
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
不同品种苹果糖度近红外光谱在线检测通用模型研究
[刘燕德 , 徐海, 孙旭东, 姜小刚, 饶宇, 张雨]
, 徐海, 孙旭东, 姜小刚, 饶宇, 张雨]
, 徐海, 孙旭东, 姜小刚, 饶宇, 张雨]
|
|


作者简介: 刘燕德, 女, 1967年生, 华东交通大学机电与车辆工程学院教授 e-mail: jxliuyd@163.com
由于果实内部细胞结构、 组成成分和光学传输特性的不同, 品种差异会对近红外建模分析果实内部品质时产生较大的影响, 以致原有模型无法高精度地预测果实品质参数。 探讨开发不同品种近红外通用模型用于在线检测苹果内部品质的可行性。 采用水果动态在线分选设备, 设置运行参数为: 积分时间100 ms, 运动速度5 s-1, 采集包括冰糖心, 红富士及水晶富士三个品种苹果的近红外漫透射光谱。 分析了三个品种近红外漫透射光谱的响应特征, 其光谱曲线走势基本一致, 在650, 709和810 nm附近存在突出吸收峰, 而在670, 750与830 nm附近存在波谷, 其差异主要表现为光谱吸收强度的差异。 采用多元散射校正, Savitzky-Golay卷积平滑及归一化处理方法, 减少了不同品种引起的光谱信息差异。 混合三个品种各校正集样本, 采用偏最小二乘回归算法建立了不同品种糖度的通用模型, 并利用无信息变量消除法(UVE)对建模变量进行筛选, 最终得到的有效变量个数为155。 所建立的UVE-PLS模型对验证集的决定系数, 均方根误差以及残留预测偏差分别为0.80, 0.61%与2.21。 在UVE筛选变量的基础上, 采用连续投影算法再对建模变量进行选择, 最终选出的变量个数为22。 采用多元线性回归(MLR)方法建立了简化后的通用模型, 对验证集的决定系数与均方根误差分别为0.78与0.64%。 测试集用于评估最佳的不同品种糖度通用模型的实际性能, 模型对每个品种测试集的潜变量数, 决定系数与均方根误差分别为6~10, 0.77~0.79与0.45~0.75%。 结果表明水果动态在线分选设备对不同品种苹果内部品质检测的潜力。 通过建立通用模型, 扩大了单一品种模型的预测范围, 提高了模型在不同品种间的预测稳健性。 并且采用合适的变量选择方法能够减少模型变量个数, 降低模型复杂程度, 并最终提高模型速率。 开发不同品种水果内部品质通用模型在波长有限的近红外光谱设备中具有良好的潜在应用。
Cultivar variability influences the near-infrared modeling and analysis of the internal quality of the fruit due to the different cell structure, composition and optical transmission characteristics of the fruit so that the original model can not predict the fruit quality parameters with high precision. The feasibility of a multi-cultivar model’s development for the online determination of the internal quality of apple including “Candy Heart”, “Red Fuji” and “Crystal Fuji” was investigated. Near infrared diffuse transmittance spectra of each cultivar were collected by the fruit sorting equipment under the condition of the interval time of 100 ms and motion speed of 5 s-1. The spectral curves of all the cultivars were similar where the prominent absorption peaks were near 650, 709 and 810 nm, and troughs were near 670, 750 and 830 nm, and their variations were mainly reflected in the spectral absorption intensity. The spectral pre-process methods including multiplicative scatter correction, Savitzky-Golay smoothing and normalization were employed to filter out the variations in signals caused by the cultivars. Partial least squares regression method was used to establish the common model for the soluble solid content where the calibration sets of the total samples were combined. Uninformative variable elimination was used to select the modeling variables whose number of effective variables selected was 155, and the performance of the UVE-PLS model resulted in greater coefficient of determination for prediction of 0.80, lower root mean square error of 0.61% and higher residual prediction deviation of 2.21. Successive projections algorithm was employed to select the variables in the wavelengths selected by UVE and the number of variables selected was 22. Multivariable linear regression was used to establish the simplified model, which resulted in coefficient of determination for prediction of 0.78 and root mean square error of prediction of 0.64%. The test sets of all the cultivars were used to access the performance of best universal model, which resulted in latent variables of 6~10, coefficient of determination for prediction of 0.77~0.79 and root mean square error of 0.45%~0.75%. The results highlighted the potential of dynamic on-line sorting instruments for the testing of internal qualities of apples. The prediction range of the single cultivar model was expanded, and the robustness of prediction model among different cultivars were improved by establishing the common model. Appropriate variable selection methods can decrease the number of model variables, reduce the complexity of the model and ultimately increase the model rate. The development of the universal model of different cultivars for predicting internal quality has a good potential application in wavelength-limited near infrared spectroscopy equipment.
水果内部参数, 如糖度(soluble solid content, SSC), 是水果的主要品质属性[1]。 传统检测方法为破坏性方法, 且分析数量有限, 而近红外(near infrared, NIR)光谱结合化学计量学是一种快速、 准确、 易于实现的无损检测技术。 目前已经研究了各种水果, 包括苹果[2, 3, 4]、 石榴[5]、 樱桃[6]、 圣女果[7]等水果种类。
在新样本测定前, 必须建立NIR模型以建立光谱和属性值之间的函数关系。 因为果实物化特性的不同, 导致其内部细胞结构、 组成成分和光学传输特性的差异, 故一般针对不同品种建立不同的近红外模型。 但这种方法增加了模型建立及维护的成本。 此外, 对于波长有限的近红外仪器, 由于校正模型的限制, 品种的适用范围也受到限制。 因此, 建立近红外通用模型将有助于推广近红外技术。 Liu等[8]建立了富士苹果, 大久保桃子和丰水梨糖度通用模型。 Wang等[9]建立了糖度与硬度的多品种洋梨模型。 前期研究中建立了新梨7号, 砀山酥梨, 玉露香梨和红富士苹果的糖度在线检测通用模型。 前两项研究都是基于便携式检测设备建立的数学模型, 未能探讨建立动态在线检测设备通用模型的可行性。 而后一项研究重点研究并比较了单一品种检测模型与在线检测通用模型的优劣势, 结果表明混合模型在减小品种差异对预测模型稳健性的影响上表现出良好的性能。 然而, 由于大量的建模数据, 增加了模型的潜变量个数, 从而降低了模型的效率。 因此, 为了在保证预测精度的前提下, 提高通用模型的效率, 以三种苹果(冰糖心、 红富士及水晶富士)为研究对象, 采用合适的预处理方法以减少不同品种的光谱差异, 并采用无信息变量消除法以及连续投影算法筛选特征波长以减少建模变量, 开发不同品种苹果糖度的近红外在线检测通用模型。 研究结果将对水果商品化处理环节具有实际应用价值。
样品选自陕西省某商业果园, 经过手工分拣后立即放于22 ℃的实验室环境下, 且整个实验阶段, 样品都保持相同的贮藏状态。 其中, 冰糖心75个, 红富士50个, 水晶富士40个, 共165个样品果。 在口感上, 红富士与冰糖心均属于脆苹果, 而水晶富士属于粉苹果。 口感的粉与脆实质上是苹果在成熟期果肉细胞的不溶性果胶及纤维素的含量和性质差异导致细胞间粘连性下降的程度和速率不同造成的[10]。 每个批次按样品比例使用15~20个果实, 并定期评估。 每个样品均在果实赤道附近的4个位置进行测量, 各测量部位相距90° 并垂直于茎轴。 在同一位置进行光谱采集与糖度测定, 且每个观测点均作为一个独立样本。
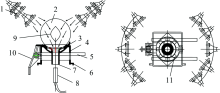
水果动态在线检测设备采用漫透射检测方式(图1), 将一组呈圆弧状配置的光源对称排列在待测样品两侧, 其发出的光均匀照射样品表面, 透过样品内部的光由果杯下方光纤探头收集后传回光谱仪, 这种方式得到的样品果肉信息更多, 避免了果实表面反射光及外部光干扰, 同时能有效消除由果实不同部位造成的糖, 酸等成分的测定误差。 设备采用QE65Pro型光谱仪(Ocean optics INC. USA), 其波长范围为350~1 150 nm, 光源为10盏12 V, 100 W的卤钨灯, 采集时参数设定为: 积分时间100 ms, 运动速度5 s-1。
 | 图1 漫透射检测机构 1: 光源; 2: 样品; 3: 密封圈; 4: 果杯; 5: 拨杆; 6: 支持端; 7: 限位装置; 8: 光纤探头; 9: 果核; 10: 弹跳爪; 11: 橡皮垫圈Fig.1 Mechanism of diffuse transmission detection 1: Light source; 2: Samples; 3: Gasket ring; 4: Cups; 5: Driving lever; 6: Stand; 7: Stop block; 8: Probe; 9: Kernel; 10: Bouncing claw; 11: Rubber hood |
设备预热30 min后, 以聚四氟乙烯球作为参比, 校正参比后采集光谱。 采用硬件触发方式采集光谱, 其结构简图如图2所示, 齿轮每4个齿对应安装一个果杯, 果杯和分度盘齿一一对应。 分度盘下方2 mm处安装有光电开关, 每转一齿, 即传动一个果杯的行程, 触发传感器, 使后续电路发出信号, 从而触发光谱仪采集并保存一条光谱。
 | 图2 光谱采集触发装置 1: 链轮; 2: 分度盘; 3: 光电开关; 4: 果杯; 5: 链条Fig.2 Trigger of spectral acquisition 1: Gear wheal; 2: Dividing plate; 3: Photoelectric switch; 4: Cups; 5: Chain |
从每个样品的测量位置取出一个圆形楔形物(最大直径50 mm), 通过粗棉布压制, 并使用温度补偿糖度计(型号PAL-1; Atago Co., Tokyo, Japan)测量果汁的SSC含量。 重复测量三次, 取其平均值作为对应测量位置的SSC含量真值。
偏最小二乘(PLS)回归广泛应用于近红外光谱分析, 以将光谱矩阵X与浓度矩阵Y相关联。 PLS回归模型可以写为
式(1)中, b表示回归系数的向量, e表示模型残差。
在PLS算法中, 留一法交叉验证通常用于分别避免由于使用太小或太大的潜变量(latent variables, LVs)而导致的欠拟合或过拟合。 LVs的最佳数量由交叉验证值的最低均方根误差确定。
通过校正集的决定系数(
式(2)— 式(4)中, n表示校正集或验证集中的样本数, yi和
RPD值的增加表明模型质量的提高, Chang等[11]定义了三个质量类别以考虑模型的可靠性: 优秀模型, RPD> 2; 可靠模型, RPD为1.4~2; 不可靠模型, RPD< 1.4。
在整个实验阶段, 将最后一批的样本作为测试集, 而其余批次样本进行建模分析。 校正建模之前, 对样本进行肖维勒准则测试。 其中, 冰糖心, 红富士与水晶富士各剔除异常样本4个, 共计12个。 将冰糖心、 红富士与水晶富士依次定义为品种1, 2与3, 每个品种的剩余样本通过Kennard-Stone(K-S)法按约3∶ 1的比例分成2组, 校正集与验证集。
全部剩余样本的校正与验证集分别由各个品种的校正和验证子集组成。 校正集仅用于构建校正模型, 验证集仅用于决定模型的参数以评估校正模型, 而测试集用于模型的外部验证。 如表1所示, 校正集与验证集的SSC范围分别为8.5%~17.5%与8.9%~16.7%, 标准偏差分别为1.48%与1.35%, 样本集覆盖了足够大的范围, 且校正集范围大于每个品种的验证集, 这些特征有利于建立稳健的近红外模型。
| 表1 样本集糖度含量统计 Table 1 Statistical values of the SSC(%) of data sets |
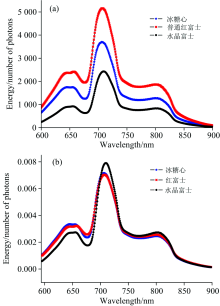
每个品种的平均原始光谱如图3(a)所示, 光谱下部(350~594 nm)与上部(900~1 150 nm)的光谱能量值较低, 有效信息较少, 主要涵盖了无价值的信号, 故将有效波长范围定义为594~900 nm(400个数据点)。 总体上看, 三种光谱主要存在吸收强度的差异, 光谱走势基本一致。 红富士光谱较另外两种光谱吸收强度较高, 而水晶富士强度最低, 其可能与果型及果肉软化有关。 光谱曲线分别在650, 709和810 nm附近存在突出吸收峰, 而在670, 750与830 nm附近存在波谷。 其中, 650 nm的吸收主要受表皮颜色的影响, 670 nm附近可能为叶绿素[12]的吸收, 750 nm附近的波谷与O— H三倍频伸缩振动有关, 830 nm附近的较弱波谷与N— H三倍频伸缩振动[13]有关。 经过比较分析, 使用多元散射校正(MSC)对光谱进行预处理, 其主要作用为消除颗粒分布不均匀及颗粒大小产生的散射影响。 并结合Savitzky-Golay(S-G)卷积平滑(平滑点数为3)来有效减少光谱的噪声, 提高光谱信噪比。
 | 图3 样品平均光谱 (a): 原始光谱; (b): 处理后光谱Fig.3 Average spectra of the samples (a): Original spectra; (b): Processed spectra |
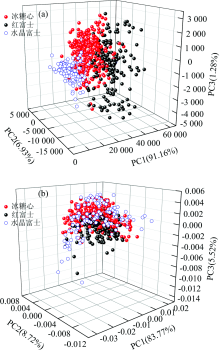
为了进一步消除不同品种的影响, 首先进行光谱差异性分析, 对光谱进行主成分分析(PCA), 以光谱前3个主成分的得分计算样本的空间距离(前3个主成分已表征了99%的光谱信息), 三个品种的三维得分分布图如图4(a)所示。
 | 图4 三个品种的前3个主成分得分分布 (a): 原始光谱的主成分得分; (b): 经过归一化及多元散射校正处理的光谱的主成分得分Fig.4 The first three PCs score plots of spectra of all cultivars (a): PC scores of original spectral data; (b): PC scores of MSC spectral data with normalized processing |
由图所示, 三个品种的主成分空间分布存在差异, 这些差异可能反映了品种之间的差异, 例如果皮, 果肉的颜色与厚度, 果胶含量等。 通过比较分析, 在光谱预处理的基础上结合归一化处理以减小差异。 将未处理的光谱与经过归一化处理及光谱预处理的光谱的PC得分图[图4(b)]进行比较, 后者的分布明显更加集群, 即光谱差异性减小, 且平均光谱[图3(b)]差异明显缩小, 因而可以进一步研究三个品种模型的通用性。
采用PLS回归算法建立三个品种的通用模型, 即混合三个品种的校正模型, 建立不同品种混合模型, 用于预测所有品种的SSC。 采用基于PLS回归系数的无信息变量消除法[14](uninformative variable elimination, UVE)筛选特征变量, 其基本思想是把变量对应的回归系数平均值与其标准差的比值作为变量选择的衡量依据, 其表达式如式(5)
式(5)中, CV为回归系数的平均值与标准差之比, i为光谱矩阵中第i列向量。
最终的判断方法是将一定数量的随机变量矩阵加入光谱矩阵中, 然后通过交叉验证建立PLS模型, 得到回归系数矩阵, 将随机变量矩阵的最大CV值(CVmax)作为阈值, 当变量对应的CV值低于CVmax时, 该变量被剔除。
采用UVE对经过预处理的全谱变量(398个数据点)进
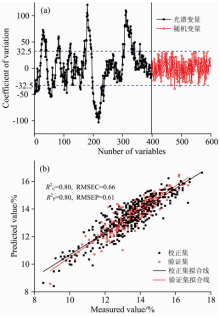
行有效变量筛选, 控制随机变量的大小为原变量的10-10, 使得扩展矩阵的特征值基本保持不变以最大程度地降低随机矩阵对原变量回归系数的影响, 随机变量个数设为200, 最终的处理结果如图5所示。
 | 图5 UVE处理结果 (a): UVE筛选变量的结果; (b): 通过UVE选择波长后的PLS模型预测结果Fig.5 Results of UVE processing (a): Result of variables selected by UVE; (b): PLS model in the wavelengths selected by UVE |
由图5(a)所示, 黑色竖线为光谱变量与随机变量分界线, 其左侧黑色曲线表示光谱变量的CV分布情况, 右侧红色曲线表示随机变量的CV分布情况。 2条蓝色水平虚线表示所得的阈值上下限, 即随机矩阵的CVmax为32.5, 且当随机变量的CV值达到其最大值的99%时, 阈值被触发。 虚线之间的变量为被剔除的变量, 而虚线外的变量即为选中的光谱变量。 最终经过UVE筛选出的剩余光谱变量个数为155, 其验证模型对比结果如表2所示。
| 表2 苹果糖度的PLS模型验证结果 Table 2 Results of PLS modeling for the SSC of apples |
由表2可知, 经过预处理, RMSEP由0.73%降低至0.61%, 而RPD由1.85增至2.21, 可见前述所用的预处理方法是可行有效的。 并且经过UVE筛选后, 大大减少了建模变量, 其潜变量个数也有所降低, 最终降低了模型的复杂程度, 提高了模型的运算速度。 而其RPD并没有降低, 说明UVE筛选变量后, 光谱的有效信息并没有丢失, 模型表现出优秀的质量。 将模型定义为UVE-PLS, 其预测散点图如图5(b)所示。
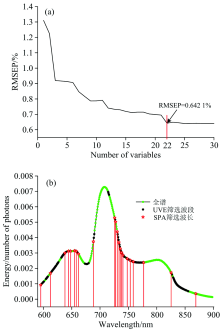
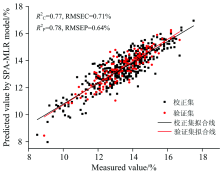
为了进一步去除光谱的冗余信息, 在UVE筛选变量的基础上, 再采用连续投影算法(successive projections algorithm, SPA)选择变量, 其基本思想是利用向量的投影分析[15], 找出包含最低限度的冗余信息的变量组, 并且使变量之间达到最小的共线性。 图6(a)显示当SPA所选变量数为22时, RMSEP最低, 并且随着所选变量数的进一步增加, RMSEP几乎不再降低。 因此这22个变量作为SPA选定变量数。 由图6(b)所示, 在UVE处理的基础上, 建模变量个数被SPA减少至22个, 且涵盖了由UVE筛选波段的大部分范围。 最终简化的多元线性回归(MLR)模型的预测结果如图7所示, 其
 | 图6 SPA变量筛选结果 (a): SPA选择变量数; (b): SPA所选变量在光谱中的位置分布Fig.6 Results of variable selection using SPA (a): Number of selected variables; (b): Locations of the selected variables in processed spectra |
 | 图7 基于22个SPA优选变量的MLR模型结果Fig.7 Result of MLR model based on 22 variables selected by SPA |
根据上述分析, 确定UVE-PLS模型为不同品种苹果糖度的最佳预测模型, 利用测试集数据评估模型的实际性能。 将每个品种测试集按照相同的预处理方法进行处理, 并放入模型进行验证, 其结果如表3所示。 其中, 对于冰糖心, 红富士与水晶富士测试集的
| 表3 苹果糖度最优模型的实际性能 Table 3 The practical performance of the optimal model for SSC of the apples |
近红外动态在线检测设备可以用于开发包括冰糖心, 红富士及水晶富士三种苹果的糖度通用模型。 采用多元散射校正结合S-G卷积平滑的光谱预处理方法, 结合归一化处理, 能够有效去除随机噪声以及基线偏差, 并减小由样品品种引起的光谱差异。 采用PLS回归算法建立了糖度通用模型, 结合UVE波长筛选方法能够有效剔除光谱的无用信息, 并且在保证预测精度的基础上, 模型预测效率由于建模数据的减少从而得到了提升。 利用SPA进一步筛选建模变量, 并且采用MLR算法建立了简化后的糖度通用模型, 其结果表明MLR通用模型在波长有限的近红外光谱仪中具有良好的潜在应用。 选定的UVE-PLS模型的实际性能表现出对糖度可靠的预测能力。 本研究表明水果动态在线分选设备用于建立不同品种水果糖度模型是可行的, 进一步研究多品种建模是必要的。 研究简化了水果商品化加工的过程, 降低了建立糖度分选模型的维护成本, 对多品种水果商品化处理具有指导意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|