

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
赤霞珠酿酒葡萄总酚含量的近红外光谱定量分析
[罗一甲1  , 祝赫
, 祝赫1 , 李潇涵1 , 董娟1 , 田昊1 , 史学伟1 , 王文霞2 , 孙静涛1, * ]
, 祝赫]
|
|


作者简介: 罗一甲, 女, 1994年生, 石河子大学食品学院硕士研究生 e-mail: luoyijiayj@126.com
酿酒葡萄中的总酚含量是影响葡萄品质的重要指标, 也是影响葡萄酒质量的关键因素。 为了快速准确地检测赤霞珠葡萄的总酚含量, 利用近红外光谱技术结合GA-ELM预测模型对赤霞珠葡萄总酚含量进行预测研究。 试验采用5个收获期(每期采集40串, 每串取10个)的赤霞珠葡萄, 采集200组葡萄的12 500~4 000 cm-1波段范围内的近红外光谱。 基于福林酚比色法原理对赤霞珠葡萄的总酚含量进行测定, 使用SPXY算法将样品按照3:1比例分为校正集和预测集, 共计150个校正集和50个预测集。 分别采用多元散射(MSC)、 标准正态变换(SNV)、 数据中心化(MC)、 移动窗口平滑(MA)和一阶导数+SG方法对原始光谱进行预处理, 优选出最佳的预处理方法为MSC。 并进一步采用竞争性自适应重加权算法(CARS)、 遗传算法(GA)、 联合区间偏最小二乘算法(si-PLS)和连续投影算法(SPA)分别对光谱波段进行提取, 经对比分析发现CARS提取的69个特征波长数据能有效提高模型的稳定性和预测结果。 在MSC预处理和特征波长提取的基础上, 引入极限学习机(ELM)算法, 建立赤霞珠葡萄总酚含量的预测模型, 在总酚含量预测过程中, 采用遗传算法(GA)对ELM模型进行优化, 并探究了不同的激活函数和隐含层神经元个数对GA-ELM模型预测能力的影响, 确定最优的激活函数为Sigmoidal, 最优的神经元个数为50个。 最后, 将ELM和GA-ELM模型的预测能力进行对比, 结果显示GA-ELM模型的预测能力高于ELM模型的预测能力, 其中MSC+CARS+GA-ELM模型预测能力最好, 校正相关系数( Rc)为0.901 7, 预测相关系数( Rp)为0.901 3, 校正均方根误差(RMSEC)为2.112 4, 预测均方根误差(RMSEP)为1.686 8, 剩余预测偏差(RPD)为2.308 0。 研究结果表明: 利用近红外光谱技术结合变量优选建立的GA-ELM模型可实现对赤霞珠葡萄的总酚含量的预测, 为赤霞珠葡萄品质的检测奠定了理论基础。
, ZHU He
The contents of total phenol in wine grape are an important indicator of grape quality and also a key factor of wine quality directly. To detect the total phenol contents of the cabernet sauvignon grape quickly and accurately, this paper used near-infrared spectroscopy and GA-ELM prediction model to predict the total phenol content of Cabernet Sauvignon grapes. In the experiment, Cabernet Sauvignon grapes were collected in 5 harvest periods (40 bunches were collected in each harvest period, and 10 grapes were acquired in each cluster), and near-infrared spectra information in the range of 12 500~4 000 cm-1 was collected for 200 groups of grapes. The total phenol content of Cabernet Sauvignon grapes was determined based on the principle of Folin-Ciocalteus colorimetry, SPXY algorithm was used to divide the samples into correction sets and prediction sets at a ratio of 3:1, with a total of 150 correction sets and 50 prediction sets. Multiplicative Scatter Correction (MSC),Standard Normalized Variate (SNV), Mean Centering (MC), Moving Average (MA), and the First Derivative +SG was used to preprocess the raw spectra, MSC was compared as the best pretreatment method.And then, competitive adaptive reweighted sampling (CARS), genetic algorithm (GA), successive projections algorithm (SPA) and synergy interval partial least squares (si-PLS) were extracted the characteristic wavelengths, respectively. The comparative analysis found that the 69 characteristic wavelength variables extracted by CARS could effectively improve the model's stability and prediction ability. Based on the MSC and different variable optimization methods, the extreme learning machine (ELM) algorithm was introduced to establish the total phenol content prediction model. In predicting total phenol content, a genetic algorithm (GA) was used to optimize the ELM model and the influence of different kernel functions and the number of hidden layer neurons on the prediction ability of the GA-ELM model investigated. The optimal kernel function was Sigmoidal, and the optimal number of neurons was 50. Finally, the prediction capabilities of the ELM and GA-ELM models were compared. The results showed that GA-ELM models were more accurate in predicting than the ELM models, and the MSC+CARS+GA-ELM model was the best with a correlation coefficient of calibration ( Rc) of 0.901 7, the correlation coefficient of prediction of 0.901 3, the root mean square error of calibration (RMSEC) of 2.112 4, the root mean square error of prediction (RMSEP) of 1.686 8 and residual prediction deviation (RPD) of 2.308 0. The combination of variable optimization methods and the GA-ELM model was an effective method, which provided a theoretical basis for detecting Cabernet Sauvignon grapes' quality.
葡萄酒的品质与葡萄的质量密切相关。 葡萄中的总酚含量决定了果实中酚成熟状态, 影响着葡萄酒的颜色、 味道和口感, 是生产优质红葡萄酒的一个关键标准。 目前, 葡萄总酚含量的测定常用福林酚法, 检测过程繁琐费时, 大样本操作困难, 检测后的样品组织遭到破坏, 商品价值丧失。 因此, 寻求一种高效、 快速的检测葡萄总酚含量的方法十分必要。
近红外光谱技术是一种新型分析检测技术, 具有快速、 无损、 便捷等优势。 在水果品质检测方面, 近红外光谱技术应用广泛, 其中在葡萄品质无损检测方面, 国内外学者进行了一定的研究[1, 2, 3]。 有时近红外光谱包含的数据量大、 信息冗杂, 需采用合适的波长提取方法使数据信息更具特征性。 许峰等[4]利用近红外光谱技术结合CARS算法对红提葡萄的糖度和酸度进行预测, 建立随机森林预测模型, 预测相关系数分别达到0.956 8和0.940 5。 Michael等[5]利用近红外光谱技术对不同年份、 不同收获期的赤霞珠和西拉葡萄的可溶性固形物(SSC)、 pH、 可滴定酸、 花青素和总酚含量进行预测, 采用不同的预处理方法结合递归特征消除(REF)算法建立PLS预测模型, 但模型的总酚含量预测结果较低。 章林忠等[6]利用近红外光谱技术对不同品种的鲜食葡萄的总酚、 总糖、 果糖、 蔗糖和SSC进行预测, 建立PLS预测模型, 但部分葡萄总酚含量的预测结果出现过拟合现象。 当前, 国内外利用近红外光谱技术对酿酒葡萄总酚含量的研究较少, 研究多在某一固定采收期下进行, 未在模型优化方面进行探讨, 模型预测能力相对较低。
以酿酒葡萄赤霞珠为研究对象, 利用近红外光谱技术结合遗传算法优化极限学习机(GA-ELM), 建立不同采收期赤霞珠葡萄总酚含量的预测模型。 采用不同光谱预处理、 特征变量筛选和建模方法, 尝试提高模型的稳定性和预测能力, 为实际生产中精准预测赤霞珠葡萄的总酚含量提供理论参考和依据。
试验使用的酿酒葡萄为赤霞珠, 样品采集地点为新疆石河子市张裕酒庄。 于2019年9月16日到10月14日期间进行, 每间隔7天采集一次样品, 共采集5次, 每次采集从不同的植株上随机采取40穗葡萄, 从每穗葡萄的上、 中、 下选取无病虫害、 无机械损伤的葡萄果实, 每10粒葡萄作为一个试验样品, 共计200个样品。 采收当天将样品运至6 ℃冷藏室进行冷藏, 试验前, 需将样品在室温下静置4 h, 使其温度与室温基本一致。 模型建立前, 使用SPXY算法将样品按照3:1比例分为校正集和预测集, 共计150个校正集和50个预测集。
本研究使用德国布鲁克(BRUKER)公司生产的TANGO-R型傅里叶近红外光谱仪对赤霞珠葡萄的光谱进行采集。 采集参数设置如下: 波长范围为12 500~4 000 cm-1, 分辨率为8 cm-1, 扫描次数为32次, 平滑为3。 仪器控制和初始光谱采集使用OPUS软件执行。 将赤霞珠葡萄放在带有圆形石英底座(直径3 cm)的光谱仪样品杯中, 以反射模式收集赤霞珠的NIR光谱。 每个葡萄平行测三次, 每个样本10颗葡萄, 共计30条光谱取其平均, 每次测量后, 应使用蒸馏水清洗光谱仪样品杯, 并用纸巾擦干, 以进行下一次样品的光谱采集。
光谱采集完成后, 采用Ivanova等[7]的方法对样品进行前处理, 并将前处理后的样品液储存于-20 ℃冰箱中, 用于后续总酚含量的测定。 总酚含量基于福林酚比色法的原理, 采用徐国前等[8]的方法进行测定, 于765 nm波长下测量样品及不同质量浓度的没食子酸的吸光度值, 并以没食子酸的质量浓度(mg·g-1)为横坐标, 吸光度为纵坐标制作标准曲线, 根据标准曲线计算每个样品的总酚含量。
采用多元散射(MSC)、 标准正态变换(SNV)、 数据中心化(MC)、 移动窗口平滑(MA)和一阶导数+SG方法对原始光谱进行预处理, 运用竞争性自适应重加权算法(CARS)、 遗传算法(GA)、 联合区间偏最小二乘算法(si-PLS)和连续投影算法(SPA)对全光谱进行特征波段的筛选, 再结合极限学习机(ELM)和遗传算法优化极限学习机(GA-ELM)建立赤霞珠葡萄总酚含量的定量分析模型, 以校正相关系数(Rc)、 预测相关系数(Rp)、 校正均方根误差(RMSEC)和预测均方根误差(RMSEP)为指标来评价模型的性能。
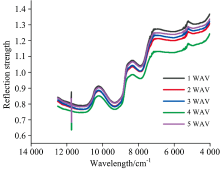
图1为不同采收期赤霞珠葡萄的原始光谱图, 由图知光谱整体趋势基本一致, 各谱线在反射强度上存在一定的差异, 在波长为10 200和8 340 cm-1附近出现波峰, 在9 300和7 880 cm-1附近出现波谷, 这些波峰与波谷可能是由于赤霞珠葡萄总酚中的基团(C—H, O—H, N—H)对近红外光谱吸收率不同造成的, 可为光谱与总酚建立关系提供理论基础。 图2为不同采收期下赤霞珠葡萄的原始平均光谱, 五个采收期的赤霞珠葡萄的光谱变化趋势也基本一致。 由于处于不同采收阶段, 葡萄内部的物质含量不同, 光谱吸收的强度也有所不同。 赤霞珠葡萄在第一个采收期(1WAV)即转色后的第1周的光谱值普遍高于其他采收阶段的光谱值, 随着采收期的延长, 赤霞珠葡萄的光谱值逐渐下降。
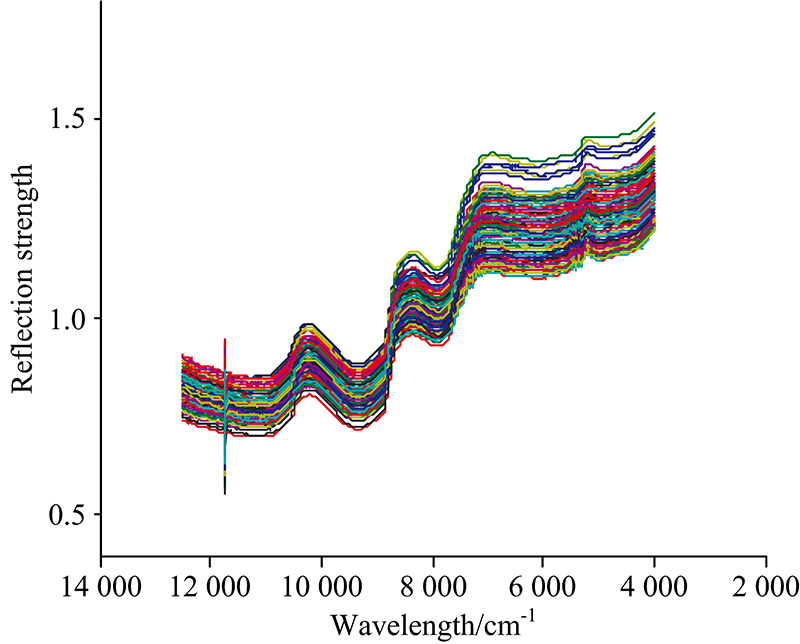 | 图1 不同采收期的赤霞珠葡萄的原始光谱曲线Fig.1 Raw spectra of Cabernet Sauvignon in different harvest stages |
 | 图2 不同采收期的赤霞珠葡萄的平均光谱曲线Fig.2 Mean raw spectra of Cabernet Sauvignon in different harvest stages |
表1为五个不同采收期下赤霞珠葡萄总酚含量的统计结果, 从整体来看, 赤霞珠葡萄在各个采收阶段总酚含量上升趋势明显。 在1 WAV赤霞珠葡萄的总酚含量平均值为18.99 mg·g-1, 随着赤霞珠葡萄采收期的延长, 总酚含量持续上升, 在4 WAV总酚含量的平均值达到最大为28.10 mg·g-1, 到5 WAV总酚含量稍有下降, 这与总酚在酿酒葡萄成熟期的变化趋势大体相同。 不同采收期的赤霞珠葡萄总酚含量差异性比较明显, 含量范围较大(11.23~34.85 mg·g-1)。
| 表1 不同采收期的赤霞珠葡萄的总酚含量统计结果 Table 1 Statistical results of total phenol content of Cabernet Sauvignon in different harvest stages (mg·g-1) |
在光谱采集过程中, 由于葡萄表面的杂散光、 采集环境、 采集仪器等因素的影响使采集后的光谱包含大量噪声信息, 影响了模型的预测结果[9]。 因此, 在建立预测模型前需对光谱进行预处理, 本研究主要使用MSC、 SNV、 MC、 MA和一阶导数+SG方法对原始光谱进行预处理, 并将预处理后的光谱建立ELM总酚含量预测模型, 结果见表2。
| 表2 不同预处理方法的总酚含量ELM模型建模结果 Table 2 Results of ELM modeling for the total phenol content with different pre-treatment methods |
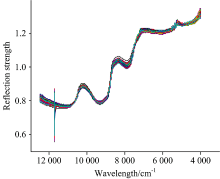
由表2可知, 经预处理后的光谱模型精度较原始光谱均有提高, 其中MSC处理过的模型预测能力明显提高, Rp为0.680 9, RMSEP为2.943 1, RPD为1.365 5, 故将MSC处理后的光谱进行后续的研究。 图3为MSC处理后的反射光谱, 光谱之间的紧密性显著增强。
 | 图3 MSC处理后的反射光谱Fig.3 Reflectance spectra obtained after MSC |
全波段光谱信息中, 存在数据冗杂和共线性变量等现象, 为了精简模型、 提高模型预测能力需要对光谱进行特征波长提取。 本研究使用的特征波长提取方法有: CARS, GA, si-PLS和SPA。
2.4.1 竞争性自适应重加权算法(CARS)
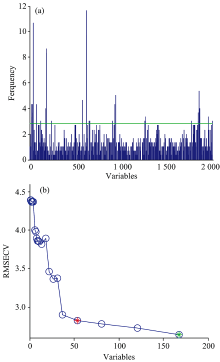
CARS基于达尔文的“ 适者生存” 思想, 利用自适应重加权采样技术和指数衰减函数在建立的模型中循环运行, 根据交叉验证均方根误差(RMSECV)最小值, 确定最优的变量子集[10]。 图4(a)显示CARS采样次数与筛选出来的波长变量个数之间的关系, 随着采样次数的增加筛选出来的波长变量数呈现出由快到慢的趋势, 这是CARS算法筛选波长变量数由粗选到细选的一个过程。 图4(b)显示的是采样次数与RMSECV之间的关系, 随着采样次数的增加, RMSECV值呈现先降低后升高的趋势, 当采样为第25次的时候, 对应的RMSECV最小为2.333 3。 图4(c)是采样过程中各波长变量的回归系数变化路径, 图中的每条线描述了不同采样周期下所有波长变量的系数, 星垂线表示采样次数为25, 结合图4(b)可知此时RMSECV值最小, 对应筛选出来的特征波长数为69, 仅占全波段的3.34%。
 | 图4 CARS特征波长提取 (a): 波长变量变化; (b): 交叉验证均方根误差变化; (c): 变量回归系数的变化趋势Fig.4 Characteristic wavebands selected by CARS algorithm (a): Variation of the number of selected wavelength variables; (b): Variation of RMSECV; (c): The changing trend of variable regression coefficients |
2.4.2 遗传算法(GA)
GA是基于自然选择原理, 通过不断迭代全局寻优的一种算法[11]。 该算法的参数设置为: 初始种群50, 变异率0.005, 遗传迭代次数为100和收敛率为0.5。 图5(a)为赤霞珠葡萄总酚变量选取频率图, 超出绿色实线以上的变量为选中的波长变量。 图5(b)为所选波长变量数与RMSECV之间的关系图, 随着所选波长数的逐渐变大, RMSECV值呈现逐渐减小的趋势, 减小趋势由快到慢, 当筛选出来的波长数为168个(绿色圆点表示), RMSECV最小为2.636 9, 所选的波长数占全波段的8.19%。
 | 图5 (a)GA筛选波段的频率分布; (b)GA波长提取Fig.5 (a) Frequency distribution of bands selected by GA; (b) Selection of wavelengths by the GA method |
2.4.3 联合区间偏最小二乘算法(si-PLS)
si-PLS是通过将全光谱区间进行划分, 并组合区间中模型精度较高的子区间共同预测样品理化指标的一种算法[1]。 将MSC算法处理过的全光谱划分为20个子区间, 在主成分为9时, 交叉验证均方根误差(RMSECV)最小为2.979, 并联合1, 15, 18, 20四个子区间, 共同预测赤霞珠葡萄总酚含量。 四个子区间对应的波段区间为12 492.46~12 068.08, 6 538.77~6 118.50, 5 265.62~4 845.36和4 416.86~3 996.60 cm-1, 共计413个特征波长变量, 占全波段的20%, 如图6所示。
 | 图6 si-PLS特征波长提取Fig.6 Characteristic wavebands selected by si-PLS method |
2.4.4 连续投影算法(SPA)
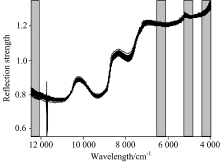
SPA是一种向前循环算法, 通过向量投影分析筛选出冗杂信息量少的波长变量, 能够有效解决信息重叠、 共线影响, 提高模型的预测能力[12]。 研究中设定SPA选取的特征波长数量为50~100个, 采用SPA算法对MSC处理过的全光谱进行特征波长提取。 当RMSE为3.204 3时, SPA算法提取出来50个特征波长, 占全光谱的2.42%, 其波长变量分布如图7所示。
 | 图7 通过SPA选择的50个特征波长分布图Fig.7 Plot of 50 wavelengths selected by SPA |
ELM是一种单隐含层前馈神经网络学习算法, 输入层、 隐含层和输出层三部分组成, 其中模型的阈值和权值可随机产生, 无需迭代调整, 因此ELM模型的训练速度和泛化能力较传统的模型具有速度快、 性能好的优势。 由于ELM模型的权值和阈值随机性, 部分权值和阈值可能达不到最优状态, 导致模型每次运行的结果不一致, 而遗传算法(GA)是常用的全局优化算法, 可以很好地寻找ELM神经网络的权值和阈值的最优值。
2.5.1 GA参数设置
在GA对ELM模型的权值和阈值优化过程中, 适宜的模型参数设置尤为重要。 GA参数经多次运行确定, 包括: 种群规模为50, 最大遗传代数为20, 代沟为0.95, 交叉变异概率为0.7, 变异概率为0.01。
2.5.2 ELM参数设置
激活函数是影响ELM模型预测性能的关键因素。 分别使用Sigmoidal, Sine和Hardlim三种不同的激活函数, 在隐含层神经元个数为40时, 利用CARS, GA, si-PLS和SPA算法对MSC处理后的全光谱进行特征波长的筛选, 将筛选出来的波长作为输入变量建立GA-ELM模型, 根据模型的预测结果来比较不同激活函数的性能。 表3是经MSC处理后, 用CARS提取特征波长的GA-ELM模型, 由表3可知当激活函数为Sigmoid时, 模型的性能相对较好, 且运行时间与其他激活函数相差不大。 利用GA, si-PLS和SPA这三种算法提取特征波长后建立的模型, 当激活函数均为Sigmoidal时, 模型的预测能力相对较高, 因此后续的研究选用Sigmoidal激活函数。
| 表3 不同激活函数的性能比较 Table 3 Performance comparison of different activation functions |
隐含层神经元个数对ELM模型的预测能力也产生着重要的影响。 隐含层神经元个数偏少会导致模型信息处理和学习能力降低, 模型出现“ 欠拟合” 状态, 如果隐含层神经元个数偏多, 模型结构将变得复杂、 运行时间将变长, 模型出现“ 过拟合” 状态。 因此需要通过多次尝试变换隐含层神经元个数, 多次运行GA-ELM模型, 从而筛选出最优的隐含层神经元个数。
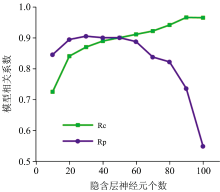
设置GA-ELM的隐含层神经元个数初始化为10, 并以10为间隔逐步增加至100, 激活函数设为Sigmoidal, 利用CARS, GA, si-PLS和SPA算法对MSC处理后的光谱进行特征波长的筛选, 将筛选出来的波长作为输入变量建立GA-ELM模型, 根据模型的预测结果选取合适的隐含层神经元个数。 图8为不同隐含层神经元个数对MSC+CARS+GA-ELM模型预测能力的影响, 当隐含层神经元个数小于50时, Rc小于Rp, 模型欠拟合; 当隐含层神经元个数大于50时, Rc远大于Rp, 模型过拟合; 当隐含层神经元个数为50时, Rc为0.901 7, Rp为0.901 3, 模型适度拟合, 故该模型组合最合适的隐含层神经元个数为50。 另外MSC+GA+GA-ELM, MSC+si-PLS+GA-ELM, MSC+SPA+GA-ELM这三种模型组合, 在隐含层神经元个数同样设置为50时, 预测能力相对较高, 因此后续研究中模型的隐含层神经元个数设为50。
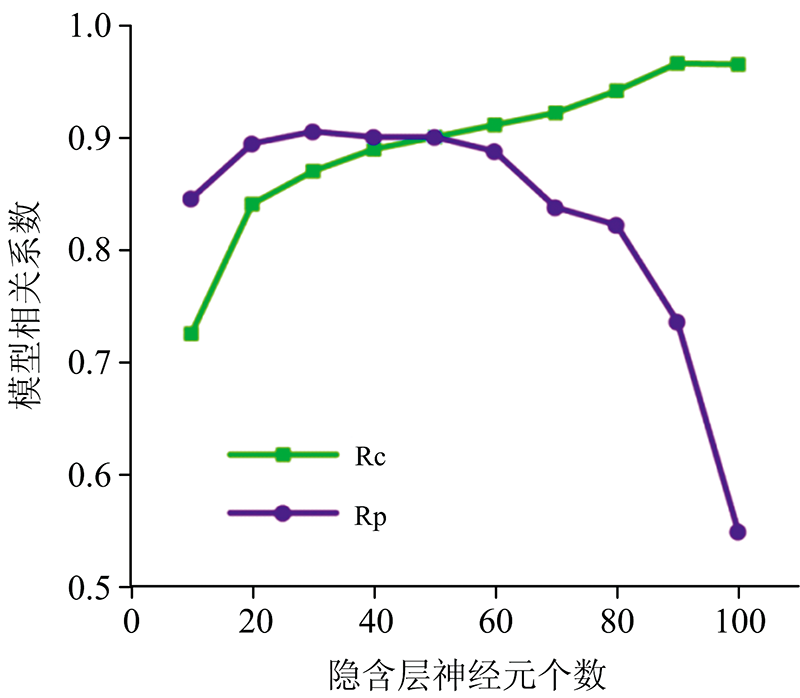 | 图8 不同隐含层神经元个数对模型性能的影响Fig.8 The influence of the number of neurons in different hidden layers on the performance of the model |
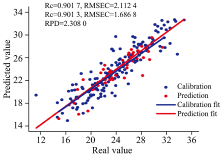
经MSC处理后, 利用CARS, GA, si-PLS和SPA算法筛选出来的波长变量数分别为69, 168, 413和50, 将筛选出来的波长作为输入变量分别建立ELM和GA-ELM预测模型, 预测结果如表4所示。 在特征波长提取方面, 经SPA算法筛选出来的波长变量数目最少, 建立的模型预测结果不高, 其原因可能是经SPA筛选出来的50个特征波长中与赤霞珠总酚相关的部分特征波长变量被剔除, 造成模型预测能力的降低; 经si-PLS算法筛选出来的特征波长变量数目最多, 但是在这些有效区间内仍存在共线性变量, 从而导致模型的预测能力降低; 经CARS提取出来的69个变量建立的模型预测结果均高于其他模型, ELM模型Rp为0.824 5, GA-ELM模型Rp为0.901 3, 结果表明, CARS算法可以明显提高总酚的预测能力。 选择合适的特征波长提取方法可以有效剔除光谱中的冗杂信息, 降低变量中的共线性, 提高近红外光谱与赤霞珠葡萄总酚含量之间的相关性, 从而提高模型的预测能力。 在建模算法方面, 将ELM和GA-ELM模型进行比较, 经不同特征波长提取方法建立的ELM模型R均为0.669 9以上, RMSE均低于3.346 4, 其中MSC+CARS+ELM的模型预测结果相对较好, 模型的Rp=0.824 5, RMSEP=2.203 2, RPD=1.767 0; 而利用不同特征波长优选方法建立的GA-ELM模型的R均在0.719 1以上, RMSE均低于2.962 2, 较传统的ELM模型, R得到提高, RMSE相应降低, 其中MSC+CARS+GA-ELM预测结果最好, 预测模型的校正集和预测集散点图如图9所示, 模型的Rc=0.901 7, Rp=0.901 3, RMSEC=2.112 4, RMSEP=1.686 8, RPD=2.308 0。 由结果可知GA-ELM模型的预测能力整体要高于ELM模型的预测能力, 因此GA可以有效优化ELM算法。
| 表4 ELM和GA-ELM模型预测效果 Table 4 The prediction results of ELM and GA-ELM models |
 | 图9 总酚含量真实值与预测值的散点图Fig.9 Scatter plot of real value and predicted value of total phenol content |
利用近红外光谱结合GA-ELM网络建立赤霞珠葡萄总酚含量预测模型。 采用MSC算法对光谱进行预处理, 结合CARS, GA, si-PLS和SPA算法对波长变量进行优选, 并基于所选的特征波长建立ELM模型, 为了进一步提高模型的精度, 采用GA算法来优化ELM神经网络。 结果表明, 利用CARS算法对MSC处理后的全光谱进行特征波长的筛选, 将筛选出来的69个波长作为输入变量建立GA-ELM模型的预测能力最好, Rc为0.901 7, Rp为0.901 3, RMSEC为2.112 4, RMSEP为1.686 8, RPD为2.308 0。 利用近红外光谱技术, 采用变量优选和GA-ELM算法对赤霞珠葡萄总酚含量的预测是一种有效的方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|