



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外光谱结合Stacking集成学习的猕猴桃糖度检测研究
[郭志强1  , 张博涛
, 张博涛1 , 曾云流2, * ]
, 张博涛]
|
|


作者简介: 郭志强, 1976年生, 武汉理工大学信息工程学院教授 e-mail: guozhiqiang@whut.edu.cn
利用近红外光谱技术Stacking集成学习对猕猴桃糖度的无损检测。 以湖北“云海一号”猕猴桃为研究对象, 采用红外分析仪获取了280个样本的光谱数据, 包含了4 000~10 000 cm-1范围内的1 557个波长数据, 使用折射仪测量糖度值。 通过蒙特卡洛随机采样结合T检验的奇异样本识别算法筛除异常值样本。 利用SPXY算法按照4∶1的比例划分训练集和测试集。 使用多元散射校正(MSC)、 SG平滑滤波(SG)、 趋势校正(DT)、 矢量归一化(VN)、 标准正态变换(SNV)五种方法对数据进行预处理。 使用无信息变量消除法(UVE)、 竞争性自适应重加权算法(CARS)和区间变量迭代空间收缩特征选择算法(iVISSA)提取特征波长, 使用连续投影算法(SPA)进行二次提取, 消除共线性变量。 由于单一模型的泛化能力有限, 为了扩大建模能力, 设计了一种基于Stacking算法的集成学习模型。 选择贝叶斯岭回归(BRR)、 偏最小二乘回归(PLSR)、 支持向量机回归(SVR)以及人工神经网络(ANN)作为基学习器, 线性回归(LR)作为元学习器建立集成模型, 比较不同组合下集成模型的性能。 使用Pearson相关系数分析基学习器与集成模型之间的关系。 结果表明: 在五种预处理方法之中, 矢量归一化的效果最佳。 对预处理后的光谱进行特征波长提取, 结果显示VN-CARS-PLSR模型效果最好, 在测试集上的
In this study, we employ near-infrared spectroscopy with Stacking ensemble learning to perform non-destructive sugar content analysis in kiwifruit. Our research focuses on the “Yunhai No.1” kiwifruit variety from Hubei. Using an infrared analyzer, we gathered spectral data from 280 samples, spanning 1 557 wavelengths in the 4 000~10 000 cm-1 range, and measured sugar content with a refractometer. Outliers were identified and excluded using a singular sample identification algorithm that combines Monte Carlo random sampling with a T-test. The SPXY algorithm was then employed to split the data into training and testing sets in a 4∶1 ratio. Data preprocessing involved multiple scattering corrections (MSC), Savitzky-Golay smoothing (SG), de-trending (DT), vector normalization (VN), and standard normal variable (SNV) transformations. Feature wavelengths were initially selected using uninformative variable elimination (UVE), competitive adaptive reweighted sampling (CARS), and interval variable iterative space shrinkage approach (iVISSA), followed by a secondary selection with the successive projections algorithm (SPA) to remove collinear variables. To address the limitations of single models in generalization, we designed an integrated learning model using the Stacking algorithm. This model incorporated Bayesian ridge regression (BRR), partial least squares regression (PLSR), support vector regression (SVR), and artificial neural networks (ANN) as base learners, with linear regression (LR) serving as the meta-learner. We assessed the performance of various ensemble model combinations and analyzed the influence of base learners on ensemble performance using the Pearson correlation coefficient. Experimental results indicated that vector normalization was the most effective among the five preprocessing methods. The VN-CARS-PLSR model demonstrated superior performance, with
猕猴桃因其营养价值高, 果肉口感好, 味道清甜爽口的原因, 享有“ 世界珍果” 、 “ 维C之王” 等美称。 其果肉包含维生素、 有机酸、 类胡萝卜素等多种对人体有益的营养物质, 也含有减缓疲劳、 提高免疫力、 预防心脑血管疾病等功效的生物活性成分[1, 2]。 糖度是衡量猕猴桃品质的重要评估指标, 不仅是果农采摘时间的依据, 更是采后分级处理的关键依据。 传统的糖度检测通过折光仪进行, 实验人员需要将果实榨汁处理, 然后将汁液滴到检测棱镜上, 以此来测定果实的糖度。 这种方法不仅步骤繁琐, 且破坏样本, 存在效率低下、 浪费资源等问题, 因此需要一种无损且精确的猕猴桃糖度检测方法。
目前近红外光谱技术(near infrared, NIR)作为一种快速且无损的新型分析技术, 被成功应用于农产品的内外品质的检验。 赵志磊等[3]采集李果实的NIR漫反射光谱, 建立了适用于“ 安哥诺” 李果实SSC和TA的定量分析模型。 王淑贤等[4]利用近红外光谱结合偏最小二乘法实现了对香精掺假普洱茶的定量分析。 Tan等[5]基于漫反射光谱完成了番茄樱桃糖度的预测, 测试集的决定系数达到了0.832。 Zhang等[6]利用Vis-NIR和SPA实现了对苹果霉心病的无损检测。 Chen等[7]以柚子为研究对象, 采用傅里叶变换近红外光谱建立PLS模型测定果实中的有机酸含量, 决定系数可达0.936。 这些研究都证明了近红外光谱是无损检测的一种有力手段, 通过近红外光谱对猕猴桃进行糖度检测是可行的。
Stacking算法作为一种集成学习框架, 与其他单一预测算法相比, 能够更加全面而又准确的建模, 已经成功应用于指纹识别[8]、 风险预警[9, 10]、 气象预报[11, 12]和负载预测[13, 14]等领域。 本研究结合近红外光谱技术, 以“ 云海一号” 猕猴桃为研究对象, 对原始光谱进行多种预处理以及特征波长选择, 最后在Stacking集成学习框架中寻找效果最好的基学习器组合策略, 进一步提升模型的预测精度, 实现对猕猴桃糖度的无损检测。
为了确保猕猴桃质量, 选择湖北省武汉市江夏区初阳奇异果园作为采摘地, 该果园种植了多种猕猴桃, 占地面积达到了350多亩。 选取其中的“ 云海一号” 猕猴桃为实验对象, 在果园里采摘。 选择标准为: 表面无病虫斑、 无新伤、 无疤痕, 完全套袋, 着色均匀, 单果重在90~110 g之间。 采摘完成之后经晾晒散去田间热, 转入冷库进行短期保存, 实验使用了280个猕猴桃果实。
采用ThermoFisher分子光谱部(Nicolet)推出的专业傅里叶变换近红外光谱系统Antaris-Ⅱ 采集猕猴桃的光谱数据。 Antaris-Ⅱ 系统主要由干涉仪、 光源、 激光器、 反射镜以及检测器等模块组成。 可以采集3 800~12 000 cm-1(833~2 630 nm)范围内的光谱数据, 标准配置分辨率为4 cm-1, 波数准确性为± 0.03 cm-1, 10次测量的标准偏差小于0.006 cm-1。
通过日本爱拓数字手持袖珍折射仪ATAGO PAL-α 测量猕猴桃样本的糖度, 其测量范围为0%~85%, 测量的精度为± 0.2%。 设备使用环境温度在10~40 ℃, 具有自动温度补偿功能, 可以通过温度传感器获取棱镜温度后进行温度补偿。
采集猕猴桃近红外光谱数据前, 先将Antaris红外分析仪预热15 min, 待光路系统稳定之后, 通过RESULT-Operation操作软件调整为积分球漫反射采样模式, 设置波数采集范围为4 000~10 000 cm-1(1 000~2 500 nm)。 采集数据时, 将猕猴桃赤道部位的中心点作为光谱采集的点。 首先将每个猕猴桃果实平放在红外分析仪的光学台上, 然后移动猕猴桃调整位置, 确保赤道部位中心与红外分析仪的激光光源投射位置对齐。 之后使用专业软件进行光谱信息的采集, 并将数据实时传输到本地硬盘。
获取猕猴桃的近红外光谱后, 通过签字笔对光谱采集点进行标记。 随后使用专业工具挖出标记位置的果肉, 挤汁处理得到了果实汁液。 为了确定果汁的糖度含量, 采用了ATAGO折射仪进行测量。 测量前, 用蒸馏水清洁棱镜表面, 并按下“ ZERO” 键进行调零, 确保测量结果的准确性。 随后, 取适量的果实汁液滴在折光棱镜的镜面上测量。 当显示屏上的箭头闪烁三次后, 显示的数值即为测量的糖度值。 为了提高数据的准确性, 重复以上操作3次, 并将这三次的测量结果取平均值, 作为该采样点的糖度数据。 此外, 还以光谱采样点为基准, 在赤道部位顺时针120° 和逆时针120° 的位置进行了标记。 以相同的方式测量了这些标记点的糖度, 将以上三处标记点的糖度平均值作为整个果实的真实糖度。 然而实验记录显示这三点的糖度值基本一致, 因此也可将光谱采集点处的糖度值视为整个果实的糖度值。
为了确保原始样本服从同一分布, 使用基于蒙特卡洛随机采样结合T检验的奇异样本识别算法筛除异常值样本。 然后使用SPXY(sample set partitioning based on joint x-y distances, SPXY)样本划分方法对猕猴桃数据集进行划分, 通过这种划分方式能够增强模型的泛化能力。 为了减少数据采集过程中噪声等外界因素带来的干扰, 使用多元散射校正(multiple scattering correction, MSC)、 SG平滑滤波(Savitzky-Golay smoothing, SG)、 去趋势校正(de-trending, DT)、 矢量归一化(vector normalization, VN)、 标准正态变换(standard normal variable, SNV)五种方法对数据进行校正, 从中选择出效果最好的预处理方法。
由于仪器采集的波长信息较为丰富, 一条光谱数据包含了1 557个波长, 但并非所有的波长都含有有效信息, 从中选择与糖度变化相关的有效波长最为关键。 因此使用无信息变量消除法(uninformative variable elimination, UVE)、 竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)和区间变量迭代空间收缩特征选择算法(interval variable iterative space shrinkage approach, iVISSA)进行特征波长选择, 然后使用连续投影算法(successive projections algorithm, SPA)对特征波长进行二次选择, 消除共线性波长。 最后选择效果最佳的波长选择方法, 降低数据维度。
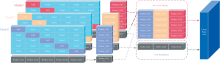
由于单一的回归模型易受数据分布的影响, 加上不同的模型解决问题的侧重点不同, 导致预测性能有一定的局限性。 为了避免上述缺陷, 研究人员开始尝试使用更多的模型来完成预测任务, 通过融合多个模型来获取更优越的预测效果。 目前常见的集成学习方法包括Bagging, Boosting以及Stacking等集成方法, 其中Stacking集成框架因其并行学习的优点而广受学者的青睐。 图1为Stacking集成学习的框架, 它由第一阶段的基学习器和第二阶段的元学习器组成。 通常会选择若干个不同类型的基学习器组成第一层模型, 训练集数据会在这层被平均分为若干份, 供基学习器进行交叉验证, 基学习器训练完之后对测试集进行预测。 第一层的预测结果通过组合形成新的特征集, 送入到第二阶段的元学习器进一步的训练。 在这一阶段, 元学习器结合基学习器新的特征, 修正第一层模型中的预测误差, 从而提升模型的预测性能。
 | 图1 Stacking集成学习框架Fig.1 Stacking ensemble learning framework |
Stacking集成学习算法的具体实现过程如下:
(1)划分数据集。 将猕猴桃的光谱数据采取SPXY法, 按照4∶ 1的比例来划分训练集Dtrain和测试集Dtest, 并进行光谱预处理和特征波长选择。 设置五折交叉验证, 为此需要将训练集Dtrain平均划分为5份M={S1, S2, S3, S4, S5}。 每次训练时取其中1份留做验证集Si, 剩余的4份数据作为训练集供基学习器进行学习。 这样一个数据集可以训练5个模型, 对这5个模型的预测误差取平均就可以得到交叉验证的误差。
(2)选择基学习器并进行五折交叉验证。 每次选取n种基学习器进行组合, 每个基学习器通过五折交叉验证得到5个训练完成的模型, 并使用模型对验证集Si和测试集Dtest进行预测, 同时收集结果。 将模型得到的预测结果
(3)生成新的特征集。 将n个基学习器的预测结果进行合并, 得到新的训练集D'train={
(4)训练元学习器。 由于第一层预测模型输出的特征和真实标签已经非常接近, 为了防止模型过拟合, 也为了缩短训练时间, 第二层选择简单的线性回归作为元学习器, 使用D'train进行训练。 输入测试集D'test获得最终的预测结果。
为了评价模型的预测性能, 比较不同模型之间的优劣, 采用训练集的决定系数
其中n为样本总数, yi为第i个猕猴桃的真实糖度,
由于测量环境和仪器设备等外界因素的影响, 采集到的猕猴桃近红外光谱信息可能会存在异常值。 这些异常的样本会影响原始样本数据的分布, 并且会对模型的训练以及预测产生影响, 因此采用蒙特卡洛结合T检验的方法筛选异常样本。
实验过程如图2所示, 首先随机筛选80%的光谱数据作为训练集, 剩余的20%作为预测集。 使用PLSR进行建模。 重复1 000次, 并记录每一次的预测均方根误差。 按照预测均方根误差从小到大进行排序, 统计前30%的模型中训练集样本出现的次数。 以80%的采样频率, 前300次PLSR建模的正常样本出现次数为240, 按照10%的标准进行上下浮动, 筛选出序号为0、 117、 166、 180、 188、 248和255样本的出现频次明显超出正常采样的频次, 表示这些样本会对模型的预测能力有较强的影响。
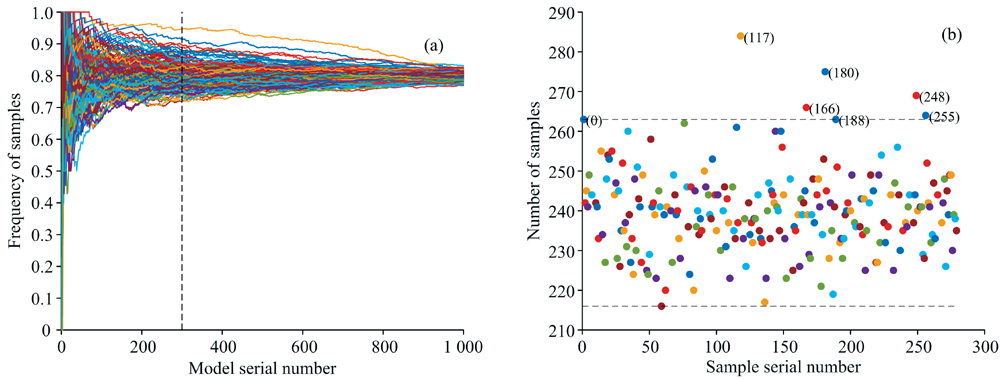 | 图2 蒙特卡洛交叉验证实验 (a): 各样本出现频次; (b): 各样本累计出现次数Fig.2 Monte Carlo cross validation experiment (a): Sample occurrence frequency; (b): Cumulative occurrences of samples |
依次将上述检查出来的可疑样本从训练集中剔除, 然后利用PLSR建立预测模型。 使用新的测试集进行预测, 得到剔除每个可疑样本后新的预测均方根误差RMSEP。 同时为了进行对比, 在保留这些可疑样本的同时, 随机删除一个其他的样本进行建模预测, 重复100次后得到100个RMSEP。 将两者进行t检验判断是否来自同一分布, t检验所计算出的概率如表1所示。 以0.05的p值为评价指标, 117号样本与原始样本无显著性差异, 而0、 166、 180、 188、 248、 255号样本与原始样本有显著性差异, 被视为异常样本。 结合RMSEP指标, 可以认为117号样本是对模型有强影响的好样本。 而其他的样本有极低的概率出现在原始样本的分布中, 因此视作异常值排除。
| 表1 各样本T检验结果 Table 1 T test results of samples |
在剔除6个异常样本之后, 剩余274个正常样本供后续实验使用。 采取SPXY法, 按照4∶ 1的比例划分训练集和测试集, 得到219个训练集样本和55个测试集样本。 从表2中可以看出, 训练集的指标范围包括了测试集的范围, 这样划分出来的训练集的代表性较强, 训练出来的模型有更好的泛化能力。
| 表2 训练集和测试集中可溶性固形物含量统计数据(° Brix) Table 2 Statistics of SSC in train set and test set(° Brix) |
为了削弱外界干扰因素对光谱的影响, 采用多元散射校正(multiple scattering correction, MSC)、 SG平滑滤波(Savitzky-Golay smoothing, SG)、 去趋势校正(de-trending, DT)、 矢量归一化(vector normalization, VN)、 标准正态变换(standard normal variable, SNV)五种预处理方法进行光谱预处理, 经过预处理之后的光谱如图3所示。
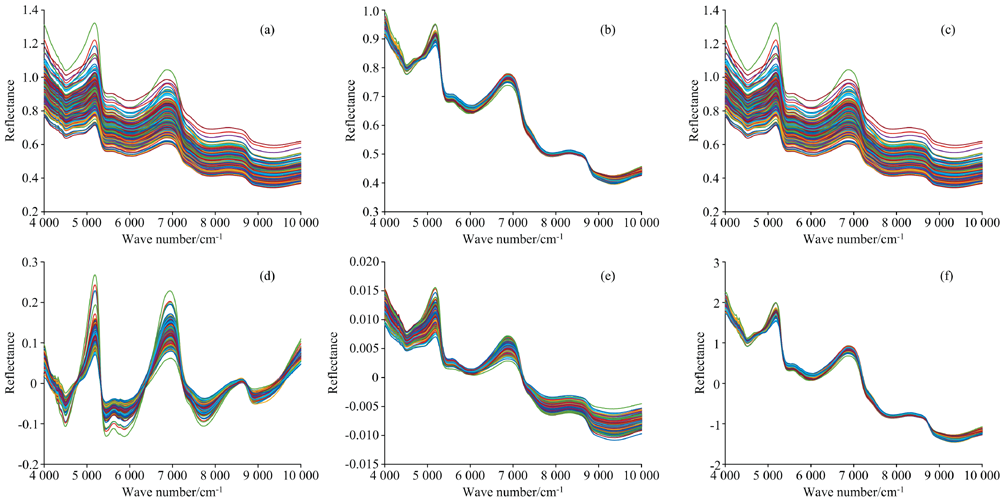 | 图3 不同光谱预处理后的光谱对比 (a): 原始光谱; (b): 多元散射校正; (c): SG平滑; (d): 趋势校正; (e): 矢量归一化; (f): 标准正态变换Fig.3 Spectral data after different spectral preprocessing (a): RAW; (b): MSC; (c): SG; (d): DT; (e): VN; (f): SNV |
与原始光谱相比, SG平滑滤波(SG)消除了光谱中的随机噪声, 光谱曲线更加平滑, 信号的信噪比得到了提高; 多元散射校正(MSC)和标准正态变换(SNV)将原始光谱曲线拉至均值, 以此来减小基线漂移对光谱产生的影响; 趋势校正(DT)则突出了曲线变化的趋势信息; 矢量归一化(VN)则是将每条光谱曲线当作矢量处理, 通过除以自身模长来得到同方向的单位矢量。 通过对原始光谱使用不同的预处理方式, 得到新的数据, 并将其送入PLSR模型进行全波长建模, 最后预测结果如表3所示。 可以看到去趋势校正(DT)的效果最差, 与原始光谱相比
| 表3 不同预处理方法所建立的PLSR模型效果对比 Table 3 Results of PLSR models established by different preprocessing methods |
2.3.1 无信息变量消除法
无信息变量消除法通过引入噪声, 通过交叉验证的逐一剔除法建模, 基于分析回归系数的算法逐渐消除信息量较少的波长, 最终达到特征提取的效果。 根据输入光谱波长数量, 将随机噪声维度设置为1 557, 确保每个波长都有对应的噪声维度。 通过范围寻优的实验将主因子数设为15。 留一法次数主要影响后续剔除单一波长后的回归实验次数。 如果次数设置过少, 实验结果可能会受到较大误差的影响; 相反, 次数过多则可能带来不必要的计算负担。 因此根据经验值将其设定为500次, 以在精确性和计算效率之间达到平衡。 随后通过光谱变量和随机噪声组成的自变量矩阵对糖度进行PLSR建模预测, 分析得到的回归系数向量, 计算稳定系数C。 选择随机噪声区域中绝对值最大的稳定系数C作为阈值, 从原始光谱中筛选稳定系数高于该阈值的波长作为特征波长, 最后得到了648个特征波长, 约占总波长的41.6%。
2.3.2 竞争性自适应重加权算法
竞争性自适应重加权算法(CARS)首先采用蒙特卡洛随机采样算法从训练集中选择数据作为建模集, 剩下的作为预测集, 使用PLSR进行建模回归。 每次选择回归系数较大的波长作为新的子集, 删除系数较小的波长, 经过多次建模之后得到预测均方根误差最小的模型, 其中剩余的波长即为选择出来的特征波长。 设置蒙特卡洛采样次数为50次, 使用五折交叉验证对模型进行评价。 图5(b)显示了交叉验证均方根误差随采样变量数的关系, 随着采样次数的增加, RMSECV呈现先减小后增大, 最后趋于稳定的形势。 在第17次采样时, 交叉验证集具有最小的RMSECV, 此时CARS筛选出了177个特征波长, 约占总波长的11.3%。
 | 图4 UVE特征波长选择过程Fig.4 The process of UVE selecting characteristic wavelengths |
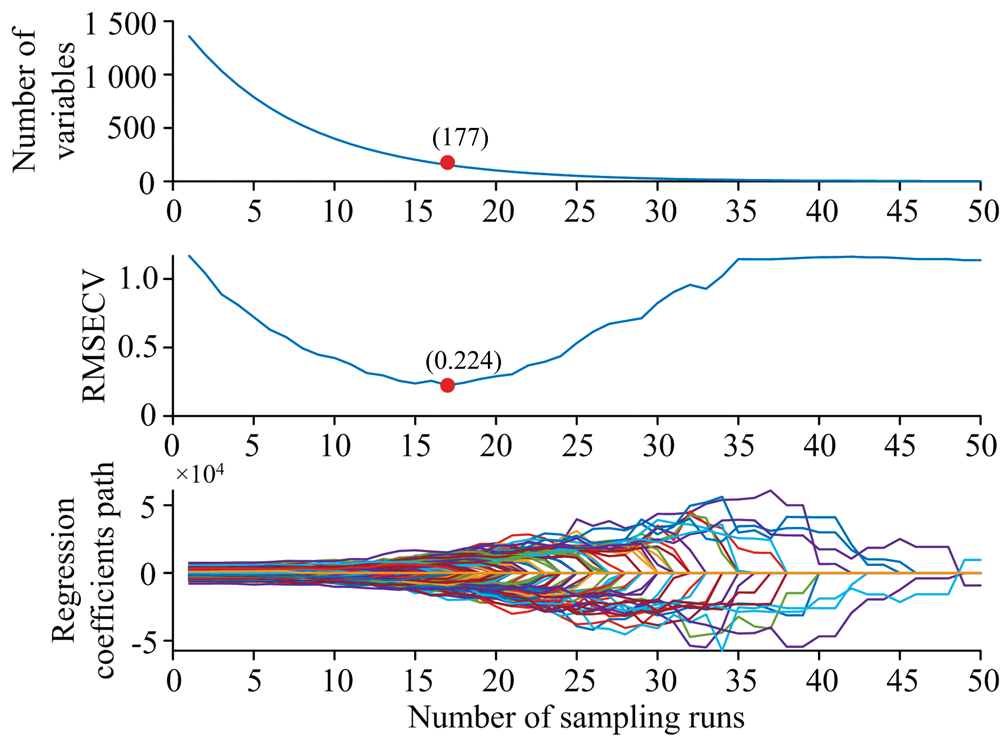 | 图5 CARS特征波长选择过程Fig.5 The process of CARS selecting characteristic wavelengths |
2.3.3 区间变量迭代空间收缩特征选择算法
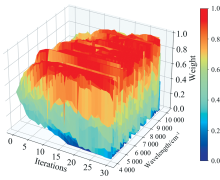
区间变量迭代空间收缩方法(iVISSA)是在VISSA算法的基础上提出的, 它结合了全局搜索和局部搜索的特点, 通过迭代的方式智能的实现波长间隔的选择。 参考文献[15]中的参数设置, 将二进制矩阵采样次数为500, 验证方式为五折交叉验证, 每个波长赋予0.5的初始权重。 在全局搜索的时候, 权重会随着迭代不断更新。 最后权重会趋向于0或者1这两个取值, 权重越大则表示越有可能是特征波长, 反之则意味着该波长将会被剔除。 从图6可以看到随着迭代次数的增加, 各个波长的权重趋向于两极分化, 最终权重为1的波长被选择为特征波长。 iVISSA算法筛选出了704个特征波长, 约占总波长的45.2%。
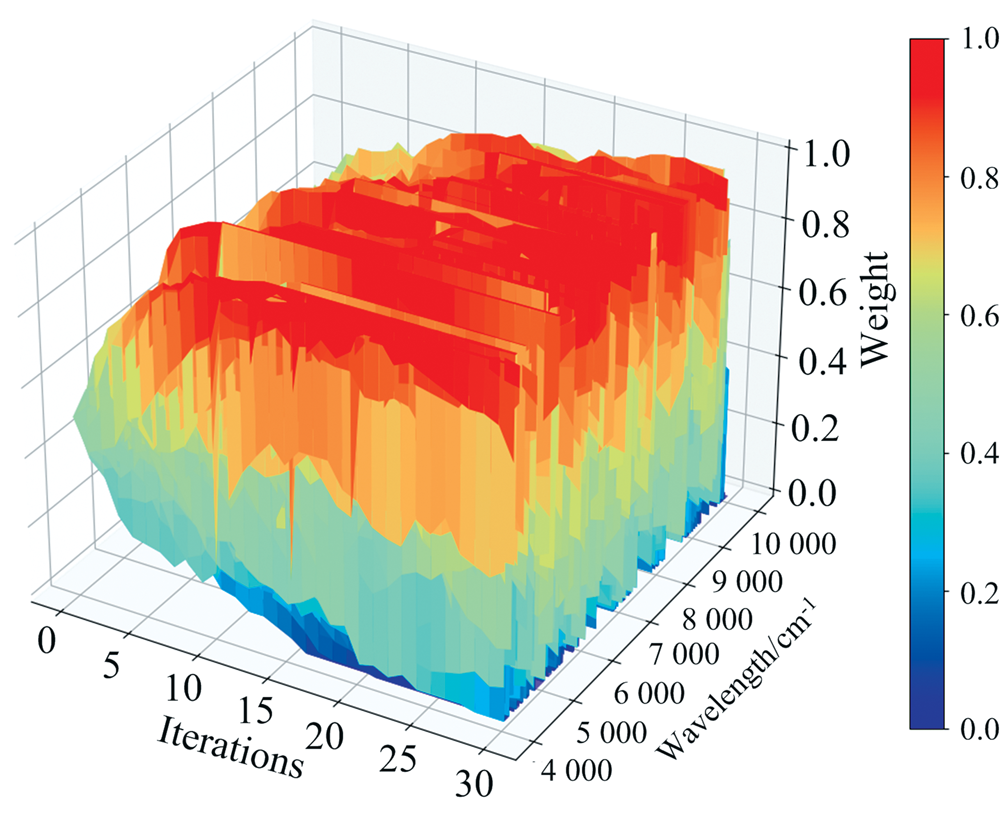 | 图6 iVISSA特征波长选择过程Fig.6 The process of iVISSA selecting characteristic wavelengths |
2.3.4 二次筛选特征波长
为了进一步减少特征光谱的冗余信息, 降低模型的计算量。 在进行完上述三种特征波长选择之后, 对筛选出来的特征波长再次使用连续投影算法(SPA)来去除共线性。 SPA是一种前向的特征选择算法, 能够随着迭代不断剔除冗余信息, 有效的减少各个波长之间存在的共线性问题。 最终CARS-SPA筛选出了83个特征波长, 占总波长的5%; UVE-SPA筛选出了26个特征波长, 占总波长的1.67%; iVISSA-SPA筛选出了36个特征波长, 占总波长的2.31%。
2.3.5 基于特征波长的PLSR建模分析
对原始光谱进行矢量归一化处理, 通过不同的特征波长选择方法对光谱数据进行降维, 将转换后的光谱数据使用PLSR进行建模分析, 模型效果如表4所示。 可以看出原始光谱在经过特征波长选择之后, 模型的预测精度不降反增, 这是因为筛选出的特征波长能有效反应猕猴桃的可溶性固形物含量, 并且去除无关波长也降低了模型的计算量。 所以对光谱进行波长选择是很有必要的。 使用CARS方法提取的特征波长所建立的模型效果最好, 在测试集中的决定系数
| 表4 基于不同特征波长选择方法建立的PLSR模型效果 Table 4 The results of the PLSR models based on different characteristic wavelengths selection methods |
2.4.1 基学习器超参数设置
选择贝叶斯岭回归(Bayesian ridge regression, BRR)、 偏最小二乘回归(partial least squares regression, PLSR)、 支持向量回归(support vector regression, SVR)以及人工神经网络(artificial neural network, ANN)作为基学习器, 使用线性回归(linear regression, LR)作为第二层的回归模型。 其中BRR、 PLSR和SVR使用Sklearn实现, 使用Hyperopt的TPE方法对其中的超参数进行寻优。 ANN使用PyTorch深度学习框架搭建, 共有3个隐藏层, 神经元数量分别为: 100, 50, 20, 最后一层输出预测值。 使用CUDA对训练进行加速。 基学习器的一些关键超参数取值如表5所示。
| 表5 基学习器部分关键参数 Table 5 Key parameters of the base learner |
2.4.2 基于Stacking集成学习的实验结果及分析
为了评估Stacking集成学习模型的效果, 对4种基学习器进行组合匹配, 产生了包括单一模型在内的15种组合方式, 建模效果如表6所示。
| 表6 不同组合的模型效果 Table 6 The results of the models based on different combinations |
从表6中可以得出以下结论:
(1)以测试集的
(2)集成模型的性能与基学习器的组合有关。 以PLSR为例, 当其与个体性能最好的SVR进行组合时, 生成的Stacking模型预测精度甚至不如SVR单一模型; 而PLSR与个体性能一般的ANN进行组合时, 集成模型的预测性能得到了显著提升。 说明预测效果最佳的集成模型并非都由性能较好的基学习器组成, 集成模型的精度还与基学习器之间的差异性有关。 这点会在后面通过计算各基学习器之间的Pearson相关系数来进一步解释说明。
(3)大多数基学习器进行组合后的集成模型效果要比单一模型的准确率要高。 尤其是BRR、 PLSR与ANN结合以后, 模型的性能得到了显著提高,
(4)并非基学习器越多, 集成模型的性能就越好。 例如BRR+SVR的组合,
2.4.3 基学习器相关系数分析
为了更好的分析Stacking集成学习算法的原理, 寻找各个基学习器的预测差异, 通过保存每个基学习器对测试集的预测值, 计算输出结果的Pearson相关系数。 计算公式如式(3)所示
式(3)中, x和y分别表示两个变量, n为样本总数,
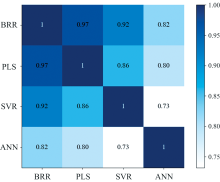
 | 图7 各基学习器相关系数矩阵Fig.7 Matrix of correlation coefficients of base learners |
从相关系数矩阵可以看出各个模型之间均有0.7以上的相关系数, 属于较强的相关性, 这也是由于各个基学习器的学习能力较强所引起的。 对角线的相关系数为1, 这表示模型与自身的相关性最高。 BRR和PLSR的相关系数达到了0.97, 这是因为两者均属于线性回归模型, 而贝叶斯模型在估计的过程中引入了正则项, 相比于PLSR对数据利用得更加充分。 SVR和线性回归模型的相关系数也偏高, 但ANN与其他基学习器的相关性较低, 一方面是由于ANN属于深度学习, 训练方法和预测方式与其他模型不同; 另一方面是由于ANN本身对数据利用率不如其他模型, 训练集和预测集的准确率低于平均水平。 正因ANN与其他基学习器之间存在差异性, Stacking集成模型的性能才有显著的提高。 结合表6不同基学习器组合的预测表现可知, 在选择Stacking集成学习模型的基学习器时, 既要考虑单一模型的预测性能, 又要考虑模型之间的差异性, 选择合适的基学习器才能带来模型性能的提升。
以湖北省武汉市的“ 云海一号” 黄心猕猴桃为研究对象, 采集了4 000~10 000 cm-1范围内的近红外高光谱数据, 剔除其中的异常样本, 经过一系列预处理以及波长选择之后, 使用Stacking集成学习模型完成了对猕猴桃的糖度预测。 结论如下:
(1)对原始光谱数据采用蒙特卡洛结合T检验的方法筛查异常样本, 以0.05的显著性为标准排除了6个异常样本, 提高了数据的质量。
(2)对原始光谱使用MSC、 SG、 DT、 VN和SNV五种预处理方式, 并建立PLSR模型进行预测, 发现VN-PLSR模型对于测试集的回归效果最好, 其
(3)将数据使用矢量归一化预处理之后, 采用UVE、 CARS和iVISSA三种方法来选择特征波长, 并使用SPA对特征波长进行二次筛选。 比较不同的模型效果, 发现CARS-PLSR模型的效果最好, 筛选出来177个特征波长, 约占总波长的11.3%, 其决定系数
(4)为进一步提高回归精度, 设计了一种基于Stacking框架的集成模型。 将BRR、 PLSR、 SVR和ANN作为基学习器进行组合, 根据实验结果发现PLSR+SVR+ANN组合的模型在测试集上的预测性能最好,
本文针对“ 云海一号” 猕猴桃的糖度无损检测问题, 提出了一种基于近红外光谱数据的算法。 不仅降低了猕猴桃糖度检测的时间和成本, 避免了传统破坏性检测方法的耗时和高成本, 而且为嵌入式产品的开发提供了算法基础, 也为其他不同种类猕猴桃的糖度检测提供了借鉴。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|