




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多模型决策融合的苹果产地判别及糖度含量预测
[姜小刚1, 2  , 何聪
, 何聪1, 2 , 姜楠3 , 黎丽莎1 , 朱明旺1 , 刘燕德1, 2, * ]
, 何聪]
|
|


作者简介: 姜小刚, 1985年生, 华东交通大学机电与车辆工程学院与智能机电装备创新研究所博士研究生 e-mail: jxg_ecjtu@163.com
苹果产地溯源与苹果糖度含量预测具有非常重要的现实意义, 通过建立模型达到产地判别与糖度预测目的。 为了克服单个模型的局限性, 通过将多个模型的预测结果综合, 提高整体预测性能。 采用近红外光谱结合多模型决策融合策略对苹果产地进行溯源鉴别, 对苹果糖度值进行预测, 验证理论方法的可行性。 采用手持式近红外检测仪采集了苹果样本的光谱, 使用样本光谱结合随机森林(RF)方法、 偏最小二乘判别分析(PLS-DA)与支持向量机(SVM)方法建立了苹果产地判别模型。 再对三种判别模型输出的预测结果使用投票制决策融合方法, 输出新的判别结果。 对所有苹果样本采集了糖度实际值, 使用样本光谱与糖度实际值结合随机森林(RF)、 偏最小二乘回归(PLSR)与支持向量回归(SVR)方法建立了糖度预测模型。 采用三种回归模型输出的结果, 通过加权法决策融合策略输出新的糖度预测结果。 在不使用投票决策方法时, 三种定性建模方法中使用RF方法建立判别模型效果最好, 预测准确度达到88.71%。 使用SVM方法预测效果最差, 预测准确度为77.43%。 使用投票决策方法后, 对苹果产地鉴别的准确度达到93.42%, 其预测的精确度与召回率也达到了双高, 均在85%以上。 在不使用加权的决策融合方法前提下, 三种定量建模方法对苹果糖度的预测均有不错的效果。 三种方法预测的决定系数均约0.87, 预测均方根误差均约为0.78。 使用了加权的决策融合方法, 对糖度的预测效果有一定的提升。 预测决定系数为0.91, 预测均方根误差为0.66。 通过在苹果产地的鉴别与苹果糖度的预测中, 使用多模型决策融合方法提高了苹果产地判别的正确率, 提升了对苹果糖度预测的准确性, 证实了所提方法的可行性。 同时, 手持式近红外检测仪结合多模型决策融合方法也为现场无损检测分析提供了一种新的高精度预测手段。
Traceability of apple origin and prediction of apple SSC is of great practical significance, and the purpose of origin discrimination and SSC prediction is achieved by modeling. To overcome the limitations of a single model, the overall prediction performance is improved by combining the prediction results of multiple models. Near-infrared spectroscopy (NIRS) detection technology combined with a multi-model decision fusion strategy is utilized for traceability identification of apple origin and prediction of apple SSC to verify the feasibility of the theoretical method.The spectra of apple samples were collected using a handheld near-infrared detector, and apple origin discrimination models were established using the sample spectra in combination with the random forest (RF) method, the partial least squares discriminant analysis (PLS-DA) method, and the support vector machine (SVM) method. The predictions from the three discrimination models are then used in a voting system decision fusion method to generate new discriminant results. Actual values of SSC were collected for all apple samples, and SSC prediction models were developed using the sample spectra and actual values of SSC combined with the random forest (RF) method, the partial least squares regression (PLSR) method, and the support vector regression (SVR) method. Using the outputs of the three regression models, the new SSC prediction is output through the weighting method decision fusion strategy. When the voting decision-making method was not used, the discrimination modeling using the RF method was the most effective among the three qualitative modeling methods, with a prediction accuracy of 88.71%. The worst prediction was made using the SVM method, with a prediction accuracy of 77.43%. After using the voting decision method, the accuracy of apple origin identification reached 93.42%, and its prediction precision and recall also reached a double high, both above 85%. All three quantitative modeling methods gave good results in predicting apple SSC without using the weighted decision fusion method. All three methods predicted coefficients of determination around 0.87 and root mean square errors of prediction (RMSEP) around 0.78. The prediction of the SSC level was improved after using the weighted decision fusion method. The prediction coefficient of determination was 0.91, and the RMSEP was 0.66. The feasibility of the proposed method was confirmed by using the multi-model decision fusion method in the identification of apple origin and the prediction of apple SSC to improve the accuracy of apple origin discrimination and the precision of the prediction of apple SSC. Meanwhile, the handheld NIR detector combined with the multi-model decision fusion method provides a new high-precision prediction approach for on-site non-destructive testing analysis.
苹果是世界第三大种植和消费的水果, 仅次于香蕉和西瓜[1]。 我国种植苹果的优势地区非常多, 阿克苏、 大凉山、 大漠、 烟台等地区的苹果富有盛名, 并走出国门, 远销海外。 来自不同地理位置的苹果在收获和销售过程中很容易混合, 使得冒充品牌地区苹果的事情时有发生, 这将影响商家信誉和消费者权益。 糖度含量(soluble solids content, SSC)是衡量苹果成熟度和口感品质的一个重要指标, 直接影响了苹果的口感和风味, 从而影响消费者对其接受度[2]。 一般采用切开后压榨果实的方式进行糖度含量测量, 该测量方法相对准确, 但对测试样品损耗很大, 快速、 无损鉴别苹果产地与检测苹果糖度的方法非常有必要[3]。
近红外光谱技术是一种快速无损技术, 检测手段简单, 设备成本低, 可用于实时在线检测, 已被广泛用于多种水果的产地鉴别与内部品质检测领域[4]。 为了应用近红外光谱分析技术去实现精准预测目的, 建立了定量或定性模型, 并且通过各种化学计量学方法与技术去提升模型的预测性能。 马永杰等[5]采集了三个不同产地红富士苹果样本的光谱, 并经过结合12种数据降维后, 构建了有效的苹果产地溯源模型。 Li等[6]采用反向传播神经网络、 支持向量机与极限学习机三种模式识别方法建立了不同产地苹果的区分模型。 张立欣等[7]采用区间法、 后向区间法、 连续投影算法与连续投影算法-区间法选取特征波段变量后, 建立了苹果可溶性固形物含量简化模型。 孟庆龙等[8]采用三种光谱预处理方法并结合连续投影算法与CARS方法进行数据降维, 建立了基于特征光谱的误差反向传播网络和多元线性回归的苹果可溶性固形物含量预测模型。 研究表明在建立苹果定性或定量模型时, 大部分方法选择对光谱数据进行预处理, 再通过特征波长选取算法结合达到精准预测的目的。 除此对数据进行融合, 对学习模型进行集成也是一大研究热点, 这些方法的使用有助于提高模型的预测能力。 Bian等[9]探讨了训练子集的生成与校准, 以及子模型的集成, 这三者都是集成模型校准成功的关键。 贾利红等[10]采集了酒醅样本的光谱数据, 在不同的预处理算法与偏最小二乘建模算法组合中筛选基本模型, 并基于模型自身的相关系数进行模型权重计算, 建立了酒醅成分集成预测模型。 张晨等[11]采集了不同贮藏期的瑞卡蓝莓与不同成熟度的绿宝石蓝莓, 采用Stacking集成学习模型结合SVR、 XGBoost和MLP对蓝莓的品质实现了高准确度、 高精度的预测。 黄华等[12]采集近红外透射光谱后基于分数阶微分及主成分分析-谱回归判别分析进行了多模型融合, 构建红富士苹果产地溯源的集成学习模型。
与在实验室精确测量不同, 越来越多的检测要求近红外技术能运用到现场快速预测。 本工作使用F750型手持式近红外检测设备, 采集了不同产地苹果的光谱, 并运用多模型决策融合策略对苹果产地进行无损鉴别, 并对苹果糖度含量鉴定分析。 本研究的目的是: (1)探究多模型决策融合方法的可行性; (2)通过探讨比较不同建模方法与多模型决策融合方法分别得出的预测结果, 验证所提出的方法能使手持式近红外光谱仪预测更精确, 为实现现场快速预测提供了一种新的思路。
实验使用的苹果样品保持品种一致, 都是红富士品种, 购买于南昌市某水果市场。 试验共采用952个样品, 分别是280个产地为阿克苏苹果, 244个产地为攀枝花苹果, 228个产地为洛川苹果, 200个产地为烟台苹果。 并分别将它们命名为产地-Ⅰ 、 产地-Ⅱ 、 产地-Ⅲ 与产地-Ⅳ 。 所有试验样品大小一致, 外表无损伤。 将苹果表面擦净后, 在室温下静置24 h后进行试验。 试验前在所有苹果的环赤道间隔90° 的位置作了标记[13]。
采用Felix F750手持式近红外光谱仪, 光谱仪安装有32 W卤素灯和近红外光谱仪模块, 波长范围为729~975 nm, 分辨率为3 nm。 对于一次光谱的采集, 光谱仪会自动扫描7次, 取平均值作为输出光谱。 获得每个样本标记处的四个光谱, 取它们的平均值作为样本最终的光谱, 以此保证所采集到的光谱信号的准确性。 每个样本光谱均采集到了83个波长点。
将样品光谱采集后, 使用折射式数字糖度计(ATAGO PAL-α , 日本ATAGO公司)测定样品的糖度含量, 并记录数据。 测量前, 使用纯净水对糖度计进行标定处理。 测量时, 将样品果肉进行榨汁, 并用干燥洁净纱布滤出果汁, 滴于糖度计的测试镜面上。 测定重复3次, 取3次的平均值作为糖度含量真实值。
采用Matlab2012a(The Mathwork, USA)和The UnscramblerX10.4(CAMO Analytics, Norway)数据分析软件进行数据处理和模型建立。 使用变量排序归一化(VSN)方法[14]对光谱数据进行预处理。 再通过SPXY样本划分方法对样本集进行划分, 得到633个建模集样本与319个预测集样本[15]。 建模集用于定性与定量模型的建立, 预测集用于对所建立模型的外部预测。
1.4.1 定性建模方法与评价标准
产地判别模型的建立是通过随机森林(RF)、 偏最小二乘判别分析(PLS-DA)与支持向量机(SVM)方法来获得的。 使用准确度、 精确度与召回率来评价模型预测结果的好坏, 并采用混淆矩阵来客观衡量模型性能。 以一个二元分类任务举例, 准确度[如式(1)所示]、 精确度[如式(2)所示]与召回率[如式(3)所示]计算公式分别为
式(1)— 式(3)中, TP、 TN、 FP、 FN分别代表真阳性、 真阴性、 假阳性和假阴性。
1.4.2 定量建模方法与评价标准
糖度预测模型的建立通过随机森林(RF)、 偏最小二乘回归(PLSR)与支持向量回归(SVR)方法获得。 通过
式(4)和式(5)中, N是试验样本数, ya是用标准方法测得的预测集中第i个样本的实际值, yb是第i个样本通过建立的近红外数学模型计算所得到的预测值, 以及yc是所有苹果样本预测值的平均值。
在采集光谱前对冰糖心苹果进行横纵经、 重量、 色差等物理指标参数的采集, 用游标卡尺采集样品的横纵径时, 选取样品的最大横径与最大纵径进行测量。 测量色差时, 测量位置与采集光谱的位置一致, 即在样品标号的位置所对应的经线与样品赤道交点处。 采集到样品的物理指标如表1所示。 其中L表示亮度, a表示红绿色差, b表示蓝黄色差。
| 表1 样品物理指标分布统计结果 Table 1 Statistical results of the distribution of physical indicators of the samples |
图1为不同产地样本的原始平均光谱。 虽然这四类样本的平均光谱大部分重叠, 但在几处仍有差异。 在740 nm[图1(a)]的波长处, 吸光度有明显的差异。 此外在914~945 nm[图1(b)]与955~970 nm[图1(c)]处出现了相应的波峰与波谷, 在波峰与波谷处也存有差异。
 | 图1 不同产地苹果的原始平均光谱对比 (a): 740 nm处波长差异对比; (b): 914~945 nm处波长差异对比; (c): 955~970 nm处波长差异对比Fig.1 Comparison of raw mean spectra of apples from different origins (a): Comparison of wavelength difference at 740 nm; (b): Comparison of wavelength difference at 914~945 nm; (c): Comparison of wavelength difference at 950~970 nm |
所有样本的糖度含量参考值如表2所示。 其中标准偏差的计算如式(6)所示。
式(6)中, n为试验样本数, xi为第i个样本的糖度含量,
| 表2 建模集与预测集苹果糖度含量参考值统计结果 Table 2 Statistical results of the reference values of apple SSC in the modeling set and the prediction set |
分别通过RF方法[图2(a, b)]、 PLS-DA方法[图2(c, d)]与SVM方法[图2(e, f)]建立了苹果产地判别模型。 其中PLS-DA方法使用交叉验证的方式得到最佳的潜在变量数为11。 SVM方法在The Unscrambler X10.4软件中运行, 使用十折交叉验证与线性核函数, 通过网格寻优的方法得到最佳精确度指数为0.01。 各建模方法的预测结果如图2(a— f)所示。 结果表明: 使用RF建模方法得到的预测效果最好, 最差的预测效果是使用SVM建模方法。 三种建模方法下, 普遍对产地-Ⅰ 与产地-Ⅲ 的误判比较多。 精确度是指模型正确预测的样本数, 即模型学习到的特征信息准确性。 在RF与PLS-DA的建模方法下, 对产地-Ⅱ 与产地-Ⅳ 的识别精度最高, 超过90%。 召回率是指类别样本被识别出的百分比, 即类别样本的特征信息越多, 越容易被判别, 所建立的模型预测性能就越好。 在SVM模型中, 对产地-Ⅳ 的召回率较高, 说明SVM方法从产地-Ⅳ 的光谱中获得的特征信息最丰富。 RF方法与PLS-DA方法对四个类别产地的召回率也都达到了80%以上, 这两种方法对四个产地的类别特征信息都能较好的识别并学习。 三种建模方法均对产地-Ⅰ 的识别精度不高, 容易预测失误, 可能是由于产地-Ⅰ 的光谱与其他三种产地苹果的光谱极为相似, 三种方法都不能完全获取到对产地-Ⅰ 的光谱特征信息。 三种建模方法均对产地-Ⅳ 有较高的识别精度, 分析认为产地-Ⅳ 相对于其他三种产地的光谱具有较大的差别, 容易获取到产地-Ⅳ 的光谱特征。
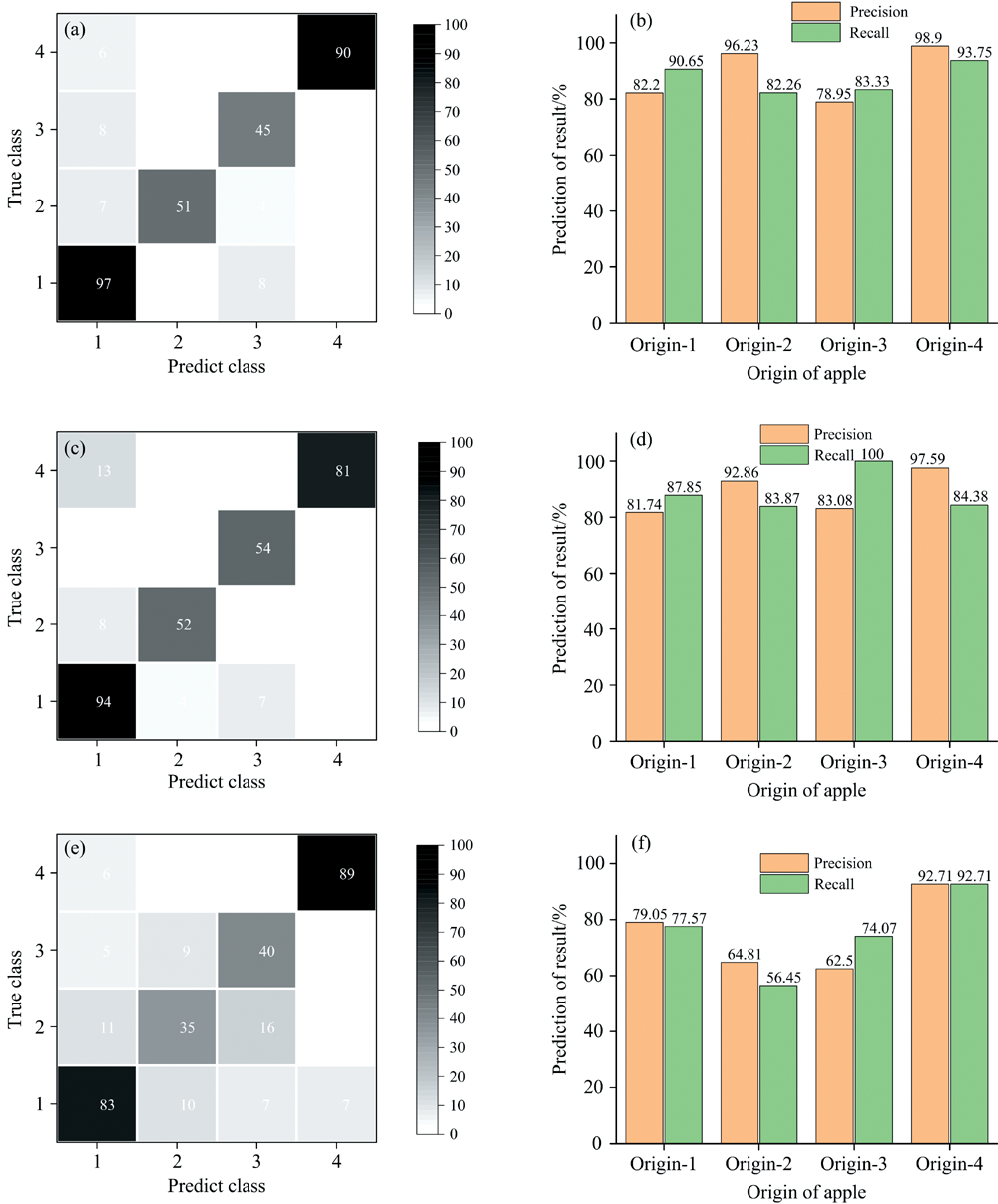 | 图2 三种定性模型预测结果的混淆矩阵图与精确度召回率柱状图 (a): RF建模; (b): RF预测模型与召回率图; (c): PLS-DA方法建模预测结果混淆矩阵; (d): PLS-DA预测模型精度与召回率柱状图; (e): SVM方法建模预测结果与混淆矩阵; (f): SVM预测模型精确度与召回率柱状图Fig.2 Confusion matrix and precision recall histogram of predictions from three qualitative models (a): Confusion matrix of predicted results from RF method modelling; (b): Histogram of RF prediction and recall; (c): Confusion matrix of predicted results from PLS-DA method modelling; (d): Histogram of PLS-DA prediction model precition and recall; (e): Confusion matrix of predicted results from SVM method modelling; (f): Histogram of SVM prediction model precition and recall |
对三个判别模型的预测结果进行融合, 使用投票制输出结果, 即“ 少数服从多数” 的原则, 如果三个判别模型的预测结果均不一致, 则使用准确率最高的判别模型输出的结果为最终结果。 图3(a)是使用多模型决策融合后的预测结果。 由图中的混淆矩阵显示, 多模型融合总体上提高了预测的准确度, 误判的情况也随之减少。 由精确度召回率图图3(b)发现, 对产地-Ⅰ 的精确度与召回率均超过90%, 尤其是对精确度的提高, 说明多模型决策融合增强了对产地-Ⅰ 的特征信息“ 抓取” , 更容易识别出产地-Ⅰ 。 由于三种判别模型对于产地-Ⅳ 的准确识出与精确识别, 以此决策融合后, 对于产地-Ⅳ 的精确度达到100%, 召回率也达到了可观的效果。 此外, 模型决策融合方法在四种产地的苹果鉴别中, 精确度与召回率达到“ 双高” , 均超过85%, 表明该方法对于这四类产地鉴别有良好的预测能力(如表3所示)。
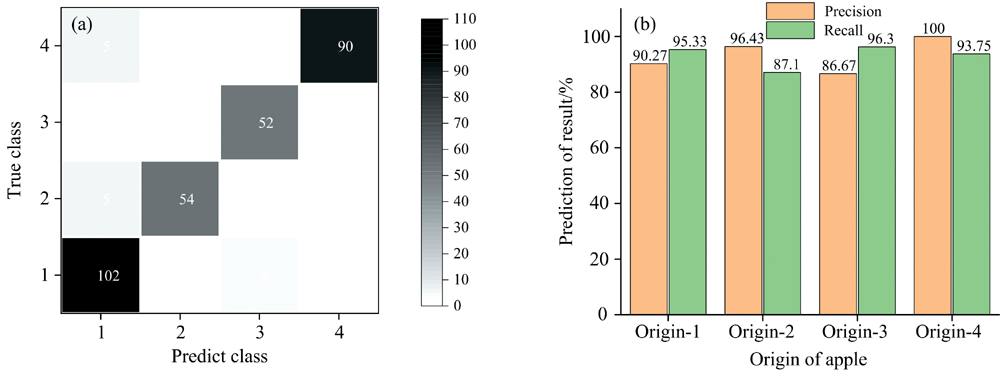 | 图3 多判别模型预测结果融合的混淆矩阵图(a)与精确度召回率柱状图(b)Fig.3 Confusion matrix (a) and precision recall histogram for fusion of multi-discrimination model predictions (b) |
| 表3 不同产地苹果定性模型验证结果 Table 3 Results of qualitative models validation for apples of different origins |
对于糖度预测模型, 使用了RF、 PLSR与SVR方法进行回归预测模型的建立。 三种模型预测结果散点图分别见图4(a, b, c)所示, 三种建模方法的预测决定系数值
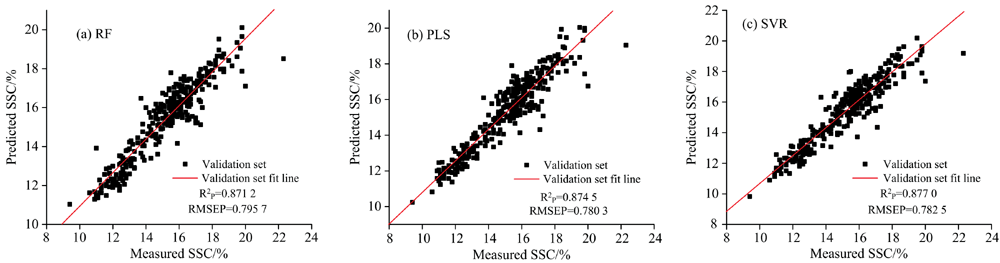 | 图4 三种定量模型的预测结果散点图 (a): RF预测散点图; (b): PLS模型预测散点图; (c): SVR模型预测散点图Fig.4 Scatterplot of prediction results from three quantitative models (a): Scatterplot of RF model predictions; (b): Scatterplot of PLS model predictions; (c): Scatterplot of SVR model predictions |
对于三种建模方法得出的糖度预测结果, 分别对不同的预测结果赋予不同的权重, 进行加权处理后, 得到最终的糖度预测结果值[10, 12]。 通过赋予预测结果Ⅰ 、 预测结果Ⅱ 与预测结果Ⅲ 不同的权值, 权值的计算过程如图5所示, 再使用网格搜索寻优法得出最优的预测结果。 其中指数系数值由零至一逐步迭代寻优, 得到最佳的指数系数值为0.3。 得到的预测结果散点图如图6所示。 预测结果决定系数
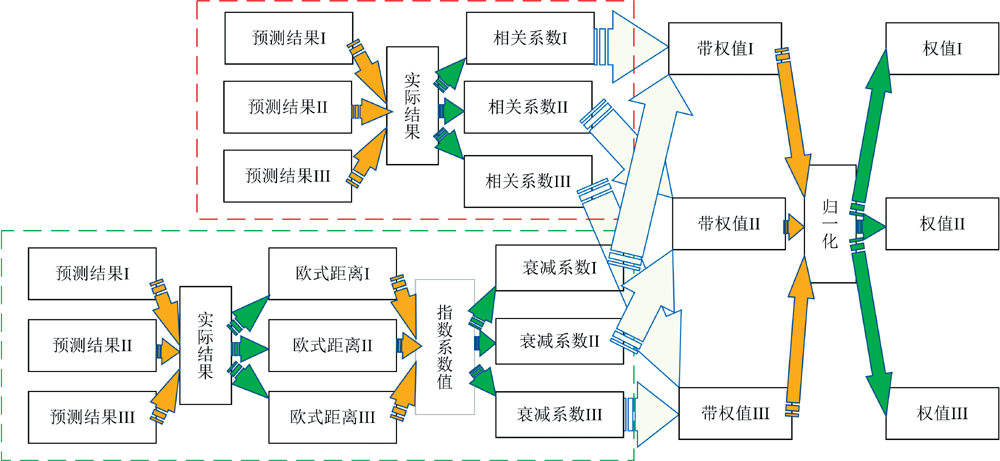 | 图5 权值计算流程Fig.5 Flowchart for weight calculation |
 | 图6 多回归模型预测结果融合的预测散点图Fig.6 Scatterplot of fusion of prediction results from multi-regression models |
| 表4 苹果预测模型验证结果 Table 4 Apple predictive model validation results |
为了鉴别苹果的原产地, 使用了RF方法、 PLS-DA方法与SVM方法进行判别模型的建立, 结果显示, 采用RF建模方法得到的预测准确度最高, 准确度为88.71%, 利用SVM方法得到的准确度最低, 准确度为77.43%。 使用所提出的多模型决策融合方法, 准确度提升至93.42%, 误判率下降。 该方法在四种产地苹果的类别预测中, 其精确度与召回率均达到85%以上, 表明多模型结合决策融合方法能提供较高的产地鉴别能力。 为了准确预测苹果糖度值, 使用了RF方法、 PLSR方法与SVR方法建立了糖度预测模型, 三种建模方法所得到的决定系数均约为0.87, 预测均方根误差均约0.78。 在使用了多模型决策融合策略后, 预测决定系数有较大的提升, 并提升至0.91, 预测均方根误差也有明显降低, 降低至0.66, 表明多模型决策方法能为苹果糖度值的预测带来更精确的结果。 说明手持式近红外检测仪结合多模型决策融合方法, 能为现场检测环节带来更高的预测准确性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|