{kind=link}
{kind=link}
{kind=link}
基于三维荧光光谱结合二维线性判别分析的油类识别方法的研究
[孔德明1  , 董瑞
, 董瑞1 , 崔耀耀2, * , 王书涛1 , 史慧超3 ]
, 董瑞, 王书涛|
|


作者简介: 孔德明, 1983年生, 燕山大学电气工程学院副教授 e-mail: demingkong@ysu.edu.cn
油类污染严重威胁到自然环境及人类健康。 因此, 识别和处理油类污染非常重要。 由于三维荧光光谱能够表征石油的荧光特征, 故一般利用三维荧光光谱法检测溶液中存在的油类污染物。 但油类的三维荧光光谱数据维度较高且直接分析的难度较大, 因此可以利用数据降维方法提取原始油类样本的光谱特征, 并利用所得到的光谱特征对样本进行识别。 基于此, 利用二维线性判别分析(2D-LDA)对油类样本进行特征提取, 研究提取的不同样本光谱特征的差别, 将得到的光谱特征作为K最近邻(KNN)分类的输入, 得到相应的分类结果。 首先, 分别配制四种不同的油类(柴油、 汽油、 航空煤油、 润滑油)样本各20个, 共计得到80个油类样本; 然后, 利用FS920光谱仪采集所有油类样本的三维荧光光谱数据; 其次, 对采集到的光谱数据进行预处理, 去除光谱中散射的干扰并标准化; 最后, 利用2D-LDA算法对样本进行特征提取, 利用KNN算法进行分类, 并将其分类结果与经主成分分析(PCA)进行特征提取后的分类结果比较。 研究结果表明, 2D-LDA提取特征的分类效果优于PCA。 利用2D-LDA分别提取发射和激发特征得到测试集识别的准确率相同且都为95%, 而将发射和激发光谱特征的分类距离相结合并重新进行分类的准确率为100%。 表明两类光谱相对于三维荧光光谱具有互补性, 将发射和激发光谱特征相结合能够更好地对样本进行分类。 而利用PCA对测试集识别的准确率仅为85%, 表明2D-LDA对三维荧光光谱数据的特征提取效果更好。 与PCA相比, 2D-LDA通过类内散度和类间散度最大化投影向量来提取样本的特征, 使得同类样本尽可能接近, 不同样本尽可能分离。 因此, 2D-LDA具有使降维后的数据更容易被区分的特点, 故其鲁棒性好。 该研究为油类的降维识别提供了一种参考。
Oil pollution seriously threatens the natural environment and human health. Therefore, it is very important to identify and deal with oil pollution. Therefore, three-dimensional fluorescence spectroscopy is generally used to detect the presence of oil contaminants in a certain solution. However, the three-dimensional fluorescence spectrum data of oils have high dimensions, and direct analysis is difficult. Therefore, the data dimensionality reduction method can be used to extract the spectral characteristics of the original oil samples. And the obtained spectral characteristics is used to identify and classify the samples. Based on this, the two-dimensional linear discriminant analysis (2D-LDA) is used to extract the characteristics of the oil samples. The differences in the spectral characteristics of the different samples extracted are studied. The obtained spectral characteristics are used as the input of the K nearest neighbor (KNN) classification to obtain the corresponding. Firstly, four different oils samples (diesel, gasoline, aviation kerosene, lubricating oil) was prepared, and each of the oils has 20 samples. So, 80 oils samples were prepared totally. Secondly, three-dimensional (3D) fluorescence spectrum data of all oil samples are collected by an FS920 spectrometer. Then, the spectral data is pre-processed to remove the scattering and to standardize it. Finally, the 2D-LDA algorithm is used to extract the characteristics of the samples, and the KNN algorithm is used to classify. The results were compared between principal component analysis (PCA) and 2D-LDA. 2D-LDA extracted the emission and excitation characteristics. Both accuracy is 95%. However, the accuracy of combining the classification distances of the emission and excitation spectrum characteristics and re-classifying is 100%. It shows that the two types of spectra are complementary to the three-dimensional fluorescence spectrum, and the combination of emission and excitation spectrum characteristics can better classify the sample. The results show that the classification effect of 2D-LDA characteristics extraction is superior to PCA. It shows that 2D-LDA is better for characteristics extraction of 3D-fluorescence spectrum data. Compared with PCA, 2D-LDA uses the intra-class matrix and the inter-class matrix to maximize the projection vector to extract the characteristics of samples. So, the same type of samples are closer, and the different type of samples are separated as much as possible. Therefore, the 2D-LDA can make it easier to identify data after reducing data dimensionality. Its robustness is good. This study provides a reference to identify oils.
石油是人们生产生活中的重要能源之一, 其具有不可替代的重要作用。 但从开采到应用的每一个环节中都有大量的石油及其产品(汽油、 煤油、 柴油等)以各种方式泄露到自然环境中。 这不仅严重污染了自然环境, 还致使大量生物死亡, 甚至威胁到人类的生命健康[1]。 因此, 只有及时对油类造成的污染进行处理, 才能有效保护生态环境和人类身体健康。 而对造成污染的油类进行准确地定性是处理油类污染的前提基础, 具有十分重要的意义。
石油的检测方法主要有红外光谱法[2]、 气相色谱法[3]和荧光光谱法[4]等。 其中, 三维荧光光谱法具有分析速度快、 灵敏度高、 可操作性强等优点, 因此被广泛应用到油类识别领域[4]。 鉴别石油的方法通常分为两种: 一是采用多维分解算法(PARAFAC[5]、 AWRCQLD[6]等)对油类的三维荧光光谱进行解析, 以得到具有定性信息的相对发射光谱矩阵和相对激发光谱矩阵, 并基于此对油类样本进行识别; 二是先对样本的光谱数据进行降维, 将其平均值、 标准差、 重心等[7]作为三维荧光光谱数据的特征, 依此实现石油种类的识别。 两种方法都是先提取能够定性光谱数据的信息, 但前者易受算法迭代次数的影响且计算量大, 部分二阶分析方法还有对组分数不敏感, 易受环境影响等缺点; 而后者所采用的方法不能够完全体现样本数据的特征。 所以寻找能够直接、 快速地提取不同油类光谱特征的方法对石油的准确分类具有重要意义。
本文将三维荧光光谱技术与2D-LDA算法相结合, 并利用K最近邻算法对目标油类进行分类。 结果表明利用2D-LDA算法提取的二维特征能够比较全面的表征原始数据, 将其用于石油分类能够获得更优的识别效果。
实验采集样本三维荧光光谱数据的仪器为FS920荧光光谱仪。 设置其发射波长范围为280~520 nm, 步长为5 nm, 激发波长范围为260~500 nm, 步长为10 nm。 实验分别配制了航空煤油(J)、 润滑油(L)、 柴油(D)、 汽油(G)四种不同类型的油类溶液。
实验配制油类溶液的步骤如下: (1)分别取用适量纯净水及十二烷基硫酸钠(SDS)配制成溶解石油所用的样本溶剂; (2)用精密电子秤分别称取相同质量的航空煤油、 润滑油、 柴油、 汽油于四个烧杯中, 加入适量的样本溶剂, 并用玻璃棒进行搅拌使其充分溶解, 分别将溶液转移至四个100 mL的容量瓶中并定容, 此为四种石油溶液的一级储备液; (3)利用移液枪分别移取20个不同体积的航空煤油的一级储备液于10 mL的容量瓶中并定容, 此为航空煤油的二级储备液; (4)取适量航空煤油的二级储备液于比色皿中, 并将比色皿放入FS920光谱仪中采集光谱数据; (5)按照步骤(3)— (4)的方法分别对润滑油、 柴油、 汽油进行配制, 得到浓度范围为0.1~2.0 mg· mL-1且梯度为0.1 mg· mL-1的四种油类样本。
实验结束后每种石油得到20个样本, 四种石油共计采集得到80个样本。 利用Kennard-Stone算法将样本分成两组, 其中一组作为训练集, 另一组作为测试集, 训练集中含有60个样本, 测试集含有20个样本。
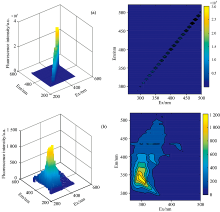
利用光谱仪采集得到每个样本的光谱数据维度大小为49× 25, 其中49为发射波长数, 25为激发波长数。 一般地, 由于光的散射效应, 使得所采集溶液的三维荧光光谱中存在瑞利散射和拉曼散射, 如图1(a)所示。 图1(a)中凸起的峰为瑞利散射, 瑞利散射的强度严重掩盖了润滑油本身的光谱, 为了避免散射对实验产生的干扰, 必须对光谱进行去散射处理。 图1(b)为利用Delaunay三角形内插值法去除散射后润滑油的三维荧光光谱图和等高线图, 能够清晰的发现散射光谱被去除, 润滑油的光谱得到凸显。
 | 图1 润滑油三维荧光光谱图 (a): 去散射前; (b): 去散射后Fig.1 Three-dimensional fluorescence spectrum of lubricating oil (a): Before removing scattering; (b): After removing scattering |
2D-LDA利用类内散度和类间散度优化投影矢量, 通过原始矩阵在投影矩阵上投影, 得到相应的特征矢量。 因此, 2D-LDA能够直接通过矩阵提取特征, 而不需要先将二维矩阵展开为一维向量再提取特征。 所以, 2D-LDA能够在保留原始结构信息基础上有效提取用于分类的特征信息。
设Xm× n为一个三维荧光光谱数据矩阵, 其中m为发射波长数, n为激发波长数, 将X乘以一个投影向量, 会得到关于矩阵X的特征向量。 通过最大化线性投影准则, 得到最佳投影向量为,
其中,
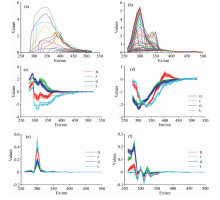
图2(a)和(b)分别为单个润滑油样本原始的发射光谱和激发光谱。 图2(c)和(d)分别为提取的所有训练样本水平方向上第一、 第二投影向量的特征信息, 也即发射光谱的特征信息; 图2(e)和(f)分别为提取的所有训练样本垂直方向上第一、 第二投影向量的特征信息, 即激发光谱的特征信息; 其中D, J, G和L分别为柴油、 航空煤油、 汽油、 润滑油。 由图2可知, 2D-LDA算法提取的油类样本的特征光谱信息降低了原来样本数据的维度, 通过前两个主要投影向量对样本的三维荧光光谱投影得到的光谱信息具有明显区分不同类型石油样本的作用。 图2(c)和(d)所示的发射光谱特征中, 不同类型石油的差别集中在280~450 nm; 图2(e)和(f)所示的激发光谱特征中, 不同类型石油的区别集中在260~350 nm。 产生这种现象原因是发射光谱中450 nm之后的石油的荧光强度极低且接近于0, 同样在激发光谱中350 nm之后的石油的荧光强度极低且接近于0。 因此, 在发射波长为280~520 nm, 激发波长为260~500 nm的范围内, 柴油、 航空煤油、 汽油、 润滑油这四种油的有效发射光谱波长和激发光谱波长范围分别为280~450和260~350 nm。
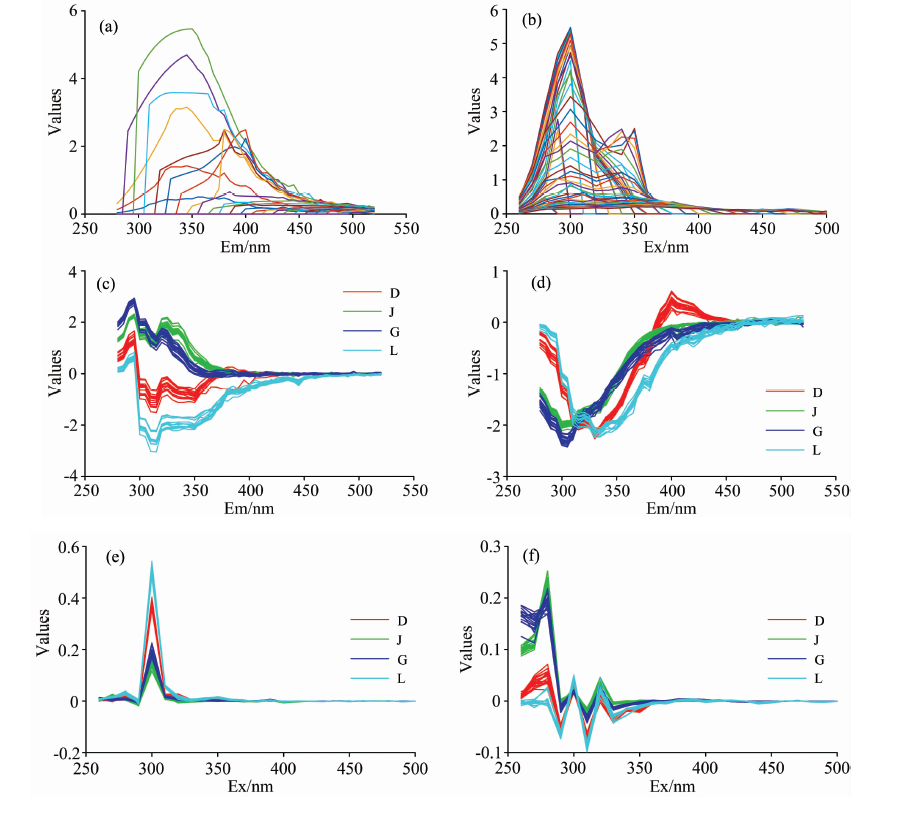 | 图2 润滑油原始发射、 激发光谱图及通过投影向量获取的训练集样本光谱特征 (a): 发射光谱图; (b): 激发光谱图; (c): 第一投影向量的发射特征; (d): 第二投影向量的发射特征; (e): 第一投影向量的激发特征; (f): 第二投影向量的激发特征Fig.2 Original emission and excitation spectrum of lubricating oil and characteristics of training sample obtained by projection vector (a): Emission spectrum; (b): Excitation spectrum; (c): First emission characteristic; (d): Second emission characteristic; (e): First excitation characteristic; (f): Second excitation characteristic |
利用PCA提取原始光谱数据的特征信息, 得到相应的主成分的特征值及对应的贡献率。 根据每个主成分对应的贡献率和累积贡献率, 选取合适的主成分数建立分类模型。 前十个主成分所对应的贡献率如表1所示。 由表1可知, 前四个主成分的贡献率分别为66.52%, 19.63%, 4.61%和3.12%, 累积贡献率为93.88%。 在主成分分析中选取的主成分数需要包含原始数据的大部分信息, 因此选取前四个主成分作为后续分析的主成分数。
| 表1 主成分的贡献率 Table 1 Contribution rate of principal component |
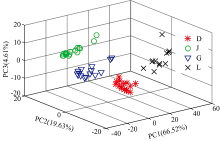
绘制训练集前三个主成分的得分散点图, 如图3所示。 由图3可知, 图中同种类型的样本聚集在一起, 而不同类型的样本彼此分离, 具有明显的区别。 并且图中不同类型的样本没有重叠的情况发生, 表明PCA能够较好的提取光谱的特征信息, 但存在少数样本会偏离同类型大部分样本的聚集位置。 将测试集的样本在由训练集建立的模型上投影, 得到测试集中各样本的得分, 并以此作为分类的信息。
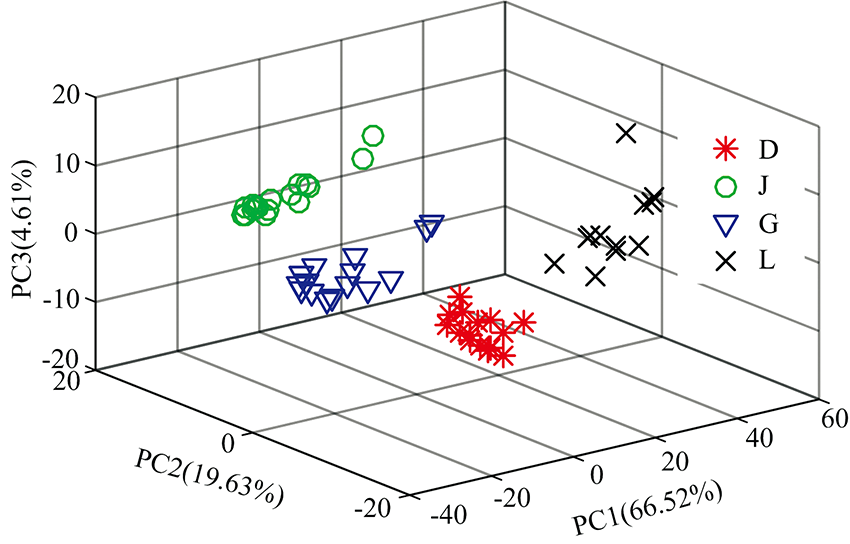 | 图3 前三主成分得分图Fig.3 First three principal component score |
2.3.1 2D-LDA提取特征后分类
分别将2D-LDA提取后的发射和激发光谱特征作为KNN分类模型的输入, 并通过计算样本之间的距离对所有样本分类, 分类结果如表2所示。 由表2可知, 发射光谱特征作为输入时, 测试集中的柴油、 航空煤油和润滑油分类的准确率为100%, 存在一个汽油样本被错误分类为航空煤油, 故汽油分类的准确率为80%, 但在整个测试集中, 存在20个样本, 只有一个样本被错误分类, 因此测试集中样本分类的准确率为95%; 激发光谱特征作为输入时, 存在一个柴油样本被错误分类为润滑油, 但其整个测试集分类的准确率也为95%。 三维荧光光谱包含发射光谱和激发光谱, 且两类光谱表征三维荧光光谱的不同方向, 在一定程度上两类光谱相对三维荧光光谱具有互补性, 所以利用两类光谱特征对样本分类结果具有差异。 而将两类特征的KNN分类距离叠加并重新作为训练集和测试集样本分类的标准, 得到识别的准确率为100%, 表明融合发射和激发光谱特征能够对油类样本实现更好地识别。
| 表2 利用2D-LDA特征提取后的分类结果 Table 2 Classification results after 2D-LDA characteristics extraction |
2.3.2 PCA提取特征后分类
将PCA提取后样本的前四个主成分的得分作为KNN分类模型的输入, 计算样本之间的距离并分类, 结果如表3所示。 由表3可知, 只有航空煤油分类准确率为100%, 而柴油、 汽油和润滑油中都存在一个样本被错误分类。 因此, 在整个测试集中, 存在3个样本被错误分类, 故分类的准确率为85%。 由图3可知, 利用PCA特征提取的结果中不存在不同类型石油重叠的情况, 但存在少数的样本偏离大部分同类样本。 因此偏离的样本可能会存在与其他类型样本的距离小于同类样本距离的情况, 从而导致错误分类。
| 表3 主成分特征提取后的分类结果 Table 3 Classification result after principal component characteristic extraction |
对比两种特征提取方法的分类结果, 表明2D-LDA提取的光谱数据特征具有提高分类准确率的作用, 经2D-LDA提取特征后的分类的准确率更高。 尽管2D-LDA算法提取的不同类型样本的光谱特征曲线存在部分重叠, 但其类内差别远小于类间差别, 并且识别率高, 表明该算法的鲁棒性好。 而PCA提取的前四个主成分的贡献率虽然已经达到93.88%, 但仍可能会丢失一些重要的辨别样本种类的特征信息, 导致分类结果出现错误。 因此, 2D-LDA提取石油光谱特征的性能优于PCA。
采集了航空煤油、 润滑油、 柴油和汽油的三维荧光光谱, 通过2D-LDA对其进行二维特征提取, 并利用KNN算法对样本分类, 得到样本的分类结果。 实验结果表明, 利用2D-LDA提取特征后的分类准确率较高, 达到95%, 且结合两类光谱特征分类得到的准确率为100%, 而PCA特征提取后的分类准确率为85%。 因此, 利用二维线性判别分析直接提取三维荧光光谱的二维光谱特征并将其用于定性分析, 能够获得更优的油类识别效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|