
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外光谱结合化学计量学对五元调和油中单组分油的定量分析
[胡晓云1  , 卞希慧
, 卞希慧1, 2, 3, * , 项洋2 , 张环1 , 魏俊富1 ]
, 卞希慧, 项洋|
|


作者简介: 胡晓云,女, 1995年生,天津工业大学环境科学与工程学院硕士研究生 e-mail: hxy16622908318@163.com
有关调和油快速准确定量检测的研究对于调和油质量控制具有重要意义。 以往对调和油定量分析的研究大多集中于二元、 三元和四元调和油, 对更高元数调和油的研究很少, 难以满足调和油检测需求。 该研究的目的是探讨近红外光谱结合化学计量学对五元调和油中各单组分油进行定量分析的可行性。 由玉米油、 大豆油、 稻米油、 葵花油和芝麻油配制成51个五元调和油样品, 并采集各样品12 000~4 000 cm-1范围内的近红外透射光谱。 首先, 采用光谱-理化值共生距离(SPXY)算法将调和油样品划分为38个校正集和13个预测集样品。 其次, 考察了主成分回归(PCR)、 偏最小二乘(PLS)、 支持向量回归(SVR)、 人工神经网络(ANN)、 极限学习机(ELM)等五种多元校正方法对五元调和油各组分定量分析的建模效果。 然后, 在最佳建模方法的基础上比较了SG平滑、 标准正态变量(SNV)、 多元散射校正(MSC)、 一阶导数(1st Der)、 二阶导数(2nd Der)和连续小波变换(CWT)六种光谱预处理方法, 并讨论了预处理方法有效地原因。 最后, 在最佳预处理方法的基础上进一步利用竞争自适应重加权采样(CARS)和蒙特卡罗无信息变量消除法(MCUVE)筛选与预测组分相关的变量。 结果显示, 在五种建模方法中, PLS是最佳的建模方法, 对玉米油、 大豆油、 稻米油、 葵花油和芝麻油五种组分的预测均方根误差(RMSEP)分别为5.564 4, 5.559 2, 3.592 6, 7.421 8和4.193 0。 经过光谱预处理-变量选择, 再建立PLS模型, 对五种组分的RMSEP分别降低至1.955 3, 0.562 4, 1.145 0, 1.619 0和1.067 1, 预测相关系数( Rp)均高于0.98, 表明采用合适的光谱预处理和变量选择方法, 可以明显提高五元调和油中各单组分油定量分析的预测准确度。 该研究为多组分调和油的快速无损定量检测提供了一种参考。
The rapid and accurate quantitative analysis of blend oil is of great importance for the quality control of blend oil. However, most previous studies on the quantitative analysis of blend oil have focused on binary, ternary and quaternary blends, and few studies have been conducted on more multi-component blend oil, which is difficult to meet the needs of blend oil detection. This study explores the feasibility of near infrared spectroscopy combined with chemometrics for the quantitative analysis of the singlecomponentoil in quinary blend oil. 51 quinary blend oil samples were formulated from corn oil, soybean oil, rice oil, sunflower oil and sesame oil, and their NIR spectra were measured in a transmittance mode in the range of 12 000~4 000 cm-1. Firstly, the sample set partitioning based on joint x-y distances (SPXY) algorithm was used to divide the sample into 38 calibration and 13 prediction set samples. Secondly, the modeling effect of five multivariate calibration methods, including principal component regression (PCR), partial least squares (PLS), support vector regression (SVR), artificial neural network (ANN), and extreme learning machine (ELM), were examined for the quantitative analysis of each component in quinary blend oil. Then six spectral preprocessing methods including Savitzky Golag smoothing(SG smoothing), standard normal variate (SNV), multiplicative scatter correction (MSC), first derivative (1st Der), second derivative (2nd Der), and continuous wavelet transform (CWT) were compared based on the best modeling method and the reasons for the effectiveness of the preprocessing methods were discussed. Finally, based on the optimal preprocessing method, the competitive adaptive reweighted sampling (CARS) and Monte Carlo uninformative variable elimination (MCUVE) algorithms were further used to screen the variables associated with the predicted components. The results showed that PLS was the optimal modeling method among the five modeling methods, with root mean square error of the prediction set (RMSEP) of 5.564 4, 5.559 2, 3.592 6, 7.421 8, and 4.193 0 for the five components of corn oil, soybean oil, rice oil, sunflower oil, and sesame oil, respectively. After preprocessing-variable selection and then PLS modeling, the RMSEP for the five components were 1.955 3, 0.562 4, 1.145 0, 1.619 0 and 1.067 1, respectively and the correlation coefficients of prediction set ( Rp) were all higher than 0.98, indicating that with appropriate spectral preprocessing, variable selection and modeling methods, the accuracy of quantitative analysis of each component in quinary blend oil was greatly improved. This research provided a reference for rapid and non-destructive quantitative detection of multi-component blend oil.
食用油是人们获取营养物质的来源之一, 中国食用油消费市场庞大, 食用油调和油因其脂肪酸营养均衡和风味独特在市场中占据重要地位。 市场中食用油的种类参差不齐, 价格差异也较大, 导致一些商家在利益驱使下做出错误标注调和油配比的欺诈行为, 例如夸大价格昂贵油的比例或加大廉价油的比例, 极大损害了消费者的权益。 针对此种现象, 国家标准GB2716— 2018明确规定食用植物调和油的标签标识应注明各种食用植物油的比例。 然而, 仍然缺乏统一的调和油定量检测参考方法。 主要原因在于调和油成分复杂, 定量检测十分困难。 因此, 有关多元调和油快速准确定量检测的研究对于调和油市场质量控制具有重要意义。
目前可用于调和油定量分析的方法较多, 大体上可分为两类。 一类为包括气相色谱法和高效液相色谱法在内的间接分析技术, 需要样品前处理和色谱柱分离, 耗时费力。 另一类为直接分析技术, 无需样品前处理, 主要包括紫外光谱法、 拉曼光谱法、 荧光光谱法、 傅里叶变换红外光谱法、 质谱法、 近红外光谱法等[1]。 然而, 以往对于调和油定量分析的研究大多集中于二元、 三元和四元调和油[2, 3], 对于含有更多组分调和油的研究很少, 难以满足调和油检测需求。 原因是更高元数调和油组分更加复杂, 定量分析更加困难。
近红外光谱技术因其快速、 无损、 绿色、 样品无需预处理等优点, 已经广泛应用于农业和食品[4]等领域。 但由于复杂样品的近红外光谱的谱带较宽, 吸收峰重叠, 基于近红外光谱的定量分析需要借助化学计量学建立多元校正模型[5]。 主成分回归(principal component regression, PCR)、 偏最小二乘(partial least squares, PLS)、 支持向量回归(support vector regression, SVR)、 人工神经网络(artificial neural networks, ANN)和极限学习机(extreme learning machine, ELM)是近红外光谱分析中常用的多元校正方法。 其中PCR和PLS是线性方法, 适用于变量内部高度线性相关的问题。 PLS克服了PCR只对光谱矩阵分解的缺点, 可以有效地降低模型的维数, 使建模结果更加准确可靠[6]。 SVR, ANN和ELM为非线性方法。 SVR是一种应用广泛的机器学习算法, 在解决小样本、 高维数据的回归问题方面具有计算速度快、 泛化能力强大的优点[7]。 ANN针对复杂的非线性变量数据具有明显优势[8]。 ELM是一种单隐藏层前馈神经网络算法, 计算速度快且结构简单[9]。 有研究表明近红外光谱结合化学计量学是实现调和油定量的良好分析工具[10, 11]。 近红外光谱信号中的背景、 噪声、 基线、 杂散光的干扰会影响校正模型的准确性和稳定性, 因此通常需要对光谱进行预处理。 常用的预处理方法有SG平滑(savitzky golag smoothing, SG smoothing)、 一阶导数(first derivative, 1st Der)、 二阶导数(second derivative, 2nd Der)、 标准正态变量(standard normal variate, SNV)、 多元散射校正(multiplicative scatter correction, MSC)和连续小波变换(continuous wavelet transform, CWT)等。 SG平滑可以去除噪声, 提高信噪比。 一、 二级导数通常用于减少背景效应对信号的干扰。 MSC和SNV是消除颗粒大小不同或分布不均引起散射效应的常用方法。 CWT兼具了平滑和导数的作用, 不仅可以去除噪声, 提高信噪比, 而且可以扣除背景干扰[12]。 由于光谱变量很多是冗余的非信息噪声或与目标属性无关的干扰变量, 因此为了提高模型的预测性能和稳定性, 在建模前通常需要进行变量选择。 常用的变量选择算法有蒙特卡罗无信息变量消除(Monte Carlo uninformative variable elimination, MCUVE)、 随机检验(randomization test, RT)和竞争性自适应重加权采样(competitive adaptive reweighted sampling, CARS)等[13]。
本研究的目的是探讨近红外光谱结合化学计量学对五元调和油定量分析的可行性。 五元调和油由玉米油、 大豆油、 稻米油、 葵花油和芝麻油配制而成。 考察了包括PCR, PLS, SVR, ANN和ELM五种多元校正方法对调和油各组分定量分析的建模效果以选取最佳建模方法。 为了提高模型的预测准确性, 比较了SG平滑、 1st Der、 2nd Der、 MSC、 SNV和CWT六种光谱预处理方法对模型预测性能的影响。 最后在最佳预处理方法的基础上进一步利用CARS和MCUVE算法筛选与预测组分相关的变量, 以建立快速准确的五元调和油定量分析模型。
实验采用玉米油、 大豆油、 稻米油、 葵花油和芝麻油配制五元调和油样品。 五种食用油均是从天津大型超市购买的不同品牌的纯油, 其中常规食用油包括玉米油、 大豆油、 稻米油和葵花油购买自鲁花、 福临门和金龙鱼三个品牌, 而由于芝麻油是非常规食用油, 品牌众多, 因此除了鲁花、 福临门和金龙鱼三个品牌外, 还购买了李锦记、 思盼、 李耳等品牌的芝麻油作为实验样品。 将五种食用油配制成质量分数均在0~40%的51个五元调和油样品。 对每个配制样品手动振荡后再超声处理20 min, 使其充分均匀混合。
实验所用测试仪器为Vertex 70型多波段红外/近红外光谱仪(Bruker光学公司, 德国)。 以空气为参比, 在透射模式下采集样品的近红外光谱。 近红外光谱仪的扫描范围为12 000~4 000 cm-1, 每个光谱由32次连续扫描平均得到, 分辨率为4 cm-1, 扫描间隔1.93 cm-1, 获得4 148个波长点。 每个样品平行测量三次, 然后计算平均光谱用于建模。
1.3.1 样品集划分
采用光谱-理化值共生距离(sample set partitioning based on joint x-y distances, SPXY)算法[14]将51个样品划分为包含38个样品的校正集和13个样品的预测集, 分别用于建立校正模型和外部预测。 与仅考虑光谱值X进行分区的Kennard-Stone(KS)算法相比, SPXY算法同时采用光谱值X和浓度值Y计算样品间距离, 可以更有效地覆盖多维向量空间, 改善样本间差异性过小和预测模型泛化能力差的情况, 以提高模型的预测性能。
1.3.2 多元校正方法
多元校正方法是建立样本光谱信号与目标分析物含量之间定量分析模型必不可少的化学计量学工具, 因此选取合适的多元校正方法是建立可靠定量模型的关键。 为了建立稳健且具有良好预测性能的五元调和油定量分析模型, 分别研究了PCR, PLS, SVR, ANN和ELM五种多元校正方法的建模效果以选取最佳方法建立模型。
1.3.3 光谱预处理
在样品检测过程中, 光谱常常会受到噪声、 背景、 基线漂移、 杂散光的干扰, 因此需要对光谱数据进行预处理, 以提高模型的预测性能。 考察了SG平滑、 1st Der、 2nd Der、 MSC、 SNV和CWT等六种光谱预处理方法对调和油各组分的预处理效果, 并确定每种组分的最佳预处理方法。 CWT处理时, 玉米油、 大豆油、 稻米油、 葵花油和芝麻油的最佳小波函数和分解尺度分别为db5, sym4, db19, coif5, db4以及37, 22, 40, 40, 25。
1.3.4 变量选择
变量选择是近红外光谱建立多元校正定量模型过程中的关键步骤, 在建立多元校正模型之前进行变量选择可以去除噪声和与目标属性无关的干扰变量, 从而提高模型的预测性能, 使模型更加可靠。 在预处理后光谱的基础上, 进一步采用了MCUVE和CARS两种方法对光谱进行变量选择。 MCUVE利用蒙特卡罗技术确定训练子集并建立大量PLS模型, 基于在建模过程中得到的每个变量相应系数的稳定性来筛选变量, 稳定性低于阈值的变量被淘汰。 与MCUVE筛选变量的方法不同, CARS在每次蒙特卡罗采样建模过程中, 通过指数递减函数强制变量选择和自适应重加权采样竞争变量选择结合的方法选择出PLS模型回归系数绝对值大的变量。 最终从N次蒙特卡罗采样中选出交叉验证均方根误差(root mean squarederror of cross validation, RMSECV)最小值对应的变量子集。
使用PLS建立模型, 利用RMSECV来优化模型的相关参数。 采用预测均方根误差(root mean squared error of prediction, RMSEP)、 预测相关系数(correlation coefficientof prediction, Rp)和剩余预测偏差(residual predictive deviation, RPD)评价模型优劣。 RPD高于2.5的模型可认为是稳健的, 它适用于预测目标属性[15]。
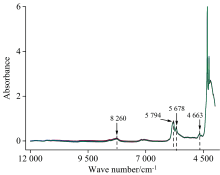
51个五元调和油样品的近红外光谱如图1所示。 从图中可以看出, 8 260, 5 796, 5 678和4 663 cm-1附近有比较明显的吸收峰。 8 260 cm-1表征— CH2和— CH3官能团C— H二级倍频伸缩振动的特征峰, 而5 796和5 678 cm-1附近为C— H一级倍频伸缩振动的特征峰。 4 663 cm-1附近的吸收峰是由不饱和脂肪酸— CH=CH— 官能团C— H一级倍频伸缩振动引起的。 51个五元调和油样品的近红外光谱非常相似, 且光谱重叠, 很难直接利用近红外光谱对调和油各组分进行定量分析, 需要借助多元校正方法, 建立样品光谱与各组分含量间的定量分析模型。
 | 图1 五元调和油样品近红外光谱图Fig.1 Near infrared spectra of quinary blend oil samples |
在优化后参数的基础上, 分别采用PCR, PLS, SVR, ANN和ELM五种多元校正方法建立五元调和油中各组分油定量分析的模型, 从而选取最佳的多元校正方法。 五种多元校正方法对五元调和油各组分含量预测的RMSEP值, 见表1。 模型的RMSEP值越低, 表明的模型预测准确性越好。 从表1可以看出, 除玉米油外, 就其他组分而言, PLS模型的RMSEP值最低, 具有最佳的预测准确性。 此外, 玉米油PLS模型的RMSEP值也较低。 因此, 选取PLS为最佳的多元校正方法, 用于建立五元调和油各组分的定量分析模型。
| 表1 五种多元校正方法对五元调和油各组分含量预测的RMSEP值 Table 1 RMSEP values of five multivariate calibration methods for each component in quinary blend oil |
尽管PLS为最佳建模方法, 但所建立模型的预测性能仍不理想, 尤其是葵花油。 采用SG平滑、 1st Der、 2nd Der、 MSC、 SNV和CWT对光谱进行预处理, 以提高模型的预测准确性。 光谱预处理后, 五元调和油各组分PLS模型含量预测的RMSEP值总结在表2中。 如表2所示, 除SNV和MSC外, SG平滑、 CWT、 1st Der和2nd Der均使调和油各组分PLS模型的RMSEP值不同程度降低。 其中就玉米油而言, SG平滑使PLS模型的RMSEP值降低程度最大; 就其他四种组分而言, CWT预处理的降低程度最大。 因此, 玉米油组分的最佳预处理方法为SG平滑, 其他四种组分的最佳预处理方法为CWT。
| 表2 不同预处理方法结合PLS对五元调和油各组分含量预测的RMSEP值 Table 2 RMSEP values of different preprocessing methods combined with PLS for each component in quinary blend oil |
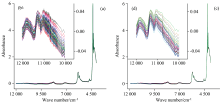
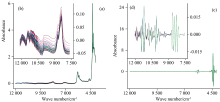
SNV和MSC预处理效果不理想可能是由于调和油样品粒径分布均匀, 光谱本身受散射光影响很小。 SG平滑预处理前后的近红外光谱图如图2所示。 从图2(a)调和油样品光谱图中看不出存在噪声, 但是将12 000~10 000 cm-1区域的光谱图放大后如图2(b)所示, 可以看出光谱存在明显的噪声。 而SG平滑预处理后12 000~10 000 cm-1区域的光谱图如图2(c)所示, 不能看到明显的光谱变化, 但将12 000~10 000 cm-1区间光谱图放大后如图2(d)所示, 可以看出光谱变得很平滑, 噪声被有效消除。 因此, SG平滑因有效去除噪声而具有较为理想的预处理效果。 1st Der和2nd Der只具有减少背景效应的作用, 虽然有一定的预处理效果但不如CWT预处理效果理想。 CWT对四种组分都是最佳的预处理方法, 从CWT预处理前后的光谱寻找原因。 CWT预处理前后的近红外光谱图如图3所示。 从图3(a)调和油样品光谱图中只能看到轻微的基线漂移, 看不到存在噪声, 但将12 000~7 500 cm-1区域的光谱图放大后如图3(b)所示, 可以看出光谱存在明显的噪声和基线漂移。 CWT预处理后的光谱图如图3(c)所示, 基线漂移得到明显改善, 进一步放大12 000~7 500 cm-1区域的光谱图, 见图3(d)可以看出噪声也被有效消除, 且能看到增多的谱峰。 因此, CWT具有除玉米油外的最佳预处理效果的原因是它兼具了平滑和求导的作用[17], 不仅可以有效消除噪声, 而且同时去除了基线漂移对信号的干扰并增强了光谱的分辨率。
 | 图2 SG平滑预处理前(a)和后(c)的近红外光谱图, 其中(b)和(d)分别为(a)和(c)在12 000~10 000 cm-1区域的放大图Fig.2 Near infrared spectra before (a) and after (c) SG smoothing preprocessing, (b) and (d) is the enlarged spectra in the region of 12 000~10 000 cm-1 |
 | 图3 CWT预处理前(a)和后(c)的近红外光谱图, 其中(b)和(d)分别为(a)和(c)在12 000~7 500 cm-1区域的放大图Fig.3 Near infrared spectra before (a) and after (b) CWT preprocessing, (b) and (d) is the enlarged spectra in the region of 12 000~7 500 cm-1 |
尽管光谱预处理后, PLS模型的预测准确性大大提高, 但是用于建模的变量还包含很多非信息的和与目标属性无关的干扰变量。 为了进一步优化模型性能, 本研究采用了CARS和MCUVE算法在预处理后光谱的基础上进一步进行变量选择。
采用变量数、 RMSECV值、 校正集交叉验证相关系数(correlation coefficients of cross validation, Rcv)和RPD评估与比较CARS和MCUVE两种变量选择方法对模型性能的影响, 计算结果总结于表3中。 RMSECV值越小, Rcv和RPD值越大, 模型的预测性能越好。 从表3可以看出, 与全光谱模型相比, 变量选择后所有单组分油模型的变量数均显著减少且CARS选择的变量数均少于MCUVE。 同时, 基于选择变量的模型在RMSECV, Rcv和RPD方面的结果更好。 表明光谱预处理后, 合适的变量选择方法不仅可以降低模型复杂度, 而且可以进一步提高模型的预测准确度。 通过综合比较, MCUVE在除玉米油和大豆油外的其他三种食用油模型中都比CARS结果略好。 因此, 玉米油和大豆油最佳变量选择方法为CARS, 而其他三种油的最佳变量选择方法为MCUVE。
| 表3 不同方法校正集样品各组分预测结果 Table 3 Predicted results for each component of the calibration set samples by different methods |
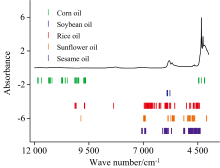
五元调和油各组分最佳变量选择方法所选变量的分布如图4所示, 作为参考, 还在图中绘制了平均光谱图。 绿色和蓝色短竖线分别为玉米油SG-CARS-PLS模型和大豆油CWT-CARS-PLS模型选择的变量, 红色、 橙色和紫色短竖线分别为稻米油、 葵花油和芝麻油CWT-MCUVE-PLS模型选择的变量。 需要说明的是变量选择是基于统计标准的, 不考虑化学因素, 以筛选特征变量建立高质量的校正模型为最终目的。 从图4可以看出, 不同食用油组分选择的变量不同, 其中玉米油选择变量的范围主要集中在12 000~9 500 cm-1, 其他四种食用油选择变量的范围主要集中在7 000~4 000 cm-1。 因此, 认为12 000~9 500 cm-1范围的变量被玉米油模型选择的概率更高, 可能包含更多与玉米油含量相关的信息, 上述讨论中SG平滑通过去除主要存在于12 000~9 500 cm-1范围的光谱噪声而对玉米油具有最佳预处理效果的结论也与此相符。 而7 000~4 000 cm-1范围内的变量被其他四种食用油模型选择的概率更高, 可能包含更多与它们含量相关的信息。
 | 图4 五元调和油各组分最佳变量选择方法所选变量的分布图Fig.4 Distribution of variables selected bytheoptimal method for each component of quinary blend oil |
基于最佳的光谱预处理、 变量选择和多元校正方法分别建立调和油各组分最佳模型并用于预测集五元调和油样品各组分含量的预测。 图5(a)— (e)和(f)— (j)分别显示了PLS模型和最佳模型预测值和真实值间的相关关系。 通过比较图5(a)— (e)和(f)— (j)可以明显看出, 与PLS模型相比, 最佳模型的点分布更加聚集且靠近回归线, 模型具有很好的相关性。 此外, 玉米油、 大豆油、 稻米油、 葵花油和芝麻油最佳模型的RMSEP值分别由最初的5.564 4, 5.559 2, 3.592 6, 7.421 8, 4.193 0下降到1.955 3, 0.562 4, 1.145 0, 1.619 0, 1.067 1, 预测准确度得到了很大的提升, 各组分RPD均大于3且Rp均大于0.98, 表明模型稳健且具有良好的预测准确度。
 | 图5 五元调和油各组分建模的预测值与真实值间的相关关系图 (a): 玉米油PLS; (b): 大豆油PLS; (c): 稻米油PLS; (d): 葵花油PLS; (e): 芝麻油PLS; (f): 玉米油SG-CARS-PLS; (g): 大豆油CWT-CARS-PLS; (h): 稻米油CWT-MCUVE-PLS; (i): 葵花油CWT-MCUVE-PLS; (j): 芝麻油CWT-MCUVE-PLSFig.5 The correlation between predicted and prepared contents (a): PLS for corn oil; (b): PLS for soybean oil; (c): PLS for rice oil ; (d): PLS for sunflower oil; (e): PLS for sesame oil; (f): SG-CARS-PLS for corn oil; (g): CWT-CARS-PLS for soybean oil; (h): CWT-MCUVE-PLS for rice oil; (i): CWT-MCUVE-PLS for sunflower oil; (j): CWT-MCUVE-PLS for sesame oil |
探讨了近红外光谱结合化学计量学对五元调和油中各单组分油定量分析的可行性。 对比五种多元校正方法的建模效果得出PLS模型预测效果优于其他模型。 为了提高模型的预测准确度, 进一步研究了六种光谱预处理和两种变量选择算法对PLS模型性能的影响以选取最佳方法。 研究结果表明, 最终建立的玉米油最佳模型为SG-CARS-PLS, 大豆油最佳模型为CWT-CARS-PLS, 稻米油、 葵花油和芝麻油最佳模型均为CWT-MCUVE-PLS, 最佳模型的RMSEP值分别为1.955 3, 0.562 4, 1.145 0, 1.619 0和1.067 1, RPD值均大于3且Rp值均大于0.98, 模型稳健且具有良好的预测准确度。 近红外光谱结合化学计量学可以对五元调和油中各单组分油进行快速准确定量分析, 是非常有前景的多元调和油定量分析工具。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|