
{kind=link}
{kind=link}
{kind=link}
基于改进K均值聚类的光谱重建训练样本选择研究
[刘振1, *  , 刘莉
, 刘莉2, * , 樊硕2 , 赵安然2 , 刘思鲁2 ]
, 刘莉, 樊硕|
|


作者简介: 刘 振, 1983年生,曲阜师范大学传媒学院副教授 e-mail: zhen@whu.edu.cn;刘 莉,女, 1997年生,曲阜师范大学工学院硕士研究生 e-mail: 441943747@qq.com;刘 振,刘 莉:共同第一作者
光谱反射率重建过程中, 训练样本的选择方法及样本容量与重建精度密切相关, 寻找一种高效的训练样本选择方法是光谱重建的目标之一。 K均值聚类计算复杂度小, 计算效率高, 但因聚类初始值选择的随机性, 以及离群点的影响致使聚类结果不稳定, 进而影响光谱重建的精度。 基于此, 提出了一种改进K均值聚类的训练样本选择方法。 首先, 将训练样本集的几何中心作为聚类中心的初始值; 其次, 基于高斯函数构建样本空间分布概率密度函数, 并以欧几里德(欧式)距离作为其他聚类中心的度量依据; 最后, 在训练样本集中, 基于簇内平方差度量光谱反射率样本间的相似度, 将每个聚类子集中与中心距离最近的样本作为训练样本。 为验证该方法的有效性, 通过主成分分析法进行光谱重建。 实验结果表明, 所提的方法相较于传统的方法, 光谱重建精度有一定的提高, 重建光谱的平均均方根误差小于4%, CIE DE2000色差小于3.756 7。 提出的改进的K均值聚类的训练样本选择方法, 能够一定程度上提高了光谱重建精度, 基本满足复制再现图像的要求。
LIU Zhen and LIU Li: joint first authors
Developing an efficient training sample selection method is one of the goals of spectral reflectance reconstruction. In spectral reflectance reconstruction, the training set selection method and sample capacity are strongly related to the reconstruction accuracy. The accuracy of the spectral reconstruction is affected by the unstable clustering results due to the randomness of the starting value selection and the outliers. K-means clustering has low computing complexity and great computational efficiency. Based on this, this paper proposes an improved K-means clustering training sample selection method. Firstly, the geometric center of the training sample set is used as the initial value of the clustering center; secondly, the probability density function of the spatial distribution of the samples is constructed based on the Gaussian function, and the Euclidean (Euclidean) distance is used as the measure of other clustering centers; finally, the similarity between the spectral reflectance samples in the training sample set is measured based on the intra-cluster squared difference, and the sample with the closest distance to the center in each clustering subset is used as the training samples are used to verify the effectiveness of the method. The spectral reconstruction was performed by principal component analysis. The experimental results show that the proposed method has been improved significantly compared with the traditional method, the average root-mean-square error of the reconstructed spectra is less than 4%, and the CIEDE2000 color difference is less than 3.756 7. The improved training sample selection method of K-mean clustering proposed in this paper can improve the spectral reconstruction accuracy to some extent and meet the requirements of reproducing the reproduced images.
在图像复制过程中, 同色异谱现象容易造成不同光照环境或设备物体颜色外貌的差异, 为了保证颜色传递过程中的准确性, 多光谱技术被广泛应用于图像再现。 多光谱技术主要通过对多通道成像信号进行光谱重建获得光谱反射率, 常用光谱重建方法有, 直接重建[1, 2]; 插值重建[3]和基于学习的重建[4]。 其中基于主成分分析的光谱重建算法通常采用奇异值分解和特征向量法, 通过求解光谱反射率与多光谱信息之间的转换矩阵, 重建光谱反射率[5]。
训练样本的数量与空间分布和光谱重建精度密切相关, 目前训练样本选择有诸多方法。 如Hardeberg提出基于最小条件数的训练样本选择方法[6]; Cheung与Westland基于光谱反射率之间的差异性, 提出了四种不同的样本选择方法, 样本光谱反射率离散程度最大的或离散程度最小的都可以作为初始样本[7]; Mohammadi等基于光谱反射率向量之间的距离提出聚类分析法, 在聚类训练样本子集中, 基于光谱反射率向量夹角选择每个子集中的代表样本[8]; 沈会良等提出了一种基于光谱反射率代表颜色的分布选取方法, 在非线性的宽带扫描仪和线性的窄带多光谱成像系统中都取得了良好的效果[9]; 刘振等提出了基于正交回归的光谱重建算法, 在训练样本的选择中依据子空间跟踪, 得到了与原始光谱反射率数据集相关性最大的训练样本参与光谱重建[10, 11]; 梁金星等提出了基于局部距离加权和相机响应优化的光谱重建算法, 利用伪逆方法求解光谱反射率转换矩阵, 研究了训练样本数目、 相机响应的扩展项数对光谱重建精度的影响[12, 13]; 李婵等提出了基于主成分分析的训练样本选择方法, 依据样本相似性原则选择训练样本子集, 提高了光谱重建过程中的色度和精度[14]。
训练样本构建了光谱反射率与多通道相机响应之间的转换模型, 由此, 如何根据不同训练样本集的光谱特征选择聚类数量, 以及如何减小训练样本的选择中计算量, 是目前研究亟须解决的问题。 基于上述分析, 本文提出的基于改进K均值聚类的光谱重建训练样本选择算法, 首先, 基于光谱反射率样本集的光谱特征确定聚类中心数量; 其次, 针对K均值聚类初始值的选择具有随机性的不足, 依据高斯分布函数, 均匀选择聚类中心, 使选取的光谱反射率样本子集更具有空间代表性。 本文提出的训练样本选择方法, 在光谱重建过程中期望能够提高色度精度和光谱准确度。
在图像采集中, 假设成像系统为线性传递函数, 光源的相对光谱功率分布函数为I(λ ), 物体光谱反射率为r(λ ), 相机的光谱敏感度函数为S(λ ), 系统噪声为ε , 则相机成像信号c表示为
式(1)中, λ max和λ min分别表示图像采集时最大与最小可见光谱波长。 如果忽略噪声, 将光谱反射率用离散的向量表示, 相机的光谱敏感度表示为[s1, s2, …, sm]T, 光源的光谱功率分布表示为[i1, i2, …, in]T, 物体的光谱反射率表示为[r1, r2, …, rn]T, 相机成像信号表示为[c1, c2, …, cn]T, 则式(1)可以表示为矩阵形式
式(2)中, m表示多光谱相机成像信号的通道数, n表示光谱反射率的维度。 将光谱成像系统的转换矩阵表示为L, 色块的光谱反射率向量用r表示, 即
则式(3)可简化为
则重建光谱反射率可以通过伪逆求解为
式(5)中,
将式(6)代入到式(5)中, 那么转换矩阵A可以用C的伪逆表示为
将式(7)代入式(6), 则重建光谱反射率
Hardeberg在训练样本的选择时, 首先, 选择向量模值最大的样本作为初始值
式(9)中, ‖ ‖ 表示向量的模值, rn为每一组光谱反射率对应的数值, n为光谱反射率样本集的维度。 其次, 在其余的光谱反射率向量中选择奇异值的最大值α max和最小值α min之比最小的向量, 作为挑选的第二个光谱反射率样本, 遵循这样的原则, 依次选取其他的样本
式(10)中, [r1, r2, …, ri]表示样本集中的i个对角元素, [r1, r2, …, rn]表示样本集中的n个对角元素。
Cheung与Westland基于方差最大值和最小值, 提出了4种不同的训练样本选择方法。
用Smax表示第一个光谱反射率样本选择样本集中离散程度最大的, r为光谱反射率向量,
Mohammadi利用聚类分析算法将样本集分为若干类, 根据样本数不同选择不同的聚类个数。 Mohammadi选择向量夹角最小的反射率作为每个类中最具有代表性的光谱反射率样本, 直至选出所有类中的最具有代表性的光谱反射率。 任意两个样本反射率rx和ry之间的距离可以表示为
式(12)中, 上标T表示矩阵的转置, dist(rx, ry)表示光谱反射率rx和ry间的欧式距离,
传统K均值聚类通过随机选取样本作为初始的聚类中心进行聚类, 但是每次聚类的结果不同, 从而影响光谱重建精度。 基于此, 本文提出了改进的K均值聚类算法, 从三个方面优化训练样本选择: 首先, 计算所有样本的簇内平方差, 并以此评价训练样本子集和训练样本集的相似程度, 确定聚类数目; 其次, 基于样本集的光谱特性确定聚类的初始中心, 并构建概率分布模型估算其他聚类中心; 最后, 基于高斯分布函数, 衡量所选样本子集与训练样本集的相似程度, 使选择的样本尽可能的表征训练样本集的光谱特征, 具体步骤如下:
(1)计算所有的训练样本集的均值, 将反射率均值
(2)计算训练样本集的簇内平方差(SSE)确定聚类中心数目K值的范围, 簇内平方差如式(14)
式(14)中, ri为光谱反射率样本集中的随机向量,
(3)计算样本集中的所有光谱反射率向量到质心c1的欧式距离
式(15), r1为样本集中任一光谱反射率向量, d(r1, r2)表示向量r1与c1的距离。
(4)根据高斯分布模型, 计算下一个质心c2被选中的概率
式(16)中, r表示光谱反射率样本集的任意变量, μ 表示数学期望, σ 2表示方差。
(5)依次选择j个质心, 将质心cj和反射率向量m之间的距离表示为d(xm, cj)。 计算光谱反射率向量到所有质心的距离, 并依据欧式距离将每个光谱反射率向量分配给其距离最近的质心, 每个质心关于反射率向量r的分布函数为
(6)重复上述步骤, 直到选择出K个质心。 计算每个类中反射率向量的均值, 作为新的聚类中心, 循环几次运算, 直至结果不再改变, 或达到最大的迭代次数。
(7)光谱反射率样本聚成K个类后, 计算每个类中的光谱反射率向量r与聚类中心c的欧氏距离
式(18)中, n为每个子集中的光谱反射率数目, d(r, c)表示光谱反射率向量r与聚类中心c的距离。
(8)选择每个类中的反射率向量r中离质心c欧式距离最近的样本c(i), 作为每个类中最具有代表性的光谱反射率向量
为验证本文提出的方法的有效性, 实验采用SinarbackeVolution 75 H数码后背搭载Sinar p3数码专用座机, 加载BG39和GG475宽带滤色片构建多通道宽带成像系统, 经线性校正后获取六通道图像信号。 实验采用colorchecker SG色卡, 矿物颜料色卡以及中国画丙烯酸颜料色卡作为实验样本, 在D50光源、 2° 视角条件下, 使用X-rite分光光度计在400~700 nm波段, 以10 nm为间隔均匀采样, 通过3次测量取平均值测量所有色块的光谱反射率数据。 其中, colorchecker SG色卡、 矿物颜料色卡以及中国画丙烯酸颜料色卡的奇数个作为训练样本集, 共844个, 偶数个作为测试样本, 共843个, 以检验本文算法的精确性。 并通过均方根误差(RMSE)和CIE DE2000色差评价重建光谱反射率重建精度。 均方根误差可用式(20)表示为
式(20)中, Δ r(δ i)为在δ i处实际测量的光谱反射率与重建后的光谱反射率之间的差值, n为光谱反射率的维数, 在本实验中为36维数据。 在D50光源下, CIE1931标准观察者条件下实际反射率与重建反射率的色差公式表示为
式(21)中, Δ L″表示明度差, Δ C'表示彩度差, Δ H'表示色度差。 调节校正系数KL, 权重系数SL。 为验证本文方法的有效性, 论文与Mohammadi方法、 Hardeberg方法、 Cheung& Westland方法进行了比较, 对光谱反射率样本集进行聚类分析, 在均方根误差和色差方面从最大值, 平均值和方差三个方面与其他方法相比较。 具体如下:
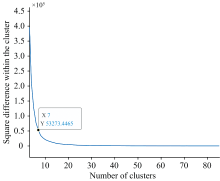
(1)计算原始光谱反射率矩阵的簇内平方差, 并绘制簇内平方差与簇数K的图像, 如图1所示。
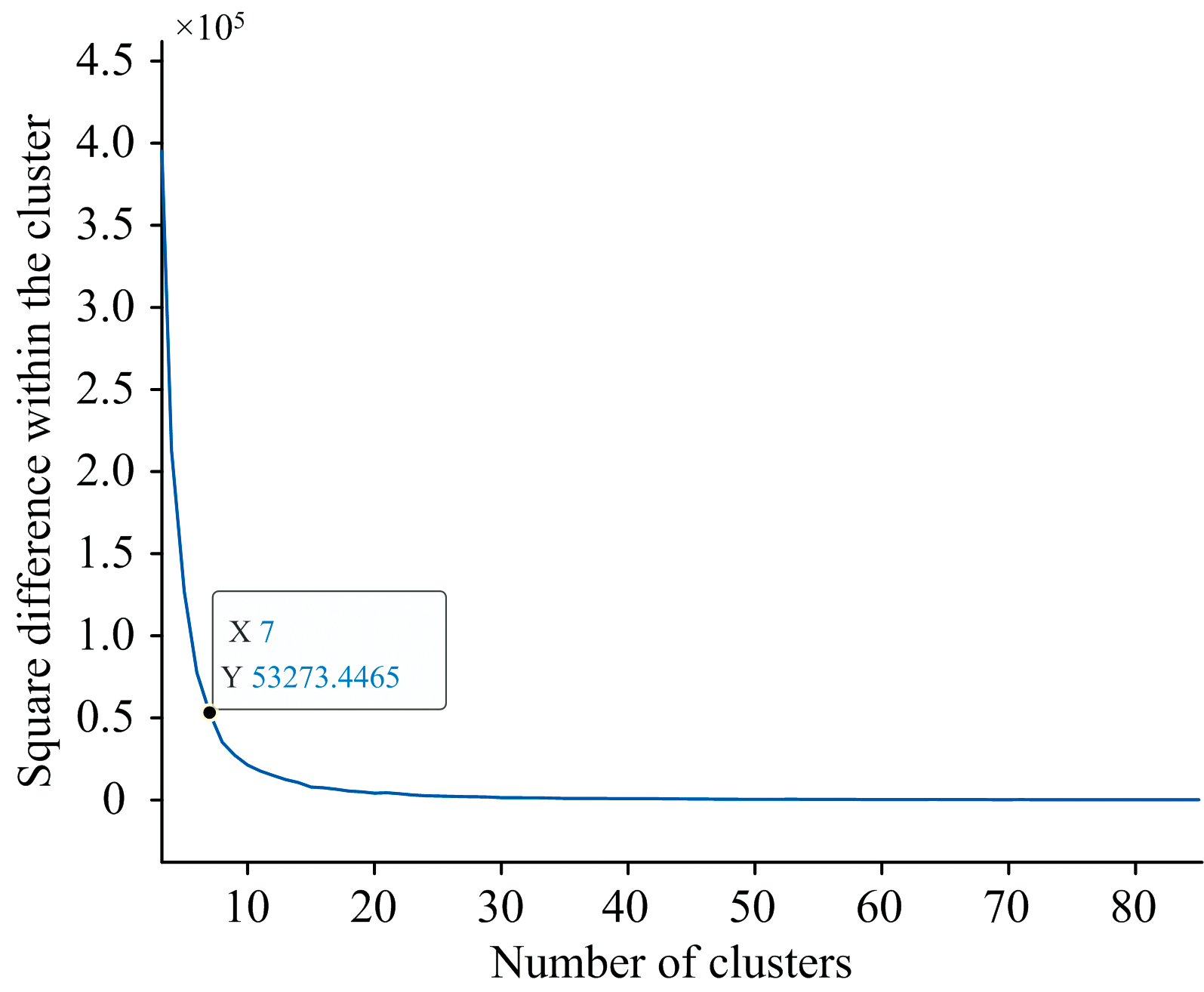 | 图1 光谱反射率数据集簇内平方差分析Fig.1 Analysis of variance within cluster of spectral reflectance data |
簇数K反映了对应簇内的光谱反射率到聚类中心的距离误差平方和, 由图1可知, 本文基于簇内平方差设置聚类数目为10~80, 光谱反射率样本数目每隔10个为一个间隔, 共8组数据。 随着K值增加, 簇内平方差值明显减小, 在K值取30时曲线变化趋于平缓。
(2)根据簇数及质心, 对训练样本集进行聚类。 聚类完成后, 选择光谱反射率训练样本, 并用主成分分析法对重建样本进行光谱反射率重建, 实验采用前6个主成分, 比较色差和均方根误差。 光谱反射率重建后均方根误差和色差如表1和表2所示。 在均方根误差方面, 计算Hardeberg方法均方根误差平均值为3.60%, Mohammadi方法4.11%, Cheung& Westland方法8.64%, 本文提出的方法3.26%, 本文提出的方法均小于Hardeberg、 Mohammadi以及Cheung等提出的方法, 光谱重建精度更高。 在色差方面, 重建的8组光谱反射率样本, 色差平均值均小于Mohammadi与Cheung等的方法, 计算所有重建样本的色差平均值, 本文提出的方法平均色差为3.103 9, Hardeberg方法为3.656 6, 色差整体平均值小于Hardeberg方法。
| 表1 聚类个数与光谱重建精度均方根误差比较 Table 1 Comparison of the number of clusters and the root-mean-square error of spectral reconstruction accuracy |
| 表2 聚类个数与光谱重建色度比较 Table 2 Comparison of the number of clusters and the color difference of spectral reconstruction |
(3)在D50光源下, 由图1可知, 当簇数K值为40时, 簇内平方差值明显减小。 把光谱反射率数据集聚为40类, 并从中选取最有代表性的光谱反射率样本, 用Hardeberg、 Mohammadi、 Cheung等提出的方法与本文提出的方法相比较。 图2是用不同方法选取40个光谱反射率样本在D50光源下的全局色度分布。 可发现, 本文提出的训练样本选择方法, 在Lab整体色度分布中较均匀, 选择的光谱反射率样本更具有颜色空间的均匀性。
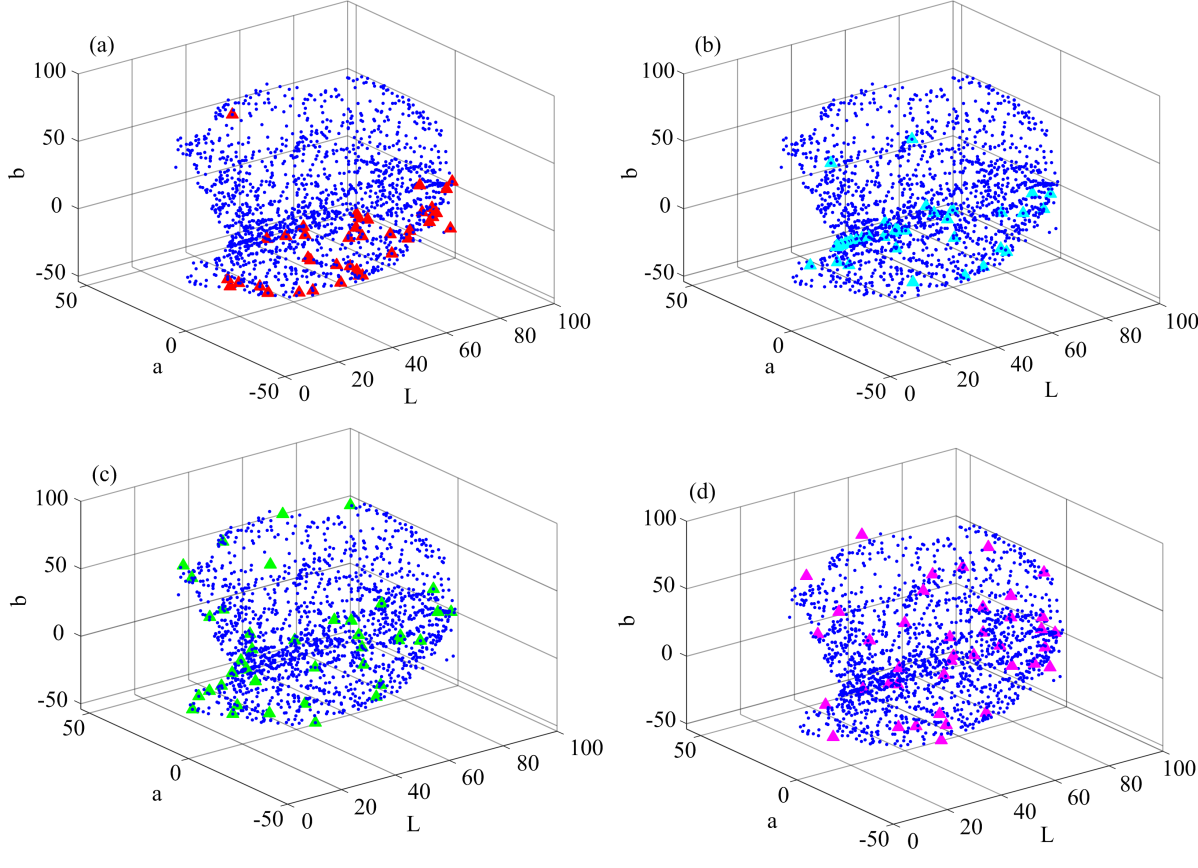 | 图2 (a)为Cheung& Westland方法、 (b)Mohammadi方法、 (c)Hardeberg方法、 (d)本文提出方法Fig.2 (a) Cheung & Westland method, (b) Mohammadi method, (c) Hardeberg method, (d) method proposed in this paper |
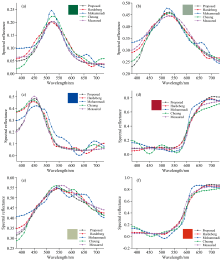
(4)为衡量光谱重建精度, 测试样本共有844个, 随机选取第25、 50、 70、 109、 275、 514个样本作为测试样本, 绘制部分色块重构的光谱反射率曲线, 如图3。 由图得, 在本文实验所用的数据中, 改进的K均值聚类方法绘制出的反射率曲线更为平滑且波动较小, Hardeberg方法与本文提出的方法与实际光谱反射率曲线最接近, 整体优于Mohammadi方法与以及Cheung等提出的方法。
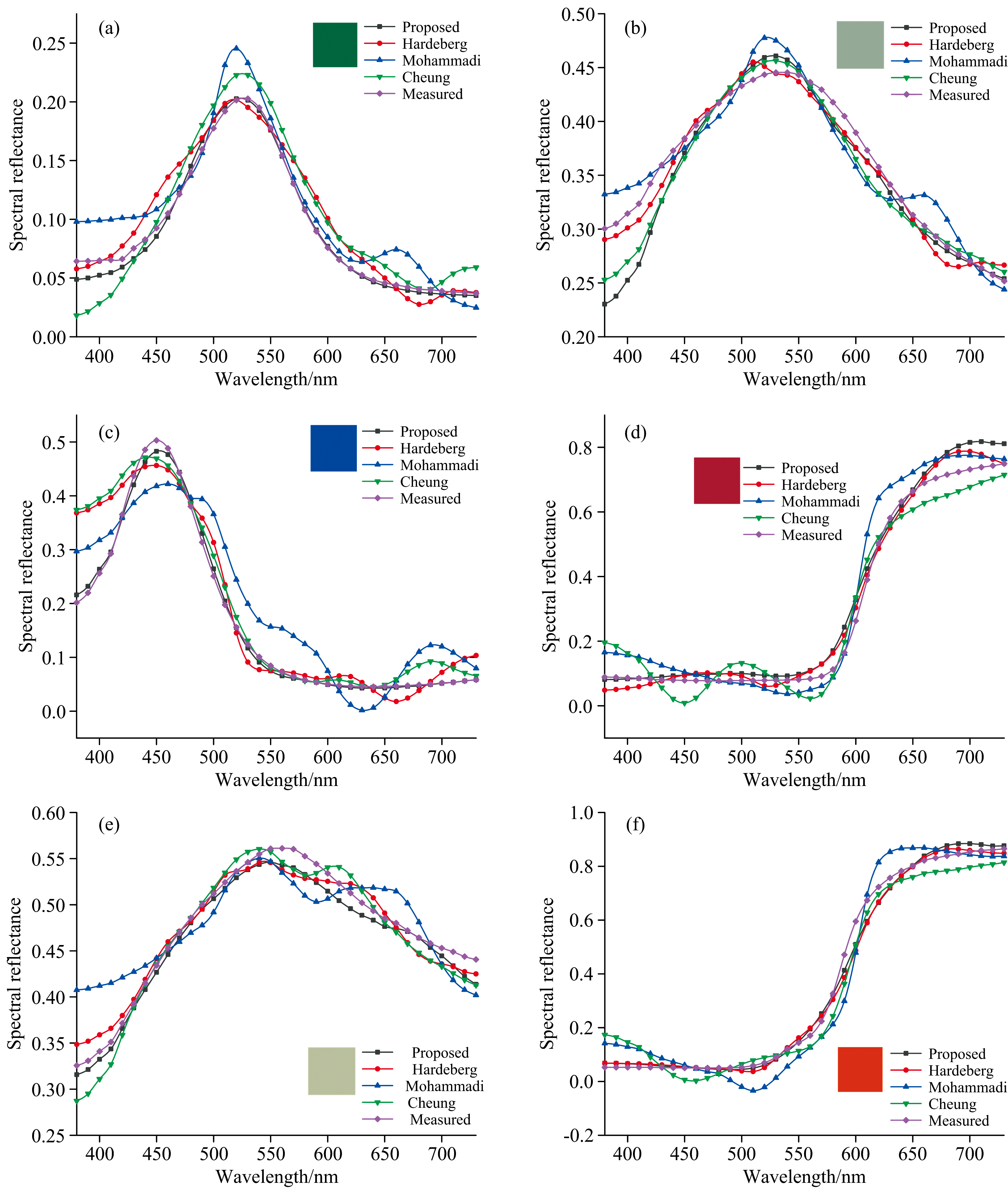 | 图3 (a)为光谱反射率第25组、 (b)第50组、 (c)第70组、 (d)第109组、 (e)第275组、 (f)第514组数据Fig.3 (a) is the spectral reflectance group 25, (b) group 50, (c) group 70, (d) group 109, (e) group 275, (f) group 514 data |
将以上数据的重建光谱反射率色差与均方根误差进行比较, 可以得出本文提出的改进的K均值聚类的训练样本选择方法, 整体光谱反射率均方根误差小于Hardeberg、 Mohammadi、 Cheung等方法, 其中光谱重建精度的平均误差不超过4.01%, 在光谱反射率重建精度方面有所提高; 色度准确性方面, 本文提出的方法, 重建的光谱反射率色差平均值和方差均小于Hardeberg、 Mohammadi、 Cheung等方法, 色差整体平均值不大于3.756 7, 减小了重建光谱反射率的色差。
提出改进的K均值聚类的训练样本选择方法, 针对目前训练样本的选择具有局限性以及相关性不强的问题进行了研究。 通过光谱反射率样本集的簇内平方差, 确定聚类数目, 依据高斯分布函数, 基于概率依次选择聚类中心, 使选择的样本具有广泛代表性与相关性参与光谱重建。 实验结果表明, 在光谱和色度指标方面, 本文提出的方法优于Mohammadi方法和其他传统方法, 能在较大程度上满足工业生产中颜色质量评估的需求。 然而, 仍有一些问题需要解决, 本文提出的方法在训练过程中相比传统方法的计算时间成本更高, 如何在样本集容量较大的情况下减少训练样本选择的计算时间, 是未来研究中的一个重要内容。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|