

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
残差网络分层融合的高光谱地物分类
[张怡卓 , 徐苗苗, 王小虎, 王克奇
, 徐苗苗, 王小虎, 王克奇* ]
, 徐苗苗, 王小虎, 王克奇]
|
|


作者简介: 张怡卓, 1978年生, 东北林业大学机电工程工程学院教授 e-mail: nefuzyz@163.com
高光谱图像具有较高的空间分辨率, 蕴含着丰富的空间光谱信息, 近年来被广泛用于城市地物分类中。 在高光谱图像分类过程中, 空间光谱特征的提取直接影响着分类精度; 传统的高光谱图像特征提取方法只利用了4或8邻域的像素进行简单卷积处理, 因而丢失了大量的复杂、 有效信息; 卷积神经网络(CNN)虽然可以自动提取空间光谱特征, 在保留图像空间信息的同时, 简化网络模型, 但是, 随着网络深度增加, 网络分类产生退化现象, 而且网络间缺乏相关信息的互补性, 从而影响分类精度。 该工作引入CNN自动提取空间光谱特征, 并且针对CNN深度增加所导致的退化问题, 设计了面向地物分类的高光谱特征融合残差网络。 首先, 为了降低高光谱图像的光谱冗余度, 利用PCA提取主要光谱波段; 然后, 为了逐级提取光谱图像的空间光谱特征, 定义了卷积核为16, 32, 64的低、 中、 高3层残差网络模块, 并利用64个1×1的卷积核对3层特征输出进行卷积, 完成维度匹配与特征图融合; 接着, 对融合后的特征图进行全局平均池化(GAP)生成用于分类的特征向量; 最后, 引入具有可调节机制的Large-Margin Softmax损失函数, 监督模型完成训练过程, 实现高光谱图像分类。 实验采用Indian Pines, University of Pavia和Salinas地区的高光谱图像来验证方法有效性, 设置批次训练的样本集为100, 网络训练的初始学习率为0.1, 当损失函数稳定后学习率降低为0.001, 动量为0.9, 权重延迟为0.000 1, 最大训练迭代次数为2×104, 当3个数据集的样本块像素分别设置为25×25, 23×23, 27×27, 网络深度分别为28, 32和28时, 3个数据集的分类准确率最高, 其平均总体准确率(OA)为98.75%、 平均准确率(AA)的评价值为98.1%, 平均Kappa系数为0.98。 实验结果表明, 基于残差网络的分类方法能够自动学习更丰富的空间光谱特征, 残差网络层数的增加和不同网络层融合可以提高高光谱分类精度; Large-Margin Softmax实现了类内紧凑和类间分离, 可以进一步提高高光谱图像分类精度。
Hyperspectral images contain a wealth of feature information, and they have been widely used in urban feature classification in recent years. In the process of hyperspectral image classification, the extraction of spatial spectral features directly affects the classification accuracy. Traditional hyperspectral image feature extraction methods only use 4 or 8 neighborhood pixels for simple convolution processing, thus losing a lot of complex and effective information. Convolution neural network (CNN) can automatically extract spatial spectral features and retain the same spatial information of the image, and the network model is simplified. However, with the increase of network depth, the network classification will degenerate, and the network lacks complementarity of relevant information, which will affect the classification accuracy. In this paper, a hyperspectral residual network for feature classification is designed for the degradation problem. Firstly, define the residual network module of the low, medium and high three-layer structure with convolution kernels of 16, 32, and 64. Then, convolve the 3-layer output features with 64 1×1 convolution kernels to complete the dimension matching and feature map. Next, the global average pooling (GAP) of the feature map is generated to generate the feature vector for classification. Finally, the Large-Margin Softmax objective function is introduced to achieve hyperspectral image classification. The experiments were performed using hyperspectral images from the Indian Pines, University of Pavia, and Salinas regions. The primary bands of the hyperspectral image were extracted by PCA. With the sample set of batch training being 100, the initial learning rate being 0.1, the momentum being 0.9, the weight delay being 0.000 1, and the maximum number of training iterations being 2×104, when the sample sizes of the three data sets are set to be 25×25, 23×23 and 27×27, the network depth is 28, 32 and 28, the classification accuracy of the three data sets is the highest, and the average overall accuracy OA is 98.75%, the average accuracy AA is 98.1% and the average Kappa coefficient is 0.98. The experimental results show that the classification method based on residual network can get more affective features. It can improve the classification accuracy with the increase of the number of residual network layers and the fusion of complementary information of different network layer outputs; Large-Margin Softmax achieves intra-class compactness. Separation between classes further improves classification accuracy.
高光谱图像含有丰富的光谱信息, 这些信息是由可见光谱到红外光谱的数百个光谱带组成。 高光谱图像的每个像素点通过高维向量来表示, 对应于特定波长的光谱反射率。 近年来, 国内外学者提出了多种高光谱图像分类算法。 Jia等[1]将SVM用于高光谱图像分类, 但是, SVM只利用了高光谱图像的光谱信息, 没有考虑图像的空间信息。 随着稀疏理论的发展, 稀疏表达在高光谱图像分类中得到广泛研究。 2011年, Chen等[2]提出联合稀疏表示模型来进行高光谱图像分类, 该模型通过空间信息确定待测像元的类别, 有效地融合了高光谱图像的空间光谱特征, 但是, 当地物种类丰富时, 容易出现错分现象。 2014年, Zhang等[3]提出了非局部加权联合稀疏分类模型, 针对邻域像元对中心像元贡献值存在的差异进行了研究。 传统机器学习方法在高光谱图像分类中得到了很大的进展, 但是需要复杂的特征提取过程, 因而分类精度有待于进一步提高。
深度学习通过分层网络获取分层次的特征信息, 简化了复杂的人工设计特征过程, 成为高光谱图像分类的研究热点。 卷积神经网络(CNN)是深度学习的一个重要分支, 在高光谱图像分类中的应用越来越广泛[4, 5]。 2015年, Hu等[6]利用CNN网络模型对高光谱图像进行分类, 利用CNN的局部连接、 权值共享等特性, 减少了模型参数, 降低了训练难度, 提高了分类性能。 2016年, Zhao等[7]通过CNN和平衡局部判别嵌入算法提取高光谱图像的空间和光谱特征来进行高光谱图像分类; 但是, 基于CNN模型的分类算法仅包含单一卷积层, 降低了其特征学习的能力。 通过增加网络深度可以提高网络的性能, 尤其处理具有非常复杂的空间光谱特性的高光谱图像。 但是, 网络层数过多导致训练误差增大, 即退化现象, 使准确率达到一定值后迅速下降。 2018年, Zhong等[8]提出了基于残差网络的高光谱图像分类方法, 网络中的残差块通过恒等映射连接其他卷积层, 并且在每个卷积层上进行批量归一化, 解决了网络层数增加带来的负担, 在高光谱图像分类中具有很好的效果。 残差网络利用残差块学习有判别力的特征, 但是没有充分利用浅层和深层的互补和相关信息; 而且, 传统的softmax分类器没有明确地鼓励类内紧凑性和类间可分离性[9], 在进行复杂地物的分类时精确度不高。 基于深度学习的融合策略在图像分类中得到广泛研究[10, 11, 12]。 本工作引入残差网络进行特征提取, 并设计了残差网络中不同层次特征融合策略, 通过Large-Margin Softmax分类器实现高光谱图像的有效分类。
图1为高光谱图像的CNN特征提取和分类流程图, 为充分利用空间信息, 提取以待分类像素为中心的样本作为输入, 经过卷积、 池化和全连接一系列的操作, 输入到softmax分类器得到分类结果。 定义样本块经过卷积和池化的输出特征向量为x, softmax输出该样本块在各个类别的概率pj如式(1)所示
其中, C为类别总数; pj的最大值为该样本块的所属类别; fj表示全连接层输出向量的第j个元素, 其表达式如式(2)所示
其中, W表示网络权值。
网络的损失函数表示为
虽然CNN在图像分类中有着广泛的应用, 但是, 仅利用几个简单的卷积和池化层, 不能充分提取高光谱图像深层的特征以进行准确分类。 虽然可以通过增加网络深度提高CNN的性能, 但是过度增加网络深度将会使网络产生退化现象, 会导致CNN出现过拟合、 梯度消失和梯度爆炸等问题。
 | 图1 基于CNN的高光谱图像分类流程图Fig.1 The flow chart of hyperspectral image classification based on CNN |
残差网络为解决深层CNN出现的退化问题将深层网络后面的卷积层变为恒等函数。 让一些层去拟合一个恒等函数很困难, 所以把网络设计为
其中, x和H(x)分别表示一个残差块的输入和输出, F(x)是残差块学习的函数。
学习一个恒等映射函数转换为学习一个残差函数
当F(x)=0时, 就构成了恒等映射H(x)=x。 由于恒等映射没有引入额外的参数, 不会给网络增加额外的参数和计算量, 同时能够加快模型训练速度、 提高训练效果。
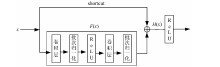
残差网络使用shortcut回路实现两个卷积层的优化[10], 即在两个卷积层的基础上叠加y=x的恒等映射, 将输入和输出相加。 加入shortcut后, 训练过程中误差可以通过恒等映射向上一层传播, 减弱层数过多造成的梯度消失现象, 残差块的基本结构如图2所示。 但是, 该网络忽视了不同网络层之间信息的互补性与相关性, 影响分类精度。
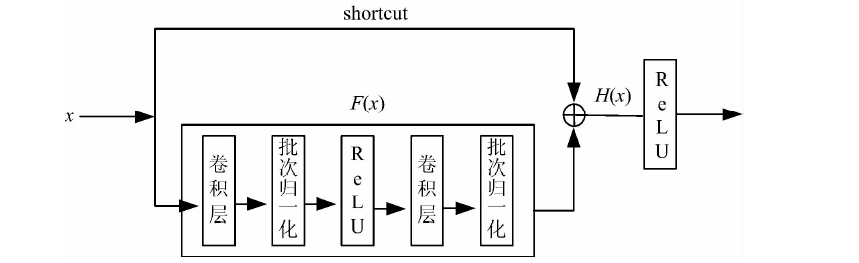 | 图2 残差块的基本结构Fig.2 The structure of the residual block |
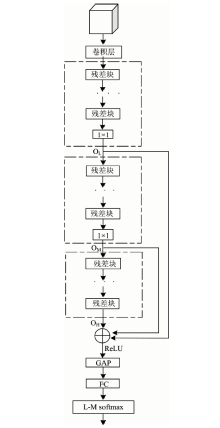
CNN中不同卷积层可以学习不同的特征, 浅层具有图像细节信息, 深层含有更多抽象信息。 为了充分利用不同层次特征信息, 将浅层特征与深层特征进行融合, 可以增强模型对复杂图像的表现能力, 图3为残差融合网络设计结构。
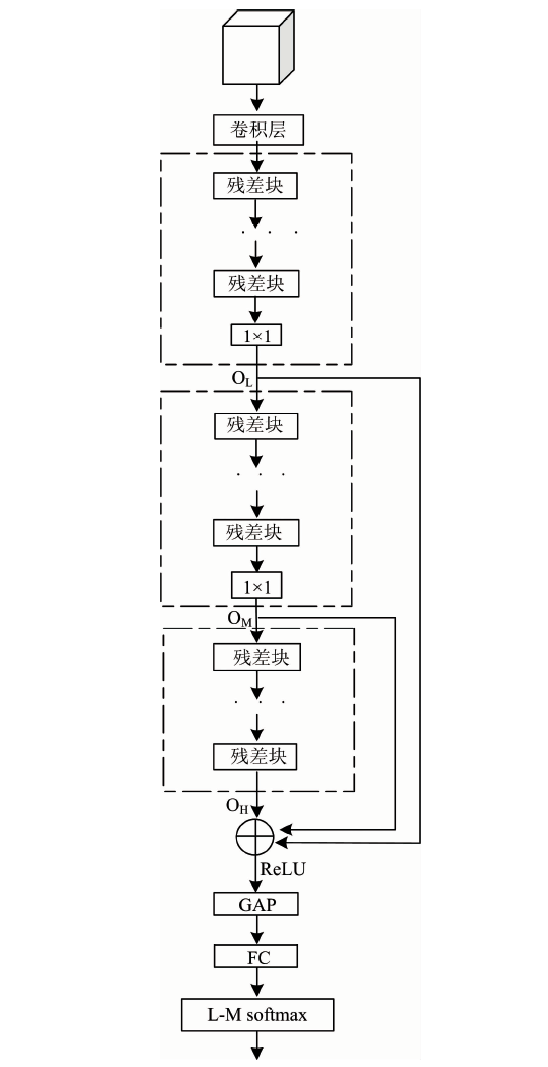 | 图3 基于残差网络多层融合分类算法流程图Fig.3 Flow chart of multi-layer fusion classification algorithm based on residual network |
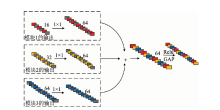
根据卷积核的数量将残差网络分为3个模块, 其中OL, OM和OH分别表示3个模块的输出; 在3个模块中分别具有16, 32, 64个卷积核, 输出不同维度的特征图, 实现特征信息的逐层提取。 为确保特征融合前具有相同的维度, 经过数量为64, 大小为1× 1的卷积核进行卷积完成维度匹配。 最后, 将3个模块的输出相加融合。 激活之后的融合特征图进行全局平均池化(GAP), 生成最终的特征图, 融合过程如图4所示。
 | 图4 多层特征融合过程Fig.4 Multi-layer feature fusion process |
最后, 将融合的特征图经过全连接网络转换成输出的特征向量, 输入到分类器进行分类。 传统的softmax分类器不能很好地学习到使类内紧凑、 类间分散的特征。 所以, 引入Large-Margin Softmax分类器。
以二分类问题为例, 假设一个样本块属于类别1, 由式(1)和式(2)可知, softmax是通过让p1> p2, 即
来进行分类, 可以写为
而Large-Margin softmax是将其变为
其中, m是正整数, 0≤ θ 1≤
通过增加一个正整数变量m, 产生一个决策余量, 能够更加严格地约束式(7)。
Large-Margin Softmax损失函数表示为
其中Ψ (θ )为
通过调节间隔m的值来调节分类边界, 式(8)对学习W1和W2提出了更高的要求, 使模型学习到类内距离更小、 类间距离更大的可区分性的特征。
实验选用的高光谱数据为Indian Pines, University of Pavia和Salinas 3个典型的数据源。 其中, Indian Pines是美国印第安纳州西北部农区的高光谱图像, 该数据有10 249个地物像素, 包括苜蓿(Alfalfa)、 玉米(Corn)、 燕麦(Oats)、 小麦(Wheat)、 木材(Woods)等16个地物类别; University of Pavia是意大利帕维亚城的一部分高光谱数据, 该数据有42 776个用于分类的地物像素, 包含树、 沥青道路(asphalt)、 牧场(meadows)、 砾石(gravel)、 裸土(bare soil)等9类地物; Salinas是美国加利福尼亚州的Salinas山谷的高光谱图像, 该图像有16类54 129个像素, 包括休耕(fallow)、 残殊(stubble)、 葡萄(grapes)、 芹菜(celery)、 生菜(lettuce)等。
图5是3个地区分别抽取3个波段叠加所成的伪彩色图像。 实验所用计算机配置为Intel(R) CoreTM i5-4460处理器, NVIDIA GeForce GTX 1070 Ti显卡; 在Linux操作系统下基于caffe框架运行实验。 在进行数据降维时, 将3个高光谱图像经过PCA处理, 提取主要的光谱波段。 将3个数据集中被标记的像素分成训练集和测试集, 分别选择10%, 2%和0.5%的样本进行训练, 其余作为测试样本。 设置批次训练的样本集为100, 网络训练的初始学习率为0.1, 当损失函数稳定后学习率降低为0.001, 动量为0.9, 权重延迟为0.000 1, 最大训练迭代次数为2× 104。
 | 图5 三类样本伪彩色图像 (a): 印第安农场; (b): 帕维亚大学; (c): 萨利纳斯Fig.5 Pseudocolored images (a): Indian Pines; (b): University of Pavia; (c): Salinas |
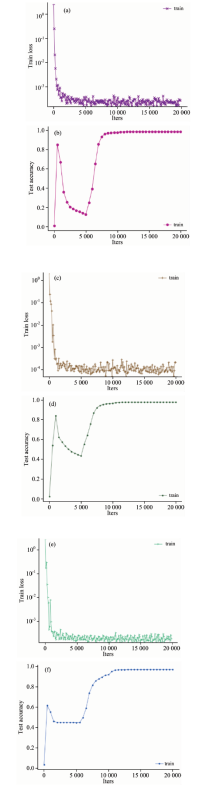
图6为3个数据集基于残差网络的特征融合算法训练过程中, 样本块大小分别在25× 25, 23× 23和27× 27, 网络深度分别为28, 32和28时, 随迭代次数增加损失函数值和准确率随迭代次数变化的曲线图。
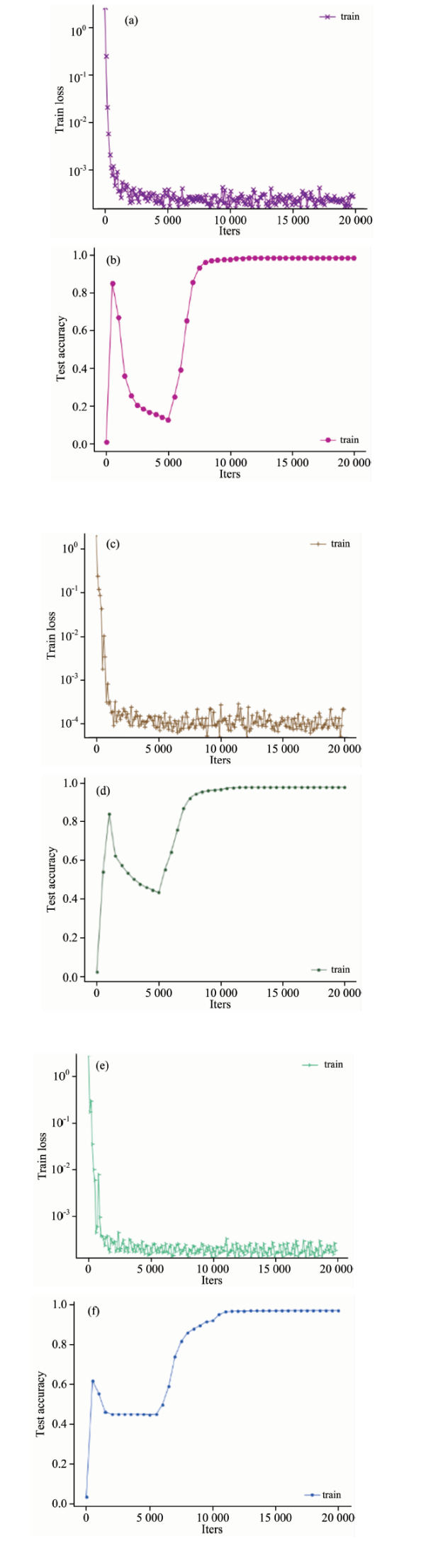 | 图6 损失函数(a, c, e)和准确率(b, d, f)变化曲线图 (a), (b): Indian Pines样本大小为25× 25, 深度为28; (c), (d): Paviau在样本大小为23× 23, 深度为32; (e), (f): Salinas在样本大小为27× 27, 深度为28Fig.6 Loss function (a, c, e) and accuracy curve (b, d, f) (a), (b): Indian Pines with a sample size of 25× 25 and a depth of 28; (c), (d): Paviau with a sample size of 23× 23 and a depth of 32; (e), (f): Salinas with a sample size of 27× 27 and a depth of 28 |
由图6(a), (c)和(e)可以看出, 当迭代次数达到2 500时, 损失函数开始趋于稳定, 比较图6(b), (d)和(f), 准确率呈现不同程度的下降, 说明随着网络层数的增加, 出现了退化问题。 当迭代次数超过10 000时, 由于残差块的学习, 将输入直接传到输出, 保护了信息的完整性, 解决了退化问题, 准确率达到最大并趋于稳定。
样本块大小和网络层数是重要的网络参数。 样本块大小会影响分类精度, 样本块过大, 会忽视一些细节信息; 样本块过小, 也会放大冗余信息, 降低分类精度。 增加网络深度在某种程度上能够提高分类精度; 但是, 层数过多会使网络产生过拟合、 梯度消失和梯度爆炸等问题。 在此, 通过交替迭代实验对这两个参数的确定进行分析。 实验过程中, 样本块大小设置范围为17× 17到31× 31, 网络深度设置在8~36之间。 为定量评估不同参数的表现, 使用总体准确率(OA)、 平均准确率(AA)和Kappa系数三个评价指标对分类精度进行评价, 其中, OA是对分类结果质量的总体评价, AA是所有类别分类精度的平均值, Kappa系数反映了分类结果与参考数据之间的吻合程度。
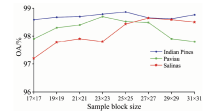
图7为3个数据集的网络深度分别设为28, 32和28时, 样本块大小对分类精度的影响曲线。 由图可以看出, 随着样本块的增大, Indian Pines分类的OA值变化较为平缓, Salinas逐渐增大, 而University of Pavia先增大后减小。 对于不同的数据集, 类内和类间的光滑度差异使得样本块大小对分类精度呈现不同的变化趋势, University of Pavia的类别区域更加复杂。 3个数据集的样本块分别设为25× 25, 23× 23和27× 27时分类精度最高。
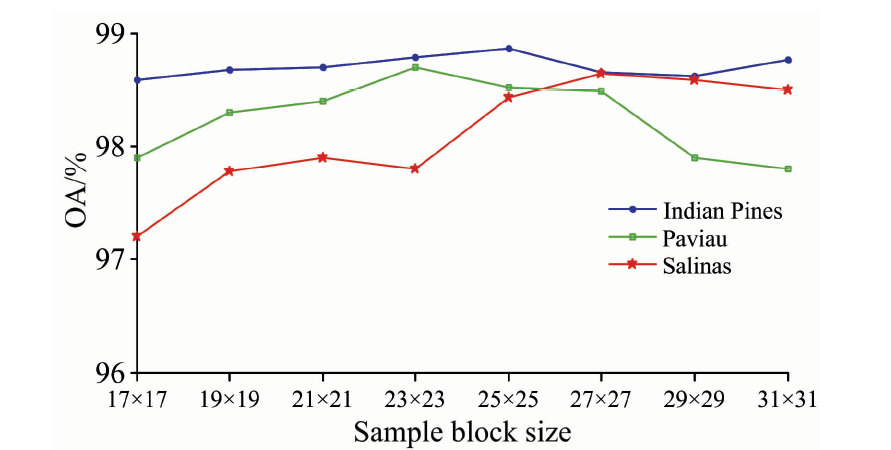 | 图7 样本块大小对分类精度的影响曲线Fig.7 The effect of sample block size on classification rate |
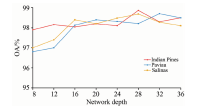
图8所示为3个数据集的样本块大小分别设为25× 25, 23× 23, 27× 27时, 网络深度对分类精度的影响曲线图。 由图8可以看出, 在网络层数8~36之间时, 分类精度都达到96%以上, 证明本工作提出的网络能有效平衡网络深度和分类的表现。 3个数据集的网络深度分别设为28, 32和28时, 分类精度达到最高。
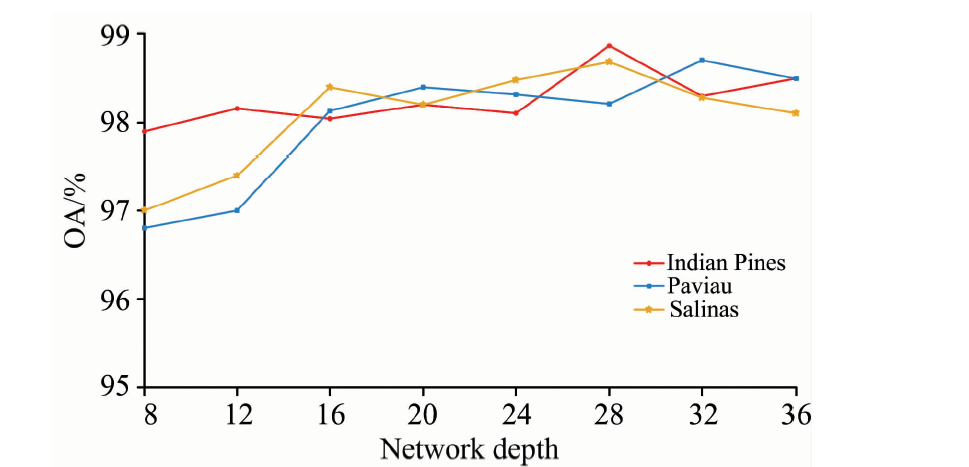 | 图8 网络深度对分类精度的影响曲线Fig.8 The effect of network depth on classification accuracy |
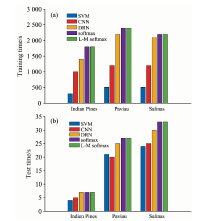
为验证基于残差网络分层融合分类算法的性能, 将该算法与常用的SVM算法、 卷积神经网络CNN和深度残差网络DRN高光谱分类方法进行比较。 其中, SVM算法利用了高光谱的像素作为输入, 使用具有高斯核的支持向量机库来实现分类; CNN是经过浅层的卷积层后输入到分类器进行分类; 而DRN采用了残差网络。 比较结果如表1所示, 相应的网络训练和测试时间如图9所示。
| 表1 SVM, CNN, DRN softmax和large-margin softmax的平均分类精度 Table 1 The average classification rates of SVM, CNN, DRN, softmax and large-margin softmax |
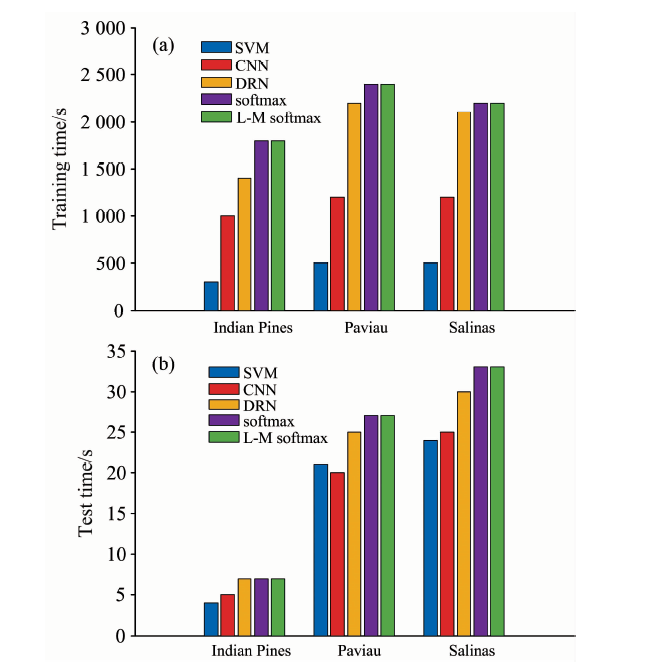 | 图9 不同网络结构在3个数据集上训练与测试时间的对比Fig.9 Comparison of training and test time on 3 data sets with different network structures |
通过比较表1中的OA可知, 与传统的机器学习算法SVM相比, CNN通过卷积层获取分层次的空间光谱特征, 减少了人工提取特征的经验性误差, OA值分别提高了4.9%, 7.8%和2.5%, 具有更好的分类效果; 但是, 卷积神经网络得到的特征数目多, 处理时间长, 大大增加了训练时间。 残差网络的引入, 解决了网络层数增加带来的负担, 同时提取到深层次的空间光谱特征, 将分类精度提高到95%左右; 但是网络深度的增加, 使训练时间明显增大。 通过比较DRN和本算法可以看出, 分层融合机制融合了不同卷积层输出的互补与相关信息, 得到更有利于分类的特征, 使分类精度达到98%以上, 证明了特征融合的有效性。 实验结果表明, 使用Large-Margin Softmax, 能够提取更有区分性的特征, 使分类精度得到进一步提高。 从图9可以看出, 网络结构的改变, 对训练时间影响较大, 但是对测试时间影响较小。
高光谱图像含有丰富的空间光谱信息, 但是在分类过程中复杂特征通常不能被充分利用。 在高光谱图像分类的方法中, SVM、 多元逻辑回归等传统的机器学习算法特征提取过程较为复杂, 而简单的CNN不能充分提取高光谱图像的深层光谱与空间特征, 并且没有充分利用多个网络层的互补与相关信息。 为解决高光谱数据特征丰富难以提取和特征信息利用不充分的问题, 设计了一种基于残差网络融合的Large-Margin Softmax进行高光谱图像分类的新方法。 通过对各种分类方法比较分析发现, 3个数据集的平均总体准确率(OA)为98.75%、 平均准确率(AA)为98.1%, 平均Kappa系数为0.98, 实验结果证明基于残差网络融合分类算法可以获得较好的效果。
基于残差网络分层融合的Large-Margin Softmax分类方法可以提取高光谱图像的有效空间光谱特征, 解决了网络层数增加带来的负担, 为高光谱图像分类提供了新思路, 但是该方法仍然存在耗时较长的问题。 所以, 在高光谱图像分类的应用中, 残差网络和分类器的设计存在巨大的潜力, 如何提高分类的速度还有待进一步地研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|