
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外光谱结合改进鲸鱼算法优化模型BAS-WOA-SVR检测藤椒油掺伪
[许素安 , 王家祥, 刘勇]
, 王家祥, 刘勇]
, 王家祥, 刘勇]
|
|


作者简介: 许素安, 1975年生,中国计量大学机电工程学院教授 e-mail: xusuan@cjlu.edu.cn
鉴于藤椒油市场良莠不齐, 以近红外光谱技术为基础, 藤椒油为研究对象, 展开对藤椒油掺伪检测研究。 首先将纯藤椒油作为基底油, 按比例配置掺入大豆油、 玉米油、 葵花籽油得到油样, 采集藤椒油掺伪样品的近红外光谱数据; 光谱数据经归一化处理后采用标准正态变换(SNV)、 多元散射矫正(MSC)进行预处理, 然后采用竞争性自适应重加权算法(CARS)、 连续投影算法(SPA)进行特征数据提取, 组合不同预处理算法与特征数据提取算法, 通过支持向量机回归(SVR)建立藤椒油掺伪预测模型。 结果表明: MSC-CARS-SVR模型校正集和预测集的决定系数( R2)最高, 校正集 R2达到了0.756 1, 预测集 R2达到0.705 2; 均方根误差(RMSE)最小, 校正集RMSE达到0.743, 预测集RMSE达到0.794。 为了提高模型的准确性, 采用鲸鱼算法(WOA)和改进鲸鱼算法(BAS-WOA)优化SVR模型, 改进的鲸鱼算法以每一次鲸鱼群的最优鲸鱼作为当前天牛须的出发位置, 分别探索左右须前进, 计算前进后的目标函数, 如果目标函数优于当前最优鲸鱼的值, 则用前进后的天牛位置替换鲸鱼位置, 进而实现了天牛须算子对鲸鱼算法的改进。 用WOA优化SVR模型, 相比之下精度最高的为MSC-CARS-WOA-SVR模型, 校正集 R2达到0.859 1, 预测集 R2达到0.821 6; 校正集RMSE降低到了0.374, 预测集RMSE降低到0.495。 相比于传统的SVR模型精度和性能都有较明显提升。 用BAS-WOA优化SVR模型, 精度最高的是MSC-CARS-BAS-WOA-SVR模型, 校正集 R2高达0.955 1, 预测集 R2高达0.943 9; 校正集RMSE降低到了0.054, 预测集RMSE降低到0.081。 相比于WOA优化算法, BAS-WOA优化的模型精确度和性能都有了进一步提升, 模型预测集 R2从0.821 6提高到0.943 9, 预测集RMSE从0.495降低为0.081。 鲸鱼算法优化SVR模型容易陷入局部极值和收敛速度问题, 改进的鲸鱼算法通过天牛须算法的左右须探寻来改进鲸鱼算法不足, 从而提升算法的全局寻优能力。 研究表明近红外光谱技术结合智能优化算法能有效识别藤椒油掺伪。
Due to the uneven market of rattan pepper oil, based on near-infrared spectroscopy technology, rattan pepper oil is the research object, and the research on the adulteration detection of rattan pepper oil is carried out. First, pure rattan pepper oil was used as the base oil, and the adulterated soybean oil, corn oil, and sunflower oil were prepared in proportion to obtain oil samples. The near-infrared spectroscopy was used to collect the spectral data of the oil samples to obtain the adulterated near-infrared spectral data of rattan pepper oil. The spectral data are normalized and preprocessed by Standard Normal Variation (SNV) and MultivariativeScatter Correction (MSC). And then, the feature data is processed by Competitive Adaptive Reweighting Sampling (CARS) and SuccessiveProjection Algorithm (SPA). Extraction, combining different preprocessing algorithms and feature data extraction algorithms, and establishing a prediction model of vine pepper oil adulteration through Support Vector Machine regression (SVR). The results show that the coefficient of determination ( R2) of the calibration set and prediction set of the MSC-CARS-SVR model is the highest, the calibration set R2 reaches 0.756 1, and the prediction set R2 reaches 0.705 2; the root mean square error (RMSE) is the smallest, and the calibration set RMSE reaches 0.743, The prediction set RMSE reaches 0.794. In order to improve the accuracy of the model, the Whale Optimization Algorithm (WOA) and the Improved Whale Optimization Algorithm (BAS-WOA) are used to optimize the SVR model. The left and right beards are moved forward, and the objective function after the advance is calculated. If the objective function is better than the current optimal whale value, the position of the whale is replaced by the position of the beetle after the move forward, thereby realizing the improvement of the beetle operator on the whale algorithm. When WOA optimizes the SVR model, compared with the MSC-CARS-WOA-SVR model with the highest accuracy, the R2 of the calibration set can reach 0.859 1, and the R2 of the prediction set can reach 0.821 6; the RMSE of the calibration set is reduced to 0.374, and the RMSE of the prediction set is reduced to 0.495. Compared with the traditional SVR model, the accuracy and performance of the SVR model are significantly improved. When BAS-WOA optimizes the SVR model, the MSC-CARS-BAS-WOA-SVR model has the highest accuracy. The calibration set R2 is as high as 0.955 1, and the prediction set R2 is as high as 0.943 9; the calibration set RMSE is reduced to 0.054, and the prediction set RMSE is reduced to 0.081. Compared with the WOA optimization algorithm, the model accuracy and performance of the BAS-WOA optimization have been further improved. The model prediction set R2 is increased from 0.821 6 to 0.943 9, and the prediction set RMSE is reduced from 0.495 to 0.081. Whale Optimization Algorithm easily falls into local extremum and convergence rate problems when optimizing the SVR model. The improved Whale Optimization Algorithm uses the left and right baleen search of the beetle algorithm to improve the lack of the Whale Optimization Algorithm, thereby improving the global optimization ability of the algorithm. The research shows that near-infrared spectroscopy technology combined with an intelligent optimization algorithms can effectively identify the adulteration of vine pepper oil, which provides a reference for the research on the adulteration of vine pepper oil.
藤椒的提取物或挥发油在抗病毒、 杀病菌和微生物等方面有显著的功效[1]。 因受利益驱动, 部分黑心商家会偷偷在藤椒油中添加葵花籽油, 大豆油, 玉米油等其他的中低价位油。 掺假行为不但破坏了市场经济, 同时侵犯了消费者应有的权益。 因此在维护合法生产经营者和广大消费者的切身利益的最大前提下, 对如何进行藤椒油快速智能的掺假鉴定, 有着重要的社会价值和经济效益。 目前, 色谱法、 核磁共振法、 紫外光谱法、 近红外光谱法等都是食用油的掺伪检测方法。 这些检测方法在实际应用过程中要结合主成分分析、 多元线性回归、 人工神经网络、 支持向量机回归等, 共同对掺伪油样进行定性与定量模型的构建与研究。
近年来, 近红外光谱技术[2]应用在粮食和农作物的检验方面, 成为一种快捷高效的现代分析检测技术, 其设备构造简易, 具有方便、 简单、 实用、 对食品伤害小、 环境污染低, 以及在线检测等的优点。 目前, 国内外均有研究者通过近红外光谱技术, 对食品安全进行一系列探讨研究。 王武[3]等在纯净的灵芝孢子油中掺入了玉米油、 薏仁油、 花生油进行掺假鉴别, 建立RVM分类器, 更加高效的识别灵芝孢子油的掺假, 为灵芝孢子油掺杂其他油样, 提供了有效的识别手段。 王哲等结合二维相关的近红外光谱技术和特征分析技术, 在划分植物油类别上有了比较显著的提升, 研究成果所包含的基于自相关谱主成分欧式距离的划分方式, 是一种较为高效的解决策略。 高冰等提出一种快速高效的筛查结合确证分析的连续分类策略, 检测鱼油存在的掺假陆生动物油脂的问题。 Mari Merce Cascant等运用近红外光谱法检测相应脂类和脂肪酸在鲑鱼油里的含量, 构建偏最小二乘回归模型来检验脂质和脂肪酸的种类; 同时通过气相色谱法和高性能薄层验证了预测结果, 说明偏最小二乘结合近红外光谱方法的预测能力较好, 预测集的相对均方根误差值低于或等于0.018。 Thiago O Mendes等为了比较各种光谱仪器采集的橄榄油掺大豆油的样本数据存在的差异性, 用了中红外光谱、 拉曼光谱、 和近红外光谱技术分别进行了数据采集, 为工业和监管机构检测橄榄油的真伪性最优化方式。 彭星星运用近红外光谱技术, 完成了核桃油中掺杂大豆油与菜籽油的定量分析。 经试验表明, 采用了最大-最小归一化法对掺杂了菜籽油中的核桃油进行了光谱的预处理, 对菜籽油定量分析的模型校正集标准误差为0.005 32, 并且其校正集相关系数为0.999 7; 交叉验证后得到的模型, 其相关系数为0.999 6, RMSECV是0.005 62。 而俞雅茹应用多元散射校正、 标准正态变换的前处理来去除干扰信息, 对模型的预测能力有一定程度的提高; 且对波段进行快速选择特征时是应用竞争性自适应重加权算法和组合区间偏最小二乘法(SiPLS), 从而导致建模的变量降低, 提升了效率。 庄小丽等采集了纯橄榄油分别掺入花生油、 山茶油、 罂粟油等样品的近红外光谱; 优选光谱特征波段建立偏最小二乘法(PLS)回归模型测定掺假浓度, 其回归模型的预测相对误差区间为-5.67%~5.61%。 刘珊珊用红外光谱技术结合偏最小二乘法, 可以迅速测定单一品牌芝麻油中的掺假量。 以上各种方法, 均具有相应的食用油掺假测定能力, 都可以借鉴。
各类食用油研究中掺伪比例一般为5%~60%, 因为低于5%比例的掺伪量研究较为困难, 高于60%则是掺伪过量, 若藤椒油占掺伪油中比例过小缺少研究价值。 本研究将纯藤椒油作为基底油, 按比例配置掺入大豆油、 玉米油、 葵花籽油得到油样, 且掺伪量的浓度区间覆盖0~100%浓度, 覆盖浓度面广并且按梯度进行划分, 结合光谱预处理和特征光谱筛选以及改进的鲸鱼算法, 对藤椒油掺伪作检测研究。
从附近超市根据国标号采购基底油和掺伪油: 纯藤椒油(NY/T 2111—2011), 纯玉米油(GB19111), 纯大豆油(GB1535), 纯葵花籽油(GB 10464)。 将藤椒油作为基底油, 向基底油中分别单次的加入不同质量的大豆油, 玉米油和葵花籽油, 将这些作为掺伪油, 制备总体积为20 mL, 掺假量从0~50%间隔为2%, 分别为2%, 4%, 6%, 8%, 10%, 12%, 14%, 16%, 18%, 20%, 22%, 24%, 26%, 28%, 30%, 32%, 34%, 36%, 38%, 40%, 42%, 44%, 46%, 48%和50%共25个梯度浓度; 50%~100%间隔为5%, 分别为55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%和100%共10个梯度浓度, 因此每种掺假油总共有35个梯度, 所以三种浓度不同掺假油能够制备105份样品。 将这些油样放入离心试管静置24 h, 选取其中70份样品作为训练集, 剩余35份样品作为验证集。
实验检测平台如图1所示。 检测平台包含了光源, 光纤, 比色皿, 近红外光谱仪和计算机。 光源适配的是HL-2000卤钨灯光源, 光谱仪是海洋光学公司NIRQuest256光谱仪, 光谱仪波长范围为897.22~2 124.47 nm。 将光源与光谱仪进行通电处理, 在实验开始之前, 为了保证光源输出稳定的光强, 保证光谱仪稳定的工作, 5 min的时间预热仪器。 然后在比色皿内放入藤椒油的样品, 通过光纤将光照射入比色皿中, 光线透过藤椒油油样品后通过光纤输入到近红外光谱仪; 光谱仪连接PC端计算机, 计算机通过上位机对光谱数据进行采集, 得到原始光谱。
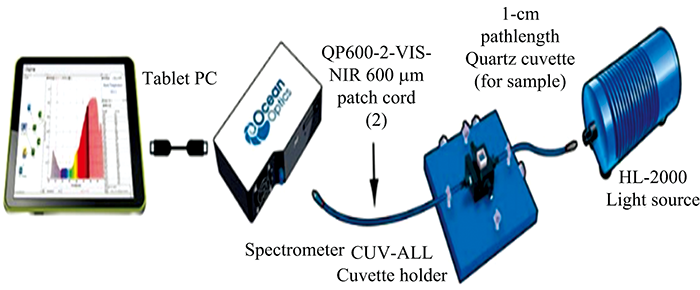 | 图1 检测平台Fig.1 Detection platform |
使用近红外光谱仪检测样品光谱数据时, 近红外光谱信号会受到一些环境的干扰和噪音影响, 直接使用原始光谱, 会出现数据不够准确的情况, 所以先进行归一化处理显得尤为重要。 采用标准正态变换(standard normal variation, SNV)、 多元散射矫正(multiplicative scatter correction, MSC)算法预处理原始光谱数据, 以消除噪声和干扰影响, 提高光谱数据的可靠度从而提升模型的精度和稳定性。 对已经经过预处理后的光谱数据通过竞争自适应法(competitive adaptive reweighted sampling, CARS)、 连续投影算法(successive projections algorithm, SPA)有效的获取特征数据, 利用SVR[4]处理特征数据, 比较各种方法提取的特征数据建模效果, 有助于加强对藤椒油掺伪建模的认知, 为后期建立藤椒油掺伪模型提供参考。
(1)均方根误差(RMSE)是用于测量所建模型的真实值同预测值间的偏差。 均方根误差的数值与建模效果的优劣之间是有一定的关联性的, 模型的预测效果越好, 则对应的均方根误差的值也越小。 RMSE的基本定义是如式(1)所示。
$\mathrm{RMSE}=\sqrt{\left.\frac{1}{N}_{1}^{N}\left[y_{i}-\hat{y}_{i}\right)\right]^{2}}$(1)
式(1)中, N为样本的个数, yi为真实值,
(2)决定系数(R2)是校正集验证系数和预测集验证系数, 该决定系数是用来评价待测样本的真实值与预测值的关联性。 R2的基本定义是如式(2)所示。
$R^2=\frac{\sum\left(y_b-y\right)}{\left(y_b-y\right)^2}$(2)
式(2)中, 待测样品的真实值由yb表达, 待测样品的校正集预测值或预测集预测值均由y来表达,
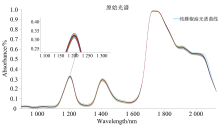
藤椒油中掺伪了大豆油的108份油样的初始近红外光谱如图2。 在897.22~2 124.47 nm波长范围内, 波峰位于1 200, 1 400和1 800 nm附近, 纯藤椒油样品及掺大豆油样品的峰型较为相似, 位置较为相近。 若从初始的图谱直接判别是否掺假是具有较高难度的。 若在光谱重叠度较大的附近来提取相关的光谱信息, 这时一定要与化学计量学进行适当的融合, 将采集得到的多元信息与微弱信息进行适当的处理, 才能顺利进行藤椒油掺伪大豆油定量鉴定的建模过程。
 | 图2 藤椒油掺伪大豆油原始近红外光谱图Fig.2 The original near-infrared spectra of vine pepper oil adulterated with soybean oil |
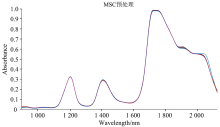
通过多元散射校正(MSC)的方法, 进行数据预处理, 能够使样本的近红外光谱数据与样本自身所包含的物理信息之间的相关性有显著的增加; 预处理结果如图3。
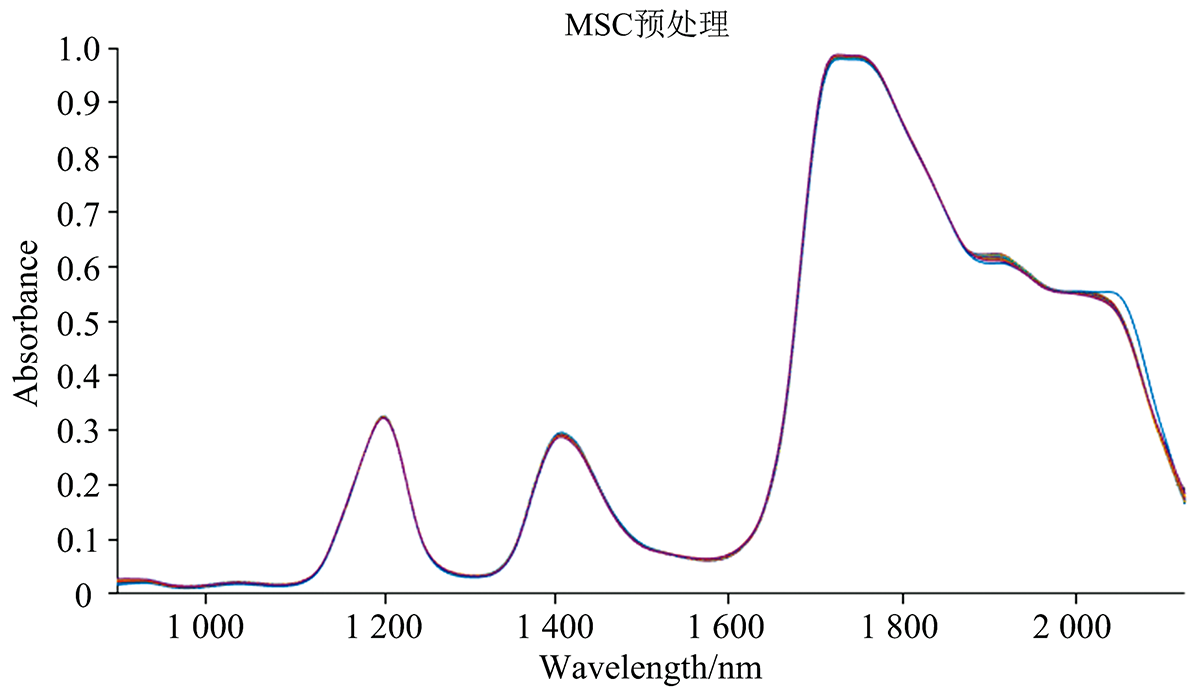 | 图3 MSC-NIRS后的光谱预处理Fig.3 Spectrum of vine pepper oil samples pretreatment by MSC-NIRS |
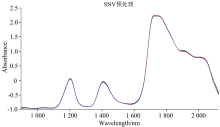
样品表面的散射和光程变化可能会对近红外光谱产生一定的影响, 用SNV算法预处理可以适当的削弱这些影响, 优化样品近红外光谱, 显然这种方法在现实中有着更高的可实用性。 预处理结果如图4所示。
 | 图4 藤椒油样本预处理SNV-NIRSFig.4 Pretreated spectrum of vine pepper oil samples (SNV-NIRS) |
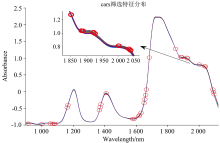
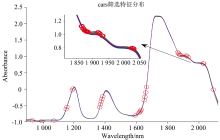
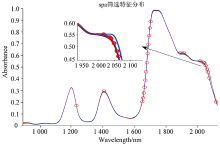
CARS算法, 是基于蒙特卡罗采样和PLS回归系数的特征波长选取方式。 首先构建的PLS模型是有关蒙特卡罗取样的, 进而计算该蒙特卡罗采样中的波长回归系数的绝对值权重, 然后对权重绝对值较小的波长变量进行剔除, 再用衰减指数法来计算删除的波长数量, 最后用剩下的变量构建PLS模型, 通过运算后的RMSE值最小的模型对应的波长就是选择的特征波长, 搜索最优建模变量组合的过程可以采用CARS方法来执行, 如图5, 图6所示。 反式烯烃上C—H的面外弯曲振动, 在1 900 nm处表现明显, 容易得出这是大豆油与藤椒油的特征吸收峰。
 | 图5 SNV-CARS优选变量Fig.5 Preferred variables (SNV-CARS) |
 | 图6 MSC-CARS优选变量Fig.6 Preferred variables (MSC-CARS) |
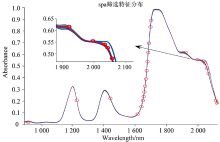
SPA算法, 是前向变量的选择算法, 可以使矢量空间共线性最小化。 SPA所包含的优点是能够在全波段光谱中, 合理的提取相应的波长, 在一定程度上, 将原始的光谱矩阵中所包含的多余可消除的信息进行去除。 如图7, 图8。
 | 图7 SNV-SPA优选变量Fig.7 Preferred variables (SNV-SPA) |
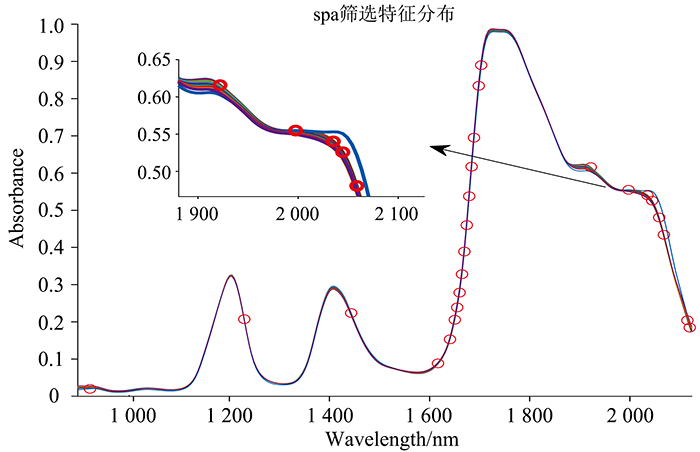 | 图8 MSC-SPA优选变量Fig.8 Preferred variables (MSC-SPA) |
近红外光谱的建模方法主要包滑主成分分析(principal component analysis, PCA)、 聚类分析(cluster analysis)、 多元线性回归(multiple linear regression, MLR)、 偏最小二乘回归(partial least squares regression, PLS)、 支持向量机分类(support vector machine classification, SVM)、 支持向量机回归(support vector machine regression, SVR)等。 其中支持向量机回归、 主成分分析和最小二乘回归为近红外光谱中较为常用的定量分析方法。
光谱仪采集的样本光谱中包含有大量重要可用信息, 同时包含采集时的外部实验环境信息。 如果直接通过特征提取算法后提取的特征波长很难区分不同种类及不同浓度的掺伪油样。 因此将提取的特征信息结合支持向量机定量分析方法, 采集大量藤椒油掺伪数据样本进行建模分析至关重要。
支持向量机法以SLT和VC维理论和最小结构风险为基础的新的模式识别方法, 其中心内容是将光谱样本数据通过非线性映射到多维空间, 然后再在此多维空间内进行线性回归。 支持向量机在当下依然有较好的实用性, 因为其模型建立简便, 并涉及到了线性和非线性的回归分析, 实用性强且广泛。 本研究的藤椒油定量预测模型将采用支持向量机(SVR)的建模方法, 需要构建损失函数, 含有线性分类和非线性分类, 核函数是可以用于构建相关性的。 在建立支持向量机模型的时候, 可以选用RBF核函数来构建模型, 因为RBF核函数的学习能力强, 有助于建立更佳的模型。
不同模型的结果如表1, 应用NIRS结合SVR, 从而对掺伪含量的定量检测进行合适建模, 能够对藤椒油掺大豆油的定量预测进行有效判别。 不同预处理结合不同的特征波长采集方式结果对比后发现四种方式的校正模型有一定差距。 根据表1可以看出, MSC-CARS-SVR模型预测集决定系数R2最高为0.705 2, 该模型采用44个特征优选变量作为建立SVR模型的输入变量, 该模型校正集决定系数R2为0.756 1, 校正集均方根误差RMSE为0.743, 且预测集RMSE为0.794。 模型精度不是特别理想, 故采用鲸鱼算法[5, 6]和改进的鲸鱼算法[7, 8], 来优化模型的相关参数, 从而提升模型的精确程度。
| 表1 藤椒油掺大豆油掺伪含量预测结果 Table 1 Prediction results of adulteration content of vine pepper oil mixed with soybean oil |
初始化天牛须算法, 设置n维空间中天牛的位置为
创建天牛左右须空间坐标
其中X为鲸鱼算法优化迭代后的最优鲸鱼位置, l是用来表示天牛质心与触须的距离,
由于两只触角获得两个位置的目标函数信息, 因此需要对两个位置择优前进
式中: δt是用来表示在第i次迭代时的步长因子, sign()为符号函数。
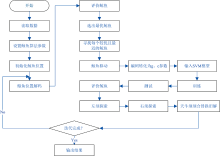
将天牛须算法(beetle antennae search algorithm, BAS)[9, 10]结合鲸鱼算法(whale optimization algorithm, WOA): 以每一次鲸鱼群的最优鲸鱼作为当前天牛须的出发位置, 分别探索左右须前进, 再计算前进后的目标函数, 如果目标函数优于当前最优鲸鱼的值, 则用前进后的天牛位置替换鲸鱼位置, 进而实现了天牛须算子对鲸鱼算法的改进。
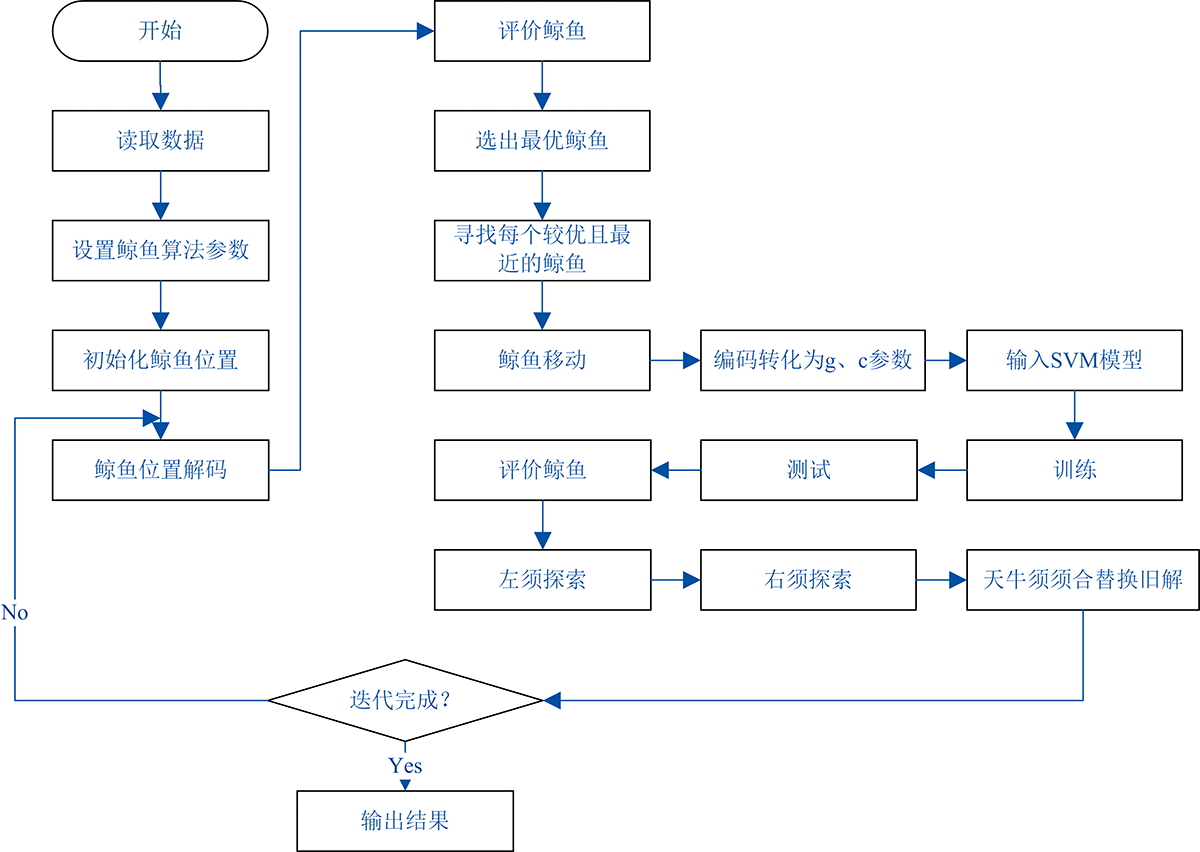 | 图9 改进后的鲸鱼算法优化SVR流程图Fig.9 The SVR flow chart of improved whale optimization algorithm |
根据表2可以看出采用近红外光谱检测技术结合SVR实现藤椒油掺伪大豆油的定量预测效果较好, 鲸鱼算法和改进后的鲸鱼算法对模型参数进行适当优化后, 对模型的精度有一定的提升作用。 预测集精度最高为MSC-CARS-BAS-WOA模型, 其预测集决定系数R2最高为0.943 9, 该模型采用54个特征优选变量作为建立SVR模型的输入变量, 且该模型校正集决定系数R2为0.955 1, 校正集的均方根误差RMSE为0.054, 且预测集RMSE为0.081, 该模型的RMSE小且R2接近1, 预测效果良好, 有较大的实际应用价值, 可以推广到实践中。 在藤椒油掺大豆油掺伪定量预测模型中, 采用MSC进行预处理效果较好, 模型精度较高; 采用CARS进行特征波段提取, 能够有效的筛选到代表性的SVR模型的输入变量, 提升了模型精度。
| 表2 优化模型后的藤椒油掺大豆油的掺伪含量的预测结果 Table 2 Prediction results of the adulterated content of vine pepper oil mixed with soybean oil using the optimized model |
从表2可以分析出, 传统的鲸鱼算法在全局的搜索方面有较强的能力, 但在局部的搜索方面表现出较弱的解决能力, 往往不能得到最优解, 只能得到次优解。 而改进后的天牛须算法结合鲸鱼算法能够有效改善传统鲸鱼算法中容易陷入局部最优的问题, 相比于MSC-CARS-WOA模型, MSC-CARS-BAS-WOA模型的预测集均方根误差RMSE从0.495降低到0.081, 校正集均方根误差RMSE从0.374降低到0.054, 预测集的决定系数R2从0.821 6提升到0.943 9, 校正集的决定系数R2从0.859 1提升到0.955 1。 说明改进后的天牛须算法结合鲸鱼算法确实能够提升模型的精度, 具有更好的实际应用价值。
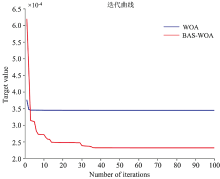
WOA和BAS-WOA迭代曲线如图10所示。 其中鲸鱼算法几乎没有迭代过程, 判断是陷入了局部最优环节。 相比之下, 改进的鲸鱼算法则一直在迭代寻优的过程, 迭代到36次得到最优解。
 | 图10 WOA-SVR和BAS-WOA-SVR迭代曲线图Fig.10 WOA-SVR and BAS-WOA-SVR iteration graphs |
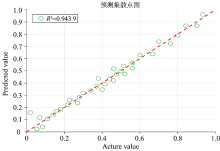
MSC-CARS-BAS-WOA-SVR模型的预测集结果图如图11所示。 越靠近图中y=x的这条直线, 就越能说明样本的预测值接近真实值, 即表明了模型的预测效果佳。 因此利用改进的鲸鱼算法能够有效改善传统鲸鱼算法中容易陷入局部最优的问题, 能够较好的提升SVR 模型的精度和实际应用性。 研究中虽然定量预测精度较高, 但是考虑到实际应用中可能存在的问题, 还得继续改进。 在现实应用中, 为了得到优选参考样品集, 可以采用交互验证, 通过增加参考集中的样品数等, 继而增加模型分类准确性。
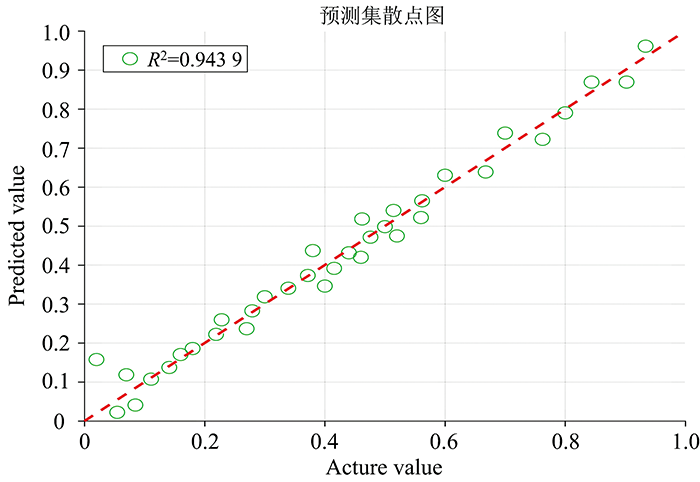 | 图11 预测集结果图Fig.11 Prediction set result graph |
从表1和表2中可知, 通过预处理和特征数据建立MSC-CARS-SVR模型的预测集决定系数R2为0.705 2, 预测集均方根误差RMSE为0.794, 其模型精度一般, 还有优化空间。 因此通过鲸鱼算法优化支持向量机参数建立的MSC-CARS-WOA-SVR模型的预测集决定系数R2从0.705 2提升到了0.821 6, 预测集均方根误差RMSE从0.794降低到了0.495, 说明经过鲸鱼算法优化后的支持向量机建立的模型能够提升模型精度和应用性, 但考虑到鲸鱼算法在局部的搜索方面会表现出较弱的解决能力, 从而导致建立的模型并不是最优模型, 只能得到的是次优解。 所以采用改进鲸鱼算法, 运用天牛须算法(BAS)优化鲸鱼算法(WOA)能够优化支持向量回归机(SVR)的核函数参数和惩罚因子, 建立了MSC-CARS-BAS-WOA-SVR藤椒油掺伪定量预测模型的预测集决定系数R2从0.705 2提升到了0.943 9, 预测集均方根误差RMSE从0.794降低到了0.081, 模型精度提升明显。
由图10适应度曲线可看出, 相比于传统的鲸鱼算法, 由天牛须算法优化后的鲸鱼算法效果更好, 迭代优化效果明显, 均方根误差(RMSE)从0.495降低到0.081, 模型预测准确率提升了0.111 3, 改进鲸鱼算法对藤椒油掺伪定量预测模型相比鲸鱼算法有明显优化, 预测效果好, 提升了模型精度, 表明该模型能够进行实际推广, 有较大的应用价值。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|