




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于1D-CNN的近红外光谱定量分析棉/涤纶/羊毛混纺纤维含量方法研究
[黄孟强1  , 匡文剑
, 匡文剑2, 3, * , 刘向1 , 何良4 ]
, 匡文剑, 刘向|
|


作者简介: 黄孟强, 1998年生, 南京信息工程大学电子与信息工程学院硕士研究生 e-mail: 20211249222@nuist.edu.cn
纤维成分的定性及定量分析在纺织品检测中一直是研究热点, 但常规检测手段存在周期长、 工序复杂且对环境不友好等问题, 因此提出一种对纺织品纤维含量快速、 无损且准确的检测方法就显得尤为重要。 研究提出一种纺织品纤维含量的定量校正模型, 可以准确预测纺织品中棉/涤纶/羊毛的纤维含量, 解决传统校正模型无法兼顾准确与多种纤维预测的难点。 针对645个羊毛/涤纶、 棉/涤纶以及羊毛/涤纶/棉混纺样品为研究对象, 采用红外光谱分析仪采集样品的近红外反射光谱, 在光谱数据预处理的基础之上, 提出一种一维卷积神经网络(1D-CNN)模型, 实现对多种纤维含量的同时预测, 为了凸显模型的优势, 在相同的训练集和测试集样本之上对比3种不同机器学习算法的预测结果。 结果表明: 选用线性函数归一化、 多项式平滑滤波(SG平滑, 滑动窗口为9, 拟合阶数为7)的预处理方法, 结合所提出的1D-CNN模型效果最优, 其模型决定系数R-Squared可达到0.998, 各含量预测的平均绝对误差(MAE)为0.62, 预测均方根误差(RMSE)为1.31。 同时采用未参与建模的138个纺织品样品验证模型泛化能力, 模型在测试集上的表现为, 决定系数R-Squared为0.996, 各含量预测的平均绝对误差(MAE)为0.80, 预测均方根误差(RMSE)为2.01。 采用所提出的模型, 可以准确预测羊毛、 棉和涤纶混纺织品中纤维含量, 为快速无损检测纺织品提供了一种可行的方法, 同时为其他混纺纤维含量的定量分析提供了新的思路。
Qualitative and quantitative analysis of fiber composition has always been a research hotspot in textile testing. However, conventional detection methods have problems such as long cycles, complicated processes, and being unfriendly to the environment. Therefore, proposing a fast, non-destructive, and accurate detection method for textile fiber content is particularly important. This study proposes a quantitative calibration model for textile fiber content, which can accurately predict the fiber content of cotton/polyester/wool in textiles. It solves the difficulty that traditional calibration models cannot consider both accurate and multiple fiber predictions. In this study, 645 wool/polyester, cotton/polyester, and wool/polyester/cotton blended samples were taken as the research objects, and an infrared spectrometer collected the near-infrared reflectance spectra of the samples. After the spectral data is preprocessed, the one-dimensional convolutional neural network (1D-CNN) model is used to predict multiple fiber contents simultaneously. The prediction results of three different machine learning algorithms are compared on the same training and test sample sets. The results show that the preprocessing method of linear function normalization and polynomial smoothing filter (SG smoothing, the sliding window is 9, fitting order is 7), combined with the proposed 1D-CNN model has the best effect, and Its model determines that the coefficient R-Squared can reach 0.998, the mean absolute error (MAE) of each content prediction is 0.62, and the root mean square error (RMSE) of prediction is 1.31. At the same time, 138 textile samples that did not participate in the modeling were used to verify the mode’s generalization ability. The model’s performance on the test set was excellent, with a coefficient of determination R-squared of 0.996, a mean absolute error (MAE) of each content prediction of 0.80, and a predicted mean square of the root error (RMSE) of 2.01. Using the model proposed in this paper, the fiber content in wool, cotton, and polyester blended textiles can be accurately predicted, providing a feasible method for rapid non-destructive testing of textiles and a new idea for the quantitative analysis of other blended fiber content.
作为决定产品价值的主要指标, 纺织品纤维成分和含量一直是生产者、 消费者和各级市场监管部门十分关心的问题[1]。 国内外为保护消费者的合法权益, 颁布相应法令规定纺织品必须标注纤维成分及其含量[2]。 但在实际生产和市场交易中, 纺织品的以次充好、 虚假声明和掺假情况等问题也并不少见。 因此, 纺织品纤维含量的定量检测一直都是众多检测项目中极其重要的一环。 现存的纺织品纤维检测方法(燃烧法、 溶解法等), 不仅检测周期长, 检测环境要求高, 还存在污染环境的问题[3]。 研究一种高效、 便捷以及环保的检测方法具有重要意义。
近红外光谱是电磁波谱的一部分, 波长范围为780~2 526 nm, 所涉及的化学键通常是R— H(C— H、 O— H、 N— H、 S— H)[4, 5], 利用其伸缩振动倍频和合频形成近红外区的吸收或反射光谱, 结合化学计量学方法, 可以建立样品浓度或含量与光谱之间的校正模型。 化学计量学方法校准后, 近红外光谱分析可以对样品进行简单高效的检测。 光谱分析结合深度学习已在食品分析[6]、 农产品质量检测[7]、 和医疗[8]等许多领域得到了广泛应用。 目前, 光谱分析结合深度学习也正逐步成为纺织品检测领域的常规分析技术, 用于纺织品纤维的分类与含量检测[9, 10]。 Yang[11]等通过对比四种光谱仪性能之后, 建立偏最小二乘校正模型对掺有棉的真丝纯度进行了快速定量分析。 Huang[12]等通过对光谱数据进行预处理后, 进一步改进PLS模型, 实现了混纺样品中亚麻含量的预测。 上述研究在使用经典机器学习算法的同时仅能实现混纺样品中某一种纤维成分的定量分析。 在废旧纺织品回收领域, 多采用深度学习结合光谱分析实现混纺样品的检测与分类[13, 14]。 然而, 针对近红外光谱分析结合深度学习实现纤维成分的检测研究相对较少, 经典机器学习方法在面对混纺织品中多种纤维含量的同时预测时显得乏力。
采用便携式近红外光谱仪采集羊毛/涤纶/棉混纺织品共计645个样品的近红外反射光谱数据。 选择合适的光谱预处理办法结合1D-CNN建立定量检测模型, 用于预测棉/涤纶/羊毛混纺织品中各种纤维含量。 所提出的模型可以有效检测棉/涤纶/羊毛混纺织品中各种纤维含量, 为市场上快速、 无损检测混纺织品中纤维含量提供了可行的办法。
由太谱(苏州)纺织科技有限公司提供Texpe T1红外光谱分析仪, 采用漫反射方式对纺织品纤维含量进行检测。 仪器光源为卤钨灯, 配有铝合金反射罩和铯钨青铜红外吸光阱, FPI红外光谱传感器波长范围1 550~1 850 nm, 光谱分辨率为5 nm, 采用24位高精度采样, 包含温度动态补偿校准, 整个系统开发流程如图1(a)所示。 单个样本扫描时间0.5 s, 整机质量小于500 g, 可单手操作。 红外光谱分析仪实物图如图1(b)所示。
 | 图1 系统开发流程(a), 用于纺织品纤维含量测量的红外光谱分析仪(b), 部分纺织品展示(c) W: 羊毛; T: 涤纶; C: 棉Fig.1 System development process (a), infrared spectroscopy analyzer for textile fiber content measurement (b), part of the textile display (c) W: Wool; T: Polyester; C: Cotton |
由江苏阳光集团提供的羊毛/涤纶、 棉/涤纶和羊毛/涤纶/棉样品共计645个混纺织品为研究对象, 样品涵盖黑色、 灰色、 红色、 黄色、 青色等各个颜色。 选取507个样本建立定量校正模型, 以138个样本用于验证模型泛化能力。 部分样品展示如图1(c)所示。
为了尽量拟合现实生活中的测试环境, 选择实验环境温度10~30 ℃, 相对湿度30%~70%。 将红外光谱仪预热5 min, 保证采集的红外光谱数据稳定、 准确。 样品平铺在桌面上, 折叠成两层, 避免光源透射纺织品导致引入背景反射光, 测量红外漫反射光谱。
在测量过程中会因为一些物理因素, 如样品状态、 检测环境以及测量条件等对红外光谱数据造成干扰, 影响建模效果, 本研究采用线性函数归一化(Normalization)、 多元散射校正(MSC)、 标准正态变量变换(SNV)、 中值滤波、 SG平滑中的单个或多个预处理组合来消除非目标因素对建模的影响。 其中线性函数归一化, 可以将一条光谱数据映射至[0, 1], 以此来减少无关信息的干扰[15], 归一化的公式如式(1)。
式中:
经预处理之后的光谱数据结合所提出的1D-CNN回归算法实现混纺织品中各种纤维含量的预测。 同时对比3种经典机器学习回归算法, 即偏最小二乘回归(PLSR, 主因子数为16)、 梯度提升回归(GBR)、 支持向量回归(SVR)。 所有的模型都在相同的训练集上进行训练, 相同的测试集上进行评估。 结果表明, 预处理Normalization+SG平滑之下结合1D-CNN校正模型之后, 模型效果达到最优。
本模型选用的评价指标是决定系数(R-Squared), 平均绝对误差(MAE), 均方根误差(RMSE), 见式(2)和式(3)。 其中, yi为纺织品纤维真实含量, ${{{\hat{y}}}_{i}}$为模型对纺织品纤维的预测含量,
$R-Squared=1-\frac{\overset{n}{\mathop{\mathop{\sum }_{i=1}}}\, {{({{y}_{i}}-{{{{\hat{y}}}}_{i}})}^{2}}}{\overset{n}{\mathop{\mathop{\sum }_{i=1}}}\, {{({{y}_{i}}-{\bar{y}})}^{2}}}$ (2)
$\text{MAE}=\frac{1}{n}\overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, \left| {{y}_{i}}-{{{{\hat{y}}}}_{i}} \right|$ (3)
$\text{RMSE}=\sqrt{\frac{1}{n}\overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{({{y}_{i}}-{{{{\hat{y}}}}_{i}})}^{2}}}$ (4)
经过便携式红外光谱仪所测的羊毛/涤纶/棉纺织品中部分纺织品原始的近红外光谱如图2(a)所示。 为减少与特征无关的信息的干扰, 将光谱数据进行归一化, 可以得到如图2(b), 归一化之后的光谱可以消除光谱强度差异所带来的干扰。
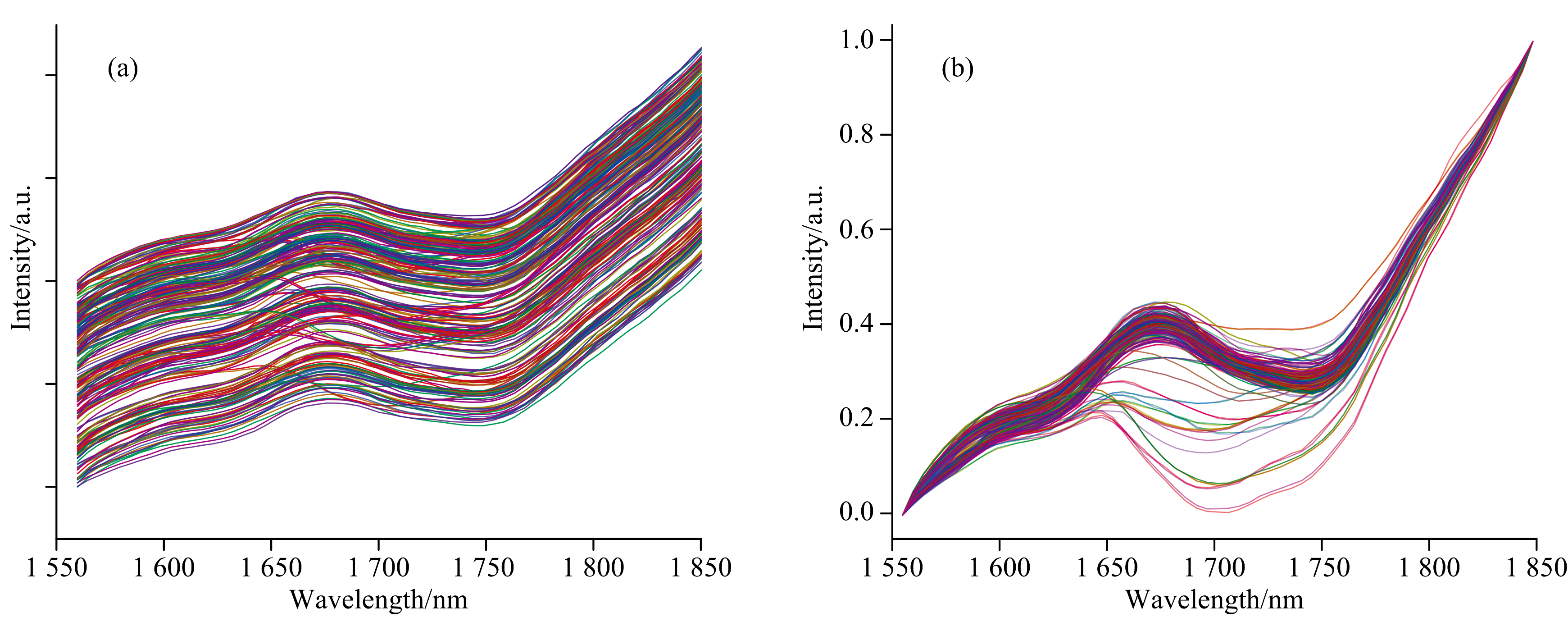 | 图2 部分样品原始数据光谱(a), 部分样品归一化后光谱(b)Fig.2 Original data spectrum of some samples (a), Normalized spectrum of some samples (b) |
卷积神经网络(CNN)是具有一定深度且可以通过梯度下降算法优化参数的前馈神经网络(feedforward neural networks)。 常常用于图像处理方向, 处理的图像多为二维和三维图像数据[16, 17]。 在处理红外光谱数据时, 对一维光谱数据进行卷积处理, 通过1D-CNN实现光谱特征、 光谱有效信息的提取以及非线性光谱数据的处理。 本研究使用1D-CNN设计定量校正模型用于处理光谱数据, 光谱数据共计61个波段, 共使用7层网络建立模型, 主要包含输入层、 池化、 卷积层、 全连接层和输出层。 1D-CNN模型的建立具体步骤如下:
(1)在将数据输入到卷积网络之前, 由于一维卷积的输入为3D张量, 先将数据进行预处理, 再将数据扩充维度。
(2)分别使用16个3× 1大小的卷积核和64个3× 1大小的卷积核, 先构建两层卷积层, 提取波段特征。
(3)采用3× 1大小的max-pooling适合于获得光谱数据的局部最大值, 得到的下采样滤波器矩阵范围内的最大特征值, 近红外光谱的局部最大值代表了波形的峰值特征。
(4)再采用3层卷积层, 大小均采用64个3× 1的卷积核进一步提取波段特征, 获取光谱数据的高维特征。
(5)经过上述操作之后得到64个15× 1大小的特征向量, 连接到Flatten层, 将卷积层提取的高维数据在Flatten层平铺展开, 最后再连接3个输出节点, 映射输出棉、 涤纶、 羊毛的含量。 具体网络结构如图3所示。
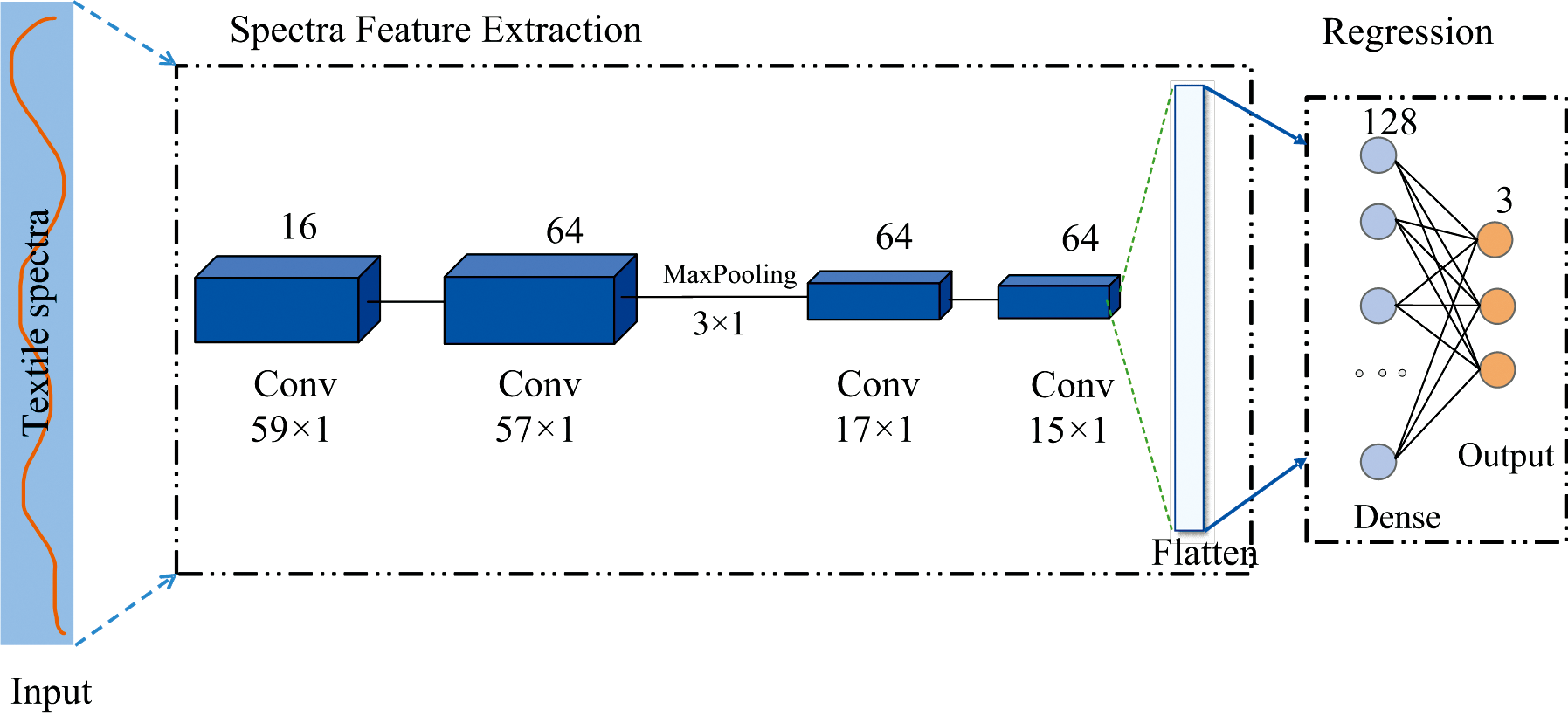 | 图3 1D-CNN网络结构Fig.3 1D-CNN network structure |
在上述的输入层、 卷积层和全连接层均采用Relu激活函数即整流线性单元, 见式(5), 而在输出层采用linear激活函数即线性激活函数。
此激活函数使得网络具有稀疏性, 并减少参数的依赖关系, 可以有效防止过拟合的发生, 同时增加了各层的非线性关系, 使网络能够学习到光谱数据中更高维度的数据特征, 增强学习能力。 而输出层的线性激活函数可使输出含量直接映射。
为建立一种准确、 高效预测纺织品纤维含量的模型, 选用经典机器学习回归算法建立模型。 使用相同的光谱数据预处理即Normalization和SNV的组合, 确保光谱数据在放入模型之前的一致性, 保证模型作为决定因素。 分别使用了PLSR(n_components=16)、 GBR、 SVR以及1D-CNN去构建纺织品各种纤维含量的预测模型。 并对4种模型预测结果进行对比分析。 PLSR、 SVR和GBR, 常常只能对一种含量进行预测, 因此使用sklearn库中的MultioutputRegressor对回归算法进行包装可以实现多种纤维含量的预测。 在相同的训练集训练之后, 对比几种模型在测试集上的表现[图4(a— d)]。 可以看出, 1D-CNN模型决定系数最高为0.989, MAE为1.25, RMSE为3.55。 另外2种机器学习模型决定系数可以达到0.90(PLSR除外)以上、 MAE、 RMSE指标均在可接受范围之内。 但模型最高决定系数R-Squared只有0.938, 预测在个别成分上存在较大误差, 模型的泛化能力有待提高。
 | 图4 不同模型泛化能力对比SVR (a)、 GBR (b)、 PLSR (c)、 1D-CNN (d)Fig.4 Comparison of generalization ability of different models SVR (a), GBR (b), PLSR (c), 1D-CNN (d) |
在相同的预处理之下, 所提出的1D-CNN模型效果最优, 具备较强的泛化能力。 3种经典机器学习算法在处理光谱有效信息以及提取光谱特征的结果欠佳。 在测量过程中, 因为一些物理因素造成光谱数据存在非线性的情况时, 这3种算法存在一定局限性。
对比分析不同模型在纺织品纤维含量的预测效果, 其中1D-CNN模型最佳, 同时分析各种光谱预处理方法对1D-CNN建模的影响, 从而确定最适合1D-CNN模型的预处理方法。 预处理主要包含Normalization、 SNV、 MSC、 SG平滑(窗口大小为9, 多项式拟合阶数为7)、 中值滤波(窗口大小为3)中一种或多种的组合来分析对模型的影响。 通过对表1分析, 可以看出直接对原始数据建模, 1D-CNN模型表现不佳, 模型在训练集和测试集上的决定系数分别为0.675和0.588。 因此应先对数据进行归一化, 以减少无关信息对光谱特征的影响, 经过归一化之后的数据在模型的表现上相比于原始数据有很大提高, 模型内外决定系数R-Squared分别达到了0.992和0.989。 不同预处理之下, 模型结果确实会有差异。 由表1的结果表明: 采用归一化+ SG平滑(窗口大小为9, 多项式拟合阶数为7)结合1D-CNN所得到的模型效果最优, 模型在训练集上的决定系数R-Squared为0.998、 MAE为0.62、 RMSE为1.31, 模型在测试集上的决定系数R-Squared为0.996、 MAE为0.80、 RMSE为2.01, 而模型在其他预处理的情况下, 模型误差反而增加, 说明纺织品的红外光谱在经过归一化和平滑处理之后, 就可以用1D-CNN提取光谱特征进行建模, 而在此基础之上再结合其他预处理方法, 存在丢失光谱信息的可能。 在1D-CNN模型下, 采用归一化+SG平滑处理模型效果最优。
| 表1 不同预处理对1D-CNN模型的影响 Table 1 The impact of different preprocessing on 1D-CNN models |
本网络模型采用的损失函数为MAE[式(3)], 当在连续梯度迭代中, 损失值变小, 生成的网络将收敛到极值, 模型呈现出最佳的预测能力。 模型的epoch设置为1 000次, 保证模型稳定、 准确的预测能力。 如图5(b)、 (d)分别为R-Squared和损失值随着epoch的趋势图。 从局部放大图可以看出, 经过600次epoch后, 模型在训练集上的决定系数已趋于稳定且接近于1.00, 但从损失曲线可以看出, 损失值在随着epoch的增加还在逐渐减小, 逐渐趋于最优。 当epoch=1 000时, 模型的决定系数和损失值在训练集和测试集都趋于稳定, 训练集上决定系数R-Squared为0.998, 损失值为0.62。 测试集上决定系数R-Squared为0.996, 损失值为0.80。 模型表现出优良的预测能力, 如图5(a)、 (c)所示, 为3种纤维含量的部分预测值, 其中图5(c)为28个样品纤维含量的预测值、 图5(d)为28个样品纤维含量的真实值。 可以看出, 预测误差较小, 模型具有较强的泛化能力。
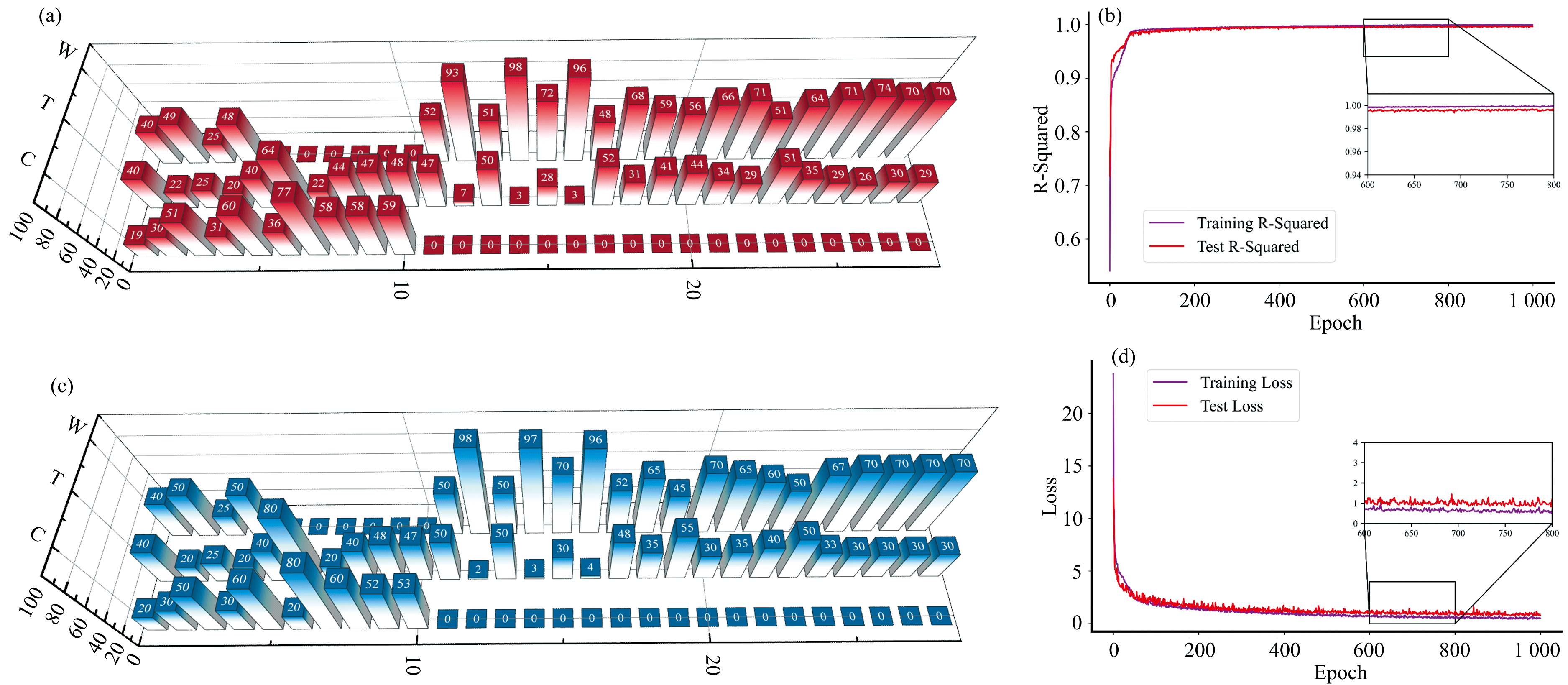 | 图5 部分样本预测值(a), 决定系数随epoch的变化(b), 部分样本真实值(c), 损失随epoch的变化(d)Fig.5 Partial sample predicted value (a), coefficient of determination with epoch change (b), partial sample true value (c), loss with epoch change (d) |
通过对红外光谱仪采集的羊毛/涤纶、 棉/涤纶以及羊毛/涤纶/棉混纺织品的光谱数据进行预处理, 结合所提出的1D-CNN建立棉/涤纶/羊毛混纺织品中各种纤维含量的定量检测模型。 以此达到市场上快速、 无损且准确预测各种纤维含量的目的。 结果表明: 针对经典的机器学习模型, 虽然模型在训练集表现良好, 决定系数在0.90以上, 但模型泛化能力较差。 而经过预处理之后的光谱数据结合一维卷积神经网络(1D-CNN), 模型在测试集表现出优良的预测能力, 具有较好的泛化能力。 最终, Normalization+SG平滑(窗口大小为9, 多项式拟合阶数为7)再结合1D-CNN模型可以实现同时对纺织品多种纤维含量的有效预测, 模型决定系数R-Squared可达0.998、 MAE为0.62、 RMSE为1.31, 测试集上决定系数R-Squared为0.996、 MAE为0.80、 RMSE为2.01。 可以实现纺织品多种纤维含量的有效预测, 有较大的应用价值, 同时为其他混纺纤维含量的定量分析提供了新的思路。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|