



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
卷积神经网络结合改进光谱处理方法用于马铃薯病害检测
[李欣庭 , 张峰, 冯洁
, 张峰, 冯洁* ]
, 张峰, 冯洁]
|
|


作者简介: 李欣庭, 女, 1993年生, 云南师范大学物理与电子信息学院博士研究生 e-mail: 707882417@qq.com
针对马铃薯早疫病不同染病时期光谱数据受到杂散光和噪声等因素的干扰, 以及波段数众多、 数据量大且谱带复杂会对光谱的定量和定性分析产生不利影响, 研究9种光谱预处理方法, 结合实验结果, 将预处理方法进行排列组合, 扩展改进为16种光谱预处理方法, 并与连续投影算法、 竞争自适应重加权算法和遗传算法3种特征波段提取方法进行组合得到64种光谱处理方法对原始光谱数据进行优化处理。 在卷积神经网络(CNN)分类模型中, 大部分经过光谱处理方法优化后的光谱数据分类精度相比原始数据的总体分类精度86.67%明显提高, 其中12种光谱处理方法的分类精度达到100%, 实现对马铃薯早疫病不同染病时期的理想分类。 为进一步对马铃薯早疫病不同染病时期进行定量分析, 将经过光谱处理方法处理后的光谱数据使用构建的CNN定量估算模型进行定量分析, 结果表明, 光谱预处理在优化数据的同时, 也会损失数据中对目标变量有用的光谱信息, 从而导致经过光谱分析方法处理后的数据结果相对于原始光谱数据的 R2和RMSE会出现下降的结果, 通过研究使用的融合光谱处理方法对原始光谱数据优化能够进一步提升模型性能, 其中基于均值中心化、 多元散射校正、 移动平均平滑相结合的光谱处理方法的CNN定量估算模型取得了最好的结果, 其 R2为1说明估算的马铃薯早疫病不同染病时期和实际值拟合程度达到100%拟合, 其RMSE仅为0.001 1, 表明马铃薯早疫病不同染病时期的估算值与真实值之间的偏差接近0, 说明该模型能够对马铃薯早疫病不同染病时期进行完美预测。 结果表明提出的CNN能够对马铃薯早疫病不同染病时期进行有效地分类检测和定量分析, 将各类预处理和特征波段提取方法按优化目的进行有效组合能够有效提高建模效果, 为农作物病害无损、 精准、 智能化检测提供理论和技术支持。
For potato early blight at different infection periods (DPP), the spectral data is interfered with by factors such as stray light, noise, etc. In addition, a large number of bands, a large amount of data and complex bands will adversely affect the quantitative and qualitative analysis of the spectrum. 9 kinds of spectral preprocessing methods are studied, combined with the experimental results, the preprocessing methods are arranged and combined, and the 16 spectral preprocessing methods are extended and improved to combine with the continuous projection algorithm, the competitive adaptive weighting algorithm and the genetic algorithm. The band extraction methods are combined to obtain 64 spectral processing methods to optimize the original spectral data. In the convolutional neural network (CNN) classification model, most of the classification accuracy after spectral processing is significantly improved compared to the unprocessed prediction classification accuracy of 86.67%, and the classification accuracy of 12 spectral processing methods is 100%, the ideal classification of potato early blight at different disease stages can be achieved. In order to further quantitatively analyze the different infection stages of potato early blight, the spectral data processed by the spectral processing method were quantitatively analyzed using the constructed CNN quantitative estimation model. The spectral information useful to the target variable in the analysis method will lead to the result that the R2 and RMSE of the data processed by the spectral analysis method will decrease compared with the original spectral data. The fusion spectral processing method used in the study can further optimize the original spectral data. Improve the performance of the model. Among them, the CNN quantitative estimation model based on the spectral processing method combined with mean centering, multivariate scattering correction, and moving average smoothing has achieved the best results. The fitting degree of the value is 100%, and its RMSE is only 0.001 1, indicating that the deviation between the estimated value and the actual value of potato early blight at different disease stages is close to 0, indicating that the model can perfectly predict potato early blight in different disease stages. The results show that the proposed CNN can perform effective classification detection and quantitative analysis of different infection periods of potato early blight, and an effective combination of various preprocessing and feature band extraction methods according to the optimization purpose can effectively improve the modeling effect, Provide theoretical and technical support for non-destructive, accurate and intelligent detection of crop diseases.
高光谱成像技术是传统成像和光谱有效结合而成的一项新技术, 包含图像信息和光谱信息[1], 能够无损检测研究对象内部和外部特性, 为农作物病害、 品质检测与分级提供了新的途径和方法[2]。 国内外的研究者开发了许多针对农作物的高光谱图像数据机器学习和光谱分析方法, 如K-最近邻算法(KNN)[3]、 BP神经网络[4]、 支持向量机(SVM)[5]、 偏最小二乘算法(PLS)[6]、 K-Means聚类算法[7]、 连续投影算法(SPA)[8]、 竞争自适应重加权算法(CARS)[9]、 遗传-偏最小二乘算法(GA-PLS)[10]、 多元散射校正(MSC)[11]、 一阶导数(D1)[12]、 二阶导数(D2)[13]、 移动平均平滑(MA)[14]等来解决数据处理问题。 尽管传统的机器学习方法在农业病害检测领域取得了很多的研究成果, 但是因为传统机器学习方法技术的局限性, 存在诊断检测耗时长、 精度低、 需要手动提取特征等问题[15], 卷积神经网络(CNN)的出现, 填补了传统机器学习方法在这些方面的不足。 CNN通过对模型输入数据进行预训练, 自动提取并不断优化特征, 能够快速处理大量数据, 相比传统机器学习方法具有更好的分类检测能力。 深度学习技术受到农业领域研究学者的广泛关注[16]。 Nzaki等通过数据增强、 加强图像特征激活等方法改善农作物病害数据集的方式, 进行CNN优化, 提高模型的性能、 能够有效地实现农作物病害诊断[17]。 Vaishnavi等基于CNN通过对棉花早期叶片病害进行识别, 并针对棉花病害识别开发了应用程序[18]; Geetharamani等针对不同类别植物叶片图像数据的病害识别, 通过CNN分类模型进行模型训练和分类, 实现了不同类别植物病害的分类[19]; 基于高光谱对物质的分析中, 利用CNN自动提取农作物光谱数据特征, 已成为农作物病害检测领域的主流方法。
针对目前对农作物病害监测领域, 检测精度低、 效率较差等问题, 本研究将基于CNN结合高光谱成像技术和光谱分析方法, 优化植物病害检测模型, 实现马铃薯病害的快速、 精准、 无损识别, 进一步提高植物病害检测领域检测方法的便捷、 经济和实用性, 为现代农业的发展提供技术支持。
在云南师范大学马铃薯种植基地选取40棵健康马铃薯植株, 在每株上部剪取一片健康叶片、 共40片。 获取光谱数据后将样本叶片接种早疫病病菌, 接种部位为叶片背面的叶脉之间, 接种量为每个叶片10 μ L, 再将叶片置于恒温恒湿光照培养箱内连续培养6 d, 期间每隔24 h采集一次高光谱图像。 选取不同染病时期: 健康、 染病2天、 4天、 6天作为样本数据。 对选取样本高光谱图像数据中每个样本随机选取10个感兴趣区域, 分别取其光谱平均反射率。 训练集和测试集比例为7∶ 3。 实验设备采用四川双利合谱的Gaia-Sorter高光谱分选仪中的Gaiarield-F-V10E型高光谱相机。 可采集256个波段, 波段范围400~1 000 nm, 其光谱分辨率为2.8 nm。 为避免实验环境和采集设备对实验结果的影响, 在进行数据采集时, 需对采集设备进行预热、 调参、 定标、 黑白校正等操作。
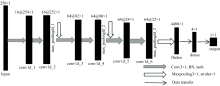
1.2.1 CNN分类模型
CNN分类模型通过卷积层提取特征, 在分类任务中, 分类算法得到的是一个决策面, 通过对比每个样本数据属于每一类的概率, 判别样本类别。 以马铃薯早疫病不同染病时期(different infection periods of potato early blight, DPP)光谱数据作为输入, 构建适用于针对病害不同染病时期识别分类的CNN分类模型。 由于光谱反射率数据是一维的, 因此本研究通过构建一维卷积神经网络实现对DPP光谱数据的识别分类。 CNN分类模型如图1所示, 输入数据为DPP光谱数据, 尺寸为256× 1(256个波段、 1个通道)。 经过多次调参测试, 最后使用6层一维卷积层(Conv1D)来提取特征值, 卷积层的卷积核个数分别为16、 16、 64、 64、 64和64, 卷积核的大小均为1, 每两层Conv1D后添加一层全局最大池化层(MaxPooling1D)来保留主要特征, 降低过拟合。 将池化尺寸大小设置为3, 输出矩阵大小为输入的三分之一, 达到减小计算量的同时解决全连接层存在的限制输入维度大小, 参数过多的问题。 每层卷积层使用双曲正切函数tanh(hyperbolic tangent function)来提高神经网络对模型的表达能力。 tanh经常被运用到多分类任务中用做激活函数。 神经网络不具有可解释性, 将卷积核和全连接的结点数取2的指数次幂。 Flatten()层作为中间层来链接卷积层和全连接层。 损失函数(Softmax loss)能够捕捉网络的特征输出与给定的期望输出之间的差异。 4个输出结点为对应4个类别, Softmax将每个特征数据匹配到概率最大的特征类别。 交叉熵损失函数(categorical crossentropy)作为模型训练的损失函数, 其刻画的是当前学习到的概率分布与实际概率分布的距离。 损失函数越小, 两个概率分布越相似。
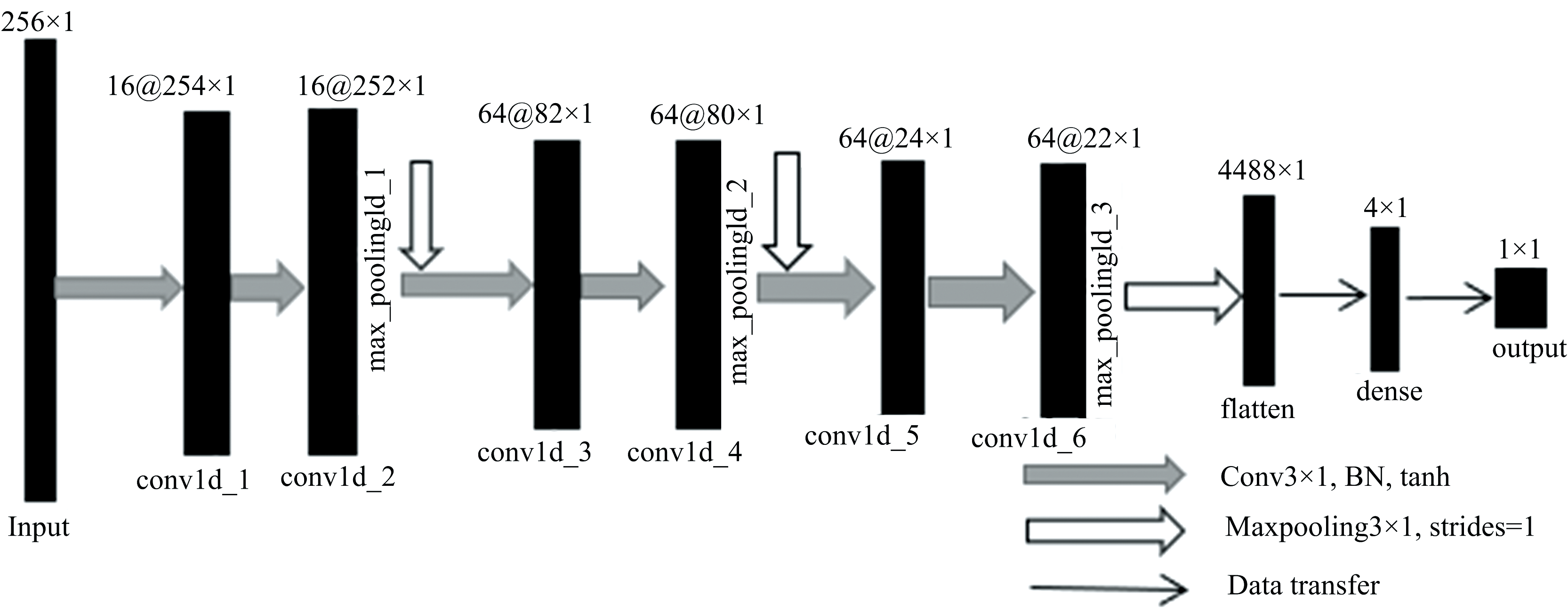 | 图1 CNN分类模型Fig.1 CNN classification model |
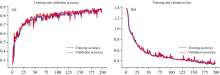
为准确评估构建CNN分类模型的稳定性和合理性, 将模型对未预处理数据识别过程中训练集和验证集的总体分类精度和损失值曲线变化过程可视化如图2(a, b)所示, 其中红色曲线为训练集结果, 蓝色曲线为验证集结果。 精度曲线中的毛刺与batch-size大小有关, batch-size越大, 毛刺越小, 曲线越平滑, 表明模型越稳定。 在训练和验证过程中精度和损失曲线存在误差和抖动现象, 但总体上随着迭代次数的增加, 精度不断提高最后趋于平缓。 图中显示训练集和验证集的精度在25次迭代以前呈急剧上升趋势, 之后趋于平稳, 损失值前期急剧下降, 最后趋于平缓直至接近于0。 当迭代次数达到200时, 精度达到86.67%, 且损失值接近0可以证明模型收敛, 同时训练集和验证集的精度曲线和损失曲线变化趋势相同值相近可知模型不存在过拟合现象, 如果继续增加迭代次数, 网络分类精度提高效果不大。
 | 图2 CNN分类模型精度和损失曲线 (a): 精度曲线; (b): 损失曲线Fig.2 CNN classification model accuracy and loss curves (a): Precision curve; (b): Loss curve |
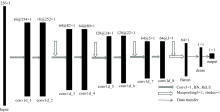
1.2.2 CNN定量估算模型
以上构建的CNN分类模型, 采用了分类思想对DPP光谱数据进行有效分类, 但无法实现进一步定量诊断。 本研究通过构建CNN定量估算模型从而对DPP 光谱数据进行定量的诊断。 不同于分类算法得到的决策面, 回归算法得到的是一个最优拟合线, 这个线条可以最好地接近数据集中的各个点。 CNN回归预测模型如图3所示, 输入数据为D1预处理后DPP光谱数据。 经过多次调参测试, 最后使用8层Conv1D来提取特征值, 卷积层的卷积核个数分别为16、 16、 64、 64、 128、 128、 64和64, 卷积核的大小均为3, 每两层Conv1D后添加一层MaxPooling1D保留主要特征, 降低过拟合。 池化尺寸大小设置为3。 为了完成回归任务, 神经网络的输出层需要被设置为一个结点, 它表示输出一条DPP光谱数据的预测结果。 研究使用均方根误差(RMSE)做输出层的损失函数, RMSE经常被用做比较模型预测值与真实值的偏差, 在此任务中, 通过不断减小损失函数的值, 进而让整个网络尽可能地去拟合真实的DPP光谱数据。 每层卷积层使用线性整流函数ReLU()作为激活函数。 最后一层深度层输出DPP光谱数据的预测值, 在RMSE损失函数的逼近下, DPP光谱数据的预测值会愈来愈趋向于真实值。 从图3可以看出回归马铃薯早疫病的真实染病时期, 使用的网络层数明显比分类时要更深。
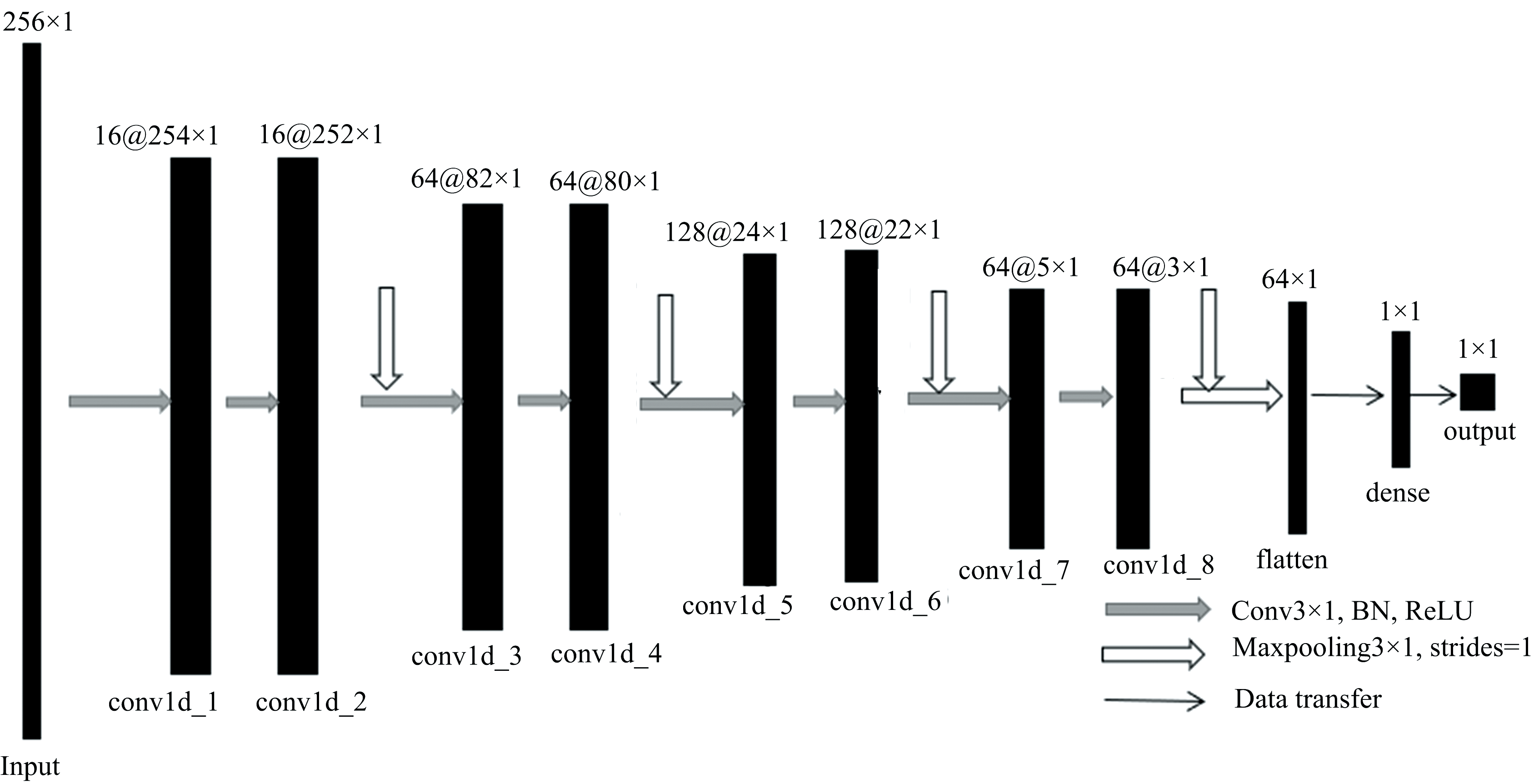 | 图3 CNN定量估算模型Fig.3 CNN quantitative estimation model |
本研究采用决定系数(R2)和均方根误差定量分析染病时期估算结果的准确率, 对构建的模型进行评估。 决定系数常常在线性回归中被用来表征有多少百分比的因变量波动被回归线描述, 是度量拟合优度的统计量, 取值范围为(0, 1), 如果R2=1则表示模型完美地预测了目标变量, 因此R2的值越接近1说明估算的DPP光谱数据和实际值拟合程度越好, 反之, 拟合程度越差。 均方根误差不仅避免了正负误差不能相加的问题而且对误差进行了平方, 加大了数值大的误差在指标中的作用, 提高了灵敏度, 用它来衡量估算的DPP光谱数据与真实值之间的偏差, 其取值越小, 表明估算准确率越高。
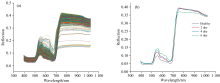
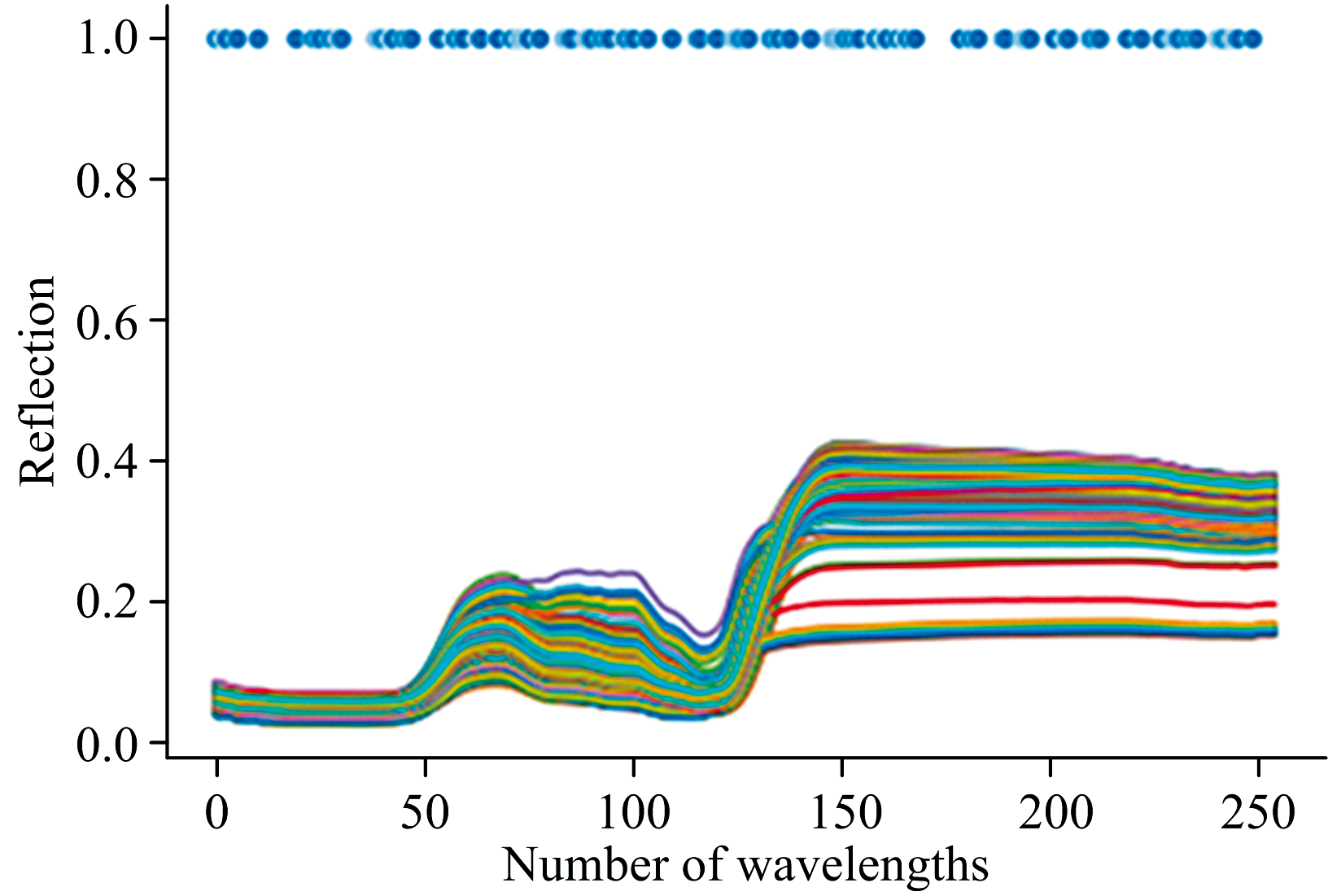
马铃薯样叶片光谱反射率曲线如图4(a)所示, DPP样本光谱大致相同, 肉眼区分难度大。 在540和750 nm附近有明显的反射峰, 680 nm附近具有明显的吸收峰。 为了利于区分DPP光谱数据的曲线变化规律, 将同一染病天数的DPP光谱数据求取平均值, 结果如图4(b)所示, 当病害发生时叶片内部元素含量将发生变化、 细胞组织遭到破坏、 叶绿素含量降低、 水分丢失, 而520~580 nm的反射峰与叶绿素含量有关、 750~1 000 nm与叶片组织细胞结构、 含水量有关, 因此不同染病时期的光谱反射率在520~580和750~1 000 mm处存在明显差异。
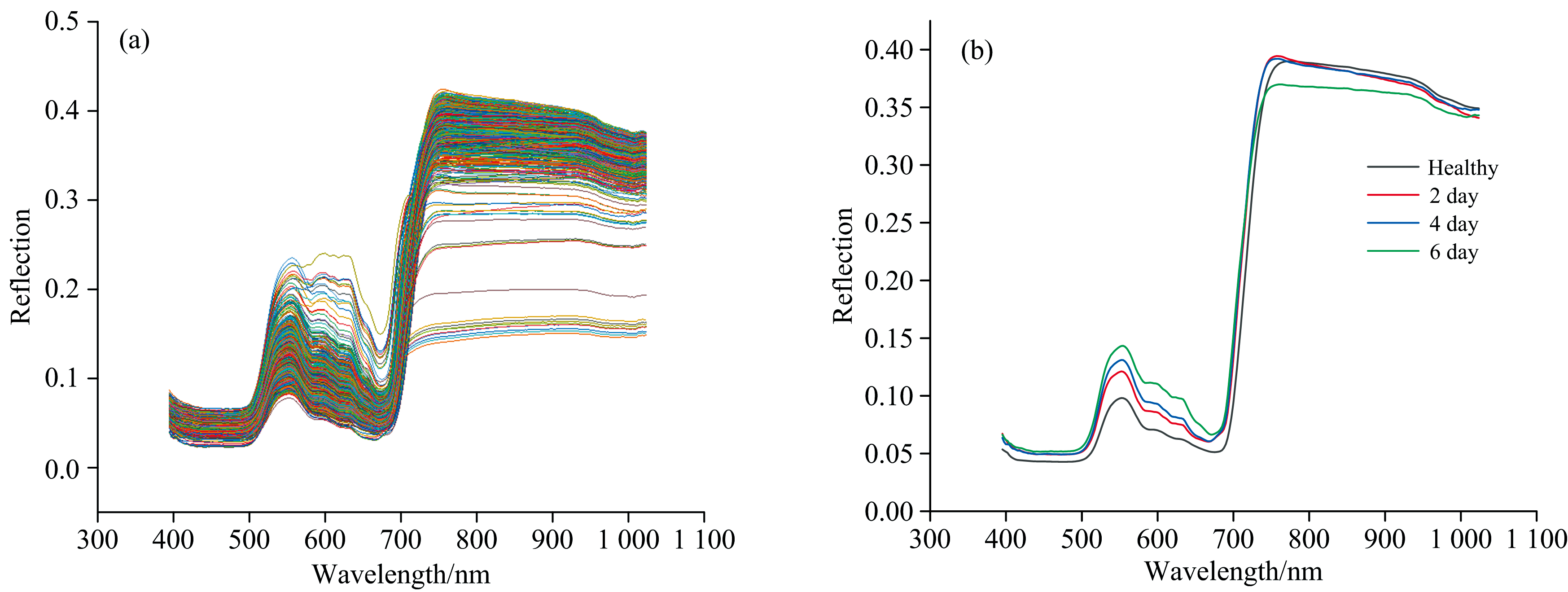 | 图4 (a)原始数据光谱图; (b)每类平均光谱反射率光谱图Fig.4 (a) Raw data spectrum; (b) Spectral graph of average spectral reflectance of each type |
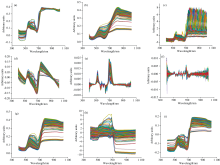
选用的9种预处理方法根据预处理的目的, 可以分为基线校正、 散射校正、 平滑处理和尺度缩放四类。 其中一阶导数(D1)、 二阶导数(D2)和趋势校正(DT)属于基线校正, 基线校正是为了扣除仪器背景或漂移对信号的影响, D1用来扣除斜线和曲线背景; D2可以提高光谱分别率; DT消除原光谱中的基线漂移, 基本消除不同采样部位、 不同样品和不同批次对光谱的影响; 多元散射校正(MSC)和标准正态变量变换(SNV)属于散射校正, 用来消除颗粒分布不均匀及颗粒大小差异产生的散射现象和光程变换对漫反射的影响以及用来消除基线漂移对光谱的影响; Savitzky-Golay平滑(SG)和移动平均平滑(MA)属于平滑处理, 对光谱曲线进行平滑, 消除光谱信号中的随机噪声, 提高样本信号的信噪比。 标准化(SS)和均值中心化(CT)属于尺度缩放, CT可以使光谱之间的差异性增大, SS能有效克服光谱数据中存在的噪声点和异常值, 解决尺度差异过大的问题。
图5(a— i)为DPP采用上文9种预处理方法处理后的光谱。 采用D1、 D2和DT处理后的光谱消除了基线和背景的干扰能够提高光谱分辨率; MSC和SNV处理后的光谱, 光谱重合度更高, 散射现象和基线漂移减弱; SG和MA平滑处理后的光谱, 光谱明显平滑, 消除毛刺, 噪声明显减弱; SS和CT处理后的光谱解决了尺度差异问题。 为验证预处理对DPP光谱数据判别结果的影响, 使用CNN分类模型对9种预处理数据和DPP光谱数据进行分类检测, 结果如表1所示, 从分类结果可以看出, 经过DT、 MSC、 D1、 D2、 SS预处理后的数据在CNN分类模型中的总体分类准确率相比RAW(未进行预处理)实验结果有不同程度的提高。 而SG、 MA、 SNV、 CT反而降低, 导致这样的结果是由于SG、 MA、 SNV、 CT在预处理的过程中会存在不同程度上破坏与目标信息变量有关的光谱信息从而导致分类精度降低。
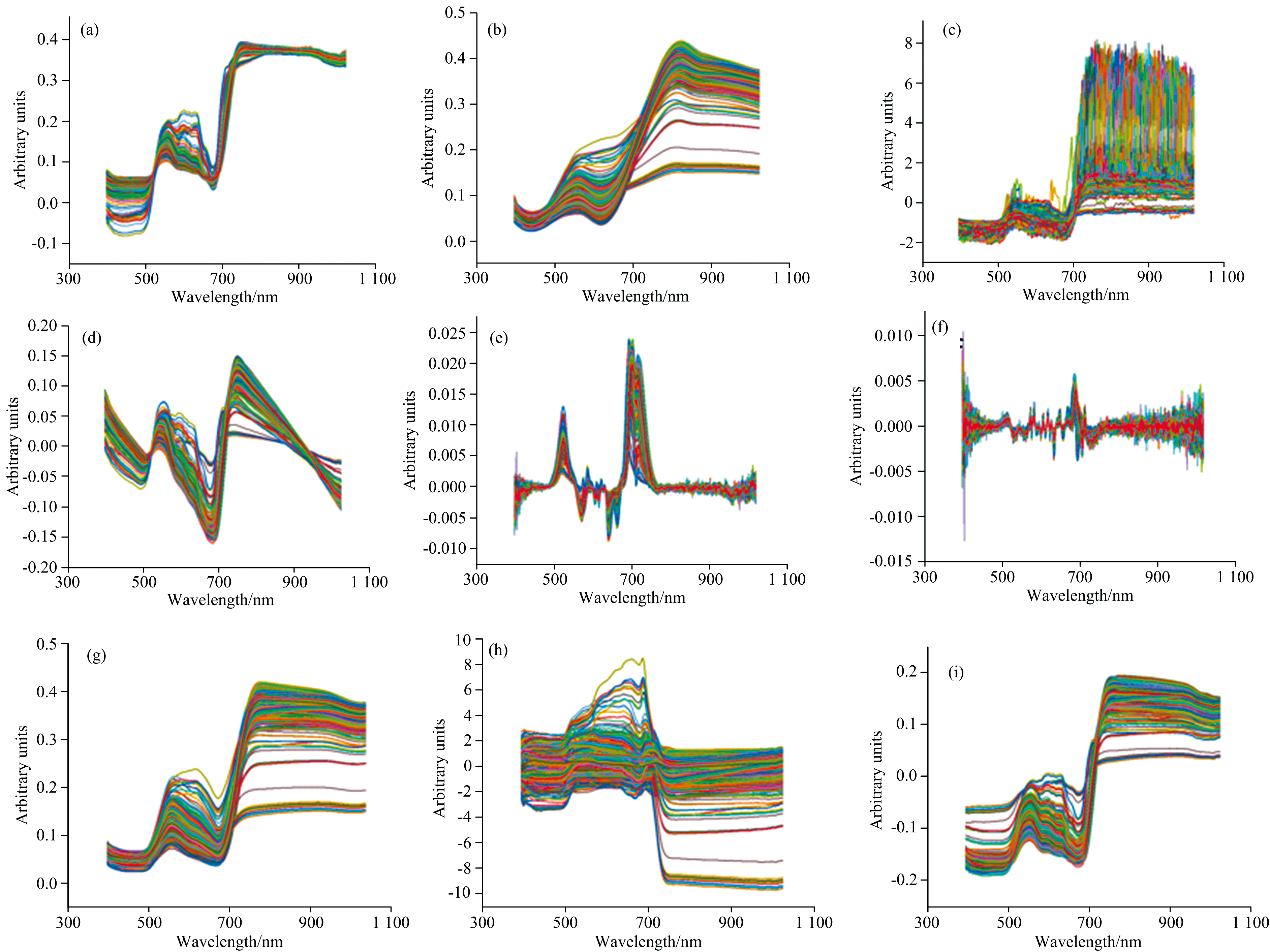 | 图5 光谱预处理结果 (a): 多元散射校正; (b): Savitzky-Golay平滑; (c): 标准正态变量变换; (d): 趋势校正; (e): 一阶导数; (f): 二阶导数; (g): 移动平均平滑; (h): 标准化; (i): 均值中心化Fig.5 Spectral preprocessing results (a): Multiple scattering correction; (b): Savitzky-Golay smooth; (c): Standard normal variable; (d): Detrend correction; (e): A derivative; (f): The second derivative; (g): Moving average smoothing; (h): Standardized; (i):!Mean centralization |
| 表1 RAW和不同预处理光谱数据在CNN分类模型中识别精度(Accuracy/%) Table 1 Identification Accuracy of RAW and different preprocessed spectral data in CNN classification model (Accuracy/%) |
由表1可知SG和MA都导致分类精度降低, 所以用剩下的3类预处理方法基线校正、 散射校正和尺度缩放进行数据预处理, 预处理方法按表2所示划分为3类进行排列组合, 得到4× 2× 2=16种预处理方法, 分别是RAW、 MSC、 SS、 D1、 D2、 DT、 MSC-SS、 D1-MSC、 D1-SS、 D2-MSC、 D2-SS、 DT-MSC、 DT-SS、 D1-MSC-SS、 D2-MSC-SS、 DT-MSC-SS。
| 表2 三类预处理方法 Table 2 Three pretreatment methods |
2.3.1 采用连续投影算法进行特征波段提取
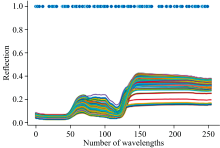
连续投影算法(SPA)从光谱信息中筛选含有最低冗余信息的特征波段组合, 使特征波段之间的共线性达到最小, 同时能够保留原始数据的绝大部分特征。 以SPA对RAW进行特征波段提取为例, 图6(a)中可以看出RMSE从28以后逐渐趋于平缓, 其中RMSE=0.1859。 之所以选择28个波长数量, 是因为RMSE相对于后面的RMSE没有太大的变化, 过多的波长参与建模会带来噪声和模型的复杂性。 图6(b)中横坐标表示的是波长, 纵坐标表示其反射率, 其中被红色方块标记的28个波段表示SPA提取的特征波段。
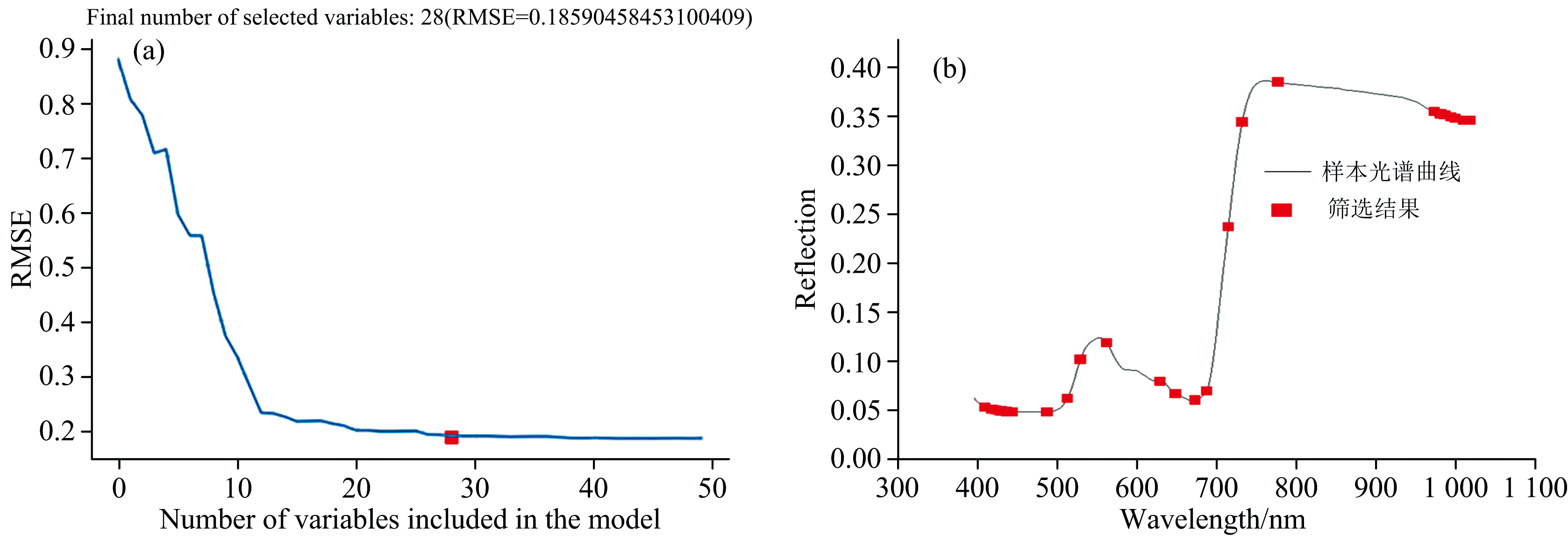 | 图6 SPA特征提取结果 (a): 不同特征波长个数与RMSE值的关系; (b): 提取的特征波长Fig.6 SPA feature extraction results (a): Relation between the number of different characteristic wavelengths and RMSE value; (b): The extracted characteristic wavelength |
2.3.2 采用竞争自适应重加权算法进行特征波段提取
竞争自适应重加权(CARS)算法能够有效地压缩数据筛选出最优的波段组合。 图7为对RAW使用CARS算法进行特征波段提取过程。 由图7(a)可知, 在进行特征波段提取的过程中随着蒙特卡罗采样次数增加, 提取的特征波段数量先急剧下降后逐渐趋于平缓。 从图7(b)看出, 当迭代次数在最佳迭代次数10之前时, RMSECV的值与迭代次数呈负相关, 在最佳迭代次数10时达到最小。 当迭代次数超过最佳迭代次数后, 尽管迭代次数的增加, 能够缓慢减少提取的波长数, 但是RMSECV的值却在快速增加, 表明在达到最佳迭代次数前进行的特征提取, 有效的淘汰了与马铃薯早疫病无关的光谱变量, 随后RMSECV值随着迭代次数的增加却快速提高, 说明在经过最佳迭代次数后增加迭代次数反而会淘汰掉与马铃薯早疫病病害有关的光谱信息使得模型的精度下降。 图7(c)中每条线代表每个光谱波段的回归系数与蒙特卡罗迭代次数的关系, 其中竖着的红线表示RMSECV值最小的位置, 红线之后RMSECV值开始增大。 根据RMSECV值最小的原则, 当迭代次数达到10次时, RMSECV的值达到最小, 通过CRAS保留了106光谱波段。
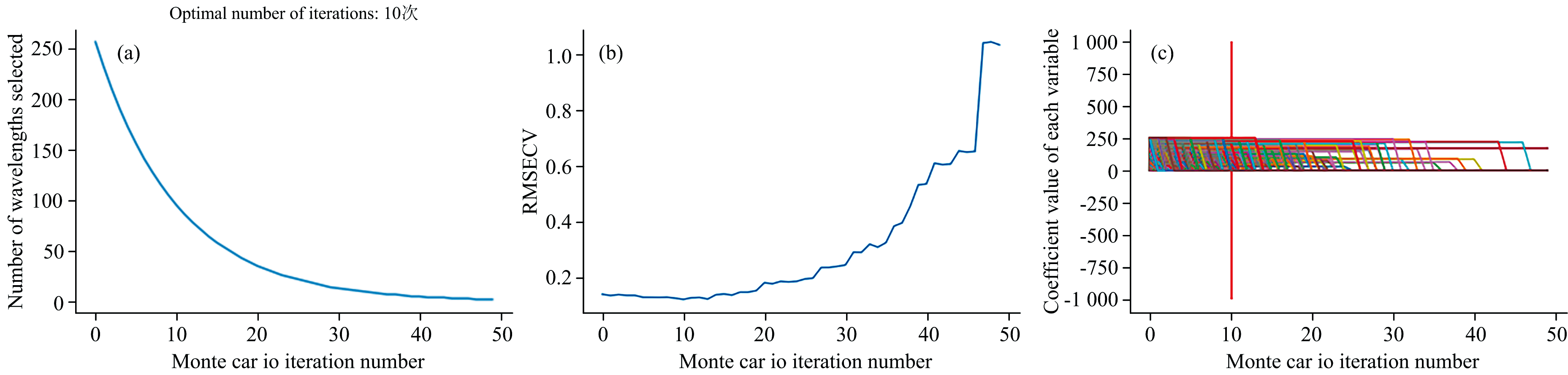 | 图7 CARS算法的波长变量筛选过程 (a): 筛选波长数与迭代次数的关系; (b): RMSECV值与迭代次数的关系; (c): 回归系数与迭代次数的关系Fig.7 Wavelength variable screening process of CARS algorithm (a): The relationship between the number of filtering wavelengths and the number of iterations; (b): Relationship between RMSECV value and number of iterations; (c): Relation between regression coefficient and iteration number |
2.3.3 采用遗传偏最小二乘算法进行特征波段提取
使用遗传偏最小二乘(GA-PLS)算法对马铃薯早疫病不同染病时期光谱数据进行特征波段筛选之前, 必须设定与其相应的参数数值。 本研究使用的GA-PLS在运算过程中需要对搜索范围进行约束, 登记变量后设置优化函数并进行交叉验证。 因为GA-PLS算法速度比较慢, 在这里只进行10个世代优化, 针对本研究使用的数据在训练集上交叉验证的R2基本都在0.98以上。 图8为使用GA-PLS算法针对RAW进行特征波段提取的结果图, 提取的特征波段数为99。
 | 图8 GA-PLS算法提取特征波段结果Fig.8 GA-PLS algorithm is used to extract characteristic band results |
2.3.4 光谱预处理算法与特征提取算法结合
由于光谱数据预处理与特征波段提取算法针对本研究获取的高光谱数据特点进行处理的目的与效果不同, 因此本研究将上文扩展改进的16种光谱预处理方法与SPA、 CARS和GA-PLS这3种特征波段提取算法进行结合, 旨在更加全面地优化光谱数据, 提高建模效果, 从而得到64种光谱处理方法。 光谱处理方法组合结果及进行特征波段提取后的波段数如表3所示, 从特征波段提取结果可知, 经过SPA、 CARS和GA-PLS进行特征波段提取将在不同程度上消除冗余, 提取有效特征信息。
| 表3 对经过不同光谱处理方法预处理后的光谱进行特征波段提取得到的特征波段数 Table 3 The number of characteristic bands is obtained by extracting characteristic bands from the spectra pretreated by different spectral processing methods |
2.4.1 CNN分类预测模型结果分析
将经过本研究方法改进扩展的64种光谱处理方法处理后的光谱数据分别通过构建的CNN分类模型, 对马铃薯早疫病不同染病时期(DPP)进行分类预测, 其分类预测结果见表4所示。 结果表明本研究使用的光谱处理方法对提高CNN分类模型的分类表现有很重要的作用, 都能在不同程度上提高模型总体分类精度。 有12种新的光谱处理方法相比于RAW-RAW的CNN的总体分类精度86.67%提高到100%达到对DPP的完美预测分类, 这12种光谱处理方法分别是D1-MSC-CARS、 D1-MSC-GA、 DT-MSC-RAW、 DT-MSC-SPA、 DT-MSC-CARS、 DT-MSC-GA、 DT-MSC-SS-RAW、 DT-MSC-SS-SPA、 DT-MSC-SS-CARS、 DT-MSC-SS-GA、 D1-MSC-SS-RAW、 D2-MSC-SS-RAW。 可知本文提出的光谱处理方法和CNN分类模型是能够针对DPP光谱数据进行有效分类, 而且将特征波段提取与光谱预处理结合, 可以实现预处理与特征提取方法的优势结合。
| 表4 不同光谱处理方法建立的CNN分类模型预测结果(总体分类精度/%) Table 4 The prediction results of the CNN classification model established by different spectral processing methods (Overall classification accuracy/%) |
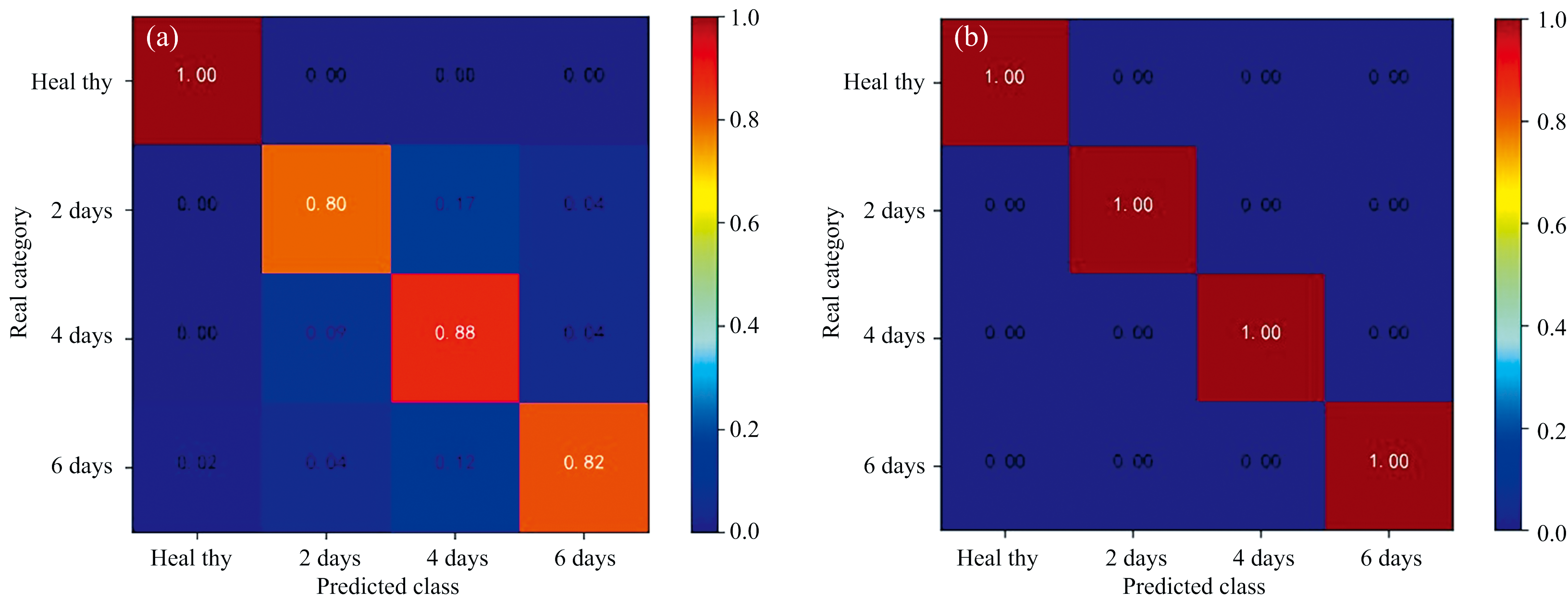
总体分类精度虽然可以反映DPP在CNN分类模型上整体的分类效果, 但是无法反映马铃薯早疫病不同染病天数之间的相互干扰, 因此, 本研究通过混淆矩阵来分析基于本文使用的光谱处理方法在CNN分类模型中对DPP的分类结果如图9(a, b)所示, 以RAW-RAW、 DT-MSC-SPA两种光谱处理方法在CNN分类模型中分类结果的混淆矩阵为例。 在混淆矩阵图中, 颜色越蓝对应的DPP的相似度越低, 越红相识度越高, 矩阵的正确分类集中在矩阵的对角线上, 如果混淆矩阵对角线相似度越高即对角线上准确率越接近于1, 则认为该模型分类效果较好。 结果表明基于CNN构建的针对不同DPP分类检测模型的不同类别检测结果精度都较高, 分类性能也比较稳定, 四种不同染病时期马铃薯光谱数据之间存在相互干扰, 但是经过光谱处理后的光谱数据能够降低甚至完全消除不同染病时期马铃薯光谱数据之间存在的相互干扰, 提高CNN分类模型的分类性能。
 | 图9 CNN分类模型混淆矩阵结果图 (a): RAW-RAW混淆矩阵; (b): DT-MSC-SPA混淆矩阵Fig.9 Confusion matrix result diagram of CNN classification model (a): RAW-RAW confusion matrix; (b): DT-MSC-SPA confusion matrix |
2.4.2 CNN定量估算模型结果分析
为进一步对马铃薯早疫病不同染病时期(DPP)进行定量分析, 将经过光谱处理方法处理后的光谱数据使用构建的CNN定量估算模型进行DPP光谱数据的定量估算, 结果如表5所示。 因为光谱预处理不仅可以优化数据, 也会损失数据中对目标变量有用的光谱信息, 从而导致经过光谱分析方法处理后的数据结果相对于未经过处理的R2和RMSE存在下降的结果, 其中采用DT-MSC-SS-RAW光谱处理方法的CNN定量估算模型取得了最好的结果, 其R2为1说明估算的DPP和实际值拟合程度达到100%拟合, 其RMSE仅为0.001 061 849, 表明DPP估算值与真实值之间的偏差接近0, 因其值越小, 表明估算的准确率越高, 得出DT-MSC-SS-RAW基于CNN定量估算模型非常好地实现对DPP的准确估算。
| 表5 不同光谱处理方法建立的CNN定量估算模型预测结果 Table 5 CNN quantitative estimation model prediction results established by different spectral processing methods |
图10(a, b)分别为测试集样本原始光谱数据(RAW)、 DT-MSC-SS-RAW在CNN定量估算模型中预测值和真实值的相关图。 从图中可以看出, 经过DT-MSC-SS-RAW处理后的预测值与真实值完全重合, 而RAW的DPP预测值与真实值存在误差。 可知使用DT-MSC-SS-RAW进行光谱处理能够实现对DPP光谱数据存在的相互干扰进行优化, 提高建模效果。
 | 图10 CNN定量估算模型预测数据散点相关图 (a): RAW散点图; (b): DT-MSC-SS-RAW散点图Fig.10 CNN quantitative estimation model prediction data scatter plot (a): RAW-RAW scatter plot; (b): DT-MSC-SS-RAW scatter plot |
针对DPP光谱数据相互干扰导致预测结果不佳的问题, 开展基于CNN对DPP光谱数据特征波段筛选和光谱预处理的相关研究。 研究结果表明, 基于CNN分类模型和定量估算模型均取得了较好的建模效果, 为进一步提高建模效果。 研究将光谱预处理方法和特征波段提取方法进行优势互补, 将传统光谱处理方法通过融合扩展到64种, 并分别用CNN分类模型、 CNN定量估算模型进行预测, 提出的光谱处理方法有12种将CNN分类模型的分类预测精度由86.67%提高到100%, 其中DT-MSC-SS-RAW使得CNN定量估算模型的R2提高到1, RMSE为0.001 1。 研究结果表明DT-MSC-SS-RAW融合光谱处理方法和CNN结合能够对DPP进行准确的病害检测和病害预测, 为基于高光谱成像技术的农作物病害检测防治提供了一个新的方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|