





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
机器学习与斯塔克展宽法结合的等离子体电子密度诊断方法
[张婷琳 , 唐龙, 彭东宇, 汤昊, 姜盼盼, 刘博通, 陈传杰
, 唐龙, 彭东宇, 汤昊, 姜盼盼, 刘博通, 陈传杰* ]
, 唐龙, 彭东宇, 汤昊, 姜盼盼, 刘博通, 陈传杰]
|
|


作者简介: 张婷琳, 1988年生,盐城工学院信息工程学院讲师 e-mail: tinglinzhang@ycit.edu.cn
电子密度是等离子体基本参数之一。 Hβ是基于斯塔克展宽的发射光谱法最常用的谱线。 在大气压条件下, 范德瓦尔斯展宽对Hβ谱线加宽的贡献突出, 它与等离子体的气体温度有关。 为了提取斯塔克展宽, 需要利用分子的转动温度预先确定气体温度, 因而其结果必然存在一定的误差, 从而导致在谱线的非线性参数拟合中将气体温度的误差传递给电子密度。 提出了一种基于机器学习的随机森林回归模型与基于发射光谱的斯塔克展宽法相结合的电子密度光谱诊断方法。 通过与传统最小二乘法的误差特性进行对比发现, 该方法具有更好的鲁棒性和泛化性能, 能够精确且快速地诊断电子密度。 通过在气体温度中引入随机偏差, 利用谱线展宽模型仿真出不同等离子体状态下的Hβ谱线, 将其作为机器学习的训练数据集。 将每组带温度偏差的谱线强度分布与对应的电子密度构成样本集, 对随机森林模型进行训练, 使模型得到最小均方误差的超参最小叶节点和决策树数量分别为2和100。 在模拟中, 考虑到气体温度的诊断误差, 将带温度偏差的光谱数据作为模型输入, 预测出电子密度。 研究表明, 经训练后的随机森林模型对电子密度的预测结果与真实值之间的平均相对误差小于3%。 利用气体温度误差范围为0~±10%的光谱测试集对模型进行评估, 随着温度误差增大, 模型预测结果比最小二乘法的结果更好。 当气体温度误差为±10%时, 模型预测电子密度的均方误差相比于最小二乘法降低了30%以上。 在光谱数据训练集中, 当训练数据集引入的偏差范围为0~±10%时, 模型的预测均方误差达到最小, 鲁棒性优于最小二乘法, 而当训练数据集所含偏差超过±10%时, 模型的预测结果较差。 另外, 利用训练好的随机森林模型分析Hβ谱线所需的时间远远小于最小二乘拟合法。
Electron density is one of the key fundamental parameters of plasma discharges. Hβ is the most used spectral line for spectroscopic diagnosis based on the Stark broadening method. The van der Waals broadening, which is related to the gas temperature, makes an important contribution to the broadening of the Hβ line at atmospheric pressure. To extract the Stark broadening width, the gas temperature should be determined in advance from the rotational temperature of molecules, resulting in inevitable errors in measuring. During the nonlinear parameters fitting processes of a spectral line, the errors in gas temperature will transfer to electron density measurement. This work proposes combining a random forest regression model based on machine learning and a Stark broadening method based on optical emission spectroscopy. Compared with the error characteristic of the traditional least square method, this method is found to have a good performance in robustness and generalization capability so that it could diagnose the electron density of plasma more precisely and quickly. Because of the different states of plasma discharges, the training set of Hβ standard theoretical line used for the machine learning is simulated by the model of spectral line broadening, in which the random errors are introduced into the gas temperature. A sample set, combined with the spectral line's intensity distribution with each group's temperature deviation and the corresponding electron density, is employed to train the random forest model. The hyperparameters (i.e., the minimum number of leaf nodes and the number of decision trees) that minimize the mean square error of the model are set to 2 and 100, respectively. It is found that the average relative error between the results predicted by the random forests regression model, which is well-trained, and the actual values are less than 3%. The model was evaluated by a test set of spectral data with a temperature error range of 0~±10%. With the increase in temperature error, the prediction results of the random forest model are better than those of the least squares method. When the error of gas temperature is ±10%, the mean squared error of predicted electron density is reduced by more than 30% compared with the least squares method. In the training set of spectral data, when the error of gas temperature introduced into the training set is in the range of 0~±10%, the minimum mean squared error of electron density is achieved, and the robustness of the model is better than that of the least squares method. However, the prediction results of the model become inaccurate when the temperature error introduced into the training set is beyond ±10%. In addition, the time spent analyzing the spectral line by the model, which is well-trained, is much less than that by the least square method.
在低温等离子体中, 电子温度大于气体温度是最为典型的特征, 因而能够通过电子的碰撞激发、 解离、 电离等过程产生大量的活性粒子, 使得低温等离子体被广泛应用于材料表面改性、 气体处理、 生物医学等领域[1, 2]。 由于电子是放电等离子体中最为活跃的组分, 其动能和粒子数密度成为描述等离子体状态的关键参数, 即电子密度和温度。 因此, 电子密度和温度以及气体温度三个参数被认为是描述等离子体最基本的特征参数[3]。 对于电子密度, 常用的诊断方法有朗缪尔探针法、 微波干涉测量法、 发射光谱法、 汤姆逊散射法、 电学测量法, 等等。 其中, 发射光谱法是一种非侵入式、 无干扰的测量方法, 通过采集和分析等离子体的辐射光谱, 依据光谱信息与等离子体状态之间的物理关联性确定等离子体特征参数[4]。 基于发射光谱法的电子密度诊断主要有斯塔克展宽法、 连续谱法和碰撞辐射模型。 相比之下, 斯塔克展宽法是目前被广泛采用的方法。 一方面, 它不需要对光谱采集系统进行绝对辐射校准; 另一方面, 它不需要分析等离子体中复杂的物理化学过程。 当然, 斯塔克展宽法一般要求电子密度达到1013 cm-3以上, 这样谱线展宽中的斯塔克效应才足够明显, 因此该方法在大气压放电等离子体中使用最多[5]。 然而, 随着气压升高, 范德瓦尔斯展宽和共振展宽在谱线加宽中的贡献愈加显著, 甚至会超过斯塔克展宽。 这就意味着范德瓦尔斯展宽和共振展宽分析的准确性具有重要的影响[6]。 研究表明, 这两种展宽机制都与等离子体的气体温度有关, 气体温度的误差和诊断不确定性会直接影响到两种展宽的分析结果[7]。 在对谱线的反卷积处理中, 通常采用Levenberg-Marquardt算法对谱线数据点进行拟合, 迭代求解福格特函数中的最优参数, 它是基于非线性的最小二乘原理。 虽然该算法具有收敛速度快、 参数优化自适应性好、 稳定性好等优点, 但是难以克服气体温度的诊断误差和不确定性对电子密度诊断的影响。
近年来, 机器学习方法正逐步应用于等离子体物理领域。 艾飞等运用全连接神经网络研究大气压介质阻挡放电等离子体特性, 提高了数值模拟的效率与效果[8]。 Zeng等人将基于物理信息的神经网络运用于介质阻挡放电的二维和三维电场强度测量, 提高了鲁棒性[9]。 王彦飞等开发了一种基于前馈神经网络和碰撞辐射模型的光谱诊断方法, 降低了基础数据偏差向诊断结果的传递[10]。 机器学习可以有效推动等离子体光谱诊断技术的发展。 与传统方法相比, 机器学习在自动特征提取、 高维数据和大数据处理、 灵活性、 泛化性能等方面都展现了较大优势。 机器学习模型能够自动学习数据中的特征表示, 发现数据中的非显式模式和复杂关系, 从而提高对数据拟合的性能。 最小二乘拟合在高维数据中容易受到维度灾难的影响, 而机器学习模型通过引入正则化、 降维等技术, 能够有效应对高维数据的挑战。 机器学习通过在训练数据中引入适量噪声, 使模型更好地适应真实世界中的变化和不确定性, 从而提高了模型的鲁棒性和泛化能力。 而最小二乘拟合容易出现过拟合或欠拟合的问题, 对新数据的预测能力较差。 本工作以电子密度的发射光谱诊断为例, 提出了一种基于机器学习的斯塔克展宽法, 通过对比分析传统的最小二乘法与新方法的误差特性, 验证了新方法可以提高光谱诊断的精度和鲁棒性。
原子特征谱线的展宽机制主要包括仪器展宽、 多普勒展宽、 范德瓦尔斯展宽、 共振展宽、 自然展宽、 斯塔克展宽。 谱线轮廓的数学描述为福格特函数(Voigt), 通常是展宽机制相关的线型函数的卷积, 具体包括高斯函数(Gaussian)和洛伦兹函数(Lorentzian)。 一般而言, 高斯函数有仪器展宽和多普勒展宽, 其余的展宽为洛伦兹函数[4, 5]。
多普勒展宽是由自发辐射的粒子相对于探测器的热运动而形成的多普勒效应, 辐射出光子的波长发生变化。 中性粒子通常服从麦克斯韦速度分布, 谱线的多普勒展宽函数的半高全宽(full width at half maxima, FWHM)表示为
式(1)中, Tg为气体温度(K), M为粒子的摩尔质量(g· mol-1)。
范德瓦尔斯展宽是由不同种类的中性粒子与自发辐射粒子之间的碰撞引起的, 且它们之间不会发生共振跃迁, 则其展宽的FWHM为
式(2)中, ν rp是辐射粒子与碰撞粒子的相对速度, Ep是碰撞粒子允许的第一激发态能级, Np是碰撞粒子数密度,
共振展宽是由同种粒子之间的碰撞产生的谱线加宽, 碰撞粒子的初态可以通过跃迁方式到达高能级和低能级。 一般情况, 碰撞过程对辐射粒子产生影响的跃迁能级有三个, 分别是g→ l, g→ u和l→ u, 其FWHM为
式(3)中, 下标g、 l、 u分别代表基态、 低能级、 高能级, n为对应粒子数密度, g为对应能级的简并度, f为振子强度[11]。
自然展宽是量子力学中的不确定性原理在跃迁能级上的体现, 从而导致谱线的加宽FWHM
$w_{\mathrm{N}}=\frac{\lambda_{\mathrm{ul}}^{2}}{2 \pi c}\left(\sum_{n<u} A_{u n}+\sum_{n<l} A_{l n}\right)$(4)
斯塔克展宽是由于辐射粒子受到周围带电粒子的库伦相互作用而产生的谱线分裂现象。 在等离子体中, 带电粒子的库伦相互作用的有效作用距离受德拜半径控制。 电子和离子对谱线都具有斯塔克展宽作用, 相对速度更快的电子一般占据着主导作用。 这使得谱线线型呈现洛伦兹函数, 但是离子的静电相互作用会导致谱线中心位置出现凹坑。 氢原子Hβ 谱线受凹坑的影响较小, 而且斯塔展宽的FWHM与电子温度的关联性很小。
在机器学习中, 模型训练的数据集是最基础的数据之一。 一般常用实验方法得到大量的原始数据作为训练数据集。 然而, 在放电等离子体中, 一方面, 等离子体特征参数难以做到宽范围的调控; 另一方面, 等离子体诊断技术也会受到诊断原理、 实验设备、 数据处理等因素的限制和不确定性。 为了获得大量机器学习所需的原子谱线数据集, 提出利用仿真实验方法模拟计算出理论上的原子特征谱线, 这得益于较为完善的光谱理论模型。 以空气放电等离子体为例, 利用Hβ 谱线的斯塔克展宽确定电子密度, 各类展宽的FWHMs与等离子体参数之间的关系参考Laux等的工作[11]。 通过设定气体温度、 电子密度、 仪器展宽FWHM参数, 获得Hβ 线型函数的高斯部分
和洛伦兹部分
将wG和wL代入到Voigt函数中, 计算出对应的等离子体状态下(电子密度和气体温度)的Hβ 谱线
式(7)中, λ c为Hβ 谱线中心波长486.13 nm。 气体温度作为谱线的重要输入参数, 常用双原子分子的转动温度表征气体温度, 其测量的实验误差通常约为10%。
首先介绍基于最小二乘拟合的光谱诊断方法, 然后介绍基于随机森林的光谱诊断方法, 最后对两种方法进行了比较。
如图1所示, 首先利用光谱仪测量激光器或者低气压灯的特征谱线, 通过洛伦兹函数拟合确定仪器展宽wI。 然后, 利用双原子分子的发射光谱确定转动温度, 在满足一定条件下可以近似等于气体温度, 分别计算出多普勒展宽wD、 范德瓦尔斯展宽wvan、 共振展宽wR。 通过式(5)可以确定谱线展宽中高斯部分wG。 其次, 利用光谱仪获取Hβ 实验谱线并对其进行预处理, 采用Levenberg-Marquardt算法对谱线的离散数据进行福格特函数的拟合, 拟合参数包括基底偏移量、 中心波长、 谱线强度、 高斯宽度和洛伦兹宽度, 其中输入并固定高斯宽度wG参数。 最后, 基于非线性的最小二乘法获取到最佳的wL。 利用式(6), 将wL减去wvan和wR, 得到wS。
 | 图1 基于Levenberg-Marquardt算法的斯塔克展宽法Fig.1 Levenberg-Marquardt algorithm-based Stark broadening method |
随机森林(random forest)是一种集成机器学习算法, 它通过构建多个决策树来进行分类或回归任务[12]。 它的主要思想是通过组合多个弱学习器(决策树)的预测结果, 得到一个更强大、 更稳定的预测模型。 随机森林通过随机采样和随机特征选择的方式引入随机性, 减少了模型的方差, 提高了泛化能力。 同时, 由于是基于多个决策树的综合结果, 对于异常值和噪声具有较好的鲁棒性, 可解释性强。 随机森林的回归模型如图2所示, 使用该学习算法进行回归的主要步骤如下:
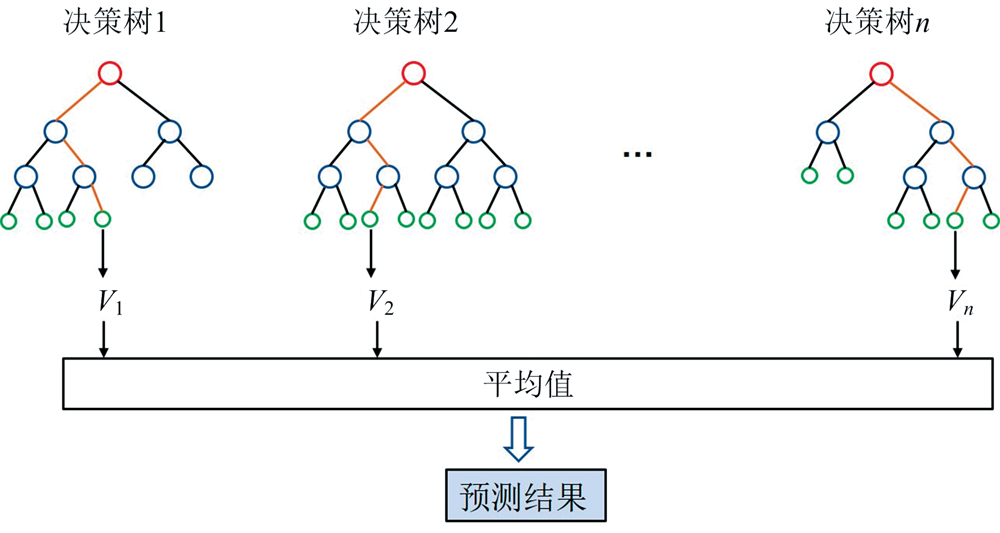 | 图2 随机森林回归模型Fig.2 Random forest regression model |
(1)数据采样: 对原始训练数据集自助采样(bootstrap sampling)生成多个训练集, 每个训练集的样本数量与原始数据集相同, 但可能存在重复的样本。
(2)决策树构建: 对于每个采样的训练集, 使用决策树算法构建一个决策树模型。 决策树的构建过程通常使用特征随机选择, 即在每个节点处, 随机选择一部分特征作为候选特征, 并根据信息增益、 增益率、 基尼指数等评估指标选择最佳的特征来划分节点。
(3)预测结果融合: 当有新的样本需要进行预测时, 随机森林中的每个决策树都会进行独立的预测, 取平均值作为最终预测结果。
光谱数据由模型仿真实验生成。 考察气体温度Tg=1 200 K, 电子密度ne在1× 1013~1× 1015 cm-3范围内均匀随机选择, 生成495组光谱。 将每组光谱数据作为一个样本, 包含2 000个采样点, 构成2 000× 1维的特征向量。 考虑到实验测得的气体温度一般存在10%左右的误差, 这里通过向仿真实验中的参数气体温度Tg引入随机偏差, 服从-10%~10%的均匀分布, 模拟实验中可能存在的测量误差和系统误差。 仿真实验生成的含有偏差的光谱共24 750组, 每组谱线强度I(i)与对应电子密度
使用Matlab 2022b软件中“ TreeBagger” 函数构建随机森林回归模型。 随机森林的最小叶节点样本数和决策树的个数是需要优化的两个重要参数。 选择2、 5、 10、 20、 50、 100六种不同的最小叶节点样本数, 利用数据集对随机森林回归模型进行训练, 获得的均方误差随决策树数量的变化如图3所示。 当最小叶节点样本数为2, 决策树个数为200时, 模型预测结果达到最小均方误差, 即最优的预测效果。 因此, 设定模型参数最小叶节点样本数为2, 决策树个数为200。
 | 图3 随机森林回归模型使用不同的最小叶节点数获得的均方误差随决策树数量的变化Fig.3 The mean square error of random forest regression model with different minimum number of leaf nodes varies with the number of decision trees |
使用含有-10%~10%均匀偏差的光谱训练数据集对模型进行训练, 然后利用训练后的模型对不含偏差、 含偏差± 2%、 ± 4%、 ± 6%、 ± 8%、 ± 10%生成的3120组光谱分别进行电子密度ne的预测。 根据式(8)计算出预测值与真实值的相对误差
式(8)中, nP为预测电子密度, nT为真实电子密度, 得到平均相对误差和标准差如表1所示。 模型预测结果与精准预测(预测完全正确)的对比如图4所示(为增强图4的可读性, 只随机选取了50个样本绘制预测结果)。 由图4和表1相对误差计算结果表明, 当原子谱线所对应的气体温度偏差越大, 模型对电子密度的预测结果与真实值的偏差越大。 虽然电子密度的范围相差两个数量级(1× 1013~1× 1015 cm-3), 但模型的预测结果与真实值之间的平均相对误差均小于3%。 这表明随机森林模型对含(10%偏差的光谱具有一定的鲁棒性和较强的抗噪性能。
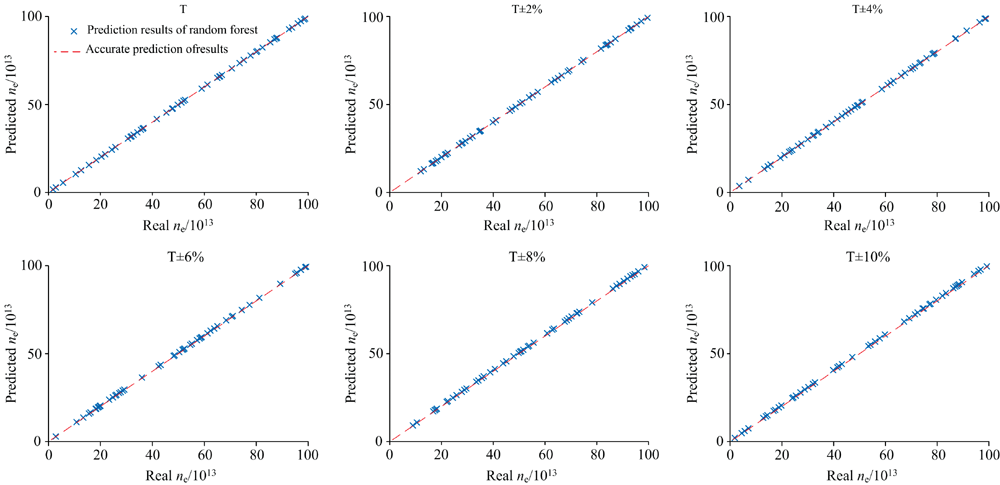 | 图4 随机森林模型对包含不同偏差的光谱预测的电子密度结果(为增加图的可读性, 每组仅随机选取了50个样本, 绘制模型预测结果)Fig.4 Prediction of electron density by random forest for spectra containing different deviations (In order to improve the readability of the graph, only 50 samples are randomly selected in each group to draw the model prediction results) |
| 表1 随机森林回归模型对含不同温度偏差的光谱的预测结果 Table 1 Prediction results of random forest regression model for spectra with different temperature deviations |
首先, 探讨气体温度误差对最小二乘法预测精度的影响。 使用不含偏差的光谱模型生成3120组待测光谱(2.2节描述的测试集), 使用Levenberg-Marquardt算法对带有偏差的Hβ 谱线测试集进行最小二乘的拟合。 对Tg不含偏差、 含偏差± 2%、 ± 4%、 ± 6%、 ± 8%、 ± 10%生成的光谱分别进行电子密度ne的拟合计算, 计算结果与精准预测(预测完全正确)的对比如图5所示。 为增强图5的可读性, 只随机选取了50个样本绘制计算结果。 由图5可知, 光谱拟合过程中的Tg偏差越大, 最小二乘的计算误差越大, 计算结果的相对误差如表2所示。 对于不含偏差的光谱, 最小二乘法预测效果很好, 相对误差为0.01%± 0.01%, 但对含偏差较大的光谱预测效果较差, 对含偏差± 10%的光谱拟合计算的相对误差达到2.64%± 2.53%, 鲁棒性差。
 | 图5 最小二乘拟合法对包含不同偏差的光谱预测的电子密度结果(为增加图的可读性, 每组仅随机选取了50个样本, 绘制模型预测结果)Fig.5 Prediction of electron density by least squares fitting method for spectra containing different deviations (In order to improve the readability of the graph, only 50 samples are randomly selected in each group to draw the model prediction results) |
| 表2 最小二乘法和不同数据集训练的三种随机森林模型对电子密度的预测结果 Table 2 Prediction results of electron density by least square method and three random forest models trained with three different data sets |
为测试不同随机森林模型的鲁棒性和抗噪能力, 构造了三个样本数相同的训练数据集, 分别为气体温度含有-5%~5%均匀偏差、 含有-10%~10%均匀偏差和含有-15%~15%均匀偏差的光谱。 通过上述三个训练集可以分别训练得到三个模型, 分别为随机森林回归模型1、 2和3。 三个模型对电子密度的预测相对误差如表2所示, 模型预测的均方误差如图6所示。 结果表明, 最小二乘法对无偏差的光谱预测效果最好, 但当光谱所含偏差绝对值大于4%时, 随机森林模型1和2的预测效果逐渐优于最小二乘法。 当光谱所含偏差为± 10%时, 最小二乘法对电子密度的预测均方误差为9.3× 1012 cm-3, 而随机森林模型2的预测均方误差为6.5× 1012 cm-3, 小于最小二乘法。 因为在训练数据中引入了适量噪声, 使得模型更好地适应真实实验中的变化和不确定性, 从而提高模型的鲁棒性和泛化能力。 使用± 10%内偏差数据集训练的随机森林模型预测效果最佳, 优于± 5%内偏差训练模型。 针对本实验中等离子体Hβ 光谱数据, 在0~± 10%偏差范围内, 随机森林模型加入的气体温度偏差(噪声)范围越大, 模型预测效果越好, 但当引入太大的噪声会降低模型的预测性能, 如图6所示± 15%内偏差光谱数据集训练模型预测效果最差。 说明在模型训练过程中加入适量噪声可以提高模型的鲁棒性和抗噪性能。
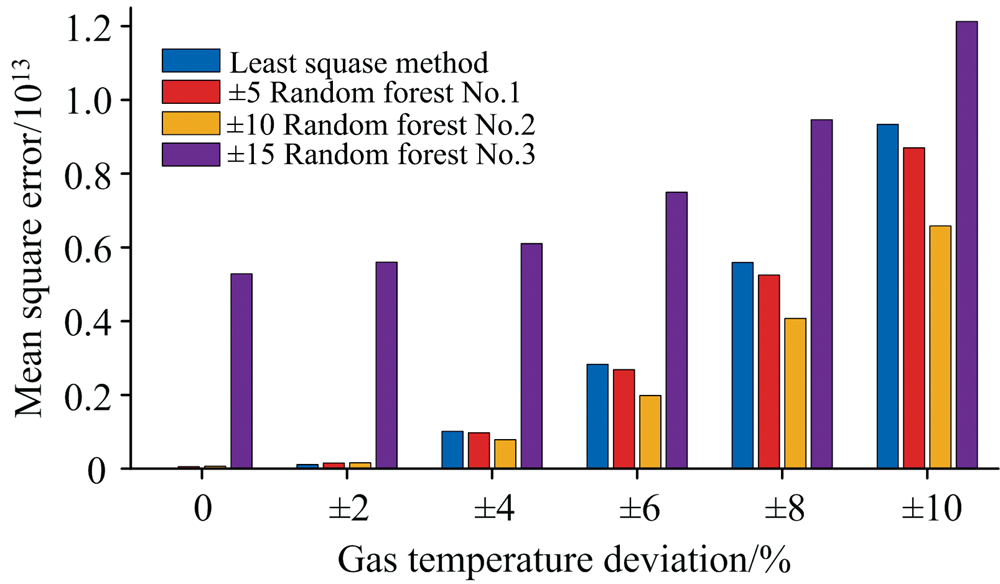 | 图6 最小二乘法和三种不同数据集训练的随机森林模型对含不同偏差的光谱的预测均方误差Fig.6 Prediction mean square error of spectra with different biases by least square method and random forest model trained with two different data sets |
此外, 训练好的随机森林回归模型在光谱诊断速度上远快于最小二乘法。 本研究所使用的计算机CPU处理器为Intel(R) Xeon(R) Gold 6258R, 主频2.70 GHz, 28核。 在Matlab 2022b软件中, 使用最小二乘法对一个等离子体光谱数据进行诊断, 预测电子密度的平均时间为22.75 s, 而使用训练好的随机森林回归模型2对一个谱线进行分析所花费的平均时间只有0.20 s。 因此, 随机森林模型可以对等离子体发射光谱进行实时的诊断。
提出了基于随机森林的机器学习与基于发射光谱的斯塔克展宽法相结合的诊断放电等离子体中的电子密度方法。 相较于传统最小二乘拟合方法, 该方法可以减小温度参数诊断的实验误差对电子密度的影响, 具有良好的鲁棒性和抗噪性。 在机器学习与等离子体诊断技术相结合方法的研究可总结如下: (1)针对实验中难以获取宽范围的等离子体参数及其原子特征谱线、 实验诊断误差等问题, 提出从等离子体光谱理论出发, 利用谱线展宽模型仿真计算出不同放电下的Hβ 原子特征谱线数据集, 并将其作为机器学习所需的训练集; (2)在机器学习模型中, 随机森林回归模型预测电子密度的均方误差相对最小, 其与真实值之间的误差小于传统的最小二乘法; (3)在Hβ 光谱数据集中, 引入气体温度的偏差在0~10%之间的结果优于最小二乘法, 而当偏差为15%时, 电子密度的预测结果变差; (4)训练好的随机森林模型分析谱线所需的时间远小于最小二乘法拟合所需的时间, 可以提供实时在线的电子密度诊断需求。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|