

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种稀疏约束的图正则化非负矩阵光谱解混方法
[甘玉泉1, 2  , 刘伟华
, 刘伟华1 , 冯向朋1 , 于涛1 , 胡炳樑1 , 汶德胜1 ]
, 刘伟华|
|


作者简介: 甘玉泉, 女, 1986年生, 中国科学院西安光学精密机械研究所副研究员 e-mail: ganyuquan@opt.ac.cn
由于受到高光谱遥感图像传感器平台的限制, 图像的空间分辨率受到一定影响, 这导致高光谱遥感图像的像元通常是多种地物的混合, 也叫做混合像元。 混合像元的存在制约了高光谱遥感图像的准确分析和应用领域。 采用高光谱解混技术可将混合像元分解为纯净的物质光谱(Endmember, 端元)和每种物质光谱所对应的混合比例(Abundance, 丰度), 为获取更多更精细的光谱提供了可能。 这对高精度的地物分类识别、 目标检测和定量遥感分析等研究领域具有重要的意义。 因此, 解混技术成为高光谱遥感图像领域的一个研究热点。 基于线性光谱混合模型(linear spectral mixing model, LMM), 提出了一种端元丰度联合稀疏约束的图正则化非负矩阵分解(endmember and abundance sparse constrained graph regularized nonnegative matrix factorization, EAGLNMF)算法。 该算法通过研究基于非负矩阵分解(nonnegative matrix factorization, NMF)的方法, 结合图正则化理论来考虑高光谱数据内部的几何结构, 将端元光谱稀疏约束和丰度稀疏约束应用于其中, 从而能够对高光谱数据的内部流形结构进行更为有效的表达。 首先, 构造了EAGLNMF算法的损失函数, 采用VCA-FCLS方法进行初始化, 然后, 设定相关参数, 包括图正则化权重矩阵参数、 端元光谱稀疏约束因子和丰度矩阵稀疏约束因子, 最后, 通过推导得到了端元矩阵与丰度矩阵的迭代公式, 并且设置了迭代停止条件。 该方法不受图像中是否有纯像元的限制。 实际上, 在现行高光谱遥感传感器平台情况下, 高光谱遥感图像中几乎不存在纯像元, 因此, EAGLNMF方法为高光谱遥感图像的实际应用提供了一种思路。 采用合成的高光谱数据, 构造了4个实验来分析该方法的可行性和有效性, 实验将该算法与VCA-FCLS, 标准NMF及GLNMF等经典的解混算法进行比较, 通过光谱角距离(spectral angle distance, SAD)和丰度角距离(abundance angle distance, AAD)这两个度量标准来进行比较。 实验1是总体分析实验。 在固定的信噪比和固定端元数目的情况下, 用以上三种经典方法与EAGLNMF同时进行解混。 实验2是SNR影响分析实验。 在固定端元数目和不同信噪比的情况下, 用这四种方法进行解混。 实验3端元数目分析实验。 在固定信噪比和不同端元数目的情况下, 用四种方法进行解混, 并且将结果进行对比。 实验结果发现提出的EAGLNMF方法在提取端元精度和估计丰度精度上都更为准确。 同时, 实验4是稀疏因子分析实验。 对端元稀疏约束和丰度稀疏约束之间的影响因子进行分析, 实验结果表明引入的端元稀疏约束对于解混结果也具有较好的影响, 并且端元稀疏约束和丰度稀疏约束之间的影响因子也对解混结果具有一定影响。 最后, 将该算法应用于AVIRIS所采集的真实高光谱图像数据, 将其解混结果与美国地质勘探局光谱库中光谱进行匹配对比, 其提取的平均端元精度相比于其他三种方法要稍好。
The space resolution of hyperspectral image is influenced due to the restriction of sensor platform, which results in more than one material in one pixel. Such kind of pixel is called mixed pixel. The existence of mixed pixels restricts accurate analysis and application of hyperspectral images. Hyperspectralunmixing technique can factorize mixed pixels to pure material signatures (endmembers) and corresponding proportion (abundance), which makes more accurate material signature available. Unmxing is very important to accurate classification and identification, anomaly detection and quantitative analysis for hyperspectral imagery. Based on linear spectral mixing model, this paper develops an endmember and abundance sparse constrained graph regularized nonnegative matrix factorization (EAGLNMF) algorithm for hyperspectral imagery unmixing. The algorithm is based on nonnegative matrix factorization, and integrates graph regularization and both endmember and abundance sparse constraints to the object function. Graph regularization is used to consider the geometrical structure of the hyperspectral image and sparse constraints can demonstrate the inner manifoldstructure. First, the lost function of EAGLNMF is constructed, and VCA-FCLS method is used as initial value. And then, the value of the parameters is set, including weighting matrix of graph regularization, sparse factors for both endmember signature matrix and abundance matrix. At last, the iteration equations for endmember matrix and abundance matrix are both obtained, and stopping criteria is given. The algorithm does not require pure pixel in the hyperspectral image. In fact, there are little pure pixel in real hyperspectral imagerydue to the sensors platform. Thus, EAGLNMF algorithm provides a kind of solution for real hyperspectral imagery. The availability and effect of EAGLNMF are verified by synthetic data via four experiments. The experiments compare EAGLNMF with VCA-FCLS, standard NMF and GLNMF. Two metrics, spectral angle distance (SAD) and abundance angle distance (AAD) are used to compare the four methods. Experiment 1 is total comparison experiment of the four methods. SNR and the number of endmembers are constant, and the value of SAD and AAD are compared. Experiment 2 evaluates the influence of SNR. Different value for SNR and constant value for number of endmembers are given to different runs. Experiment 3 evaluates the influence of number of endmembers. Different value for number of endmembers and constant value for SNR are given to different runs. The experiment result shows that EAGLNMF method obtains more accurate result for both endmebers and abundance. Moreover, experiment 4 evaluates the influence of sparse factor between endmember signature and abundance. The result demonstrates that endmember sparse constraint shows a positive effect to unmixing. And, sparse factor between endmember signature and abundance shows effect to unmixing result. In addition, real AVIRIS hyperspectral image is applied to VCA-FCLS, standard NMF, GLNMF and the proposed EAGLNMF, and compared with the ground truth of USGS, the result shows that EAGLNMF obtains best unmixing result among the four algorithms and the accuracy of the estimated endmembers is good.
高光谱遥感影像以其纳米级的光谱分辨率所获取的光谱信息而广泛应用于伪装目标探测[1, 2]、 环境监测[3]、 天文探测[4]、 物质分类识别[5]、 精细农业[6]及岩矿识别[7]等领域。 然而, 由于受到图像传感器平台的限制, 其空间分辨率受到一定影响, 同时, 由于自然界地物的复杂多样性, 所获取的高光谱遥感图像中单像元得到的光谱不一定只是一种物质的光谱, 可能是几种不同物质光谱的组合。 这样的像元被称为混合像元。 混合像元的存在制约了高光谱遥感影像的准确分析和应用。 为了扩大遥感图像的应用领域和提高其应用精度, 必须解决混合像元问题。 光谱解混技术就是用来解决混合像元问题的一项技术。 它将高光谱图像的混合像元分解为端元和丰度的组合, 为更精细的光谱应用提供了可能。 因此, 光谱解混技术是实现高光谱遥感技术定量化研究的重要条件。
光谱解混技术需要首先建立光谱的混合模型。 目前, 根据物质的混合状态和物理作用, 光谱混合可以分为线性混合模型和非线性混合两种模型[8]。 线性混合模型仅考虑到达传感器的光子与某一地物发生作用, 忽略了物质相互之间的影响。 然而, 当地物分布尺度较小时, 光子与多种物质发生作用, 导致非线性混合。 非线性混合模型不仅考虑光子与地物之间的作用, 还要考虑光子在不同物质之间的散射作用[8, 9]。 在非线性混合模型中, 可分为基于辐射度理论的非线性模型和基于计算理论的混合模型。 比较典型的采用基于辐射度理论的非线性光谱混合模型有Hapke模型[10]和几何光学模型[11]。
基于辐射度理论的模型通常针对特定地物类型, 需要大量先验知识, 从混合光谱产生根源上探究光谱解混工作。 然而, 很多先验知识很难获取, 需要对特定地物进行大量研究。 所以, 近年来, 从计算方法的角度来进行非线性解混的研究也相继出现, 主要有基于神经网络的方法、 基于核函数的方法、 基于流形学习的方法等。 其代表方法有多层感知器MLP方法(multilayer perception)[12], 神经网络ARTMAP方法(adaptive resonance theory MAP)[13]等。 总体来说, 相比于非线性混合模型, 线性光谱混合模型具有建模简单、 物理意义明确等优点, 也是目前最常用的光谱解混模型。
光谱解混技术通常包括三个研究方向, 分别是获取端元数目, 提取端元光谱及估计端元丰度。 目前获取端元数目方向的研究较少, 较为著名的算法有Hysime[14]及VD[15]。 大量的算法集中于研究提取端元光谱及其相应的丰度。
基于线性混合模型的端元提取方法可以分为两类。 一类是基于几何学的方法, 另一类是基于统计学的方法。 基于几何学的方法认为高光谱影像的所有像素点都集中于一个单形体内, 其顶点则认为是端元。 具有代表性的方法有纯像元指数(pixel purity index, PPI)[16, 17], N-FINDR[18], 顶点成分分析(vertex component analysis, VCA)[19], 正交子空间投影方法(orthogonal subspace projection, OSP)[20], 及体积增长方法(simplex growing algorithm, SGA)[21]等。 基于几何学的方法可理解为直接从高光谱图像中提取端元光谱, 因此需要假设图像中存在纯像元。 但是在实际高光谱遥感图像中, 纯像元几乎不存在, 所以其解混精度相对较低。 基于统计学的方法则不需要假设图像中存在纯像元, 充分利用数据的统计特性来求解端元光谱。 基于非负矩阵分解(NMF)[22]的解混方法也是统计学方法中的一种较为有代表性的方法。
非负矩阵分解是由Lee和Sueng在1999年提出的将一个非负矩阵分解为两个低秩非负矩阵乘积的矩阵分解方法[22]。 而对于基于线性模型的高光谱图像而言, 高光谱图像本身, 其端元光谱矩阵及丰度矩阵都可以看作是非负矩阵, 因而可以将非负矩阵分解用于求解光谱解混问题。 非负矩阵分解可保证非负性且无需指定迭代步长, 同时, 非负矩阵分解不需要高光谱图像中纯像元的存在。 因此, 基于非负矩阵分解的方法在高光谱解混领域具有其优越性。
目前, 一些学者在基于NMF的解混技术上已经奠定了研究基础。 2007年, Miao和Qi提出了最小体积约束的NMF(minimum volume constrained NMF, MVC-NMF)解混算法[23]。 由于NMF的目标函数非凸, 通过加入体积约束, 将最小二乘分析和凸面几何结合起来, 取得了较好的解混结果。 但是, 该方法中体积约束采用行列式来计算, 导致梯度计算较为复杂, 并且在每次迭代过程中将负值强制置0来保证非负性, 这对收敛也产生一定影响。 2011年, Cai等提出了采用图正则化(graph regularized NMF, GNMF)的概念来表示数据[24]。 随后, Rajabi等于2011年将GNMF方法应用于高光谱解混[25], 其结果相比于传统的NMF方法精确程度更高, 虽然该方法不仅考虑到了高光谱数据的欧式距离内部结构, 同时考虑了其内部黎曼几何结构, 但是忽略了丰度的稀疏特性。 2013年, Lu等提出了Graph Regularized L1/2 NMF(GLNMF)方法来进行光谱解混, 它在图正则化基础上加入丰度稀疏约束, 并且取得了较好的结果[26], 但是其算法的解混精度仍有提高的空间。
本文针对上述研究中存在的问题, 提出了在GLNMF算法的基础上, 对端元光谱矩阵也加入了稀疏约束的方法, 称为端元丰度稀疏约束的图正则化非负矩阵分解(EAGLNMF)算法。 通过合成高光谱数据和真实高光谱数据验证, 本文方法取得了较好的实验结果。
在线性混合模型中, 高光谱影像的像元为各端元按照一定比例的线性组合, 各端元在像元中所占比例称为丰度, 丰度需要满足和为一约束和非负约束。 假设第i个像元用mi(i=1, 2, …, N)表示, 则mi可以表达为如式(1)所示
其中, ai∈ aL× p为端元光谱, si, j∈ sp× N为对应端元的丰度值, p为端元数目, L为光谱通道数, N为像元数目, ni为像元mi中的噪声。 其非负约束(abundance non-negativity constraint, ANC))与和为一约束(abundance sum-to-one constraint, ASC)和表示如式(2)
给定一个非负矩阵Y∈ RL× N和一个正整数r< min(L, N), 通过非负矩阵分解NMF可以找到两个低秩非负矩阵W∈ RL× p和H∈ Rp× N, 使其满足
定义一个目标函数来描述分解后乘积对原矩阵的逼近程度, 它通过最小化欧氏距离的目标函数来表示。 非负矩阵分解的目标函数表示如式(4)
其中, ‖ · ‖ F表示Frobenius范数, 简称F范数。 为了控制步长和矩阵的非负性。 在文献[22]中采用乘性迭代规则, 表示如式(5)和式(6)
式(5)和式(6)即为矩阵W和H的迭代公式。 采用乘性迭代规则, 可以自动调整步长以进行迭代, 对每个矩阵元素施以不同步长, 保证了非负性, 消除了参数选择带来的影响。 然而, 一般情况下, 目标函数具有明显的非凸性, 存在大量局部极小值, 因此会有不唯一解, 这也是NMF方法所存在的缺点。
NMF通过其非负约束可在欧氏空间中表示数据, 但是并没有考虑数据内部的几何特性, 也无法识别数据空间上的结构特征。 GNMF则克服了这个缺点。 从几何学角度来看, 数据通常是从一个嵌入高维空间的低维流形数据所采样得到的。 因此, GNMF方法通过构造最近邻域图来解译数据内在的几何信息[24]。 实际应用中, GNMF方法在目标函数中引入权重矩阵来构造一个新的正则项。 但是, GNMF方法没有考虑到丰度矩阵的系数特性。 GLNMF方法则在目标函数中引入了丰度矩阵约束, 进一步提高了解混精度。 其损失函数可以表示为
其中, λ 用来调整丰度矩阵稀疏约束‖ S‖ 1/2的影响权重, ‖ S‖ 1/2的定义如式(8), Tr(· )表示矩阵的迹, 并且, L=D-W,
假设数据X=[x1, x2, …, xN]∈ RL× N为给定数据, 那么, 对每个xi(i=1, …, N)可代表L维空间中的一个数据点, 这N个数据点可作为顶点构造最近邻域图。 邻域图的权重矩阵用W表示。 W的定义有很多方法, 其中0-1权重, 热核权重, 点积权重为三种常用的权重定义方法[24]。 考虑到高光谱数据的凸面几何特性, 即高光谱数据构成的凸面几何体的顶点为端元光谱, 因此, 选择热核加权方法来定义权重矩阵W更适合。 如果点xi是点xj的最近邻域之一, 那么权重可表示如式(9)
其中, σ 用来控制两点之间的相似程度。
通常情况下, 由于真实的端元光谱矩阵本身并不具备稀疏性, 因此在每次迭代过程中, 端元光谱矩阵是稀疏的, 而且多个稀疏矩阵的乘积形成一个非稀疏矩阵。 有关此理论的证明仍是一个开放性问题[27, 28]。 基于上述理论, 本文在GLNMF方法的基础上引入端元光谱的稀疏约束。 无论端元光谱矩阵本身是否为稀疏矩阵, 引入稀疏约束后对端元光谱矩阵进行稀疏分解, 在降低噪声影响的同时, 可进一步提高端元光谱的提取精度。 本文将算法的损失函数定义为如式(10)
其中, A为估计出的端元, S为分解出的丰度矩阵, 参数μ 用来控制光谱数据的平滑程度。 α =α 0
根据F范数的性质, 有以下等式成立, ‖ A
式(10)改写如式(12)
采用拉格朗日乘子法和KKT条件, 假设φ ik和φ jk分别为常数aik≥ 0和sjk≥ 0的拉格朗日乘子, 并且Ψ =[φ ik], Φ =[φ jk], 则拉格朗日L表示如式(13)
对式(13)的L分别求A和S的偏导数
根据KKT条件有, φ ikaik=0和φ jksjk=0, 结合式(14)和式(15)则有
用式(16)及式(17)可以得到迭代规则如式(18)和式(19)
将其改写后, 可得到乘性迭代规则如式(20)和式(21)
(1) 不同的初始值会得到不同的结果。 通常会采用两种初始化方法, 分别是随机初始化和VCA-FCLS方法来进行初始化。 随机初始化方法采用随机选择0到1之间的值作为A和S的初始值。 但根据以往研究结果, 随机初始化方法往往没有VCA-FCLS初始化方法准确程度高, 因此, 本文采用VCA-FCLS方法对所提出的算法进行初始化。
(2) 要保证丰度矩阵满足ASC和ANC约束。 根据式(20)和式(21)的迭代规则, S显然不满足这两个约束条件, 因此, 在对S进行迭代时, 采用文献[26]的方法, 将矩阵X和A用矩阵Xt和At代替, 其分别定义如式(22)和式(23)
其中, N为像元个数, P为端元个数, δ 为一个常数, 用来调节ASC的约束效果, 使得丰度和趋近于1。 实验结果表明, δ 的选择会对解混精度造成影响, 随着δ 的增大, 光谱解混的结果更为准确, 但这也导致了收敛速度变慢。 为了平衡解混精度和收敛速度, 本文实验选择δ =20。
(3) 本文设置两种迭代停止规则。 ①当迭代次数达到所设置的最大次数时迭代停止。 ②当目标函数不再收敛时也迭代停止。 设置一个差值ε 作为停止迭代阈值, 实验中选择ε =10-4, 当连续十次目标函数差值小于ε 时, 则迭代停止。 其目标函数定义如式(24)所示, 停止迭代规则如式(25)所示。
(4) 如果在迭代过程中, A和S中出现0值或者负值, 则加上一个极小值来保证迭代可行。
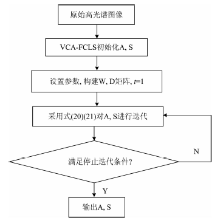
(5) 本文的算法流程表示如下, ε 表示停止迭代阈值, α 0和τ 是用来调整稀疏程度的常数, λ 是调整端元稀疏与丰度稀疏程度的因子, 即有β =θ α , μ 是调整参数, P为端元数目, Tmax为最大迭代次数。
算法流程:
① 输入: 数据: 原始高光谱数据矩阵(X);
参数: ε , α 0, θ , τ , μ , P, Tmax
输出: 端元光谱矩阵A及丰度矩阵S
② 具体步骤:
Step1 分别用VCA和FCLS方法来初始化端元A和丰度矩阵S, 令t=1;
Step2 构建W, D矩阵;
Step3 采用式(20)和(21)对A和S进行迭代, 令t=t+1;
Step4 满足停止迭代条件, 则迭代终止, 输出A和S。
其算法流程图如图1所示。
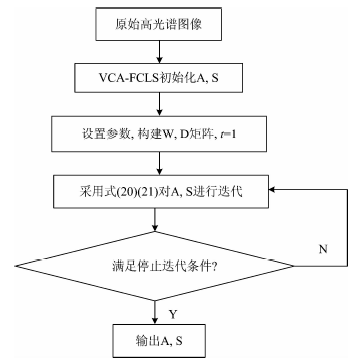 | 图1 EAGLNMF算法流程图Fig.1 Flowchart of EAGLNMF |
采用合成数据和真实高光谱数据对提出方法进行评估, 并将其与VCA-FCLS、 标准NMF和GLNMF等三种方法进行比较。 采用两个定量评估标准, 分别是光谱角距离(SAD)和丰度角距离(AAD), 分别对提取的端元及其对应丰度的准确性进行评价。 SAD用来计算估计出的光谱与真实光谱之间的光谱角, SAD值越小, 则估计出的端元光谱与真实光谱的差别越小。 AAD是用来评价估计出的丰度与真实丰度之间的差别, AAD值越小, 说明估计丰度越接近其真实丰度。 其公式表示如式(26)和式(27)
为了对所有估计出的端元及丰度进行评价, 采用SAD和AAD的均方根(root mean square, RMS)来进行评价, 用式(28)和式(29)表示
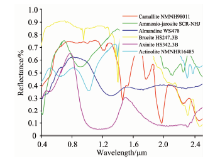
采用文献[23]的方法进行模拟数据合成。 模拟数据大小为64× 64, 从USGS光谱数据库[29]中选择一系列反射光谱来合成的。 本文合成数据所选择的光谱数据有224个谱段, 覆盖波长范围为0.38~2.5 μ m, 光谱分辨率为10 nm。 将整个图像分成8× 8的小块, 每个小块内都用六种不同物质光谱进行填充, 六种物质光谱均从USGS光谱数据库中选择, 选中的6种物质光谱曲线如图2所示。 所产生的图像然后通过一个空间低通滤波器来进行线性混合。 本文采用9× 9的滤波器来合成模拟数据。 同时, 将丰度大于80%的像素点的丰度值用1/p来代替, 并且加入0均值高斯噪声来模拟可能出现的误差和传感器噪声等。 算法分析通过4个实验来完成。 实验1是总体分析实验, 对几种算法进行总体比较分析。 实验2是SNR影响分析实验, 验证算法对信噪比(signal to noise ratio, SNR)的敏感程度。 实验3是端元数目分析实验, 验证端元数目对几种方法的影响程度。 实验是系数因子分析实验, 分析了稀疏系数α , β 之间影响因子θ 对解混结果的影响。 同时, 为保证结果准确性, 所有的实验结果都是30次运行结果的平均值。 实验1、 实验2和实验4都是用选中的6种物质来进行模拟数据的合成, 除了实验3中根据所需要的端元数目来进行模拟数据的合成。
实验中, 所有算法验证均采用MATLAB 2016b平台编程, 运行计算机配置如下: CPU型号为Intel(R) Core(TM) i3-3110M CPU@2.4 GHz, 内存为4 GB, 操作系统为Win7 64bit Service Pack1。
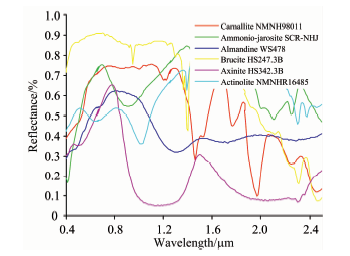 | 图2 USGS光谱库选择的六种物质光谱Fig.2 Six material signatures selected from USGS |
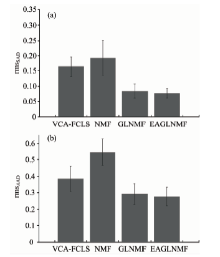
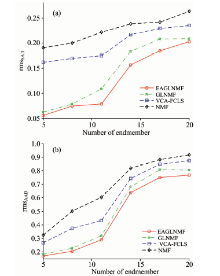
实验1(总体分析实验): 实验1的目的是对几种不同算法进行总体比较。 在本实验中, 加入了SNR为20 dB的高斯噪声。 采用VCA-FCLS, NMF, GLNMF及EAGLNMF几种方法来进行求解。 其中, NMF, GLNMF及EAGLNMF均采用VCA及FCLS的结果作为初始迭代值。 终止迭代规则为式(25), 当连续10次迭代结果满足式(25)或者当迭代次数达到设定的最大次数Tmax时, 则终止迭代。 EAGLNMF的参数设置为ε =10-4, α 0=0.1, τ =25, θ =2, μ =0.1P=6, Tmax=3 000。 为了保证ASC约束, 采用式(22)和式(23)中方法来实现。 图3(a)和(b)分别给出几种方法下rmsSAD和rmsAAD及其标准偏差。 在图3(a)中, VCA-FCLS, NMF, GLNMF和EAGLNMF方法的rmsSAD分别为0.164 0, 0.193 0, 0.084 0和0.076 7, 其对应的标准偏差分别为0.032 2, 0.057 4, 0.023 1和0.015 9。 从图3(a)中可以看出, VCA-FCLS比标准NMF方法的rmsSAD及其标准偏差的值都更小, 说明VCA-FCLS比NMF的端元提取精度更高, 这是由于标准NMF方法仅仅从非负矩阵分解的角度进行解混, 没有考虑到高光谱数据的几何特性。 GLNMF和EAGLNMF方法的端元提取效果比VCA-FCLS和NMF方法要好一些, 同时, 从数据对比可以看出, EAGLNMF比GLNMF的端元提取结果稍好, 这是因为EAGLNMF方法对端元增加了稀疏约束, 在迭代过程中降低了噪声的影响。 在图3(b)中, VCA-FCLS, NMF, GLNMF和EAGLNMF方法的rmsAAD分别为0.384 1, 0.545 6, 0.291 4和0.275 3, 其对应的标准偏差分别为0.077 6, 0.080 7, 0.064 1和0.056 0。 从图3(b)中可以看出, 其结果与rmsSAD具有一致性。 总体来说, EAGLNMF方法的解混效果要优于其他几种方法。
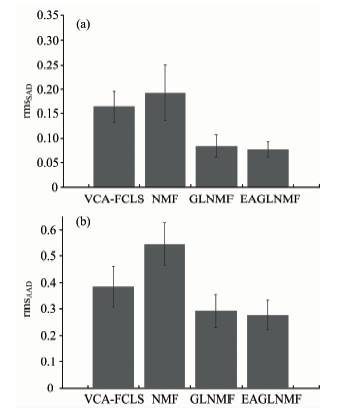 | 图3 几种方法的(a)rmsSAD和(b)rmsAAD的对比Fig.3 Comparison of rmsSAD and rmsAAD for VCA-FCLS, NMF, GLNMF and EAGLNMF |
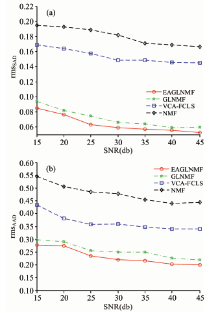
实验2(SNR影响分析实验): 本实验目的是评估噪声对算法的影响程度。 实验选择相同的端元数目和不同程度信噪比的情况下, 来对算法进行分析。 此实验中, 端元数目P=5, 信噪比分别为15, 20, 25, 30, 35, 40和45 dB的高斯噪声加入了合成数据。 其中, 合成数据的生成方法与实验1中相同, 参数设置也与实验1中相同。 从图4(a)中可以看出, VCA-FCLS的端元提取效果优于NMF方法, 同时, GLNMF和EAGLNMF方法的端元提取精度比VCA-FCLS更高。 EAGLNMF方法所获得的rmsSAD值最小, 其端元提取精度比GLNMF方法稍好。 从图4(b)中可以看出, VCA-FCLS的丰度估计效果优于NMF方法, 同时, GLNMF和EAGLNMF方法的丰度估计效果比VCA-FCLS更准确。 EAGLNMF方法所获得的rmsAAD值最小, 其丰度估计结果比GLNMF方法稍好。
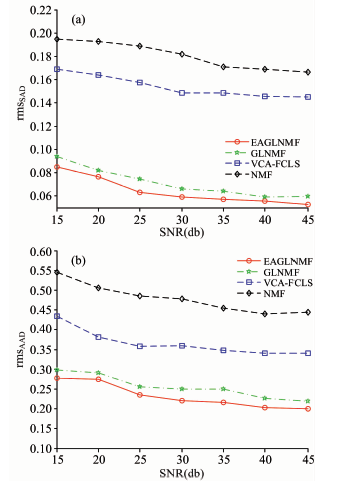 | 图4 在不同SNR值下(a)rmsSAD和(b)rmsAAD的对比Fig.4 Comparison of (a) rmsSAD and (b) rmsAAD for the methods with different SNRs |
实验3(端元数目分析实验): 实验3的目的是测试不同端元数目对算法解混精度的影响。 在相同信噪比和不同端元数目情况下算法的解混效果。 从光谱数据库中选择对应数目的端元光谱来合成数据, 几种方法分别对相同端元数目的合成数据来进行分解, 其中, SNR统一设置为20dB, 端元数目P分别设置为5, 8, 11, 14, 17和20, 其他参数设置与实验1相同。 其实验结果如图4所示。 从图5(a)中可以看出, 随着端元数目的增加, 四种方法的rmsSAD值也随之增加, NMF端元提取效果最差, VCA-FCLS方法的端元提取精度要优于NMF; GLNMF和EAGLNMF的提取精度比VCA-FCLS方法更为准确。 同时也可以看出, EAGLNMF方法的端元提取结果比GLNMF方法稍好, 尤其是当端元数目增多的时候, 其端元提取的精度相比于GLNMF更为准确。 从图5(b)中可以看出, 随着端元数目的增加, 四种方法的rmsAAD值也随之增加, 并且其值与rmsSAD具有一致性, 这说明丰度估计的结果与端元提取的结果具有一致性。 同时也可以看出, EAGLNMF方法的丰度估计结果比GLNMF方法稍好。
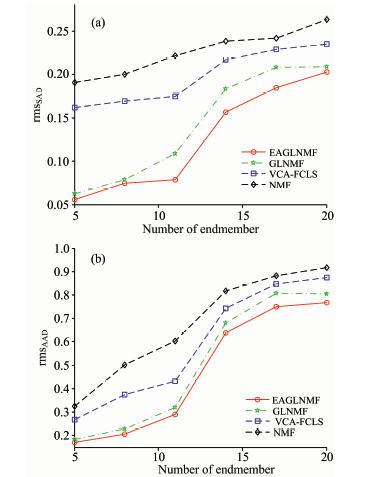 | 图5 不同端元数目下(a)rmsSAD和(b)rmsAAD的对比Fig.5 Comparison of (a) rmsSAD and (b) rmsAADfor the methods with different number of endmembers |
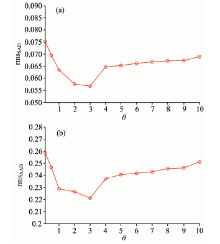
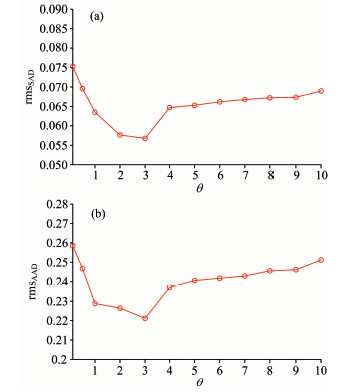 | 图6 EAGLNMF方法在不同θ 值时(a)rmsSAD 和(b)rmsAAD的对比Fig.6 Comparison of (a) rmsSAD and (b) rmsAAD for the methods with different θ |
实验4(稀疏因子分析实验): 实验4用来分析稀疏系数α , β 之间的影响因子θ 对解混结果的影响。 设β =θ α , 在实验1, 2, 3中, θ =2。 在本试验中, 采用的合成数据构造方式与实验1相同, 参数设置也与试验1相同, 但是, 分别将θ 设置为0.1, 0.5, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10来进行分析。 从图6(a)和(b)中可以看出, 当θ 由0.1到3逐步递增时, rmsSAD和rmsAAD的值均逐渐变小, 解混结果逐渐变好; θ 从3到10的时候, rmsSAD和rmsAAD的值逐渐变大, 解混结果逐渐变差; 但仍然好于θ =0.1和θ =0.5的情形, 这说明加入的端元稀疏约束因子在小于丰度稀疏的情况下, 解混结果较好; 同时, 加入的端元稀疏约束对于解混结果也具有较好的影响。 但是, 需要对端元稀疏约束和丰度稀疏约束之间的影响因子θ 进行合理的选择。 当影响因子θ < 1时, 削弱了丰度稀疏约束的影响, 影响了解混精度; 当影响因子逐渐增大至3时, 解混精度逐渐提高; 当继续增大时, 解混精度则有降低的趋势, 这说明端元稀疏约束和丰度稀疏约束对解混结果都产生了影响。
采用机载可见光及红外成像光谱仪(airborne visible/infrared imaging spectrometer, AVIRIS)所拍摄的美国内华达州的Cuprite数据[30]。 由于该地区主要为裸露的矿物岩石, 且具有混合情况, 较适合用来验证算法对混合数据的分解能力[31, 32]。 Cuprite数据有224个波段, 波段范围为0.4~2.5 μ m, 由于低的信噪比和吸收波段, 剔除了波段1~2, 104~113, 148~169, 221~224, 留下了188个波段进行分析。 本文选择了其原始数据的右上角图像, 图像大小为250× 191。 其第20波段的图像显示如图7所示。
 | 图7 AVIRIS Cuprite数据集第20波段的子图Fig.7 Band 20 of the sub-image of AVIRIS Cuprite data set |
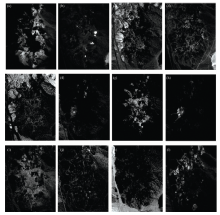
此区域有最多18种物质, 但是其中一些是相似物质, 因此, 选择了12种物质端元进行提取。 在此实验中, 参数设置如下, ε =10-4, α 0=0.1, τ =25, λ =3, μ =0.1P=6, Tmax=3 000。 按照本文算法所提取出的端元光谱曲线及其在数据库中的光谱曲线如图8所示。 提取出各端元对应的丰度图如图9所示。 为了将解混结果进行定量分析, 对各种物质的SAD值进行了比较, 表1给出了对比结果, 从中可以看出, 本文算法相比较于GLNMF, NMF, VCA-FCLS方法的解混结果稍好。
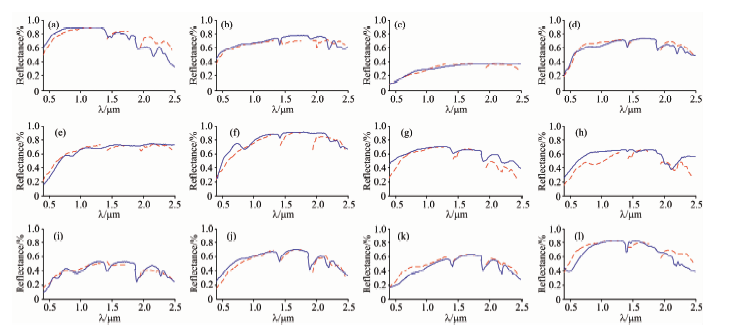 | 图8 USGS光谱库光谱曲线(蓝色实线)与EAGLNMF方法提取的端元光谱曲线(红色虚线)对比 (a): Alunite; (b): Muscovite; (c): Sphene; (d): Montmorillonite; (e): Pyrop; (f): Andradite; (g): Chacedony; (h): Buddingtonite; (i): Nontronite; (j): Kaonlinite#1: (k): Kaolinite#2; (l): DumortieriteFig.8 Comparison of original spectral signatures (blue solid lines) and estimated ones using EAGLNMF (red dotted lines) (a): Alunite; (b): Muscovite; (c): Sphene; (d): Montmorillonite; (e): Pyrop; (f): Andradite; (g): Chacedony; (h): Buddingtonite; (i): Nontronite; (j): Kaonlinite#1: (k): Kaolinite#2; (l): Dumortierite |
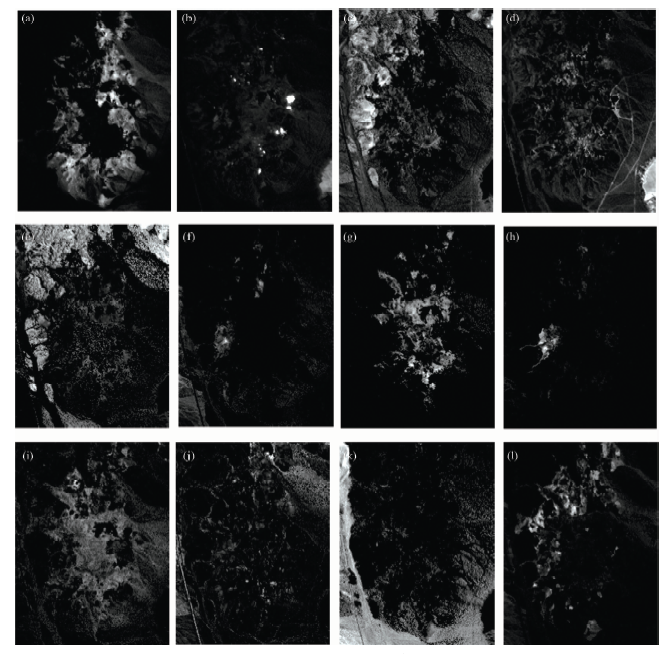 | 图9 EAGLNMF方法估计的丰度图 (a): Alunite; (b): Muscovite; (c): Sphene; (d): Montmorillonite; (e): Pyrop; (f): Andradite; (g): Chacedony; (h): Buddingtonite; (i): Nontronite; (j): Kaonlinite#1: (k): Kaolinite#2; (l): DumortieriteFig.9 Estimated abundance fractions maps using EAGLNMF (a): Alunite; (b): Muscovite; (c): Sphene; (d): Montmorillonite; (e): Pyrop; (f): Andradite; (g): Chacedony; (h): Buddingtonite; (i): Nontronite; (j): Kaonlinite#1: (k): Kaolinite#2; (l): Dumortierite |
| 表1 不同方法的SAD值比较 Table 1 Comparison of SAD with different methods |
提出了一种基于端元光谱和丰度联合稀疏约束的图正则化非负矩阵光谱解混方法。 该算法在传统的非负矩阵分解方法基础上, 加入了端元稀疏和丰度稀疏约束因子, 同时对数据的几何结构考虑后加入了图正则化约束因子, 并构造了端元矩阵和丰度矩阵的迭代公式, 获得了较好的解混结果。 从仿真实验可以看出, 图正则化约束通过对所观测的数据定义一个邻域图来考虑数据内部的几何结构, 端元和丰度联合系数约束一方面减少了解的数量, 提高了收敛速度, 另一方面降低了噪声对结果的影响。 试验结果表明本文算法的解混精度相比于一些经典算法有所提高。 针对本文算法, 后续将在图正则化非负矩阵分解基础上, 优化稀疏约束条件, 并进一步提高算法效率。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|