


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
柠檬酸发酵过程种子罐培养液质量参数的近红外预测模型
[穆良银1  , 赵忠盖
, 赵忠盖1, * , 金赛2 , 孙福新2 , 刘飞1 ]
, 赵忠盖, 金赛|
|


作者简介: 穆良银, 1998年生, 江南大学轻工过程先进控制教育部重点实验室硕士研究生 e-mail: 6211905033@stu.jiangnan.edu.cn
在柠檬酸发酵过程中, 种子罐中菌种培养的好坏将直接关系到发酵的水平, 因此快速准确检测种子罐中培养液质量参数非常重要。 柠檬酸发酵过程中种子罐培养液质量参数目前大多采用人工测量, 无法满足实时监控和精确控制的需求。 基于近红外光谱, 针对种子罐培养液中总酸(TA)和还原糖(RS)的测量, 构建了化学计量模型。 首先, 对原始光谱进行分析, 为消除随机噪声以及减少批次差异性对于样本光谱的影响, 依次采用平滑处理(SG)和去趋势处理(DT)的SG-DT方法进行光谱预处理。 然后, 利用间隔偏最小二乘(iPLS)方法对光谱进行特征波长选择, 讨论了不同划分区间数对选择结果的影响, 并确定了目标质量参数为总酸(TA)时的最佳划分区间数为21, 特征波长个数为495, 目标质量参数为还原糖(RS)时的最佳划分区间数为20, 特征波长个数为361。 分析光谱变量和质量参数变量之间的相关程度, 引入BP网络建立总酸(TA)的校正模型, 分别用PLSR和BP网络建立还原糖(RS)的校正模型, 比较模型预测效果以确定最优模型。 得到基于BP网络的总酸(TA)的最优预测模型的
The quality of the bacterial strain cultivation in the seed tank during the citric acid fermentation process directly affects the fermentation level. Hence, it is crucial to accurately and rapidly detect the quality parameters of the culture solution in the seed tank. However, these parameters are currently largely measured manually, which does not meet real-time monitoring and precise control requirements. This paper builds a chemometric model for measuring the total acidity (TA) and reducing sugars (RS) in the seed tank's culture solution, based on near-infrared spectroscopy. Initially, the original spectra were analyzed, and to eliminate random noise and reduce batch variability effects on the sample spectra, the SG-DT method of smoothing (SG) and detrending (DT) were sequentially used for spectral preprocessing. Then, the Interval Partial Least Squares (iPLS) method was used for feature wavelength selection, the effect of different division intervals on the selection result was discussed, and the optimal division interval number for the target quality parameter of TA was determined to be 21, with 495 feature wavelengths. For RS, it was 20, with 361 feature wavelengths. Subsequently, the correlation between spectral variables and quality parameter variables was analyzed. A BP network was introduced to establish the calibration model for TA, and both PLSR and BP networks were used to establish the calibration model for RS, and model prediction effects were compared to determine the optimal model. Finally, the optimal prediction model for TA based on the BP network had an
柠檬酸作为一种有机酸, 已经广泛应用于食品、 纺织、 医药、 化工、 化妆品、 饲养等领域。 目前柠檬酸主要通过发酵法生产, 已成为世界第二大发酵产品[1]。 发酵法生产柠檬酸时, 原料的质量、 菌种以及环境的控制都是需要关注的指标。 在柠檬酸发酵过程中, 接种到发酵罐中的菌种先通过无性繁殖生长到成熟状态, 这个过程在种子罐中完成。 菌种培养的好坏将直接关系到发酵的水平, 影响最终的发酵质量以及柠檬酸的产量。 监控菌种培养过程的培养环境对柠檬酸发酵过程至关重要, 而目前主要靠人工采集种子罐培养液样本, 通过离线方法化验质量参数的理化值, 对后续发酵过程控制带来了不稳定和不确定性。
近红外光(near infrared, NIR)的波长范围为780~2 526 nm, 含氢元素的化学基团(如C— H、 O— H、 S— H、 N— H等)分子振动的倍频与合频的吸收信息可以通过近红外光反映, 因此几乎所有的有机化合物和混合物都被近红外光谱所覆盖[2]。 建模是近红外光谱分析的重要任务, 其主要目的是通过建立近红外光谱与所研究样本之间的定量或定性关系, 将光谱数据转化为有用的信息, 用于样本的定量分析(如组成成分、 浓度预测)或定性分析(如样本分类与鉴别), 实现对样本的快速、 准确和无损的分析与预测。 Mohammadi等利用遗传算法的支持向量机回归结合近红外光谱分析原油的SARS[3]; André s Cruz-Conesa等利用可见近红外光结合偏最小二乘建模来预测家禽排泄物的营养成分[4]; Birenboim等利用偏最小二乘判别分析(PLS-DA)方法对药用大麻品种分类[5]; 周新奇等开发了一套近红外光谱在线监测系统, 在线检测酒酿培养前的水分、 淀粉及酸度, 从而解决酒酿培养问题[6]。 将近红外光谱分析技术应用到柠檬酸发酵过程的研究较少。 郝超等利用概率偏最小二乘(probability PLS, PPLS)结合近红外光谱对柠檬酸发酵过程原料段液化清液进行监控[7]; 张萌等利用深度信念网络构建近红外光谱定量分析模型并成功应用到柠檬酸发酵过程发酵罐中发酵液质量参数总糖的预测[8]; Jin等分别利用PLS和堆叠自编码器建立了柠檬酸发酵过程发酵罐底物、 产物和细胞浓度的在线预测模型并对比模型的性能[9]。 种子罐与发酵罐和原料段相比, 种子罐需要严格的培养条件、 培养时间较短且使用频率较高, 因此种子罐培养液的过程变量信息较为复杂, 随机噪声和批次重复性差对过程变量信息影响较大, 在利用近红外光谱分析培养液的质量参数时, 需要严格地分析原始光谱, 通过合适的处理改善光谱质量和提取有用的变量信息, 然后建模分析质量参数。 将近红外光谱分析技术应用到柠檬酸发酵过程种子罐培养液质量参数的检测研究尚未出现。
本研究NIR光谱对柠檬酸发酵过程中菌种培养过程的质量参数进行检测, 分别构建种子罐培养液总酸(TA)和还原糖(RS)两个质量参数的在线预测模型。 首先, 分析原始光谱存在的问题, 采用平滑处理(savitzky-golay, SG)和去趋势处理(detrending, DT)结合的的SG-DT方法对光谱进行预处理。 然后, 对处理后的光谱利用间隔偏最小二乘法(interval PLS, iPLS)进行特征波长选择, 并引入偏最小二乘回归(PLSR)和误差反向传播神经网络(BP-ANN)两种多元校正方法建立质量参数的定量分析模型。 最终采用最优的预测模型对实际柠檬酸发酵过程中菌种培养过程的质量参数进行预测, 实现了柠檬酸发酵过程种子罐培养液的多个质量参数的在线预测, 为后续发酵过程的控制提供了依据。
实验所用样本是某柠檬酸工厂生产过程中不同日期、 不同批次的种子罐培养液, 剔除异常值后共有443个样本。 样本光谱采集选用无锡迅捷光远科技有限公司生产的IAS-3120便携式光谱分析仪, 仪器分辨率为1 nm, 扫描速度为60次· s-1, 光谱波长范围为900~1 700 nm。
采集到的样本光谱分别结合由酸碱滴定法测定的总酸(TA)和由高锰酸钾滴定法测定的还原糖(RS)理化值使用SPXY(sample set parititioning based on joint x-y distance)法进行划分, 该方法同时考虑了理化值和光谱两种变量的空间分布, 有效地覆盖样本空间, 提高模型稳定性[10]。 按照3∶ 1的比例划分训练集和测试集, 在对总酸(TA)和还原糖(RS)分别进行单变量建模时, 训练集和测试集样本数均为332和111。
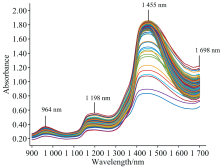
种子罐培养液样本的原始光谱图1所示。 可以看出, 964、 1 198、 1 455和1 698 nm附近存在着明显的吸收峰。 其中, 1 198、 1 455和1 698 nm附近分别为总酸(TA)和还原糖(RS)分子中官能团C— H的三倍频吸收带、 官能团O— H的二倍频吸收带以及官能团C— H的二倍频吸收带, 而964 nm附近为总酸(TA)分子中官能团0-H的三倍频吸收带。 种子罐培养液样本光谱存在着高度相似和谱带重叠的问题, 并且由于采集的样本来自多个发酵批次, 光谱分布呈现出批次差异性。 针对较为复杂的种子罐培养液样本数据, 需要结合多元校正方法来构建质量参数的定量校正模型。
 | 图1 原始近红外光谱Fig.1 Original near infrared spectra |
实际生产过程采集到的样本光谱可能受到样本分布不均匀带来的散射、 环境噪声、 批次差异导致的基线漂移等问题的影响, 在构建模型前对光谱进行预处理十分必要。
在柠檬酸发酵过程中, 发酵过程环境复杂, 环境噪声和人工采样噪声等随机噪声对样本光谱有着一定影响。 发酵过程的批次重复性差, 建模的培养液样本采集自多个批次, 不同批次间的样本光谱存在一定的差异, 这些差异对质量参数和光谱间的相关关系影响较大。 综上考虑, 培养液光谱预处理的目标应当是消除随机噪声以及减少批次差异性对于样本光谱的影响, 因此依次采用平滑处理(SG)和去趋势处理(DT)对光谱进行预处理, 前者可以消除随机噪声, 后者可以减少批次差异性和抑制基线漂移[11, 12]。
平滑处理(SG)基本通过2a+1个点宽度的窗口来计算数据点的加权平均值。 去趋势处理(DT)采用最小二乘法将原始光谱的吸收度和波长拟合出一条趋势线, 然后从原光谱中减去该趋势线。
特征波长选择是近红外光谱建立模型过程中的重要步骤, 可以减少光谱信噪比低、 光谱信息与被测信息之间存在线性不相关、 光谱之间存在严重的多重相关性、 光谱受外界环境因素变化等影响。
采用间隔偏最小二乘法(iPLS)选择培养液样本光谱的特征波长。 iPLS能够减少全光谱波段冗余数据量, 提高建模效率, 其原理是划分全光谱为若干个宽度相等的子区间, 在每个子区间上进行PLSR建模, 选择交叉验证均方根误差(RMSECV)最小的局部模型对应的区间作为基区间, 然后单向或者双向扩充波长区域[13, 14, 15]。 算法具体步骤如下:
(1) 全波长下建立全局PLSR模型。
(2) 将光谱划分为n个等宽的光谱子区间, 每个子区间分别建立局部PLSR模型。
(3) 用RMSECV作为局部模型的评价指标, 比较全局模型和局部模型的的指标, 取指标最优的局部模型所在子区间作为第一入选区间。
(4) 将余下的的子区间分别与入选区间组合, 每个组合区间都建立PLSR模型, 选择指标最优的模型所对应的子区间作为第二入选区间。 重复上述过程, 直到所有子区间都进入组合模型。
(5) 比较每次组合模型的RMSECV值, 指标最优(RMSECV最小)的模型对应的组合区间即为最佳特征波长区间。
1.5.1 多元校正方法
使用偏最小二乘回归(PLSR)和误差反向传播神经网络(BP-ANN)分别建立定量校正模型, 并确定最佳建模方法。
PLSR是一种线性回归方法, 通过提取光谱变量和理化值变量的主成分求得两者之间的关系函数, 从而对新样本预测, 具体建模步骤:
(1) 分别提取光谱矩阵和理化值矩阵的主成分见式(1)和式(2)
其中, T和U分别是光谱矩阵和浓度矩阵的得分矩阵, P和Q分别是光谱矩阵和浓度矩阵的载荷矩阵, Ex和Ey分别是光谱矩阵和浓度矩阵的误差矩阵。
(2) 对U和T进行线性回归, 见式(3)
(3) 利用未知的光谱矩阵Xnew和P求出未知理化值的光谱的Tnew, 再由以式(4)计算理化值, 见式(4)
误差反向传播神经网络(BP-ANN)是一种浅层的神经网络模型, 网络结构如图2所示, 可以用来拟合光谱变量和理化值变量之间的非线性关系。
 | 图2 BP神经网络结构图Fig.2 BP neural network structure diagram |
具体建模步骤为:
(1) 网络结构初始化: 确定神经网络的节点数、 选择适当的激活函数、 设定学习率和更新算法等参数;
(2) 计算隐含层的输出: 将光谱作为输入数据传递给神经网络的隐含层, 通过激活函数对输入进行加权和非线性变换, 得到隐含层的输出;
(3) 计算输出层: 将隐含层的输出传递给神经网络的输出层, 进行加权和非线性变换, 得到最终的输出结果;
(4) 计算误差: 将神经网络的输出与实际目标理化值进行比较, 计算预测结果与真实值之间的误差;
(5) 误差反向传播更新权重: 利用误差反向传播算法, 根据误差大小调整权重, 使预测结果逐渐接近实际目标理化值;
(6) 判断是否迭代结束: 检查模型的收敛情况, 如果满足停止条件, 则结束建模过程; 否则, 回到步骤(2)继续迭代, 进行下一轮的计算和更新。
以上建模过程中使用的算法使用Python3.9版本语言编写, 代码编译软件为Pycharm, 系统内置Numpy、 Pandas等库, 并安装了深度学习框架Tensorflow数值运算库。
1.5.2 模型评价
采用预测决定系数
其中, yi为预测集目标变量实际值,
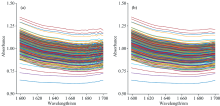
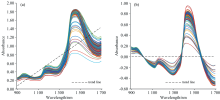
为了改善光谱质量, 完成后续构建预测模型的任务, 采用SG-DT方法对原始光谱进行预处理。 图3(a, b)所示为原始光谱的局部放大和SG处理后的光谱局部放大, 放大部分为1 600~1 700 nm的局部光谱, 可以明显看出SG对于噪声的削弱。 光谱经过平滑处理后再对其进行去趋势处理, 原始光谱和DT处理后的光谱如图4(a, b)所示, 图中虚线为样本光谱分布趋势线, 可以看出DT对于批次差异性的减少和对于基线漂移的抑制。
 | 图3 原始光谱和SG处理后的光谱的局部放大 (a): 原始光谱的局部放大; (b): SG处理后的光谱的局部放大Fig.3 Local magnification of original spectra and spectra after SG processing (a): Local magnification of the original spectra; (b): Local magnification of the spectra after SG processing |
 | 图4 原始光谱和DT处理后的光谱, 其中虚线为光谱分布趋势线 (a): 原始光谱; (b): DT处理后光谱Fig.4 Original spectra and spectra after DT processing, with the dashed line representing the spectral distribution trend line (a): Original spectra; (b): Spectra after DT processing |
光谱预处理虽然消除了随机噪声、 减少批次差异性, 但是预处理后光谱变量中仍然包含着与质量参数变量无关的干扰变量, 需要利用特征波长选择方法进行降维, 保留有效变量, 去除干扰变量。 本工作采用iPLS方法选择特征波长, 以RMSECV作为评价指标, 采用k折交叉验证(k=5), 统计了划分不同子区间个数的选择结果, 如表1所示。
| 表1 iPLS划分不同区间数的选择结果 Table 1 Best predictive results of PLSR models based on different feature selection methods |
由表1可看出, iPLS划分不同区间数对于模型预测结果是有一定影响, 划分合适的区间数不仅可以最大程度减少变量冗余、 降低模型复杂度, 也可以得到更佳的建模效果。 其中, 特征波长选择的目标质量参数为总酸(TA), iPLS划分的区间数为21时, RMSECV最小为0.112 5, 选择的特征波长个数为495, 相对于全光谱的801个波长变量, 减少了38.2%; 目标质量参数为还原糖(RS), iPLS划分的区间数为20时, RMSECV最小为0.144 0, 选择的特征波长个数为361, 相对于全光谱的801个波长变量, 减少了54.9%。 总酸(TA)和还原糖(RS)的预处理后光谱被选择的特征波长变量分布如图5所示。
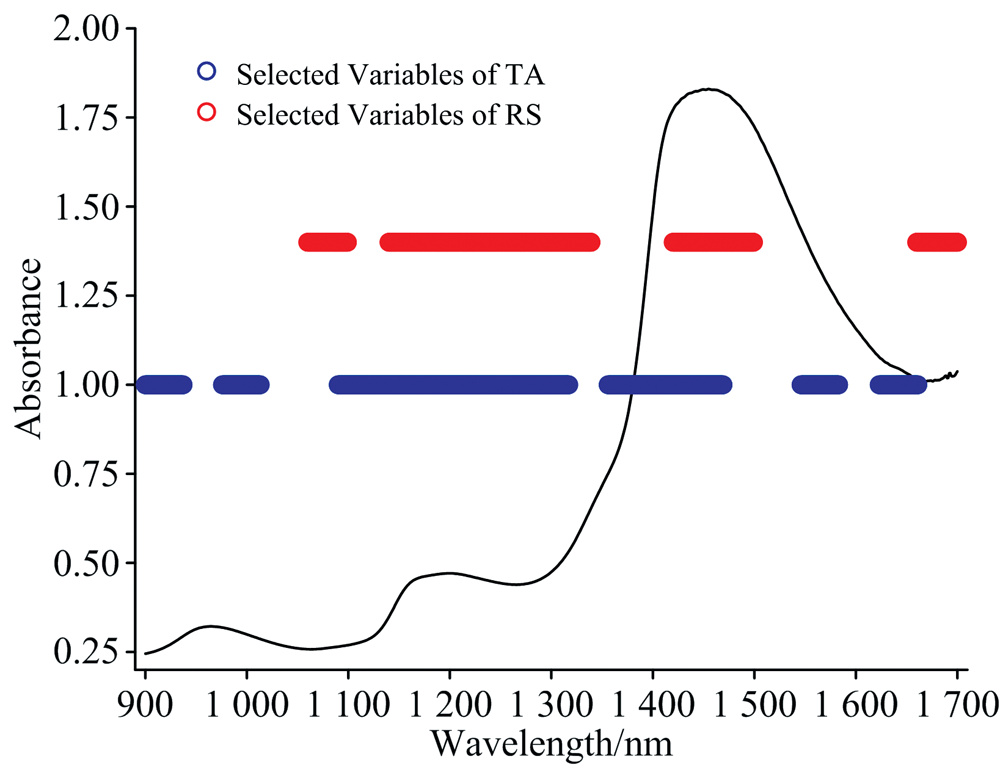 | 图5 选择的特征波长变量分布Fig.5 Distribution of feature wavelength variables selected |
图5中蓝色竖线代表总酸(TA)的光谱经过SG-DT预处理后通过iPLS选择出的特征波长, 红色竖线代表还原糖(RS)的光谱经过SG-DT处理后通过iPLS选择出的特征波长, 黑色曲线为培养液样本的平均光谱。 从图5可以看出, 总酸(TA)所对应的特征波长主要集中在900~1 000和1 100~1 500 nm波段附近以及1 550和1 650 nm附近, 而还原糖(RS)的特征波长主要集中在1 100~1 300和1 400~1 500 nm波段附近以及1 700 nm附近, 与1.2节中分析原始光谱的波峰对应的官能团吸收带(TA分子中官能团吸收带在964、 1 198、 1 455和1 698 nm附近, RS分子中官能团吸收带在1 198、 1 455和1 698 nm附近)较为吻合。 然而由图中可以看出有许多非吸收峰附近的波长也被选作特征波长, 说明质量参数在光谱中的部分信息被覆盖, 无法通过直接观察、 主观经验来获得, 通过特征波长选择方法可以挖掘出这部分信息, 使得模型能够更准确地预测质量参数, 可靠性较高。
分析经过光谱预处理和特征波长选择后的光谱波长变量与对应目标质量参数变量之间的相关程度, 结果如表2所示。
| 表2 波长变量和质量参数变量的相关程度 Table 2 Correlation between wavelength variables and quality parameter variables |
表2中RXY为波长变量X与质量参数变量Y之间的相关系数, 范围为[-1, 1], |RXY|为其绝对值, 范围为[0, 1]。 |RXY|的大小反映了波长变量与质量参数变量的相关程度, 0~0.2为极弱相关或无关, 0.2~0.4为弱相关, 0.4~0.6为中等程度相关, 0.6~0.8为强相关, 0.8~1.0为极强相关。 RXY具体计算公式如式(7)所示。
式(7)中, cov(X, Y)为X与Y的协方差, var(X)和var(Y)分别为X和Y的方差。 通过计算处理前后的光谱变量和目标质量参数变量之间的相关系数, 分析两者之间的相关程度, 不仅可以体现光谱预处理和特征波长选择对于减少光谱受环境因素的影响、 改善光谱和目标变量之间的非线性、 减少波长变量之间的多重相关性方面起到的作用, 还可以依此选择建模所使用的多元校正方法。
从表2可以看出, 经过光谱预处理和特征波长选择后的光谱变量和目标质量参数变量之间的相关系数绝对值无论是最大值还是平均值都增加了, 说明光谱变量和目标质量参数变量之间的线性关系得到了一定加强。 然而经过预处理和降维后的光谱变量和质量参数之间的相关程度仍未达到强相关或极强相关, 尤其是光谱变量和总酸(TA)变量之间仍是弱相关, 因此使用可以处理非线性的BP网络来建立TA的预测模型; 光谱变量和还原糖(RS)变量之间由弱相关达到了中等程度相关, 使用PLSR和BP网络分别建立预测模型, 并比较两者建模的预测效果以选择最优模型。
针对经过光谱预处理和特征波长选择后的光谱, 建立了基于BP网络的总酸(TA)的预测模型和分别基于BP网络及基于PLSR的还原糖(RS)的预测模型, 同时为了更直观地体现光谱预处理和特征波长选择对于模型预测结果的改善, 针对原始光谱建立了两个质量参数的预测模型, 模型的预测结果由表3所示。
| 表3 模型预测结果 Table 3 Model prediction results |
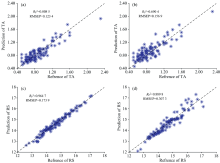
由表3可以看出, 相对于原始光谱, 经过预处理和特征选择后的光谱变量建立的质量参数预测模型预测效果更好。 在对总酸(TA)建模过程中, 经过处理后的光谱所建立的BP网络模型预测效果优于原始光谱, 模型的
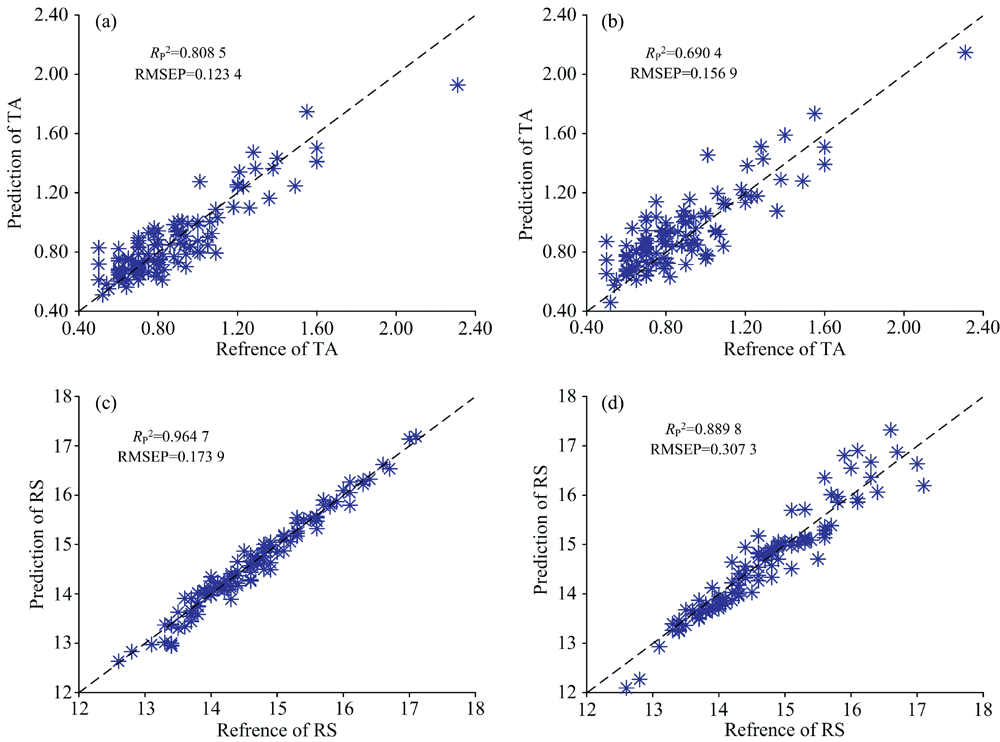 | 图6 总酸和还原糖的最优模型和BP模型的预测结果 (a): TA的SG-DT-iPLS-BP最优模型; (b): TA的BP模型; (c): RS的SG-DT-iPLS-BP最优模型; (d): RS的BP模型Fig.6 Prediction results of the optimal model and BP model for TA and reducing sugar RS (a): Optimal model of SG-DT-iPLS-BP for TA; (b): BP model for TA; (c): Optimal model of SG-DT-iPLS-BP for RS; (d): BP model for RS |
在柠檬酸发酵过程中实时在线收集种子罐培养液近红外光谱并实时传输到监控计算机中, 利用已经导入监控计算机中的上述最优模型通过近红外光谱预测菌种培养过程种子罐培养液中的总酸(TA)和还原糖(RS)含量。 模型的60个新样本预测误差如表4所示, 满足实际生产过程要求(TA预测平均相对误差在10%以内, RS预测平均相对误差控制在1%以内)。 预测结果如图7(a, b)所示。
| 表4 最优模型对新样本预测的误差 Table 4 Prediction error of the optimal model for new samples |
 | 图7 最优模型对新样本预测结果 (a): TA预测结果; (b): RS预测结果Fig.7 Prediction result of optimal models for new samples (a): Prediction results of TA; (b): Prediction results of RS |
从图中可以看出预测结果与实际值之间良好的一致性。 这种实时预测方法可以帮助监测柠檬酸发酵过程中菌种培养过程的质量参数, 并及时采取必要的调整措施以优化生产效率和产品质量。
采用近红外光谱代替柠檬酸发酵过程中菌种培养的过程变量, 建立质量参数总酸(TA)和还原糖(RS)的近红外光谱预测模型。 通过对原始光谱的分析, 利用SG-DT方法对光谱进行预处理以消除随机噪声和减少批次差异性带来的影响; 通过交叉验证的方式确定了iPLS选择特征波长的最佳子区间划分数并得到了最优特征子集; 通过对光谱变量和质量参数变量的相关程度分析确定了建模所用的多元校正方法。 研究结果表明, 质量参数总酸(TA)的最佳模型为SG-DT-iPLS-BP, 模型的
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|