{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于t-SNE的恒星光谱降维与分类研究
[姜斌 , 赵梓良, 王淑婷, 韦纪宇, 曲美霞
, 赵梓良, 王淑婷, 韦纪宇, 曲美霞* ]
, 赵梓良, 王淑婷, 韦纪宇, 曲美霞]
|
|


作者简介: 姜 斌, 1977年生, 山东大学机电与信息工程学院副教授 e-mail: jiangbin@sdu.edu.cn
随着天文学的发展以及天文望远镜观测能力的提升, 国内外许多大型巡天望远镜将产生PB级的恒星光谱数据。 恒星光谱是来自恒星的电磁辐射, 通常由连续谱与吸收线叠加而成, 其差异源于恒星的有效温度、 表面重力加速度以及元素的化学丰度等。 恒星光谱自动分类是天文数据处理的一项重要研究内容, 是研究恒星演化和参数测量的基础。 海量的恒星光谱对分类方法提出了高效、 准确的要求。 传统的人工分类方法存在速度慢、 精度低等缺点, 已经无法满足海量恒星光谱特别是低信噪比恒星光谱自动分类的实际需要, 机器学习算法目前已经被广泛地应用于恒星光谱分类。 恒星光谱的一个显著特征是数据维度较高, 降维不但可以实现特征提取, 而且可以降低计算量, 是光谱分类的首要任务。 传统的线性降维方法如主成分分析仅依据方差对光谱进行降维, 不同类型的光谱在投影到低维特征空间后会出现交叉现象, 而流形学习能够产生优良的分类边界, 很好地避开重叠, 有利于后续的分类。 针对光谱数据维度较高的特点, 研究了光谱数据在高维空间内的分布以及流形学习对高维线性数据降维的原理, 比较了t-SNE和主成分分析两种降维方法对光谱数据降维的效果, 并使用基于属性值相关距离的改进的K近邻算法进行光谱分类, 最终对实验结果进行了分析并使用多种机器学习分类器进行比较和验证。 采用Python语言及Scikit-learn第三方库实现了算法, 对SDSS的12 000条低信噪比的恒星光谱进行实验, 最终实现了光谱数据的高精度自动处理和分类。 实验结果表明, 对于光谱数据的降维处理, 基于流形学习的t-SNE方法能够在高维光谱数据中恢复低维流形结构, 即找出高维空间中的低维流形, 并解出与之对应的嵌入映射, 在降维过程中最大程度地保留不同类别光谱样本之间的差异从而产生明显的分类边界。 特征提取后, 使用机器学习分类器能够在测试数据集上达到满意的分类准确率。 所使用的方法也可以应用于其他的巡天望远镜产生的海量光谱的自动分类以及稀少天体的数据挖掘。
With the development of astronomy and the improvement of telescope observation ability, many large sky survey telescopes have produced petabytes of stellar spectra. Stellar spectra are a kind of complex frequency domain signal, which is usually composed of continuous spectrum and absorption lines. The differences are mainly caused by the effective temperature, surface gravity acceleration and chemical abundance of elements of stars. The automatic classification of stellar spectra is an important part of astronomical data processing and the basis of studying stellar evolution and parameter measurement. The massive stellar spectra require efficient and accurate classification methods. The traditional manual classification methods have the disadvantages of low speed and accuracy, which cannot meet the actual needs of automatic classification of massive stellar spectra. Machine learning algorithms have been widely used in spectra classification. A significant feature of the stellar spectra is the high data dimension. Dimensionality reduction can not only achieve feature extraction, but also reduce the amount of computation, which is the primary task of spectra classification. The traditional linear dimensionality reduction method only reduces the spectra according to the variance, and different types of spectra will cross in the feature space, while manifold learning can produce good classification boundaries to avoid overlap, which is conducive to subsequent classification. In this paper, the distribution of spectra in high dimensional space and the principle of manifold learning to dimensionality reduction of high dimensional linear data are studied. The effects of two dimensionality reduction methods: t-SNE and principal component analysis were compared and the improved k-nearest neighbor algorithm based on the correlation distance of attribute values was used for spectra classification. Python and Scikit-learn were used to implement the algorithm. 12 000 low signal/noise stellar spectra from SDSS were tested and high precision automatic processing and classification of spectral data are realized finally. Experimental results show that the t-SNE method based on manifold learning can restore the low-dimensional manifold structure in high dimensional spectral data. The low-dimensional manifold features in high-dimensional spaces are found and the corresponding embedded mappings are solved. In the process of dimension reduction, the differences between spectral samples of different categories are preserved to the greatest extent. The three-dimensional visualization of the experimental results shows that PCA can lead to the crossover of the distribution of stellar spectra of different categories, while the t-SNE algorithm can produce more obvious category boundaries. The k-nearest neighbor algorithm based on attribute value correlation distance can achieve satisfactory classification accuracy on test data sets after feature extraction. The method used in this paper can also be applied to the automatic classification of massive spectra generated by other telescopes and data mining of rare objects.
随着天文光谱数据量呈指数级增加, 人工分类方法由于具有效率低、 在低信噪比数据上分类准确率较低等缺陷, 已经无法满足需要。 目前机器学习算法在天文光谱分类中得到广泛应用, 并取得了较好的效果。 Navarro等[1]利用人工神经网络对不同信噪比的光谱数据进行分类, 分类结果对低信噪比的光谱数据也具有高度的可信度; Kheirdastan等[2]使用概率神经网络作为大质量恒星光谱的自动分类工具, 得到了准确的光谱型分类结果。 此外, 利用熵学习机对恒星光谱数据进行分类, 分类结果也较为准确[3]: Chen等利用受限玻尔兹曼机[4]提高了光谱分类的效率。
光谱降维是准确分类的重要前提。 传统的降维方法如局部线性嵌入[5]以及线性判别分析[6]已被广泛应用到光谱降维并取得较好的效果。 自编码器[7]也已被广泛应用于数据的降维。
针对传统的主成分分析(principal component analysis, PCA)在低维空间内出现的交叉问题, 本文研究流形学习方法, 对光谱进行降维。 实验表明经流形学习算法t-SNE (t-distributed stochastic neighbor embedding)降维后的恒星光谱能够产生更加明显的分类边界, 并很少发生数据的重叠问题, 训练出的分类器具有更好的效果。
t-SNE[8]是一种基于SNE (随机邻接嵌入)的非线性降维算法, 适合将数据降维至2~3维从而利于可视化。 在SNE算法中, 首先构建一个高维对象间的概率分布, 使得类似的数据有更高的概率被选择, 而差异大的数据被选择的概率较低。 随后SNE在一个低维空间里再构建这些点的概率分布, 使得高维与低维空间的概率分布之间尽可能的相似。 SNE通过将数据点之间的高维欧式距离转换为表示数据间相似性的条件概率。 数据样本点xi、 xj之间的条件概率pj|i由式(1)给出
其中σ i是以数据点xi为中心的高斯方差。 对于高维数据点xi和xj的低维对应点yi和yj, 可以计算类似的条件概率qj|i
SNE的目标是最小化条件概率的差异。 为了计算条件概率差的最小值, SNE使用梯度下降法最小化KL距离。 然而, SNE的代价函数关注于映射中数据的局部结构, 该函数的优化难以实现, 因此需要在实现方式上加以改进。
t-SNE在低维空间中使用更注重长尾分布的t分布代替高斯分布表示两点之间的相似度, 对于相似度较大的点, t分布在低维空间中的距离稍小; 而对于低相似度的点, t分布在低维空间中的距离需要更远。 该分布能够有效处理数据中的离群点, 即异常数据, 以提高降维效果。
基于属性值相关距离的K近邻算法(feature correlation difference k-Nearest Neighbor, FCD-KNN)[9]是一种对于传统K近邻算法在距离函数上改进的算法。 算法首先用改进的距离函数计算待分类样本与已知类别的训练样本之间的距离, 再选取前K个最小距离, 拥有K个最小距离的样本称为邻近点, 根据类可信度确定待分类样本的种类。 算法更重视数据在统计上的相关性, 而不仅仅是衡量数据之间的欧式距离。
改进的距离函数为相关距离函数, 样本x1和x2的相关系数为
定义样本x1和x2之间的相关距离为
样本之间的相关距离越小, 两个样本间的相关性越大。
类可信度的定义为: Cr代表种类, Xtest为待分类样本, Xr为邻近点中属于Cr的样本, N为邻近点样本总数, Nr为邻近点中属于Cr的样本数量。 T(Cr, Xtest)为Xtest对Cr的类可信度, 表示为
属于Cr类的样本数越多, 且类可信度越小, 待分类样本被标为Cr类的可能性越大。 综上所述, 基于属性值相关距离的K近邻算法的算法步骤如下:
(1) 计算训练样本与测试样本间的相关距离;
(2) 设定合适的K值, 选择相关距离最小的K个训练样本, 计算属于不同类的邻近点数Nr;
(3) 计算出待分类样本与每一类的类可信度T(Cr, Xtest), 待分类样本的种类确定为拥有最小的类可信度的种类。
实验数据使用SDSS-DR14[10]中的A, F, M以及O四种类型的恒星光谱共12 000条(5< S/N< 10)。 归一化后分别采用PCA与t-SNE算法将其降至二维。
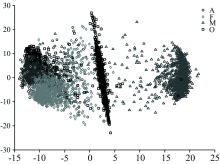
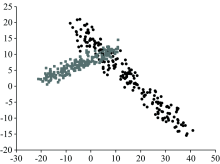
经过PCA降维后的数据在二维平面上的分布如图1所示: A类恒星与F类恒星存在较大的数据重合, 而O类与M类的数据具有较为明显的类别边界。
 | 图1 PCA降维后的数据分布Fig.1 Distribution of data after dimension reduction by PCA |
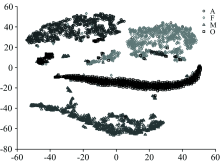
图2展示了经过t-SNE降至二维后的数据分布。 由于t-SNE基于流形学习, 降维后的数据被划分至不同的流形当中, 而PCA降维后的数据基本呈块状和线状。 更重要的是, 除了极少量的数据, 同类型的数据均能够聚集在一个区域, 不同类别数据之间具有明显的分类边界。
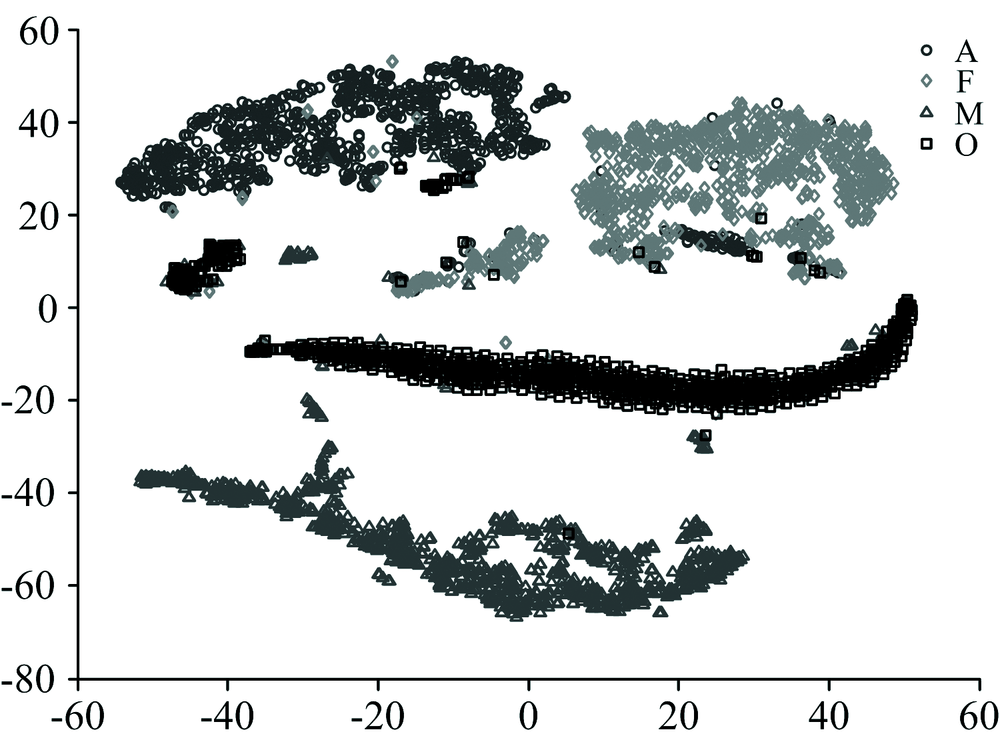 | 图2 t-SNE降维后的数据分布Fig.2 Distribution of data after dimension reduction by t-SNE |
对比图1和图2, 可以看出, 在将数据降至二维时, t-SNE能够产生更加鲁棒的分类边界, 为分类提供了更好的条件。
为了验证降维算法的有效性, 首先使用朴素的KNN算法以及FCD-KNN算法进行分类准确度的测试。 在多次实验后得到的分类准确率均值如表1所示。
| 表1 KNN和FCD-KNN算法的分类准确率结果 Table 1 Results of classification accuracy of KNN and FCD-KNN algorithms |
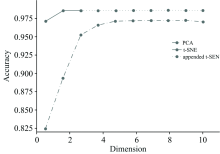
从表1可以看出, t-SNE在二维情况下的降维效果远超PCA, 而FCD-KNN算法在光谱数据的分类能力超过了传统的KNN算法。 图3描述了t-SNE将数据降至1~3维以及PCA将数据降至1~10维后使用FCD-KNN算法进行分类的准确率变化图。
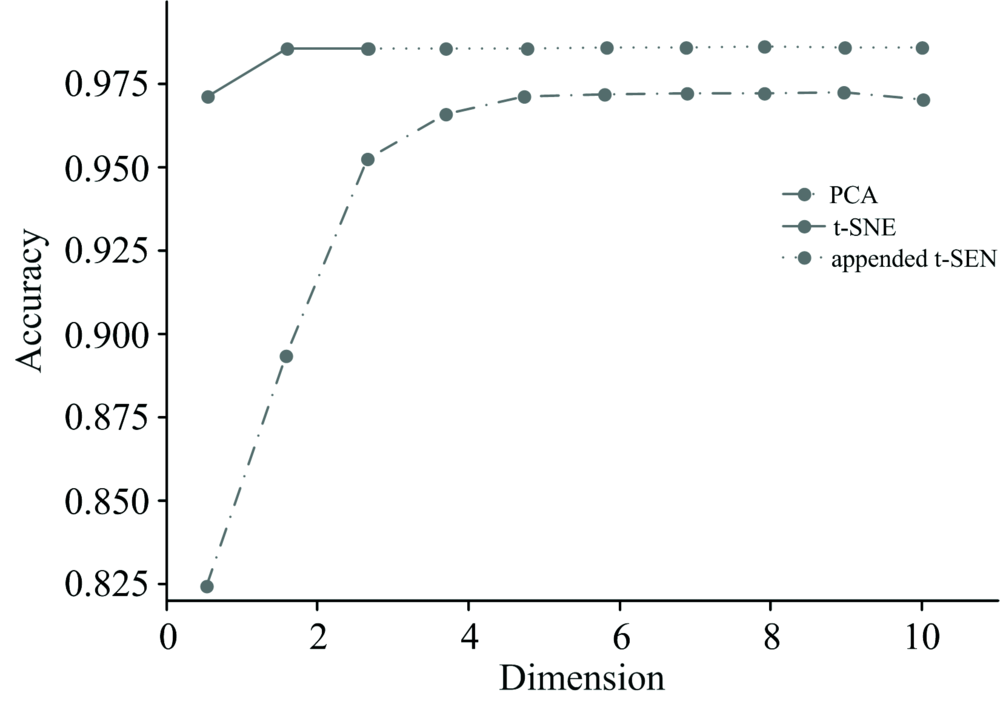 | 图3 PCA与t-SNE的降维效果比较Fig.3 Comparison of the dimensionality reduction effect of PCA and t-SNE |
可以看出, 当维数较低时, t-SNE降维后数据的分类准确率明显高于PCA降维后的结果。 随着维数的增加, PCA降维后数据的分类准确率也在逐渐增加, 随后达到了收敛, 并在第10维时出现了分类准确率下降的趋势, 这是因为PCA在提取出数据第10个主成分时, 光谱噪声开始被部分提取, 反而影响了分类准确率。 图3表明PCA能够达到的最高降维能力与t-SNE有较大差距。 实验结果表明, t-SNE与FCD-KNN算法的配合使用可以用于低信噪比恒星光谱分类并能够达到较高的分类准确率, 超过了传统方法。
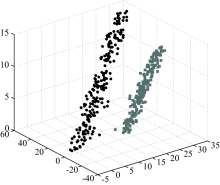
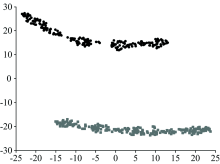
传统的降维算法PCA的思想是使数据在降维后保留最大化的方差, 而对于光谱数据, PCA的降维过程易产生数据重叠的问题。 图4和图5展示了三维数据在经PCA降至二维时产生的重叠现象。
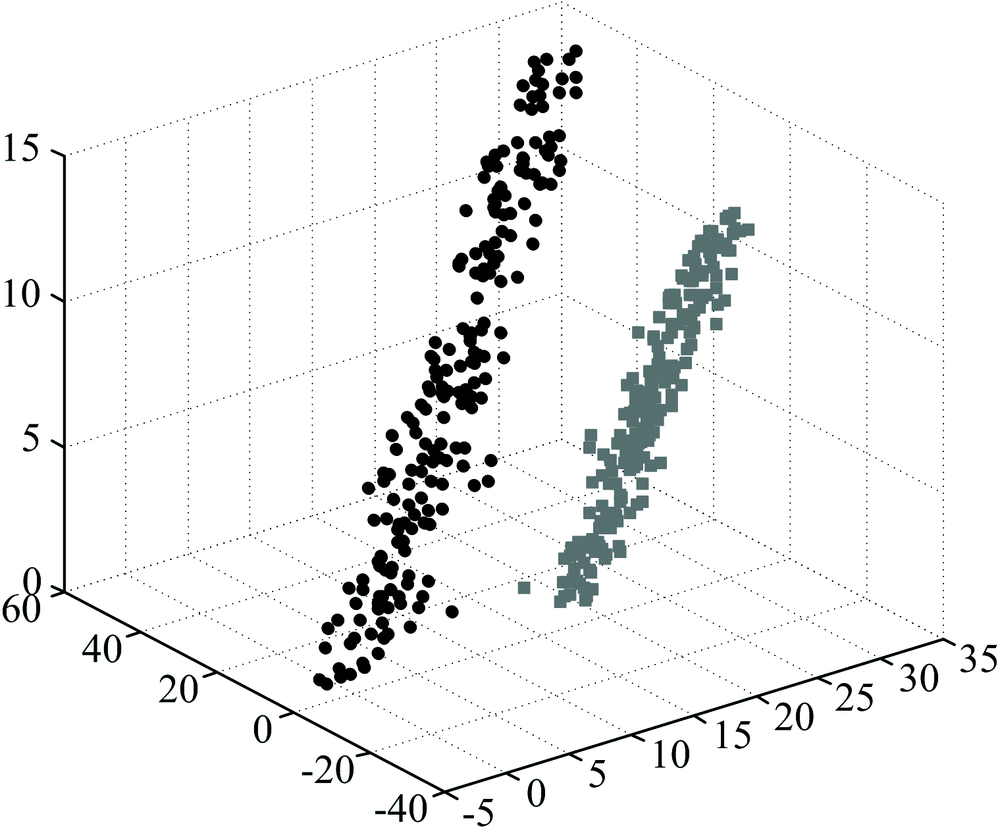 | 图4 假设的三维原始数据Fig.4 Hypothetical three-dimensional data |
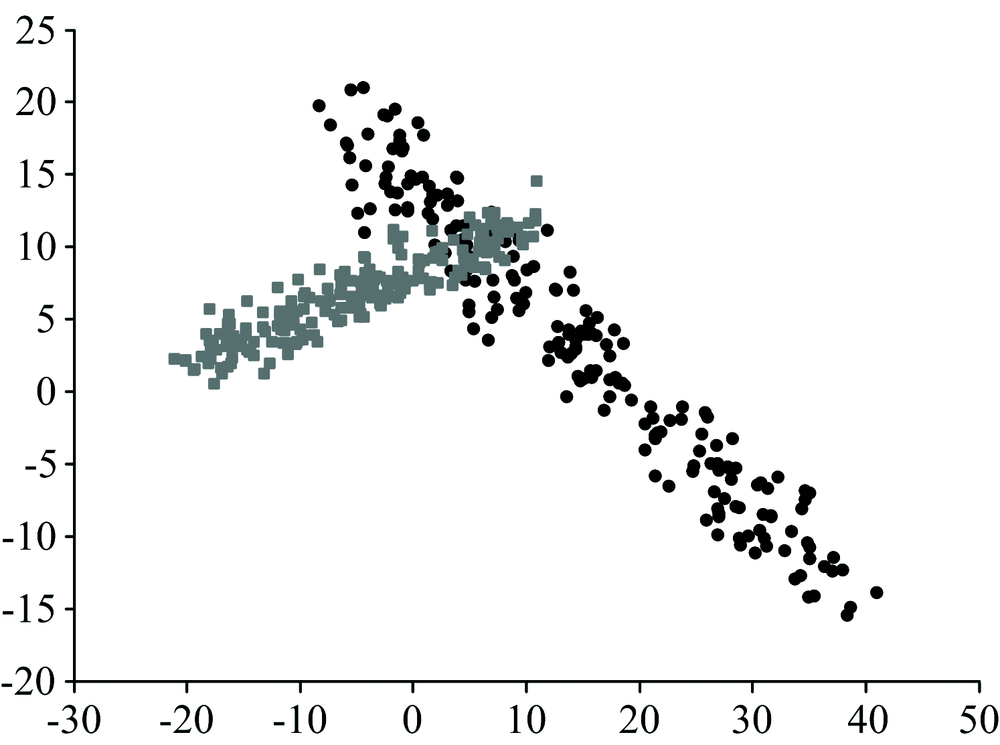 | 图5 PCA的交叠现象Fig.5 Overlapping phenomenon of PCA |
在t-SNE算法中, 该问题得到了很好的解决。 根据流形学习算法的基本思想, t-SNE能够有效抽取高维空间中的流形结构, 从而避免了数据在低维空间内的重叠。 图6为图4所示数据经t-SNE降维后的结果, 可以看出数据在降维后依然保持了其在高维空间的间距, 未发生重叠现象。
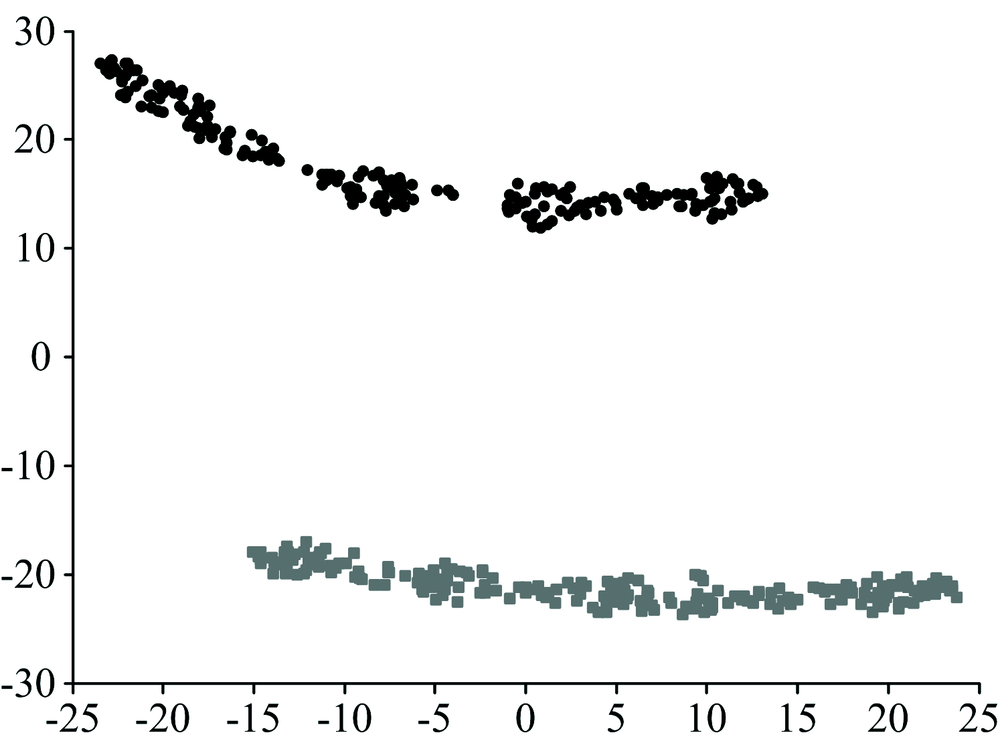 | 图6 t-SNE的降维结果无交叠现象Fig.6 Results of t-SNE show no overlapping phenomenon |
低信噪比恒星光谱分类是天文数据处理的重要研究内容。 本文分析了光谱数据在高维空间内的分布, 使用流形学习中的t-SNE方法对SDSS恒星光谱数据进行降维, 并使用FCD-KNN算法对光谱分类。 实验结果表明, t-SNE方法在低信噪比恒星光谱数据上的降维效果超过传统的PCA方法, 而FCD-KNN算法也比基于欧式距离的KNN算法有更好的表现。 本文提出的方法可以被直接应用于天体光谱分类, 且不仅局限于文中提到的恒星类型。 所使用的算法能够显著减少天文工作者的工作量, 具有一定的应用价值。 下一步的工作可以应用t-SNE算法对郭守敬望远镜(large sky area multi-object fiber spectroscopic telescope, LAMOST)[11, 12]最新发布的光谱数据进行降维后根据数据的分布寻找稀有天体, 如碳星、 激变变星等。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|