{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于波段选择的烟草病害检测模型
[潘兆杰1  , 孙根云
, 孙根云1, 2, * , 张爱竹1 , 付航1 , 王新伟3 , 任广伟3 ]
, 孙根云, 张爱竹|
|


作者简介: 潘兆杰, 1999年生, 中国石油大学(华东)海洋与空间信息学院硕士研究生 e-mail: panzhj99@163.com
烟草是我国重要的经济作物, 税收的重要来源, 为国家的经济发展做出了巨大贡献, 然而, 烟草病害严重影响烟叶产量与品质。 采用光谱分析技术对烟草病害进行早期防治具有非常重要的现实意义。 以接种烟草花叶病毒(TMV)与马铃薯Y病毒(PVY)的烟草为研究对象, 分别采集室内与室外培养的染病烟草叶片高光谱数据。 为实现对烟草病害的精准识别, 每隔两天对两种染病烟草进行光谱数据采集, 将每种病害数据详细地分成五个严重度等级, 最终获得1 697个在350~2 500 nm波段范围内的光谱数据。 为对烟草高光谱数据进行有效利用, 以支持向量机(SVM)为基础, 结合快速近邻波段选择算法(FNGBS)与归一化匹配滤波(NMFW), 提出一种聚类与排序相结合的波段选择算法(FNG-NMFW)。 FNG-NMFW首先采用FNGBS算法对烟草光谱进行精细分组, 再采用NMFW算法对各组波段进行排序以选择特征光谱, 实现烟草光谱特征提取与降维。 在波段选择的基础上, 采用SVM对烟草特征光谱进行分类, 最终实现高精度烟草病害检测。 研究结果显示: 该模型性能稳定, 在样本数量较少情况下, 即可实现TMV与PVY两种病害的高精度识别。 对于TMV1与TMV3, 该算法可以获得精度优于94%的检测结果, 对于PVY1与PVY3, 该算法精度接近90%, 表明该算法可有效完成两种病害早期的识别与预防工作。 与采用全波段光谱数据进行病害检测的模型相比, FNG-NMFW模型优势明显, 烟草病害检测结果总体精度达94.46%, 精度提高约1.5%, 检测时间由12.9 s缩短为1.1 s。
Tobacco is an important economic crop and source of tax revenue in our country. It makes a huge contribution to the country’s economic development. However, tobacco diseases affect the yield and quality of tobacco leaves seriously. Therefore, It is important that the use spectral analysis technology for early prevention and control of tobacco diseases. Objects of research are tobaccos inoculated with tobacco mosaic virus (TMV) and potato Y virus (PVY). The hyperspectral data of infected tobacco cultivated indoors and outdoors are collected respectively. In order to improve the detection accuracy of tobacco diseases, spectral data of two kinds of diseased tobacco are collected every two days, each disease data is divided into five severity levels in detail, and finally, 1 697 spectral data in the 350~2 500 nm band are obtained. In order to make effective use of hyperspectral tobacco data, this paper is based on a support vector machine (SVM), combined with a fast nearest neighbor band selection algorithm (FNGBS) and normalized matched filtering (NMFW), and proposes a combination of clustering and sorting Band selection algorithm (FNG-NMFW). Firstly, FNG-NMFW uses the FNGBS to group the tobacco spectrum finely and then sorts the groups of bands based on the NMFW algorithm to select the characteristic spectrum and realize the extraction and dimensionality of the tobacco spectrum. After completing the band selection, this paper uses SVM to classify tobacco characteristic spectra and achieves high-precision tobacco disease detection. The research results show that the model has stable performance and high accuracy. When the proportion of training samples is only 40%, an overall accuracy (OA) is better than 80%; when the number of feature bands is selected as 40, OA can be better than 85%. The algorithm can achieve higher accuracy for both TMV and PVY diseases, but the recognition accuracy of TMV is slightly lower than that of PVY. For the monitoring of TMV1 and TMV3, the algorithm can achieve monitoring with an accuracy better than 94%, and for the monitoring of PVY1 and PVY3, the accuracy of the algorithm is close to 90%, which shows that the algorithm can realize the early identification and prevention of two diseases. Compared with the model that uses full-band spectral data for disease detection, the FNG-NMFW model has obvious advantages. The accuracy of tobacco disease detection results is 94.46%, the accuracy is improved by more than 1.5%, and the modeling time is shortened from 12.9 seconds to 1.1 seconds.
烟草是重要的经济作物, 是我国经济税收的重要来源, 为我国经济发展做出巨大贡献[1]。 烟草花叶病毒病(tobacco mosaic virus, TMV)与马铃薯Y病毒病(potato virus Y, PVY)是烟草上的重要病害, 严重影响烟叶产量与品质。 目前, 烟草病害检测方法主要依靠人工田间调查[2], 该类方法费时、 费力。 开发一种快速、 高效的烟草病害检测方法对于防治烟草病害, 提高烟叶产量与品质至关重要。
随着遥感图像光谱分辨率的提高以及数据处理能力的不断增强, 高光谱遥感被逐渐应用到国民生产与生活中。 高光谱遥感可以在不损害农作物的情况下完成监测, 且检测精度较高, 获得国内外学者的广泛关注。
孙俊等[3]基于油麦菜高光谱数据, 采用竞争自适应加权与支持向量回归机建立判别模型, 实现了油麦菜叶片中水分的检测。 有研究采用傅里叶变换等方法实现农作物条锈病检测。 雷雨等[4]利用主成分分析(principal component analysis, PCA)与最大类间方差法(OTSU)进行建模, 实现了对小麦条锈病的分级检测。 王小龙等[5]采用高光谱技术, 融合PCA与支持向量机(support vector machine, SVM), 实现了棉田虫害检测。
高光谱在烟草领域的研究起步较晚, 但是由于烟草在国民经济中的重要地位, 其发展较为迅速[1]。 吕小艳等[6]采用微分技术估测烟叶SPAD值。 刘勇昌等[7]建立一元线性回归模型, 实现对PVY的检测。 然而由于数学回归模型的局限性, 该方法无法充分挖掘烟草光谱特征。 为提高检测精度, 部分学者引入指数法。 李梦竹等[8]基于光谱指数构建烟叶钾含量预测模型, 模型决定系数R2达0.93。 王帅等[9]利用植被指数建立非线性回归模型用于烟草估产。 杨艳东等[10]利用植被指数实现烟草叶片氯密度预测。 光谱指数法虽然在烟草相关领域获得良好表现, 但植被指数库的构建难度较高。 基于机器学习的方法能够挖掘数据的深浅层特征, 部分学者将其引入烟草领域。 陈楠等[11]利用反向传播网络分析烟草光谱数据, 实现了烟草叶片中镉含量的检测。 朱洋等[12]利用人工蜂群算法(artificial bee colony, ABC)优化SVM, 提升了烟草蛙眼病与赤星病的判别精度。 谢裕睿等[13]基于残差网络进行烟草病害检测。 上述基于机器学习的算法实现烟草病害检测精度的提升, 但由于高光谱存在数据冗余, 检测精度仍难以满足精准防治的要求。
已有算法虽通过采用数学回归法, 指数法以及机器学习算法使得检测精度不断上升, 但在模型泛化性, 运行效率以及精度等依然存在不足。 本文针对TMV和PVY, 提出了一种新的聚类与排序相结合的波段选择方法(FNG-NMFW), 并结合SVM构建了烟草病害检测模型。 该方法能够有效解决光谱冗余问题, 实现烟草病害的高精度高效率检测。
感染TMV与PVY两类病害的烟草样本由中国农业科学院烟草研究所提供。 供试烟草为分别在室内与室外培养的普通烟草品种K326。 室外种植区位于青岛即墨试验基地(N36° 26'52.54″, E120° 34'55.24″), 海拔高度为54.47 m, 四季变化和季风进退比较明显。 室内培养条件, 如表1所示。 待烟草植株长到7~8片叶期(生根期), 将TMV与PVY两种病毒分别接种于烟草植株上, 烟草接种病毒7 d之后开始测量烟草光谱数据。
| 表1 室内培养条件表 Table 1 Indoor culture conditions |
采集感病烟草光谱数据的仪器为美国ASD公司生产的Field Spec4便携式地物光谱仪, 光源采用光谱仪自带的卤素灯。 该套设备可测量的光谱范围是350~2 500 nm, 采样间隔为1 nm。 光谱采集过程中, 每株烟草视为一个样本。 为保证测量的是叶片表征范围, 测量时使光谱仪的探头对准烟草叶片中间, 保持仪器与待测叶片之间距离固定。 为降低测量时的偶然误差, 在测量一个样本时, 分别于烟株上、 中、 下叶位选择一片叶片, 每个叶片按照叶基、 叶中和叶尖部位(避开叶脉)进行光谱测量, 最终将所获光谱取平均得到一个样本数据。
数据采集过程中, 每隔2 d观察一次烟株病情进展, 根据《GBT-23222— 2008 烟草病虫害分级调查方法》, 对感染TMV与PVY的烟草按严重程度分成0, 1, 3, 5, 7和9六个等级, 其中0级表示健康烟草。 数据采集结束后共获11类, 累计1 697条合格的烟株样本, 各类样本数量如表2所示。 训练集主要选择室内数据, 测试集主要选择室外数据。 训练集比例为75%, 训练集与测试集配置如表3所示。
| 表2 样本数量介绍 Table 2 Introduction to the number of samples |
| 表3 训练集与测试集配置 Table 3 Configuration of training set and test set |
为了减少随机误差, 更好地分析感病烟草光谱, 首先对每类光谱数据进行平均处理, 处理公式如式(1)所示
${{R}_{i,\text{mean}}}=\frac{1}{{{N}_{i}}}\overset{{{N}_{i}}}{\mathop{\underset{j=1}{\mathop \sum }\,}}\,{{R}_{i,\text{ }\!\!~\!\!\text{ }j}}$(1)
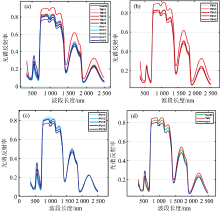
式(1)中, i(i=1, …, k)为病害编号, Ni为第i类样本的数量。 Ri, j为病害编号为i的第j个样本的高光谱数据。 经过平均处理, 共获得11条光谱曲线, 分别在图1(a— c)中展示。 为分析不同病害之间的差异, 同时对各类病害数据进行平均处理, 相应曲线如图1(d)所示。
 | 图1 烟草光谱曲线图 (a): 不同种感病烟草光谱曲线图; (b): 感染TMV烟草的不同严重度等级光谱曲线图; (c): 感染PVY烟草的不同严重度等级光谱曲线图; (d): 健康及感染TMV、 PVY病害的烟草光谱曲线图Fig.1 Spectrum curve of tobacco (a): Spectral curves of different kinds of susceptible tobacco; (b): spectral curves of different severity levels of TMV infected tobacco; (c): spectral curves of different severity levels of PVY infected tobacco; (d): spectral curves of healthy and TMV and PVY infected tobacco |
由图1(a)可知, 感病烟草光谱曲线整体上保持近红外波段高反射、 红波段强吸收的光谱特性; 在部分光谱范围内, 不同感病烟草光谱曲线相似性高, 不易区分。 由图1(b)可知, 不同严重度的TMV烟草在1 600~1 800 nm范围内差异较大。 由图1(c)可知, 不同严重度的PVY烟草在500~700 nm范围内差异较大。 综上, 感病烟草光谱数据存在较高的冗余, 仅在少数波段存在较强的区分性, 因此必须进行数据降维。
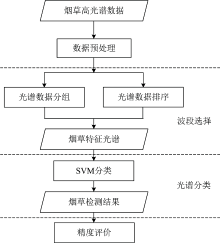
提出的FNG-NMFW算法流程如图2所示, 一共包含三个步骤: 采用FNGBS[14]对烟草高光谱数据进行精细分组, 之后根据NMFW[15]确定的权重系数选择各波段组特征波段, 最后采用SVM进行特征分类, 实现感染TMV与PVY烟草的精准检测。
 | 图2 烟草病害检测方法流程图Fig.2 Flowchart of tobacco disease detection method |
为了将FNGBS应用到烟草病害检测, 首先构建离散烟草高光谱数据X={x1, x2, …, xi, …, xL}T∈ RL× N, 其中xi为各样本数据在第i个波段处的反射率, N为样本的数量, L为波段数。
首先设置波段分组数M, 即输入SVM的特征波段数。 高光谱分组共分为两步: 粗分组与精细分组。 粗分组的原则是使各波段组包含的波段数尽可能相等, 因此各组别之间的分割波段可由式(2)表示
式(2)中, mod(· , · )为取余操作, 按照算法G(m)的原则, 最终粗分组结果{X'm
在进行精细分组之前, 需要引入一个辅助参数pm, pm可以根据式(4)获得。
${{p}_{m}}=\left\lfloor m\times \frac{L}{M}-\frac{L}{2M} \right\rfloor , \text{ }m=1, 2, \cdots , M$ (4)
则
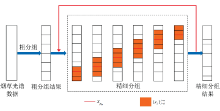
获得各波段组的${{x}_{{{p}_{m}}}}$之后就可以进行精细分组操作。 首先基于欧氏距离计算xi与xj之间相似性, 其中i, j=1, 2, …, L, 并构建相似矩阵DL× L。 判断D(${{x}_{{{p}_{m}}}}$ , xj)是否小于R(j)(初始值设为无穷大), 其中a≤ j≤ b。 若D(${{x}_{{{p}_{m}}}}$ , xj)< R(j)则使R(j)=D(${{x}_{{{p}_{m}}}}$ , xj), 并利用向量T1× L记录对应波段所属波段组m, 即T(j)=m。 将迭代总数设为n, 重复上述步骤。 待迭代次数等于n或向量T不再改变, 停止处理。 最终根据标签向量T, 选择每个波段组中最长波段对应的索引作为新分割波段, 以获得精细分组结果分组流程如图3所示。
 | 图3 烟草高光谱分组流程图Fig.3 Flowchart of Tobacco Hyperspectral fine grouping |
在进行精细分组的同时, 需要利用NMFW计算波段重要性, 以此选择每个波段组中的最佳波段。 在计算NMFW时, 首先将数据矩阵X转置, 此时X=[X1, X2, X3, …, Xd, …, XN]T, 1≤ d≤ N, 其中Xd=[xd, 1, xd, 2, …, xd, L]代表第d条样本的光谱数据。
NMFW算法的核心是式(6)
式(6)中,
已知滤波器w, 以及光谱数据X={x1, x2, x3, …, xL}T∈ RL× N。 光谱数据经过滤波器, 获得输出Y, 可由式(7)表示
由式(7)可知, Y为L条波段数据的加权和。 其中第j个权重的绝对值|wj|代表第j个波段对于Y的重要性。
为减少劣质波段对检测结果的影响, 需要对烟草高光谱数据进行标准化。 首先定义一个标准化矩阵A, 如(8)式。
式(8)中, A是一个N维对角矩阵, 对角线(d, d)处对应的参数是第d条样本数据的2范数的倒数。 之后利用$\tilde{X}=AX$, $\tilde{m}'=\frac{1}{N}\overset{N}{\mathop{\underset{d=1}{\mathop \sum }\, }}\, {{\tilde{X}}_{d}}$计算参数$\tilde{X}$和$\tilde{m}'$。 基于上述参数可获得标准化常数$\tilde{\kappa }$与标准化权重$\tilde{w}$。
由于共有N条样本, 为分析各波段对整体检测结果的影响, 引入标准化权重的绝对值的平均值$|\tilde{w}{{|}_{avg}}$, 如式(9)
$|\tilde{w}{{|}_{\text{avg}}}=\frac{1}{N}\overset{N}{\mathop{\underset{d=1}{\mathop \sum }\, }}\, |{{\tilde{w}}_{d}}|$ (9)
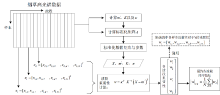
在完成$|\tilde{w}{{|}_{avg}}$计算之后, 对各个波段进行降序排序, 每个波段获得唯一的序号。 NMFW算法流程如图4所示。 而最终获得的特征光谱即为各波段组中最小序号对应的波段。
 | 图4 烟草高光谱排序流程图Fig.4 Flowchart of Tobacco Hyperspectral sorting |
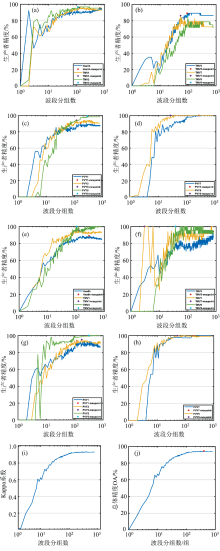
波段分组的数目会影响最终的波段选择数量, 因此, 首先研究不同波段分组数对检测结果的影响。 实验样本共有2 151个波段, 波段分组数变化范围为[2, 800], 不同分组数的检测结果如图5(a— j)所示。
 | 图5 波段分组实验结果图 (a), (b), (c), (d)表示不同感病样本的生产者精度分类结果, (e), (f), (g), (h)是用户精度(UA)分类结果, (i), (j)感病烟草总体Kappa系数与OA随波段分组数的变化图Fig.5 Experimental results of band grouping (a), (b), (c) and (d) show the producer accuracy (PA) of tobacco disease detection algorithm; (e), (f), (g) and (h) show the user accuracy (UA) of tobacco disease detection algorithm; (i) and (j) show the kappa and OA oftobacco disease detection algorithm |
由图5可知, 随着波段分组数的上升, 各类样本检测精度整体呈上升趋势, 且在波段分组数较少时上升较快。 OA在特征光谱数仅为20时即已突破80%。 除此之外, 当特征光谱数上升到一定数量之后, TMV1(PA), Health(UA)以及PVY1(UA)随特征光谱数上升而下降。 这表明少量光谱即可实现较高精度的病害检测, 光谱数量过多反而不利于烟草病害检测。 因此, 选择特征光谱对于烟草病害精准防治是必要的。
为选择合适的波段分组数, 提取了各类变化曲线的关键节点, 如表4所示。 表4中精度指标的最大值点表示该指标第一次取得最大值时对应的分组数; 平稳点为精度趋于平稳时对应的波段分组数, 当波段分组数选择大于平稳点时, 指标变化小于3%。 最优波段分组数的选择基于以下标准: (1)对应较高的检测精度。 (2)从稳定的曲线中选择。 (3)能够兼顾其他类别的精度。 (4)满足以上条件的最小波段分组数。
| 表4 各参数曲线关键点 Table 4 Key points of each parameter curve |
为使选择最佳波段分组数时各类别均可获得较高精度, 将最大值点和平稳点的最大值作为候选最优波段分组数。 当最大值点小于平稳点时, 最大值点可能具有偶然性, 因此首先排除此类最大值点。 TMV5(UA)变化曲线无平稳点, 因此, 最大平稳点无法代表全部病害检测精度。 OA以及Kappa系数的最大值点相同, 不妨选取OA的最大值点。 综上, 最终将674与397作为候选最佳波段分组数, 基于候选最佳波段分组数获得的结果如表5所示。
| 表5 不同候选波段分组数烟草病害检测精度比较 Table 5 Comparison of tobacco disease detection accuracy of different candidate band group numbers |
由表5可知, OA的最大值点在精度、 稳定性以及建模时间上均获得最优结果。 为实现烟草病害精准识别, 采用OA的最大值点对应的分组数— — 397作为最终波段分组数。
为了分析FNG-NMFW算法的性能, 将其与全波段病害检测算法进行对比。 两个模型均采用SVM分类器, 核函数参数C与σ 由网格搜索法获得, 分别为102和2-3。 实验结果如表6所示。
| 表6 不同波段选择方法下的SVM建模结果 Table 6 SVM modeling results under different band selection methods |
由表6可知, 全波段病害检测算法的OA为92.80%, FNG-NMFW达94.46%。 在运行效率上, 相较于全波段算法, 虽然FNG-NMFW增加了波段选择步骤, 但是由于选择的波段较少(特征光谱数由2 151减为397), 大大提高了运行效率, 数据处理时间由12.9 s降到1.1 s。 综上所述烟草病害检测算法更有助于实现高精度烟草病害检测。
由表6中各类样本的检测精度可知, 虽然全波段分类在Health类别的精度高于FNG-NMFW算法, 但是在实际生产中, 烟草患病种类与患病等级的精准识别对烟草病害的精准防治至关重要。 可以看到, FNG-NMFW算法在不同患病等级的烟草检测上均优于全波段分类算法。 由图1(a)可知, 处于患TMV与PVY不同阶段的烟草的光谱曲线差别较小, 因此具有较高的检测难度。 但是, 通过特征光谱的选择, 本算法能够对不同病害种类进行有效识别, 对早期烟草患病等级(患病等级1, 3), 除PVY1的89.3%外, 其余患病等级检测均高于93%。 因此, FNG-NMFW具有较好的实用价值。
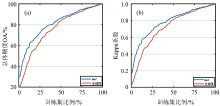
为进一步验证FNG-NMFW的稳定性, 将其与全波段算法在1%~100%的训练集比例下进行实验, 实验结果如图6所示。 当训练集比例较高时, 两算法精度相差较小, 但当训练集比例处于1%~75%时, FNG-NMFW与全波段算法相比具有明显优势。 这说明FNG-NMFW在小样本情况下能够实现精度的有效提升。 在实际生产中, 因训练样本不足而造成烟草病害检测精度较低的问题是普遍存在的, 而FNG-NMFW能够通过选择特征光谱有效缓解这一问题。 因此, FNG-NMFW在烟草病害精准识别领域具有较好的应用前景。
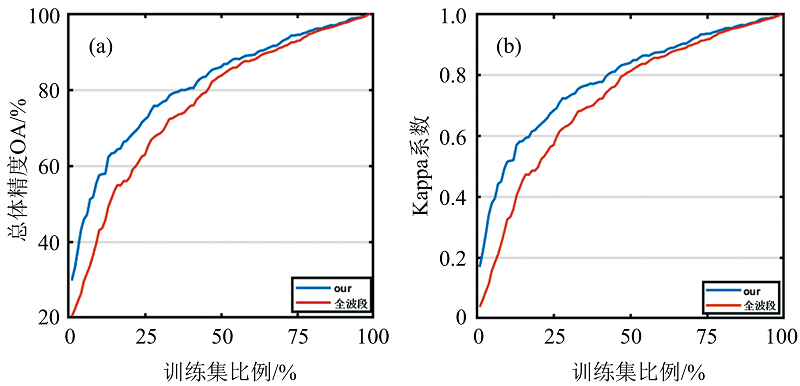 | 图6 不同训练集比例下OA与Kappa系数变化图 (a): OA变化图; (b): Kappa系数变化图Fig.6 Variation chart of overall accuracy OA and kappa coefficient under different training set proportion (a): Overall accuracy variation diagram; (b): kappa coefficient variation diagram |
基于烟草高光谱数据, 结合聚类与排序算法, 提出了一种新的波段选择算法, 并采用SVM算法对病害烟草进行分类, 实现了病害烟草的高精度检测。 主要结论如下:
(1)分组算法根据聚类的原则能够有效地将烟草高光谱数据分成不同的组别, 排序算法可以根据各个波段对最终分类结果的贡献程度对其进行排序。 将两者结合可以获得用于烟草病害检测的高质量特征光谱。
(2)在与全波段算法的对比实验中可知, 将FNG-NMFW获取的特征光谱作为分类器输入, 可有效提升病害检测精度和效率, 并且在训练样本较少的情况下依然可以获得较高的精度。
(3)本工作首次针对严重度详细分级的烟草进行病害检测模型研究, 虽然各级烟草之间的光谱差异较小且存在较为严重的波段冗余, 但是采用波段选择算法进行降维之后, 可以利用SVM实现烟草病害的精准识别。
本算法在部分样本检测结果上精度依然较低。 下一步的工作可通过优化分类算法, 充分挖掘光谱深浅层特征, 进一步提高烟草病害检测精度。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|