






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱和卷积神经网络的大白菜农残检测
[姜荣昌1, 2  , 顾鸣声
, 顾鸣声2 , 赵庆贺1 , 李欣然1 , 沈景新1, 3 , 苏中滨1, * ]
, 顾鸣声]
|
|


作者简介: 姜荣昌, 1982年生, 哈尔滨市大数据中心高级工程师, 东北农业大学电气与信息学院博士研究生e⁃mail: jake_jrc@harbin.gov.cn; jake_jrc@qq.com
针对大白菜农药残留传统化学检测手段存在前期处理过程繁琐、 检测周期长等不足, 提出了一种快速无损识别大白菜农药残留种类的方法。 以1组无农药残留和4组含有均匀喷洒农药(毒死蜱、 乐果、 灭多威和氯氰菊酯)的大白菜样本为研究对象(药液浓度配比分别为0.10, 1.00, 0.20和2.00 mg·kg-1), 经12小时自然吸收后, 利用高光谱成像系统获取400~1 000 nm高光谱图像, 并选取ROI感兴趣区域后经多元散射校正(MSC)预处理; 分别采用竞争性自适应重加权算法(CARS)、 主成分分析算法(PCA)和离散小波变换(DWT)降维(分别基于db1, sym2, coif1, bior2.2和rbio1.5小波基函数); 最后, 将降维后的高光谱数据分别输入卷积神经网络(CNN)、 多层感知机(MLP)、 K最邻近算法(KNN)和支持向量机(SVM)建立模型并比较。 结果显示, CNN, MLP, KNN和SVM算法均在降维算法DWT(小波基函数及变换层数分别为coif1-2, coif1-4, bior2.2-2和sym2-2)取得最优总体精度分别为91.20%, 83.20%, 66.40%和90.40%, Kappa系数分别为0.89, 0.79, 0.58和0.88, 预测集用时分别为86.01, 63.23, 20.02和14.03 ms, 总体精度和Kappa指标均优于基于CARS和PCA降维算法建模结果。 可见, 高光谱与离散小波变换和卷积神经网络相融合显著提高分类识别精度, 改善“休斯”现象, 为实现无损和快速检测识别大白菜农残提供一个新的方法。
Traditional chemical detection methods for analyzing pesticide residues in chinese cabbage are slow and destructive. In this study, a rapid, non-destructive method for identifying the types of pesticide residues in chinese cabbage samples was developed. First, the hyperspectral imaging system was used to analyze chinese cabbage samples exposed to one of four pesticides chlorpyrifos, dimethoate, methomyl and cypermethrin. The pesticide concentration ratios were 0.10, 1.00, 0.20 and 2.00 mg·kg-1, respectively; and the data was compared to a pesticide-free sample. After 12 hours of natural degradation at room temperature, a hyperspectral imaging system corrected by a black and white plate was used to obtain 400~1 000 nm hyperspectral images of chinese cabbage samples, and the target area was selected by ENVI software. The specific regions of interest (ROI) in samples were further investigated, and the pre-processing by multiple scattering correction (MSC). Secondly, three algorithms such as competitive adaptive reweighting algorithm (CARS), principal component analysis (PCA), discrete wavelet transform (DWT) (based on db1, sym2, coif1, bior2.2, and rbio1.5 wave base functions) were then used to screen for dimensionality reduction from optimally pre-processed results. Finally, the screening results and the samples divided by the Kennard-Stone algorithm were adopted to construct three recognition models separately. Such as k-nearest-neighbor (KNN), support vector machine (SVM), multilayer perceptron (MLP) and convolutional neural network (CNN) were used to determine the best screening method for the dimension of pesticide residues and the optimal hyperspectral recognition model. Our results showed that the CNN, MLP, KNN, and SVM algorithms achieve the best overall accuracy (91.20%, 83.20%, 66.40%, and 90.40%, respectively), Kappa coefficient (0.89, 0.79, 0.58, and 0.88), and the prediction set time (86.01, 63.23, 20.02 and 14.03 ms) under the dimensionality reduction algorithm DWT, respectively; the wavelet basis function and the number of transform layers are coif1-2, coif1-4, bior2.2-2 and sym2-2. All three indicators are better than the modeling results based on CARS and PCA dimensionality reduction algorithms. It showed that the combination of discrete wavelet transform and convolutional neural network shortens the time of classification and identification and significantly improves the classification and identification accuracy, and improves the Hughes phenomenon, providing a new method for non-destructive and rapid detection and identification of chinese cabbage pesticide residues.
大白菜营养丰富价格低廉, 经过加工腌制后可做成泡菜、 酸菜等, 是老百姓餐桌上不可或缺的美味佳肴。 在大白菜种植过程中不可避免的使用农药来防治病虫害。 一些农户缺乏农药用药常识, 片面追求高产, 使得农药的不规范使用、 滥用问题日益严重, 造成大白菜叶片中残留过量农药; 实验证明成年人长期食用含有农药残留超限的蔬菜后, 会出现腹泻、 肠道菌群失调或慢性中毒等不同反应; 儿童会出现非正常性生理早熟、 智力发育迟缓, 重度可导致身体畸形和基因突变。 因此, 如何无损、 快速、 准确的进行大白菜农残检测具有十分重要的意义。
现阶段农药残留化学检测常用方法有理化分析法和免疫分析法, 虽然这两种方法具有高灵敏度和精度, 但是, 理化分析法和免疫分析法检测前都需要较复杂的预处理工序, 费时、 费力、 有破坏性, 而且易出现假阴性或假阳性[1]等现象。 随着光谱技术不断进步, 基于光谱技术的农药残留检测应用逐渐增多, 常见的光谱技术有基于拉曼和红外光谱技术[2, 3], 由于检测机理的限制, 拉曼和红外光谱易受环境干扰, 影响测量精度和灵敏度。
近几年高光谱技术在农作物农药残留检测方面应用逐渐增多, 高光谱技术与拉曼和红外等光谱技术相比具有图谱合一的优点, 不仅提供光谱空间分布信息, 而且高度连续且密集光谱信号可对被测物体化学组成精确定量分析; Sun等[4]利用高光谱技术获取生菜叶片高光谱数据并建模, 基于随机森林-递归特征消除-连续投影算法-最小二乘支持向量回归(RF-RFE-SPA-LSSVR)模型能够识别混合农药残留, 模型预测准确率为93.86%。 吉海彦等[5]利用高光谱成像仪采集菠菜叶片900~1 700 nm光谱数据, 采用卡方检验特征选择算法筛选出8个特征波长后, 再利用支持向量机建立识别模型, 模型预测准确率为99.30%, 能够准确识别菠菜叶片农药残留。
针对现阶段农药残留检测方法的不足和大白菜农残无损、 快速检测空白, 利用高光谱技术的优点, 提出了一种基于高光谱离散小波变换和卷积神经网络(CNN)的大白菜农药残留检测识别算法, 应用于大白菜样本高光谱数据集, 验证所提算法的可靠性和准确度, 为后期建立基于便携式农药残留检测设备打下基础。
实验所用的大白菜样本均采购于哈尔滨市某大型商超。 实验农药为40%毒死蜱(市售, 河北八源生物制品有限公司)、 58.00 mg· L-1乐果(网购, 中国计量科学研究院)、 90%灭多威(市售, 山东华阳农药化工集团有限公司)和4.5%氯氰菊酯(市售, 安徽尚禾沃达生物科技有限公司)。 按照《中华人民共和国食品安全国家标准GB2763— 2019》中大白菜最大农药残留限量要求, 分别将毒死蜱、 乐果、 灭多威和氯氰菊酯分别配置0.10, 1.00, 0.20和2.00 mg· kg-1的药溶液分别装入4个喷壶内, 喷射距离8~10 cm, 每种药溶喷洒10个样本, 共计40个样本, 均匀喷后平放置于室温(温度20 ℃, 湿度65%RH)自然吸收12 h后采集高光谱影像数据(共50个样本, 其中10个为无农药残留样本)。
高光谱采集设备使用美国Headwall Photonics公司生产的高光谱成像系统, 由面阵CCD、 光栅光谱仪、 高光谱成像镜头、 均匀光源、 一维电动台、 USB1394图像采集卡、 高性能图形工作站及相关采控软件构成。 实验所用高光谱相机分辨率为1 000× 164 Pix, 位深度为24 bit, 线性阵列扫描成像方式; 光栅光谱仪的光谱范围为400~1 000 nm, 共有800个波段, 光源由2个200 W溴钨灯构成, 位于电动台两侧, 入射角呈45° ; 采控软件通过RS232串口控制电动台移动速度及方向, 如图1所示。
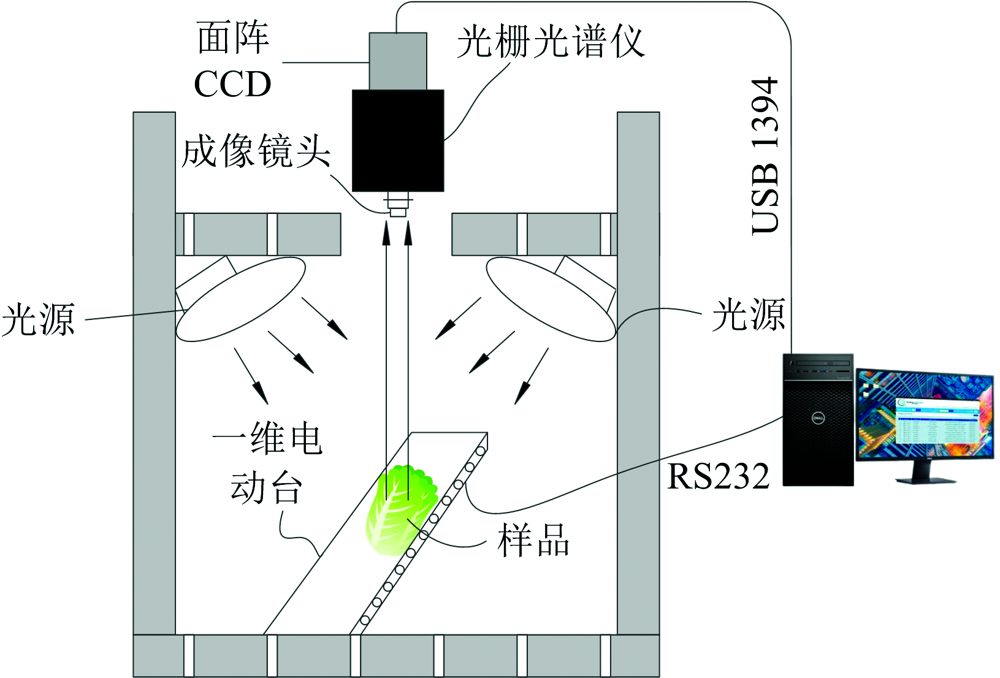 | 图1 高光谱成像系统结构示意图Fig.1 Schematic diagram of hyperspectral imaging system |
高光谱图像采集过程中会受到两方面干扰, 一方面是由于大白菜样本形状各异、 表面高低不平等原因会产生漫反射; 另一方面是由于电网中暗电流和谐波的存在, 导致相机工作状态不稳定, 产生较大的图像噪声, 影响光谱采集效果。 因此, 在采集前必须对高光谱相机进行参数设置和黑白校正, 经多次调试和效果比对, 最终曝光时间设置为0.03 s, 电动台的移动速度参数设置为3.0 mm· s-1, 镜头垂直向下距电动台450 mm。
后续所使用的数据分析处理软件包括: ENVI 5.2(ITT Visual Information Solutions, Boulder, Co., > USA), OriginPro 8(OriginLab Co., Ma, USA), The Unscrambler X 10.4, Python 3.6, TensorFlow 2.0等软件。
为方便数据采集将大白菜样本裁剪为16 cm× 8 cm长方条, 使用ENVI软件在每个大白菜样本上避开主茎干选取40个感兴趣区域(region of interest, ROI), 选取位置如图2所示。 每个ROI选择的范围是30× 30 Pix, 计算出这900个像素点平均光谱反射值作为一条光谱记录, 共计2 000条(5× 400)光谱记录。
 | 图2 大白菜样本ROI选取示意图Fig.2 Schematic representation of selection of ROI on Chinese cabbage sample |
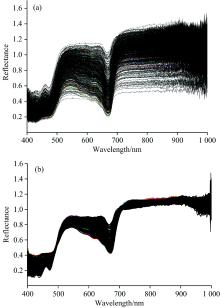
在高光谱图像采集过程中, 会受到来自样本自身因素干扰(如样本平整度、 色差和水分含量等)和环境因素干扰等, 为了减少上述干扰的影响, 需要对高光谱图像进行光谱预处理以消除干扰影响。 使用Unscrambler软件对高光谱数据进行多元散射校正(multiple scattering correction, MSC)预处理; 5组样本各随机选取200条光谱在预处理前与后的谱形如图3所示。 图3(a)为未经光谱预处理的原始样本曲线, 图3(b)为经MSC预处理后样本曲线。
 | 图3 光谱数据预处理 (a): 原始光谱; (b): 经MSC处理Fig.3 Spectral data preprocessing by MSC (a): Without preprocessing; (b): With MSC preprocessing |
如图3(b)所示, 靠近400和1 000 nm边缘波段光谱反射曲线波动较剧烈, 说明此处受到干扰较大, 数据严重失真, 影响后期建模分类效果; 因此, 需要进行噪声裁剪, 为每个样本掐头去尾剔除噪声较大400~414和912~1 000 nm的边缘波段, 保留415~911 nm(对应原800波段中的20~749, 共计729波段)用于建模分析。
小波变换(wavelet transform, WT)是一种信号变换分析方法, 提供一种随频率改变的“ 时间-频率” 窗口, 通过小波基函数的伸缩平移运算实现信号(函数)多尺度、 多分辨细化, 可同时提取细节分量(高频部分)和近似分量(低频部分), 连续小波变换表达式为
式(1)中, j为缩放因子, k为平移因子, j和k均为连续变量, 量, Ψ (λ )为小波基函数。
离散小波变换[6](discrete wavelet transform, DWT)是小波变换的一种, 可实现在离散尺度上进行信号分解, 通过高低通滤波器来实现高低频信号分解, 离散变换公式为
式(2)中, a和b分别为第a层分解和第b个小波系数, ϕ a, b(λ )为离散小波基函数。
将高光谱数据中的波长-反射率与信号的时间-频率相对应, 利用离散小波变换多尺度分解特性实现降维, 既每层变换均略去细节分量(高频部分), 将分解后的近似分量(低频部分)作为建模数据, 以此类推, 每层变换均在上层变换的近似分量基础上进行再变换, 每层变换数据维度减半, 达到数据降维目的。
1.7.1 多层感知机
所使用的多层感知机(multilayer percetron, MLP)[7]具有4个全连接层和1个输出层, 网络结构如表1所示; 设置学习率learning_rate(LR)为0.001, 迭代次数epochs为500, 批量大小为batch_size(BS)为64, 测试集验证频率validation_freq为1, 优化器使用Adam算法。
| 表1 多层感知机网络结构 Table 1 MLP network structure |
1.7.2 卷积神经网络
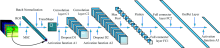
卷积神经网络[8](convolutional neural networks, CNN)是一种在多层感知机基础上建立的深度学习网络, 通过增加若干个卷积层(convolution layer)来增强网络的特征抓取能力。 虽然经典模型如AlexNet(8层)、 VGGNet(11~19层)、 GoogLeNet(Inception V1 22层)、 ResNet(18~152层)分类效果较好, 但模型层数较多、 参数量巨大, 对硬件性能要求较高。 本工作重新设计卷积神经网络结构如图4所示; 高光谱大白菜样本图像经ROI提取、 预处理和噪声裁剪后数据为2 000× 1× 1× 729, 为了便于二维卷积运算, 将光谱数据变形为2 000× 27× 27× 1(all_batch× width× height× channels), 卷积神经网络结构参数设置如表2所示。
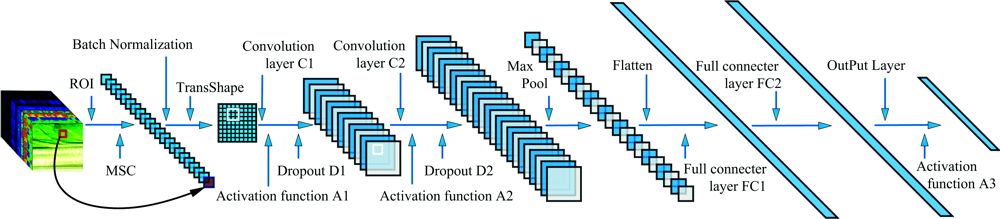 | 图4 卷积神经网络结构Fig.4 CNN structure |
| 表2 卷积神经网络结构参数设置 Table 2 Parameter settings of the CNN structure |
卷积神经超参数的选取直接影响到识别模型分类精度, 为了确定关键超参数Learning_rate, Batch_size和Epochs, 高光谱数据经多次、 多参数训练, 如图5所示; 图5(a)为Batch_size=50, Epochs=1 000时, 4种不同Learning_rate下的模型训练损失值, 从中可以看出当Learning_rate为0.005和0.01时均出现Training loss value(TLA)为不变值1.6, 说明此时Learning_rate过大, 导致模型无法收敛; 当Learning_rate为0.001时模型收敛速度较快。 图5(b)为Learning_rate=0.001, Epochs=1 000时, 6种不同Batch_size下的模型训练损失值, 中可以看出当Batch_size为70, 90, 110和130时Training loss value下降缓慢且振荡剧烈, 说明此时模型不稳定, 泛化能力较弱; 仅当Batch_size为50时Training loss value下降迅速且起伏较小。 图5(c)为Learning_rate=0.001, Batch_size=50时, 6种不同Epochs下的模型训练损失值, 从中可以看到随着Epochs不断增加, 总体精度(overall accuracy, OA)呈明显上升趋势, 当Epochs为1 000时, OA到达顶峰。 综合考量, 最终确定超参数Learning_rate为0.001, Batch_size为50, Epochs为1000, 优化器采用Adam算法。
 | 图5 卷积神经网络超参数选择 (a): 基于4种Learing rate的模型训练损失值; (b): 基于6种Batch size的模型训练损失值; (c): 基于6种Epochs的模型总体精度Fig.5 CNN hyperparameter selection (a): TLA for different LR; (b): TLA for different BS; (c): OA for different Epochs |
为了更全面比较模型性能和精度, 同时还采用支持向量机(support vector machine, SVM)和K最邻近(K-nearest neighbor, KNN)机器学习算法进行建模。
由于样本数量较少, 容易发生模型过拟合, 在建模过程中引入数据增强技术(data augmentation), 在原有的高光谱数据基础上增加高斯噪声, 将样本数据量扩充为原来的2倍; 除此之外, 还采用Dropout和Regularization L2技术提高模型泛化能力和鲁棒性。
为了从光谱曲线角度清楚地区分不同类型的样品之间的光谱信息的差异, 将每类样品的400条光谱曲线取平均值, 得到该平均光谱曲线如图6所示。
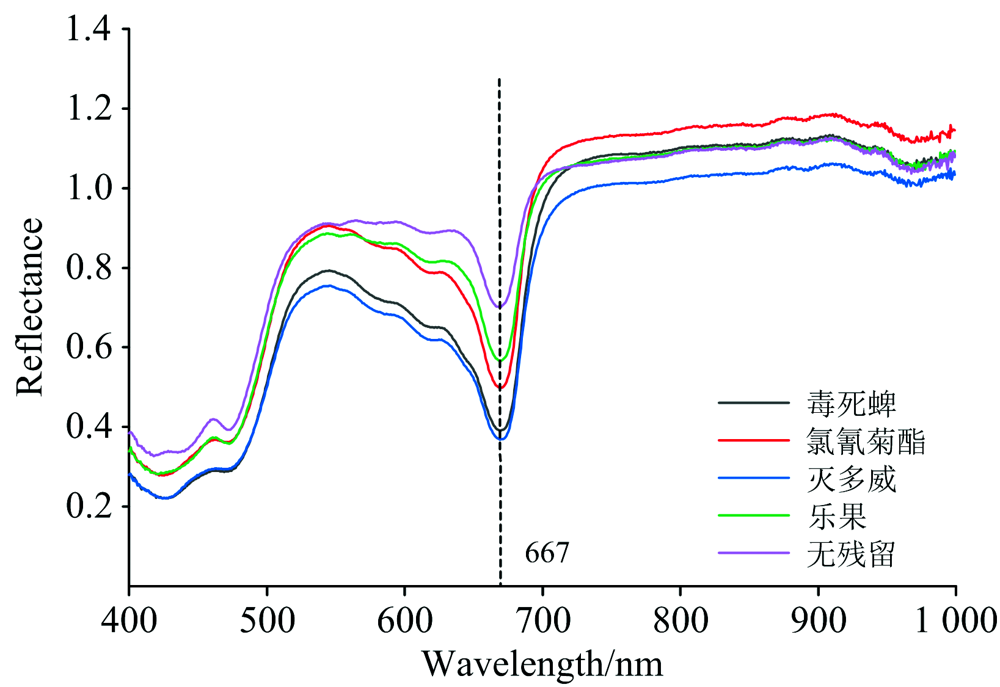 | 图6 大白菜样本平均光谱曲线Fig.6 Average spectra of chinese cabbage samples |
由图6可以看出, 在400~700 nm波段内, 出现3次较为明显反射波谷, 分别出现在410 nm紫光、 490 nm青光和667 nm红光附近; 在667~710 nm波段内反射率陡然上升, 710 nm波段后反射率逐渐平稳, 符合绿色叶片光谱反射率规律。 在530~667 nm波段内5条光谱反射曲线区分度较高, 印证了叶片光谱反射率与农药胁迫存在相关联理论[9], 为实现通过光谱对大白菜农药残留进行识别提供了科学依据。
2.2.1 离散小波变换降维
为了比较降维效果, 以db1小波基为例, 在平均光谱曲线上进行离散小波变换, 每次变换后均只保留低频分量, 舍弃高频噪声分量, 1~6层离散变换降维后得到的数据维度分别为364, 182, 91, 45, 22和11。
降维后的光谱曲线如图7所示, 可以看到随着变换层数的增加, 曲线形状与原始曲线差异逐渐变大; 图7(a)为经过1层离散小波变换后的低频分量曲线, 与图6相比具有较高的相似性, 能够较好的表征原曲线之间相对位置关系, 但所用数据维度只占原数据的1/2; 随着离散小波变换层数的增加, 数据维度以2-m递减(m为小波变换层数), 图7 (f)为经过6层离散小波变换后的曲线, 虽然数据维度只有11维, 仍能够看出在关键的节点处曲线相对位置关系。
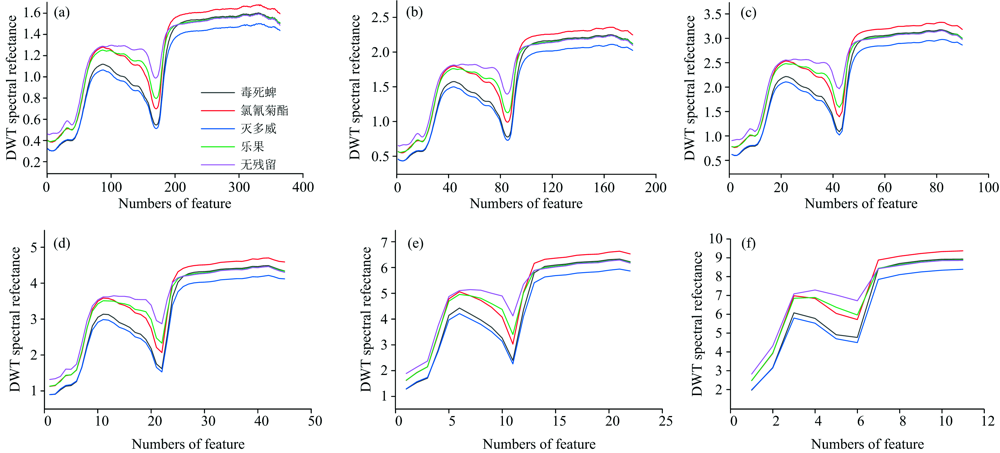 | 图7 基于db1小波基函数离散小波变换后的低频部分曲线 (a)— (f)分别经1~6层离散小波变换Fig.7 Low frequency portions of wavelet transform based on db1 function (a)— (f) corresponding to 1~6 layers of DWT, respectively |
2.2.2 PCA和CARS降维
采用主成分分析(principal component analysis, PCA)算法对所有裁剪后的大白菜高光谱数据进行降维, 前11, 22, 45, 91, 182和364主成分累计贡献率分别为99.11%, 99.48%, 99.76%, 99.91%, 99.98%和99.99%。
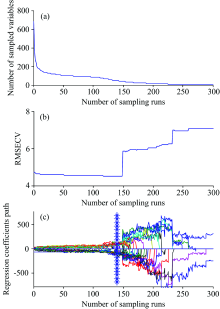
采用竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)进行全样本降维, 其中, 采样频率设置为0.8, 筛选阈值为0.8, 蒙特卡洛采样次数为300, 交互验证组为15, 筛选过程如图8。
 | 图8 CARS筛选特征波长过程Fig.8 Process of selecting characteristic wavelength by CARS |
在图8(a)和(b)中可以看到随着运行次数的增加, 特征波长数量逐渐减少, RMSECV呈现先下降后上升的趋势, 当在140次运行时RMSECV到达最小值; 图8(c)表示特征波长变量回归系数的变化趋势, “ * ” 表示RMSECV最小的位置, CARS共筛选出特征波长39个, 占全波段的6.12%, 特征波长分别为430.04, 445.81, 448.06, 448.81, 449.56, 472.09, 472.84, 509.64, 534.42, 538.17, 625.28, 626.78, 627.53, 703.38, 749.19, 749.94, 755.19, 756.70, 757.45, 767.21, 767.96, 797.25, 804.76, 805.51, 807.01, 812.27, 823.53, 830.29, 831.04, 831.79, 832.54, 833.29, 840.05, 843.05, 873.09, 892.62, 909.89, 928.66, 936.17 nm。
2.3.1 基于多种小波基离散变换降维模型评价
不同的小波基函数降维效果不同, 为了获得最佳分类识别效果, 选取Daubechies小波族中的db1, Symlets中的sym2, Coiflets中的coif1, Biorthogonal中的bior2.2和ReverseBior中的rbio1.5分别对数据进行1~6层小波变换后建立识别模型, 建立流程如图9所示。 样本划分采用Kennard-Stone算法, 样本总数的75%作为训练集, 25%作为预测集。
 | 图9 基于高光谱离散小波变换的卷积神经网络分类流程图Fig.9 Flow chart of hyperspectral image classification based on DWT and deep learning |
4种算法的总体精度如图10(a)— (d)所示。 总体来看, 基于CNN和MLP算法的总体精度曲线平稳度均高于基于KNN和SVM算法, 说明CNN和MLP算法学习与预测能力较强, 各算法总体精度随离散变换层数的增加成波浪式上下浮动, 经bior2.2降维后的总体精度高于其他。 图10(a)中除db1和rbio1.5小波基外, 其余小波基降维后基于CNN算法建模总体精度在78.40%~91.20%之间波动; 其中, 经coif1第2层变换时总体精度取得最优值为91.20%; 图10(b)中经coif1和rbio1.5第4层变换后MLP算法总体精度均取得最优值为83.20%; 图10(c)中经sym2第2层变换后KNN算法总体精度取得最优值为66.40%; 图10(d)中经bior2.2第2层变换后SVM算法总体精度取得最优值为90.40%。
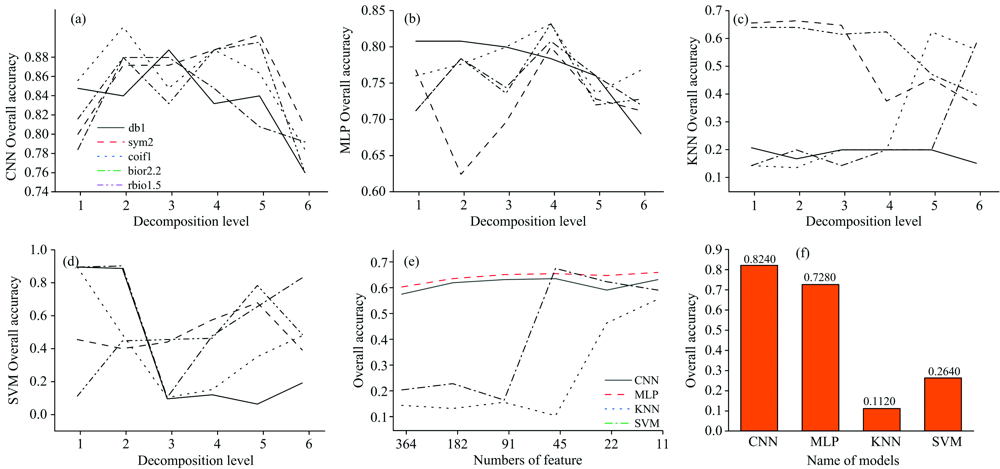 | 图10 基于DWT, PCA和CARS降维的建模结果 (a)— (d)分别为基于DWT降维的CNN, MLP, KNN和SVM模型总体精度; (e)基于PCA降维4种模型总体精度; (f)基于CARS降维4种模型总体精度Fig.10 Modeling results based on DWT, PCA and CARS (a)— (d) Overall accuracies of CNN, MLP, KNN and SVM models based on DWT; (e) Overall accuracies of four models based on PCA; (f) OAs of four models based on CARS |
2.3.2 基于PCA和CARS降维模型评价
为充分验证本研究所提出的离散小波变换降维算法的可靠性, 分别取PCA降维后前364, 182, 91, 45, 22和11个主成分(分别对应离散小波1~6层变换后的数据维度)进行建模, 4种算法的总体精度如图10(e)所示。 随着数据维度的减少, CNN和MLP算法总体精度波动不大, 但KNN和SVM算法的总体精度波动较大, 相比而言CNN和MLP算法学习能力相对较强, 模型稳定性较好。 SVM算法在取前45个主成分时获得最优总体精度为62.80%。 经CARS降维后4种算法的总体精度如图10(f)所示, CNN取得该降维算法最高总体精度82.40%, KNN算法总体精度最低为11.20%, 可见KNN算法不适合该类数据样本。
2.3.3 不同降维和建模算法横向评价
3种降维和4种建模算法总体精度和Kappa系数如表3所示。 从整体来看在总样本未经降维过程的分类模型预测用时最长, 精度不高; 基于CARS降维算法分类总体精度最低; 经DWT降维后的分类模型KNN, SVM, MLP和CNN总体精度分别为66.40%, 90.40%, 83.20%和91.20%。 此外, 经DWT降维后4种分类算法预测用时略高于其他2种降维算法。
| 表3 不同算法的总体精度和Kappa系数 Table 3 Overall accuracies and Kappa coefficients of different algorithms |
不同算法的分类精度如表4所示, 从整体来看灭多威和乐果分类精度较低(分类精度分别为92.00%和96.00%), 其原因可能是两种药物分子式均含有类似的甲基, 导致光谱特征区分度较低; 毒死碑和氯氰菊酯分别在CARS-SVM和DWT(bior2.2-2)-SVM算法取得最佳分类精度100%, 说明SVM识别分类能力较好; 乐果和无残留均在DWT(coif1-2)-CNN获得最高分类精度100%, 说明DWT-CNN算法有较好的降维、 特征提取和分类识别能力。
| 表4 不同算法的分类精度 Table 4 Overall accuracies of the various prediction algorithms |
融合高光谱、 离散小波变换和卷积神经网络提出了一种基于高光谱离散小波变换的卷积神经网络分类算法, 对5组大白菜样本高光谱数据集进行分类识别, 结果表明:
(1)经降维后的高光谱数据与未降维数据相比较, 预测集总体精度、 Kappa均有明显提高, 同时用时也大大缩短, 说明降维算法能有效除去冗余数据降低维度, 改善“ 休斯现象” , 提高建模算法精度。
(2)基于coif1小波基函数的离散小波算法通过多层低通滤波器能够有效过滤高频干扰信息, 达到降维的效果; 与PAC和CARS降维算法相比较, 基于离散小波变换降维数据的同时, 不仅较好的保留原始光谱曲线形状, 而且还能较好还原曲线相对空间位置, 提高了高光谱数据分类识别准确度。
(3)卷积神经网络具有较强的特征抓取和学习能力, 基于离散小波变换和卷积神经网络算法模型总体精度为91.20%, 与MLP、 SVM和KNN相比分别高出了8.00%, 0.80%和24.80%, 充分发挥了离散小波变换降维与卷积神经网络的优势。
本工作仅在单一农药残留基础上建立识别模型, 为后期实现便携式无损、 快速检测大白菜农残设备研发提供一个新的方法。 下一步研究工作将侧重在混合农药残留的条件下构建分类模型, 并最大限度压缩模型参数量, 缩短预测时间。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|