{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
SiPLS-CARS与GA-ELM对哈密瓜冠层叶片含水率的反演估测
[郭阳1  , 郭俊先
, 郭俊先1, * , 史勇1 , 李雪莲1 , 黄华2 , 刘彦岑1 ]
, 郭俊先, 史勇|
|


作者简介: 郭阳, 1995年生,新疆农业大学机电工程学院硕士研究生 e-mail: 2744103108@qq.com
传统的叶片含水率检测方法效率低、 操作繁琐且是有损的检测, 不利于大田哈密瓜叶片含水率的快速获取。 为实现对大田哈密瓜生长期进行更精细的田间灌水管理, 利用光谱技术分别获取了哈密瓜植株在成长期(M1)、 开花期(M2)、 结果期(M3)、 成熟期(M4)四个时期内的冠层叶片样本, 采用烘干法测得叶片样本的含水率。 为提高预测模型的精度和稳定性, 首先开展并讨论极限学习机(ELM)模型中的核函数与隐含层神经元个数的选择对ELM模型精度的影响。 随后分别利用联合子区间偏最小二乘法(SiPLS)及其与竞争性自适应重加权采样法(CARS)、 遗传算法(GA)、 连续投影算法(SPA)的组合算法对全波段光谱数据中与叶片含水率相关性高的特征波长进行筛选提取。 再分别使用GA与粒子群算法(PSO )对已经确定最佳核函数与隐含层神经元个数的ELM模型中的输入层与隐含层间的连接权值(W)和隐含层神经元阈值(B)进行优化选择, 获取最优且稳定的W与B值, 进一步提高模型的稳定性和预测精度。 最后将四种特征波长提取算法优选出的特征波长分别进行ELM, GA-ELM, PSO-ELM建模分析, 以校正集和预测集的相关系数Rc与Rp为模型评价指标, 经过对比分析优选出能准确预测哈密瓜冠层叶片含水率的反演估测模型。 采用SiPLS及其与CARS, GA和SPA的组合算法提取特征波长, 筛选出的变量数分别为273, 20, 32和6, 占全光谱变量的15.6%, 1.2%, 1.9%和0.03%。 进一步将筛选出的特征波长作为自变量, 叶片的含水率作为因变量, 建立了ELM的预测模型, 最佳预测精度Rp值为0.845 0, 预测精度不是很理想。 故引入GA与PSO对ELM中随机产生的W与B值进行优化选择。 最终, 经过研究发现, 利用GA优化后的ELM模型结合SiPLS-CARS筛选出的特征波长建立的哈密瓜冠层叶片含水率预测精度最优, 故反演叶片含水率的最优建模方式为SiPLS-CARS-GA-ELM,Rc值为0.928 9,Rp值为0.903 2, 所建模型精度较高, 可为大田哈密瓜冠层叶片的含水率进行快速检测, 为田间灌溉管理提供科学依据。
To realize more precise irrigation management during the growing period of Hami Melon in the field. The traditional methods for measuring leaf moisture content are inefficient, complicated and destructive, which is not conducive to obtaining moisture content of Hami melon leaves in the field. In this study, the leaf samples of cantaloupe in four periods of growth (M1), flowering (M2), fruit (M3) and maturity (M4) were obtained by spectral technology, and the moisture content of the leaf samples was measured by drying method. The influence of the choice of kernel function and the number of hidden neurons on the precision of the ELM model is discussed. Then SiPLS and its combined algorithm with CARS, GA and SPA were used to extract the characteristic wavelengths with a high correlation with leaf moisture content. GA and PSO algorithms are used to optimize the connection weights (W) between the input layer and the hidden layer of the ELM model, and the threshold (B) of the hidden layer of the ELM model, the optimal and stable W and B values are obtained further to improve the stability and prediction accuracy of the model. Finally, four feature wavelength extraction algorithms are combined with ELM, GA-ELM and PSO-ELM to analyze the model, and the Correlation Coefficient between the correction set and the prediction set is taken as the evaluation index of the model. Through the comparison and analysis, the inversion estimation model of cantaloupe canopy leaf moisture content was optimized. The results show that the number of SiPLS and its combination with CARS, GA and SPA are 273, 20, 32 and 6 respectively, accounting for 15.6%, 1.2%, 1.9% and 0.03% of the total spectrum variables. Taking the selected characteristic wavelength as the independent variable and the moisture content of the leaves as the dependent variable, the prediction model of ELM is established, but the prediction accuracy is not very ideal. Therefore, GA and PSO are introduced to optimize the randomly generated W and B values in ELM. Finally, it is found that the precision of predicting water content of cantaloupe canopy leaves based on the ELM model optimized by GA and SiPLS-CARS is the best. Therefore, the optimal modeling method of leaf moisture content retrieval is SiPLS-CARS-GA-ELM,RC value is 0.928 9,RP value is 0.903 2, the precision of the model is high, which can be used to detect the leaf moisture content in cantaloupe canopy, the research provides the theoretical basis for the field irrigation management.
水是农作物的必备要素。 哈密瓜植株在生长的过程中若缺少水会影响其生长和哈密瓜的产量和品质。 哈密瓜叶片可通过光合作用和新陈代谢功能为哈密瓜植株的生长提供所必须的元素; 水也是植株叶片生长必不可少的元素之一。 因此, 如何能够快速获取哈密瓜植株叶片的含水量, 对监测大田哈密瓜生长和指导田间灌溉精细化管理以及节约新疆水资源具有重要的研究意义。
目前, 近红外光谱已经成为在工农业生产过程质量监控领域中不可或缺的重要分析手段之一, 这与该技术具有的本质特点, 主要包括测试方便、 仪器成本低、 分析速度快等。 利用近红外光谱可以实现对待测目标的理化指标和理化性质的无损检测[1, 2, 3, 4]。 光谱技术在植物叶片含水率的无损测定中同样应用广泛, 例如孙红[5]等利用CA和RF各筛选出15个特征波长, 然后结合PLSR建立了马铃薯叶片含水率的预测模型, 其训练集的决定系数为0.983 2, 预测集的决定系数为0.947 1。 李玉鹏[6]等利用可见近红外光谱获取烤烟叶片的原始光谱数据, 针对原始光谱数据进行平滑处理, 并结合PLS建立烤烟叶片的含水量, 最终模型训练集的相关系数为0.977 1, 预测集的相关系数为0.957 3, 表明该模型对预测烤烟叶片含水率是可行的。 孙俊[7]等通过获取高光谱图像并利用干燥法测量叶片含水率, 然后分别使用CARS, SR和SPA结合SVR预测油麦菜叶片含水率, 但预测精度不够理想, 引入ABC对SVR的参数进行优化, 最终的预测模型为CARS-ABC-SVR, 其预测集的决定系数为0.921 4, 均方根误差为2.95%。 陈香[8]等采用透射法对玉米叶片水分含量进行检测, 利用相关系数和主成分分析获取叶片含水率的敏感波段, 然后使用敏感波段进行组合获得12种植被指数, 最终选取了最优差值植被指数DVI(1 423, 800)与透射率T1323和T1058建立了玉米叶片含水率多元线性回归诊断模型, 建模集决定系数
本工作以新疆特色农作物哈密瓜冠层叶片为例, 基于SiPLS的特征区间选择以及与CARS, SPA和GA相组合的特征波长优选方法, 提取与叶片含水率相关性高的特征波长, 利用GA和PSO对ELM模型中随机产生的输入层与隐含层间的连接权值(W)和隐含层神经元阈值(B)进行优化, 再结合ELM, GA-ELM和PSO-ELM探讨不同建模方式下对哈密瓜叶片含水率预测准确性的影响, 并选取最优的预测模型来实现对哈密瓜叶片含水率精准、 无损且快速的检测, 为田间灌溉管理技术提供科学依据。
选取新疆哈密地区巴里坤县三塘湖镇中湖村为试验点, 该地形呈西高东低之势, 气候干燥酷热多风, 属典型的大陆性气候。 试验田位置为东经93° 51', 北纬43° 48'。
甜瓜品种: 金华蜜25号, 俗称“ 新86” , 晚熟品种, 生育期100 d, 单瓜重3.5 kg左右。
于2020年在哈密瓜植株成长期(M1)内的6月20日、 开花期(M2)内的7月1日、 结果期(M3)内的7月18日、 成熟期(M4)内的8月10日的四个时间点各随机获取50个哈密瓜叶片样本, 一共采集200个作为实验样本。 考虑到采集样本时田间蒸腾量大且易受气温的影响使叶片水分蒸发, 从田间采摘叶片后立即将其按照编号装进密封食品保鲜袋内, 带回实验室使用高精度天平(精度为0.1 g)称取哈密瓜叶片的鲜质量。
对称取过鲜质量的叶片样本使用美国海洋光学公司的maya2000微型光纤光谱仪测定其光谱数据, 光谱测定范围为200~1 100 nm, 光谱采样间隔为0.2 s。 主要工作参数设置包括积分时间为7 200 μs, 扫描次数为10, 平滑点数为3。 避开主叶脉在叶片左、 中、 右3个点采集近红外光谱数据再取这3次数据的平均值作为样本的原始光谱。 受到硬件的影响, 得到的光谱数据在光谱波段首端受到噪声影响较大, 故剔除, 最终使用的波段为380~1 100 nm。 将200个叶片样本按照3:1随机划分为150个校正集和50个预测集样本, 用于建模分析。
将称过鲜质量和已经测定光谱数据的样本放置到105 ℃烘箱内杀青30 min, 然后80 ℃下将叶片烘干至恒重, 称其干质量; 相对含水率的计算公式为
式(1)中: RWC为叶片相对含水率; FW为叶片鲜质量; DW为叶片干质量。
采集的原始光谱数据中除了包含样品本身的特征信息外, 还掺杂一些影响模型准确性的无用信息, 同时获取的光谱数据量大且复杂, 如果将所有的数据都用于建模, 不仅费时费力还影响模型的稳定性, 大量的数据计算会影响相对含水率的无损检测效率, 不利于快速检测。 因此有必要选取与相对含水率相关性较高的敏感波段, 然后再提取关键的特征波长, 简化模型的复杂程度, 提高模型的预测精度。
1.4.1 联合子区间偏最小二乘法
联合子区间偏最小二乘法(SiPLS)[11]是以常规区间偏最小二乘法为基础的一种方法, 其基本原理是将全光谱数据等均分成N个子区间, 然后对同一次区间划分中精度较高的几个局部模型所在的子区间联合起来, 建立PLS的回归预测模型, 以RMSECV作为模型的评价指标, 以此来确定最佳的联合子区间。
1.4.2 特征波长选择
为进一步降低输入变量的维度, 提高模型的预测精度, 在SiPLS的基础上分别结合GA[12]、 CARS[13]、 SPA[14]三种常见的特征波长选择算法, 对SiPLS筛选出来的联合子区间进行特征波长的选择, 进而实现数据降维, 简化模型, 提高模型预测精度的目的。
极限学习机(ELM)[15]相比于前馈神经网络等在运算过程中不需设定大量的参数, 且运算速度更快, 只需按照实际情况选择合适的激励函数(TF), 在算法运行过程中随机产生网络的输入权值及隐含层单元偏置, 且不需要调整, 比较容易实现。 因此, ELM具有学习速度快, 高强的泛化能力促使模型只有唯一的最优解等特点。 预测模型的评价指标为相关系数(R)和均方根误差(RMSE)。 其中校正集均方根误差为RMSEC、 预测集均方根误差为RMSEP; 校正集相关系数为Rc、 预测集相关系数为Rp, 预测模型的相关系数越大表示相关性越高; 预测模型的RMSEP越小, 模型的预测效果越好。
式(2)和式(3)中: xi为光谱数据;
以上光谱数据处理和定量预测模型的建立均使用Matlab2018b软件完成(美国, MathWorks), 采用Matlab2018b软件绘图。
ELM与其他预测模型相比, 其预测精度主要受隐含层神经元个数(N)和隐含层神经元的激活函数(TF)的影响, 同时输入层与隐含层间的连接权值(W)和ELM模型中的隐含层神经元阈值(B)是随机生成的, 这可能导致在给定参数时会出现数值为0的情况, 使得输出矩阵不满秩, 模型中的隐含层节点失效; 这使得ELM网络在建模的过程中不能自动寻找到最佳的网络结构, 进而在面对复杂, 无规律的数据时, 会造成模型的精度和稳定性较差。
为增强ELM网络稳定性和预测精度, 在确定ELM的最佳激活函数和隐含层节点数后使用遗传算法(GA)和粒子群算法(PSO)对ELM模型中的W和B的值进行优化选择, 以期实现对ELM预测模型的精度和泛化能力的提高。
1.6.1 利用GA优化ELM
使用GA对ELM模型中W和B的值进行优化选择, 其具体过程如下: (1)设置遗传算法的初始参数; (2)使用适应度函数(Fitness)对随机产生的初始种群的优劣程度进行评价, 且种群中每个个体都包含了ELM模型的初始权值和隐含层阈值, 并逐个计算种群内每个个体的适应度值, 适应度值越小, 所对应的个体就是越好的。
式(4)中: yij为训练集中部分样本的输出预测值; xij为训练集部分样本真值; k为训练集样本个数。 (3)把较优的个体使用选择、 交叉、 变异对种群进行优化, 进而获得新的种群。 然后检查是否满足进化条件, “ 否” , 返回重新计算, “ 是” , 运算结束, 选取最优的种群个体, 将其确定为最优的初始权值和隐含层阈值, 完成对ELM模型的优化。
1.6.2 利用PSO优化ELM
利用PSO算法寻优优化的能力, 可以在一定范围内实现对ELM模型中W和B的值完成优化选择, 避免ELM模型在预测过程中盲目性的训练, 进而实现对相对含水率预测精度提高的目的, 其具体过程如下: (1)设置粒子群算法的初始参数, 包括粒子群的规模、 空间维度、 惯性参数w、 学习因子c1和c2、 迭代次数和最大速度vmax等; (2)粒子群算法是将所有粒子对应的初始权值和隐含层阈值都代入到ELM模型中, 将模型预测的均方误差(MSE)作为粒子群算法的适应度, 并把粒子的当前最优和全局最优与最优适应度做对比, 若比最优适应度小, 说明当前输入权值和阈值所建立的ELM模型进行预测产生的均方误差较小, 则将当前粒子最优(P)和全局最优(G)更新为最优适应度, 依据式(5)和式(6)来确定全局最优位置。
式(5)和式(6)中: c1和c2为学习因子; r1和r2为0到1的随机数; w为惯性因子; v为粒子速度; X为粒子位置。 (3)将最优适应度更改为Pb和Gb, 然后当迭代次数达到最大值或适应度达到设定值时停止寻优, 把粒子群算法得到的最优初始权值和隐含层阈值代入ELM中, 实现对模型稳定性和精度优化的目的。
虽然ELM模型中的输入层与隐含层间的连接权值(W)和隐含层神经元阈值(B)是随机生成的, 但其隐含层神经元个数(N)和隐含层神经元的激活函数(TF)是可以通过设置来实现对模型预测精度和稳定性优化的目的, 因此在对ELM中的W和B进行优化前, 针对N和TF的设定进行讨论是非常有必要的。
(1)核函数的选择: 将所有样本的原始光谱作为ELM的输入变量, 然后分别使用“ sig” , “ sin” , “ hardlim” 三种核函数建立叶片相对含水率的预测模型, 预测结果如表1所示。 从中可以看出使用“ sig” 核函数建立的预测模型精度明显优于其他两个核函数, 其训练集相关系数为0.898 6, 预测集相关系数为0.879 7, 具有较强的预测能力, 因此选择“ sig” 作为ELM的核函数。
| 表1 不同核函数建立ELM模型的预测结果 Table 1 Prediction results of ELM model with different kernel functions |
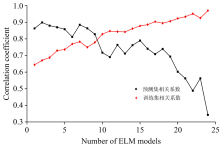
(2)隐含层神经元个数的选择; 一般隐含层神经元个数默认为训练集样本的个数, 这容易导致模型的稳定性和准确性易受样本量的影响, 不利于模型的通用性, 同时N的个数太少, 会导致模型“ 过拟合” , 数目过多会导致模型“ 欠拟合” 。 尝试选用5, 10, 15, 20, ···, 115, 120个隐含层节点数, 一共有24个ELM建模的预测结果, 对每种结果都进行5次的重复测试, 然后求其平均值以比较所有模型的拟合情况, 结果如图1所示。 从图中可以看出训练集的相关系数随着隐含层神经元个数的增加一直稳定上升, 但在第10个ELM模型(即隐含层神经元个数为60)之前, ELM预测模型一直处于“ 过拟合” 状态; 同时在第15个ELM模型(即隐含层神经元个数为75)以后, 预测集的相关系数开始快速下降, 而训练集的相关系数还在稳定上升, 这使得模型预测精度大幅下降。 因此选择隐含层神经元个数为75。
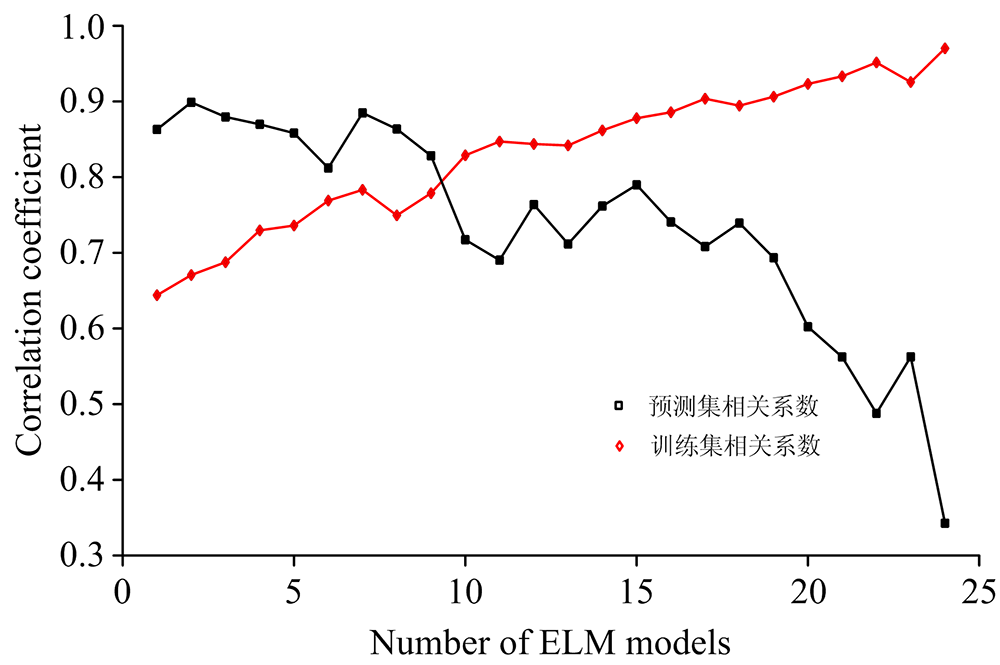 | 图1 隐含层神经元个数对模型的影响Fig.1 The influence of number of neurons in the hidden layer on the model |
2.2.1 基于SiPLS的特征区间选择
全波段的光谱信息中会存在一些与叶片含水率无关的光谱信息, 这样不仅会影响模型的准确性还会影响计算速度。 因此使用联合子区间偏最小二乘法(SiPLS)将全波段的光谱分成不同的联合子区间, 然后选择相关性最好的区间进行数据降维。 不同区间总数的划分结果如表2所示。
| 表2 子区间优选结果 Table 2 Results of subinterval optimization |
最终运行结果选择的最优子区间为[9, 14, 18], RMSECV的最小值为0.010 97, 总共筛选出273个光谱变量, 占总变量的16.6%。 接下来对优选的子区间利用特征波长提取算法进行数据降维, 进一步实现提高模型精度提高和简化模型的目的。
2.2.2 CARS结合SiPLS筛选特征波长
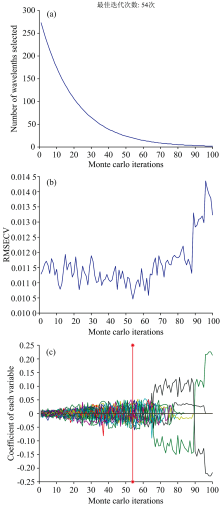
使用CARS算法对经过SiPLS选择的273个光谱变量进行特征波长选择, 进一步降低光谱数据的维度。 设置CARS的Monte Carlo采样次数为100, 并使用5折交叉验证的方式。 其中每次采样都是随机, 这使得每次CARS得出的结果都不一样, 故要得到较优的特征波长数, 需要多次进行验证比较。 最优的筛选特征波长变量如图2所示。
 | 图2 CARS筛选光谱变量过程 (a): 变量优化过程; (b): RMSECV变化趋势; (c): 回归系数变化Fig.2 CARS screening spectral variable process (a): Variable optimization process; (b): RMSECV trend; (c): Change of regression coefficient |
由图2(a)可知, 在前30次的采样中, 大量的波长被快速剔除, 之后缓慢的减少, 慢慢趋于平稳, 这体现粗选和精选的两个筛选阶段。 图2(b)是验证过程中RMSECV的变化过程, 在RMSECV达到最小值前, 误差表现出递减的趋势, 这表示有大量与哈密瓜叶片含水率无关的波长在被剔除。 图2(c)为RMSECV达到最小值时的第54次采样所对应的各波长回归系数的变化趋势, 故最后当RMSECV值为0.010 5时, 筛选出光谱变量数为20个, 只占原始光谱变量的1.2%。
2.2.3 GA结合SiPLS筛选特征波长
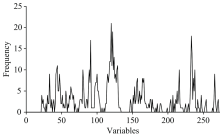
GA的控制参数设置为: 初始种群数为100, 变异概率0.01, 遗传迭代次数为100和变异概率0.5。 图3为GA迭代100次所选光谱变量的频率, 一共筛选出32个特征光谱变量。
 | 图3 光谱变量频率图Fig.3 Frequency of the variables selected |
2.2.4 SPA结合SiPLS筛选特征波长
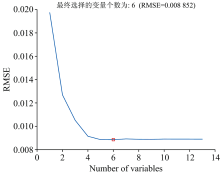
使用SPA算法对经过SiPLS选择的273个光谱变量进行特征波长选择, 进一步降低光谱数据的维度。 设置SPA的变量选择为1到20, 变量的选择过程如图4所示, 从图中可以发现RMSE的值是随被选择的波长数的变化而变化的, 当被选择波长数大于6时, 此时的RMSE的值趋于平稳, 变化不再显著, 此时的RMSE的值为0.008 852。 考虑到被选择波长数越少越能减少模型的运算量和复杂度, 因此最终选择的最优变量数为6。
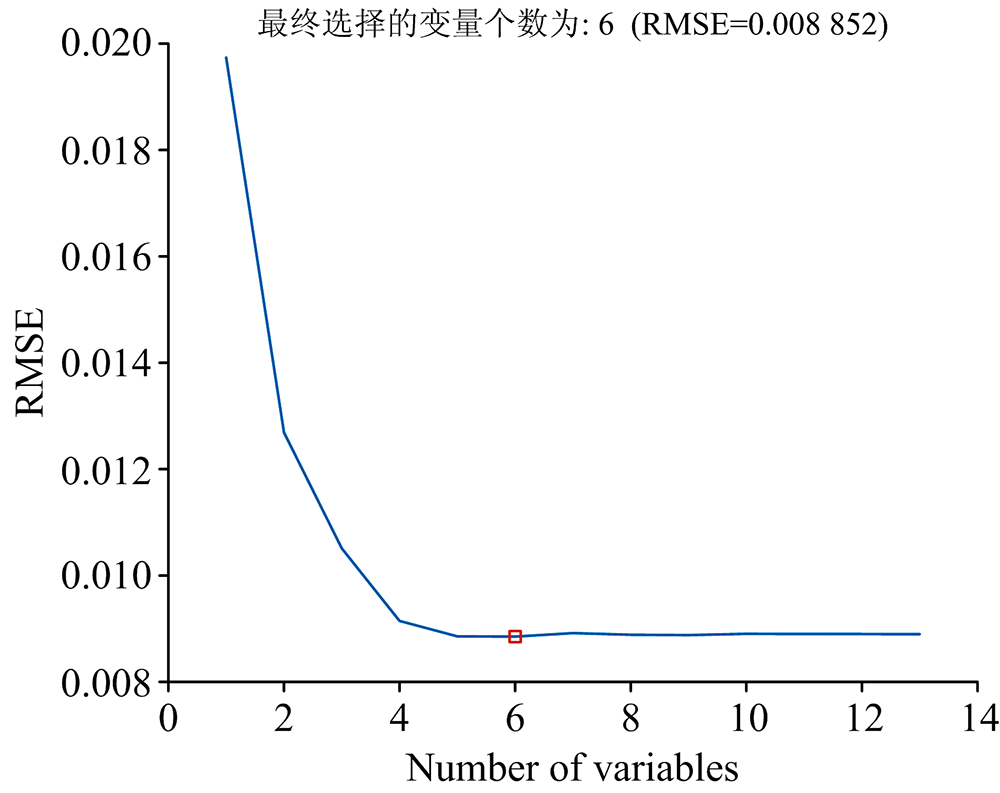 | 图4 SPA优选变量过程Fig.4 SPA optimization variable process |
2.3.1 基于GA与PSO对ELM的优化
在对光谱的特征波长进行选择后, 分别使用GA与PSO对ELM模型的输入层与隐含层间的连接权值(W)和隐含层神经元阈值(B)两个参数进行优化, GA的参数设定: 种群N为40, 最大遗传代数150, 代沟为0.95, 交叉概率0.7, 变异概率0.01; PSO的参数设定: 种群N为40, 最大遗传代数150, 学习因子c1=2, c2=2, 粒子的速度和位置为-1到1, 惯性权值为-1到1; 优化过程如图5和图6所示。
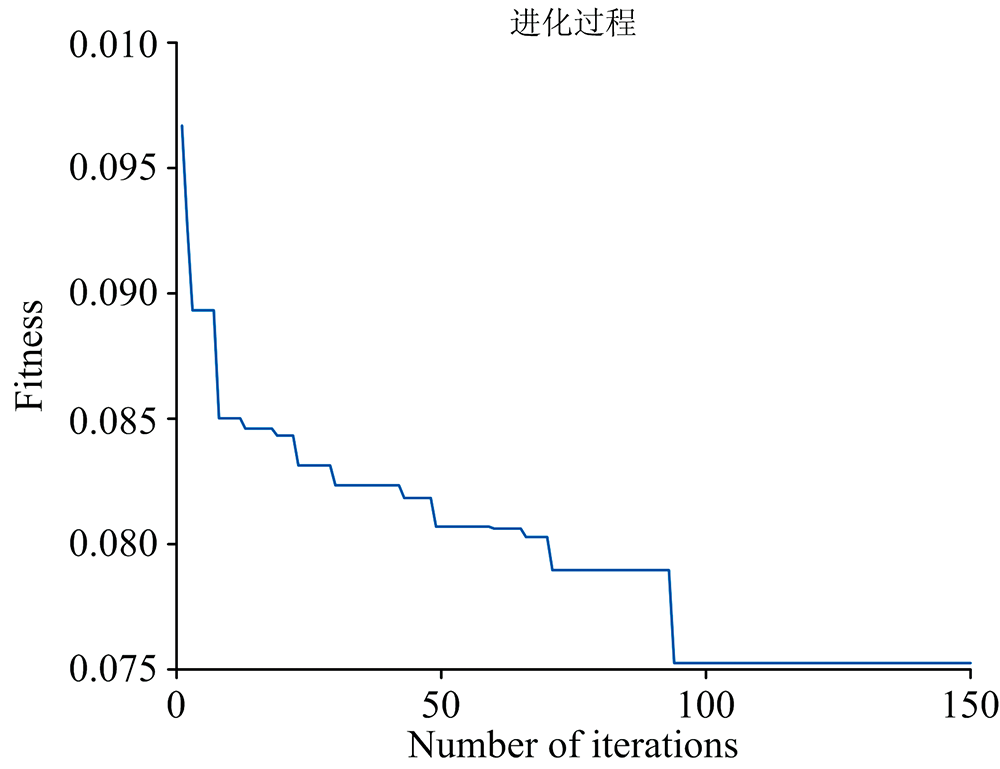 | 图5 GA寻优过程Fig.5 GA optimization process |
 | 图6 PSO寻优过程Fig.6 PSO optimization |
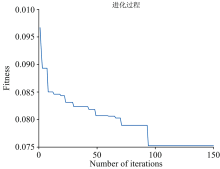
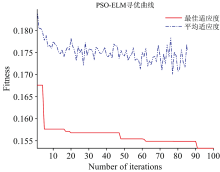
GA和PSO在寻优ELM的输入层与隐含层间的连接权值(W)和隐含层神经元阈值(B)的过程中, 随着迭代次数增加, 适应度函数的适应度值, 即模型的最终预测值与实际值的误差在逐渐减小, 从图中可以看出GA在迭代94次左右达到稳定, 适应度为0.075 2; PSO在迭代91次左右达到稳定, 适应度为0.153 3, 同时适应度越小, 选取ELM的W和B就愈加优秀, 故在迭代次数94和91处选取的参数最佳。
2.3.2 叶片含水率预测模型的建立
分别以SiPLS以及与CARS, GA和SPA相组合的4种特征波长选择算法获取与叶片含水率相关性高的波长变量, 将其作为ELM, GA-ELM和PSO-ELM建模分析的自变量, 哈密瓜冠层叶片的含水率作为模型因变量。 其中GA-ELM与PSO-ELM模型中的W和B参数是经过优化选择的, 建模结果如表3所示。
| 表3 叶片含水率预测建模效果 Table 3 Modeling results of leaf moisture content prediction |
由表3的数据可以发现, 基于SiPLS特征区间算法选择的特征波长变量所建立的预测模型的精度都低于SiPLS与CARS, GA和SPA三种特征波长相组合的方式, 这主要是因为SiPLS筛选出的特征波长数据量仍然较多, 里面还包含一些与叶片含率无关的波长变量, 导致模型的预测精度下降, 同时过多的波长变量也会增加模型的复杂程度。 因此SiPLS-CARS, SiPLS-GA和SiPLS-SPA三种特征波长筛选组合算法, 最终选取的波长白变量数为20, 32和6, 分别占全光谱变量的1.2%, 1.9%和0.03%, 三种组合算法不仅都大大简化了预测模型, 还提高了模型的预测能力, 表明准确的筛选出与叶片含水率相关性高的波长变量。
从表3可以看出, 所有ELM模型的预测精度都低于GA-ELM与PSO-ELM, 这表明遗传算法和粒子群算法优化ELM的参数后, 使得模型的预测精度得到了提升。 其中GA-ELM模型的精度明显高于PSO-ELM, 可能是因为GA与PSO在优化ELM过程中最佳适应度值分别为0.075 2与0.153 3, 明显GA的适应度值低于PSO, 而适应度值越小表示优化效果越佳, 同时适应度值代表最终预测值与实际值的误差, 故GA优化ELM的预测精度要优于PSO优化的ELM。 最终得到的最优预测模型为SiPLS-CARS-GA-ELM, 其预测集相关系数为0.903 2, 与PSO-ELM和ELM模型相比, 模型精度分别提高了0.019 3和0.058 2, 模型的输入变量也只有20个, 模型在精度和简化两方面都得到了提升, 故SiPLS-CARS-GA-ELM模型可以较好的实现对未知哈密瓜冠层叶片含水率的无损检测。
以哈密瓜冠层叶片为研究对象, 分别获取其成长期(M1)、 开花期(M2)、 结果期(M3)、 成熟期(M4)四个生长期内叶片样本的光谱数据, 并利用烘干法测得哈密瓜叶片的含水率, 将其作为模型的因变量, 建立哈密瓜叶片的含水率的定量预测模型, 实现哈密瓜叶片含水率的精准预测。 先对ELM的核函数和隐含层神经元个数进行优化设置, 然后利用GA和PSO对ELM中随机生成的输入层与隐含层间的连接权值(W)和隐含层神经元阈值(B)进行优化, 以期提高模型的预测精度。 然后采用特征区间提取算法SiPLS筛选出与叶片含水率相关性高的特征子区间为[9, 14, 18], 筛选出特征波长数273; 为降低模型的复杂程度, 对筛选出的特征区间和特征波长提取算法CARS, GA和SPA进行组合, 进一步筛选出与叶片含水率相关性高的特征波长, 并分别结合ELM, GA-ELM, PSO-ELM建立叶片含水率的定量预测模型。 结果表明: (1)提取的特征子区间[9, 14, 18], 以及与CARS, GA和SPA进行组合都有效的减少建模的变量, 最终得到的变量数分别为273, 20, 32和6; 变量压缩率分别为84.4%, 98.8%, 98.1%和99.97%; (2)建立的ELM模型预测精度并不是很理想, 引入GA、 PSO优化ELM的(W)与(B)后, 建立的预测模型精度相比与ELM得到了明显的提升, 经过对比分析得到最优预测模型为SiPLS-CARS-GA-ELM, 对应的Rc与RMSEC为0.928 9和0.848%, Rp与RMSEP为0.903 2和1.064%。 综合上所述, 利用SiPLS与CARS进行特征波长筛选, 经GA参数优化后, 可以极大提高ELM的预测精度和稳定性, 为新疆大田哈密瓜的田间管理提供了科学依据, 同时也为农作物叶片的含水率检测提供了参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|