{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Stacking集成学习的近红外光谱油页岩含油率预测
[李泉伦1  , 陈争光
, 陈争光1, * , 焦峰2 ]
, 陈争光, 焦峰|
|


作者简介: 李泉伦, 1995年生, 黑龙江八一农垦大学硕士研究生 e-mail: 18663065663@163.com
为了克服单一模型预测精度很难进一步提高的不足, 利用近红外光谱分析结合基于Stacking框架的异构集成学习模型实现对油页岩含油率的检测。 以松辽盆地某区块所取230个油页岩岩芯样本为研究对象, 使用低温干馏法测量油页岩样本的含油率, 同时扫描每个样本对应的近红外光谱数据。 样本使用蒙特卡洛算法进行异常样本剔除, 将剔除异常样本后的213个数据按照3∶1的比例随机划分为训练集和预测集。 利用去趋势加基线校正方法进行预处理消除光谱数据中噪声和基线漂移, 利用随机森林算法进行波长重要性排序并保留重要波长, 在此基础上采用CARS算法进行特征波长提取, 进一步降低数据维度。 最后, 构建以PLS, SVM, RF和GBDT为初级学习器, PLS回归模型为次级学习器的Stacking集成学习模型, 各初级学习器模型参数使用网格搜索进行寻优。 使用决定系数和预测均方根误差作为各模型的评价指标, 探究单一模型和集成学习模型对油页岩含油率预测的准确性。 研究结果表明, RF-CARS方法能够有效筛选重要波长, 进而提高模型效率。 基于Stacking的异构集成学习模型与单一模型(SVM和PLS)和同构集成学习模型(RF和GBDT)相比有更好的预测效果和更强的稳定性。 在多次随机划分数据集的基础上, Stacking集成学习模型的平均决定系数 R2为0.894 2, 相比于其他单一模型平均提高了0.062 3; RMSEP为0.586 9, 比其他模型平均降低了0.147 4。 说明, 基于Stacking的异构集成学习模型能够组合初级学习器的优势, 提高油页岩含油率预测精度, 为油页岩含油率快速检测提供了一种新方法。
Aims to overcome the shortcomings that the prediction accuracy of a single model is hard to improve further, A heterogeneous ensemble learning model based on the Stacking framework, combined with near-infrared spectroscopy analysis technology, was adopted to detect the oil content in oil shale in this study. A total of 230 oil shale core samples, collected from some block in Songliao Basin, were taken as the research object, whose oil content was measured by the low-temperature dry distillation method, and near-infrared spectral data corresponding to each sample was scanned simultaneously. The Monte Carlo algorithm was employed to eliminate outlier samples, and 213 samples, after removing outliers, were randomly divided into a training set and test set according to the ratio of 3∶1. The detrend coupled with the baseline correction method was used to eliminate the influence of noise and baseline drift in spectral data. After that, the random forest algorithm (RF) was used to extract the characteristic wavelength according to the importance of wavelength. In order to further reduce the data dimension, the CARS algorithm was used to extract the characteristic wavelength. Finally, PLS, SVM, RF and GBDT, whose parameters were optimized by grid search, were adopted as primary learners, and the PLS regression modelwas adopted as secondary learners to build the stacking ensemble learning model. The accuracy of the single and ensemble learning models for oil shale oil content prediction was compared under evaluation indicators of R2 and RMSE. The research results show that the RF-CASR method can effectively screen important wavelengths and improve the efficiency of the model, thereby improving the model efficiency. Heterogeneous integrated learning models based on Stacking have better predictive performance and greater stability than single models (SVM, PLS) and homogeneous integrated learning models (RF, GBDT). Based on multiple random divisions of the data set, the average R2 of the Stacking ensemble learning model is 0.894 2, an average increase of 0.062 3 compared with other models; the RMSEP of 0.5869 is an average of 0.147 4 lower than other models. The results of this study show that the heterogeneous integrated learning model based on stacking can combine the advantages of primary learners to predict the oil content of oil shale quickly and accurately, which provides a new fast and portable method for oil shale oil content detection.
油页岩(又称油母页岩)是一种沉积岩, 可以作为石油的替代能源。 油页岩在全球范围内储量丰富, 美国是油页岩储量最多的国家, 我国油页岩资源也十分丰富[1]。 油页岩含油率是评价其质量好坏的重要指标之一。 使用常规方法检测油页岩含油率存在着检测繁琐, 效率低下的问题。 因此研究一种快速便携的油页岩含油率检测方法尤为重要。
近红外光谱分析能够在不破坏样本, 不使用试剂的情况下直接对样本进行检测, 具有测试方便、 成本低、 效率高的特点。 目前, 近红外光谱检测已经广泛应用于食品[2]、 土壤[3]、 石油[4]等内部成分的检测。 Romeo等[5]对昆士兰中部斯图尔特矿床的53个油页岩样品进行了干酪根含量的光谱分析并建立偏最小二乘(partial least squares, PLS)定量分析模型, 证明了近红外光谱分析技术可以用于油页岩含油率的检测。 王智宏等[6]对模拟的油页岩样本筛选特征波长后利用近红外分析建立多元线性回归(MLR)模型进行含油量检测。 张福东等[4]采用径向基核函数的支持向量机、 偏最小二乘和BP神经网络油页岩含油率进行建模分析对比, 结果表明经过异常样本剔除的径向基核函数支持向量机模型能够达到较优的预测结果。 以上研究表明, 利用近红外光谱结合建模分析检测油页岩含油率是可行的。
目前, 基于近红外光谱的建模分析中, 大部分学者以某种单一方法建立回归和分类模型, 为了提高模型的预测性能, 常常在光谱预处理或模型超参数优选等环节对模型进行优化。 但是, 基于单个学习器所建立的模型的泛化能力或鲁棒性提升空间有限。 比如, 随机森林[7]、 支持向量机[8]等非线性建模方法尽管具有一定的抗噪声能力, 但是这类非线性模型在一定程度上容易出现过拟合。 梯度提升决策树和偏最小二乘回归等线性模型尽管处理线性问题展现出拟合度高的优势, 但是对高维非线性问题的表现性能往往不尽人意。 几年来, 一些研究将多个单一学习器以一定的策略组合, 构成集成模型, 以提高学习器解决问题的能力。 研究结果表明, 基于多个单一学习器的集成学习模型往往可以获得比单一学习器更优越的泛化性能或鲁棒性[9, 10], 并且能在保证集成学习系统性能的前提下, 选择一组最佳子学习器来提高学习系统的效果。
常见的集成策略有投票法、 Boosting、 Bagging、 Stacking, 投票法主要用于分类问题, Boosting和Bagging所集成的弱学习器一般是同类型的, 即同构集成模型。 Stacking属于一种异构学习器集合方法, 即利用不同类型的弱学习器进行组合, 使各学习器之间取长补短、 优势互补, 以此来提高模型预测的准确性。 Stacking集成策略由Wolpert[11]提出, 是一种异构串行学习器, 由多个初级学习器作为第一层预测模型, 一个次级学习器作为第二层预测模型。 将初级学习器的预测结果作为次级学习器的输入再次进行训练, 得到结果为最终的预测结果。 目前大多数研究都是建立单一模型对近红外光谱进行定量分析, 本研究尝试在基于RF、 CARS等降维方法对油页岩光谱数据进行特征波长提取的基础上建立基于Stacking的异构集成学习模型, 将常见的典型的SVM和RF等非线性学习方法和PLS和梯度提升决策树(GBDT)等非线性异构模型进行组合, 期望能够提高油页岩含油率模型的预测效果, 快速便捷地检测油页岩含油率, 减少检测的试错风险和成本。
1.1.1 样本
实验样本取于大庆油田松辽盆地某区块岩芯, 共取230个块状油页岩岩芯, 对采集的岩芯样本在测量和分析前进行密封处理并使用液氮低温保存。 使用低温干馏法测量每个样本含油率数据, 所有样本的含油率统计特性分布如表1所示。
| 表1 含油率统计特性 Table 1 Oil content statistical characteristics |
1.1.2 光谱数据采集
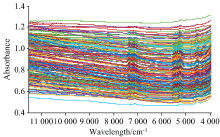
对所取的230个块状岩芯样本使用傅里叶变换近红外光谱仪TANGO(德国BRUKER公司)进行光谱数据采集, 波数范围为11 542~3 940 cm-1, 分辨率是8 cm-1。 由于采集到的油页岩样本多为块状, 且大小不均, 为了保证样本的均质性, 将样本粉碎, 通过60目筛的油页岩样本装袋密封待测。 每个样本扫描32次取平均值作为最终光谱数据, 如图1所示为230个岩芯样本的光谱数据; 从图1可以看出, 由于岩芯颜色较深, 因此光谱吸光度整体较高, 导致吸收峰不够突出, 且由于来自不同底层的岩芯颜色变化较大, 基线漂移严重。 在7 300、 5 200和4 500 cm-1波数附近有明显的吸收峰, 8 800 和4 200 cm-1附近有少量吸收峰。 这些吸收峰与芳烃和CH3伸缩振动的倍频峰以及CH2变形伸缩振动的合频峰一致。
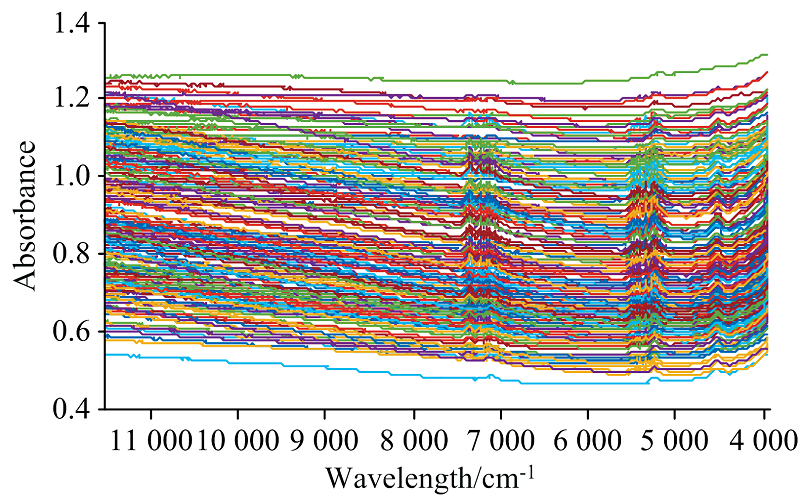 | 图1 原始光谱图Fig.1 Original spectra |
由于实验环境和实验条件等限制, 油页岩的物理和化学性质测量、 光谱曲线获取等环节均有可能存在较大误差, 导致个别样本测量值偏离真实值较大, 所以需要对这类异常样本进行识别并剔除, 以提高模型预测的准确率。 使用蒙特卡洛交叉验证法[12](Monte Carlo cross validation, MCCV)结合PLSR模型对异常样本进行判别和剔除, 该方法通过随机采样建立大量的PLS模型进行内部交叉验证, 不仅可以检测近红外光谱波段和含油量的异常值, 而且还能检测到它们共同的异常值, 因此使用该方法能够有效剔除异常样本。
在光谱采集的过程中固体颗粒物散射会对近红外漫反射光谱产生影响, 而标准正态变量变换(standard normal variate correction, SNV)可以有效消除固体颗粒物产生的影响。 考虑到Savitzky-Golay(S-G)卷积平滑能够有效地消除噪声影响, 一阶导数(1st derivative), 二阶导数(2nd derivative), 基线校正(baseline correction, BSC), 去趋势(detrend, DT)算法是光谱预处理中常用的消除基线和去除其他背景干扰的方法。 本研究尝试用这些方法对岩芯光谱数据进行预处理, 从中选出效果较优的预处理方法。
随机森林回归算法对变量随机加入噪声, 通过计算加入噪声后与原变量的均方误差(mean square error, MSE)下降量来衡量波长的重要性, 从而去除冗余特征, 挑选出与含油率具有良好响应关系的特征波长。 随机森林特征波长优选结果虽然能够有效去除冗余信息, 但是筛选出来的波长仍然相对较多。 而竞争自适应重加权(competitive adaptive reweighted sampling, CARS)算法通过PLS模型回归系数权重的大小来衡量波长的重要性, 能得到较少的特征波长组合而且消除了波长间共线性的影响。 由于RF波长提取可以在不增加运算复杂度的情况下, 对波长进行重要性评价, 而这一优势恰好可以弥补CARS算法重复采样而导致效率降低的问题。 所以将RF去除冗余特征后的波长再使用CARS算法进行二次特征波长提取, 能够在保留重要波长的基础上去除噪声干扰, 从而降低数据维度, 精简模型, 提高模型运行效率。
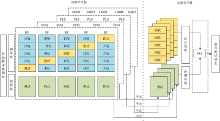
基于Stacking的集成学习的初级学习器模型要同时满足多样性和预测的准确性, 即各学习器不仅要有较好的预测准确性而且还要存在一定的差异, 这样才能使得各学习器能够相得益彰、 优势互补达到更好的预测结果。 为了满足这两点要求, 第一层预测模型选择学习能力强且差异性大的SVM, PLS, RF和GBDT的四个回归模型作为初级学习器。 其中, SVM对于非线性小样本的预测能力较好, PLS在处理线性回归问题上能有较好的预测结果。 RF和GBDT是分别基于bagging思想和boosting思想的以决策树为基础的集成学习算法, 具有很好的泛化性, 不易过拟合。 次级学习器选择简单稳定的模型能够有效地提高预测精度避免过拟合风险, 故选择PLS作为次级学习器对模型进行集成。 基于Stacking集成学习的油页岩含油率预测模型框架如图2所示。
 | 图2 基于Stacking的集成学习框架Fig.2 Ensemble learning framework based on stacking |
算法的具体步骤为: (1)将原始样本集按比例划分为训练集和测试集。 (2)各个初级学习器按照5折交叉验证进行建模, 每个初学习器将其中的1份作为测试集, 剩下的作为训练集。 使用5折训练集训练每个初级学习器, 并对5折测试集进行预测, 所有初极学习器的预测结果作为次级学习器训练集。 (3)原始测试集放入初级学习器进行预测, 将得到的预测结果平均后作为新的测试集。 (4)将新的训练集和新测试集放入次级学习器进行训练得到的预测结果为最终预测结果。
通过计算模型预测值和真实值之间的决定系数(R2)和均方根误差(RMSE)的大小来判别模型的好坏, 通常R2越接近1, RMSE越小, 说明模型的预测效果越好。
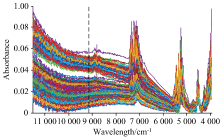
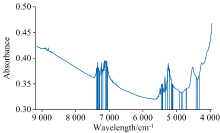
将不同预处理方法处理后的光谱数据建立PLS交叉验证模型, 通过模型的回归系数(R2)和均方根误差(RMSE)的大小来衡量光谱数据预处理的优劣(表2)。 其中, 序号为1的FULL表示未经异常样本剔除的样本集建模结果, 序号为2的模型为采用MCCV剔除样本后的模型结果, MCCV重复采样100次, 采用5折交叉验证, 模型保留7个主成分, 共计剔除17个异常样本。 序号3— 10的模型是在MCCV剔除异常样本之后采用不同的预处理方法得到的模型的结果。 从表中可以看出基于去趋势和基线校正(序号10)的预处理方法相较于其他方法效果最好, 这是因为原始光谱曲线存在较为严重的基线漂移(图1), 对于光谱数据建模存在较大影响, 因此DT+BSC算法效果较明显。 图3是DT+BSC算法预处理后的光谱数据, 从图中可以看出, DT+BSC方法能够有效地处理光谱数据基线漂移以及噪声干扰, 从而提高模型的效果。 此外, 预处理后的数据在波段11 542~9 156 cm-1没有明显的吸收峰且存在较为严重的噪声, 所以后续研究将使用去除11 542~9 156 cm-1波段的数据, 剩余1 265个波长。
| 表2 不同预处理方法的建模结果 Table 2 Modeling results under different pretreatment methods |
 | 图3 DT+BSC预处理结果Fig.3 The results pretreated by DT+BSC |
将剔除异常样本和预处理后的213个样本数据按照训练集和测试集3∶ 1的比例随机划分, 总体样本被划分为160个训练集样本和53个测试集样本。
2.2.1 RF衡量波长重要性
使用网格寻优算法寻找到随机森林参数的最优组合是决策树500棵、 决策树最大深度为110、 叶子节点最小样本数为1, 将寻优后的参数代入模型。 计算每个波长的均方根误差(MSE)下降量, 并以此作为衡量波长重要性的指标。 将波长按照MSE下降量的大小进行降序排列, 设置阈值为0.2, 将MSE下降量0.2以下的波长剔除, 剩余407个波长作为RF波长选择的结果。 图4为优选后的波长结果, 从图中可以看出, 重要性高的波长点大都在光谱波峰附近。 但是一二倍频的合频区域(6 000 cm-1附近)有大量波长被选择, 保留的波长相对较多, 仍有部分信息量少的波长被保留了下来。
 | 图4 基于RF建模优选的波长结果Fig.4 Optimal wavelength selection results based on RF modeling |
2.2.2 CARS特征波长选择结果
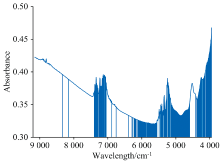
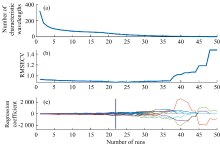
通过CARS算法对经过RF提取特征波长后的变量再次提取, 具体表达结果如图6所示。 其中, 图5表示特征波长数[图5(a)]、 RMSECV[图5(b)]和回归系数[图5(c)]随着运行次数变化的过程。 从图中可以看出, 随着运行次数的增加, 特征波长数由快速减少到缓慢减少, 这是CARS算法由粗选到优选的过程, RMSECV的值由高到低再升高, 在运行到第22次时达到最低点, 随后呈上升趋势, 这是由于新引入的波长含有更多的冗余信息, 导致模型精度降低。 回归系数的路径图随着运行次数的增加路径逐渐变得离散, 结合RMSECV的变化分析发现, 图中蓝色竖线位置RMSECV最小, 回归系数的路径相对集中。 此时选择的36个光谱波长集合为最优波长组合, 其波长分布如图6所示, 所选波长基本在吸收峰或者吸收峰附近。 经过CARS波长选择之后, RF选择结果中没有明显吸收峰而被选择的波长(6 000 cm-1附近)均被CARS算法滤除, 特征波长和光谱曲线的吸收峰的对应关系更加明显。
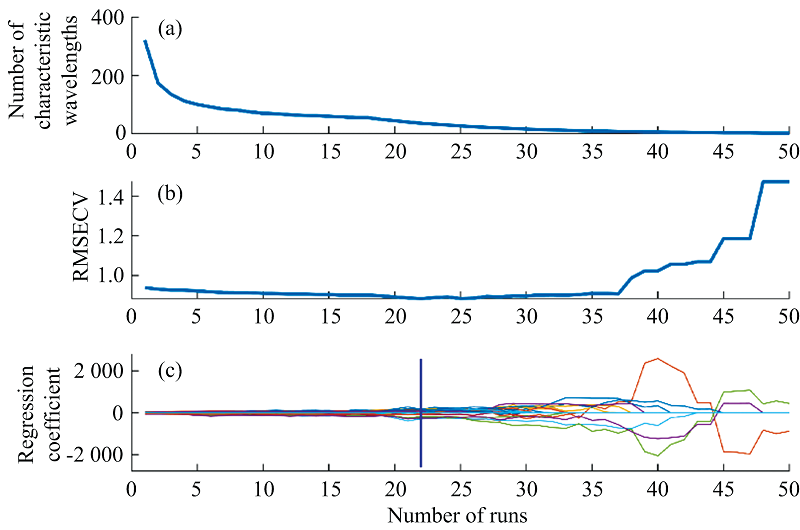 | 图5 CARS算法筛选特征波长的过程Fig.5 The process of selecting characteristic wavelengths by CARS algorithm |
 | 图6 CARS算法筛选的特征波长Fig.6 Characteristic wavelength filtered by CARS algorithm |
由于RF回归模型能够对波长选择结果进行有效评价, 建模结果可以体现波长筛选的效果[13], 因此使用RF回归模型对RF+CARS波长选择结果进行评价, 并与全谱、 RF波长选择结果、 CARS波长选择结果进行对比。 不同波长选择结果的RF回归模型性能参数如表3所示。 其中, RF模型参数为默认参数(树数量为10)。 由表3可知, 所有经过波长选择之后的模型性能参数优于全谱模型。 经过RF衡量后的重要波长仍然可能存在噪声信息和共线波长, 而CARS算法能够对噪声和共线波长进行有效淘汰。 故对RF衡量过的波长使用CARS算法进行二次筛选能够表现出更好的效果。 从建模结果可以看出, 经过RF-CARS进行特征波长筛选后, 波长数量下降的同时, 模型的精度也有所提升。 说明RF-CARS可以有效地对油页岩含油率的近红外光谱进行波长提取, 并表现出良好的效果。
| 表3 波长选择后的建模结果 Table 3 Modeling results after wavelength selection |
2.3.1 油页岩含油率的分析结果
利用去趋势结合基线校正方法对油页岩含油率的原始光谱数据进行预处理, 将RF+CARS优选出的有效光谱特征变量作为Stacking 集成学习的输入样本。 为了验证Stacking集成学习模型预测结果可靠性, 以R2和RMSE值为评价指标, 将Stacking集成学习模型与SVM, RF, GBDT和PLS四种单一模型进行分析, 比较模型性能优劣。 使用网格搜索对各初级学习器模型进行调参, 其中支持向量机模型惩罚因子为810.35, gamma为0.016 7。 随机森林模型决策树数目和叶子节点最小样本数参数分别为685和1。 梯度提升决策树设定决策树参数为13 200、 学习率为0.000 1、 最大深度为5。 作为次级学习器的偏最小二乘模型主成分个数设定为7。 Stacking 集成学习预测模型实验结果如表4所示。
| 表4 单一模型与Stacking模型对比 Table 4 Performance comparison between the single models and the Stacking model |
从表4可以看出, 组合模型的训练集和预测集对油页岩含油率定量分析都取得了较好的效果。 其中, 组合模型的
2.3.2 不同模型结果比较
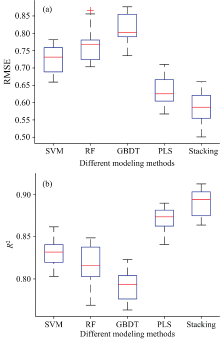
按照3∶ 1的比例随机划分油页岩含油率样本集100次, 对每次划分的样本集分别建立SVM, RF, PLS和GBDT四个单一学习器模型以及Stacking集成学习模型。 图8为100次划分样本集后不同模型预测集R2和RMSE的箱线图。
图7中SVM, RF, GBDT, PLS, Stacking各模型的R2中位数分别为0.830 3, 0.807 5, 0.791 3, 0.871 0和0.893 5。 与其他单一预测模型相比, Stacking集成学习模型决定系数R2的中位数最高。 Stacking的RMSE的中位数为0.586 9, 对比于SVM, RF, GBDT和PLS分别降低了0.138 1, 0.177 6, 0.225 6和0.047 5。 从箱线图的大小来看Stacking模型能够相对稳定地对油页岩含油率进行预测, 即该模型具有较好的鲁棒性。 以上结果表明, Stacking集成学习模型可以结合各初级学习器的优势从而表现出比单一模型更好的性能, 在一定程度上提高了预测能力。 能够更好地对基于近红外光谱的油页岩含油率进行预测。
 | 图7 单一学习器与集成学习预测结果的比较Fig.7 Comparison of prediction results between single learner and ensemble learning |
基于Stacking集成策略对模型融合, 将SVM, RF, GBDT和PLS模型作为初级学习器, PLS模型作为次级学习器进行堆叠。 虽然各单一模型效果差别不大, 但组合后的模型效果明显优于各单一模型, 该结果与蒋薇薇等[14]将集成学习算法在近红外光谱定量分析领域中应用的研究结果相一致。 从单一模型的评价指标看PLS模型的表现最好, RF和GBDT是基于决策树构成的模型, 能够寻找决策树最优的线性组合, 可以灵活处理各种数据, 平衡误差, 减少误差值的影响。 SVM通过高维空间映射能够避免过拟合问题能够提升模型的泛化性。 以上4个模型在表现性能上各有优劣, 但是单独预测的效果不够理想。 Stacking集成模型打破了传统模型单一性的局限, 提升了预测模型的准确率和泛化性, 从而表现出更好的效果。
基于Stacking集成学习算法建立了油页岩含油率近红外定量分析模型, 进行油页岩含油率预测分析。 首先, 对采集的近红外光谱数据进行处理, 使用MCCV剔除异常样本, DT+BSC方法对光谱数据预处理, 在消除噪声的同时减少无关信息对模型的干扰。 其次, 为了降低数据维度去除冗余信息保留重要信息, 利用随机森林对波长进行重要性评价后再使用CARS算法进行特征波长提取。 最后, 建立了以RF, GBDT, PLS和SVM为初级学习器, PLS为次级学习器的Stacking集成学习模型。 研究结果表明, Stacking集成学习模型相比于单一模型对油页岩含油率预测表现出了较好的性能和鲁棒性, 说明本方法在油页岩含油率近红外光谱分析方面是可行的。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|