
{kind=link}
{kind=link}
{kind=link}
基于XGBOOST的恒星光谱分类特征数值化
[张枭1, 2  , 罗阿理
, 罗阿理1, * ]
, 罗阿理]
|
|


作者简介: 张 枭, 1990年生, 中国科学院大学国家天文台硕士研究生 e-mail: cyscum@outlook.com
恒星光谱分类是研究恒星的基础性工作之一, 常用的光谱分类是基于20世纪70年代Morgan和Keenan建立起来的并逐步完善的MK分类系统。 然而基于MK规则的交互式决策分类系统对处理海量天文光谱数据存在着一定的困难。 目前光谱巡天一般采用的自动化分类则是模版匹配方法而忽略对谱线特征的测量。 怎样自动、 客观地提取海量光谱中的分类特征并应用这些特征进行分类可以对天体的物理化学性质的统计分析至关重要。 针对此问题, 通过机器学习和计算光谱的谱线指数结合的方法, 提取光谱特征, 并通过大数据分析定量地确定对光谱特征谱线的分类判据(数值化), 确定每一类光谱具有物理意义的特征谱线的强度分布。 首先对LAMOST DR4恒星光谱测量其谱线指数作为输入, 光谱的分类标记采用官方发布的分类结果。 使用XGBoost算法进行自动分类及特征排序, 从而获得已知或未知的对于分类决策最为敏感的谱线。 首先, 选取高信噪比( S/N>30)、 被LAMOST标记为B, A, F和M的恒星光谱数据, 总计约414万个。 然后, 对光谱数据计算谱线指数从而使其得到降维处理, 过滤冗余信息。 其次, 将处理后的恒星光谱数据随机划分为训练集和测试集, 通过适当调整算法参数, 用训练集得到所需要的分类决策树模型, 用测试集测试其稳定性和可用性, 以防止出现过拟合, 同时使用算法自带函数进行提取分类特征。 最后, 输出并整理实验中算法所得的决策树模型, 并挑选其概率比较大的分支作为最终的决策树模型。 通过实验, 可以发现在固定参数下, XGBoost所得的模型有一定的自适应性, 较少受数据集影响, 总体准确率可达88.5%; 同时其所输出的分类决策树与已知的特征较为吻合, 而且可以获得基于大数据的、 数值化的特征谱线对应分类的范围, 为完善基于特征的分类提供定量的规则。
Star spectral classification is a foundational work of stellar research. The Morgan-Keenan (MK) classification system which was developed in 1970s is the most widely used classical classification system. However, MK based interactive decision classification system has some difficulties when dealing with massive quantity of astronomical spectral data. Nowadays the most widely used method of automatically classification is template match which neglects measuring the spectral line. As a result, one of the most popular topics is how to extract features from massive data objectively and precisely and to apply the features for making classification decisions. In this paper, we processed the spectral data of LAMOST DR4 stars to obtain the line index as input data and used the official released labels of the spectrum as outcome. The XGBoost algorithm was applied to automatically classify the stellar spectra and rank the features. In this way, the identified and potential line indices which are sensitive to classification were revealed. Firstly, we labeled and selected the spectral data of stars with B, A, F and M by LAMOST high signal-to-noise ratio ( S/N>30) with the sample size amounting to around 41. 4 million. Then, the line indices of spectral data was calculated to reduce the dimension and to filter out the redundant information. Secondly, the processed star spectral data were randomly divided to a training set and a test set. By modifying the parameters, the required classification decision tree model was fitted by training set using XGBoost algorithm and the stability and availability of the model were validated by test set to avoid over-fitting. In the meantime, the classification features were extracted by the algorithm’s own function. Finally, the branch with the highest probabilities was selected as the final decision tree model. Through experiments, it is shown that the XGBoost model has a better performance in self-adaptability under fixed parameters with less affection in data sets and the overall accuracy rate as high as 88.5%. Moreover, the output classification decision tree is more consistent with identified features and the numerical characteristics of spectrum and its corresponding range are obtainable through the model. This would shed light on providing quantitative rules for evaluating classification decision trees with numerical spectral features.
LAMOST, 全称是“ 大天区面积多目标光线光谱望远镜” , 是一架自适应光学的施密特反射式望远镜, 位于北京兴隆观测站。 因纪念元代天文学家郭守敬而冠名为郭守敬望远镜[1]。
LAMOST产生的约一千万条恒星的光谱是目前世界上最大的恒星光谱库。 对这些光谱分类对研究银河系的各种规律是十分必要的。 LAMOST光谱数据处理的官方软件流程是采用模板匹配的方法[1], 但存在缺陷: (1) 数据质量存在限制, 连续谱的质量直接影响了分类结果; (2) 本质上是高维数据的距离, 意味着数据里包含一些重复、 可约简的信息。
在过去的数十年中, 很多自动分类方法已经应用于恒星光谱分类。 人工神经网络(ANN)算法在天文领域应用广泛。 2011年, Schierscher和Paunzen使用ANN算法对SDSS DR7数据的部分恒星光谱进行分类[2]; 在2017年Hampton等通过ANN对积分场光谱型的发射线进行分类[3]。
支持向量机(SVM)算法在天文也有广泛应用。 近些年来, Liu等在2015年对LAMOST数据使用线指数和SVM算法进行MK分类[4]; 2016年Du等使用Baysian SVM和PCA方法对SDSS DR10进行M型星子型M0, M1, M2, M3, M4的分类[5]。
PCA是一种常用的特征提取方法, 但是PCA提取的是数学特征, 不具有物理意义。
采用谱线指数进行光谱自动分类除了前述Liu等的工作外[4], 王光沛等也对lick线指数进行了聚类[7]。 这些工作都揭示了谱线指数与物理特征之间的某种联系。 但这种多特征与恒星类型之间的联系并非简单关系, 而是一种需要通过树来表达的复杂关系。
基于树的机器学习算法是一类有监督的机器学习算法, 具有模型结构相对简单、 运算量相对较小, 同时准确率相对较高等优点。 其中, Chen等[8]提出的XGBoost算法, 是一种迭代型树类算法, 有着更容易实现的并行处理、 更快的运算处理速度、 比起传统决策树更高的准确性等备受瞩目, 成为一种流行的机器学习算法, 应用于诸多领域。 此外, XGBoost克服了ANN算法复杂的、 难以解读的隐藏层问题; 相对SVM等算法, 有更高的准确率。 而对于光谱分类最为重要的特点是其能够容易、 直观地提取分类特征, 对这些分类特征的物理解释可以帮助我们理解唯像光谱分类背后的物理本质。
通过所获得的分类的数值特征, 我们就可以将基于MK原则的分类决策树中某些定性的决策规则定量化, 使得分类决策更加简单并容易解释。
我们数据取自LAMOST DR4, 考虑到以生成模型、 统计分析为主要目的, 所以尽可能多选取样本; 为了得到较为准确的结果, 同时选取高信噪比(S/N> 30)恒星光谱数据。
同时对光谱数据进行线指数计算, 使得原本的伪连续谱简化为27维数据的矩阵, 大大降低原数据量。
| 表2 各类恒星光谱数量 Table 2 The quantity of stellar spectra |
将414万条光谱线指数数据随机分为训练集和测试集, 两者数据比约为3:1。
调整XGBoost的参数为: 采用决策树, booster为gbtree, 因为多分类并希望得到属于每一类的概率, objective为multi:softpro, 学习率eta=0.7, 为了提高模型准确率, 设置最大可能树深度为12; 为了模型更加稳定, 设置正则项lambda为4, 也使得算法保守。
为了得到模型, 迭代次数只设为1次, 这样因为没有对残差进行拟合, 牺牲一定的准确率, 但是可以较容易的得到所需要的决策树模型。 其他大多采取默认。
实验得到XGBoot分类正确率如表3。 从中可以看出, 实验分类结果和LAMOST所标定的结果大体一致, 虽然舍弃了对残差的拟合, 总体正确率仍较高, 在88.5%左右。 和Liu等2015年使用SVM所做的恒星线指数分类结果类似, 相比其他类型, B型星分类正确率偏低。 考虑到B型特征线指数仅为He线, 而本次分类实验未包括He线; 同时, 相比其他类型, B型数量明显偏少, 这对实验结果同样有明显影响。
| 表3 基于XGBoost分类误差矩阵 Table 3 The confusion matrix in terms of percentage of the XGBoost-based MK classification |
通过XGBoost自带函数, 我们可以得到每类线指数所占权重的打分, 这里只保留权重最大的7个特征, 如图1。
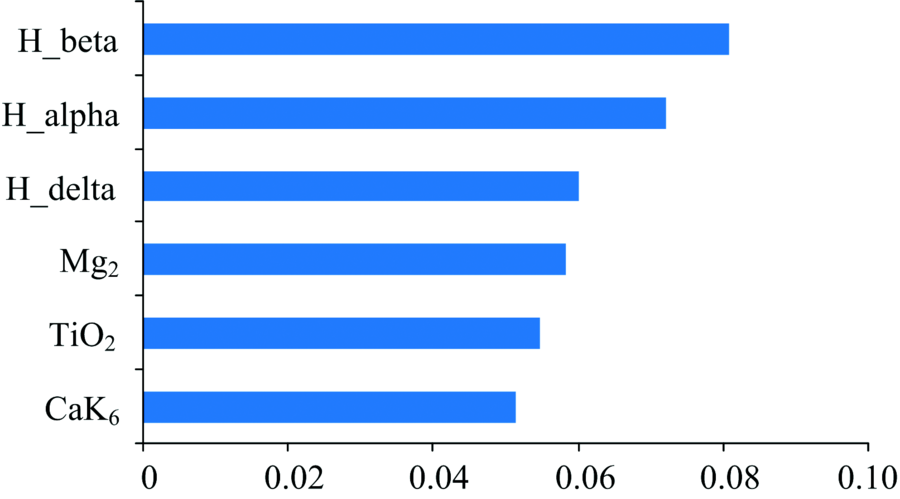 | 图1 XGBoost对特征的打分Fig.1 The scores given by XGBoost |
这个评分会随着参数不同而发生变化, 但总体差异不会很大。 没有选取H_alpha, 是因为某些数据H_alpha存在缺失情况。 下面分别以这些特征作为横纵坐标, 每一类取1 000个最高信噪比的光谱数据绘制散点图和边缘分布图如图2。
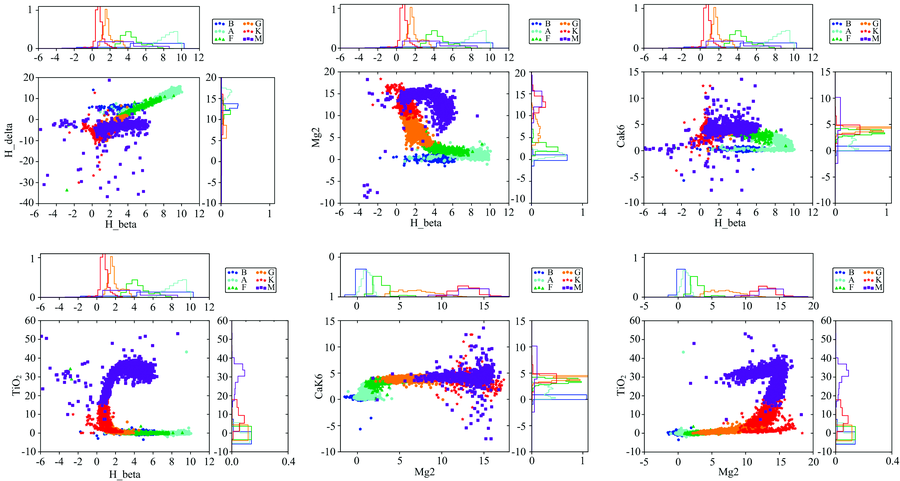 | 图2 XGBoost所得到的线指数分布图Fig.2 The distribution of the MK classes of the test data resulting from an XGBoost applied to the parameter space defined by line indices |
对411万光谱进行了基于XGBoost的MK分类, 和LAMOST结果相比, 达到了较高的正确率。 除了约四分之一的B型分类错误, 其他正确率均在85%以上。
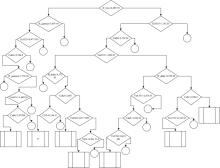
同时得到了A, F, G, K, M的分类决策树, 这里我们以A型星为例, 挑选了每一类相对应的可能性最大的7个分支。 图3即为A型星的分类决策树图。 其中左向箭头为YES, 右向箭头为NO, 菱形方框内的参数即为表1中所述的线指数及其取值范围, 长方形为输出的可能性较大的结果, 圆形为停止, 即该分支可能性相对较小而被舍去。 图3中的“ P” 为程序认为该分支为概率最大的一个分支。
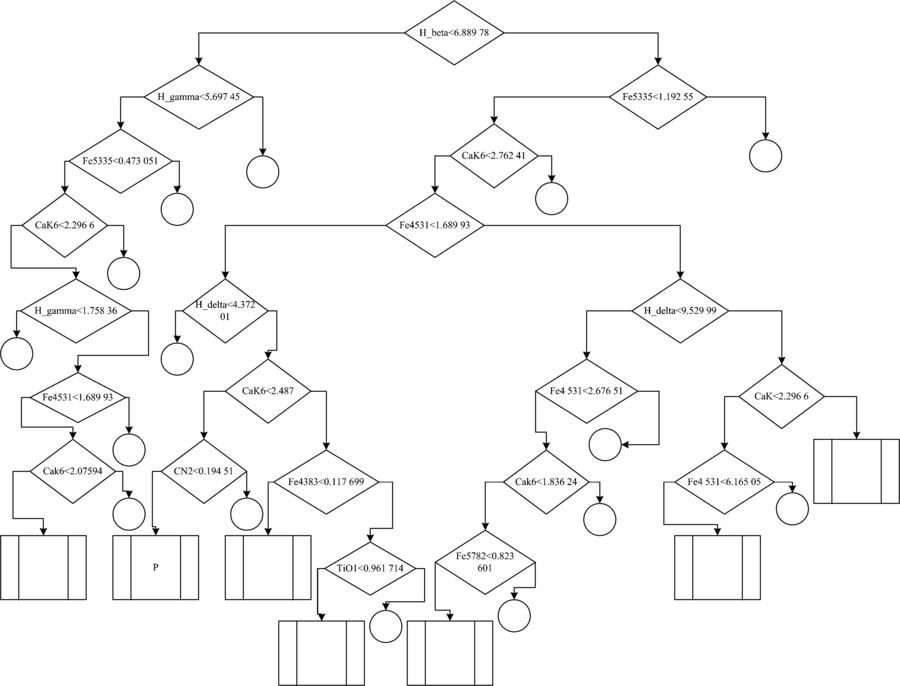 | 图3 A型星分类决策树Fig.3 The decision tree of A type star |
可以看出, 判别决策树基本符合已知结论, A型星的特征谱线是很强的巴尔末线, 特别是H_beta和H_gamma。 例如, 绝大多数A型星的特征谱线之一的H_beta> 6.889 78; 而对于巴尔末线和Fe4531线均较弱情况下, 即H_beta< 6.889 78并且H_gamma< 5.697 45, 算法以CaK6在2.075 94的分界线, 取小于此数值的部分, 作为与F0等类型的分界面。 同样, 对于带有金属Fe线且Fe4531< 1.689 93, 位于B和A之间, 以H_delta> 4.372 01作为分界线; 对于Fe4383> 0.117 699, 以TiO1< 0.961 714区分含有Fe线丛B9, M和A0。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|