






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
水稻产量遥感监测机器学习算法对比
[竞霞1  , 张杰
, 张杰1, 2 , 王娇娇2 , 明世康2 , 傅友强3 , 冯海宽2 , 宋晓宇2, * ]
, 张杰]
|
|


作者简介: 竞 霞, 1978年生, 西安科技大学测绘科学与技术学院副教授 e-mail: jingxiaxust@163.com
水稻是我国的主要粮食作物, 利用高光谱遥感技术在水稻未成熟之前对水稻产量进行监测, 一方面可以及时调整栽培管理方式, 指导合理追肥, 另一方面, 可以准确掌握水稻的产量信息, 帮助政府提前做出决策。 以2019年—2020年广州市白云区钟落潭试验基地氮肥梯度实验为基础, 分别获取水稻分化期和抽穗期冠层高光谱数据、 作物群体长势参数(生物量、 叶面积指数)及作物养分吸收量, 利用贝叶斯岭回归(BRR)、 支持向量回归(SVR)、 偏最小二乘回归(PLSR)三种方法建立各生育期的产量监测模型并进行精度对比, 确定水稻产量的最优估算时期和最佳估测模型。 结果表明, 三种方法中, BRR和SVR方法更适合产量监测, 在不同时期及不同的参数组合下均有较好的表现( R2>0.82, NRMSE<8.22%); 基于2019年与2020年数据, 采用全波段光谱信息进行产量监测时, 分化期最佳监测模型为BRR模型, R2为0.90, 抽穗期最优监测模型为SVR模型, R2为0.87; 采用全波段光谱协同作物群体长势参数进行产量监测时, 两时期最佳监测模型均为BRR模型, R2分别达到0.90和0.92; 相较于BRR模型和SVR模型, PLSR模型在不同时期和不同参数组合下, 最高 R2仅为0.75; 基于2020年数据, 以三种不同的参数组合作为输入时, 两时期估算结果均为BRR模型最优, 且分化期建模精度高于抽穗期( R2至少增加0.02, NRMSE至少降低0.61%); 当输入参数组合为全波段光谱协同作物群体长势参数、 作物养分吸收量时, BRR模型对产量的估算精度达到最高, R2为0.94。 分析认为产量的最优监测时期是分化期, 最优监测模型为BRR模型。 研究结果可为水稻产量的早期遥感监测提供参考。
, ZHANG Jie
Rice is China's major grain food crop, grown mainly in the Yangtze River valley and southern China and on the Yunnan-Guizhou Plateau. The use of hyperspectral remote sensing technology to monitor rice yield before it matures is important. It can promptly adjust cultivation management methods and guide reasonable fertilization, and accurately grasp rice yield information to help the government make decisions in advance. In this study, the nitrogen fertilizer gradient experiment was carried on 2019—2020 at Zhongluotan experimental base in Baiyun District, Guangzhou City. The rice canopy hyperspectral data, crop population growth parameters (plant above-ground biomass (AGB) and leaf area index (LAI)) and crop nitrogen nutrient intakes at the rice differentiation and heading stage were obtained. Three machine learning algorithms, Bayesian Ridge Regression (BRR), Support Vector Regression (SVR), and Partial Least Square Regression (PLSR), were used to establish yield estimate models based on the different data sources, including rice canopy spectrum data, spectrum data combined with crop growth parameters, and spectral data, crop growth parameters, and crop nutrient intake data. The estimation accuracy of BRR, SVR and PLSR models, were evaluated and compared, then the best estimation model and optimal estimation growth period for rice yield were determined. The results showed that among the three methods, the BRR and SVR methods were more suitable for yield monitoring, with better performance in different periods and different parameter combinations ( R2>0.82, NRMSE<8.22%). Based on the 2019 and 2020 data, the best monitoring model for yield monitoring using full-band spectral information was the BRR model at the differentiation stage with R2 of 0.90 and the SVR model at the tasseling stage with R2 of 0.87. When full-band spectral information was used for yield monitoring, the best monitoring model for both periods was the BRR model with R2 of 0.90 and 0.92, respectively, compared with the BRR and SVR models, the highest R2 of the PLSR model was only 0.75 for different periods and different combinations of parameters; based on the 2020 data, when three different parameter combinations were used as inputs, the BRR model was the best in both periods, and the modeling accuracy was higher in the differentiation period than in the tasseling period ( R2 increased by at least 0.02 and NRMSE decreased by at least 0.61%), and when the input parameter combinations were full-band spectra with crop population growth parameters and crop nutrient uptake, the accuracy of the BRR model for yield estimation reached Through the experimental study, it was concluded that the optimal monitoring period for yield is the differentiation period. The optimal monitoring model is the BRR model. The study results can provide a reference for early remote sensing monitoring of rice yield.
水稻是我国种植面积最大、 覆盖范围最广的粮食作物。 获取高产、 高品质的水稻是我国实施精准农业的新要求[1]。 基于高光谱信息的作物生长参数监测, 是农业遥感的研究热点。 建立水稻收获前的产量监测模型, 是精准制定田间管理措施、 快速评估水稻产量的可靠依据[2]。
大量学者已利用高光谱遥感对水稻等作物产量预测进行了深入研究[3]。 薛利红等在实测水稻高光谱反射率的基础上, 构建了基于光谱植被指数-叶面积氮指数的复合水稻产量估测模型, 取得了较好的估测精度[4]。 宋红燕等发现水稻植株氮含量的敏感波段是552和890 nm, 并基于氮素敏感波段构建了比值植被指数(ratio vegetation index, RVI)和绿色归一化植被指数(green normalized vegetation index, GNDVI), 依此构建的产量监测模型决定系数(R2)达到0.724[5]。 Kawamura等使用迭代逐步消除偏最小二乘法(iterative stepwise elimination partial least squares, ISE-PLS)对400~930 nm之间的波段进行逐步消除选择产量预测敏感波段, 建立水稻收获前产量估算模型, 模型最大决定系数为0.873, 认为水稻孕穗期为最佳估算时期[6]。 冯伟等对水稻叶片氮素参数、 冠层光谱等参数进行多时期相关性分析, 认为灌浆前期叶片氮素积累量和叶面积氮指数能够反映水稻籽粒产量状况, 实验结果表明利用水稻灌浆前期特征光谱参数和拔节— 成熟期特征光谱指数的累积值能够稳定预报水稻成熟期籽粒产量[7]。 目前关于高光谱数据的研究大多通过相关性分析等方法实现对数据的特征降维, 去除高光谱数据中的冗余信息, 以较少的特征参数参与模型的构建, 在降低模型构建难度的同时, 可能会丢失部分有效信息。 而机器学习模型具备强大的处理高维数据与冗余数据的能力, 能够有效抵抗高维数据中存在的噪声, 基于更高效益的数学方法与数据处理方式实现对数据中有效信息的提取[8, 9]。 Bao等在小麦品种的快速分类模型的构建中, 使用连续投影算法(successive projections algorithm, SPA)、 主成分分析算法(principal component analysis, PCA)和随机蛙跳(random frog, RF)三种特征提取方法, 从数百个光谱波段中筛选可用于建立分类模型的光谱变量, 使用线性判别分析(linear discriminant analysis, LDA)支持向量机(support vector machine, SVM)、 极限学习机(extreme learning machine, ELM)三种机器学习算法分别以全波段和经过特征筛选的波段作为输入变量进行小麦品种分类模型构建, 以全波段作为输入变量的ELM算法分类精度最优[10]。
水稻生长过程中, 植株本身在生长过程中水分供应、 光热吸收、 土壤养分固定等都会影响水稻的产量[11]。 本文根据前人研究, 选择水稻分化期与抽穗期冠层全波段光谱数据, 筛选与产量相关的植株地上生物量、 叶面积指数, 土壤养分参数等影响因子, 利用贝叶斯岭回归(Bayesian ridge regression, BRR)、 支持向量回归(support vector regression, SVR)、 偏最小二乘回归(partial least square regression, PLSR), 分别构建: (1)基于全波段光谱信息的产量监测模型; (2)基于全波段光谱信息协同长势参数的产量监测模型; (3)基于全波段光谱信息协同长势参数、 作物养分吸收量的产量监测模型。 探索不同算法在不同的输入参数下的适应性, 筛选最优变量因子, 为水稻产量遥感监测提供依据。
2019年— 2020年在广东省广州市白云区钟落潭试验基地(23° 23'24″N— 23° 23'59″N, 113° 25'48″E— 113° 26'24″E)开展水稻变量施肥的小区实验。 试验基地内, 2019年的试验品种为美香占2号(V1), 插秧时间2019年8月8日, 插秧密度为20 cm× 20 cm。 共设计15个小区采样测试; 每个小区插秧规格为16穴× 16穴。 2020年的试验品种为美香占2号(V1)和五丰优615(V2), 插秧时间为2020年8月8日, 共30个小区, 插秧密度为20 cm× 20 cm, 根据插秧规格, 每个小区16穴× 20穴。
2019年及2020年试验共设计5个氮素水平(N0, N1, N2, N3, N4), 分别为0, 60, 120, 180和240 kg N· ha-1, 设3次重复; 其中基肥、 分蘖肥、 穗肥的施用比例为5:2:3; 磷、 钾肥用量分别为54和144 kg· ha-1。
2019年和2020年分别于分化期(2019-09-13, 2020-09-10)和抽穗期(2019-10-11, 2020-10-09)进行水稻地上生物量(above ground biomass, AGB)、 叶面积指数(LAI)、 土壤营养参数及其他水稻品质相关数据的田间采集, 其中2019年每时期获取15个样本, 2020年每时期获取30个样本。 数据获取情况见表1。
| 表1 试验数据获取 Table 1 Test data acquisition |
水稻冠层高光谱数据采集使用美国ASD Filed Spec Pro 2500背挂式野外光谱仪, 光谱范围为350~2 500 nm。 根据前人的研究, 作物光谱的可见光与近红外范围已能够反映作物的生长状况, 因此本次实验采用454~950 nm的冠层光谱数据, 重采样后间隔为4 nm[12, 13]。 测量时间为北京时间10:00— 14:00, 期间天气晴朗, 在每一个采样点测量前后均用标准白板对冠层辐亮度数据进行校正。 探头距离冠层高度约1 m, 垂直向下, 探头角度为25° ; 每个采样点取10次测量平均值作为该样方的冠层辐亮度值。 同一年的试验中, 记录采样点的位置, 保证不同生育期同一小区在相同位置采集数据。 对测定的冠层辐亮度和白板辐亮度利用式(1)计算目标的光谱反射率。
式(1)中, R为冠层反射率, Ltarget为冠层辐亮度(μ W· cm-2· nm-1· sr-1), Lboard为白板辐亮度(μ W· cm-2· nm-1· sr-1), Rboard为白板反射率。
测量光谱后, 在小区内随机选择6穴水稻植株样本, 去根并逐丛计数茎蘖数, 分化期茎叶分离, 抽穗期将茎叶和穗分离, 测定叶面积2 000 cm2(S)左右, 将其烘干后记录重量(w1), 余叶也一并烘干称重(w2), 利用以式(2)计算叶面积指数(LAI)
式(2)中, γ 为取样植株样品穴数, D为种植密度, 由小区内水稻种植穴数除以小区面积得到。
根据采样点种植密度和水稻样本的干重计算单位面积植株的地上生物量(above ground biomass, AGB, g· m-2), 计算公式如式(3)
式(3)中, WL, WS和WE分别为水稻测试样本叶片、 茎、 穗的干重(g), γ 为取样植株样品穴数, D为种植密度。
2020年水稻抽穗期(2020年10月10日)及收获后(2020年11月25日)分别于不同氮肥处理小区获取田间0~20 cm土样, 测试土壤理化性质, 根据2020年试验小区施肥量、 土壤残留养分含量计算了不同小区作物可吸收养分量, 如式(4)所示
作物氮(磷、 钾)肥养分吸收量=施肥氮(磷、 钾)肥养分总量-土壤氮(磷、 钾)养分残留量 (4)
其中施肥养分量由试验中所施用氮、 磷、 钾肥料中有效养分含量百分比折算, 本试验中氮肥尿素中N含量46%, 钾肥氧化钾中K含量60%, 磷肥磷酸钙中P含量12%; 土壤养分残留量由土壤养分测试指标与耕层土质量相乘得到, 本研究中耕层土质量按照耕层厚度20 cm计算, 研究中未考虑肥料挥发及淋滤损失量。
于成熟期逐小区实收125丛稻株(5 m2)测产, 将稻谷风干, 取100 g左右于105 ℃下烘干48 h, 测定含水量, 然后将稻谷转换成含水量为14%的稻谷产量。
偏最小二乘回归(partial least square regression, PLSR)通过最小化误差的平方和, 寻找一组新的潜在变量来解释自变量X与因变量Y之间的统计关系, 并且可以在建模过程中实现对数据的主成分分析、 典型相关性分析和回归分析, 是一种常见的对数据进行降维处理、 解决数据多重共线性问题、 简化建模过程的线性回归方式[14, 15]。 贝叶斯岭回归(Bayesian ridge regression, BRR)是基于贝叶斯方法与最小二乘法的改进而提出的, 通过对线性贝叶斯回归模型加入L2正则化, 结合相关参数的先验信息形成先验分布并给出预估数值[16]。 支持向量回归(support vector regression, SVR)的基本思想是通过寻找最优划分超平面, 忽略小于偏差ε 的的样本, 对其他样本进行回归; 偏差ε 的引入是SVR区别于传统回归模型的地方, 即以预测y值为中心, 与真实y值之间存在一个宽度为2ε 的区域, 在此区域内, 预测y值与真实y值的差别认为是0。 其回归模型为f(x)=wTx+b, w和b为模型待确定参数[17]。 它能够较好的完成自变量与因变量之间的非线性回归。
利用PLSR, BRR和SVR三种算法构建水稻产量估算模型时, 采用k-fold交叉验证方法进行建模, 即将样本集随机分为k组子数据集, 轮流使用其中的k-1份子数据集建模, 另一份作为验证, k次建模后的均值为模型的精度。 采用决定系数(R2)和归一化均方根误差(normalized root mean square error, NRMSE)两个指标联合验证模型预测精度, R2越大, 代表模型拟合度更高, NRMSE越小, 模型稳定性越好, NRMSE< 10%表示模型具有较好的稳定性。
2.1.1 水稻产量与不同生育期AGB、 LAI的相关性分析
2019年与2020年合并后的水稻产量与AGB和LAI进行相关性分析可知, AGB, LAI与产量在分化期相关系数分别为0.809和0.678, 抽穗期AGB和LAI与产量的相关性则是有所下降, 分别为0.635, 0.590, 但都达到了0.001水平显著(r(0.001)=0.474, n=45)。 2020年水稻产量与AGB、 LAI进行相关性分析, 分化期与抽穗期所有长势参量均达到了0.001水平显著(r(0.001)=0.570, n=30), 两时期比较, 分化期相关系数高于抽穗期, AGB、 LAI与产量在分化期相关系数分别为0.596和0.839, 抽穗期相关系数分别为0.586, 0.696。 同时, LAI与AGB同样具有较高的相关性, LAI代表叶片尺度植株的生理状态, AGB可表示植株地上部分整体的发育状况; 由于水稻产量的形成是一个动态且复杂的生物学过程, 在同一生育时期, 不同的长势参数可能对水稻的产量形成具备不同的作用机理, 故建模过程中同时加入AGB和LAI两个长势参量探究其对产量形成的影响。
2.1.2 水稻产量作物养分吸收量的相关性分析
于2020年10月10日, 水稻分化肥施用1个月之后, 以及11月23日, 水稻成熟收获后, 分别采集不同氮肥处理小区土壤数据, 进行土壤养分测试, 获取小区土壤碱解氮(mg· kg-1)、 速效钾(mg· kg-1)及有效磷(mg· kg-1)含量数据。 根据小区施肥量数据及土壤养分残留含量数据, 分别计算了作物养分吸收量, 并分析了水稻抽穗期及成熟期养分吸收量与AGC、 LAI及产量的相关关系, 结果如表2所示。
| 表2 2020年AGB、 LAI及产量与作物养分吸收量的相关性(n=30) Table 2 Correlation between biomass, LAI, yield and crop nutrient uptake in 2020 |
抽穗期作物养分吸收量与产量的相关系数分别为0.713, -0.086和0.526; 成熟期作物养分吸收量与产量的相关系数分别为0.723, -0.242和0.402, 其中两时期作物吸收N与作物吸收K和产量具有较好的相关性, 作物吸收P则与产量线性关系不显著, 但不能排除是否存在其他关系; 分化期与抽穗期的AGB、 LAI和两时期作物吸收N均达到了极显著相关, 最大相关系数为0.818。 由于成熟期作物吸收N, P和K量在水稻成熟后才可获取, 难以实现水稻产量早期监测, 故模型中土壤养分参数仅使用至抽穗期作物吸收N, P和K量。
2.1.3 冠层光谱与水稻长势参数的相关性分析
如图1、 图2所示, 对水稻分化期与抽穗期冠层光谱与长势参数进行相关性分析, 2019年与2020年所有长势参数在两生育期相关系数有所不同, 但均具有相似的变化趋势, 近红外部分均保持在某一值持平, 整体变化幅度很小且以正相关为主, 可见光部分则以负相关为主。 所有长势参数在550 nm附近出现相关性“ 低谷” , 相关系数低于其他可见光部分。 在可见光区域与近红外区域的交界处, 光谱反射率受叶片内细胞间隙折射率不同的影响, 反射率急剧增加, 相关系数迅速由负转正, 有明显的降低后再抬升的趋势。
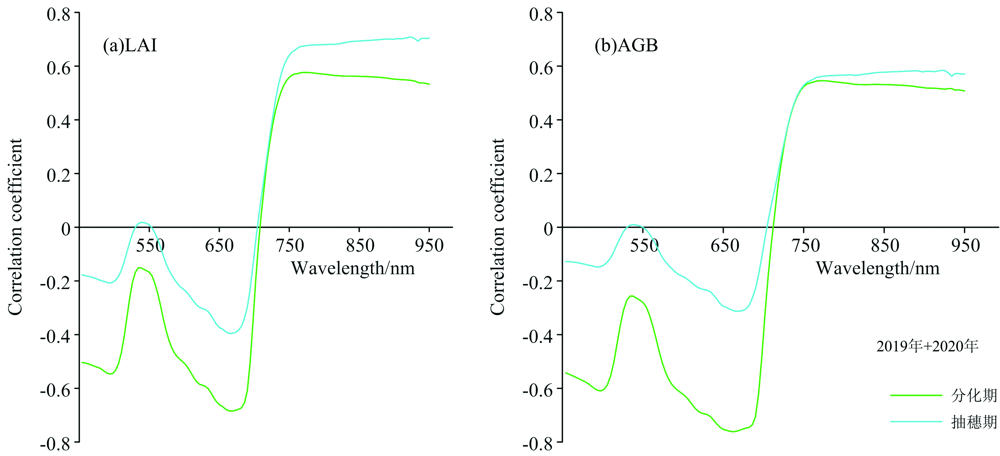 | 图1 2019年与2020年水稻不同生育期冠层光谱与长势参数相关性Fig.1 Correlation between canopy spectra and growth parameters at different growth stages of rice in 2019 and 2020 |
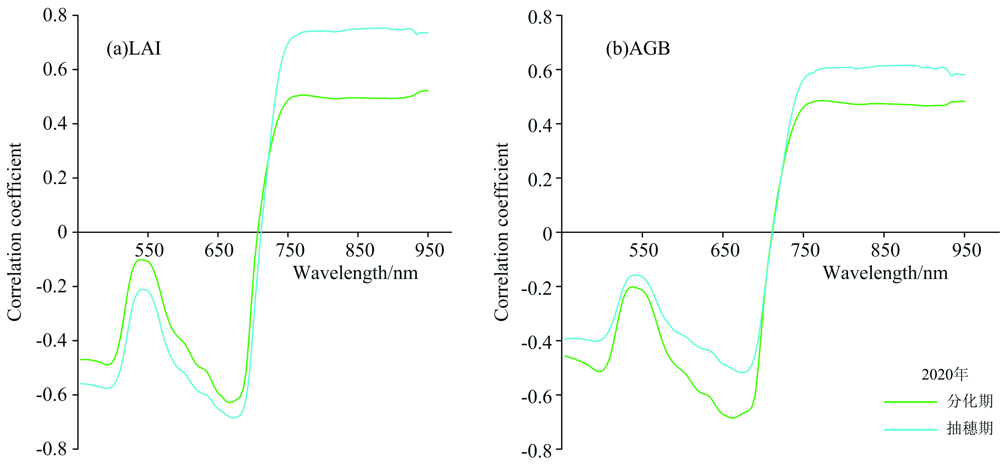 | 图2 2020年水稻不同生育期冠层光谱与长势参数相关性Fig.2 Correlation between canopy spectra and growth parameters at different growth stages of rice in 2020 |
图1(a)和(b)是将2019年与2020年数据分生育期合并后的冠层光谱与长势参数的相关系数, LAI与AGB在两时期具有相似的变化趋势, 在可见光部分, 抽穗期LAI与AGB同冠层光谱的相关性较差, 均未超过0.4, 分化期明显优于抽穗期, 尤其在602~690 nm之间, 冠层光谱与LAI最大相关系数达到-0.685(666 nm), 与AGB最大相关系数达到-0.762(62 nm), 在近红外部分, 则是抽穗期优于分化期且LAI与冠层光谱的相关性更高, LAI与AGB的最大相关系数分别为0.708(922 nm)、 0.584(922 nm)。 图2(a)和(b)为2020年两生育期冠层光谱与长势参数的相关性, LAI与冠层反射率相关性全波段抽穗期高于分化期, 在近红外区域相差0.1左右, 分化期最大相关系数-0.623(666 nm), 抽穗期最大相关系数为0.753(886 nm), AGB与冠层反射率相关性在可见光区域分化期高于抽穗期, 而在近红外区域抽穗期更高, 分化期最大相关系数为-0.665(662 nm), 抽穗期最大相关系数为0.616(878 nm)。
LAI与AGB在冠层光谱的大部分区域均表现出较强的相关性, 可以认为LAI与AGB参数能够被冠层光谱较好的表达, 而LAI与AGB和产量的相关性达到极显著水平, 故利用作物生长前期的光谱数据进行产量监测是可行的。
分别使用BRR, SVR和PLSR构建水稻产量预测模型, 基于2019年与2020年合并后分化期(n=45)和抽穗期(n=45)数据, 构建基于全波段光谱、 全波段光谱+AGB、 LAI的产量预测模型; 基于2020年分化期(n=30)和抽穗期(n=30)数据, 构建基于全波段光谱、 全波段光谱+AGB、 LAI, 全波段光谱+AGB、 LAI+作物养分吸收量的产量预测模型; 表3为三种方法使用2019年与2020年数据建模的决定系数(R2)与归一化均方根差(NRMSE), 表4为三种方法使用2020年数据建模的决定系数(R2)与归一化均方根差(NRMSE)。
| 表3 基于2019与2020年数据的模型精度(n=45) Table 3 Model accuracies based on the data in 2019 and 2020 |
2.2.1 基于光谱信息与农学参量的水稻产量预测
由表3可知, 以全波段光谱作为输入参数时, 三种方法所建立的产量预测模型, 分化期精度优于抽穗期, BRR模型在分化期R2达到了0.897 1, NRMSE为6.76%, 较抽穗期R2高0.032 4, NRMSE低1%; SVR模型在分化期R2为0.877 6, NRMSE为7.59%, 抽穗期R2为0.865 5, 两时期预测精度与模型稳定性接近, 而PLSR模型在分化期的R2较抽穗期相差较大, 相差0.199, NRMSE相差3.6%。 以全波段光谱+AGB、 LAI作为输入参数时, BRR模型与SVR模型抽穗期精度则优于分化期, 其中BRR模型在分化期R2为0.903 0, NRMSE为6.57%, 在抽穗期R2为0.915 2, NRMSE为6.24%, R2均达到0.9以上; SVR模型在分化期较仅输入全波段的模型精度反而有所下降, R2降低0.027 5, 抽穗期模型较仅输入全波段的模型精度有提升, 但提升不大; PLSR模型则是在分化期表现较好, 但仍未能超过BRR模型与SVR模型的预测精度。 从整体来看, BRR模型在仅使用全波段作为输入参量时已取得较好的预测精度, 加入长势参数时, 离群点变的更少, 所有点基本位于0误差线两侧, 对产量中的较大与较小值均有较好的预测效果。
 | 图3 基于全波段光谱的产量预测模型Fig.3 Yield prediction model based on full band spectra |
 | 图4 基于全波段光谱— 长势参数的产量预测模型Fig.4 Yield prediction model based on full band spectrum-growth parameters |
2.2.2 基于光谱信息-农学参量及作物养分吸收量的水稻产量预测
基于2020年分化期与抽穗期数据所建的产量预测模型, 以全波段光谱作为输入参数时, 三种模型在分化期的模型精度优于抽穗期模型精度; 以全波段光谱+AGB、 LAI作为输入参数时, 分化期BRR模型R2提高至0.925 0, 抽穗期BRR模型R2提高至0.905 7, SVR模型与PLSR模型较仅输入全波段时未有较大提升, 但SVR模型仍具有良好的估测精度; 以全波段+AGB、 LAI+作物养分吸收量作为输入参量时, BRR模型在分化期R2达到最大, 为0.940 3, NRMSE为4.34%, 抽穗期模型R2为0.922 4, NRMSE为4.95%, 散点分布均匀, 在分化期模型估算精度更好, SVR模型则是在抽穗期模型估算精度更好。 PLSR模型在分化期与抽穗期表现均低于BRR模型与SVR模型, 且离群点更明显。
| 表4 基于2020年数据的模型构建精度(n=30) Table 4 Model construction accuracy based on the data in 2020 |
分别以2019年与2020年分化期与抽穗期水稻全波段光谱、 全波段光谱+作物长势参数、 全波段光谱+作物长势参数+作物养分吸收量作为自变量, 采用BRR, SVR和PLSR三种回归模型对水稻产量进行建模估计, 选取最佳估算模型与最佳估算时期。 实验结果表明, 利用分化期与抽穗期冠层光谱监测当季水稻产量是可行的; 三种方法中, BRR模型能够更有效的对水稻产量进行估计, 各生育期估算均达到最优, 基于2019年与2020年数据的模型, 最大R2为0.915 2, 基于2020年数据, 最大R2为0.940 3, 在仅输入全波段光谱的时候也取得了较好的估算结果; 加入水稻长势参数、 作物氮素吸收量后, 能够有效提高模型的拟合优度与稳定性, 这是由于水稻产量与作物不同时期吸收和转化来自土壤和环境的养分存在密切关系, 合理优化作物养分吸收能够有效提高作物产量。 综合对比下, 水稻产量的最佳估算时期是分化期; BRR和SVR两种机器学习模型的估算精度在两种监测模型中均优于PLSR, 虽然PLSR选取了较少的参数, 降低了模型复杂度, 但是也丢失了部分可用来估算水稻产量的信息波段, 而两种机器学习模型利用所有信息进行回归建模, 较大程度的保留了与水稻产量相关的信息, 且简化了数据处理流程; 在不同时期与不同输入参数下, 基于先验分布的BRR模型能够更好的解决高光谱数据中的多重共线性问题, 对于数据中存在的噪声能够有效抵抗, 在具有上百个波段的高光谱数据的输入下, 保持了模型的稳定性, 有利于模型的推广。
 | 图5 基于全波段光谱的产量预测模型Fig.5 Yield prediction model based on full band spectrum |
 | 图6 基于全波段光谱— 长势参数的产量预测模型Fig.6 Yield prediction model based on full band spectrum-growth parameters |
 | 图7 基于全波段光谱— 长势参数— 作物养分吸收量的产量预测模型Fig.7 Yield prediction model based on full band spectrum-growth parameters-crop nutrient absorption |
本工作仅选用了BRR, SVR和PLSR三种方法构建水稻产量的模型, 未能选用更多的方法进行监测模型建立, 若增加其他方法, BRR方法是否还能保持最优还有待研究。 此外, 将不同参数作为自变量进行输入时只是简单拼接, 未考虑不同参数的权重分布, 不同参数与产量是否存在最优映射的关系有待下一步研究。 全波段建模方法需要算法具有良好的噪声抵抗能力, 进一步提高算法的噪声抵抗能力以及稳定性, 有利于获取更好的监测精度。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|