
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于优选NIR光谱波数的绿豆产地无损检测方法
[黄燕1  , 王璐
, 王璐2 , 关海鸥2, * , 左锋3, 4 , 钱丽丽3, 4 ]
, 王璐, 左锋|
|


作者简介: 黄 燕, 1970年生, 黑龙江八一农垦大学工程学院教授 e-mail: kelly_clever@163.com
产地是影响农作物生产的重要环境因素, 产地溯源对于食品安全具有重要意义。 针对传统农产品产地检测一般采用化学分析法, 其操作繁琐且存在破坏性和耗时较长等不足的问题, 以北方寒地绿豆为研究对象, 分别在白城、 杜蒙、 泰来等优质绿豆主产区, 获取绿豆的籽粒和粉末两种状态的近红外光谱数据(NIR), 利用优选NIR光谱特征波数, 建立了绿豆产地无损检测的新方法。 首先在吸光度值较强的10 105.37~4 078.655 cm-1波数范围内, 采用多元散射校正法(MSC), 对不同产地的绿豆原始光谱数据进行预处理, 以消除光谱干扰信息。 应用竞争性自适应重加权采样算法(CARS), 优选不同产地绿豆籽粒和粉末状态的光谱特征波数, 以减少光谱曲线的特征向量维度。 最后利用前馈神经网络(BP)自适应推理机制, 建立了绿豆产地与其光谱特征波数之间非线性映射模型, 并将网络输出的编码向量解析至产地名称, 作为绿豆产地检测的输出结果。 研究结果表明: (1)原始光谱经过多元散射校正预处理后, 绿豆粉末光谱曲线的误差从12.87降到3.20, 绿豆籽粒光谱曲线的误差从153.04降到27.73, 提供有效可靠的光谱数据。 (2)通过竞争性自适应重加权采样算法, 提取绿豆光谱曲线的重要特征波数, 从籽粒和粉末状态原始2 114个波数中, 分别优化为61个和107个特征波数, 波段总数目减少了94.94%以上, 并将其作为绿豆产地识别的特征指标。 (3)创新性提出了MSC-CARS-BP绿豆产地检测模型, 以优选出的光谱特征波数为定量依据, 分别对绿豆籽粒和粉末进行产地检测, 预测集准确率为92.59%和98.63%, 相关系数均达到0.99以上。 该方法能够利用近红外光谱处理技术, 实现绿豆产地无损检测的目标, 为农产品产地自动快速溯源提供了技术支持和参考。
Origin is an important environmental factor affecting crop production, and tracing the origin is of great significance for food safety. The chemical analysis method is generally used in traditional agricultural product origin detection, and its operation is cumbersome, destructive and time-consuming. In this study, northern cold mung beans were used as the research object. Near-infrared spectral data of mung bean in two states of seed and powder were obtained in the main origins of high-quality for Baicheng, Dumeng and Tailai. A new nondestructive detecting method for mung bean origins were established by optimizing the NIR characteristic spectrum wavenumbers. Firstly, in the range of 10 105.37~4 078.655 cm-1 wavenumber with strong absorbance value, the raw spectral data of mung beans from different regions was preprocessed by using multivariate scattering correction (MSC) method to eliminate spectral interference information. Then competitive adaptive reweighted sampling(CARS) algorithm is applied to optimize the characteristic spectral wavenumbers of mung bean seed and powder states from different origins to reduce the feature vector dimension of the spectral curve. Finally, a feed-forward neural network (BP) adaptive inference mechanism was used to establish a non-linear mapping model between the origin of mung bean and its spectral characteristic wavenumber, and the encoding vector output by the network was parsed to the original name as the output result of the detection of the origin of the mung bean. The results show that: (1)Preprocessed with multiple scattering corrections in the raw spectral, the error of the spectral curve of mung bean powder is reduced from 12.87 to 3.20, and the error of the spectral curve of mung bean seed is reduced from 153.04 to 27.73, which provides effective and reliable spectral data. (2) Through the competitive adaptive reweighting sampling algorithm, the important characteristic wavenumbers of mung bean spectral curve are extracted. From the 2 114 original wavenumbers of seed and powder state, 61 and 107 characteristic wavenumbers are optimized respectively, and the total number of wavebands is reduced by 94.94%, which is taken as the characteristic index of mung bean origin recognition. (3) The MSC-CARS-BP mung bean origin detection model was put forward innovatively. Based on the optimized spectral characteristic wavenumber as the quantitative basis, the origin detection of mung bean seed and powder was carried out respectively. The accuracy of the prediction set was 92.59% and 98.63%, and the correlation coefficient was above 0.99. This method can use near-infrared spectrum processing technology to achieve the goal of non-destructive detecting of mung bean origin, and provide technical support and reference for automatic and rapid traceability of agricultural products origin.
产地是影响农作物生产的重要环境因素, 很大程度上决定了农产品的产量和质量, 农产品产地溯源对于粮食安全具有重要意义。 传统农产品产地检测一般采用化学分析法, 张协光等[1]基于EA-IRMS结合元素分析技术, 利用C稳定同位素对大米产地进行判别。 Opatic等[2]通过同位素组成联合矿物元素指纹, 溯源生菜的不同产地。 Martinec等[3]利用南瓜籽油中的微量元素, 实现了其产地的检测。 鹿保鑫等[4]应用矿物元素指纹图谱, 对黑龙江黄豆进行了产地溯源。 为避免传统检测方法普遍存在着操作繁琐且耗时长, 具有破坏性等不足, 诸多学者利用近红外光谱技术具有快速、 无损、 无污染等优势[5, 6], 来实现农产品产地检测, 并逐渐得到了广泛应用。 陈璐等[7]利用近红外光谱技术, 结合偏最小二乘判别分析法, 建立了金银花产地的检测方法。 Ren等[8]应用近红外光谱技术, 建立了红茶产地检测方法, 其准确率达到94.3%。 有报道应用近红外光谱技术, 结合MP波长选择方法, 实现了黑木耳产地的溯源模型。 钱丽丽等[9]筛选了不同产地大米的近红外光谱特征, 构建了多年际地理标志大米产地检测方法。 张智峰等[10]采用主成分分析和灰色关联分析, 提取苦荞近红外光谱波长特征, 建立苦荞产地的检测模型。 绿豆是我国重要杂粮之一, 具有较高的营养和药用价值, 产地是影响绿豆生长的重要环境因素, 因此不同产地绿豆的无损溯源尤其重要。 目前基于绿豆近红外光谱特征提取, 实现快速无损检测绿豆产地的研究鲜有报道。 本研究以东北寒地绿豆为研究对象, 分别在白城、 杜蒙、 泰来等优质绿豆主产区, 获取绿豆的籽粒和粉末两种状态的近红外光谱数据; 采用多元散射校正法(multiple scattering correction, MSC), 对绿豆原始光谱数据进行预处理; 应用竞争性自适应重加权采样算法(competitive adaptive reweighted sampling, CARS), 优选不同产地绿豆籽粒和粉末状态的光谱特征, 利用前馈神经网络(back propagation neural network, BP)自适应推理机制, 建立绿豆产地与其光谱特征之间映射模型, 实现绿豆产地无损检测的新方法, 为绿豆产地自动快速溯源提供技术支持。
试验样本在东北地区的白城、 杜蒙和泰来基地获取, 采样点的海拔分别为: 134~396, 115~164和146~179 m, 其土质包括山地、 沙土和黑土, 绿豆品种主要有大鹦哥绿、 农博九号、 东兴8号、 龙江9号、 白绿8号、 363号、 小明绿、 毛绿豆、 黄绿豆、 小鹦哥绿、 白绿11号、 绿丰5号、 绿丰2号等。 通过3点田间随机方式, 采集不同产地绿豆原始样本。 采用傅里叶变换近红外光谱仪(TensorⅡ 型)波数范围: 109 95.25~3 998.793 cm-1, 获取绿豆籽粒和粉末的近红外光谱数据时, 设定扫描次数: 64次, 分辨率: 8 cm-1, 环境温度为: (25± 1) ℃, 相对湿度为20%~30%。
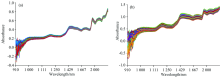
为获取不同产地绿豆的近红外光谱数据, 将试验样本与仪器置于具有相同环境参数。 实测数据时, 将光谱仪预热30 min, 并通过白平衡校正, 消除干扰信息, 进一步提高采集数据的可靠性。 试验采集461个绿豆样本, 其中绿豆粉末219个样本和绿豆籽粒242个样本。 按2∶ 1的比例划分样本集, 即绿豆粉末状态下, 校正集样本为146组(白城58组、 杜蒙58组和泰来30组), 预测集样本为73组(白城29组、 杜蒙29组和泰来15组)。 绿豆籽粒状态下, 校正集样本为161组(白城60组、 杜蒙58组和泰来43组), 预测集样本81组(白城30组、 杜蒙29组、 泰来22组)。 粉末和籽粒状态下, 不同产地绿豆样本的近红外光谱数据, 如图1(a, b)所示。
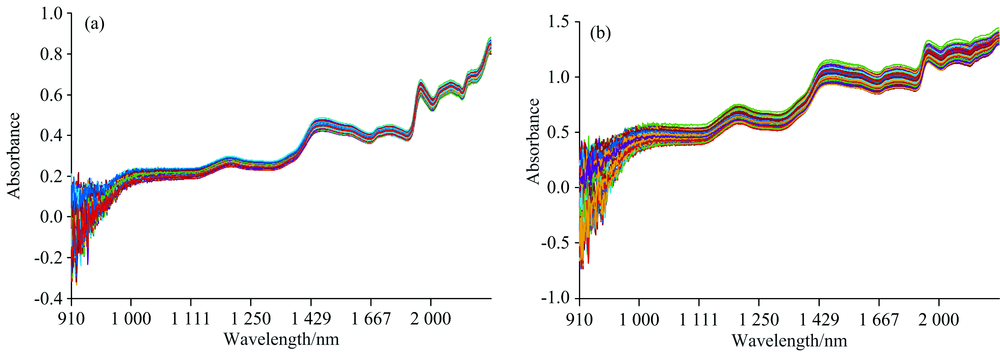 | 图1 两种状态的绿豆样本近红外光谱 (a): 绿豆粉末近红外光谱; (b): 绿豆籽粒近红外光谱Fig.1 Near-infrared spectra of mung bean samples in two states (a): Near infrared spectra of mung bean powder; (b): Near infrared spectra of mung bean seed |
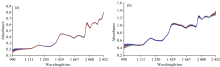
考虑光谱曲线两端存在着较大噪音, 选取NIR波数范围为10 105.37~4 078.655 cm-1。 绿豆粉末和籽粒颗粒大小不同, 极易产生散射等情况, 研究中采用多元散射校正方法(MSC), 对原始光谱数据进行预处理, 以消除由于待测对象存在颗粒分布不均匀, 而产生的光谱散射等干扰信息。 采用多元散射校正法分别对绿豆粉末和籽粒两种状态进行预处理, 对绿豆原始光谱数据(RAW)进行多元散射校正预处理后, 绿豆光谱曲线(MSC-RAW)的效果如图2所示。
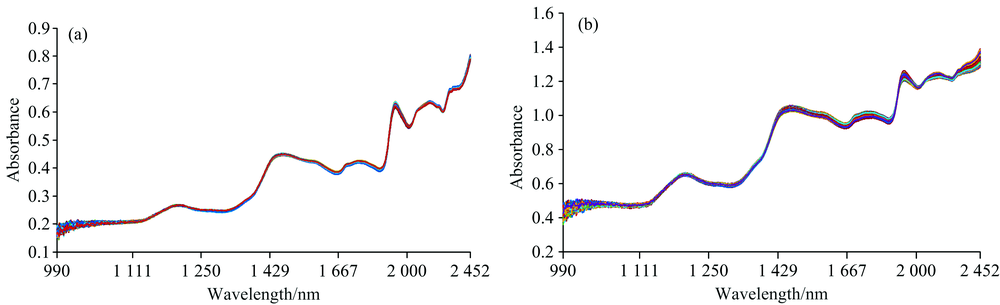 | 图2 绿豆近光谱数据的MSC预处理结果 (a): 绿豆粉末; (b): 绿豆籽粒Fig.2 MSC preprocessing results of mung bean near-spectrum data (a): Mung bean powder; (b): Mung bean seeds |
图2中绿豆粉末和籽粒两种状态, 通过多元散射校正对光谱2 114个波数曲线预处理后, 原光谱多元散射校正曲线的平均值分别为0.368 0和0.824 5。 经过MSC预处理后的光谱, 相对原始光谱均减小了噪声和散射的干扰, 提高了近红外光谱的分辨率, 为后续光谱曲线的特性分析提供了基础。 在显著性检验中绿豆粉末光谱曲线的误差从12.87降到3.20, 绿豆籽粒光谱曲线的误差从153.04降到27.73, 二者显著性检验的假设概率P-value均趋近于0, 因此减少了由于绿豆颗粒分布不均匀而产生的噪声影响, 为不同产地绿豆的光谱特性分析, 提供真实可靠的数据源。
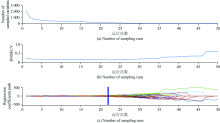
由于绿豆粉末和籽粒两种状态的光谱变量较多, 为构建快速高效的绿豆产地检测模型, 优选出反映产地信息的主要波数, 代替MSC处理后光谱曲线的数千个波数, 作为绿豆产地判定的有效依据。 采用竞争性自适应重加权采样算法(CARS)[11], 计算绿豆粉末状态的光谱变量数、 内部交叉验证RMSECV值、 以及每个变量回归系数, 其变化过程如图3所示。
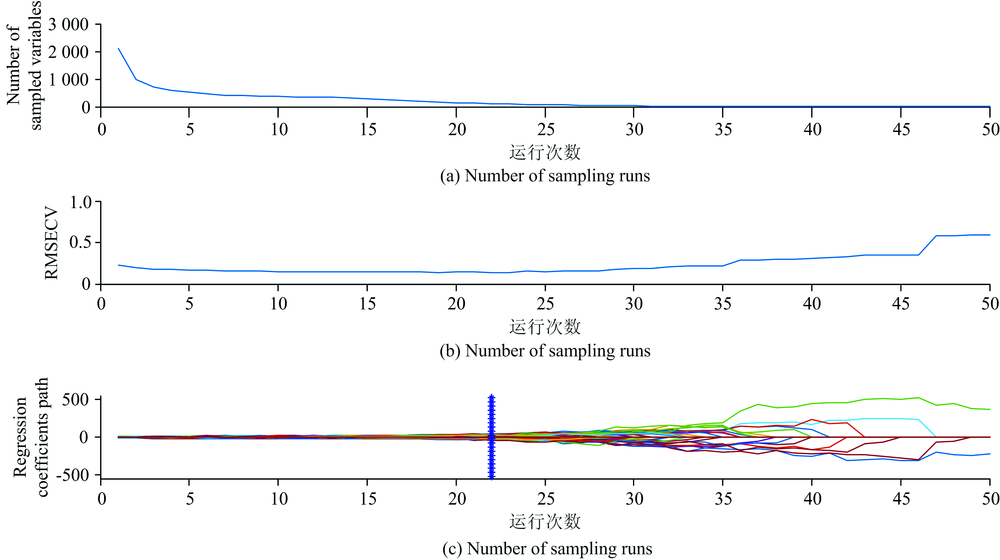 | 图3 绿豆粉末CARS算法指标参数Fig.3 CARS algorithm index parameters of mung bean powder |
图3(a)中绿豆粉末状态光谱有效变量数逐步减少, 随着采样次数增加逐渐平稳; 图3(b)中对应RMSECV值反映了选择的光谱特征波数, 所构建回归模型的预测误差变化趋势; 图3(c)中每条曲线代表每个波数变量回归系数的变化趋势, 其中* 号代表具有最小RMSECV值的最优变量子集的位置, 之后RMSECV值开始上升, 表示一些有效光谱变量被删除, 而导致产地识别的回归模型精度变差。 当蒙特卡罗采样次数为22次时, 图3(b)中的RMSECV值达到最小值0.139 5, 此时筛选出的光谱特征波数, 共包含107个变量, 将其作为绿豆粉末状态时, 绿豆产地识别的有效依据。
同样将绿豆籽粒的MSC预处理光谱变量, 进行上述计算, 其光谱变量数、 内部交叉验证RMSECV值、 以及每个变量回归系数, 其变化过程分别如图4(a, b, c)所示。
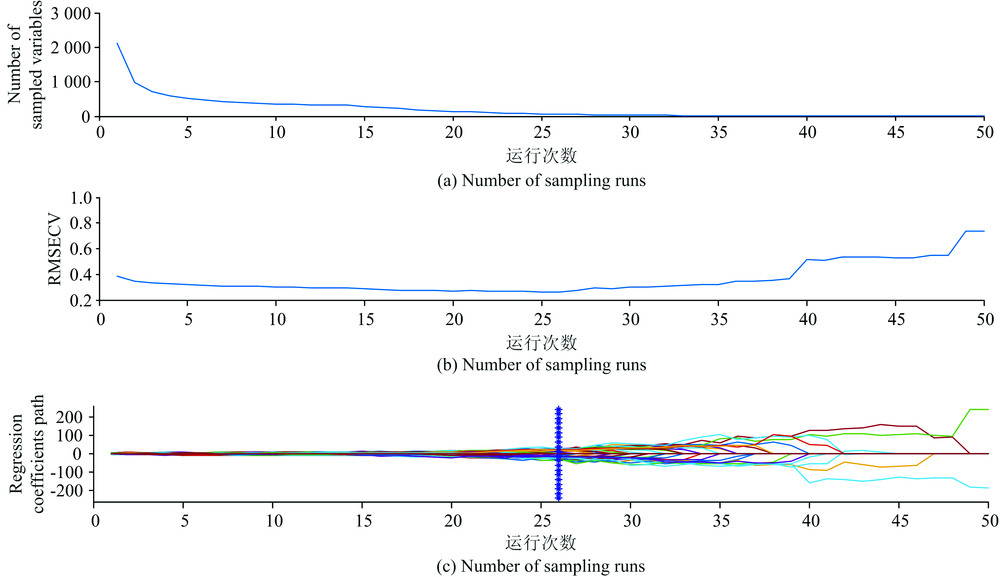 | 图4 绿豆籽粒CARS算法指标参数Fig.4 CARS algorithm index parameters of mung bean seeds |
图4中绿豆籽粒状光谱有效变量数、 内部交叉验证RMSECV值、 以及变量回归系数的变化趋势, 均与绿豆粉末状时发展趋势相一致。 当蒙特卡罗采样次数为26次时, 图4(b)中的RMSECV值达到最小值0.262 4, 此时筛选出的光谱特征波数, 共包含61个变量, 将其作为绿豆籽粒状态时, 绿豆产地识别的有效依据。
2.3.1 神经网络模型结构
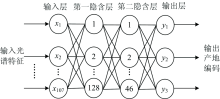
由于神经网络具有自适应归纳推理的机制, 并可以任意精度逼近一个复杂的非线性函数, 能够解决绿豆产地与光谱特征波长之间存在着映射关系。 构建绿豆粉末检测产地的模型关键是网络结构和参数的确定, 依据文献[12]建立由输入层, 隐含层和输出层构成的BP神经网络, 其中隐含层的神经元为双曲正切函数, 输入层为优选出的绿豆光谱特征波数, 输出层为绿豆产地编码。 由于绿豆粉末状态时, 筛选光谱特征波数为107个变量, 所以神经网络输入层为107个节点; 输出为白城(001)、 杜蒙(010)、 泰来(100)3个绿豆产地编码, 因此输出层为3个节点; 根据Kolmogorov定理和实际试验, 确定第一隐含层和第二隐含层分别为128个和46个神经元, 网络结构为107-128-46-3型, 具体如图5所示。
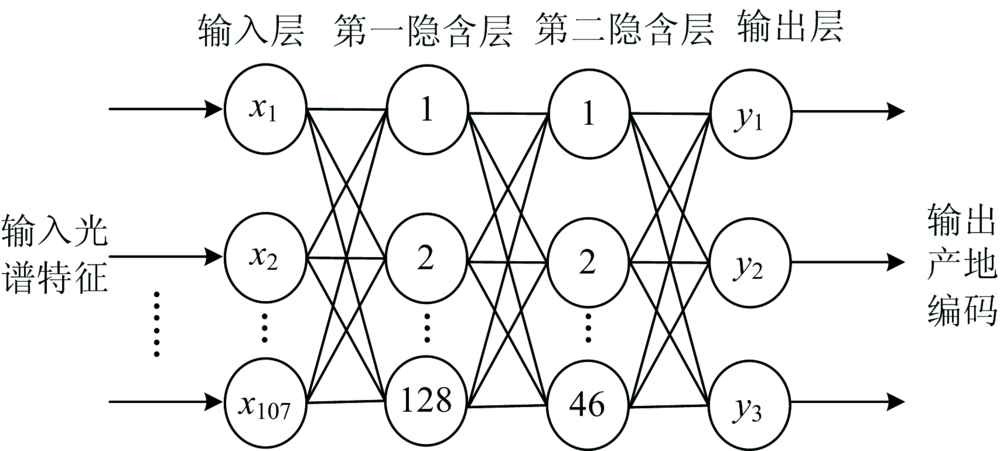 | 图5 绿豆粉末神经网络的拓扑结构Fig.5 Topology diagram of mung bean powder neural network |
由于绿豆籽粒状态时, 筛选光谱特征波数为61个变量, 同理构建具有3个隐含层的神经网络结构61-138-46-50-3型, 作为绿豆籽粒状态的产地检测模型。
2.3.2 绿豆产地检测模型应用及结果分析
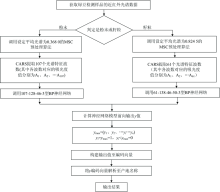
在网络实际训练时, 设定目标精度为0.001, 惯性系数α =0.6, 学习速度η =0.8, 最大学习次数为300 000。 采用梯度下降法训练神经网络, 以确定绿豆粉末和籽粒两种状态的产地检测模型具体参数。 利用训练好的神经网络模型, 构建的绿豆产地无损检测模型。 绿豆产地无损检测模型的具体流程, 如图6所示。
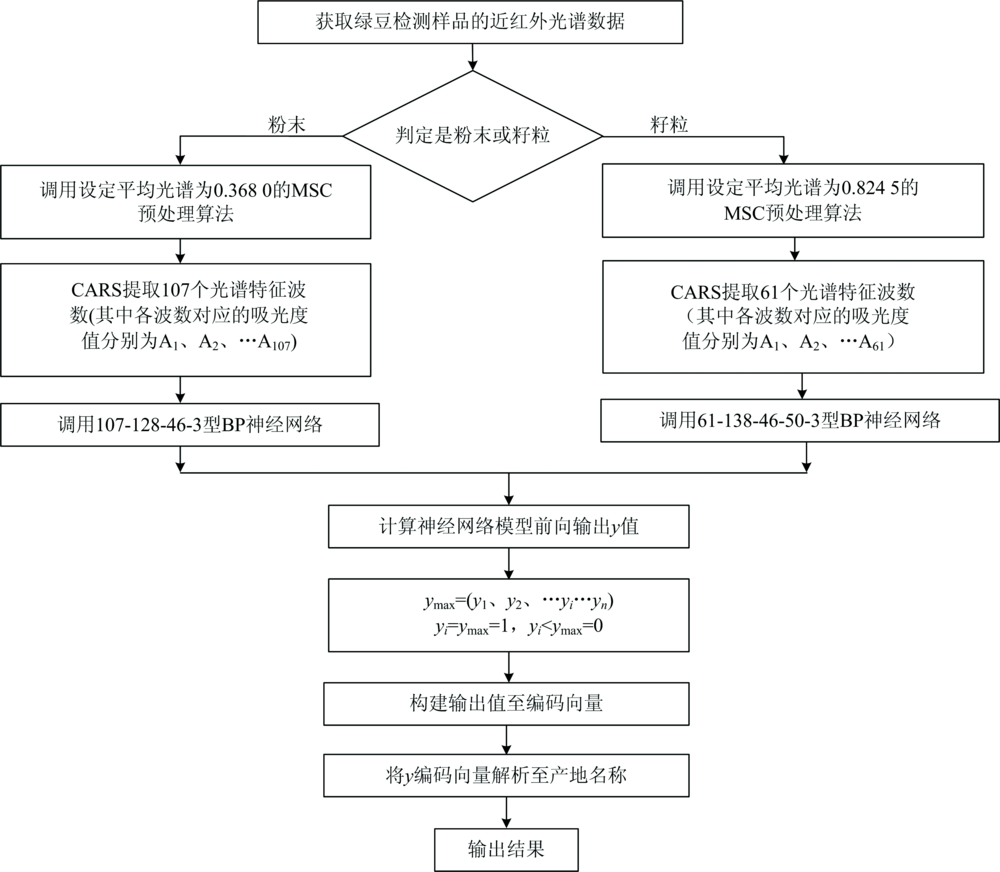 | 图6 绿豆产地无损检测模型流程图Fig.6 Flow chart of non-destructive testing model of mung bean origin |
图6中首先获取绿豆两种状态的近红外光谱数据, 根据绿豆状态, 选择多元散射校正法(MSC)预处理原始光谱数据; 利用绿豆粉末或籽粒状态下的光谱波数特征数据, 调用对应神经网络检测模型, 计算网络模型前向输出y值; 通过比较网络输出的最大值, 构建输出值至编码向量, 并将网络输出的编码向量解析至产地名称, 作为绿豆产地检测的输出结果。
仿真实验中绿豆粉末219个样本, 校正集样本为146组, 预测集样本为73组; 绿豆籽粒242个样本, 校正集样本为161组, 预测集样本81组。 在绿豆粉末和籽粒状态下, 应用RAW-BP, MSC-BP和MSC-CARS-BP模型, 分别对绿豆产地进行检测, 比较3种产地检测模型性能, 其结果如表1所示。
| 表1 绿豆产地检测模型仿真结果 Table 1 Simulation results of mung bean origin detection model |
从表1中可以看出, 对于绿豆粉末状态, 从原始光谱2 114个波数中优选107个NIR光谱波数, 光谱波数减少了94.94%; MSC-CARS-BP模型的识别精度为98.63%, 优于RAW-BP模型和MSC-BP模型的识别精度94.52%和76.71%, 其均方误差和相关系数分别为0.001 0和0.997 8。 对绿豆籽粒状态下的优选61个NIR光谱波数, 光谱波数减少了97.11%; 此时MSC-CARS-BP模型的识别精度为92.59%, 同样优于RAW-BP模型和MSC-BP模型的识别精度90.12%和88.89%, 其均方误差为0.001 0, 相关系数仍为0.997 8。 绿豆粉末和籽粒状态下, 绿豆产地检测模型RAW-BP模型和MSC-CARS-BP模型的准确率均能达到90%以上, 其中MSC-CARS-BP模型性能最好, 识别错误率仅为1.37%和7.41%, 是一种绿豆产地检测的有效方法。
以北方寒地绿豆为研究对象, 通过研究不同产地绿豆的籽粒和粉末两种状态的近红外光谱数据, 提出一种基于优选NIR光谱波数的绿豆产地无损检测的新方法。 主要结论如下:
(1)采集东北三省境内中的白城、 杜蒙、 泰来等地绿豆籽粒和粉末两种状态的光谱数据, 在多元散射校正预处理的基础上, 通过竞争性自适应重加权采样算法, 在绿豆两种状态的原始光谱波数中, 提取出61个和107个特征波数, 原始光谱波数优减了94.94%以上, 为绿豆产地有效检测提供了简单可靠的特征依据。
(2)应用提出的MSC-CARS-BP模型, 以优选的绿豆籽粒和粉末的特征波数为输入变量, 利用神经网络自适应的归纳推理规则, 分别对绿豆籽粒和粉末进行产地检测, 预测集准确率分别为92.59%和98.63%, 相关系数均达到0.99以上, 实现了绿豆产地快速无损检测的新方法。
该方法极大程度简化了原光谱建模规模, 避免了传统农产品产地检测操作繁琐且存在破坏性及耗时长等不足, 实现了一种绿豆产地自动、 快速、 无损检测的目标, 为农产品产地自动快速溯源提供技术支持。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|