

{kind=link}
{kind=link}
{kind=link}
{kind=link}
不同核函数支持向量机和可见-近红外光谱的多种植被叶片生化组分估算
[陈方圆1, 2  , 周鑫
, 周鑫1, 2 , 陈奕云1, 2 , 王奕涵3 , 刘会增4, 5 , 王俊杰5, 6 , 邬国锋1, 5, 6, * ]
, 周鑫]
|
|


作者简介: 陈方圆, 1988年生, 武汉大学资源与环境科学学院博士研究生 E-mail: fangyuanchen@whu.edu.cn
氮、 磷、 钾元素是植物有机质的重要生化组分, 准确估算其含量对监测管理植被的新陈代谢和健康状况具有重要意义。 可见-近红外光谱结合多种建模方法已被用于植被生化参数的监测, 其中支持向量机回归方法被证明能够较好拟合反射光谱和植被生化参数之间的非线性关系, 而选取适当的核函数是其成功的关键。 以宜兴地区水稻、 玉米、 芝麻、 大豆、 茶叶、 草地、 乔木和灌木等八种植被叶片样本为研究对象, 分析比较基于径向基核函数、 多项式核函数和S形核函数的支持向量回归模型估算叶片氮、 磷、 钾元素含量的能力。 利用一阶微分变换、 标准正态变量变换和反对数变换对叶片可见-近红外光谱进行预处理, 运用bootstrapping法生成1 000组校正集和验证集, 分别建立基于三种核函数的支持向量回归估算模型, 以决定系数( R2)和相对分析误差(RPD)的均值作为评价指标。 结果显示, 结合一阶微分和反对数变换光谱, 采用径向基核函数模型对氮、 钾元素估算精度最高(氮: 平均 R2=0.64, 平均RPD=1.67; 钾: 平均 R2=0.56, 平均RPD=1.48), 结合一阶微分变换光谱, 采用径向基核函数模型对磷元素估算精度最高(磷: 平均 R2=0.68, 平均RPD=1.73)。 研究表明, 结合不同预处理的可见-近红外光谱, 基于径向基核函数的支持向量回归模型具有较好的估算多种植被叶片生化组分含量的潜力。
, ZHOU Xin
Nitrogen (
植被有机质控制着植被的新陈代谢过程和健康状况, 例如营养循环、 光合作用、 植物生产力和凋落物分解速率等。 氮(N), 磷(P)和钾(K)元素是植被有机质的三种重要生化组分, 快速掌握这三种元素的含量(cN, cP和cK), 对于监测植被生长过程中的新陈代谢过程和健康状况至关重要[1]。
传统化学分析手段测定植被氮、 磷、 钾元素含量, 具有较高的准确性, 但是过程复杂费时, 且对植株本身具有破坏性, 同时, 传统方法手段也无法提供这些元素含量的时空特征信息。 而遥感技术具有精细尺度下数种植被生化参数的估算潜力[1], 植被可见光和近红外(visible and near-infrared, VNIR)波段的反射率光谱包含了纤维素、 蛋白质、 木质素以及其他参数的综合光谱信息, 可被考虑用于估算氮、 磷、 钾元素的含量。 许多研究发现植被氮元素含量与叶片尺度的VNIR光谱相关性密切[2, 3], 也有研究表明VNIR光谱与植被磷、 钾元素含量之间存在相关关系[4], 因此, 在精细时空尺度下, 植被的VNIR反射率光谱具备相对快速、 低成本量化分析植被营养水平的潜力。
植被的光谱反射率与生化组分含量之间存在非线性关系, 尤其在近红外波段区间, 因而需要探究非线性模型来解决问题。 支持向量机(support vector machine, SVM)是一种新的基于统计学习理论的机器学习方法, 其利用结构风险最小化原则避免过拟合问题, 在最小化经验风险下所得结果优于传统的神经网络算法, 而且SVM在小样本、 高维度数据情况下具有优异的建模能力[5]。 若干研究已证明了支持向量机回归(support vector machine regression, SVR)在估算植被生化参数方面的潜力, 例如Wang等[6]运用SVR模型和VNIR光谱对小麦叶片中的氮元素进行量化研究, Yao等[7]利用包括SVR模型在内的多种算法进行小麦氮元素含量的估算, Zhai等[8]基于VNIR光谱, 结合SVR模型和偏最小二乘回归(partial least squares regression, PLSR)方法估算植被叶片的氮、 磷、 钾元素含量, 结果表明结合室内VNIR光谱测量的SVR方法具备估测植被生化组分含量的可行性。
SVR模型中的核函数可将目标空间映射到更高维的特征空间, 将目标空间内自变量和因变量之间的非线性关系转化为特征空间中的线性关系进行处理, 常用的核函数包括线性(
以江苏省宜兴地区的多种植被为研究对象, 基于室内VNIR光谱, 比较采用径向基核函数、 多项式核函数和S形核函数的SVR模型在估算多种植被叶片氮、 磷、 钾元素含量方面的有效性和稳健性, 加深我们对利用VNIR光谱和SVR模型进行植被生化参数反演的理解。
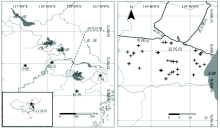
宜兴市地处江苏省南部(31° 07'— 31° 37'N, 119° 31'— 120° 03'E), 属亚热带季风区, 四季分明, 年平均气温16 ℃, 年平均降水量1 498.8 mm。 该市南部为低山丘陵, 北部为平原低洼, 土地肥沃, 主要植被种类包括北部的水稻、 小麦、 茶叶等农作物和南部的毛竹等林木。
2010年8月11日— 14日采集了包括水稻(14个)、 玉米(13个)、 芝麻(12个)、 大豆(11个)、 茶叶(11个)、 草地(13个)、 乔木(10个)和灌木(11个)在内的八种植被共计95个叶片样本, 每类植被中的样本点均随机选取(图1), 采样时记录下每个样本点的地理坐标, 并将剪下的新鲜植被叶片用塑料袋保存好, 当天送回实验室进行室内分析。
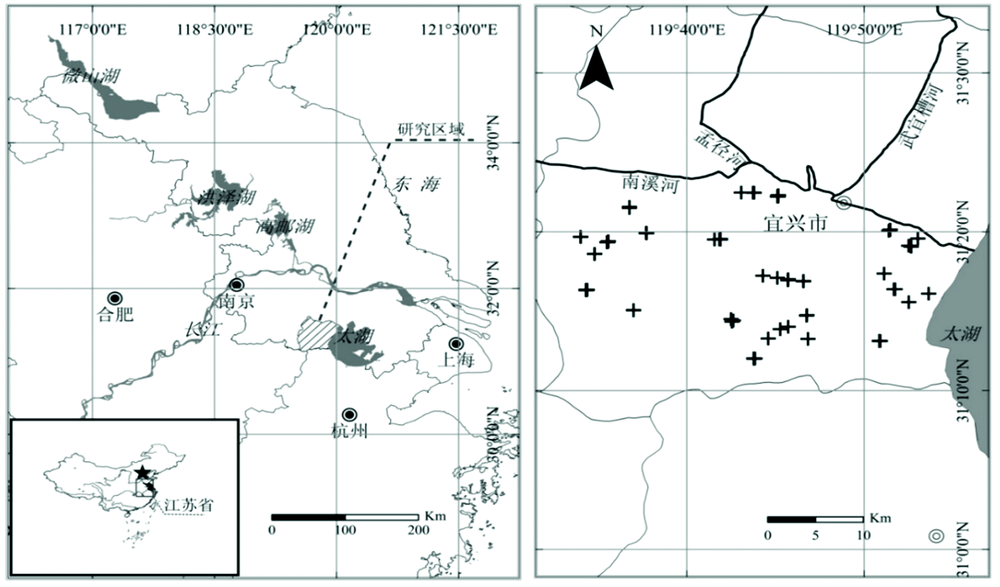 | 图1 研究区域(a)和采样点(+)分布图(b)Fig.1 Maps showing the Yixing region in China (dashed area) (a) and the distribution of sampling sites (+) (b) |
采用ASD FieldSpec3地物光谱仪测量植被叶片反射光谱。 光谱范围为350~2 500 nm, 其中350~1 000 nm之间采样间隔为1.4 nm, 1 000~2 500 nm之间为2 nm。 光谱测量在暗室进行, 将当天采集的新鲜叶片样本均匀铺盖在无反射的黑色托盘内, 采用50 W卤素灯作唯一光源, 光源距离样本中心30 cm, 入射角为15° , 光谱仪探头位于样本垂直上方15 cm, 其视场角为25° 。 测试前先对仪器进行标准白板校正, 测试过程中每测六个样本便重新校正一次, 确保测量稳定。 每个样本采集10条光谱曲线, 进行算术平均, 得到样本点的光谱反射率数据。
植被叶片样本经过光谱测量后, 分别进行叶片氮、 磷、 钾元素含量的化学分析。 其中叶片中氮元素的含量采用凯氏定氮法测定, 磷元素的含量采用钼锑抗比色法测定, 钾元素的含量采用火焰光度计法测定[8]。
对分析得到的氮、 磷、 钾元素含量数据分别进行异常点检测, 当某一样本落在样本集学生化残差± 2.5范围之外且大于两倍平均杠杆值时, 将其视作异常点予以剔除, 以此确保模型的准确度。 经计算, 氮元素样本集中剔除了两个异常点, 磷元素样本集中剔除了两个异常点, 钾元素样本集中剔除了两个异常点。
去除叶片反射光谱中噪声较大的350~399和2 401~2 500 nm边缘波段, 选取400~2 400 nm波段以10 nm为间隔进行重采样, 得到401~2 391 nm波段原始反射光谱。 在结合前人研究的基础之上, 采用三种光谱预处理方法消减背景噪声, 首先对原始反射光谱进行一阶微分变换(
1.4.1 支持向量回归及核函数
支持向量模型可表述为
式中K(xi, x)为核函数, xi为输入向量(本研究中为光谱反射率数据), x是用于计算更高维特征空间的数据项, yi为输出向量(本研究中为生化组分含量), ai为拉格朗日因子矩阵, n为样本数量, b为残差, C为正则化参数, 用以控制超出误差的样本的惩罚程度。 核函数可将非线性关系映射到高维空间中, 构建线性回归进行处理, 本研究分别采用了多项式核函数[式(2)], 径向基核函数[式(3)]和S形核函数[式(4)]
其中c, d, k, σ , ϑ 和k'等核函数中的参数由优化算法确定[11]。
1.4.2 模型建立与验证
从样本集中随机选取70%(65个)样本作为校正集, 针对每一种核函数, 在Matlab2010b环境下利用LIBSVM工具箱进行支持向量回归模型的校正[12]。 三种核函数中的参数采用网格参数寻优法和五折交叉验证确定, 取交叉验证过程中均方根误差(root mean square error, RMSE)最小时所对应的各参数为最优值[8]。 剩余30%(28个)样本作为验证集, 以检验校正所得SVR模型的表现, 模型精度评价指标采用决定系数(determination coefficient, R2)和相对分析误差(ratio of performance to standard deviate, RPD)。 上述评价指标中, R2越大, 模型预测效果越好, 此外, 当RPD在1.4~2时, 表示模型有一定的预测能力, 在2~2.5时表示模型预测能力良好, 大于2.5时则表明模型有很好的预测能力。
为减少随机抽样建模所导致的误差, 采用bootstrapping方法, 对原始93个样本进行有放回的抽样, 获得1000组校正集和验证集, 将上述模型校正和验证流程重复1 000次, 并计算出1 000次模型校正和验证的R2均值与RPD均值, 用以评价基于不同核函数的模型表现。
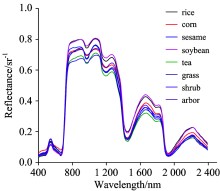
植被叶片样本生化组分含量统计如表1所示, 不同种类植被叶片的氮、 磷、 钾元素含量差异较大, 可达10倍以上。 八种植被叶片的平均反射光谱曲线总体形态比较一致, 反射率高低存在差异, 如图2所示。 其中在550 nm附近因叶绿素的弱吸收而形成反射峰, 700至750 nm区间内出现反射率增长最快的“ 红边” (red edge), 780~1 300 nm近红外波段区间反射率较高, 主要是叶片细胞组织反射造成, 1 450和1 950 nm附近的反射谷则主要是由水分的吸收引起。
| 表1 植被叶片样本氮、 磷、 钾元素含量统计 Table 1 Descriptive statistics of the contents of nitrogen (cN), phosphorus (cP) and potassium (cK) of plant leaf samples |
 | 图2 八种植被叶片平均反射光谱曲线Fig.2 The average original reflectance spectra of leaf samples from eight kinds of plants |
对植被叶片氮、 磷、 钾元素含量与预处理光谱及原始光谱的相关关系进行分析, 其结果如图3所示。 叶片原始光谱与各生化组分含量之间的相关系数都比较小(cN: -0.22~0.20, cP: -0.21~0.19, cK: -0.37~0.12), 经预处理后的光谱与三种含量之间的相关系数都有显著增大, 某些波段达到0.05显著性水平。 而三种预处理方法对相关关系的提升作用相当, 与一阶微分变换相比(最大相关系数分别为cN: 0.54, cP: 0.63和cK: -0.66), 进一步采用SNV变换或Log(1/R)变换仅略微提高相关关系(< 0.03)。
 | 图3 植被叶片cN, cP, cK与预处理光谱的相关性 注: 虚线代表生化组分含量与原始光谱的相关性(a): 一阶微分变换与cN; (b): 一阶微分和SNV变换与cN; (c): 一阶微分和Log(1/R)变换与cN; (d): 一阶微分变换与cP; (e): 一阶微分和SNV变换与cP; (f): 一阶微分和Log(1/R)变换与cP; (g): 一阶微分变换与cK; (h): 一阶微分和SNV变换与cK; (i): 一阶微分和Log(1/R)变换与cKFig.3 Correlations of the contents of nitrogen (cN), phosphorus (cP) and potassium (cK) against the original reflectance (dash line) and their derived values with different pre-processing methods Note: the dashed lines refer to the correlations between the biochemical components and original reflectance spectra (a): First derivative; (b): first derivative plus standard normal variate (SNV); (c): First derivative plus absorbance transformation (Log(1/R)) for cN; (d): First derivative; (e): First derivative plus SNV; (f): First derivative plus Log(1/R) for cP; (g): First derivative; (h): First derivative plus SNV; (i): First derivative plus Log(1/R) for cK |
利用三种不同预处理方法和三种核函数, 建立支持向量机回归模型估算植被叶片氮、 磷、 钾元素含量, 其结果如表2所示。 总体上看, 基于RBF核函数模型的精度最佳, 多项式核函数模型结果次之, 而S形核函数模型效果最差。 模型校正结果显示, 基于一阶微分变换的RBF核函数模型对三种组分含量的反演结果最优; 模型验证结果表明, 基于一阶微分和Log(1/R)变换的RBF核函数模型对氮、 钾元素含量的反演精度最佳(cN: 平均R2=0.64, 平均RPD=1.67; cK: 平均R2=0.56, 平均RPD=1.48), 而基于一阶微分变换的RBF核函数模型则是磷元素的最佳估算模型(平均R2=0.68, 平均RPD=1.73)。 分别选出验证过程中R2最高的模型, 其对生化组分含量的预测值与实测值在0.05显著性水平下均存在强相关性(cN: R2=0.85, RPD=2.63; cP: R2=0.87, RPD=2.80; cK: R2=0.83, RPD=2.30), 如图4所示。
| 表2 基于径向基核函数、 S形核函数和多项式核函数的植被叶片cN, cP, cK估算SVR模型结果 Table 2 Performances of support vector regression models with radial basis function kernel, sigmoid kernel and polynomial kernel for estimating the contents of nitrogen (cN), phosphorus (cP) and potassium (cK) of plant leaves |
 | 图4 验证过程中R2最高模型的预测表现 (a): cN; (b): cP; (c): cKFig.4 Performance of the best models for estimating the contents of nitrogen (cN) (a), phosphorus (cP) (b) and potassium (cK) (c) with the validation dataset |
基于RBF核函数的SVR模型对植被叶片氮、 磷、 钾元素含量的预测优于S形核函数和多项式核函数模型。 植被叶片生化组分含量与其VNIR光谱之间的关系通常是非线性的, 且会受到叶片生化组分特征及实验条件的影响。 RBF核函数(也称高斯核函数)能够实现高维空间的非线性映射, 即使在样本分布未知情况下, 其旋转对称性可确保不造成大的偏差[5], 而S形核函数在某些参数条件下不满足核函数半正定性要求, 其应用会受到限制[13]。 此外, 与多项式核函数和S形核函数相比, RBF核函数的待优化参数较少, 模型复杂度更低, 稳健性更好。 综合他人研究[6]和本实验结果, 基于VNIR光谱和支持向量机进行植被叶片生化组分含量估算时, 可优先考虑RBF核函数。
传统的估算植被生化参数方法包括多元线性回归(MLR)和偏最小二乘回归(PLSR)。 多元线性回归法一般选择若干个波段参与运算, 但波段选择没有考虑植被的吸收特征, 容易忽略与目标参数密切相关的光谱信息; 偏最小二乘回归是多元线性回归与主成分分析(PCA)的组合, 克服了波段选择和多元共线性的不足, 但与多元线性回归同属线性方法, 对非线性关系的处理能力有限[6]。 本工作所用的支持向量机回归方法, 通过合适的核函数将非线性关系映射到高维空间, 可有效处理变量间非线性关系; 若干研究对比了PLSR和SVR对非线性关系数据的建模预测能力, 发现SVR表现更佳[6, 14]。 人工神经网络(ANN)法在处理非线性问题时同样有较好的效果[15], 但其存在模型物理意义不明、 模型过拟合等不足[7]。 因此, 在利用植被叶片光谱进行生化组分参数估算时, 基于RBF核函数的支持向量机回归模型具有很大潜力。
基于RBF核函数的支持向量机回归模型, 针对八种不同植被叶片的光谱数据, 估算氮、 磷、 钾等三种元素含量的平均精度为0.64, 0.68和0.56, 最佳精度可达0.85, 0.87和0.83。 Yao等[7]利用支持向量机方法估算小麦叶片氮含量的精度可达0.78, Axelsson等[14]结合各种支持向量机方法基于景观尺度的红树林高光谱数据反演其叶片的氮、 磷、 钾、 钙等化学元素的含量, 发现只有氮元素的反演结果令人满意(R2=0.67)。 与这些研究相比, 本工作所得模型精度适中, 稳健性较好, 表明建立一个针对混合植被类型的多生化参数估算模型是可以实现的。 然而本研究采用的是基于植被叶片尺度的室内光谱测量, 对模型在不同季节, 不同尺度, 不同光谱数据时的适用性, 还需进一步验证; 同时, 对于其他潜在的光谱预处理方法和核函数模型, 也有待进一步探究比较。
利用八种植被叶片的可见-近红外光谱数据, 结合不同光谱预处理方法, 构建了基于径向基核函数、 多项式核函数和S形核函数的支持向量回归模型, 并比较这三种不同核函数的模型估算叶片氮、 磷、 钾元素含量的表现。 得到结论如下: (
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|