









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于近红外光谱的小麦成分检测仪
[毛立宇1, 2  , 宾斌
, 宾斌1, * , 张洪明2, * , 吕波2, 3, * , 龚学余1 , 尹相辉1 , 沈永才4 , 符佳2 , 王福地2 , 胡奎5 , 孙波2 , 范玉2 , 曾超2 , 计华健2, 3 , 林子超2, 3 ]
, 宾斌, 张洪明, 吕波, 龚学余|
|


作者简介: 毛立宇, 1997年生,南华大学电气工程学院硕士研究生 e-mail: 1106096173@qq.com
当前较为传统和普遍的谷物成分和品质检测方法主要是传统分离式、 人工检测, 传统检测方法的主要问题是耗费时间长效率低, 无法实现快速检测。 近红外(NIR, 波长范围: 780~2 500 nm)光谱分析技术具有适用样品范围广、 定量测量精度高、 检测时间极短, 分析效率高, 无损检测, 不污染环境、 操作简单、 可以实现现场快检或在线检测等优点, 广泛的应用于谷物和粮食品质的在线或快速检测。 目前现有的近红外谷物检测仪器一般能检测谷物少数成分的结果, 但结构复杂、 价格昂贵。 且由于不同季节不同地区谷物的差异导致模型适用性差, 难以在基层谷物收购、 加工和流通环节推广应用。 针对这些问题, 设计了一款基于近红外光谱分析的小麦品质检测仪。 采用Python上位机来控制近红外光谱仪, 通过设定和修改采集参数集成控制检测仪三个舵机以及重量传感器, 实现光谱采集, 并对光谱数据进行预处理, 代入模型计算得到目标样品的理化指标。 通过主成分分析(PCA)处理去除异常值, 后经过递推平均滤波、 标准正态变换(SNV)等预处理, 再经过竞争自适应重加权采样(CARS)特征筛选后利用偏最小二乘回归(PLS)得到最优模型。 测试结果表明, 该系统能够长时间稳定运行, 并有效降低了杂散光、 样品均匀性等因素带来的误差。 并可实现一台机器对不同地区不同季节的小麦的水分、 湿面筋、 白度和容重指标的检测, 可以满足谷物收购与储存等方面的需求。
, BIN Bin, ZHANG Hong-ming, LÜ Bo, GONG Xue-yuCurrently, the traditional measuring methods of grain quality are mainly the traditional separation and manual inspection, which take a long time and have low efficiency. Near Infrared (NIR, 780~2 500 nm) spectral analysis technology has the advantages of a wide range of applicable samples, high accuracy of quantitative measurement, high measurement efficiency, and non-destructive testing, which is widely used in agriculture online or rapid measurement. Currently, the existing NIR instruments measuring grain quality are expensive, which prevents a wider application of this kind of device. Moreover, the predicting model is limited in applicability due to the differences ingrains in different seasons and regions. To solve these problems, in this study, a new type of NIR spectrometer system is developed to measure wheat quality. The system uses a control system developed with Python. By setting and modifying the acquisition parameters, the three steering gears and weight sensors are integrated to control the spectra data acquisition. The spectral data are preprocessed and substituted into the model to calculate the quality parameters of the target wheat samples. The principal component analysis (PCA) method removes the outlier's spectral data. Then, the selected spectral data are preprocessed by recursive mean filtering and standard normal transformation (SNV). Finally, the optimized model is obtained with the partial least squares regression (PLS) method after competitive adaptive reweighting sampling (CARS) wavelength selection. The prediction model is currently developed for moisture, wet gluten, and whiteness of wheat. The results show that this model can effectively reduce the error caused by stray light, sample uniformity, and other effective factors. The developed NIR spectrometer system can satisfy the requirements of grain acquisition and storage.
我国是一个农业大国, 每年的粮食总产量巨大, 粮食的安全储存一直以来都是国家极为重视的问题[1], 因此实现粮食质量品质的有效检测势在必行。 近红外(near infrared, NIR, 波长范围: 780~2 500 nm)光谱分析技术是在线快速检测方法的翘楚, 可测的样品范围广、 可以实现精度很高的定量测量、 无损检测, 不污染环境、 检测时间极短, 分析效率高, 操作简单、 可以实现现场快检或在线检测, 广泛的应用于粮食收储时的检测[2, 3, 4, 5, 6, 7]。
近红外吸收光谱, 其波段主要是含氢原子团(N— H、 O— H、 C— H)的伸缩振动的倍频及组合频[8, 9, 10, 11], 当分子受到红外线照射时, 对应频率的原子团就会被激发产生共振, 从而产生对应的吸收光谱[8, 9, 10, 11]。 分子振动的非谐振性使分子振动从基态向高能跃迁时产生可见/近红外光谱, 通过测量物质吸收可见/近红外光能量大小, 可以反应被测物质的特征[11, 12]。
目前有很多国内外学者致力于测量谷物样品中的水分、 湿面筋、 粒色、 蛋白质、 淀粉、 脂肪等各种指标的研究。 陈峰等运用近红外光谱分析技术, 成功的建立了预测小麦水分、 蛋白质含量和硬度等指标的模型, 模型具有较高的决定系数和较低的标准偏差, 证明了近红外光谱技术可以用于小麦品质的测试[13]。 苏鹏飞等利用近红外光谱分析技术, 成功的建立了曲粮大麦、 小麦以及豌豆水分的快速分析模型[14]。 张玉荣等建立了一套基于BP神经网络的近红外光谱小麦水分预测模型[15]。 朱虹等通过ZX-888型近红外分析仪, 完成了小麦水分含量快速检测的研究[16]。 除了水分指标, 徐璐璐等分析了不同近红外模型在小麦湿面筋检测中的应用, 实验结果表明, 3种校正模型都取得较好的预测效果, 证明了近红外在小麦湿面筋检测中的可行性[17]。 Delwiche等以单粒法对小麦粒色进行鉴别, 采用偏最小二乘回归(partial least squares, PLS)和MLR方法建立回归模型, 可以很好的对不同粒色的小麦样品进行鉴别[18]。 Li和Liang等提出了模型集群分析的概念, 并讨论了基于MPA(模型集群分析)思想下的变量选择和模型评估的应用。 提出, 在进行模型建立之前, 应首先进行特征变量选择, 以提高模型的准确性和可解释性[19]。 郑峰等采用了子模型遍历统计方法来识别和剔除小麦样品中的异常数据。 通过剔除这些异常样本数据, 可以有效降低模型的预测误差, 提高预测结果的准确性[20]。
本研究利用近红外光谱技术设计了一款可同时检测小麦水分、 湿面筋、 白度的近红外检测仪, 并加入容重模块实现小麦容重的测量, 本检测仪器突破了市面上检测仪价格昂贵的缺点, 并创新性的建立了小麦白度这一检测指标。 同时在建模方面对比了不同预处理组合的建模结果[21], 以及剔除异常样本的必要性。
近红外谷物成分质检仪概念图如图1所示。 该系统包括光谱仪、 舵机模块、 24 V电源、 卤素灯、 容重模块、 可编程恒压恒流电源。 光谱仪的采集波段为580~1 100 nm。 舵机由Python和16路舵机控制器控制, 并利用可编程恒压恒流电源和24 V电源提供6 V的电压。 卤素灯也是利用可编程恒压恒流电源和24 V电源供电, 提供恒流电源, 最大输出电压60 V, 最大输出电流24 A, 最大输出功率1 440 W。 该容重模块由变送器、 重量传感器和容重桶组成, 测量一定体积小麦的质量, 精度为千分之一克, 换算可得到小麦的容重。
 | 图1 近红外谷物成分检测仪概念图 1: 光谱仪; 2: 变送器; 3: 舵机控制器; 4: 可编程恒压恒流电源; 5: 24 V电源; 6: 卤素灯; 7: 重量传感器; 8: 容重桶Fig.1 Concept diagram of near infrared grain component detector 1: Spectrometer; 2: Transmitter; 3: Steering gear controller; 4: Programmable constant voltage constant current power supply; 5: 24 V power supply; 6: Halogen lamp; 7: Weight sensor; 8: Density bottle |
本研究中采用了波长观测范围为580~1 100 nm的光纤光谱仪进行透射光谱数据采集。 之所以本文选择580~1 100 nm光谱仪进行数据采集, 主要是考虑到设备整体制造成本和之后的市场应用的竞争力。 在580~1 100 nm这个波段, 可以采用成本较低的硅传感器进行光谱数据探测, 而1 100~2 500 nm波段光谱信号则需要采用成本高昂的铟镓砷传感器进行探测。 由于样品在580~700和1 000~1 100 nm波段吸收度较高, 最终采集的透射信号噪声相对较大, 不适合用于建模分析。 因此, 通过本研究发现, 700~1 000 nm波动较为适合用于小麦透射光谱建模分析。
此光谱仪由CCD传感器加上32bits RISC微控制器组成, 拥有较为精简的光路和电路架构。 光谱仪采用固定光栅角度的交叉CT光路结构, 系统中无运动或转动光学部件, 增强了系统的抗震性与抗撞击性。 此外, 所用光谱仪的波长分辨率为0.3 nm, 波长准确度为± 0.05 nm, 波长重复度± 0.05 nm, 可以较好地满足本研究中测量小麦样品光谱的需求。 为了降低整体系统的成本以提升推广可行性, 本光谱仪采用了非制冷CCD探测器。 因此, 在样品测试中采用每次采集样品前采集背景光谱的方法来降低环境温度变化带来CCD探测器效率的变化。 本研究所用光谱仪输入端为标准的 SMA905光纤接口, 便于开展光学调试与系统装配。 光谱仪可以通过MiniUSB或UART串口与计算机或STM32单片机系统连接, 以实现光谱仪数据采集控制与光谱数据传输。
系统软件是基于Python环境开发的。 当系统通过USB和RS485连接光谱仪、 舵机和重量传感器时, 在串口工具栏下拉框中选择正确的串口。 软件界面状态指示灯亮绿色且串口连接成功时, 表示光谱仪、 舵机、 重量传感器连接成功。 在开始检测前, 可通过点击设置按钮对配置文件进行更改, 其中包括光谱积分时间、 扫描次数、 谷物模型的加权系数、 光谱预处理方法的选择等。 其中预处理方法有三次样条插值(Spline), 平滑, 求导(Savitzky-Golay一阶或二阶导数、 差分一阶或二阶导数)、 信号校正[多元散射校正MSC、 标准正态变量变换(standard normal variate transform, SNV)、 去趋势校正DT]、 标准化(均值中心化、 标准化)等。 准备好配置文件后, 在漏斗中加入适量谷物, 点击界面的开始按钮, Windows控制系统开始读取配置文件, 光谱仪按配置文件参数采集背景光谱。 随后Windows系统控制舵机转动, 上封板打开, 谷物下落至光源与光谱仪位置, 光谱仪开始采集谷物的透射光谱, 每采集完一次舵机转动一次, 采集十次谷物的透射光谱数据后做主成分分析(principal component analysis, PCA)处理剔除异常光谱并求平均光谱, 以消除谷物的不均匀性带来的误差。 计算样品的吸收光谱, 并进行预处理, 预处理结束后, 代入到小麦模型, 得到小麦的水分、 湿面筋、 白度等检验指标, 通过容重模块得到的谷物质量, 然后利用其质量除以容重桶容积得到容重结果。 软件工作流程如图2所示。
 | 图2 软件工作流程图Fig.2 Software flow chart |
为了提升系统模型的代表性, 从安徽省、 河南省、 河北省、 甘肃省、 浙江省、 江苏省、 四川省等地方收集小麦样品, 分别收集两个季节的样品, 每个季节获取65份, 共130份。 将收集到样本密封冷藏保存, 防止腐坏。 在采集其真实成分指标时, 先置于实验室环境下2 h, 使样本温度升至常温, 排除采集过程中样本温度的变化对检测结果的影响。
采用由上海青浦绿洲检测仪器有限公司生产的谷物水分测定仪(LDS-AG)测量小麦水分指标作为真实值; 采用由杭州大吉光电仪器有限公司生产的面筋数量和质量测定仪(MJ-IIC)测量小麦的湿面筋度作为真实值; 采用由上海力辰西仪器科技有限公司生产的便携式白度仪(WSB-1)采集小麦的白度作为真实值。 每个样本重复测定三次取其平均值, 如图3所示, (a)为水分含量分布图、 (b)为湿面筋含量分布图、 (c)为白度分布图。
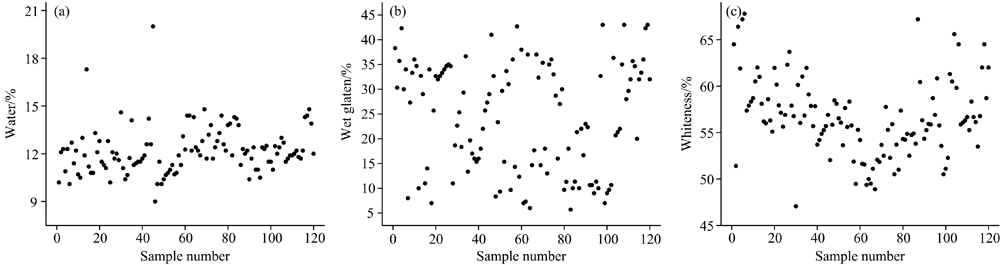 | 图3 小麦真实成分含量分布 (a): 水分含量分布; (b): 湿面筋含量分布; (c): 白度分布Fig.3 Distributions of true components in wheat (a): Water content; (b): Wet gluten content; (c): Whiteness |
完成样本成分指标采集后, 进入近红外光谱的动态采集过程, 将冷藏的小麦样本取出, 置于实验室环境下2 h, 使样本温度升至常温, 排除光谱采集过程中样本温度的变化对检测结果的影响。 开启近红外谷物成分质检仪样机, 将小麦倒入, 进行光谱采集。 在对小麦光谱采集过程中, 对小麦背景光谱采集一次, 透射光谱采集10次, 然后对这10次透射光谱做PCA处理再求平均值, 最后计算出吸收光谱。 原始吸收光谱如图4(a)所示。
吸收光谱计算公式为[22]
式(1)中: A为吸收光谱; B为背景光谱; T为透射光谱。
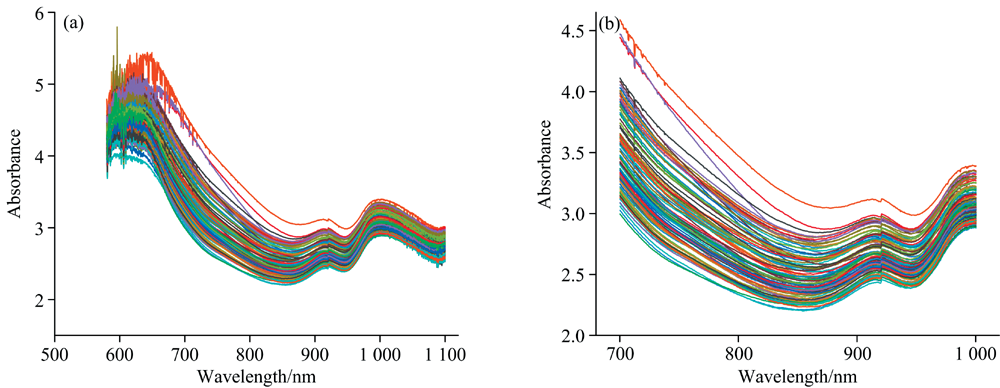 | 图4 小麦原始吸收光谱和700~1 000 nm原始吸收光谱 (a): 原始吸收光谱图; (b): 700~1 000 nm原始吸收光谱Fig.4 Original absorption spectra of wheat and 700~1 000 nm original absorption spectra (a): Original absorption spectrum; (b): Original absorption spectrum in the range of 700~1 000 nm |
在580~700和1 000~1 100 nm波长范围信号噪声比较大, 已经无法通过预处理方法来消除, 而这种高噪声会影响模型的预测精度以及稳定性, 为了避免高噪声的影响, 只截取700~1 000 nm的光谱做建模分析。 700~1 000 nm波段的原始吸收光谱如图4(b)所示。
在获得小麦近红外光谱数据和真实理化指标后, 用浓度梯度法, 将130份样本划分为100个作为训练集, 30个作为预测集。 训练集和预测集理化指标的最大值、 最小值、 平均值、 标准差、 方差如表1所示。
| 表1 样本集理化指标 Table 1 Physical and chemical indexes of sample sets |
在建模或预测分析过程中需要对样本数据的有效性进行判定, 识别出异常数据并及时予以剔除, 从而提高近红外定量分析结果的可靠性。 无论用漫反射方式还是用透射方式, 小麦样品颗粒之间的空隙不可能完全相同, 所以无法保证获得的吸收光谱的一致性。 如果小麦样品颗粒间隙过大或者样品中含有其他杂质(如秸秆或石子等), 采集到光谱就会偏离小麦颗粒的真实吸收光谱, 也就是产生了异常光谱。 为了保证获得的吸收光谱数据的稳定性与可靠性, 需要对所获得的原始光谱数据进行筛选。 主成分分析(principal component analysis, PCA)是一种常用的数据分析方法。 PCA通过线性变换将原始数据变换为一组各维度线性无关的表示, 可用于提取数据的主要特征分量, 常用于高维数据的降维。 通过对原始光谱数据集进行降维处理, 可以快速发现数据集中的异常光谱数据。 因此采用PCA的方法对原始光谱进行筛选, 以达到去除异常光谱数据的目的, 处理之后的光谱如图5所示。
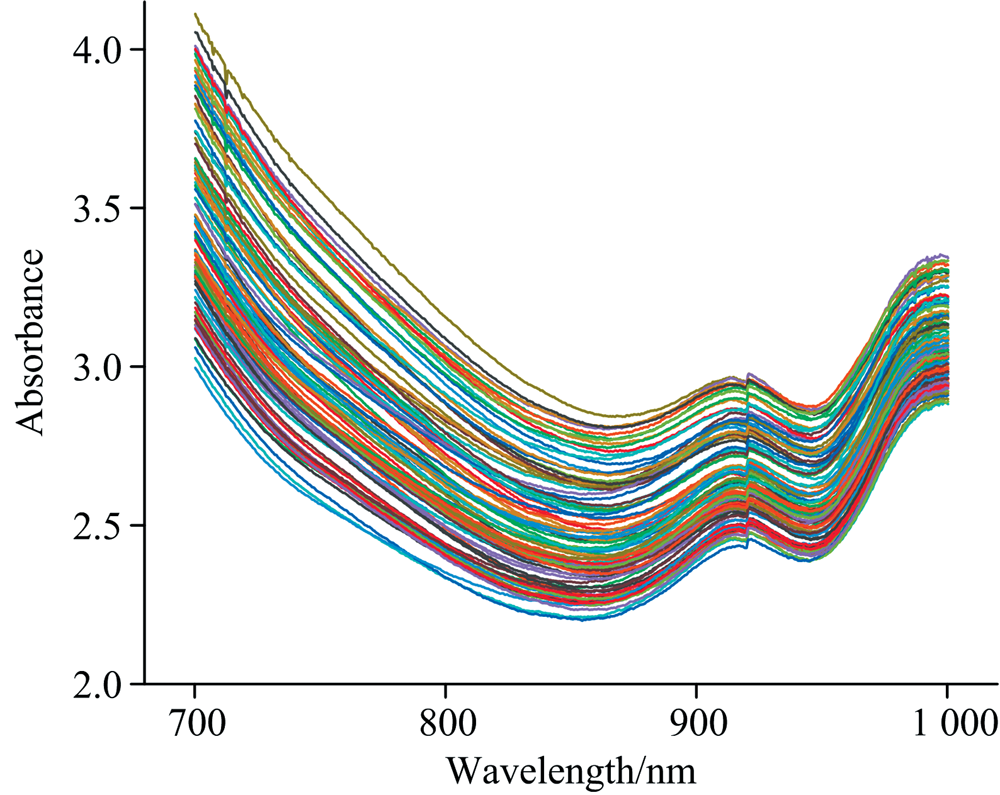 | 图5 剔除离群值后的700~1 000 nm原始吸收光谱Fig.5 Original absorption spectra after eliminating outliers in the region of 700~1 000 nm |
在小麦样本的光谱分析中, 常常会遇到杂散光、 噪声和基线漂移等干扰因素, 这些因素会对最后的定量和定性分析结果造成不良影响。 因此, 在建立模型之前, 通常需要对原始光谱进行预处理[23]。
尝试过多种预处理方法。 其中Savitzky-Golay平滑和递推平均滤波法可以降低光谱的噪声提高信噪比, Savitzky-Golay平滑的特点是在滤除噪声的同时可以确保信号的形状、宽度不变, 递推平均滤波法的特点是能很好的抑制周期性信号。 求导(Savitzky-Golay一阶)能够消除基线漂移, 并提高光谱分辨率。 多元散射校正MSC和标准正态变量变换 SNV可以去除散射光影响, 对信号进行校正, 两者的区别在于MSC是对样本集进行处理, SNV是对单个样本进行处理。 下文以水分含量利用递推平均滤波法、 SNV这种预处理组合为例详细阐述。
由于光谱具有周期性的噪声, 采用递推平均滤波法对其进行降噪处理。 递推平均滤波(又称滑动平均滤波法), 对周期性干扰有良好的抑制作用, 平滑度高, 适用于高频振荡的系统。 光谱滤波前后效果对比如图6(a)所示。 标准正态变换(standard normal variate transformation, SNV)光谱处理方法主要用于固体颗粒近红外光谱。 不同地区不同季节产的小麦颗粒大小具有差异性, 不同的粒径会对颗粒表面的散射和光程的变化等产生影响, 导致光谱数据不具有普遍适用性。 将平滑后的光谱再经过SNV预处理, 得到的光谱如图6(b)。
 | 图6 预处理之后的光谱 (a): 光谱滤波前后对比; (b): SNV处理后的吸收光谱Fig.6 Preprocessed spectra (a): Comparison of spectra before and after filtering; (b): Absorption spectra after SNV treatment |
由图6(a)可见, 在经过递推平均滤波法之后, 光谱得到一定效果的降噪处理。 从图6(b)可以观察出, 通过进行SNV处理后, 光谱之间的差异明显缩小, 从而消除个体样品由于颗粒粒径大小等因素导致的差异, 使得具有相同样品性质的光谱更加趋于一致。
每个近红外光谱谱线既带有丰富的样品理化信息也带有与目标无关的干扰信息, 在建模之前筛选有效特征波长, 可以调高模型的准确性。 不同物质成分的官能团(如O— H, C— H等)在吸光度谱中可能表现出一些典型的吸收峰, 这些峰对应于某些波长范围内的较强吸收[21]。 然而, 具体的吸收峰位置可能会受到小麦具体样品理化指标的影响而有所差异。 竞争自适应重加权采样(competitive adaptive reweighted sampling, CARS)算法可以识别和提取与特定化学键和官能团相关的光谱特征。 通过对小麦样品进行CARS光谱分析, 可以获得一系列特定波长的光谱信号。 并且CARS算法选择PLS模型交互验证均方根误差(RMSECV)最小的子集中的波长作为特征波长。 利用这些波长建模便可以得到RMSECV最小的水分、 湿面筋、 白度模型, 以提高模型预测的准确性。 通过CARS处理, 水分从916个波长点中筛选出了85个、 湿面筋筛选出52个、 白度筛选出96个特征波长点。 筛选出的波长点如图7所示, 其中红色短线表述三个模型分别选取的特征波长。
 | 图7 小麦样品典型吸光度光谱 红色短线标注位置为(a)水分、 (b)湿面筋、 (c)白度建模所优选的特征波长位置Fig.7 Characteristic wavelengths selected from absorbance spectra of wheat sample The red line indicates the selected wavelength for (a) moisture, (b) wet gluten, and (c) whiteness modelling |
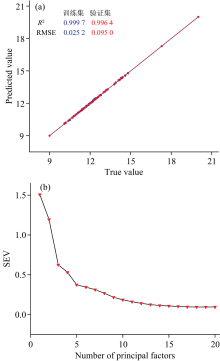
偏最小二乘回归综合了多元线性回归、 主成分分析和典型相关分析的优点, 使其成为建模过程中更优的选择。 将通过PCA处理之后剩下的95个训练集样本, 利用The Unscrambler对样本进行PLSR建模分析。 图8(a)是水分模型预测值与真实值对比图。 模型主因子数的选择一般是依据验证标准误差(SEV), 通常选择最小SEV值对应的因子数作为主因子数。 由图8(b)可知, 水分含量模型选择19作为模型的主因子数。
 | 图8 建模结果 (a): 水分模型预测值vs真实值图; (b): 主因子数与SEV关系Fig.8 The modeling results (a): Moisture model predicted value vs. true value; (b): Relationship between principal factor number and SEV |
分析模型可靠性的指标一般为
校正标准误差SEC计算公式为[22]
式(2)中: d为本校正模型的自由度, d等于n-k为模型变量数, n为校正样品数量;
SEC是评估校正集所有样品的模型预测值与参考值之间差异的标准偏差, 代表模型的整个残余误差。 通常, 随着模型变量数k的增加, SEC会下降。
验证标准误差SEV计算公式为[22]
式(3)中: dv为所有v个验证样品用到的参考值的总数;
SEV是用于评估验证集所有样品的模型预测值与参考值之间差异的标准偏差。 SEV越小, 表明模型的预测能力就越强。 通常, SEV大于SEC。
相关系数R2计算公式为[22]
式(4)中: yi为第i个样本的真实值;
越大, 校正模型对参考值解释得越好, 模型拟合也就越好。 R2取值范围为0~1。 在建立模型时, R2越接近1越好。
在得到这些模型之后, 对预测集样本进行同样的预处理操作, 然后进行预测, 以此来检验模型的可靠程度。 以水分为例, 预测集样本很好的分散在回归线两侧, 说明水分真实值与预测值之间吻合度很高, 达到实际应用需求。 图9(a)是预测集水分含量的预测结果。
 | 图9 水分含量预测结果 (a): 水分含量预测集样本预测结果; (b): 水分含量预测误差Fig.9 The predicted results of the model for water content (a): Prediction value vs true value; (b): Prediction error |
根据建模指标显示, 光谱与小麦水分指标有较强的相关性, 预测相关系数(R2)达到了0.997 8, 预测标准误差(RMSEP)为0.067 3。 水分模型的预测精度为: 约68%的样本预测值与真实值的偏差在± 0.038%内, 约95%的预测偏差在± 0.128%以内。 由图9(b)可以看出, 小麦水分含量预测误差分布较为集中, 有个别误差较大的离散点, 分析其原因可能是样机因为长时间运行发热导致采集的光谱出现波动。
采用和水分一样的处理流程, 得到湿面筋和白度的模型, 湿面筋和白度的预测图和预测误差图分别如图10所示, 其中(a)是湿面筋含量预测集样本预测结果, (b)是白度预测集样本预测结果, (c)是湿面筋含量预测误差图, (d)是白度预测误差图。
 | 图10 小麦湿面筋和白度模型预测结果 (a): 湿面筋含量预测集样本预测结果图; (b): 白度预测集样本预测结果; (c): 湿面筋含量预测误差图图; (d): 白度预测误差图Fig.10 Prediction results of wheat wet gluten and whiteness (a): Wet gluten content prediction results; (b): Prediction results of whiteness content; (c): Prediction error of wet gluten content; (d): Whiteness prediction error chart |
根据建模指标显示, 光谱与小麦湿面筋与白度指标也有较强的相关性, 湿面筋的R2达到了0.974 3, RMSEP为1.813 1, 湿面筋模型的预测精度为: 约68%的样本预测值与真实值的偏差在± 1.500%内, 约95%的预测偏差在± 3.640%以内。 白度的R2达到了0.956 4, RMSEP为0.709 9, 白度模型的预测精度为: 约68%的样本预测值与真实值的偏差在± 0.530内, 约95%的预测偏差在± 1.119以内。
由图10(c)可以看出, 小麦湿面筋含量预测误差分布在两端的比中间段误差大, 其原因可能是边界效应的影响, 是模型在边界处存在一定波动。 由图10(d)可以看出小麦白度误差分布与水分误差分布相似, 所以应是同一原因造成个别点误差较大。 针对这些原因, 后续将对光谱仪添加恒温控制系统, 增加模型的样本量, 进一步提高模型的稳定性和预测准确性。
近红外光谱分析过程中, 通常都是“ 尝试地” 使用预处理方法, 再根据建模结果选择最好方法。 预处理的选择做了多种组合的尝试, 具体结果如表3所示。
| 表3 模型不同预处理方法比较 Table 3 Comparison of modeling results with different pretreatment methods |
由表3可以看出, 经过递推平均滤波法、 SNV预处理后, SEC与SEP分别为0.025 2和0.095 0, 两者相差为0.069 8且均接近0,
小麦真实容重指标的采集同样是用上海青浦绿洲检测仪器有限公司生产的谷物水分测定仪(LDS-AG), 该仪器具有测定小麦容重的功能。 在采集小麦真实容重之后, 利用本研究设计的检测仪样机采集小麦预测值。 经对比表明, 误差在± 3.9 g· L-1以内, 符合国家标准。 真实值与预测值比对如图11所示。
 | 图11 容重预测结果Fig.11 Volume weight prediction results |
设计了一款面向小麦成分检测的近红外光谱检测仪。 通过优化样本筛选和预处理方法, 建立了小麦样品的水分、 湿面筋度和白度的分析模型。 建立的小麦水分预测模型的R2=0.997 8, RMSEP=0.067 3。 与苏鹏飞[14]等建立的小麦水分预测模型R2=0.994 2, RMSEP=0.209相比, 本研究建立模型的相关性和预测偏差均更为优异。 本研究中所建立的湿面筋预测模型的R2=0.974 3, RMSEP=1.813 1。 与徐璐璐[17]等建立的小麦湿面筋预测模型R2=0.960 9, RMSEP=1.112相比, 本研究的湿面筋预测模型相关性更好, 但是RMSEP数值略大。 因此, 后续需要通过进一步提升湿面筋参考值测量准确性和优化建模算法来降低湿面筋预测模型的RMSEP。 本研究建立的白度预测模型R2=0.956 4, RMSEP=0.709 9。 水分、 湿面筋、 白度预测模型均拥有很好的相关性, 且误差皆在国标允许范围之内。 容重指标的误差在± 3.9 g· L-1以内符合国家± 4 g· L-1以内的标准。 检测方法和模型的适用性和可推广性是验证其价值的关键。 因此, 在选取样品的时候, 特意选择了国内不同产地的小麦样品, 也特意选择了不同年份收获的小麦样品, 以保证所建的模型具有较好的适用性。 在未来具体应用中, 可能会由于一些实际样品的特性与建模样品的特性差异较为明显而产生预测偏差。 因此, 在后期实际使用过程中还需要对本方法进行一定的数据验证。 如果测量偏差超出正常范围, 还需要根据所测量小麦样品的特性而适当采集特定的光谱数据来进行样本光谱数据补充, 以进一步提升模型预测的准确性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|