


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
深度信念网络的近红外光谱分析建模方法
[张萌 , 赵忠盖
, 赵忠盖* ]
, 赵忠盖]
|
|


作者简介: 张 萌, 1996年生, 江南大学自动化研究所轻工过程先进控制教育部重点实验室硕士研究生 e-mail: zhangmeng92@126.com
近红外光谱是一种快速、 无损的定量分析工具, 现如今已广泛的应用在各个行业中。 近红外光谱分析技术应用的关键就在于如何建立一个有效而又精确的模型。 目前常用的定量分析方法大多为浅层模型, 深度信念网络(DBN)是一种基于概率的深层模型, 可以自动学习输入的有效特征表示, 且只要设置最后隐层输出节点数低于输入光谱维度, 在对光谱数据完成特征提取的同时即可实现降维。 对于近红外光谱样本量大、 变量多、 维度高等问题, 提出一种基于深度信念网络的近红外光谱建模方法, 定量分析物性浓度。 该方法以近红外光谱数据作为输入信号, 首先对多层受限玻尔兹曼机(RBM)进行无监督学习, 实现光谱自身特征的提取; 然后利用目标理化值对网络进行微调得到最优模型参数。 在建立DBN校正模型的基础下对其进行改进, 建立DBN-PLS校正模型。 通过建立DBN近红外光谱校正模型、 DBN-PLS近红外光谱校正模型, 验证了DBN建模和DBN-PLS建模的可行性, 并引入决定系数( R2)和均方误差(MSE)两个模型评价指标, 对比分析了传统BP建模和DBN建模的精度。 分析结果表明, 相较于传统定量分析方法建模, 利用DBN方法建模和DBN-PLS方法建模可以提高预测精度。
Near infrared NIR spectroscopy is a fast, non-destructive quantitative analysis tool that has been widely used in various industries. How to build an effective and accurate model is of importance to the application of NIR spectroscopy. At present, most commonly used quantitative analysis methods are based on shallow models, while Deep Belief Network (DBN) is a probability-based deep model. It can automatically learn the effective feature representation of the input, and as long as the number of last hidden layer output nodes is lower than the dimension of the input spectrum, the spectral data can be reduced in dimension while the feature extraction is completed on the spectral data. Near-infrared spectroscopy is characterized by a large sample size, large variables, and high dimensionality. This paper proposes a near-infrared spectroscopy modeling method based on a deep belief network to estimate the physical concentration. The method uses near-infrared spectroscopy data as the input layer. Firstly, unsupervised learning of the multi-restricted Boltzmenn Machines (RBM) is employed to achieve the feature extraction of the spectrum itself. Then the target physicochemical value is used to fine tune the network, and optimize model parameters. Based on the DBN calibration model, the final regression layer of the deep belief network is developed by the PLS method, and the DBN-PLS calibration model may avoid the optimal local problem caused by the gradient descent algorithm. In this paper, the feasibility of DBN modeling and DBN-PLS modeling is verified by two model evaluation indexes including decision coefficient ( R2) and mean square error (mse), and the traditional BP modeling and DBN modeling are compared and analyzed. The analysis results show thatDBN method modeling and DBN-PLS method modeling can improve the prediction accuracy.
近红外光的本质是一种电磁波, 一般定义780~2 526 nm区间内的波段为近红外光谱区, 近红外光谱主要是由有机物质吸收光后分子振动从基态向高能级跃迁时产生的, 反映了含氢集团X— H(X主要为C, N和O等)基频振动的倍频和合频信息[1]。 而应用近红外光谱分析技术的关键就在于如何建立准确有效的模型[2]。
在近红外光谱分析中, 目前常用的模型建立方法有多元线性回归法[3](multiple linear regression, MLR)、 主成分回归[4](principle component regression, PCA)、 偏最小二乘法(partial least squares, PLS)[5]、 人工神经网络[6](artificial neural networks, ANN)和支持向量机法(support vector machine, SVM)[7]。 PLS是目前近红外光谱分析中应用最广泛的建模方法之一, 它从自变量矩阵和因变量矩阵中提取主成分, 有效降维, 并消除自变量间可能存在的复共线性关系[5]。 但PLS无法准确拟合非线性关系。 人工神经网络是目前应用广泛的非线性建模方法, 其中反向传播(BP)算法是目前使用最多的神经网络算法之一[6], 但BP网络算法易陷入局部最优, 收敛速度慢。 支持向量机是一种基于统计学理论的机器学习方法, 它有较好的泛化能力并且能避免模型陷入局部最优[7], 现在也越来越多的应用在近红外光谱分析建模。 但SVM没有准确的选用标准, 而且无法从给定的输入空间中选择有效特征用于建模。
深度信念网络是一种具有多个隐藏层的多层感知器, 它可以学习深层结构实现复杂函数的逼近, 从大量输入数据中学习有效的特征表示[8]。 应用深度信念网络(deep belief network, DBN)建模的优点是: (1)深度网络具有复杂的多层结构, 具有很好的表示能量, 对于大数据的处理尤其有效; (2)DBN通过逐层预训练初始优化网络参数, 可以避免由于随机初始化参数而导致模型陷入局部最优; (3)DBN可以从输入空间中自动学习有效的特征表示。 Shang等[9]在2014年就应用DBN网络对原油蒸馏装置建立软测量传感器模型; 王宇红等[10]将DBN与极限学习机(ELM)结合建立软测量模型; Wang等[11]应用DBN对拉萨地区的太阳辐射进行估算。
考虑到近红外光谱内部波长之间的相关性, 以及其与目标值之间的非线性关系, 提出利用深度信念网络对近红外光谱建模。 该方法不需要关于光谱数据的先验知识就可以实现对光谱自身的特征提取, 且只要设置顶层隐层节点数小于输入光谱的维度, 在实现光谱数据特征提取的同时也实现了降维。 将其应用在近红外光谱数据中, 通过验证相关系数R2、 均方误差MSE指标, 对比说明DBN模型和DBN-PLS模型预测的结果优于BP方法建模。
选用两个数据集验证本方法。 第一个数据集为从Tecator Infratec食品和饲料分析仪上收集的猪碎肉近红外透射光谱。 波长范围为850~1 050 nm, 分辨率为2 cm-1。 共包含172个校验集光谱, 43个验证集光谱。 第二个数据集为布鲁克MATRIX-F型傅里叶近红外光谱仪(OPUS分析软件包, 德国Bruker公司)采集的柠檬酸发酵液近红外光谱, 分辨率为16 cm-1, 波长范围为3 996~11 988 nm。 采用Kennard-Stone法对260个样品按2:1划分校验集和验证集, 得到174个校验集光谱和86个验证集光谱。 Kennard-Stone法的原理是根据变量之间的欧式距离, 在样品光谱的特征空间里选择距离最大的样品作为校验集样品[17]。
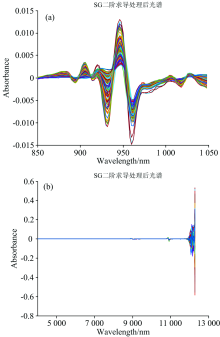
为去除来自高频随机噪声、 基线漂移、 光散射等影响, 需对光谱进行预处理。 平滑是光谱信号处理中改善信噪比最常用的方法[6]。 采用了Savitzky-Golay卷积平滑法对光谱预处理, 经过预处理的近红外光谱如图1。
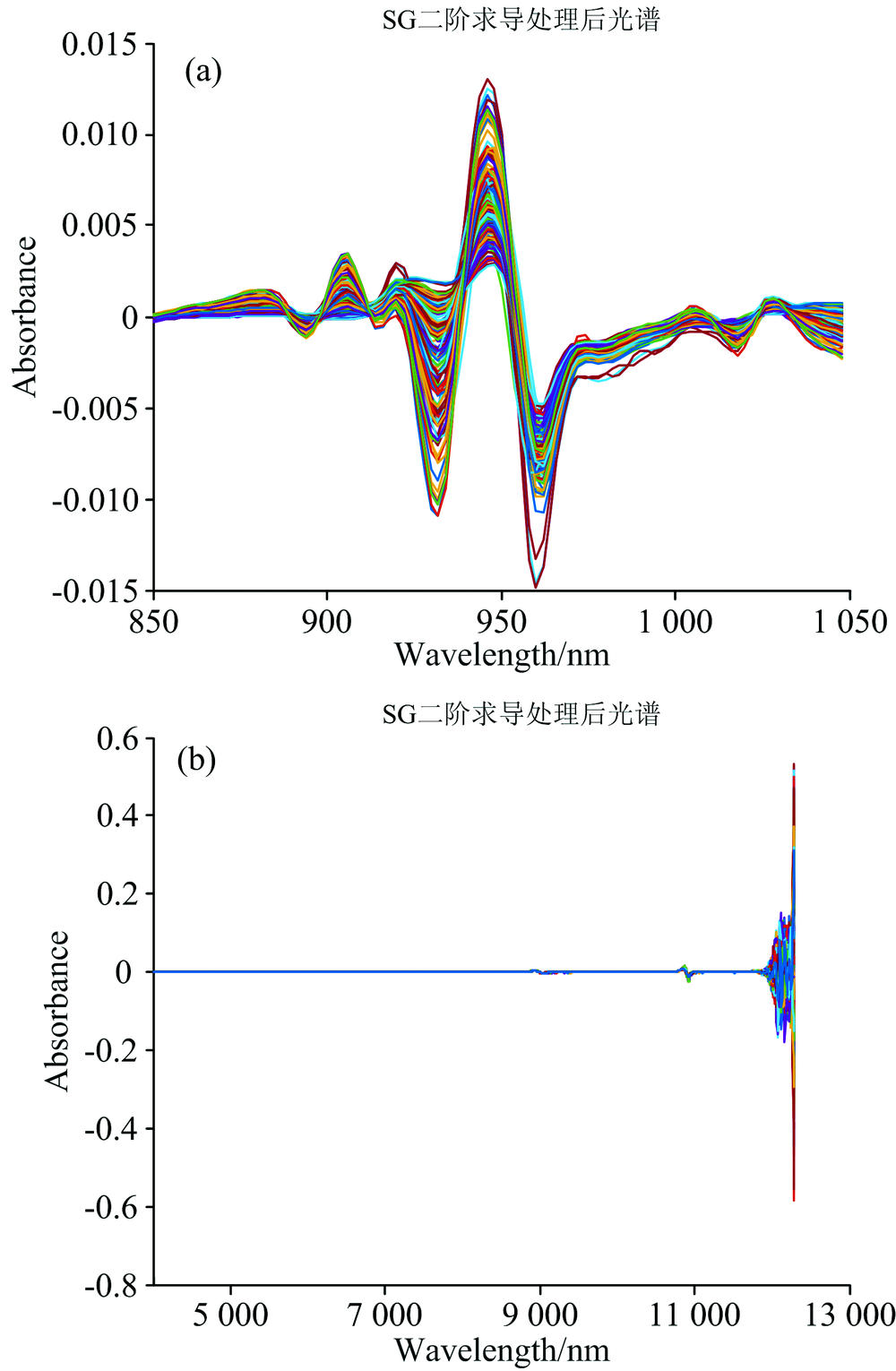 | 图1 预处理后的光谱图 (a): 猪肉; (b): 柠檬酸发酵液Fig.1 Preprocessed near infrared spectra (a): Pork; (b): Citric acid fermentation liquid |
1.2.1 基于深度信念网络的建模
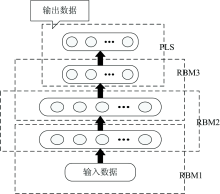
DBN是深度学习的生成模型之一, 由多层受限玻尔兹曼机(restricted Boltzmenn machines, RBM)堆叠而成[12], 结构如图2所示。 基于DBN的近红外光谱建模首先输入光谱数据, 对RBM进行逐层预训练, 完成对光谱数据进行特征提取和降维, 得到RBM的初始权值; 然后, 利用目标理化值对初始权值进行反向微调, 得到最终优化权值; 最后, 添加回归层, 即可完成近红外光谱的预测建模。 该算法的流程图如图3。
 | 图2 (a)RBM结构图; (b)DBN结构图Fig.2 (a) Diagram of RBM structure; (b) diagram of DBN structure |
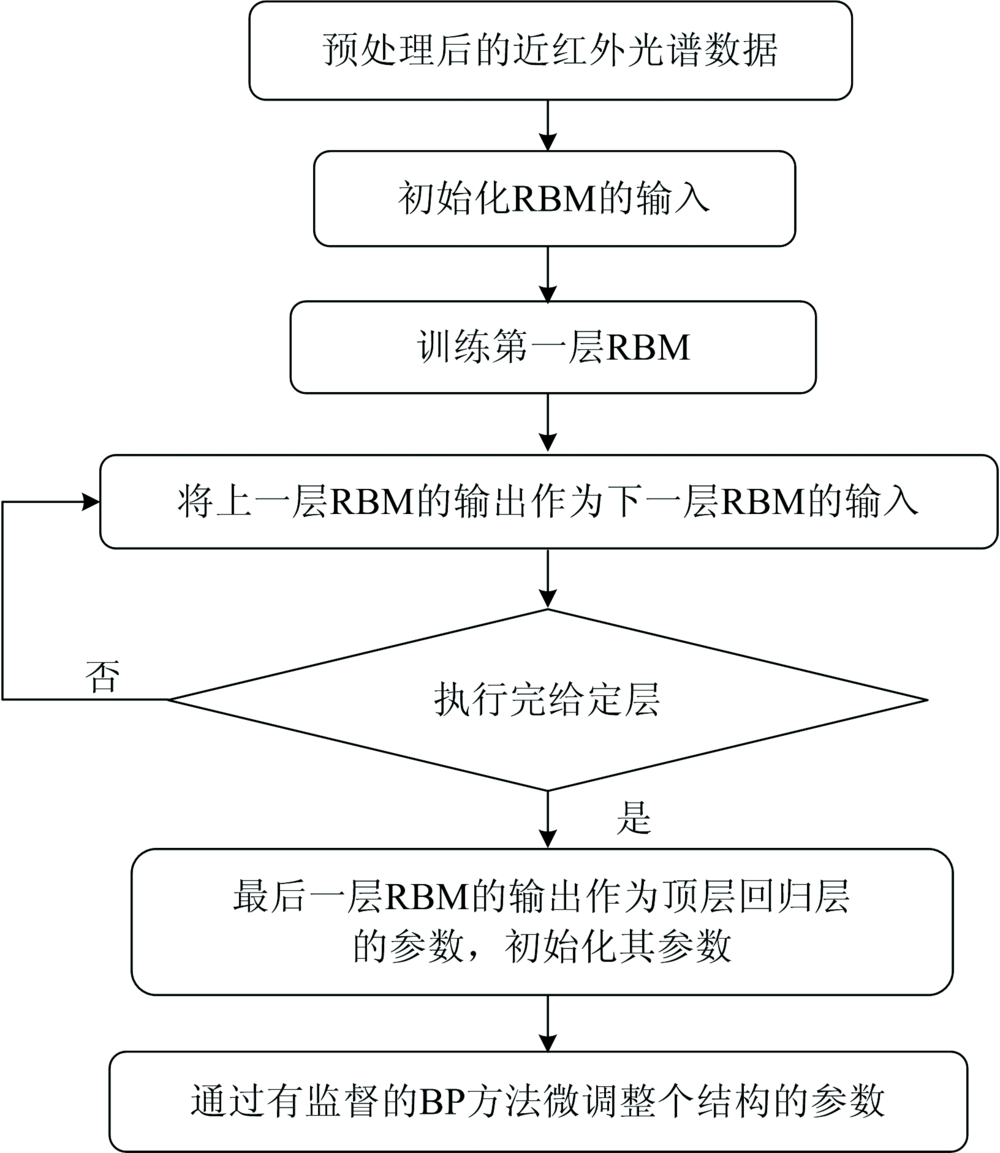 | 图3 DBN预测模型算法流程图Fig.3 Flow chart of DBN prediction model algorithm |
光谱吸光度X与目标理化值Y的配对组合表示为{(X1, Y1), (X2, Y2), …, (Xn, Yn)}。 将光谱吸光度X作为第一层RBM的输入层。 根据图2(a)所示, RBM结构包含一个可视层(v)和一个隐含层(h)[13], 可视层用于表示输入光谱数据信息, 隐含层表示对输入光谱的学习能力。 对于给定的状态(v, h), RBM作为一个系统所具备的能量定义为
式(1)中, θ 为模型参数。
可视层和隐含层的联合概率为
其中
P(v, h)对v的边缘分布为
可以计算出第j个隐层单元和第i个可视层单元的条件概率分布分别为
训练一个RBM即调整参数θ , 使其更好地拟合给定的训练样本[13]。 最大化以下似然函数
一般采用梯度法对其求偏导, 但式中
其中, ε 表示学习率。
在完成对RBM的逐层预训练之后, 利用目标理化值Y通过梯度下降算法最小化目标损耗函数
1.2.2 改进的深度信念网络建模
在深度学习的过程中, 无监督过程可以提取输入样本的隐变量, 监督过程通过BP算法对整个网络进行参数微调。 然而基于梯度的优化算法也会陷入局部最优, 将DBN与PLS结合可以避免由于梯度下降算法带来的问题。 DBN最后一层隐含层是对原始输入样本的若干次学习后得到的深层特征, 这一特征之间不存在相关性, 符合PLS模型对自变量的要求。 因此, 考虑将PLS运用到DBN的训练过程中, 对DBN进行改进, 提高模型的预测效果。
DBN-PLS模型结构图如图4。 运用DBN-PLS对近红外光谱建模的具体步骤如下:
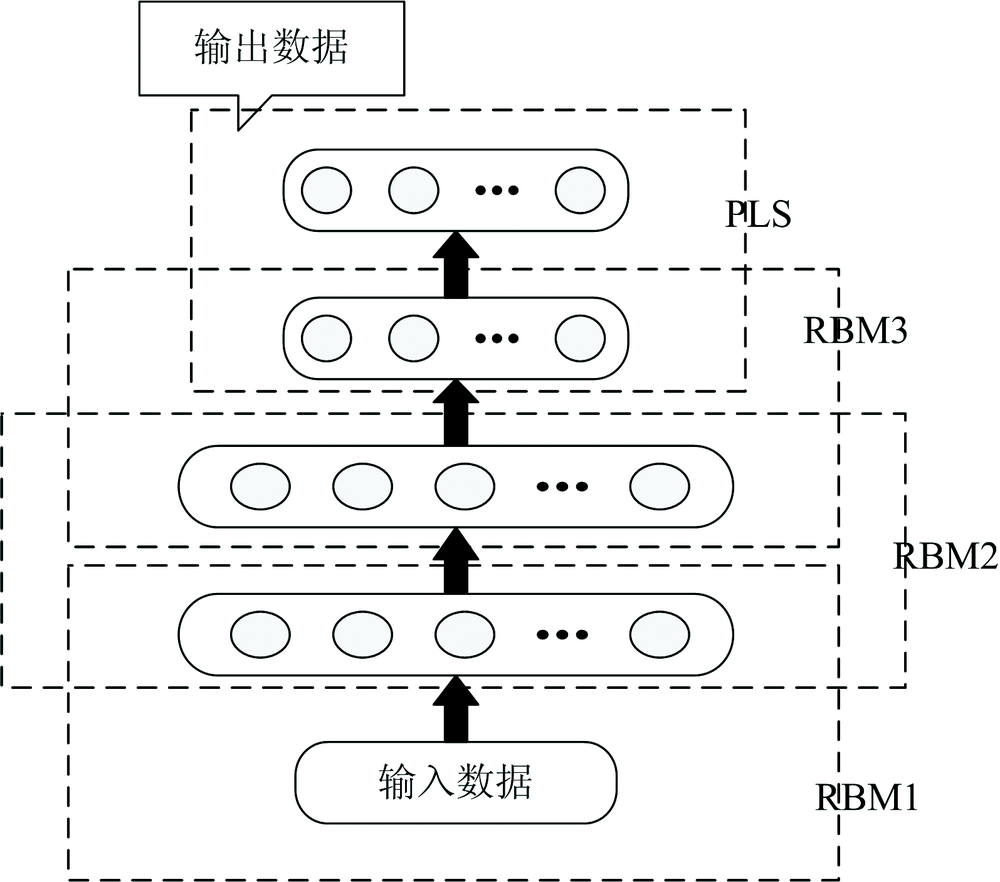 | 图4 DBN-PLS模型结构图Fig.4 Diagram of DBN-PLS model |
(1)对近红外光谱数据进行预处理;
(2)构建近红外光谱的DBN模型, 完成近红外光谱的特征提取和降维;
(3)将提取的有效特征输入PLS模型, 建立DBN-PLS预测模型;
(4)将验证集数据输入到DBN-PLS模型中, 进行验证。
为验证模型预测的准确性, 本文选用决定系数(R2)和均方误差(MSE)两个评价指标对模型进行评价。 R2表示真实值和预测值的相关程度。 MSE可以评价数据的变化程度, MSE的值越小说明预测模型有越好的精确度[16]。
其中,
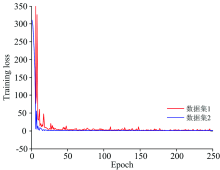
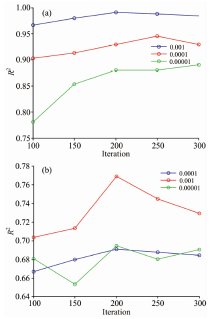
模型参数选择是影响DBN模型特征提取能力以及模型预测精度的重要因素。 本文影响结果的参数主要有RBM层数、 迭代次数(iteration)和学习率(learining rate)。 随着模型层数的增加, 层间连接权值增加, 训练难度也会增加, 设置了2层RBM结构。 图5为不同迭代次数下整个网络的训练损失, 迭代次数过小模型易欠拟合, 迭代次数过大模型易过拟合。 图6给出了在不同学习率和不同迭代次数下的R2大小。 由图5和图6可以看出, 两个数据集在迭代次数大约为200时, 模型的训练损失趋于0, 数据集1在学习率ε =0.001时, 模型的精度最高, R2为0.990 7, MSE为0.910 0; 数据集2在学习率ε =0.000 1时, 模型精度最高。 表1例举了iteration为200的时候, 猪肉含水量的近红外光谱预测模型在不同学习率下的R2和MSE大小。
 | 图5 迭代次数对模型的影响Fig.5 The impact of iteration number on the model |
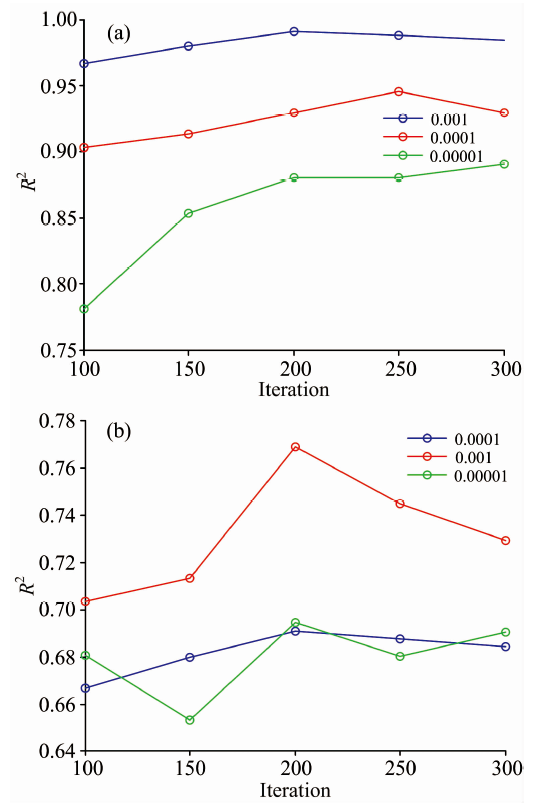 | 图6 不同学习率下迭代次数对模型的影响 (a): 猪肉; (b): 柠檬酸发酵液Fig.6 The influence of iteration times on the model under different learning rates (a): Pork near infrared spectrum; (b): Citric acid fermentation liquid near infrared spectrum |
| 表1 学习率选择表 Table 1 Learning rate selection table |
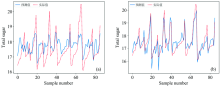
对于猪碎肉近红外光谱数据集, 我们对比了三种预测模型, 结果如表2。 可以看出, 用BP方法对近红外光谱建模的R2为0.902 6, 而用DBN模型和DBN-PLS模型建模后的R2分别为0.990 7和0.964 4, 预测精度都优于BP模型。 图7分别给出了猪肉含水量的BP模型、 DBN模型和DBN-PLS模型。 图7(a)为BP模型预测值与实际值的对比, 图7(b)为用DBN模型建模的预测值和实际值对比, 图7(c)为用DBN-PLS模型建模的对比图。 可以看出, DBN模型和DBN-PLS模型的预测效果都优于BP模型。
| 表2 猪肉近红外光谱预测模型评价指标 Table 2 Evaluation index of model for pork near infrared spectrum |
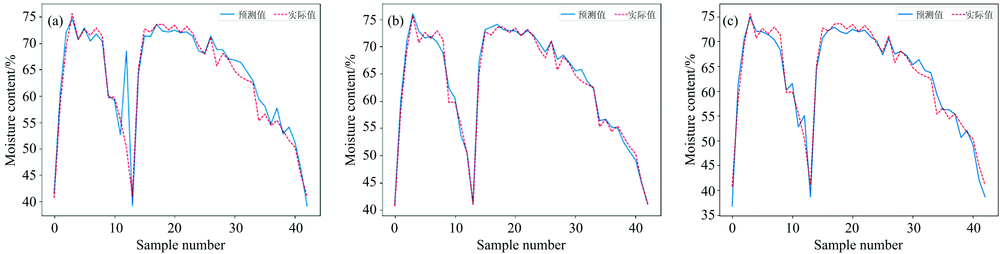 | 图7 猪肉近红外光谱模型对比结果 (a): BP模型; (b): DBN模型; (c): DBN-PLS模型Fig.7 Comparison results of model for pork near infrared spectrum (a): BP model; (b): DBN model; (c): DBN-PLS model |
对于第二个柠檬酸发酵液近红外光谱数据集, 我们分别应用了PLS模型和DBN-PLS模型对其建立校正模型, 并计算了其评价指标, 结果如表3所示, 并在图8给出了其模型预测值和实际值的对比图。 图8(a)为PLS模型建模效果, 图8(b)为利用DBN对光谱数据进行特征提取和降维后的建模效果。 可以明显看出, 利用DBN-PLS对柠檬酸发酵液近红外光谱数据集的建模效果明显优于PLS模型的建模效果。
| 表3 柠檬酸发酵液近红外光谱模型评价指标 Table 3 Evaluation index of model for citric acid fermentation broth near infrared spectrum |
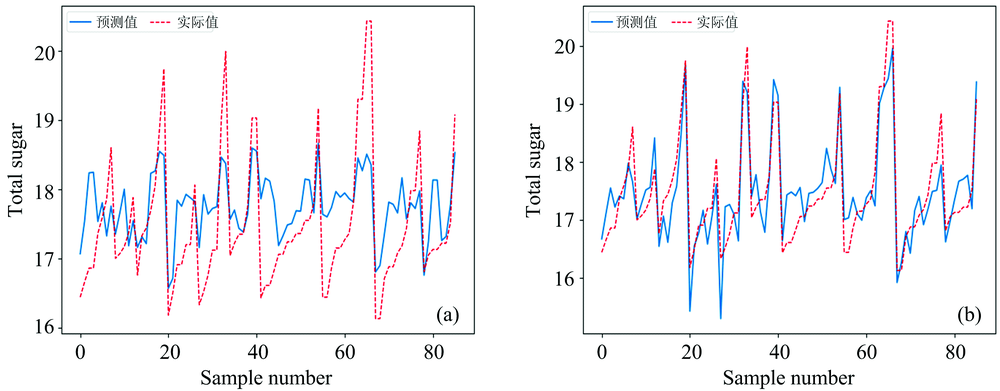 | 图8 柠檬酸发酵液近红外光谱建模对比 (a): PLS模型; (b): DBN-PLS模型Fig.8 Comparison of PLS and DBN-PLS models for near infrared spectra of citric acid fermentation broth (a): PLS model; (b): DBN-PLS model |
DBN网络可以实现复杂函数的逼近, 且由于其结构特性, 可以自动实现对输入数据的特征提取, 得到输入数据中更深刻的特征信息, 运用DBN模型分析预测可以解决其他建模方法初始参数难确定的问题。 利用近红外光谱数据和DBN网络建立了DBN和DBN-PLS近红外光谱预测模型, 通过将其与BP预测模型对比, 验证了DBN模型和DBN-PLS模型的可行性, 并且DBN模型和DBN-PLS模型预测精度优于BP模型。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|