
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于SMOTE和Inception-CNN的种植和组培金线莲鉴别
[蓝艳1  , 王武
, 王武1 , 许文2 , 柴琴琴1, * , 李玉榕1 , 张勋2 ]
, 王武, 李玉榕|
|


作者简介: 蓝 艳, 女, 1998年生, 福州大学电气工程与自动化学院硕士研究生 e-mail: 2031530637@qq.com
金线莲是一种珍贵中药材, 其治疗、 保健作用十分显著。 金线莲培育方式主要有种植、 组培等, 不同培育方式的金线莲, 在性状上仅表现出细微差异, 但药用、 市场价值差异显著, 培育方式鉴别能有效保证药用疗效、 维护良好市场秩序, 然而由于不同品系、 产地、 培育时间等复合差异的影响, 增加了培育方式鉴别难度与复杂度。 提出一种基于改进1D-Inception-CNN模型的金线莲培育方式鉴别方法。 采用近红外光谱仪采集种植、 组培金线莲的光谱, 首先使用合成少数类过采样技术(SMOTE)进行过采样以解决种植品、 组培品样本比例不平衡问题, 其次构建基于改进Inception结构的一维卷积神经网络对来自不同品系、 产地、 培育时间的金线莲进行种植品、 组培品鉴别, 最后采用贝叶斯优化方法对构建的卷积神经网络模型超参数进行优化; 最终五折交叉验证平均鉴别准确率、 精确率、 召回率、 综合评价指标高达97.95%、 96.16%、 100%、 98.02%。 研究表明, 实验提出的鉴别模型为快速鉴别金线莲种植品、 组培品提供一种有效方法。
Anoectochilus roxburghii (Wall.) Lindl. (Orchidaceae) is one of the most precious Chinese medicine with extraordinary effects in medical treatment and health protection. Planting and tissue-cultured are two main cultivated methods of A. roxburghii. There are slight characteristic differences between Planting and tissue-cultured A. roxburghii, but they show significant differences in medicinal and market value. Therefore, the identification of cultivated methods plays an important role in effectively securing the medicinal efficacy of A. roxburghii and maintaining a good market order. However, due to the influence of composite differences such as different cultivars, different geographical origins and different times of cultivation, the difficulty and complexity of identification in cultivated methods increase heavily. This paper proposes an effective model to discriminative different cultivated methods of A. roxburghii based on improved 1D-inception-CNN. The experiments were conducted on two kinds of A. roxburghii, and their NIRS data were collected by a Fourier transform near-infrared spectrometer. Considering the unbalanced proportion of planting and tissue-cultured samples,the NIRS data was over sampled by using SMOTE first. Secondly, a one-dimensional convolutional neural network based on improved Inception was constructed to identify planting and tissue-cultured A. roxburghii though both include different varieties, different geographical origins and different cultivating times. Finally, Bayesian optimization was used to optimize the hyperparameters of the model. The final average identification accuracy, precision, recall, and F1-score of five-fold crossvalidation reached 97.95%, 96.16%, 100%, and 98.02%. The identification model proposed in this experiment provides a useful method to identify planting and tissue-cultured A. roxburghii effectively and rapidly and provides an idea for the identification of cultivation methods of other Chinese herbal medicines.
金线莲是一种珍贵的中药材, 具有抗肿瘤、 抗糖尿病、 抗病毒、 抗肝炎等疗效[1], 被广泛应用于临床治疗。 然而, 金线莲自然生长率低, 生长条件严苛, 由于人工过度开发, 其野生资源日益短缺[2], 无法满足市场需求, 为了解决供不应求的问题, 人工培育金线莲规模不断扩大。 根据生长方式的不同, 金线莲可分为种植品、 组培品。 种植品由于营养物质的累积效应其多糖[3]、 微量元素[4]等有效成分远远高于组培品; 就市场价值, 种植品每公斤8 000~20 000元不等, 组培品每公斤1 150~1 500元不等。 不难发现, 金线莲种植品、 组培品的药用价值和市场价值差异显著。 种植品和组培品难以辨认的现象严重影响金线莲处方疗效以及市场秩序, 因此寻找一种快速有效的种植品、 组培品鉴别方法已成为中药质量监管中迫切需要解决的问题。
中药材的鉴别通常借助于分子生物学鉴定法[5]、 HPLC指纹图谱法[6]等化学分析方法, 然而, 这些方法存在专业性强、 操作要求高、 费用、 时间成本高、 对样本有损坏等不足, 限制了该方法在市场环境中的应用。 为了克服上述方法的不足, 具有快速、 无损、 低成本特点的近红外光谱技术(near-infrared spectroscopy, NIRS)应运而生, 其与模式识别方法的结合已被广泛应用在中药材鉴别中。 文献[7]构建PLS-DA模型对纯葛根与葛根掺假物进行快速鉴别, 鉴别准确率可达100%; 文献[8]基于PLS-DA方法建立了性能良好、 模型稳定的藏红花掺假鉴别模型; 文献[9]提出了一种改进朴素贝叶斯分类器快速有效地实现了不同产地三叶青的鉴定, 上述研究在不同品系或产地的中药材分类中表现出良好的效果。 由于采集的近红外光谱数据的高维特性, 传统模式识别方法需要首先进行特征提取来简化和提高模型分类精度, 特征提取和分类算法的分离增加了鉴别模型复杂度和难度, 导致模型的泛化性能差。
针对近红外光谱数据特点, 学者们提出了基于深度学习方法的品系或产地鉴别方法。 文献[10]提出了一种端到端自适应的一维卷积神经网络用于马兜铃酸及其类似物的鉴别; 文献[11]构建了一维卷积神经网络模型用以提取茶叶的特征并进行产地分析; 在金线莲及其伪品的鉴别中, 文献[12]基于1D-Inception-CNN构建了一个高精度的鉴别模型。 研究结果表明上述模型的分类性能远超基于传统机器学习方法的模型, 然而上述研究仅针对不同品系或产地等单一差异下的品系或产地鉴别, 对于不同品系、 不同产地且不同培育时间等复合差异下的培育方式鉴别少有报道。
本研究对象为种植、 组培两种培育方式下生长的金线莲, 包含不同品系、 不同产地、 不同培育时间等复杂情况的样本, 因此, 本研究中的培育方式鉴别相比伪品鉴别具有更复杂的区分性, 直接应用文献[12]的模型存在特征提取能力不够的问题, 导致识别精度差。 本文针对不同品系、 产地、 培育时间的金线莲培育方式的鉴别需求, 基于金线莲的NIR数据, 提出改进1D-Inception-CNN的金线莲鉴别模型, 并通过实验对比验证该模型的有效性。
实验所使用的金线莲样品数据均由福建中医药大学提供, 一共收集了91批金线莲, 其中, 组培品18批, 种植品73批。 样本中包含了本地、 尖叶、 小圆叶、 大圆叶、 台湾银线兰等不同品系; 样本来自宁德、 漳州、 泉州、 三明、 南平、 福安、 莆田、 云南等产地; 组培品包含瓶苗、 盆苗、 炼苗等, 种植品包含野生苗、 林下仿野生苗等; 除野生样本外, 培育时间1~24个月不等。 每批样本经3~5次清洗, 直至表面无泥沙, 放于烘箱60 ℃恒温烘干至恒重, 随后用中药粉碎机粉碎, 过60目筛。
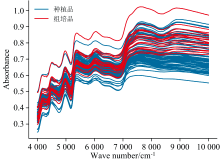
取适量上述样本粉末装入指管, 使用瑞士步琦公司生产的NIRFlexN-500型傅里叶变换近红外光谱仪进行数据采集, 仪器扫描范围为4 000~10 000 cm-1, 扫描次数设置为32次, 分辨率为8 cm-1, 在室温25 ℃, 空气湿度为60%的条件下进行采集, 每次扫描前保持样本处于夯实、 均匀、 平整的状态, 每个样本重复扫描三次, 取平均值作为样本近红外光谱。 最终, 获得2组共91批金线莲近红外光谱, 每条NIR数据有1 501个波数点, 原始光谱如图1所示。 数据均使用Python语言编写程序进行分析。
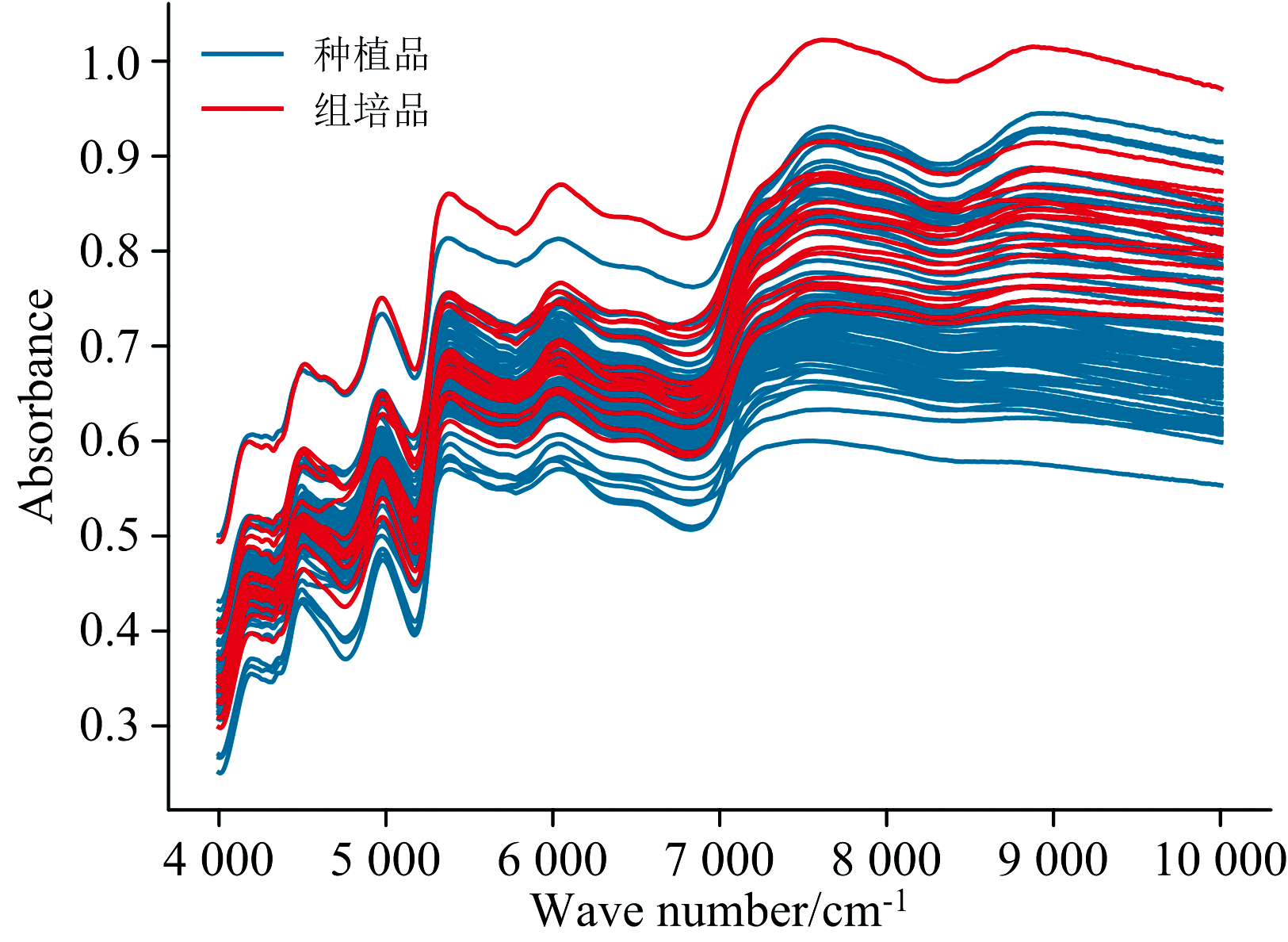 | 图1 原始数据集近红外光谱Fig.1 Near-infrared spectroscopy of the original dataset |
由于金线莲生长周期长、 生长所需环境严格, 一年能采集的样本批次不多, 由于人为因素的影响在实际应用中要积累大量样本需要几年甚至更长的时间, 因此在实际金线莲样本积累的过程中存在种植、 组培样本不平衡问题。
然而分类鉴别模型一般都需要建立在不同类别的训练样本数目相当这个基本假设上, 事实上如果类别样本数量差别很大, 会对训练学习造成很大的影响[13]。 在本研究中培育方式为种植、 组培的金线莲样本数量比例超过4∶ 1, 采用常规模式识别分类器倾向于将大部分的分类结果识别为种植品, 如果不对该特性进行针对性改进和预处理, 将严重影响最终的鉴别结果。
目前解决样本类别不平衡问题比较成熟的技术主要分为两类: (1)对原有的数据进行处理, 使得数据的分布变得平衡, 如合成少数类过采样技术(synthetic minority over-sampling technique, SMOTE)[14]。 (2)采用代价敏感机制对算法进行改进, 使得某类别错误分类的代价更高[15]。 在现实生活中, 代价敏感值难以确定, 大大增加了该方法的难度和不确定性, 这是实际应用中难以克服的问题。 因此选择SMOTE算法对类别不平衡问题进行处理。
文献[12]所提出的1D-Inception-CNN(这里称它为原始1D-Inception-CNN)是针对一维NIR数据提出的鉴别模型, 具有低计算复杂度及高精度的特点。 复合差异下不同培育方式的金线莲光谱重叠严重, 鉴别难度很大, 将原始1D-Inception-CNN直接应用于不同培育方式的金线莲鉴别时仍存在特征提取能力不足的问题, 从而导致鉴别准确率不高。 因此对原始1D-Inception-CNN模型特征提取层进行改进, 主要策略为在两条Inception支路上各增加一层卷积层以获取更多特征信息, 设计的改进1D-Inception-CNN模型结构如图2所示, 改进前后模型结构参数对比如表1所示。
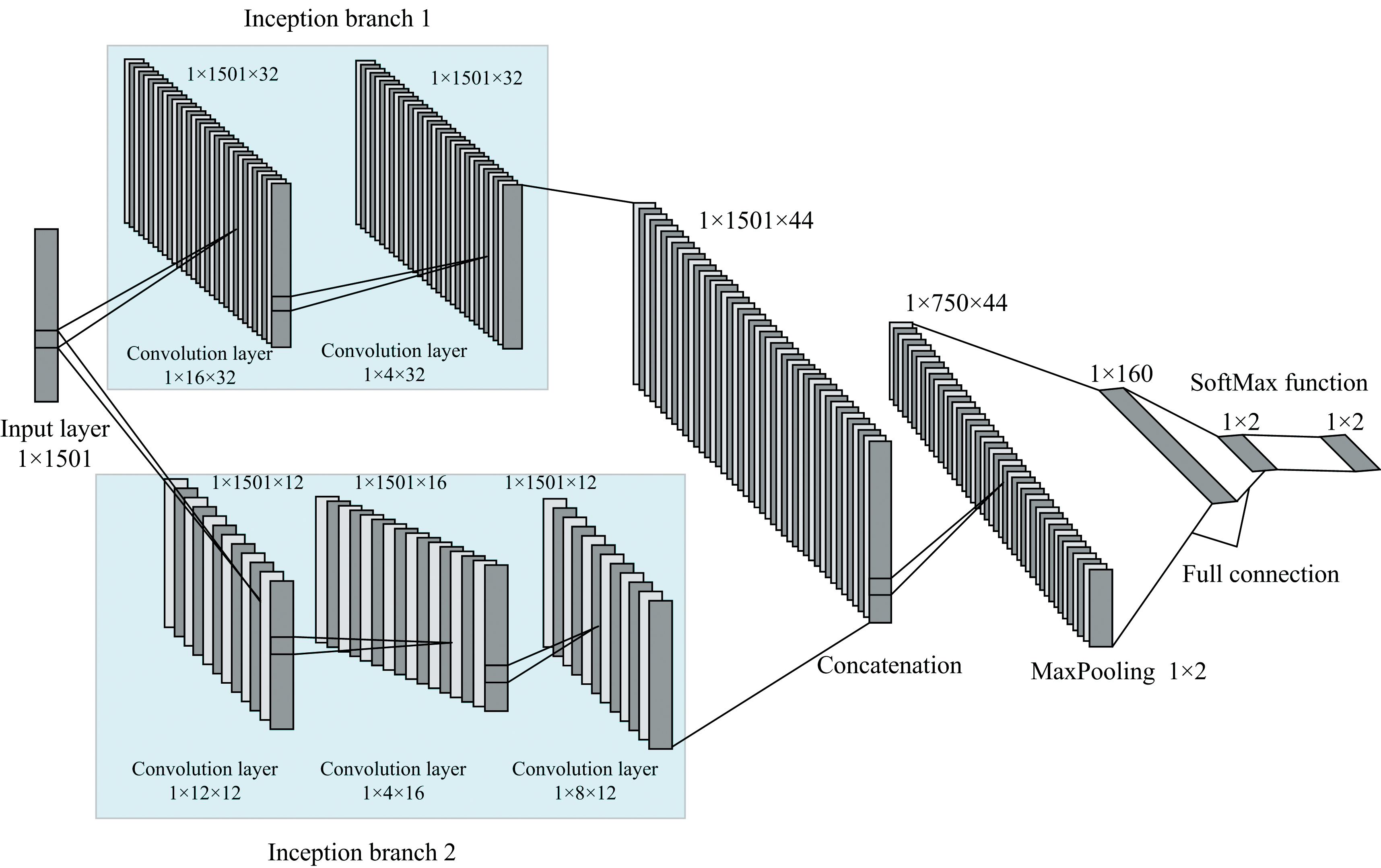 | 图2 改进的1D-Inception-CNN结构图Fig.2 Improved 1D-Inception-CNN structure diagram |
| 表1 改进前后1D-Inception-CNN具体参数 Table 1 Specific parameters of original and improved 1D-Inception-CNN |
图2中近红外光谱数据由输入层送到Inception支路1(包含2个卷积层)和Inception支路2(包含3个卷积层)进行特征提取, 随后由连接层进行两个Inception支路特征信息的融合, 融合的特征经过最大池化操作以减少模型复杂度, 同时一定程度上避免过拟合的发生, 随后输入到两个全连接层和SoftMax函数完成种植、 组培样本的分类。
由于CNN超参数对模型性能影响很大, 合适的优化方法不仅能加快寻找模型超参数的速度, 同时能保证模型鉴别结果的稳定性。 常用于参数优化的方法有网格搜索[16]、 随机搜索[17]等。 对参数众多的CNN而言, 网格搜索次数的增加呈指数级增长, 而随机搜索容易陷入局部最优, 易造成鉴别结果的不确定性。 贝叶斯优化算法[18]是一种基于模型的序贯优化方法[19], 每一次评估都能够学习到上一次评估的经验, 从而确定下一个参数组合, 依次循环这一步骤, 直至迭代终止。 作为一种全局优化算法, 贝叶斯优化算法与网格搜索相比, 具有更低的计算复杂度, 与随机搜索相比, 搜索目的性更加明确, 不易被局部最优点所束缚, 因此, 贝叶斯优化算法能够更加有效地找到模型参数的全局最优解。 选用贝叶斯优化法对超参数进行寻优, 待寻优参数有: 训练迭代次数(Epoch)、 批大小(Batch-size)、 全连接层神经元个数(Units)、 最大池化窗口大小(MaxPooling-size)、 各卷积层卷积核个数(Filters)、 各卷积层卷积核大小(Kernal-size), 超参数及寻优设置如表2所示。
| 表2 超参数的搜索空间 Table 2 Search Spaces for Hyperparameters |
其中, Inception两个支路中各卷积层卷积核个数和卷积核大小的搜索范围均按表中Filters、 Kernal-size设置。
优化算法的目标函数(objection function, OF)设定如式(1)
式(1)中, Kfold代表交叉验证序号, ACC、 PRE、 REC、 F1等参数的具体含义及计算方法可参考1.6节的详细介绍。
组培品和种植品本质上是二分类问题, 二分类算法常用准确率(Accuracy, ACC)来评价, 为进一步判断预测结果是组培品中真实结果为组培品的比例和模型综合性能, 选取精确率(Precision, PRE)、 召回率(Recall, REC)和综合评价指标(F1-score, F1)进行评估。 上述评估指标的计算公式如式(2)— 式(7)
式(2)— 式(7)中, TP代表实际为正例的样本预测为正例(即真正例)的数量, TN代表实际为反例的样本预测为反例(即真反例)的数量, FP代表实际为反例的样本预测为正例(即伪正例)的数量, FN代表实际为正例的样本预测为反例(即伪反例)的数量。 对于类别不平衡样本集模型性能的评价常使用ROC曲线-AUC指标进行评估, 该指标可以有效度量模型对正例样本的鉴别能力, 其中, ROC曲线纵坐标为“ 真正例率” (true positive rate, TPR), 横坐标为“ 假正例率” (false positive rate, FPR), AUC即为ROC曲线下方的面积, 代表着模型对正例样本的鉴别能力。 组培品处方疗效、 市场价值较种植品低, 因此在这个实验中将其作为正例。
考虑到传统机器学习方法对光谱特征提取操作的依赖性, 仅选用改进1D-Inception-CNN模型来进行SMOTE过采样分析。 模型训练的整体流程如图3所示, 首先对原始数据进行SMOTE操作, 接着对特征进行标准化, 选择一个分类模型并进行五折交叉验证, 对模型五折交叉的平均性能进行评估, 选择性能最好的模型并进行参数优化从而得到最终的模型。
 | 图3 实验流程Fig.3 Experimental process |
本实验采用五折交叉验证对改进1D-Inception-CNN模型进行验证, 从而提高模型的泛化能力, 增强其稳定性。
原始数据集包含2组数据, 分别是种植品73批, 组培品18批; 经SMOTE处理的数据集包含两组, 分别是种植品73批, 组培品73批, 为保持类别比例的一致性, 在划分数据集时采用分层采样的方式, 两个数据集划分情况如表3所示。
| 表3 数据集划分 Table 3 Dataset division |
为验证SMOTE算法对改善鉴别效果的有效性, 基于全光谱数据对表3中两个数据集分别构建改进1D-Inception-CNN模型进行鉴别分析, 并采用贝叶斯优化对改进1D-Inception-CNN模型参数进行寻优, 迭代次数设置为100。
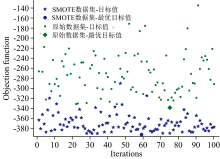
基于原始、 SMOTE处理数据集的超参数搜索过程及迭代目标值如图4, 由图4可看出基于原始数据集, 贝叶斯优化整体目标值比较分散, 介于-130与-340之间, 在第75次迭代中达到最优目标值-338.62; 而基于SMOTE数据集, 贝叶斯优化整体目标值较为集中, 介于-285与-395之间, 在第59次迭代中达到最优目标值-392.13。 据此可知, 经过SMOTE处理的数据集为模型提供了良好的数据基础, 为鉴别效果带来了很大的提升。
 | 图4 超参数搜索结果Fig.4 Hyperparameter search results |
据图4可知优化过程后期, 贝叶斯优化在原始、 SMOTE数据集上都具有很好的多样性, 能有效避免陷入局部最优。
模型性能指标对比具体结果如表4所示。 由表4可知, 经SMOTE算法合成的新数据集准确率略高于原始数据, 精确率、 召回率及综合评价指标均远高于原始数据集。
| 表4 原始数据集、 SMOTE数据集鉴别结果 Table 4 Identification results of the original dataset and SMOTE dataset |
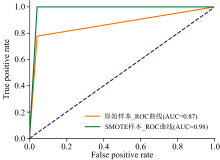
两个样本集的ROC曲线对比如图5所示, SMOTE样本集在模型下AUC高达0.98, 而原始样本集在模型下AUC仅为0.87, 进一步说明SMOTE处理后的样本集能有效增强模型对组培品的鉴别能力。
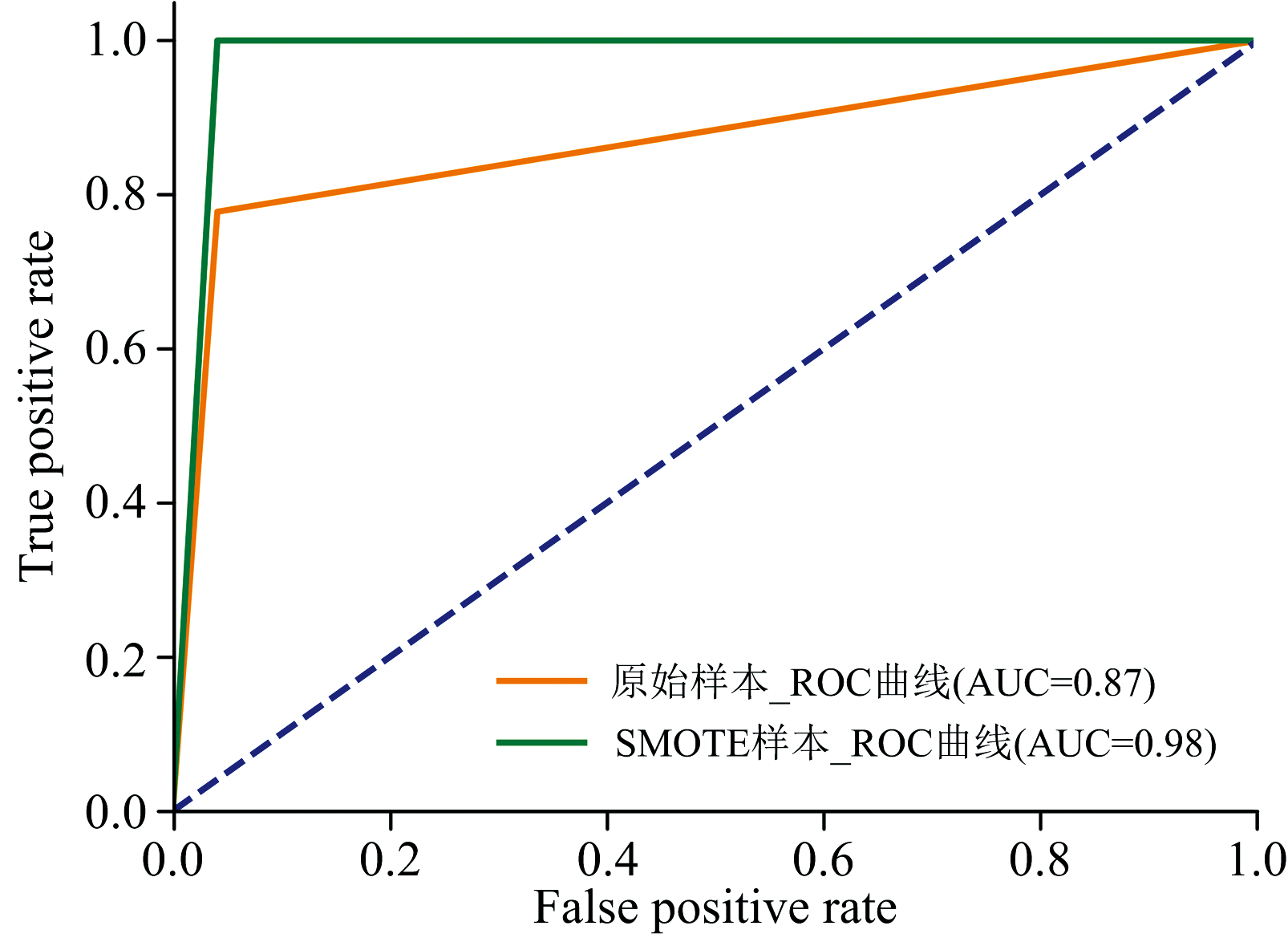 | 图5 原始数据集、 SMOTE数据集ROC曲线Fig.5 ROC curve of the original dataset and the SMOTE dataset |
为验证改进1D-Inception-CNN的模型性能, 基于SMOTE样本集, 分别建立原始1D-Inception-CNN、 随机森林(random forest, RF)与逻辑回归(logistic regression, LR)用于对比鉴别效果。 原始1D-Inception-CNN按文献[12]进行超参数设置, RF模型中决策树个数设置为100, LR模型中正则化系数设置为1.0, 改进1D-Inception-CNN超参数如表5。 其中, Filters1_1代表支路1中第一卷积层的卷积核数量, Filters1_2代表支路1中第二卷积层的卷积核数量, Kernalsize1_1代表支路1中第一卷积层的卷积核大小, 以此类推。
| 表5 改进1D-Inception-CNN超参数设置 Table 5 Hyper-parameters of improved 1D-Inception-CNN |
各模型训练后的测试集分类性能如表6所示, 各项分类指标显示, 原始1D-Inception-CNN的性能整体优于RF和LR模型, 但值得注意的是, 在文献[12]中性能卓越的模型在本节实验中的表现不如预期, 其召回率甚至略低于LR模型, 主要原因在于本研究所使用的各批金线莲不但在品系、 产地上有所差异, 在培育方式、 培育时间上更有所不同, 其NIRS数据重叠度十分高, 需要特征提取更好、 性能更强的模型才能更好地区分培育方式。 而改进1D-Inception-CNN由于增强了特征提取能力以及进行了全局参数优化, 各项评估指标均达到最优。
| 表6 不同分类模型性能 Table 6 Performance of different classification model |
研究了在不同品系、 产地、 培育时间等复杂情况下金线莲培育方式的鉴别, 提出了一种基于改进1D-Inception-CNN的金线莲培育方式鉴别方法。 首先针对样本类别不平衡的问题, 采用SMOTE算法对样本集进行平衡化处理, 得到类别平衡的SMOTE数据集; 其次针对不同培育方式的金线莲NIRS数据差异小的问题, 在原始1D-Inception-CNN结构的基础上, 对网络结构进行了改进, 得到了改进1D-Inception-CNN, 增强了网络对特征的提取能力; 最后利用贝叶斯优化对改进1D-Inception-CNN内部的超参数进行优化以进一步提高模型性能。 实验结果表明, SMOTE算法能够有效改善样本集的不平衡特性, 原始1D-Inception-CNN的性能优于传统机器学习方法RF和LR, 改进1D-Inception-CNN较原始1D-Inception-CNN而言, 对特征的提取能力更强, 模型性能最佳, 五折交叉平均准确率、 精确率、 召回率、 综合评价指标分别达97.95%、 96.16%、 100.00%、 98.02%, 能高精度鉴别金线莲种植品、 组培品。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|