






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外光谱结合随机森林算法: 一种快速有效的附子产地溯源策略
[龚圣1  , 朱雅宁
, 朱雅宁2 , 曾陈娟3 , 马秀英3 , 彭成1 , 郭力1, * ]
, 朱雅宁]
|
|


作者简介: 龚 圣, 1997年生, 成都中医药大学药学院硕士研究生 e-mail: 2020ks289@stu.cdutcm.edu.cn
可靠的原产地认证方法对于保护指定产地的高价值中药材(例如道地药材、 地理标志产品等)至关重要。 附子作为著名的传统中药和川产道地药材, 疗效显著, 临床应用广泛, 在国内外市场需求量很大。 不同产地的附子疗效和价格有所不同, 大众很难通过传统经验进行准确鉴别, 基于植物代谢组学模式下的质谱检测技术, 测试样本制备过程繁琐冗长、 操作复杂、 检测时间长, 且重现性偏低。 近红外光谱作为一种成熟、 快速、 无损的检测技术, 被机器学习集成后为中药材在线质量监管和控制带来新途径。 基于近红外光谱技术结合随机森林算法建立了一种不同产地附子无损鉴别模型。 在四川、 陕西和云南等主要栽培区域共采集了255份附子样本, 采用傅里叶变换近红外光谱获得所有样本的漫反射光谱信息。 采用单一和组合光谱预处理方式以消除光谱中的多种干扰, 并筛选出最佳预处理方式, 以此为输入指标建立随机森林模型。 采用灵敏度、 特异度和平衡精度等指标评价了模型的综合性能。 结果表明: Savitzky-Golay平滑+多元散射校正为最佳预处理方式; 仅采用全波长数据, RF模型对3组省级的样本的预测准确率超过了90%, 预处理后预测准确率达98.39%; 对于市/县一级样本, RF模型同样具有优秀的判别能力, 准确率大于75%。 模型对道地产区周边栽培区域的样本, 识别率达100%。 过滤出前100个特征波数, 重新优化模型, 模型对各市/县级区域的识别精度超过85%, 尤其是对一些产自高原样本的识别能力得到了明显提升。 研究中采用了环境友好型溯源策略, 分析速度更快, 样品损失更少, 精度更高, 为不同产地附子快速、 高效的鉴别提供了新模式, 为后续附子及其相关炮制品的鉴别和溯源提供了参考。
Effective and reliable methods of origin certification are essential for protecting high-value Chinese medicinal materials (e.g geo-authentic Chinese medicinal materials, geographical indication products, etc.) from designated regions. As a famous traditional Chinese medicine and a geo-authentic Chinese medicinal material produced in Sichuan Province, Aconiti Lateralis Radix Praeparata (Fuzi) has a remarkable curative effect and wide clinical application is in great demand in domestic and international markets. The efficacy and price of the Fuzi of different origins vary, and it is difficult for the public to identify them through traditional experience accurately. Mass spectrometry-based on plant metabolomics is a tedious and lengthy test sample preparation process, complicated operation, long detection time, and low reproducibility. Near-infrared (NIR) spectroscopy, a mature, fast and nondestructive detection technique was integrated with machine learning to bring new ways for online quality supervision and control of Chinese medicinal materials. Therefore, a non-destructive identification model based on NIR spectroscopy combined with a random forest (RF) algorithm was developed for different origins of Fuzi. A total of 255 samples of Fuzi were collected from the major cultivation regions of Sichuan, Shaanxi and Yunnan, and the diffuse reflectance spectral information of all samples was obtained using Fourier transform NIR spectroscopy. Single and combined spectral preprocessing methods are used to eliminate multiple interferences in the spectra, and the best preprocessing method is screened and used as an input indicator to build an RF model. The comprehensive performance of the RF model was evaluated using sensitivity, specificity and balanced accuracy. The results showed that Savitzky-Golay 11-point smoothing combined with multivariate scattering correction was the best preprocessing method.Using only the full wavelength data, the prediction accuracy of the RF model for the three groups of provincial samples was also checked over 90%, and the prediction accuracy after preprocessing reached 98.39%. For the city/county level samples, the RF model also had the excellent discriminative ability, greater than 75% accuracy. The RF model achieved 100% recognition rate for samples from cultivation areas around the traditional production areas. The top 100 feature wave numbers were filtered out, and the model was re-optimized, and the recognition accuracy of the model for each city/county level region was over 85%, especially for some samples from the highlands was significantly improved. In this study, an environment-friendly traceability strategy with faster analysis, less sample loss and higher precision was adopted, providing a new model for the rapid and efficient identification of Fuzi of different origins and a reference for the subsequent identification and traceability of Fuzi and its related processed products.
附子为毛茛科植物乌头(Aconitum carmichaelii Debx.)膨大侧根加工品, 具有回阳救逆, 补火助阳, 散寒止痛之功效, 被誉为“ 回阳救逆第一要药” [1], 是一种重要的、 高价值的川产道地药材。 独特的地理条件、 生态环境和栽培管理技术, “ 江油附子” 具有独特的品质独特和显著的疗效, 为附子上品, 具有“ 道地药材” 和“ 地理标志产品” 的双重美誉, 其疗效与经济效益均高于其他地区附子[2]。 在过去的10多年, 由于附子种植带来良好的经济效益, 全国多地都进行了引种, 四川布拖、 陕西汉中、 云南禄劝等地种植规模较大, 对江油附子市场形成了冲击。
产地造假是中药材质量监管面临的难题之一, 特别是那些质量与疗效和产地有明显关联性的药材被造假的风险更大。 附子的疗效和毒性与产地具有明显的关联性, 不同产地附子的毒性成分相差巨大[3]。 研究报道, 江油附子毒性低于布拖附子与巍山附子[4], 云南附子的毒性是其18倍[4, 5]。 市场上仍然存在用其他产地附子冒充江油附子的现象。 “ 道地药材” 和“ 地理标志产品” 标签的随意使用不仅损害了消费者的利益, 更不利于市场监管, 甚至有可能导致严重的用药事故。 为了对道地药材及地理标志产品的声誉保护, 利于市场监管, 对附子产地进行快速、 有效的识别非常必要。
近红外光谱(near-infrared spectroscopy, NIR)作为一种绿色分析技术, 具有方便、 快速、 高效、 准确、 低损耗等其他分析方法无法比拟的优势, 广泛应用于中药材的产地鉴定与质量评价中, 例如川贝母[6]、 人参[7]、 太子参[8]、 丹参[9]、 余甘子[10]、 葛根[11]、 三七[12]等。 然而, 近红外区[780~2 500 nm(12 000~4 000 cm-1)]谱带较宽, 中药样品的吸收带重叠严重, 使得用常规方法进行近红外光谱分析非常困难, 因此在近红外光谱分析中, 变量优选是一个关键步骤。 随机森林算法[10]、 遗传算法[13]、 模拟退火法[14]、 区间偏最小二乘法[15]、 竞争自适应加权抽样[16]、 蒙特卡罗无信息变量消去法[17]等算法是目前常用的近红外光谱变量筛选手段。 随机森林是处理大型和背景嘈杂数据集最有效的学习算法之一[18]。
随机森林(random forest, RF)是由Leo Breiman提出的一种集成算法[19], 多应用于分类问题。 RF是一种由多棵弱决策树为基分类器的集成算法(图1), 通过组合多棵独立的弱分类决策树后根据投票或取均值的方式得到最终预测结果的机器学习方法, 往往比单棵决策树具有更高的准确率和更强的稳定性。 随机抽取样本和样本特征以及算法集成使RF具有出色的性能, 随机性使RF具有更稳定的抗过拟合能力, 多棵决策树集成使RF具有更高的准确率。 RF随机列抽样的特性使RF能处理高维数据, 对离散型和连续型数据能同时处理, 也无需对数据做标准化处理, 可以将数据缺失样本单独作为一类处理, 因此RF对数据的格式要求较低。 然而RF算法本身较为复杂, 建模速度偏慢, 并且随着决策树数目增多, 训练模型需要更长的时间。 简而言之, RF具有处理样本类不平衡数据、 特征遗失数据和高维数据等优势, 基于RF构建的模型具有优秀的抗过拟合和抗噪声的性能[20]。 这种机器学习方法已被用于疾病诊断[21]、 愈后分析[22], 气候分析[23], 种群识别[24], 公共卫生[25], 食品掺假[26], 产地溯源[27]等问题, 目前文献中没有关于NIR光谱采用RF在附子产地鉴定中的研究。 本研究采集了附子三个主要栽培区域共255份样本的NIR光谱数据, 按照1:3的比例将数据集随机划分为测试集和训练集, 并分别训练了省级预测模型和市/县级预测模型, 采用测试队列评估了模型的实用性和可靠性。
 | 图1 随机森林算法原理Fig.1 Principle of random forest algorithm |
附子样本分别来源于四川(江油、 布拖、 盐源、 安县), 云南(德钦、 禄劝、 虎跳峡)和陕西(南郑、 洋县、 眉县)3省10个栽培地共255份样本, 为了确保样品的地理真实性, 研究中亲自前往各栽培地采集样本, 详细信息见表1。 所有样本经成都中医药大学药学院高继海副教授鉴定为毛茛科乌头属植物Aconitum carmichaelii Debx.的侧根。 样本采集后使用超纯水清洗, 陶瓷刀切片, 45 ℃烘箱干燥, 水分被控制在10%左右, 恒温干燥箱中保存备用。 用于后续测定的样本, 干燥后粉碎, 过80目筛, 存放于干燥箱, 备用。 所有实验用的样本存放于成都中医药大学药学院郭力教授实验室。
| 表1 样品信息 Table 1 Information of Fuzi |
PerkinElmer Frontier傅里叶变换近红外光谱仪(PerkinElmer公司, 美国); Mili-Q去离子水发生器(Millipore公司, 美国); 101-2AB电热鼓风干燥箱(北京中兴伟业仪器有限公司, 中国); HX高速粉碎机(中国永康溪岸五金药具厂, 中国); 80目不锈钢筛网(北中西泰安公司, 中国)。
SIMCA-P 13.0(Umetrics AB, 瑞典); RStudio 4.1(RStudio Team, 2016; http://www.rstudio.com/)。
取预处理好的附子样品3(± 0.1) g, 置于仪器配套的样品杯中平铺适当压紧。 采用仪器配备的PerkinElmer Spectrum 14.0光谱采集软件采集光谱数据, 采用积分球漫反射模式, 扫描范围10 000~4 000 cm-1, 分辨率4.0 cm-1, 能量值2 400, 累计扫描64次。 扫描样品前, 仪器预热30 min, 白板扣除背景干扰, 为减小实验误差, 每份样品平行扫描3次, 分析时取其平均光谱。 在光谱采集过程中, 保持室内温度约25 ℃。
异常样本会对模型的准确性产生负面影响。 因此, 本研究基于Hotelling’ s T2分布的聚类方法, 95%置信限以外的样本被视为异常值样本[28]。 经过检验, 本研究中所有的样本无异常。
受到附子样本颗粒大小不均匀、 环境温度、 仪器光程等因素的影响, 以及噪声干扰、 基线漂移等问题的存在, 需要将得到的近红外光谱数据进行预处理, 提高后续分析结果的准确性。 本研究中, Savitzky-Golay 11点平滑(SG)用来减低其光谱自身所携带的随机误差、 提高信噪比, 多元散射校正(multiplicative scatter correction, MSC)被用于消除因附子样本颗粒分布不均匀及颗粒大小产生的散射, 标准正态变量变换(standard normal variate transformation, SNV)用于降低由样本颗粒大小、 表面散射及光程变换对漫反射的影响[29], 小波去噪(wavelet denoising, WDS)用于得到原信号的最佳恢复, 上述处理过程由SIMCA-P 13. 0完成。
随机森林由多棵分类决策树组成, 在构建决策树的过程中, 不进行修剪, 每棵决策树均通过随机选择观测值和变量形成。 因此, 随机森林模型有两个重要参数, ntree和mtry, 它们分别决定了模型的整体分类性能、 规模和单棵决策树的情况。 减小mtry值, 决策树之间的相关性和分类能力也会相应的降低; 增大mtry值, 两者也会随之增大。 ntree值由最优mtry值确定, 两者越大模型的分类能力就越强, 但是这会增加模型过拟合风险; 过小则会降低模型的分类能力。 事先通过计算袋外数据(out-of-bag, OOB)错误率对模型进行内部评估, 选出最优mtry和ntree值。
各产地附子的原始光谱如图2所示, 样本间的光谱整体表现出类似的趋势。 乌头类生物碱是附子的主要成分之一, 乌头碱、 中乌头碱、 苯甲酰乌头碱、 苯甲酰次乌头碱等双/单酯型二萜生物碱是附子主要的“ 毒-效” 成分, 其中的含氢基团(O— H, N— H, C— H)振动吸收也能一定程度上反映样本信息。 4 650 cm-1附近是N-H振动合频的吸收带; 6 000 cm-1附近波段主要为C— O和H— O一级倍频与合频吸收; 5 200和7 000 cm-1是O— H的合频和二倍频的吸收带; 其中一些产地样本在6 956和7 252 cm-1附近具有更强的吸收。 就附子原始光谱而言, 其谱图间不存在明显的区别, 叠加严重, 因此采用机器学习来探索这些数据是必要的。
 | 图2 原始光谱Fig.2 Raw spectrum |
2.2.1 主成分分析
将原始光谱进行主成分分析(principal component analysis, PCA), 如图3所示。 以3省[图3(a)]和10个市/县级产地[图3(b)]为观察样本分别进行PCA分析, 其中两类PCA的主成分(PCs)的贡献率一致, PC1, PC2和PC3分别解释了38.8%, 26.4%和11.25%方差, 前3个主成分的解释方差达到76.4%。 图3(a)中显示, 3省的样本在空间分布上相互叠加严重, 且同一省份内样本分布也呈现出明显的差异, 尤其是来自四川的样本。 同样, 图3(b)中得出结果也比较类似, 各组内样本分布相互叠加严重。
 | 图3 不同产地附子主成分分析三维分值图 (a): 包含3个类别; (b): 包含10个类别Fig.3 3D score plots of PCA of Fuzifrom different cultivation places (a): Containing 3 categories; (b): Containing 10 categories |
2.2.2 最佳预处理方式
不同的预处理方式对模型的预测准确率存在显著影响, 因此需要筛选出最佳的预处理方式, 基于RF模型默认参数(ntree=500, mtry=2)比较了14种预处理方式下模型的预测准确率, 如图4所示, SG+MSC和SG+MSC+SNV模式都具有较佳的准确率, 因此后续分析选择SG+MSC处理方式处理的NIR数据。 需要明确的是MSC和SNV属于同一类数据预处理方法, 同时使用MSC和SNV模式, 有过度处理数据的可能性, 还需要在后续的实际研究中探讨。
 | 图4 不同预处理方式对模型准确率的影响Fig.4 Effects of different pre-processing methods on model accuracy |
2.2.3 RF模型的建立
在默认参数(ntree=500, mtry=2)条件下, 使用训练数据集初步探索了RF模型对3省样本的袋外数据错误率(OOB Error), 模型的决策树数目在230~500时, 模型的袋外数据犯错率趋于稳定[图5(a)]。 随后, 使用“ randomForest” 软件包中“ tuneRF” 函数测试了1~100内的最佳mtry值, 当mtry为4时, 模型整体误判率为最低2.58%[图5(b)]。
 | 图5 最佳ntree值(a)和mtry值(b)Fig.5 Optimal ntree (a) and mtry (b) values |
样本按照3:1的比例被随机划分为训练集和测试集两组, 进行建模分析(ntree=500, mtry=4), 这个过程主要由RStudio 4.1软件中的“ randomForest” 和“ caret” 包完成。
灵敏度(Sensitivity)、 特异度(Specificity)、 阳性预测值(Pos Pred Value)、 阴性预测值(Neg Pred Value)、 Prevalence、 Detection Rate、 Detection Prevalence和平衡精度(Balanced Accuracy)等是用来评判模型的性能常用指标, 本研究中, 上述指标值由“ caret” 包自动计算得出, 针对多分类模型时, 将采用加权计算上述参数。 其中前4个指标都主要反映了模型对分类样本的识别能力, 平衡精度也是一个重要参数, 通常其值越接近1, 模型性能越佳。
2.2.4 RF模型对省级区域的识别结果
首先, 使用训练集样本建立了四川(Sichuan)、 云南(Yunnan)和陕西(Shaanxi)省级识别模型[图6(a)], 并采用测试集样本评估了模型性能[图6(b)]。 194份训练队列样本仅5例样本被错误划分(97.42%), 62份测试样本有61份被准确预测(98.39%)。 模型对3省样本的灵敏度和特异度都达到了1.000 0, 平衡精度也分别达到了0.982 8, 0.988 4和1.000 0[图6(c)]。 由此可见, 仅采用全波长数据训练省级预测模型, 仍能取得较高的预测率, 在后续的应用中也推荐使用全波长NIR数据对附子的大区域来源进行预测。 事实上, 这3个省的土壤、 气候、 地理环境、 海拔等因素差异较大, 是导致附子的生长代谢等方面出现差异的主要因素。 此外, 附子在各地的栽培方法、 采收时间等管理因素也有所差异, 也是导致附子各成分的积累出现差异的原因之一。
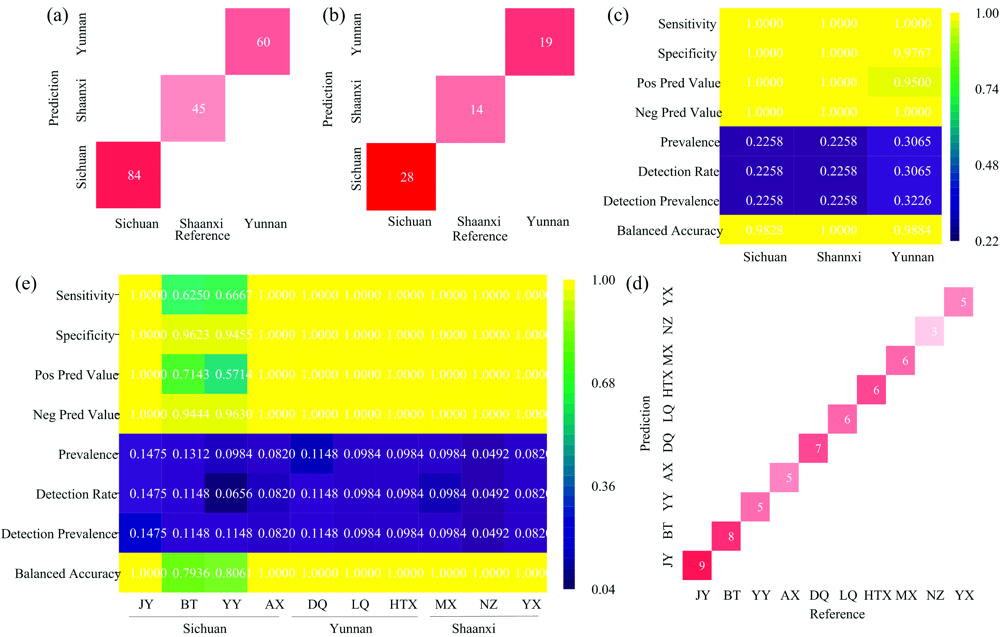 | 图6 RF模型对省级样本训练集(a)和测试集(b)的预测结果和识别性能(c); RF模型对市/县级测试队列样本(d)的预测结果和识别性能(e)2.2.5 RF模型对市/县级区域的识别结果Fig.6 Prediction results and recognition performance (c) of the RF model for the training set (a) and test set (b) of provincial samples; prediction results (d) and recognition performance (e) of the RF model for the city/county test cohort samples |
按照2.2.3模型, 采用训练集样本全波长数据重新训练了一个新的市/县级模型, 探索了最佳ntree和mtry值, 分别为500和4, 此时模型犯错率最低为2.05%, 结果如图6(d, e)所示。 模型对大部分产地样本的灵敏度和特异度都达到了1.000 0, 除了来自布拖(0.625 0, 0.962 3)和盐源(0.666 7, 0.945 5)的样本, 平衡精度仅有0.793 6和0.806 1。 然而布拖和盐源在地理上相隔较近, 种植基地都处于高海拔区域(> 2 500 m), 且种植技术比较一致(定点扶贫县, 得到了四川好医生攀西药业的技术支持), 导致两个栽培地之间的样本差异降低, 这在一定程度上增大了分类难度。
由于NIR数据中存在许多无效数据, 导致RF模型运行时间过长, 根据随机森林模型对各波数的重要性评分[基于Gini指数, 图7(a)], 优选出前100个重要特征波数[图7(b)], 重新训练模型。 结果显示, 优化后的RF模型对布拖(BT)和盐源(YY)的灵敏度(0.750 00, 1.000 00)、 特异度(1.000 00, 0.963 64)以及平衡精度(0.875 00, 0.981 82) 得到显著提升[图7(c, d)], 对其余产地附子的判别性能则无明显改善。
 | 图7 (a)特征波数重要性评分; (b)前100个重要波数; (c)优化RF模型对BT和YY样本的判别性能; (d)优化的RF模型Fig.7 Feature wavenumber importance score (a), filter out the top 100 important wavenumber (b), reoptimize RF model (d) to improve the classification performance of BT and YY samples (c) |
在来自四川的样本内, 本研究选取了江油附子的种源地之一安县的样本, 这两地在地理间隔上要比布拖和盐源更近。 有趣的是, 模型对江油和安县的样本表现出了100%的识别能力。 除此之外, 对于来自云南和陕西各地的样本, 模型同样表现优异, 高海拔与低海拔之间的样本得到了完全划分。 尽管都是作为附子主要产地之一, 云南多数附子种植在1 500 m海拔上的地区, 而来自陕西汉中和宝鸡的样本则多数来源于低海拔(< 1 500 m)的地区。 根据林俊芝[30]和张定堃[4]等的报道, 安县附子中新乌头碱、 乌头碱、 展花乌头宁、 塔拉乌头胺、 苯甲酰新乌头原碱、 苯甲酰次乌头原碱、 脱水苯甲酰新乌头原碱及新乌头原碱含量较江油附子更高, 而江油附子中尼奥林、 附子灵、 次乌头碱、 塔拉他定、 卡米查林、 附子亭、 宋果灵含量更高, 这种差异的形成与两地的栽培条件差异有关。 采用这些化合物的含量差异还可以用于区分布拖附子和巍山附子。
尽管NIR数据主要反映了化合物官能团信息, 一定程度上这种生物碱含量差异在光谱信息中也得到体现, 利用这些差异使NIR在中药材质量监控、 成分预测以及在线评估等领域得到应用。 本研究只初步探索了NIR集成机器学习在附子主要的3大种植生产区域的应用, 而我国多数地区都是附子适宜引种区域[1]。 各地气候、 环境、 种植和管理等因素差异较大, 在一定程度上影响植物的生长发育和代谢物积累, 同时也会影响微量元素和元素同位素的富集[31], 从而给全国附子产地识别、 精准溯源等方面提供了可能。
(1)通过比较不同预处理方式和优化RF模型参数, 建立了两个针对不同尺度范围的附子产地识别模型, SG+MSC相结合为最佳的预处理模式, ntree=500, mtry=4, RF模型达到最佳性能。
(2)对于省级样本, 仅采用原始光谱数据RF模型同样表现出了优异的性能, 训练集和测试集的准确率分别为92.78%和91.94%, 预处理后模型的准确率达到98.39%。 对于市/县级样本, RF模型不仅能准确识别道地产区江油附子, 而且对其他栽培地附子的识别率超过了85%。
(3)后续研究中可以通过测定样本内硫、 锶、 铅、 硼元素的稳定同位素丰度比值(δ 34S, δ 87Sr, δ 207Pb, δ 208Pb和δ 11B), 获得各栽培地样本间元素同位素丰度差异信息, 来增强模型的稳定性和可靠性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|