

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
注意力机制的混合卷积高光谱图像分类方法
[刘玉娟1, 2, 3  , 刘颜达
, 刘颜达1, 2, 3 , 闫振1, 4 , 张智勇1, 2, 3 , 曹益铭1, 2, 3 , 宋莹1, 2, 3, * ]
, 刘颜达]
|
|


作者简介: 刘玉娟, 女, 1984年生, 吉林大学仪器科学与电气工程学院副教授 e-mail: liuyujuan@jlu.edu.cn
高光谱图像以其高分辨率的空间和光谱信息在军事、 航空航天及民用等遥感领域均有重要应用, 具有重要的研究意义。 深度学习具有学习能力强、 覆盖范围广及可移植性强的优势, 成为目前高精度高光谱图像分类技术研究的热点。 其中卷积神经网络(CNN)因强大的特征提取能力广泛应用于高光谱图像分类方法研究中, 取得了有效的研究成果, 但该类方法通常单独基于2D-CNN或3D-CNN进行, 针对高光谱图像的单一特征, 一是不能充分利用高光谱数据本身完整的特征信息; 二是虽然相应提取网络局部特征优化性好, 但是整体泛化能力不足, 在深度挖掘HSI的空间和光谱信息方面存在局限性。 鉴于此, 提出了基于注意力机制的混合卷积神经网络模型(HybridSN_AM ), 使用主成分分析法对高光谱图像进行降维, 采用卷积神经网络作为分类模型的主体, 通过注意力机制筛选出更有区分度的特征, 使模型能够提取到更精确、 更核心的空间-光谱信息, 实现高光谱图像的高精度分类。 对Indian Pines(IP)、 University of Pavia (UP)和Salinas (SA)三个数据集进行了应用实验, 结果表明, 基于该模型的目标图像总体分类精度、 平均分类精度和Kappa系数均高于98.14%、 97.17%、 97.87%。 与常规HybridSN模型对比表明, HybridSN_AM模型在三个数据集上的分类精度分别提升了0.89%、 0.07%和0.73%。 有效解决了高光谱图像空间-光谱特征提取与融合的难题, 提高HSI分类的精度, 具有较强的泛化能力, 充分验证了注意力机制结合混合卷积神经网络在高光谱图像分类中的有效性和可行性, 对高光谱图像分类技术的发展及应用具有重要的科学价值。
, LIU Yan-da
Hyperspectral Imagery (HSI), based on its high-resolution spatial and spectral information, has important applications in military, aerospace, civil, and other remote sensing fields, which has great research significance. Deep learning has the advantages of strong learning ability, wide coverage, and strong portability, which has become a hot spot in the research of high-precision hyperspectral image classification. Convolutional Neural Networks (CNN) are widely used in the research of hyperspectral image classification because of their powerful feature extraction ability and have achieved effective research results. Still, such methods are usually based on 2D-CNN or 3D-CNN alone. For the single feature of hyperspectral image, the complete feature information of hyperspectral data cannot be fully utilized. Secondly, the local feature optimization of the corresponding extraction network is good, but the overall generalization ability is insufficient. There are limitations in the deep mining of spatial and spectral information of HSI. Because of this, this paper proposes a Hybrid Spectral Convolutional Neural Network Attention Mechanism (HybridSN_AM) based on attention mechanism. The principal component analysis method is used to reduce the dimension of hyperspectral images, and the convolutional neural network is used as the main body of the classification model to screen out more distinguishable features through the attention mechanism so that the model can extract more accurate and more core joint space-spectral information, and realize high-precision classification of hyperspectral images. The proposed method was applied to three datasets: Indian Pines(IP), the University of Pavia (UP), and Salinas (SA). The experimental results show that the overall classification accuracy, average classification accuracy, and kappa coefficient of target images based on this model are higher than 98.14%, 97.17%, and 97.87%. Compared with the conventional HybridSN model, the classification accuracy of the HybridSN_AM model on the three data sets increased by 0.89%, 0.07%, and 0.73%, respectively. It effectively solves the problem of hyperspectral image joint space-spectral feature extraction and fusion, improves the accuracy of HSI classification, and has strong generalization ability. It fully verifies the effectiveness and feasibility of the attention mechanism combined with a hybrid convolutional neural network in hyperspectral image classification, which has important theoretical value for developing and applying hyperspectral image classification technology.
高光谱遥感技术是一种将成像技术与光谱技术结合的多维信息获取技术, 具有高空间分辨率、 高光谱分辨率的优势[1], 其三维数据立方体含有丰富的空间、 辐射和光谱信息[2], 是目前遥感对地探测的主要技术手段, 在地质灾害勘测[3]、 矿产资源勘探[4]、 国防安全监测[5]、 水质环境检测[6]等领域具有广泛的应用。
高光谱图像(hyperspectral imagery, HSI)分类方法是高光谱遥感对地观测的关键技术, 是众多遥感应用的先决条件, 具有重要的研究意义。 在高光谱图像分类的早期研究中, 目视解译作为图像的基本分类方法, 但该方法具有较强的主观性且对解译人员的要求较高, 随着高光谱数据获取的便捷, 该方法在鲁棒性、 解译精度、 处理速度等方面难以满足需求。 像素级分类方法的出现如支持向量机[7]、 多项逻辑回归等, 使得高光谱图像光谱维度的信息得以利用。 此外, 还有一些其他分类方法集成了降维技术, 加强对数据的特征提取, 如基于指数参数、 投影转换理论、 波段组合、 空间域算法、 流行学习及深度学习的相关特征提取方法[8, 9]。
空间特征的提取可以增强样本的鉴别性和稳定性, 主要表现在对纹理特征和图像形态学特征的提取, 空谱信息的联合提取能够有效提高高光谱图像分类的精度[10]。 目前该类研究已经吸引了一些研究者的关注, 尽管基于空谱联合提取的高光谱图像分类方法理论可解释性好、 计算量和样本需求小、 抗噪声能力强, 取得了较好的分类效果, 但其应用于分类的精度受限于特征来源, 大多数特征是基于特定的需求所设计, 并依赖于参数设置阶段的专家知识, 因此, 在复杂场景的适用性较差。
相比于传统的机器学习, 深度学习具有学习能力强、 覆盖范围广及可移植性好的优势, 被广泛应用在解决一些通用人工智能问题领域, 如: 目标识别、 专家系统等, 受到这些领域成功应用的启发, 也被应用在图像数字处理领域中, 其中卷积神经网络(convolutional neural network, CNN)因其强大的特征提取能力被广泛应用于HSI分类中, 并取得了良好的分类效果。 如Haut[11]等对原始高光谱数据进行主成分分析(principal component analysis, PCA)以降低原始空间维数目, 将降维后的数据输入到2D-CNN进行特征提取。 Chen[12]等利用3D-CNN的深度特征提取方法进行HSI分类。 但单独使用2D-CNN或3D-CNN存在一些缺点, 2D-CNN不能从光谱维度中提取出良好的鉴别特征图, 3D-CNN在计算上更为复杂且在很多具有相似纹理特征的光谱波段上表现不佳。 此外, 在高光谱图像分类中仅使用卷积神经网络进行特征提取仍存在不足, 图像的背景会对待分类目标产生一定干扰, 使二者的可分离度不够。
计算机视觉的注意力机制(attention mechanism, AM)能够在一定程度上缓解卷积神经网络的不足, 使神经网络根据任务的重要性, 在众多信息中聚焦重要信息, 忽略次要信息[14]。 鉴于此, 提出了结合AM的混合CNN模型, 既克服了单独使用2D-CNN或3D-CNN的弊端, 充分利用图像的光谱和空间特征, 同时增强目标特征和背景的可分离性, 提高高光谱图像分类的精度。
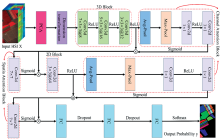
结合注意力机制的混合卷积神经网络模型(HybridSN_AM)整体框架如图1所示, 首先利用主成分分析法实现对原始高光谱影像降维, 将降维后的高光谱图像划分为图像块输入网络, 然后利用3D-CNN、 2D-CNN提取不同尺度的空间和光谱信息。 特征提取完成后, 先经过通道注意力机制, 依据特征通道间的关系, 生成一维向量μ 后, 与输入特征相乘, 实现通道位置元素的加权, 然后再经过空间注意力机制, 以此达到压缩空间维度的目的, 利用特征的空间关系生成二维矩阵γ 后, 与输入特征相乘, 实现空间位置元素的加权。 最后通过3个采用Dropout方法缓解网络过拟合的全连接层输出图像预测分类结果。
 | 图1 基于注意力机制的混合卷积高光谱图像分类结构网络图Fig.1 Classification structure network of hybrid convolution hyperspectral images based on attention mechanism |
高光谱遥感图像具有光谱波段范围广、 光谱分辨率高、 数据量大的特点, 相邻波段之间冗余信息较多, 易造成休斯现象, 即分类精度随着特征维数的增加呈现先上升后下降的趋势。 为降低冗余信息对后续分类造成的影响并减少计算量, 采用PCA方法对原始图像降维。
PCA的核心思想在于成分的主次能够根据它们在空间中某一方向投影值的方差来区分, 越重要的成分对应的投影方差越大。 HSI主要维度的数据信息能够通过投影变换获取, 实现降维。 由于经PCA后只减少了光谱波段, 保持相同的空间维度, 故HSI的空间信息得以完整保留, 具体步骤如下[13]:
(1) 原始高光谱数据立方体用I∈ RM× N× D, 其中I表示输入, M为宽度, N为高度, D为光谱波段数, 将其转化为S× B的2维数组, 其中S=M× N, 用X(S× D)表示。
(2) 计算X(S× D)的列均值μ , 并将X(S× D)去中心化得到X'。
(3) 对X'求协方差矩阵Y, 具体为
(4) 对Y进行奇异值分解, 求得特征值及λ 对应的特征向量α 。
(5) 从大到小对特征值λ 进行排序, 求各个主成分的贡献率η i和前L个主成分的累计贡献率φ L, 具体为
(6) 取前L个特征值对应的特征向量组成投影矩阵β , 重构高光谱图像数据I。
3D-CNN是通过将3D核与3D数据进行卷积完成的, 可以同时提取光谱特征和空间特征。 HybridSN_AM模型中包含了3层三维卷积, 其中第一层为8个尺寸为7× 3× 3的卷积核; 第二层为16个尺寸为5× 3× 3的卷积核; 第三层为32个尺寸为3× 3× 3的卷积核, 采用ReLU作为激活函数, 在三维卷积中, 第i层第j个特征图的空间位置(x, y, z)的激活值表示为
式(4)中, φ (* )是激活函数; bi, j是第i层第j个特征图的偏置参数; dl-1是第(l-1)层特征图的数量和第i层第j个特征图的核ω i, j的深度, 2η +1是沿光谱维度的内核深度, 2γ +1是核的高度, 2δ +1是核的宽度, ω i, j是第i层第j个特征图的权重参数。
式(5)中, bi, j是第i层第j个特征图的偏置参数; dl-1是第(l-1)层特征图的数量和第i层第j个特征图的核ω i, j的深度; ω i, j是第i层第j个特征图的权重参数。
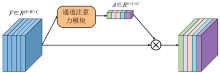
通过通道注意力机制模块, 我们能够为输入图像中的不同通道赋予不同的重要性, 以此增强重要通道的光谱信息, 抑制次要通道的光谱信息。 该模块的示意如图2所示, 设网络输入的特征尺寸为H× W× C, 其中H× W为空间尺寸, C为通道数。 利用通道注意力模块得到对一个C维的权重向量, 将C维权重向量的每一个元素与输入特征所有空间位置的对应通道元素相乘, 即为通道注意力机制。 具体表示如式(6)— 式(8)
通道注意力机制首先对输入特征进行平均池化和最大池化, 然后利用2层2维卷积计算通道位置权重, 卷积核尺寸为1× 1, 分别得到平均输出和最大输出, 二者相加后利用Sigmoid激活函数进行整合, 最终得到通道权重向量μ 。
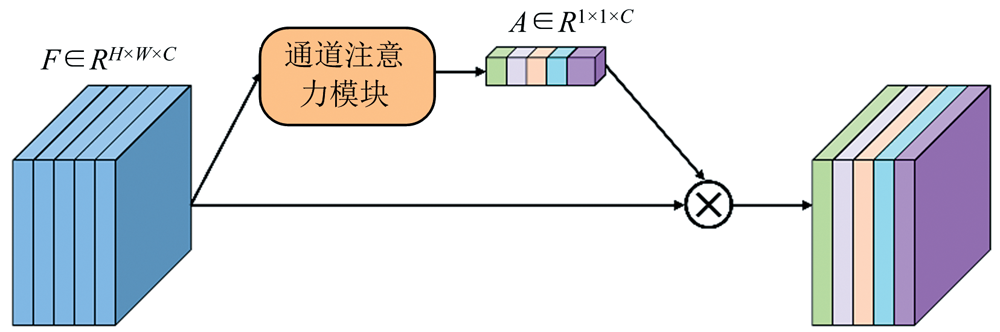 | 图2 通道注意力机制模块Fig.2 Channel attention mechanism module |
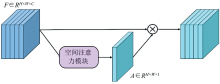
空间注意力机制模块能够对各种形变数据在空间中进行转换并自动捕获重要区域特征, 能够保证图像在经过裁剪、 平移或者旋转等操作后依然可以获得和操作前原始图像相同的结果[15]。 空间通道注意力机制模块如图3所示, 设网络输入的特征尺寸为H× W× C, 其中H× W为空间尺寸, C为通道数。 利用空间注意力模块得到一个H× W的权重矩阵, 将H× W权重矩阵的每一个元素与输入特征所有通道的对应空间位置元素相乘, 即为空间注意力机制, 具体计算如式(9)
空间注意力机制首先对输入特征分别计算平均值和最大值, 对于提取的特征图, 由于其通道数为1, 将平均值和最大值特征拼接为2通道, 然后利用二维卷积计算空间位置权重, 卷积核尺寸为7× 7, 利用Sigmoid激活函数进行整合, 最终得到空间权重矩阵γ 。
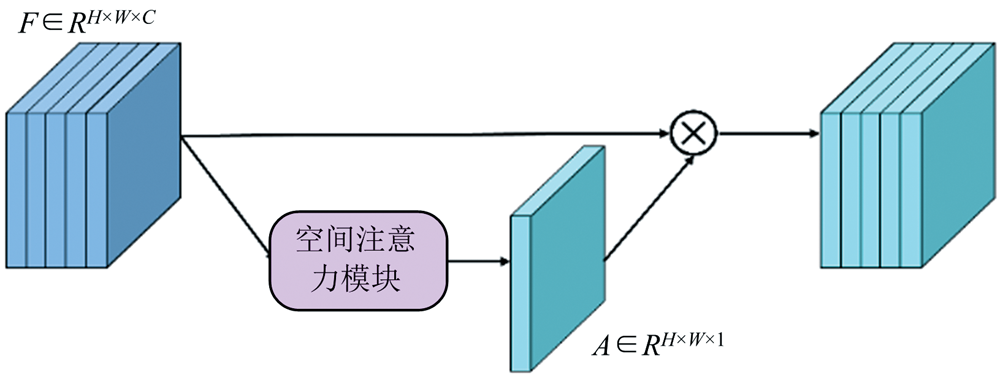 | 图3 空间注意力机制模块Fig.3 Spatial Attention mechanism module |
最后采用的是三个全连接层, 其输出节点数分别为256、 128、 和C, 其中C为地物类别种类, 在第一个全连接层时, 首先需要对模型最终输出特征进行展平, 可以看出第一层全连接的输入节点数最多。 在全连接模块中, 为了防止模型过度拟合, 使用了2个Dropout层, 其比例为0.4, 以便增强网络的健壮性, 但由于这部分隐藏神经元是随机丢弃的, 因此在整个模型中增加了不确定因素, 导致每次的分类结果稍有差别。
选择Indian Pines (IP)、 University of Pavia (UP)和Salinas (SA)3个公开数据集对所提算法的有效性进行验证。
Indian Pines数据集: 该数据集由美国NASA喷气推进实验室研制的机载可视红外光谱仪于1992年在美国印第安纳州西北部的印第安松树试验场采集得到, 共16种地物, 影像包含145× 145个像素, 空间分辨率为20 m, 光谱分辨率为10 nm, 光谱覆盖400~2 500 nm, 包含224个波段, 剔除由于噪声及水吸收影响严重的24个波段, 最终用于实验的数据有200个波段。
University of Pavia数据集: 该数据集由反射光学系统成像光谱仪于2002年在意大利帕维亚大学采集, 共9种地物; 该影像的空间尺寸为610× 340, 空间分辨率为1.3 m, 光谱覆盖430~860 nm, 包含115个波段, 在剔除12个受强噪声影响的波段后, 最终有103个波段用于实验。
Salinas数据集: 该数据集由AVIRIS设备于1992年在美国加利福尼亚州萨利纳斯山谷获得, 共16种地物, 数据集具有512× 217的空间尺寸, 空间分辨率为3.7 m, 原始影像由224个波段构成, 剔除20个受水吸收影响的波段后, 最终用于实验的数据有204个波段。
实验环境及参数设置如下:
硬件环境: Windows10操作系统、 电脑机型Intel(R) Core(TM) i7-11700K @3.60GHz 3.60 GHz+32.0GB、 图形显卡型号是NVIDA GeForce RTX 3070 Ti。
软件环境: 采用Pytorch CUDA 1.12版本深度学习框架搭建网络模型, Python3.7, 使用Anoconda3作为环境管理软件, 采用Pycharm作为Python的集成开发环境。
参数设置: 批次规模设为128; 训练轮数(epochs)设为100; 采用交叉熵损失函数计算损失值; 训练集和测试集划分比例为1∶ 9; 均为随机抽取, 随机数状态设为345; 窗口大小设为25; 主成分数量设为30; 学习率设置为0.001。 使用反向传播算法和Adam优化器来优化模型的参数和权重, 以此不断提升模型的准确性。
分类性能衡量指标使用总体准确率(overall accuracy, OA) 、 平均准确率(average accuracy, AA)和Kappa系数。
OA表示在一幅图像中被正确分类的像元数量占总体像元数量的比值, 具体计算如式(10)
AA表示分类精度的平均值, 具体计算如式(11)
Kappa系数表示度量一致性的指标, 能够避免数据类别不平衡带来的影响, 具体计算如式(12)和式(13)
式(12)和式(13)中, Pi, i表示第i类且分配到第i类的像元总数, Pi, j表示第i类分配到第j类像元总数, n表示总的类别数目。
将提出的方法与2D-CNN、 3D-CNN、 以及HybridSN模型在IP、 SA及UP数据集上进行应用并对结果进行对比分析, 模型训练过程中的损失曲线如图4所示, 从损失曲线中可以看出, IP数据集大约在50个epochs后达到收敛, SA和UP数据集的分类难度比IP数据集低, 大约在30个epochs后达到收敛, 损失值越小, 表明模型预测越接近真值。
 | 图4 三个数据集模型训练中损失曲线图 (a): IP数据集; (b): SA数据集; (c): UP数据集Fig.4 Loss curves in model training of three data sets (a): IP data set; (b): SA data set; (c): UP data set |
采用不同方法的分类效果如图5所示, 从图中可以看出相对于单独使用2D-CNN或3D-CNN, 基于混合卷积神经网络的两个模型能够取得更好的分类效果, 表1、 表2及表3列出了这四个模型在分类精度上的对比结果, 基于混合卷积的网络模型分类精度优于单独使用2D-CNN或3D-CNN的模型, 而HybridSN_AM模型相较于HybridSN模型有更高的分类精度, 针对IP数据集, OA、 AA、 Kappa系数分别提升0.81%、 0.98%、 0.91; 针对SA数据集, OA、 AA、 Kappa系数分别提升0.04%、 0.1%、 0.04; 针对UP数据集, OA、 AA、 Kappa系数分别提升0.61%、 0.85%、 0.8。
 | 图5 不同方法分类效果图 (a): IP数据集应用不同方法的分类结果图; (b): SA数据集应用不同方法的分类结果图; (c): UP数据集应用不同方法的分类结果图Fig.5 Classification effects of different methods (a): Classification result graphs of different methods applied to IP data set; (b): Classification result graphs of SA data set using different methods; (c): Classification results graphs of different methods applied to PU data set |
| 表1 不同方法在Indian Pines上的分类精度对比表 Table 1 Comparison of classification accuracies of different methods for the Indian Pines |
| 表2 不同方法在University of Pavia上的分类精度对比表 Table 2 Comparison of classification accuracies of different methods for the University of Pavia |
| 表3 不同方法在Salinas上的分类精度对比表 Table 3 Comparison of classification accuracies of different methods for the Salinas |
针对高光谱图像信息特征提取不充分及待测目标与图像背景分离度差的问题, 设计了基于注意力机制的混合卷积高光谱图像分类方法, 所提出的模型通过联合3D-CNN和2D-CNN以充分挖掘高光谱图像的空间、 光谱信息, 实现图像信息特征最大化提取, 并减少了参数量, 而后通过注意力机制再次对光谱维度和空间维度进行加权, 进一步放大各类地物之间的差异, 增强背景和目标的可判别性, 最后通过全连接层输出图像预测分类结果。 解决了不能充分利用高光谱数据本身完整的特征信息及模型整体泛化能力不足的问题, 实验结果表明, 使用混合卷积神经网络模型的分类性能优于单独使用单一网络, 使用相同的模型参数, 引入注意力机制后, HybridSN模型比未使用注意力机制的模型在三个数据集上的分类精度分别提升了0.89%、 0.07%和0.73%, 进一步验证了基于注意力机制的混合卷积神经网络模型的可行性和优越性, 具有较强的鲁棒性和网络泛化能力。
本研究虽然取得了较好的分类结果, 对高光谱图像分类技术的发展及应用具有重要的理论价值, 但仍有不足, 需要提取更深层的光谱特征和空间特征, 在优化网络参数、 减小计算复杂度和多特征融合等方面需继续深入研究, 并融合波段选择、 数据增强和残差块等先进技术来优化和更新模型, 以适应高光谱图像分类方法研究中高精度、 智能化的发展前沿。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|