




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
近红外光谱结合共识模型快速检测果酒的总酚含量
[叶华1, 3  , 袁雷明
, 袁雷明2, * , 张海宁3, 4 , 李理敏2 ]
, 袁雷明, 张海宁|
|


作者简介: 叶 华, 1978年生, 江苏大学博士研究生, 淮阴工学院讲师 e-mail: hgyehua@126.com
果酒发酵中的多酚是引起果酒口感、 颜色变化的重要因素。 为保证果酒品质, 有必要开发一种快速监测发酵过程中多酚含量变化的技术。 收集不同批次成熟期的蓝莓、 桑葚为原料, 分别碾压成汁, 同时按比例混合二者, 于小型发酵罐进行发酵。 通过离线收集不同发酵时段的发酵液于离心管, 高速离心后取上清液置于棕色瓶保存, 共计得到48个果酒发酵样本。 将上清液置于三个平行样比色皿, 以傅里叶快速变换近红外光谱仪(FT-NIR)采集其透射光谱, 取平均值作为该样本的光谱信号。 然后将棕色瓶内的发酵液以国标法(即以标准液的吸光度值制定标准曲线)测定各样品的总酚含量, 以duplex法计算样本光谱之间的距离且按2∶1的比例划分为训练集和预测集。 采用间隔偏最小二乘法(iPLS)将训练集样本的透射光谱与总酚含量之间构建定量模型, 间隔数从2依次变化到60个。 该研究创新之处是使用共识方法融合多个已构建好的iPLS成员模型, 按一定的共识规则分配权系数。 通过各成员模型交互验证的残差及其残差之间的相关性来优化各成员模型的线性组合, 以拉格朗日乘数法求解各成员模型的权系数, 使间隔偏最小二乘-共识模型(consensual iPLS, C_iPLS)的交互验证均方根误差最小。 相比于全局PLS模型、 划分不同间隔数量时的iPLS模型, C_iPLS均具有较小的预测误差。 当划分39个间隔时由三个iPLS成员模型(即14th, 16th, 18th)组成的共识模型误差最小为124.2, 交互验证相关系数为0.944, 对预测集样本的预测均方根误差为163.4, 预测相关系数为0.931, 预测性能均优于PLS和iPLS模型。 另外, 作为对比选用连续投影算法与无信息变量剔除法来优化光谱模型, 其预测性能均不及本文提出的共识模型。 分析各iPLS模型预测残差之间的相关性, 发现共识模型主要是融合那些具有较高预测性能且模型间较低相关性的成员模型。 结果表明, 光谱分析结合共识方法可提高回归模型的预测精度、 减少建模所需变量数, 能够用于果酒总酚含量的离线快速检测。
Polyphenol is one of important factors that cause the changes of taste and color in fruit-wine. To ensure the quality of fruit-wine, it is necessary to develop a fast measurement that monitors the change of polyphenol content during the fermentation. The ripe blueberry and mulberry were collected from different harvest batches. They were crushed respectively into juice, and their mixed juice was also mixed in certain ratio for fermentation in the small fermentation tanks. Those fermenting liquors from the different fermenting periods were collected through the off-line sampling access. The supernate was obtained by centrifugation pretreatment and totally 48 fermenting samples were preserved in the brown bottles for later use. The supernate were injected into three paralleled cuvettes, whose transmission spectrums were scanned by FT-NIR spectrometer, and their repeated readings were averaged for the spectral signals. Then, the total phenol content was measured by the national standard method (i.e. the standard curve was established between the absorbance value and the standard solution), and all samples were divided into the calibration and prediction set in a ratio of 2∶1 by duplex algorithm, which was used to calculate the spectral distance from the divided sample to the center of the rest samples. Interval partial least square (iPLS) was used to construct series of quantitative models between the transmission spectra and the total phenol contents in the training set, and the number of intervals was successively changed from 2 to 60. The innovate point in this work was that the consensual rule was used to integrate the calibrated member models (here referring to the iPLS model) into a consensus model and distribute the weighting coefficients. The linear combinations of member models were optimized to minimize the mean squared error (MSE) in the consensus model through the residual errors from the cross validation and their correlations. The weighted coefficient of each member model was solved by Lagrange multiplier method, so as to minimize the root mean square error of the consensus model. Compared with the global model of partial least squares (PLS), interval partial least-squares (iPLS) model with different number of spectral intervals, the consensual iPLS (C_iPLS) model commonly obtained a better performance. When the full spectra were divided into 39 intervals, the C_iPLS model, composed of three iPLS members models (those were 14th, 16th, 18th iPLS model respectively), got the minimum root mean squared error of cross validation (RMSECV) of 124.2, as well as the correlation coefficient of cross validation ( Rcv) of 0.944, and the samples in prediction set were tested well with root mean square of prediction (RMSEP) of 163.4, as well as the correlation coefficient ( Rp) of prediction of 0.931. In addition, the successive projection algorithm and the uninformative variable elimination were used to optimize the spectral model, but the predictive performances were not better than the proposed consensus model. By analyzing the correlation between the predicted residuals of each iPLS model, it was found that the consensus model commonly screened these member models featured with high prediction performance and low correlation between member models. Results showed that the spectral analysis technology combined with the consensus method could improve the prediction accuracy of the regression model, reduce the modeling number of variables, and could be employed off-line for the rapid detection of total phenol content in fruit wine.
果酒是以成熟水果为原料发酵酿造而成的一种酒类, 纯度较低, 营养丰富, 有着独特的风味口感, 是各类酒中最具发展潜力的一种酒类[1]。 蓝莓、 桑葚等果品富含花青素、 多酚、 有机酸、 酚酸、 氨基酸等多种具有保健功能的营养物质[2], 尤其是多酚类含量丰富并具有多种生理功能, 深受饮酒人士的喜爱。 多酚通常是果酒品质的重要指标之一, 检测方法包括高效液相色谱法和分光光度计法, 但费时费力, 因此在果酒发酵过程中急需一种快速检测多酚含量的分析技术。
近红外光谱(near-infrared spectroscopy, NIRS)作为一种近30年来快速兴起的分析技术, 其快速、 简单、 低成本、 可重复性高等优点在食品安全与营养[3, 4]、 药物组分及活性[5]、 环境污染[6]、 石油化工[7]等方面得到了广泛的应用。 采用可见-近红外光谱测量苹果[8]、 柑橘[9]、 葡萄[10]等水果的内部品质, 预测相关性一般高于0.8。 常用化学计量学建模方法为偏最小二乘法(partial least square, PLS), 它是一种矩阵投影建模技术, 通常是采用全波段的光谱构建回归模型。 但全波段的光谱数量比较大, 一般在几百甚至几千以上, 且获取的光谱信息易受如水吸收峰[11]、 仪器性能等因素干扰, 因此变量筛选就显得尤为重要[8, 12, 13]。
通常, 待测物的理化指标与特定光谱区域的信号存在较高相关度, 一些用于光谱变量的筛选方法被提出来, 如间隔偏最小二乘法(interval PLS, iPLS)、 联合区间法、 遗传算法、 连续投影算法等。 但这些方法仅是筛选其中的一个或几个区间或多个变量来构建单个PLS模型, 而忽略了其他光谱区间对构建模型的贡献, 使信息损失。 为此, 一些多模型的共识方法被提出[14, 15, 16], 如基于不同样本子集建模的均值共识策略[14], 或基于不同模型分配权重的共识策略[15, 16]来提高光谱预测精度, 本文则提出一种基于光谱区间模型来分配各成员模型iPLS权重的共识策略。
采用江苏省溧水县生产的兔眼蓝莓、 桑葚(品种为镇椹1号、 台湾1号、 射阳3号), 于成熟期收集各批次于果园的不同位置。 按照蓝莓、 桑葚果酒的酿制工艺[17, 18], 将每批次进行单独打浆、 加酶、 灭酶等操作获取蓝莓汁、 桑葚汁; 按比例混合不同批次蓝莓汁、 桑葚汁, 共计得到16份果汁液, 分别装入各小型发酵罐进行发酵。
以离线采样法分别收集处于发酵中后期的发酵液三次, 将其1 000 r· min-1离心10 min后, 取上清液置于棕色瓶, 共计48个样, 用于后续的光谱采集及多酚含量测量。
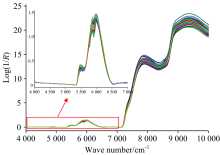
针对每个发酵液样本, 装载于3个10 mm光程的比色皿, 采用AntarisⅡ 傅里叶变换近红外(FT-NIR)光谱仪(美国Thermo Fisher公司) 收集透射光谱, 扫描范围为10 000~4 000 cm-1。 以仪器内置背景为参比, 扫描次数16次, 分辨率为8 cm-1, 共计1 577个波数点。 图1为各测试样的平均透射光谱曲线。
 | 图1 果酒的平均光谱透射曲线Fig.1 The averaged transmission spectra of fruit-wine |
根据国家标准GB/T8313— 2018总酚含量的测定方法, 以分光光度计法在波长765 nm处测量不同浓度没食子酸标准溶液Y的吸光度A, 绘制标准曲线(A=0.489 4Y+0.012 5, R2=0.996 9), 再对各发酵液标准处理得到的吸光度值计算出总酚浓度。
采用duplex算法以逐个拾取距离其余样本的光谱中心距离最远的那个样本依次按照2∶ 1的比例划分为校正集和预测集(如表1所示), 其中校正集用于构建、 训练模型, 预测集作为外来样本用于检验模型的预测性能。
| 表1 果酒样本集的总酚含量的统计结果 Table 1 Statistic results of polyphenol content in fruit-wine |
间隔偏最小二乘模型是基于某一间隔区域的光谱信息建立的偏最小二乘模型。 一般是将全区间光谱分割为n个等长度间隔, 基于这些间隔内的光谱信息, 分别构建偏最小二乘模型, 并从n个iPLS模型中选择一个预测性能最好的作为最终模型。
共识模型f(x)(consensus modeling), 并不是一种基于特征空间映射的建模方法, 而是融合多个成员模型、 按一定的共识规则分配权系数ci, 从而达成共识。 具体步骤为: (1)成员模型fi(xi)是基于训练集的各特征集{x1, …, xn}分别构建而成; (2)根据权系数ci加权各成员模型[如式(1)], 同时计算各成员模型预测值
图2为间隔偏最小二乘-共识模型(C_iPLS)构建流程: 首先将训练集的光谱数据划分n个间隔, 以每个间隔的光谱变量作为特征集, 分别构建n个iPLS模型, 作为成员模型fi与权系数ci向量相乘构建共识模型F(x)。 对式(3)的MSE进行开方计算, 即为共识模型的交互验证均方根误差(root MSE of cross validation, RMSECV), 此参数作为共识模型的主要评价指标。 调整成员模型的间隔数量n, 根据RMSECV最小原则来选取最佳共识模型。
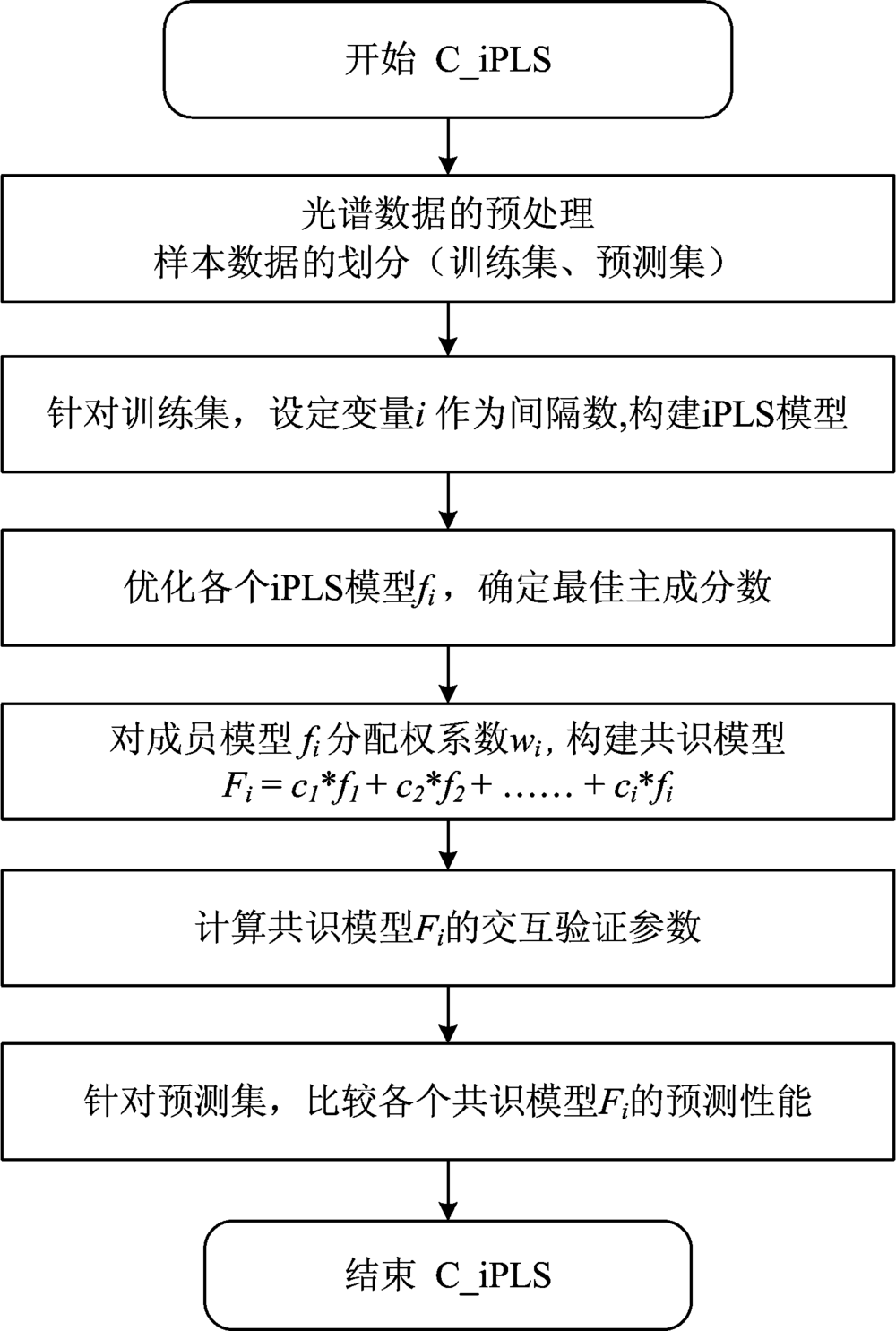 | 图2 间隔偏最小二乘-共识模型的工作流程Fig.2 Workflow of the consensus modeling iPLS |
基于校正集建立基于全光谱区间的PLS模型, 以内部交叉验证避免所建模型的过拟合或欠拟合[9]。 采用多元散射校正(MSC)、 标准正态变换(SNV)等方式对果酒透射光谱数据进行预处理, 但构建的PLS模型相比于无预处理时的预测性能, 并未得到改善。 因此, 本工作所处理的光谱数据均为原平均光谱。
将全区间光谱划分的间隔数量从2依次增加到为60; 并基于这些间隔的光谱变量分别构建PLS模型, 以RMSECV最小为原则筛选最佳的iPLS模型。 作为对比, 连续投影算法 (SPA)、 无信息变量剔除(UVE)等变量筛选方法用于校正集的模型构建。
图3为不同间隔数n时的最佳iPLS及C_iPLS模型的交互验证均方根误差, 随着n变大, RMSE值均呈现先变大后逐渐变小, 当n> 12时, 误差在125~155内波动。 当n=1, 此时iPLS模型、 PLS模型、 C_iPLS模型等价。 当间隔数为3时, 两者模型性能最差, RMSE均达到185以上; 当间隔数为39时, 此时的iPLS模型、 共识模型同时具有最小的RMSECV, 分别为131.3和124.2, 为全局(n≤ 60)最低值。
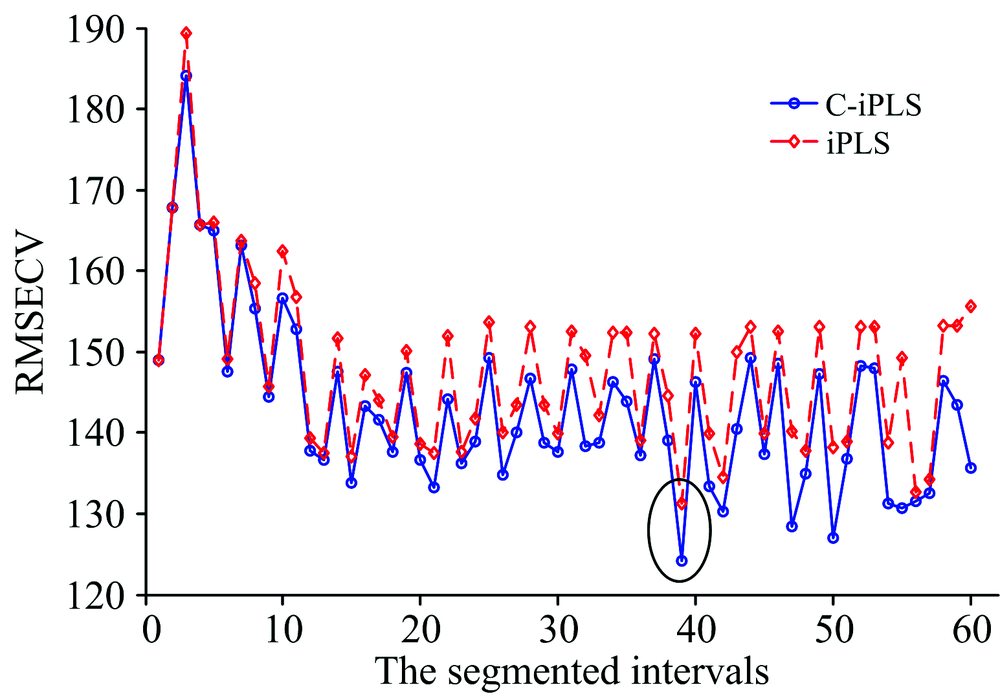 | 图3 间隔偏最小二乘模型及其共识模型的交互均方根误差变化趋势Fig.3 RMSECV tendencies of the developed iPLS and C_iPLS models |
表2为几种模型的预测结果。 当n=39时, 以第14个间隔中的40个光谱变量构建的iPLS模型预测性能优于其他iPLS模型, 但相比于全局PLS模型、 共识模型, 其预测效果最差, 预测均方根误差(root mean squared errors of prediction, RMSEP)低至178.7。 结合以划分39个间隔时的14th, 16th, 18th三个iPLS为成员模型构建的共识模型(如图4所示), 具有最好的预测性能, RMSEP低至163.4, 优于iPLS和PLS模型, 此时C_iPLS模型对训练集、 预测集的样本预测分布如图5所示, 样本分布越接近45° 对角线表示模型预测性能越好。 与传统的SPA和UVE变量筛选后的模型对比, 共识模型的预测性能具有一定的优越性。
| 表2 几种不同回归模型的预测比较 Table 2 Comparisons of different regression models for prediction |
 | 图4 间隔偏最小二乘模型的交互验证均方根误差柱形图Fig.4 Bar plot of RMSECV by the iPLS models |
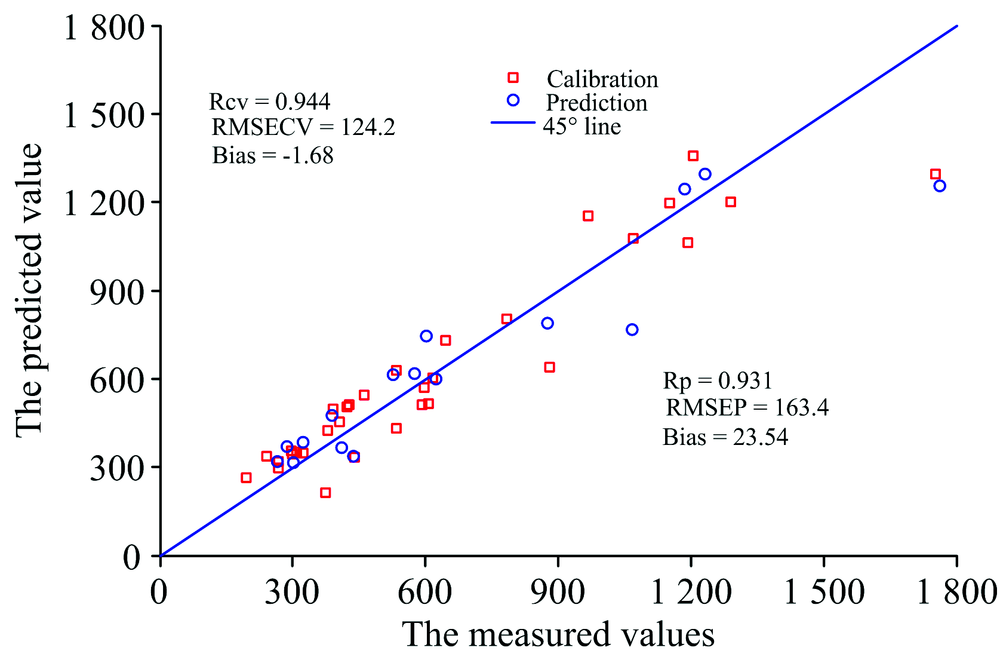 | 图5 间隔偏最小二乘的共识模型的预测散点图Fig.5 Scatter of prediction versus measurements for C_iPLS model |
分析共识模型中各成员模型的权系数, 仅入选了三个iPLS模型, 共识模型的表达式为F(x)=0.783f14+0.092 7f16+0.124 3f18。 成员模型的权系数绝对值越大, 表示该成员模型在共识模型占有的信息就越多。 从构成来看, 共识模型舍弃了绝大部分的iPLS模型, 这是由于其他iPLS模型具有较大的预测误差才设置其权系数为0; 从图4及权系数来看, 共识模型不仅舍弃了部分具有较低RMSECV的iPLS模型, 还分配了部分具有较差预测能力iPLS模型的权系数, 如舍弃了11th~13th, 29th等iPLS模型, 以及对18thiPLS成员模型分配的权系数大于16th iPLS成员模型。 分析式(3), 可以发现, 除了要求各成员模型的残差平方和
统计39个iPLS模型的交互验证残差向量(ei, ej)之间的相关性rij, 如图6所示, 区域越白, 表示相关性越高; 反则表示相关性越低。 观察间隔11th~13th的iPLS模型, 与其他间隔的iPLS存在较高的相关性; 而部分黑色区域如间隔1th~7th的iPLS模型之间虽然存在较低的相关性, 但是这些模型的RMSECV值较大, 易使公式3中的MSE数值变大。 作为一个好的共识策略, 应该筛选那些具有较低RMSECV的成员模型, 以及这些成员模型残差之间较低的相关性, 从而提升了共识模型的预测精度、 稳定性。
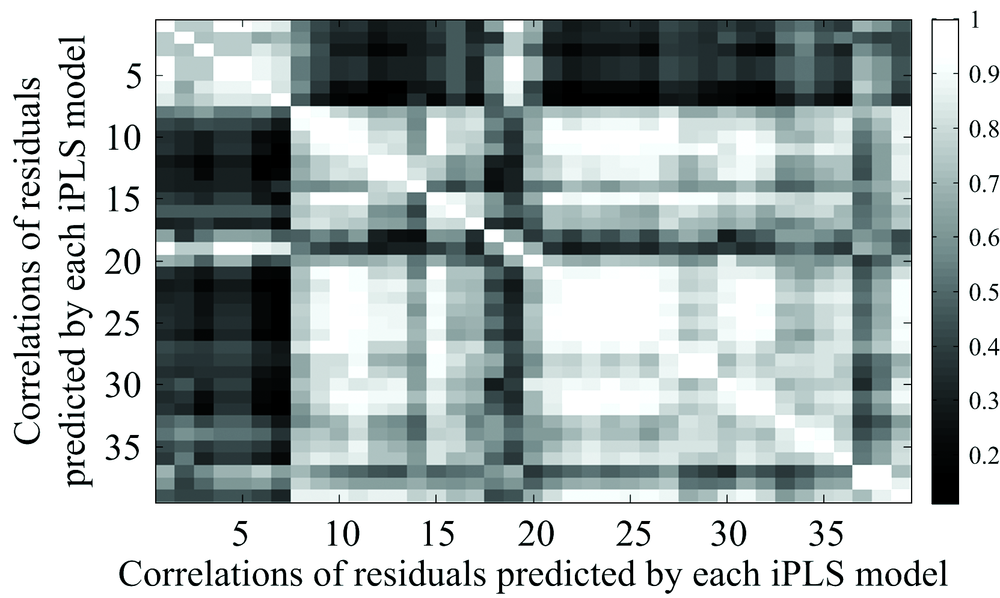 | 图6 间隔偏最小二乘模型的残差向量间的相关性Fig.6 Correlation mappings between the residual vectors of iPLS models |
探讨傅里叶变换近红外光谱快速离线测量发酵过程中的果酒多酚含量。 通过间隔偏最小二乘法挖掘不同光谱区间内的模型信息, 并以iPLS模型作为成员模型, 融合各成员模型之间的冗余信息, 使共识模型同时考虑了各特征集的模型信息、 各个成员模型的误差以及误差之间的相关性, 使共识模型的预测结果更加稳定、 可靠, 有助于近红外光谱的应用推广。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|