
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
遗传算法和连续投影算法结合的土壤有机碳含量高光谱估算模型
[牛芳鹏1, 2  , 李新国
, 李新国1, 3, * , 白云岗2 , 赵慧4 ]
, 李新国, 白云岗|
|


作者简介: 牛芳鹏, 1995年生,新疆水利水电科学研究院助理工程师 e-mail: niufp0225@163.com
土壤有机碳含量是土壤肥力与土壤质量的主要决定因素, 与土壤生产力密切相关。 采用高光谱模型估算土壤有机碳含量成为了解土壤肥力的重要方法。 利用高光谱分析技术结合机器算法实现快速、 高精度的估算土壤有机碳含量, 对土壤肥力的可持续利用至关重要。 根据实测的土壤有机碳含量及其高光谱反射率数据, 运用Savitzky Golay方法对光谱波段进行平滑去噪, 采用连续投影算法(SPA)、 遗传算法(GA)对原始光谱及其5种不同数学变换光谱分别进行特征波段的筛选, 并基于随机森林(RF)方法构建土壤有机碳含量的高光谱估算模型。 为进一步降低模型的复杂度, 将SPA算法与GA算法相结合, 寻找最佳特征参数, 以提升土壤有机碳含量特征波段的识别率和可信度。 结果表明: (1)在原始光谱中, 基于GA算法筛选SOC含量的高光谱响应波段主要集中在350~410、 827~928、 997~1 064、 1 201~1 234、 1 541~1 574、 1 667~1 710、 2 153~2 186和2 357~2 707 nm; 当RMSE为6.09时, SPA算法筛选了11个特征变量。 (2)基于GA算法筛选特征波段时, 原始光谱R、 标准正态变量(SNV)、 多元散射校正(MSC)、 一阶微分(FD)、 对数的倒数(RL)与连续统去除(CR)的维数分别降低到407、 697、 668、 667、 493、 784维, 占全光谱波段的18.93%~36.47%; 基于GA-SPA算法筛选后, 6种光谱变量的维度介于8~17维, RMSE介于4.53~6.30。 (3)在一阶微分光谱形式下, 基于GA-SPA算法挑选的12个特征变量所构建的RF模型预测效果最好, 模型的建模集
Soil organic carbon content was a major determinant of soil fertility and soil quality and was closely related to soil productivity. The estimation of soil organic carbon content using hyperspectral models has become an important method of understanding soil fertility. Using hyperspectral analysis combined with machine algorithms to achieve rapid and highly accurate estimation of soil organic carbon contents was essential for the sustainable use of soil fertility. Using the measured soil organic carbon content and its hyperspectral reflectance data as the research object, we applied the Savitzky Golay method to smooth and demise the spectral bands, used successive projection algorithm (SPA) and genetic algorithm (GA) to screen the original spectra and its five different mathematical transformed spectra respectively for the characteristic bands, and constructed the random forest (RF) method based on the soil organic carbon content. The hyperspectral estimation model of soil organic carbon content was constructed using the random forest (RF) method. The SPA algorithm was combined with the GA algorithm to find the optimal feature parameters to improve the recognition rate and confidence in the SOC feature bands. The results showed that in the original spectrum, the hyperspectral response bands based on the GA algorithm to screen SOC content were mainly concentrated on 350~410, 827~928, 997~1 064, 1 201~1 234, 1 541~1 574, 1 667~1 710, 2 153~2 186, 2 357~2 707 nm. When the RMSE was 6.09, 11 characteristic variables were screened by the SPA algorithm. The dimension of the original spectrum, standard normal variables (SNV), multiple scattering corrections (MSC), first-order differential (FD), logarithmic reciprocal (RL) and continuum removal (CR) were reduced to 407, 697, 668, 667, 493 and 784 dimensions respectively, accounting for 18.93%~36.47% of the full spectral band when filtering the characteristic bands based of the GA algorithm. After screening based on the GA-SPA algorithm, the dimensions of the six spectral variables ranged from 8 to 17 dimensions, and the RMSE ranged from 4.53 to 6.30. In the first-order differential spectral form, the RF model constructed based on 12 feature variables selected by the GA-SPA algorithm predicted the best results from a modeling set
土壤有机碳(soil organic carbon, SOC)在促进植物的生长和发育、 改良土壤物理性质方面发挥着重要的作用, 是土壤碳库的重要组成部分。 在西北干旱地区, 关于土壤有机碳的研究, 对推进绿洲农业发展与“土壤碳循环”具有重大作用与意义[1]。 关于SOC含量的研究早期都是通过经验模型法估算的, 不涉及机理过程问题, 较易实现, 但受人为因素和区域尺度影响较大。 随着高光谱遥感技术的发展, 土壤反射光谱成为一种快速、 高效的土壤属性估算方法, 学者们关于光谱信息的预处理[2]、 特征变量选择[3]、 建模手段[4]等方面做了大量的研究。 Moura-Bueno等采用导数、 归一化和非线性变换等六种预处理技术与偏最小二乘、 多元线性回归、 支持向量机和随机森林算法(random forest, RF)四种多元校正方法以确定预测SOC含量的最佳组合[5]。 Wang等分析了澳大利亚东部半干旱牧场的SOC库存, 采用逐步回归和遗传算法(genetic algorithm, GA)来选择信息量最大的变量, 然后使用这些选定的预测变量来训练增强回归树和RF模型, 结果表明GA-RF能够可靠的预测SOC储量, 其构建的模型RMSE为7.44, R2为0.48[6]。 肖艳等采用小波变换和连续投影算法(successive projection algorithm, SPA)挑选黑土SOC含量光谱特征波段, 其构建的支持向量机模型建模集R2由土壤全谱的0.75提升至第3层小波低频系数的0.91, RMSE由7.46降低至4.12[7]。 目前, SOC含量特征波段的提取主要采用逐步回归、 相关系数法或SPA等单一方法, 易受到外部环境的影响, 不能敏感的反映土壤光谱信息。 如何将不同分类模型组合并应用于光谱信息的识别中, 并与机器算法结合提高模型精度逐渐成为一种高效的手段。 为减少光谱信息重叠, 采用GA算法对预处理后的光谱数据进行特征波段筛选后, 结合SPA算法进一步寻找最佳特征参数, 以提升SOC含量特征波段的识别率, 最后利用RF方法建立基于特征波段的GA-SPA-RF土壤有机碳含量模型, 以期能够为准确地定量估算湖滨绿洲土壤有机碳含量提供基础支撑。
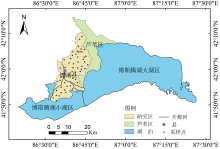
博斯腾湖西岸湖滨绿洲位于新疆焉耆盆地, 地理位置介于86°30'—86°50'E, 4l°33'—42°14'N, 海拔1 047~1 048 m。 天气寒冷和干燥, 年均气温为9.0 ℃, 夏季月均温22.8 ℃, 冬季月均温9.0 ℃, 年平均降水量为83.60 mm, 地下水可利用量为9.05×108 m3·a-1, 矿化度为0.10~10.00 g·L-1。 研究区植被主要以胡杨、 芦苇等为主, 土壤类型主要以草甸土与盐渍土为主。
 | 图1 研究区位置图Fig.1 Location map of the study area |
按照“S”型线路进行设点取样, 为保证样品代表性, 2020年10月于31个不同土地利用类型0~50 cm深度的样点, 每一采样点由上到下每10 cm取一份土样, 自然风干后研磨过100目孔筛。 SOC含量采用重铬酸钾容量法—外加热法测定, 单位为g·kg-1。 光谱数据采用美国ASD公司FieldSpec3型地物光谱仪测量。 测量环境如下: 远离可能干扰土壤光谱的物体及环境, 选择云量小于5%、 风力低于3级的晴朗天气, 时间为12:00—14:00; 视场角小于25°, 探头垂直于土样表面约15 cm处, 测量前对光谱仪进行预热与白板校正。 采集光谱数据时采用五点梅花法, 每个土样共获得15条光谱曲线, 去除异常光谱值后, 对剩余曲线均值化得到最终的土样光谱数据。 所有光谱曲线统一去除水汽影响较大的波段(1 300~1 450和1 800~1 950 nm)以及噪音影响较大的尾部波段(2 451~2 500 nm)[8]。
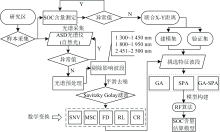
图2描述了SOC含量估算模型的构建流程: (1)对采集的土壤样品测定SOC含量与光谱反射率数据; (2)采用Savitzky Golay(SG)滤波方法对光谱曲线进行平滑和去噪, 并对原始光谱反射率(reflectivity, R)分别进行标准正态变量变换(standard normal variable, SNV)、 多元散射校正(multiple scatter correction, MSC)、 一阶微分(first derivative, FD)、 对数的倒数(reciprocal of logarithm, RL)与连续统去除(continnum removal, CR)5种光谱数学变换; (3)基于联合X-Y距离(sample set partitioning based on joint X-Y distances, SPXY)方法划分103个样本为训练集, 52个为验证集, 并采用GA、 SPA与GA-SPA算法对原始光谱R及5种变换光谱分别进行降维处理; (4)基于RF方法构建研究区SOC含量估算模型, 决定系数R2(coefficient of determination, R2)、 均方根误差(root mean square error, RMSE)和相对分析误差(ratio of standard deviation to RMSE, RPD)评价模型的精度与稳定性, 当R2取值趋于1, RMSE越接近0, RPD≥2.00时, 表明模型的拟合度越高。
 | 图2 SOC含量估算模型构建流程图Fig.2 Flow chart of constructing SOC content estimation model |
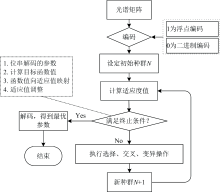
遗传算法(GA)是一种模拟学习生物界自然进化过程的算法, 旨在寻找最优种群, 能够减少谱矩阵的信息冗余和多重共线性问题, 降低陷入局部最优解的风险, 提高模型的精度。 利用GA算法选择特征波段时, 种群数设置为60, 繁殖代数设置为100, 交叉概率设为0.6, 变异率设置为0.1, 采用北卡罗来纳大学gaot遗传算法工具箱。 图3为GA算法过程图。
 | 图3 GA算法挑选特征变量过程图Fig.3 Process diagram of selecting feature variables by GA algorithm |
连续投影算法(SPA)是一种基于向前变量选择的方法, 并从光谱矩阵中选择共线性最小变量组合的算法。 通过最小化矢量空间共线性, 采用向量投影分析挑选最大向量, 最后经过模型校正筛选光谱的特征波长, 减少了模型的冗余度, 提高了模型的稳定性和可靠性。 算法中特征波长数的迭代范围设置为2~35, 通过建立多元线性回归模型交叉验证得到的一个均方根误差值RMSE, 选择其中最小的RMSE值对应的波长和波长数确定为最后的最优值。
(3)GA-SPA算法。 为进一步简化模型, 在GA算法基础上应用SPA算法继续进行特征波段的筛选, GA算法在选择特征变量的过程中具有很强的随机性, SPA算法倾向于在选择特征波长的过程中选择具有较少共线性的波长, GA算法通过多重计算以最高精度选择变量, 结合SPA算法, 可以有效选择功能带。
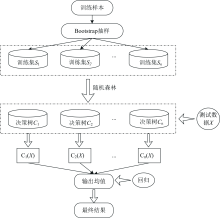
随机森林(RF)是一种采用随机森林分类器对新数据进行判别和分类的算法。 在处理比较大的数据时, 运算速度快, 无需进行变量的选择; 在计算变量的非线性效应与处理连续和离散数据时, 它能够很好地容忍噪声和离群点的影响, 充分反映变量之间的相互作用[9]。 在算法模型建立过程中, 设置决策树的数量为500。 图4为RF方法过程图。
 | 图4 SOC含量RF模型构建过程图Fig.4 Construction process of RF model for soil organic carbon content |
2.1.1 基于GA算法挑选光谱特征波段
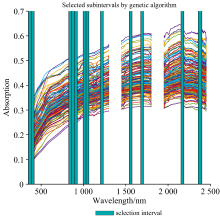
经GA算法处理后, 原始光谱R最终选择出407个波段作为特征变量, 占全波段的18.93%, 由图5可知, 原始光谱基于GA算法挑选的特征变量主要集中在350~410、 827~928、 997~1 064、 1 201~1 234、 1 541~1 574、 1 667~1 710、 2 153~2 186和2 357~2 707 nm。 经SNV、 MSC、 FD、 RL和CR 光谱数据变换后, 光谱维数分别降低到697维、 668维、 667维、 493维、 784维, 分别占全光谱波段的32.42%, 31.07%, 31.02%、 22.93%、 36.47%。
 | 图5 基于遗传算法挑选原始光谱特征波段的结果Fig.5 Results of selecting characteristic bands from original spectra based on Genetic Algorithm |
2.1.2 基于SPA算法挑选光谱特征波段
由图6可知, 基于SPA算法对原始光谱数据R进行特征波段筛选时, 当RMSE为6.09, 模型趋于稳定状态, 共挑选11个特征变量。 光谱数据进行数学变换后挑选情况为: SNV、 MSC、 FD变换后光谱分别挑选了14个特征波段, RMSE值分别表现为6.00、 6.04、 4.86; RL变化光谱, 当RMSE为6.04时, 模型趋于稳定状态, 共挑选10个特征变量; CR变化光谱中, 当RMSE为6.39时, 共挑选了8个特征波段。
 | 图6 利用SPA筛选光谱特征波长Fig.6 Screening of spectral characteristic wavelength by SPA |
2.1.3 基于GA-SPA算法挑选光谱特征波段
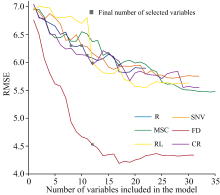
由图7可知, 在原始光谱数据R中, 当RMSE为6.30时, 模型趋于稳定状态, 挑选了8个特征波段, 分别为407、 1 260、 1 700、 2 132、 2 153、 2 157、 2 186和2 360 nm; SNV光谱中, 当RMSE为6.30时, 得到了10个特征波段; MSC光谱中RMSE达到5.95时, 共挑选了17个特征波段; FD与RL光谱分别挑选了12个特征波段, RMSE值分别表现为4.53、 5.99; CR光谱中, 当RMSE为6.27时模型较稳定, 选择了11个特征波段。
 | 图7 利用GA-SPA筛选光谱特征波长Fig.7 Screening of spectral characteristic wavelength by GA-SPA |
由表1可知, 原始光谱R中, 采用GA算法挑选的特征波段构建的RF模型
| 表1 基于GA算法挑选特征波段构建RF模型 Table 1 Selecting characteristic bands based on GA algorithm to construct RF model |
由表2可知, 通过SPA算法挑选光谱数据的特征波段时, 光谱数据经数学变换后, 效果明显好于原始波段, 原始波段R建模效果最差,
| 表2 基于SPA算法挑选特征波段构建RF模型 Table 2 Selecting characteristic bands based on GA algorithm to construct RF model |
由表3可知, 在GA算法的基础上结合SPA算法构建的RF模型效果明显有所提升。 建模效果最好的光谱转换为SNV,
| 表3 基于GA-SPA算法挑选特征波段构建RF模型 Table 3 Based on GA-SPA algorithm to select characteristic bands to construct RF model |
基于GA、 SPA、 GA-SPA算法构建的RF模型中, 光谱反射率经过FD形式变换后, 模型的预测效果一直较好且稳定,
(1)在原始光谱R中, 基于GA算法筛选SOC含量的高光谱响应波段主要集中在350~410、 827~928、 997~1064、 1 201~1 234、 1 541~1 574、 1 667~1 710、 2 153~2 186和2 357~2 707 nm。 GA算法筛选波段时原始光谱R及SNV、 MSC、 FD、 RL和CR光谱的维数分别降低到407、 697、 668、 667、 493、 784维, 占全光谱波段的18.93%~36.47%。
(2)基于SPA算法挑选特征波段, 当模型趋于稳定状态时筛选的特征变量只有8~14个, RMSE介于6.00~6.39。 GA-SPA算法筛选后, 模型的特征变量介于8~17个, RMSE介于4.53~6.30。
(3)基于GA-SPA算法构建的RF模型, 验证集
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|