
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
光纤传能的移动式激光诱导击穿光谱钢铁快速检测与分类
[李文鑫1  , 陈光辉
, 陈光辉1, 3 , 曾庆栋1, 2, * , 袁梦甜1, 3 , 何武光1 , 江泽方1 , 刘洋1 , 聂长江1 , 余华清1 , 郭连波2 ]
, 陈光辉, 袁梦甜|
|


作者简介: 李文鑫, 1999年生, 湖北工程学院物理与电子信息工程学院本科生 e-mail: 3300144190@qq.com
为了实现工业现场对特种钢材的快速检测与种类识别, 采用基于光纤传能的移动式激光诱导击穿光谱(LIBS)样机对14种特种钢材进行光谱数据的采集与分析, 采用预选谱线并遍历组合的降维方法与支持向量机(SVM)相结合的算法对特钢材料的光谱进行快速分类。 分别将原始光谱数据、 归一化处理后的光谱数据、 归一化处理+遍历组合优选谱线数据作为SVM分类模型的输入向量, 并对比了不同输入向量下模型对特钢识别的准确度。 结果表明: 在事先选出的51条特征谱线作为输入变量的基础上, 归一化光谱数据作为SVM分类模型的输入特征时, 识别准确度达到95.71%, 明显高于使用原始光谱数据作为输入向量时SVM分类模型的准确度11.43%。 进一步地, 使用MATLAB程序遍历谱线组合, 通过遍历各种谱线组合选出最优的输入谱线组合, 当优选6条特定的谱线时, 对特钢种类识别的准确度达到100%, 且建模速度也有相应提升。 可以看出, 当预选出大量常见特征数据时, 机器自动选取特征与人工挑选谱线相比, 具有明显优势, 基于此降维方法的SVM算法模型在LIBS快速分类技术中具有很好的工业应用前景。
, CHEN Guang-hui, YUAN Meng-tianIn order to realize the industrial on-site rapid detection and identification for special steel, a mobile laser-induced breakdown spectroscopy prototype based on optical fiber delivering laser energy is adopted in this experiment to collect the spectral data of 14 special sheets of steel. The spectra of special steels were rapidly classified via dimensionality reduction in which pre-selected spectral lines were traversed, combined with a support vector machine (SVM).In the experiment, original spectral data, normalized spectral data and normalized spectral data after traversed were used as the input vectors of the SVM classification model, and the recognition accuracy of the model for special steels under different input vectors was compared. The results show that on the basis that more than 51 spectral lines were selected as input variables, the recognition accuracy of normalized spectral data as input variables for steels reaches 95.71%. It is significantly higher than 11.43%, whose accuracy was used raw spectral data as the input vector. Further, the MATLAB program was used to traverse the spectral line combination to choose the optimal input features. When 6 specific spectral lines were selected, the accuracy of special steels recognition reached 100%, and the modeling speed was also improved accordingly. It can be seen that when a large number of common feature data are pre-selected, automatic feature selection by machine has obvious advantages over the spectral line of manual selection. The SVM algorithm based on this dimension reduction method has a good industrial application prospect in LIBS rapid classification technology.
钢铁行业是我国国民经济的支柱性产业, 是关系到国计民生的基础性行业。 2018年我国全年钢铁产量已占世界总产量的50%。 最近几年由于产能过剩, 中低端和粗钢的生产所占比重很大, 因此大部分钢铁行业都处于亏损状态, 未来加大高端钢材的产量是改变严峻形势的唯一方式。 在实际生产中, 根据不同用途需要向钢内加入不同的合金元素来改变钢铁的某方面的性能, 比如硫(S)可以改善钢的切削性、 加工性和磁性, 但也会引起钢的热脆性, 降低钢的机械性能, 如使疲劳极限、 塑性和耐磨性显著下降等, 影响钢件的使用寿命; 磷(P)具有强烈的固溶强化作用, 可以增加钢的强度和硬度, 但也会降低钢的塑性和韧性等等。 由于不能准确识别废材所含材料就无法合理的再利用, 每年有大量的废弃钢铁的堆积, 这不仅污染环境也是资源的浪费。 为了提高钢铁废弃物的回收利用率, 如何对钢铁材料进行快速检测分类成为了一个新的研究热点。 现有的元素分析方法有X射线荧光光谱分析方法、 原子吸收光谱分析技术和电感耦合等离子体-原子发射光谱分析技术等, 由于这些技术都有各自的缺点和不足[1, 2, 3, 4], 尚不能满足快速检测的需要, 因此急需一种新的快速在线检测技术。
激光诱导击穿光谱(laser induced breakdown spectroscopy, LIBS)是一种近年来发展迅速的原子发射光谱技术, 它采用高能量激光脉冲聚焦到样品表面产生等离子体, 通过对等离子体中原子和离子能级跃迁辐射出的特征光谱采集和分析, 获得被测样品中所含的元素种类及其含量[5, 6]。 LIBS技术具有无需进行样品预处理, 分析速度快, 非接触, 对样品几乎无损等优点, 在工业生产实时在线监测方面具有很大的发展潜力[7, 8, 9]。 采用LIBS技术结合分类算法对材料进行快速分类是当前研究的一个热点。
传统的分类算法一般采用K临近法, 然而该算法的特征谱线选取较为复杂。 由于钢铁合金中的基体元素为Fe元素, 其中还含有Cr, Ni, C, Mn, Ti, Mo, Cu等多种元素, 相比于其他类型材料, 钢铁合金样品的LIBS谱线异常丰富, 各元素间的相互干扰更为复杂, 为LIBS定量分析带来了很多挑战[10, 11]。
支持向量机(support vector machine, SVM)是一种基于结构风险最小化准则的学习方法, 它能够利用核函数变换将原始非线性数据转化为高维线性数据, 剔除大量冗余数据, 具有很强的鲁棒性和容错性。 2015年, 杨友盛等[12]利用SVM强大的分类功能, 通过Si和Mn对应的特征谱线波长和光谱强度, 利用Si、 Mn含量和温度来判定转炉终点。 结果显示该模型的准确率达98%以上, 证明了在实验环境不变的情况下, SVM分类模型可以用在光谱定性分析上。 2016年, 谷艳红等[13]对土壤中的Cr元素进行定量分析, 采用LIBS技术结合SVM的方法, 相比于传统定量分析方法, 大大提高了定量分析的精度, 其定标曲线拟合相关系数由0.689提高到0.998, 表明SVM算法具有良好的实用性。 然而, 在使用SVM算法时, 当直接输入大量特征时容易发生过拟合, 从而导致模型的泛化程度降低, 此时需要对输入向量进行降维处理。 合理地选择样品组成元素的特征谱线组合作为输入, 可降低输入向量的维度。 人工选择特征谱线组合较耗时繁琐且效果难以保证。 采用谱线遍历组合优化输入向量的降维方法可对所有组合测试, 寻找最优的输入向量, 但相关工作鲜有报道。
本工作采用基于光纤传能的移动式LIBS系统结合SVM算法对特种钢材进行快速检测和分类, 并提出一种基于预选谱线然后遍历组合的方法对输入向量进行优化降维, 建立基于SVM算法的光谱识别模型, 实现对不同牌号的特种钢材的快速分类。
基于光纤传能的移动式LIBS实验装置如图1所示, 采用的激光器为一款紧凑型调Q的Nd:YAG激光器(型号: Ultra 50, 美国Bigsky公司生产), 该激光器输出波长为532 nm, 脉冲重复频率为10 Hz。 输出的激光脉冲经过耦合模块耦合进一根芯径为1 mm的传能光纤, 经光纤输出的最大单脉冲激光能量约为29 mJ, 经过准直透镜进行准直, 然后被二向色镜反射后, 经过聚焦透镜聚焦在样品靶材表面, 激发产生等离子体光谱。 等离子体光谱经透镜采集耦合到光纤, 然后传输到一台紧凑型光纤光谱仪(型号为Avaspec-2048 USB2, 10 μ m狭缝, 2 400线· mm-1(VE)光栅)。 该光谱仪的光谱波长范围约为290~1 020 nm, 光谱分辨率为0.08~0.11 nm。 配有一个门控2048像素的CCD阵列探测器(型号为Sony 554), 主要功能是将光信号转换为电信号。 光谱信号随后通过USB接口传输并显示在笔记本电脑上。 每次光谱采集的积分时间设置为1.1 ms, 采集延迟时间设为1.3 μ s。
 | 图1 LIBS实验装置 (a): 原理框图; (b): 样机Fig.1 LIBS system (a): Schematic; (b): Prototype |
实验采用14个特钢材料作为分析样品, 分别对其进行编号, 各样品中各元素的参考浓度(Wt%)和对应的编号如表1所示(该参考浓度由生产厂家采用火花直读法测得, 分析精度在5%以内)。 实验参数设置如1.1节所述, 对每个样品采集30幅光谱, 每幅光谱由10个激光脉冲产生的光谱经过平均后得到, 14个样品共采集420幅光谱。
| 表1 14个钢铁样品中各元素的含量信息(Wt%) Table 1 The concentration information of each element in 14 types of steel samples |
SVM算法是在统计学理论基础上发展起来的一种机器学习算法, 是一种二分类模型, 其基本模型是定义在特征空间上的最大间隔分类器, 在解决小样本、 非线性及高维模式识别问题时具有许多特有的优势。 本工作使用中国台湾大学林智仁(Lin Chih-Jen)教授等开发设计的一个简单易用和快速有效的SVM软件包libsvm-3.23进行数据处理。 将数据分为两部分: 训练集和测试集, 训练集与测试集设置相同的标签, 每个输入都是一组特征向量与一个判断样品属性的标签值。 SVM工具箱先通过训练集计算出一个分类模型, 然后对测试集进行预测, 并将预测的标签与真实标签做出对比, 以验证模型的准确性。
在等离子体光谱中, 由于激光能量的波动、 样品的不均匀性和激光与物质相互作用过程的复杂性, 单一元素的校准模型往往不能满足定量分析的要求, 特别是基体元素为Fe时, 谱峰重叠严重, 导致单一元素的特征谱线强度稳定性较差[15]。 因此难以用单一元素的特征谱线作为SVM的特征参数来建立定量分析模型去准确识别钢铁种类, 而采用多元素的多条谱线信息输入支持向量机模型时, 模型训练效果较好, 主要是因为多种谱线信息的输入可以有效校正基体效应的影响。
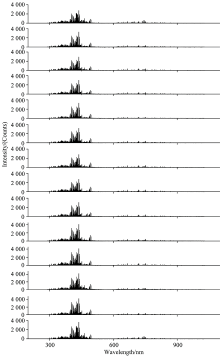
以美国国家标准与技术研究院(National Institute of Standards and Technology, NIST)的原子光谱数据库为参照, 结合课题组自主研发的LIBSystem软件自带的光谱数据库, 对14种钢铁的等离子体发射光谱进行采集与分析, 其光谱如图2所示。
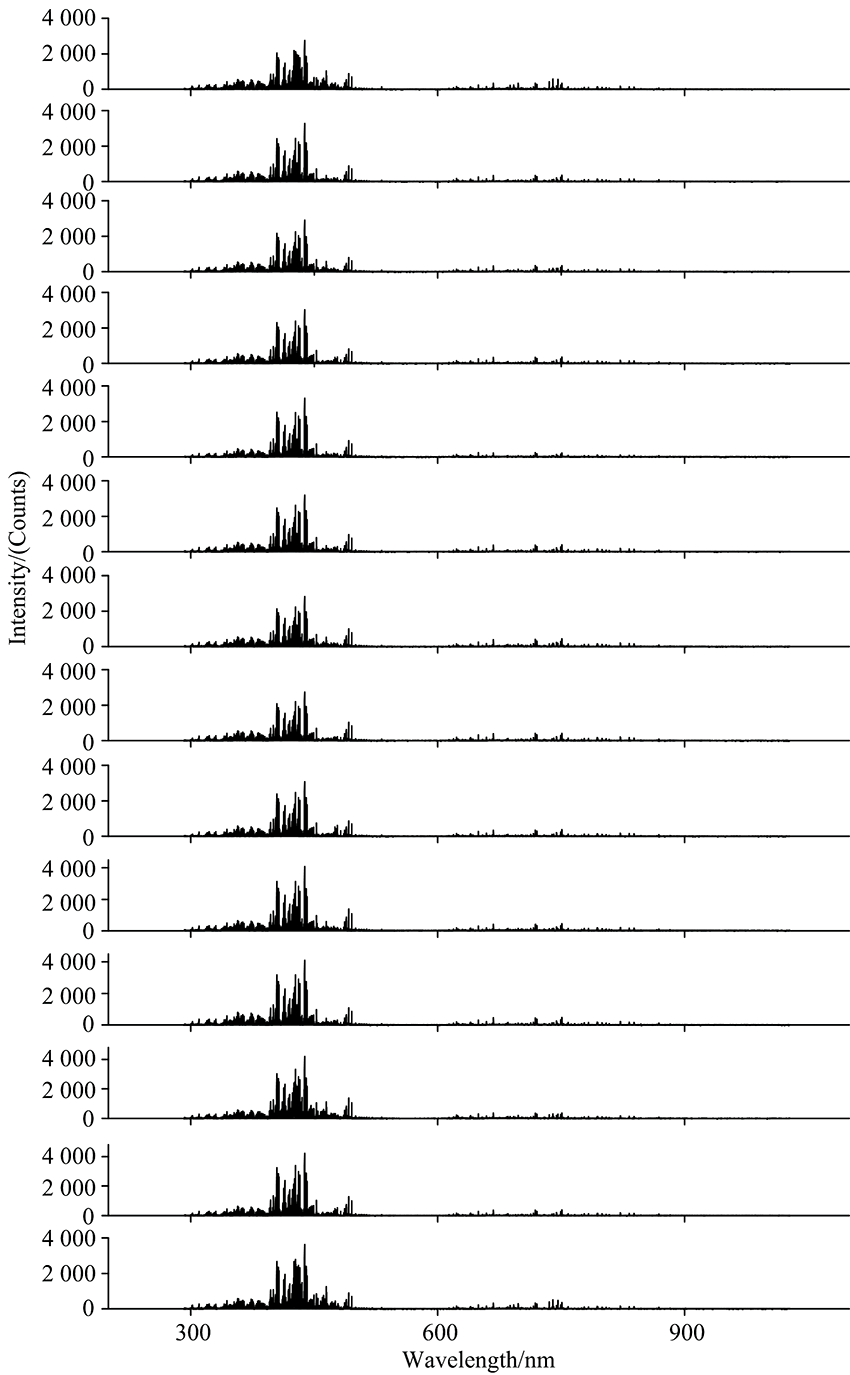 | 图2 14种特钢样品的等离子体发射光谱Fig.2 The emission spectra of 14 types of special steel samples |
建模前, 首先预选出Mn, Ni, Cr, Mo和V元素的共计51条待测谱线(见表2), 然后, 用Fe: 404.58 nm的谱线作为参考线, 对51条谱线进行归一化处理。 预选谱线的原则是, 以NIST光谱数据库为依据, 同时挑选谱线强度较高、 波形完整、 没有自吸收现象和不被其他元素干扰的谱线作为分析线, 这样有利于建立多元素变量的分析模型来识别不同牌号的钢铁。
| 表2 选择的特征谱线 Table 2 The selected emission lines |
在统计学习中, 各类变量经常存在相关性导致输入向量的维度过高, 造成训练模型出现过拟合问题, 需要对输入变量进行降维处理。 常见的降维方法有人工选取、 PCA和线性判别分析(linear discriminant analysis, LDA)等。 但传统的降维方法常常会在降维的过程中丢失信息, 导致模型准确度不理想, 而人工选谱则过于麻烦, 测试结果有可能出现误判。 测试覆盖度有限及人力成本有限是测试技术所面临的瓶颈。 上述难题表明了对实现自动化选谱处理的渴望。 本工作在分类前首先预选出可能的理想谱线, 然后通过计算机将预选谱线随机组合, 并且将这些组合作为输入特征建立多个SVM分类模型, 以寻找到一个理想可靠的模型对钢铁进行分类识别。
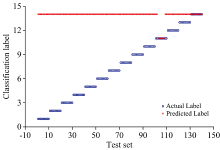
实验中, 采用交叉验证法获得SVM算法中惩罚因子C和核函数参数g的最优值, 由前文可知, 每个钢铁样品采集30组光谱数据, 随机选择其中20组作为训练集, 另10组作为测试集。 因此训练集有280组, 测试集有140组光谱数据。 同时, 依据表1的样品编号分别设置特钢的标签值为1~14。 首先, 用训练集的280组光谱数据训练SVM模型, 再将测试集中的140组光谱数据输人该SVM模型进行预测。 预测结果如图3所示, 图中, 符号“ ” 代表每组光谱数据的实际标签, 符号“ × ” 代表预测的标签, 当“ ” 与“ × ” 重合时, 表示预测值与实际值一致; 相反, “ ” 与“ × ” 不重合时, 表示未能正确识别。
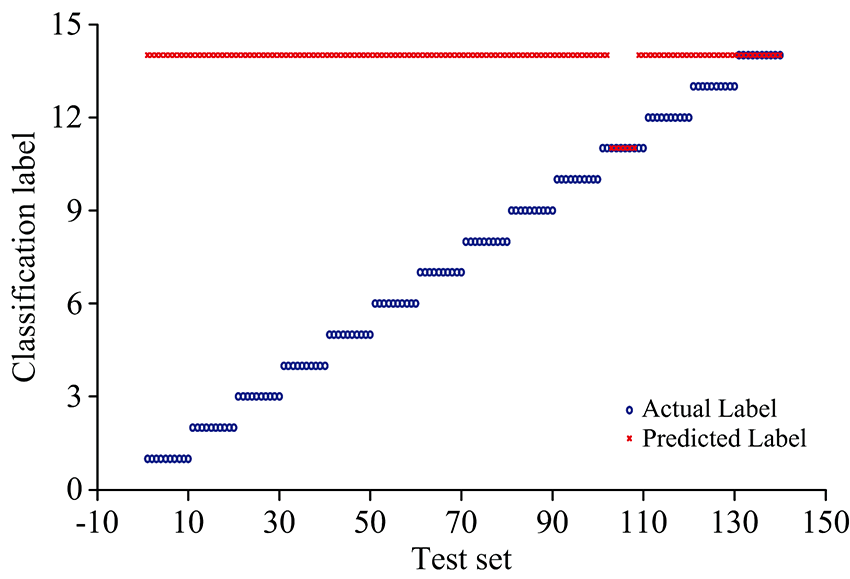 | 图3 SVM的预测结果Fig.3 The prediction results by SVM |
由图3可见, 当将14个钢铁样品的测试集140个光谱数据直接输入训练后的SVM模型时(选取的谱线为表2中的Mn, Mo, V, Cr和Ni的强谱线, 共51条), 图中出现了124个误判点, 仅11号样品的分类效果较好, 可能的原因是原始光谱的总体波动过大, 导致预测结果趋于一个样品, 即14号样品。 而11号样品的波动对分类结果影响可能不是特别大, 使得部分数据被正确预测。 可见, 采用51条金属元素的特征谱线作为SVM分类器模型的输入向量时, 14种钢铁的平均识别正确率仅为11.43%, 此时的模型并不理想。
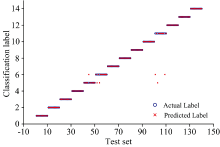
为了减小光谱数据波动的影响, 进一步的提高SVM分类算法的准确率, 以Fe: 404.58 nm的谱线作为参考线, 对所选的待测元素的特征谱线光谱强度做归一化处理, 将归一化后的光谱强度作为SVM分类模型的输入量进行训练和预测, 预测结果如图4所示。 结果表明, 谱线强度做归一化处理后可以校正实验测量条件的扰动造成的偏差, 减小实验条件波动的影响。
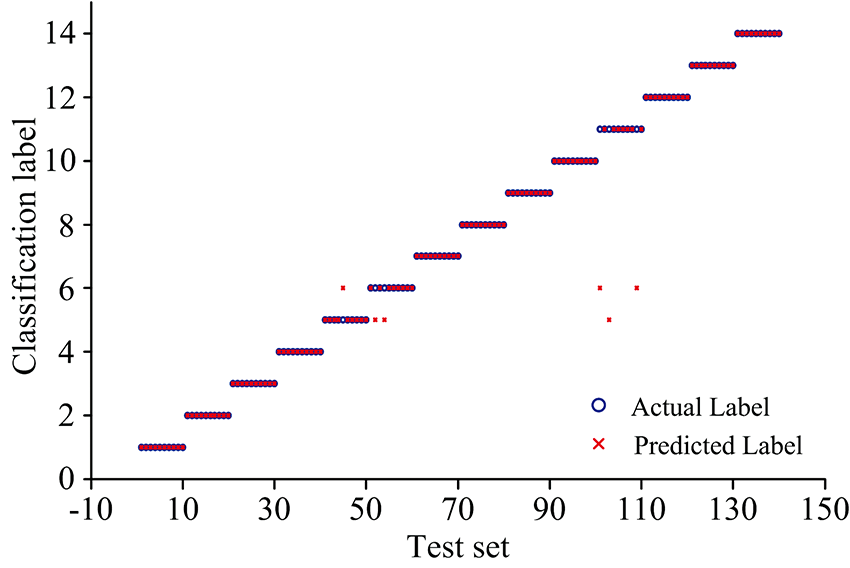 | 图4 归一化后SVM的预测结果Fig.4 The prediction results of normalized spectra by SVM |
由图4可见, 将归一化处理后的测试集共140个光谱数据输入训练后的SVM模型时, 图中出现了6个误判点。 由图可见, 出现误判的点为5, 6和11号样品, 根据表1各样品的元素浓度可知, 5, 6和11号样品所含Mn, Cr, Ni, Mo和V元素的浓度极其相似, 例如, 对Cr元素而言, 6号与11号Cr元素含量分别为1.02%和1.05%; 对Ni元素而言, 5和6号样品所含的浓度含量都为0.02%; 对V元素而言, 5和6号样品中所含的浓度含量分别为0.006%和0.005%。 以上元素浓度差别十分微弱, 并且由于目前绝大多数的激光器能量并不十分稳定, 导致某些样品中相似浓度的元素谱线做归一化后强度值极为接近, 系统模型受此影响从而发生了误判。
采用归一化处理后的51条特征谱线作为SVM分类器模型的输入向量, 14种特钢的平均识别正确率为95.71%, 此时的分类模型虽能识别大多特种钢材, 但精准度还并不理想。
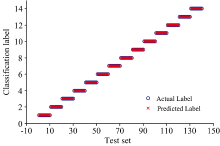
为了进一步提高分类的准确性, 使用MATLAB程序遍历不同谱线的组合作为输入变量, 进行多次建模, 最终挑选出最优的输入特征, 即6条最优特征谱线组合(如表3所示), 此时的SVM判断准确率达到了100%, 其实验结果如图5所示。
| 表3 SVM预测准确度达100%的6条特征谱线 Table 3 The 6 spectral lines with SVM prediction accuracy of 100% |
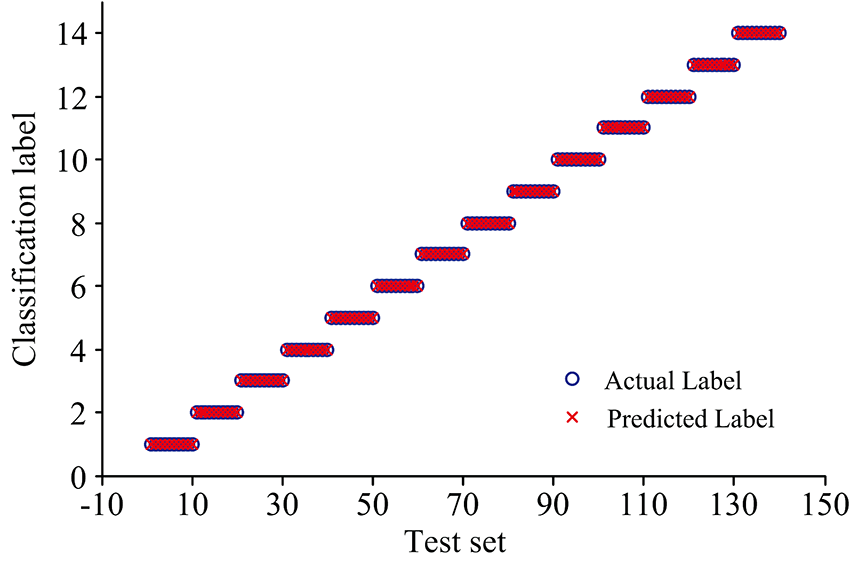 | 图5 挑选6条特征谱线后SVM预测结果Fig.5 The SVM prediction results using selecting 6 special spectral lines |
表4为不同输入特征下的准确率与建模时间的比较。 由表4可知, 采用数据归一化处理+遍历组合选出的6条最优特征谱线作为输入向量时, SVM模型识别准确度达到100%。 这是由于在众多谱线中, 算法通过遍历各种组合, 只余下辨识度高、 代表性强的谱线作为输入向量, 使得模型的精准度得到大幅提升。 从平均建模时间来看, 对数据采用归一化+遍历组合的算法处理后, 其建模时间也大大缩短, 相比于使用原始光谱的SVM分类模型, 其建模时间减小了37%。
| 表4 不同输入下SVM的平均预测准确率和平均建模时间 Table 4 The average prediction accuracy and mean modeling time of SVM with different inputs |
基于光纤传能的移动式LIBS样机平台, 采用预选谱线+遍历组合的降维方法与SVM算法相结合, 对14个特钢材料的LIBS光谱进行快速分类。 SVM算法计算简单、 训练速度快、 并且每次训练的模型稳定。 然而, 当单独将51条预选谱线作为输入特征输入到SVM算法时, 测试集中140组光谱数据在直接输入大量特征时发生了过拟合, 导致模型的泛化程度降低, 预测准确度仅为11.43%, 此时, 对14种特钢材料的分类精度并不理想; 当采用归一化光谱数据作为输入特征输入到SVM算法时, 预测准确度提高到95.71%, 说明对光谱数据进行归一化处理可以显著提高SVM模型的分类准确性; 而当51条预选谱线经过谱线遍历组合降维之后, 仅剩6条被选择的谱线作为输入特征时, 此时的SVM模型预测准确度达到了100%。 实验结果表明, 采用谱线遍历组合的方法是一种行之有效的降维方法。 同时, 该降维方法相对于人工选取特征谱线来说, 方便快捷, 操作简单, 对模型的优化程度高。 当面临大量特征数据时, 机器自动选取特征与人工挑选谱线相比具有明显优势。 可以看出, 基于谱线遍历组合降维方法的SVM算法模型结合LIBS技术, 在材料快速分类方面具有很好的工业应用前景。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|