
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱数据处理算法的小麦赤霉病籽粒识别
[刘爽1, 2  , 谭鑫
, 谭鑫1, * , 刘成玉3, 4 , 朱春霖1, 2 , 李文昊1 , 崔帅4 , 杜懿峰4 , 黄殿成4 , 谢锋3, 4 ]
, 谭鑫, 刘成玉|
|


作者简介: 刘 爽, 1994年生, 中国科学院长春光学精密机械与物理研究所硕士研究生 e-mail: liushuang_0730@163.com
赤霉病是小麦的一种主要病害, 它会导致小麦减产甚至绝收, 严重影响小麦种子质量, 此外小麦受侵染分泌的真菌毒素危害人类身体健康。 因此, 小麦赤霉病籽粒的识别具有非常重要的意义。 起初普遍采用色谱法和酶联免疫法进行赤霉病检测, 这些方法设备昂贵、 检测速度慢、 准确性低。 近年来, 高光谱成像技术被广泛应用于农作物的识别与检测中, 但是在小麦赤霉病检测的应用研究中, 大多采用抽样检测的方法, 图像采集完成后需要通过ENVI软件手动选取感兴趣区域。 前期准备工作冗杂, 而且容易发生漏检, 漏检的小麦籽粒在存储运输过程中向周边籽粒快速侵染, 难以保障小麦安全健康。 鉴于此, 利用高光谱成像系统结合机器学习提出了一种用于对大量小麦赤霉病籽粒样本快速可视化识别的算法, 以降低漏检率并提升检测效率。 实验分别采集健康小麦和染病小麦469~1 082 nm波段的高光谱图像, 通过直方图线性拉伸结合图像分割的方法获取小麦样本的掩膜图像信息。 利用Savitzky-Golay平滑去噪法与标准正态变量变换法(SNV)进行数据预处理, 通过主成分分析法(PCA)和连续投影法(SPA)进行特征变量提取, 筛选特征变量个数分别为4个和8个。 在掩膜图像位置采集健康小麦样本与染病小麦样本各400份, 其中75%用于建模集, 25%用于测试集。 采用十折交叉验证法结合线性判别分析法(LDA) 、 K-近邻算法(KNN)、 支持向量机(SVM)分别建立分类模型, 测试集准确率都达到90%以上。 随后比较了网格法(GRID)、 粒子群算法(PSO)、 遗传算法(GA)三种核参数寻优方法对SVM模型的影响, 其中, SG-SPA-SVM(PSO)模型分类效果最优, 建模集准确率为95.5%, 均方根误差为0.212 1, 测试集准确率为98%, 均方根误差为0.141 4。 基于样本点预测的基础之上, 对掩膜获得所有小麦样本的光谱曲线进行预测并将识别结果反馈回掩膜中再进行伪彩色显示, 实现染病籽粒可视化识别。 结果表明, 高光谱成像结合SG-SPA-SVM(PSO)算法建立的分类模型可以高效快速、 准确无损、 可视化的实现小麦赤霉病籽粒识别, 为研制小麦赤霉病自动识别设备提供了算法基础。
, TAN Xin, LIU Cheng-yuFusarium head blight (FHB) is a major disease of wheat, which can lead to wheat yield reduction or even crop failure, seriously affecting the quality of wheat seeds. Mycotoxins secreted by the diseased wheat are deposited in the food chain, and ultimately endanger human health. Therefore, recognition of wheat scab is very important. First of all, chromatography and enzyme-linked immunosorbent assay (ELISA) are widely used to detect scab. These methods were expensive, slow and have low accuracy. In recent years, hyperspectral imaging technology has been widely used in crop identification and detection, but in the application of wheat scab detection, sampling detection method is mostly used. After image acquisition, the region of interest (ROI) is manually selected through ENVI software. Preliminary preparations are complicated and easy to be missed detection. The undetected wheat grains quickly infect the surrounding grains during storage and transportation, which is difficult to ensure the safety and health of wheat. In view of this, this paper presents a fast visual recognition algorithm for wheat scab samples based on hyperspectral imagery and machine learning to reduce the rate of missed detection and improve the detection efficiency. The hyperspectral images of healthy wheat and infected wheat in 469~1 082 nm band were collected, and the mask image information of wheat samples was accurately obtained by histogram linear stretching combined with image segmentation. Savitzky-Golay smoothing denoising method and standard normal variable transformation (SNV) method are used for data preprocessing. Principal component analysis (PCA) and successive projections algorithm (SPA) were used to extract features, and 4 and 8 feature variables were selected respectively. There were 400 healthy wheat samples and 400 infected wheat samples collected in the mask image position, 75% of which were used for modeling set and 25% for testing set. Ten fold cross validation method combined with linear discriminant analysis (LDA), K-nearest neighbor algorithm (KNN) and support vector machine (SVM) was used to establish the classification model. The accuracy of the test set is over 90%, and the SPA dimension reduction model is better than the PCA dimensionality reduction model. Then, the effects of GRID, particle swarm optimization and GA three kernel parameter optimization methods on SVM model are compared. Among them, SG-SPA-SVM (PSO) model has the best classification effect. The accuracy of modeling set is 95.5%, REMS is 0. 2121, the accuracy of test set is 98%, and REMS is 0.141 4. Based on the prediction of sample points, the spectral curves of all wheat samples obtained by the mask were predicted and the recognition results were fed back to the mask and displayed in pseudo-color to realize the visual identification of infected grains. The results show that the classification model based on hyperspectral imaging technology combined with SG-SPA-SVM (PSO) algorithm can effectively, quickly, accurately, nondestructively and visually identify wheat scab, providing an algorithm basis for the development of automatic identification equipment for wheat scab.
保障粮食作物的品质安全一向被国内外广泛研究, 小麦作为世界上最重要的粮食作物之一也是研究重点[1, 2]。 赤霉病是小麦的一种主要病害, 它会导致小麦减产, 严重时甚至绝收。 小麦受真菌侵染时会分泌脱氧雪腐镰刀菌烯醇(deoxynivalenol, DON), 该毒素被列为第三类致癌物, 人畜食用后会导致急性中毒。 目前主要通过高效液相色谱法、 酶联免疫法等生物化学方法对小麦赤霉病籽粒进行检测[3]。 但由于以上方法所需设备昂贵, 准确性和重复性较差, 容易出现假阳性或假阴性现象, 难以保障小麦安全健康[4]。 因此小麦赤霉病高效快速、 准确无损的检测方法对保障小麦食品安全具有重要意义。
高光谱成像技术将光谱分析技术与数字成像技术相结合, 不仅可以获得样本大量波段的空间图像信息, 而且可以获得每一像素点的光谱信息, 由于其灵敏度高、 测量速度快、 抗干扰能力强等特点, 广泛应用于无损检测、 病害检测等食品安全领域中[5, 6, 7]。 Barbedo等利用高光谱成像技术检测小麦籽粒中的游离脂肪酸, 并用来估计小麦籽粒中DON浓度[8]。 梁琨等通过高光谱成像技术, 基于染病小麦的特征波长图像建立的小麦赤霉病籽粒识别模型[9]; 杜莹莹等通过高光谱成像技术完成了对6种不同等级的小麦脱氧雪腐镰刀菌烯醇含量进行鉴别[10]。
以上研究成果表明高光谱成像技术在小麦赤霉病籽粒的识别上有重要前景。 现阶段高光谱成像技术在小麦赤霉病检测的应用研究中大多采用抽样检测的方法, 高光谱图像数据采集完成后需要手动选取样本区域。 面对大量数据, 若选择抽样检测获得样本染病情况并估算总体染病率, 难以对病粒进行定位, 容易发生漏检导致健康小麦受到的感染, 造成难以估量的损失。 若全数检测又由于前期准备工作冗杂难以实现快速连续识别。 针对以上存在问题, 结合高光谱成像技术与机器学习算法提出一种用于对大量小麦赤霉病籽粒样本快速可视化识别的算法, 以降低漏检率并提升检测效率, 为研制小麦赤霉病自动识别设备提供了算法基础。
实验所用小麦籽粒样本由“ 第二粮仓” 计划示范农场— — 安徽龙亢农场提供, 其籽粒饱满, 呈椭圆状, 共有三份样品, 一份样品包含240粒健康小麦, 一份样品包含273粒受赤霉病侵染的小麦, 一份样品由染病小麦与健康小麦各50%混合组成共256粒。
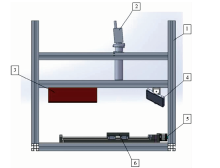
高光谱成像系统如图1所示, 系统主要包含高光谱成像仪、 光源、 电控位移平台、 样品台、 反射镜、 暗箱、 计算机等主要部件。 高光谱成像仪由中国科学院上海技术物理研究所杭州大江东空间信息技术研究院研制, 成像波谱范围为469~1 082 nm, 光谱分辨率2.3 nm, 共270个波段, 线视场含480个像素, 镜头焦距为35 mm, 光源为21 V/150 W溴钨灯光源(卓立汉光)。 将待测样本均匀平铺在白色背景板上并放置在位移平台中部, 测量时扫描速度为3 mm· s-1, 镜头与样本距离为300 mm, CCD积分时间为10 ms。
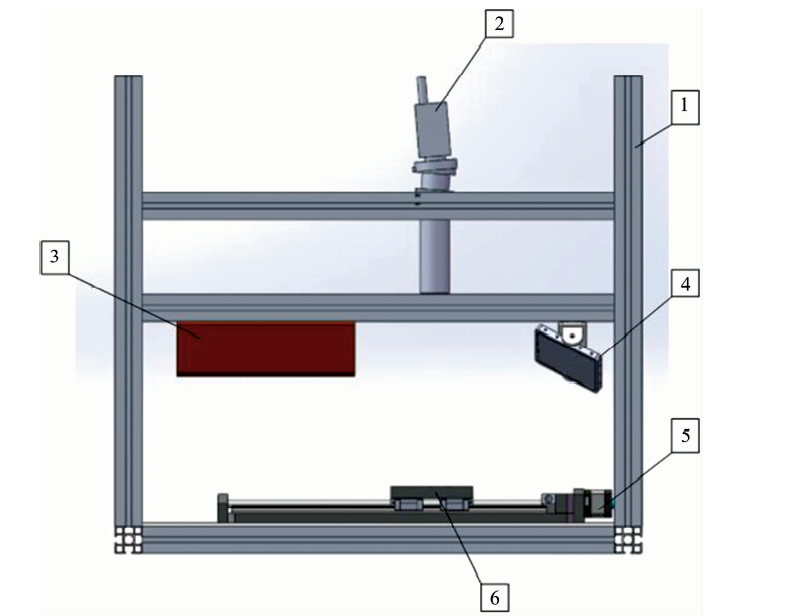 | 图1 高光谱成像系统结构示意图 1: 暗箱; 2: 高光谱成像仪; 3.光源:4: 反射镜; 5: 电动位移平台; 6: 样品台Fig.1 Schematic diagram of hyperspectral imaging system 1: Black box; 2: Hyperspectral imager; 3: Light; 4: Mirror; 5: Electric displacement platform; 6: Sample table |
分别采集赤霉病染病率为0%, 50%和100%的三组小麦籽粒的高光谱图像。 高光谱成像仪所获得的原始数据中每一点的数据值反映CCD记录的光信号强度, 需要通过辐射校正将其转换为反射率信息, 使用辐射校正可以有效减小传感器暗电流噪声和光强变化对图像信号产生的影响。 辐射校正公式为
式中I0为原始高光谱数字图像, Ib为反射率为0的高光谱数字图像, 通过盖住镜头盖获得; Iw为反射率为1的标准反射率板获得的高光谱数字图像, Rc为辐射校正后的高光谱数字图像。 高光谱图像数据分析与处理通过ENVI 5.1(美国Boulder公司)和Matlab 2016a(美国TheMath Works公司)完成。
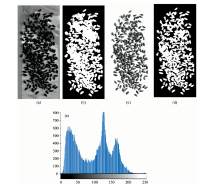
利用图像分割的方法获取小麦样本掩膜以得到小麦籽粒位置。 以健康小麦高光谱图像为例, 选择成像清晰且样本与背景区分明显的波段图像(实验选用539.2 nm波段), 利用大津法计算阈值, 提取图像掩膜。 由于光照不均、 籽粒阴影等原因, 在籽粒摆放较多的地方分割效果并不理想如图2(a和b)所示。 由灰度直方图(e)可以看出, 图像灰度分布主要集中在三段区间, 其中小麦籽粒灰度主要集中在0~70, 利用直方图线性拉伸的方法增强图像, 再通过大津法进行图像分割效果良好, 如图2(c和d)所示。 通过同样方法获得染病小麦图像掩膜。
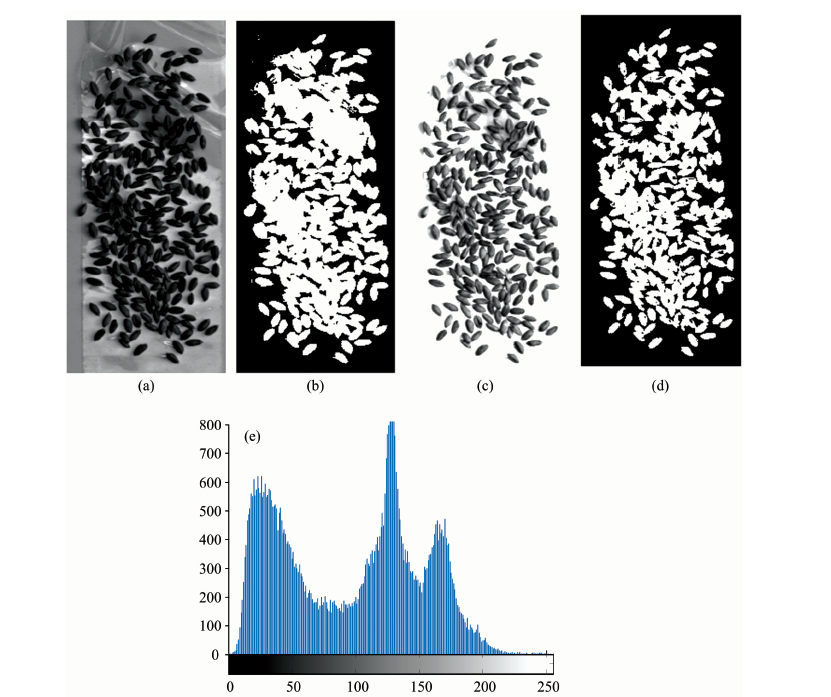 | 图2 健康小麦高光谱图像 (a): 539.2 nm波长下原始图像; (b): 图a的二值图; (c): 对图a直方图线性拉伸; (d): 图c的二值图; (e): 图a的灰度直方图Fig.2 Healthy wheat hyperspectral image (a): Original image at 539.2 nm wavelength; (b): Binary image of figure a; (c): Histogram linear stretching of figure a; (d): Binary image of figure c; (e): Gray histogram of figure a |
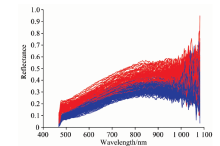
在掩膜中各随机取400个点的光谱数据作为健康小麦与染病小麦样本, 如图3所示。 由于高光谱成像仪的成像原理, 在光谱波段靠近两端的临界区会有较强的机器噪声, 因此选用480~922 nm波段噪声较弱的光谱数据进行后续处理。 由图像可以看出, 健康小麦和染病小麦样本的平均光谱反射率曲线形状大体相似, 但染病样本反射率要高于健康样本。
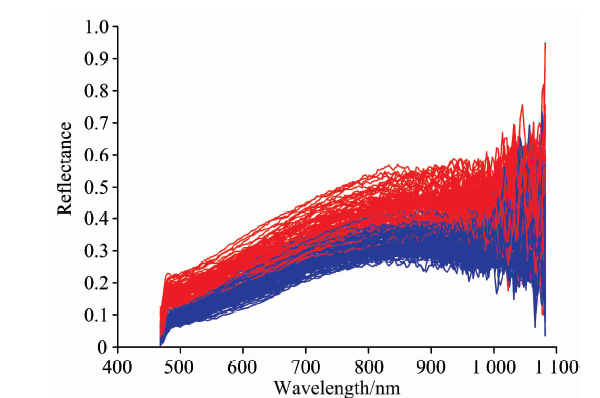 | 图3 小麦样本反射率光谱Fig.3 Reflectance spectra of wheat samples |
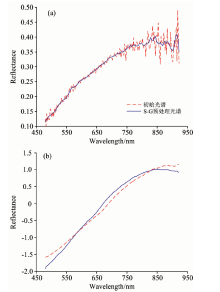
高光谱数据会受光源不稳定性、 系统暗噪声、 光照不均匀等因素的影响。 预处理算法可以减少噪声信号对样本数据的干扰, 保障预测模型的精度与稳定性。 比较Savitzky-Golay卷积平滑算法和标准正态变量变换(standard normal variable transformation, SNV)两种算法对样本高光谱数据预处理效果。 小麦样本光谱曲线经过SG算法平滑后有效减少了噪声的影响, 如图4(a)所示。 SNV算法可以有效消除固体颗粒大小、 表面散射所带来的光谱误差, 但由于两种光谱的曲线趋势相似, 标准化后差异较差如图4(b)所示。
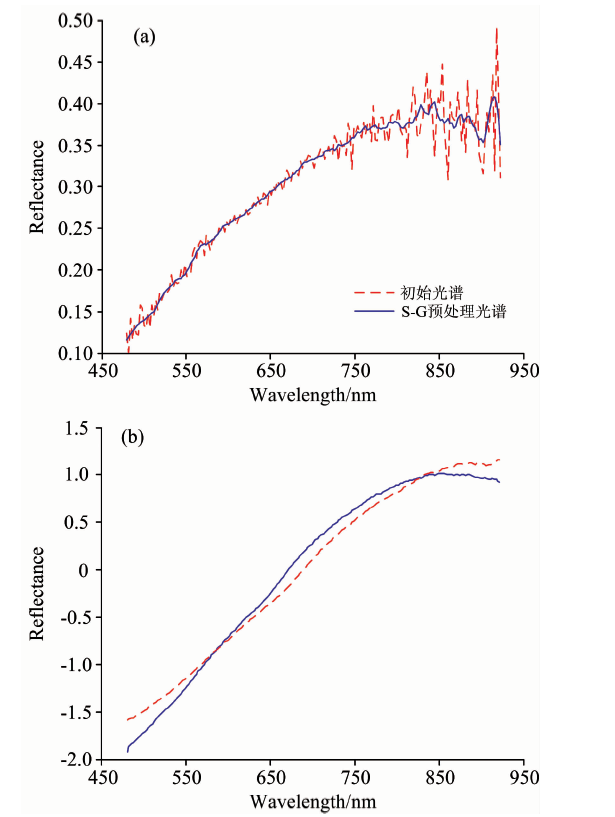 | 图4 小麦样本预处理光谱曲线Fig.4 Spectrum curve of wheat preprocessing |
高光谱数据具有波段多、 数据量大、 冗余性强等特点, 在提高数据信息量的同时也使得数据处理速率变慢。 通过特征提取算法选择数据中的重要波段或较少的综合变量来代替原有数据, 既降低数据的维度又保留大部分信息。 实验中特征提取采用主成分分析法(principal component analysis, PCA)和连续投影算法(successive projections algorithm , SPA)两种方法进行对比。
利用PCA算法对SG预处理后的高光谱数据进行特征提取, 得到前4个主成分贡献率依次为: 86.500 3%, 10.769 5%, 1.657 8%和0.425 7%。 前4个主成分累计贡献率已经达到了99.3533%, 说明前4个主成分分量就可以很好的表示原高光谱数据99%以上的信息量。 图5表示了样本数据在PC1, PC2和PC3三维空间下的分布情况, 由图5可知健康小麦与染病小麦样本在经过PCA变换后有一定的聚类效果, 具有较好的分类能力。
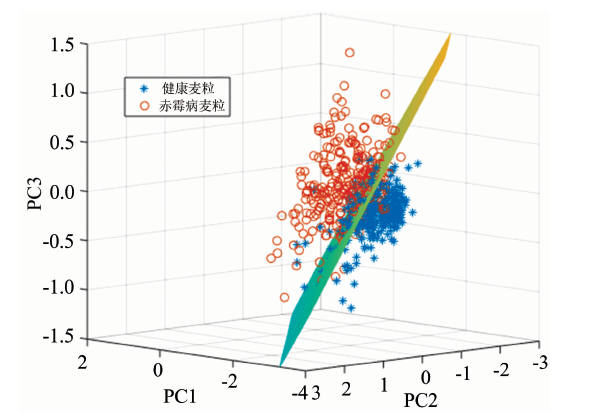 | 图5 主成分分析结果Fig.5 Principal component analysis results |
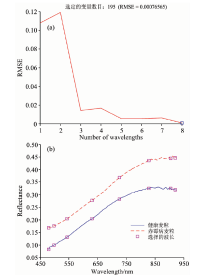
利用SPA算法对SG预处理后的高光谱数据进行特征波长选择, 图6(a)表示当RMSE最小为0.000 77时采用8个波长进行建模, 图6(b)表示样本数据基于SPA算法变量筛选后的8个特征波长为: 479.9, 498.2, 543.8, 630.5, 726.2, 828.9, 904.1和920.1 nm。
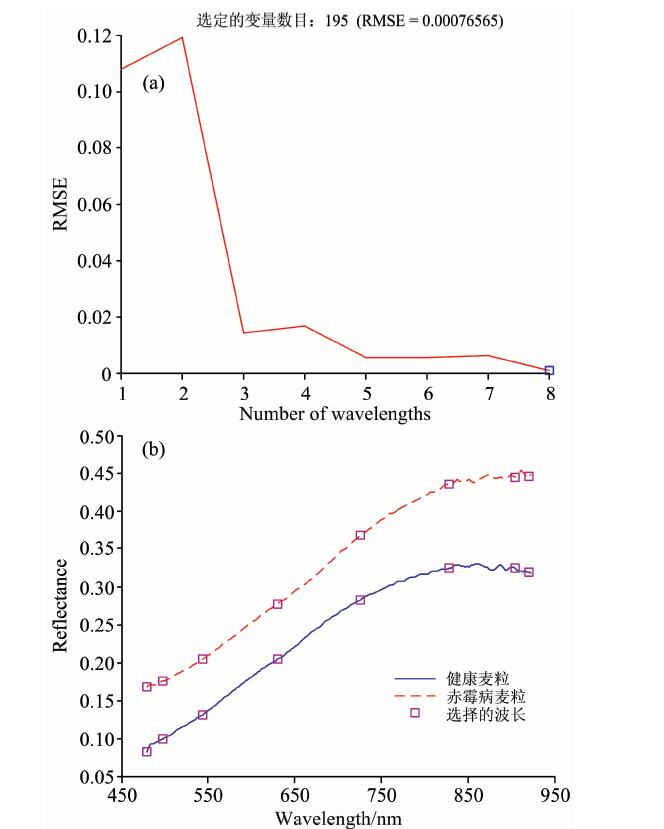 | 图6 基于SPA的特征波长选择Fig.6 Feature wavelength selection based on SPA |
利用线性判别分析法(linear discriminant analysis, LDA)、 K近邻算法(K-nearest neighbor algorithm, KNN)、 支持向量机(support vector machine, SVM)结合十折交叉验证法建立小麦赤霉病籽粒识别模型。 首先将健康小麦与染病小麦样本记录标签然后随机打乱, 每类样本中75%用于建模集, 25%用于测试集。 利用LDA对预处理算法进行分析, 对测试集进行预测结果如表1所示。 结果表明通过SG预处理后的数据所建模型要远优于SNV预处理的结果。
| 表1 LDA模型识别结果 Table 1 Recognition results of LDA model |
对SG预处理后的数据进行PCA和SPA两种降维变换, 再通过LDA, KNN和SVM三种方法分别建立分类模型进行比较。 其中, 同样结合采用十折交叉验证法建立模型, KNN算法中采用欧式距离公式计算临近9个点的距离, SVM采用高斯径向基核函数(RBF)为核函数, 并利用网格搜索法对核参数进行寻优计算。 采用kappa系数对分类结果做出评价, kappa系数是基于分类混淆矩阵的评价参数, 计算方式如式(2)所示, 其中下标中的+表示行或列的求和, Nte为测试样本总数。 三种分类器分类结果如表2所示, 可以看出SVM的建模效果要优于LDA与KNN, 且SPA降维数据所建模型性能要优于PCA, 即SG-SPA-SVM建立的模型最优, 建模集准确率达到95.33%, 测试集准确率达到97.0%, kappa系数为0.94。
| 表2 3种分类模型识别结果 Table 2 Recognition results of three classification models |
SVM的RBF核函数中包含有两个重要参数: 惩罚系数c和核宽度参数g对建模效果产生影响。 比较网格搜索法(GRID)、 粒子群算法(PSO)以及遗传算法(GA)对参数c和g寻优效果, 以提高模型精度。 识别结果如表3所示, 基于PSO寻优得到的c, g建立模型最优, 测试集准确率提升达到98%, 其中c为6.964 4, g为36.758 3, Kappa系数值为0.96。
| 表3 3种核参数寻优模型识别结果 Table 3 Recognition results of three nuclear parameter optimization models |
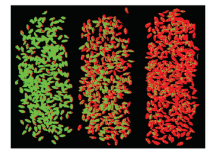
基于样本点预测的基础之上, 根据掩膜获得所有小麦样本的光谱曲线, 利用该最优分类模型SG-SPA-SVM(PSO)进行赤霉病籽粒的识别实验, 将掩膜下每一点的识别结果反馈回掩膜中并进行伪彩色显示, 实现染病籽粒可视化识别, 如图7所示。 图像中绿色表示小麦籽粒健康, 红色表示小麦籽粒染病, 从左到右三堆小麦籽粒的染病率依次为0%, 50%和100%。 结果表明, 小麦籽粒染病情况的预测结果与实际情况吻合度很高, 仅由于在小麦边缘由于三维结构与光照角度的因素使得采集的光谱数据不够准确发生少量误判, 但是在实际应用中可以轻易辨别, 说明本文所建立的赤霉病籽粒识别模型具有较高的准确性。
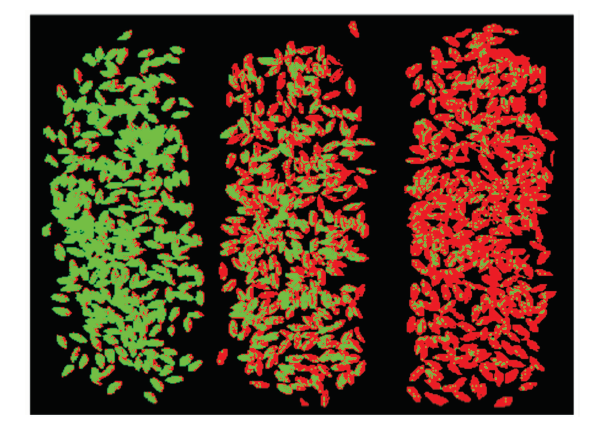 | 图7 小麦赤霉病可视化识别图像Fig.7 Visual recognition image of wheat fusarium head blight |
小麦赤霉病快速识别是粮食食品安全领域亟待解决的问题。 利用高光谱成像系统采集的高光谱图像结合机器学习提出了一种用于对大量小麦赤霉病籽粒样本快速可视化识别的算法。 实验结果表明: (1)预处理算法中, SNV算法在标准化数据的同时使得光谱差异变小, 相较之下SG算法更好的平滑光谱曲线; (2)PCA和SPA分别将高光谱数据维度减到4和8, 大量减少了数据的冗余程度, 分类结果表明SPA略优于PCA; (3)采用LDA, KNN和SVM结合十折交叉验证法建立分类模型, 其中SVM算法建模识别效果最优; (4)对比GRID, PSO和GA三种SVM核参数寻优方法, SG-SPA-SVM(PSO)算法识别效果最好, 建模集准确率为95.5%, REMS为0.212 1, 测试集准确率为98%, REMS为0.141 4。 (5)结合掩膜与分类模型, 对所有小麦样本的光谱曲线进行识别预测, 并将预测结果反馈回掩膜中进行伪彩色显示, 实现染病籽粒可视化识别。 基于高光谱数据处理算法可以高效快速、 准确无损、 可视化的实现小麦赤霉病籽粒识别, 为研制小麦赤霉病自动识别设备提供了基础。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|