重, 提高模型的灵活性和适应性, 因此建模效果最好。 综上所述, 使用SGD-DR的SE-DCNN有最佳建模效果(RMSE=2.154 g· kg- 1, R2=0.971, RPD=5.902), 是本研究中预测精度最高的模型。
 | 图8 基于卷积神经网络建模的SOM的实测值与预测值的散点图Fig.8 Scatter plot of measured and predicted values of SOM based on convolutional neural network modeling |
 | 图9 基于SGD-DR的卷积神经网络建模的SOM含量的预测精度曲线Fig.9 Prediction accuracy curves of SOM content based on convolutional neural network modeling with SGD-DR |
以广西国有黄冕林场和广西国有雅长林场的林地土壤为研究对象, 利用不同的降噪方式和数学转换方式为高光谱数据进行了预处理, 分析对比了各种预处理组合的降噪和特征提取效果。 使用3种机器学习、 3种经典CNN模型以及SE-DCNN进行建模效果的对比, 结果证明SE-DCNN模型精度较为理想, 为广西林地SOM含量预测的预处理方式和建模方法提供了参考。 然而, 还存在其他可能提高SOM含量预测精度的方法。 因此, 在未来可以使用一些新的光谱预处理技术来降低噪声对光谱的干扰, 或者改变土壤样本量的分配比例, 从而进一步提高模型精度, 实现SOM含量的快速、 准确预测。
以广西国有黄冕林场和国雅长林场207份土壤为样本, 使用土壤光谱数据, 分析了18种光谱预处理方式、 3种机器学习方法和4种深度学习方法的建模效果, 最终选择了一个准确有效的SOM含量预测模型。 结论如下:
(1)本研究所涉及的预处理方式中, SGD可以有效消除噪声并保留数据原始特征。 DR、 (1/R)'和(log(R))'的数学变换方式在相邻波段与SOM含量的相关度图中呈现出丰富的相关性, 它们的相关系数曲线分布多样化, 说明经过SGD的一阶微分是较好的预处理方式, 可以增强光谱数据的特征表达能力。
(2)在使用机器学习的SOM含量预测模型中, 验证集精度最高的组合为SVM-SGD-DR(R2=0.937, RMSE=3.195 g· kg-1, RPD=3.98)。 SVM模型可以对非线性问题进行优化, 得到较好的建模效果。
(3)在使用SGD-DR的CNN模型中, SE-DCNN模型相比TCN、 VGGNet-7和ResNet-18模型有更高的建模精度。 相比之下验证集的R2分别提高了4.5%、 3.3%和3.6%; RMSE分别减低了1.296、 1.018和1.094; RPD分别提高了2.216、 1.893和1.987。 CNN模型中模块的选择会影响网络的深度、 宽度、 感受野、 特征提取能力等方面, 从而影响预测结果的准确性和泛化性。
(4)在所有建模方法中, SE-DCNN模型因为采用了空洞卷积和通道注意力的机制, 预测土壤样本的SOM含量的总体效果最佳(R2=0.971, RMSE=2.154 g· kg- 1, RPD=5.902)。 因此, 采用基于SGD-DR的SE-DCNN模型能够较好地预测广西国有黄冕林场和国有雅长林场的SOM含量。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|