
{kind=link}
{kind=link}
{kind=link}
{kind=link}
土壤重金属铅、 锌高光谱反演模型可迁移能力分析研究
[陶超1, * , 王亚晋1  , 邹滨
, 邹滨1, 2 , 涂宇龙1 , 姜晓璐1 ]
, 邹滨|
|


作者简介: 王亚晋, 女, 1993年生, 中南大学地球科学与信息物理学院硕士研究生 e-mail: wyj165011042@163.com
现有基于高光谱遥感技术的土壤重金属含量反演模型, 大多是采用同一试验区且有限的样本点进行定量反演建模。 但考虑到实际应用需求, 该类模型在不同试验区是否具有较好的迁移推广能力是目前迫切需要回答的问题。 如不可行, 是否存在其他可行手段用于土壤重金属污染评估? 为回答上述问题, 选取湖南省郴州市和衡阳市两铅锌矿区作为实验研究区, 并首先利用郴州地区采样点分别对Pb和Zn两种重金属进行定量回归建模和定性分类建模, 然后比较两种模型在衡阳实验区的可迁移能力。 实验结果表明: (1)基于偏最小二乘回归(PLSR)的定量回归模型可迁移能力较差。 分别采用四种光谱预处理方式建模, 发现回归模型对异地采样的预测精度很低, 难以正确反演衡阳试验区重金属Pb和Zn的含量。 (2)基于支持向量机(SVM)分类的定性反演模型具有一定的可迁移能力, 以郴州地区采样数据训练得到的SVM分类模型能有效判定衡阳试验区Pb、 Zn的污染状况, 分类精度分别达到84.78%和86.96%。 结果表明, 在快速检测土壤重金属污染状况的问题上, 定性分类是一种更加切实可行的方式。
The existing model of soil heavy metal content reversal model by hyperspectral remote sensing technology is mostly based on the limited sample points of the same study area. However, considering the practical application requirements, whether the model has a good migrate ability is an urgent question. If it is not feasible, is there any other feasible means for soil heavy metal pollution assessment? In order to answer the above-mentioned questions, this paper selects two lead-zinc mines in Chenzhou City and Hengyang City as research areas. The quantitative inversion and qualitative classification of heavy metals Pb and Zn were carried out using the sampling sites in Chenzhou area to compare the two models in Hengyang City of the migrate ability. Experiments show that: (1) Quantitative inversion model based on Partial least squares regression (PLSR) has poor migration ability. The regression model was established by four spectral preprocessing methods. It was found that the prediction accuracy of the model was very low, and it was difficult to correctly invert the contents of Pb and Zn in Hengyang research area. (2) Support vector machine (SVM) classification of qualitative inversion model has a certain ability to migrate. Based on Chenzhou area sampling data, training SVM classification model can effectively predict the Hengyang research area Pb and Zn pollution situation, the prediction accuracies are 84.78% and 86.96%, respectively. The results show that qualitative classification is a more practical way to detect soil heavy metal pollution rapidly.
人类活动导致的土壤重金属污染目前已引起全球的广泛关注[1], 据调查, 我国有超过10%的耕地受到重金属污染。 由于重金属在土壤中难以被微生物降解, 由此产生的累积效应将严重影响农作物的生长[2], 进而造成食品安全和人体健康风险。 因此如何有效快速地检测土壤重金属污染状况并进行防治已成为目前亟待解决的关键问题。
高光谱具有光谱分辨率高, 波段连续性强, 获得光谱信息精细的优势[3], 能有效替代传统的利用稀疏采样点进行空间插值的方式。 近10年来, 利用高光谱遥感技术反演土壤重金属含量已逐渐成为研究热点[4]: 如Kemper[5]采用多元逐步回归和人工神经网络, 估算出西班牙某矿区As, Pb, Cd等六种重金属含量; Eunyoung Choe[6]等基于多元逐步回归绘制出河流沉积物中重金属Pb, Zn等的浓度分布图; 吴昀昭[7]使用单因变量法和偏最小二乘回归模型预测出南京城郊农业土壤Cu, Cd, Pb等8种重金属含量; 黄长平[8]在不同入选波段数和光谱采样间隔下, 基于偏最小二乘回归(partial least squares regression, PLSR)回归分析方法得到预测重金属Cu含量的最佳模型。 谭琨等对比分析多元线性回归, 偏最小二乘回归, 最小二乘支持向量机三种模型反演重金属含量的效果, 指出最小二乘支持向量机的准确性和稳定性最佳。
尽管国内外学者提出了很多反演重金属含量的方法, 但大多是基于样本点数据进行定量分析, 通过回归模型预测重金属含量, 很少讨论模型在其他研究区的适用情况。 针对这一问题, 本文在现有研究基础上, 首次进行了定量反演模型和定性分类模型在不同地域的可迁移能力对比分析实验。 实验中定量分析采用偏最小二乘回归模型, 分别经过四种光谱预处理方式后建立郴州试验区重金属含量回归模型, 选择精度最高的两个模型反演衡阳试验区的重金属含量。 定性分析采用支持向量机模型, 将郴州地区采样点作为训练样本得到的支持向量机(support vector machines, SVM)模型用以判别衡阳地区的重金属污染情况。 实验结果表明SVM分类模型较与PLSR回归模型更能有效地对异地重金属污染状况做出正确判定, 具有一定的可迁移能力。
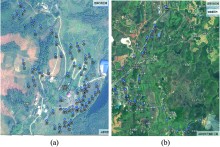
研究区1位于湖南省郴州市的某铅锌矿区, 当地多种植茶树, 土壤呈酸性, 以红壤为主。 取样点沿道路布设, 共采集83个土壤样本。 研究区2位于湖南省衡阳市的某铅锌矿区, 当地种植水稻等农作物, 土壤呈弱酸性, 以红壤为主, 取样点沿主干道布设, 共采集46个土壤样本。 采样时利用手持GPS Magellan explorist 610测量出采样点的经纬度坐标, 并按序进行样本标号, 将其导入谷歌地图中, 得到两个研究区采样点的空间分布, 如图1所示。
 | 图1 研究区谷歌影像图 (a): 郴州试验区; (b): 衡阳试验区Fig.1 Google images of the study area (a): Chenzhou research area; (b): Hengyang research area |
1.2.1 土壤采样和光谱测量
采样时在10 m2范围内采用五点采样法采集表层20 cm深度范围内的土壤, 然后混合提取约500 g样本装入密封的专用塑料袋中。 土壤样本采集后, 均在阴凉通风的室内风干, 取出石块, 植物碎片等杂质, 研磨后将样本过100目土壤筛, 分为两部分, 存储在专用的容器中。 一部分用于测定重金属浓度, Pb, Zn的含量通过等离子体发射光谱仪(ICP-8300)电感耦合等离子发射光谱法测定(USEPA-6010C: 2007); 另一部分在实验室内进行光谱测量, 采用PSR-3500野外便携式地物光谱仪, 采样波段范围为350~2 500 nm, 光谱带宽: 350~1 000 nm为1.5 nm, 1 000~1900 nm为3.8 nm, 1 900~2 500 nm为2.5 nm; 光谱分辨率: 350~1 000 nm为3.5 nm, 1 000~1 900 nm为10 nm, 1 900~2 500 nm为7 nm, 一共1 024个波段。
1.2.2 光谱数据预处理及建模方式
为提高计算效率, 首先将1 024个波段每隔10 nm重采样[9], 得到208个波段, 再分别进行一阶微分变换(first derivative)、 标准正态变换(standard normal variate), 基线校正后多元散射校正(baseline correction after multiplicative scatter correction)和包络线去除(continuum removed)四种预处理操作, 如图2所示。 由于测量时易受到环境、 仪器的影响, 光谱预处理可以增强土壤原始光谱曲线的阶跃、 峰、 谷等细节特征, 有利于地物识别和重金属信息的提取[10], 提高信噪比, 增强反演模型的鲁棒性。 其中, 一阶微分变换(以FD表示)对噪声影响的敏感性较低, 可以有效去除光谱信号中的噪声, 消除基线和其他背景的干扰; 标准正态变量变换(以SNV表示)主要用于消除固体颗粒大小、 表面散射以及光程变化对光谱的影响; 基线校正后多元散射校正(以BC-MSC表示)是对土壤光谱进行了双重校正, 可以有效消除样本间散射导致的基线偏移效应[10]; 包络线去除(以CR表示)将反射率数据归一到一个一致的光谱背景上, 能有效突出光谱曲线的吸收和反射特征[3]。
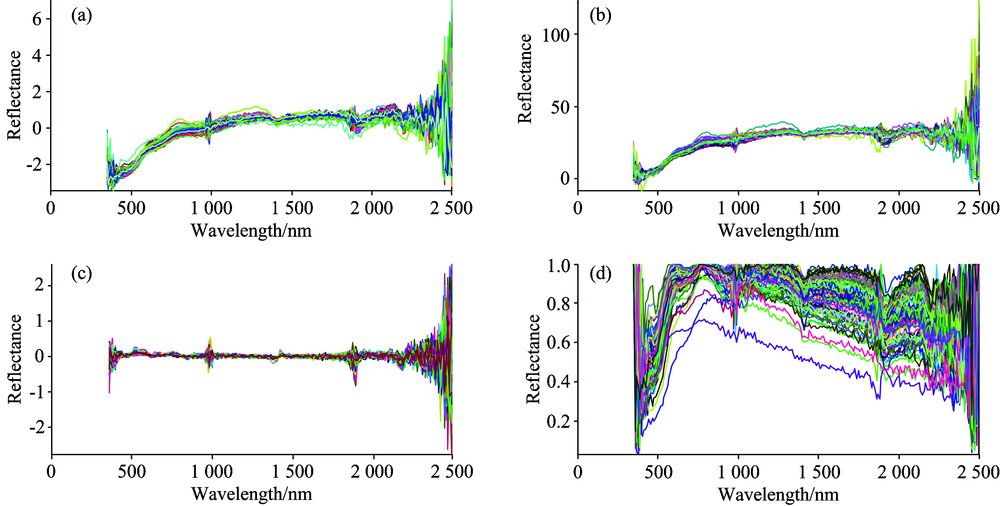 | 图2 不同光谱预处理图像 (a): SNV; (b): BC-MSC; (c): DF; (d): CRFig.2 Reflectance spectra with different pretreatments (a): SNV; (b): BC-MSC; (c): DF; (d): CR |
鉴于高光谱数据具有波段数量多, 波段间相关性强的特点, 选用偏最小二乘回归分析方法用于定量分析建模。 偏最小二乘回归通过对系统中的数据信息进行分解和筛选的方式, 可以有效克服变量多重相关性在系统建模中的不良作用, 使分析结果更加可靠, 增强模型的稳健性[11], 建模基于软件Unscrambler 9.7, 提取的成分个数通过交叉验证选择。
实验的定性分析采用支持向量机分类模型。 支持向量机是由Vapnik等提出的一种基于小样本的统计理论[3], SVM分类方法具有适用高维特征空间, 小样本学习, 抗噪声能力强等特点[12]。 针对研究区采样点数量有限, 土壤高光谱波段多的情况, SVM分类能表现出极大的适用性。 实验中, SVM分类基于台湾大学林智仁教授开发的Libsvm软件包在MATLAB 2014a平台上实现, 核函数选择高斯径向基, 参数通过网格搜索法选择最优值。
将两个研究区的样本重金属含量数据导入SPSS 17.0中进行描述分析, 结果如表1所示。 根据土壤环境质量标准(GB15618— 1995)[13], 两个研究区内重金属污染严重, 其中, 郴州地区重金属Pb, Zn的平均含量超过国家二级标准三倍以上, 衡阳地区则超过十倍以上, 即两个研究区的重金属含量都远超出农业生产和人类健康水平的限制值。 通过变异系数分析研究区内重金属的浓度分布, 得出两种重金属在各研究区内变异系数较大, 属于强变异, 原因在于, 有些采样点重金属污染严重, 而有些采样点则不受到污染的影响, 造成样本点的重金属含量空间分布离散化程度大, 不服从正态分布。
| 表1 重金属含量描述统计分析(mg· kg-1) Table 1 Descriptive statistics for heavy metal concentrations in soil samples (mg· kg-1) |
将郴州地区83个样本全部用于回归建模, 衡阳地区46个样本用于预测分析。 首先, 利用SPSS进行显著性F检验选取波段数, 选入和剔除值分别设为0.05和0.1。 其次, 将筛选后的波段用于偏最小二乘回归建模, 最终以可决系数R2, 均方根误差RMSE, 相对分析误差RPD衡量模型精度。 模型的精度评价根据Willianms和Saeys提出的理论[14], 当R2> 0.90, RPD> 3.0时, 模型具有极好的预测能力, 当0.82< R2< 0.90, 2.5< RPD< 3.0时, 模型具有很好的预测能力, 当0.66< R2< 0.81, 2.0< RPD< 2.5时, 模型具有较好的预测能力, 当0.50< R2< 0.65, 1.5< RPD< 2.0时, 模型具有适当精度的预测能力, 当R2< 0.50, RPD< 1.5时, 建模失败。 建模结果如表2所示。
| 表2 PLSR建模结果 Table 2 PLSR modle result |
建模结果显示, 经过一阶微分, 标准正态变换, 基线校正后多元散射校正, 包络线去除四种光谱预处理后, 所建立的偏最小二乘回归模型精度各不相同。 可以看到, 对于定量反演模型来说, 并没有特定的最佳光谱预处理方式, 依重金属浓度和类别而异。 实验表明, 光谱分别经过基线校正后多元散射校正和标准正态变换后所建立的偏最小二乘回归模型对同一区域内重金属Pb和Zn的反演精度最高。
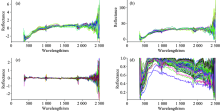
为检验模型的可迁移能力, 分别将上述两个反演精度最高的模型应用于预测衡阳地区的重金属Pb和Zn的含量, 实验结果如图3所示。
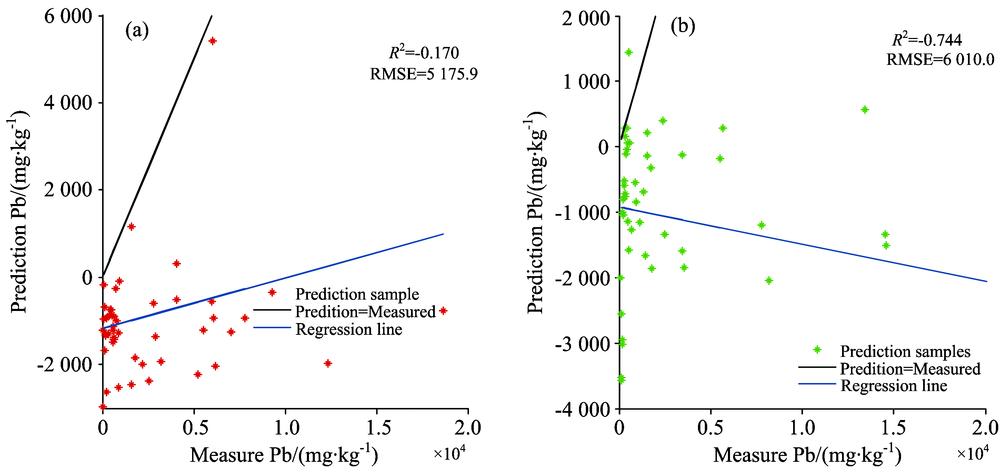 | 图3 重金属Pb, Zn的预测结果Fig.3 Predictive model results of heavy metals Pb and Zn (a): Pb; (b): Zn |
分析图中数据, 发现两个模型的预测结果都出现可决系数R2为负的情况, 违背了0≤ R2≤ 1的取值范围, 这是因为基于PLSR模型预测的重金属含量出现大量负值, 造成异常, 使计算的残差平方和(SSE)大于重金属含量实测值的总变异平方和(SST), 且两个模型预测得出的均方根误差RMSE都很大, 分别达到了5 175.9和6 010.0, 表明预测值与实测值的偏离较大, 回归模型的精确性和可靠性较差。 以上实验证明, 在郴州试验区建立的重金属回归模型, 难以预测衡阳试验区的重金属含量, 定量反演模型的推广迁移能力较差。
实验首先根据重金属浓度, 按照Muller地质积累指数(Igeo)进行污染分级。
式中, Cn表示重金属元素的实测含量, Bn表示该元素的背景值。
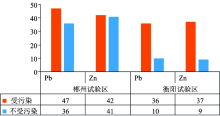
以Igeo的大小分为7个等级, 当Igeo< 0, 污染等级为0, 表示无污染; 当0≤ Igeo< 1, 污染等级为1, 表示轻度污染; 当1≤ Igeo< 2, 污染等级为2, 表示中度污染; 当2≤ Igeo< 3, 污染等级为3, 表示中度污染到重污染; 当3≤ Igeo< 4, 污染等级为4, 表示重污染; 当4≤ Igeo< 5, 污染等级为5, 表示重污染到极重污染; 当Igeo≥ 5, 污染等级为6, 表示极重污染。 由于两个研究区重金属污染严重, 因此将污染等级0级和1级的光谱数据划分为不受污染的一组, 将2级及以上的光谱数据划分为受污染的一组, 统计重金属Pb, Zn的污染分组情况, 如图4所示。
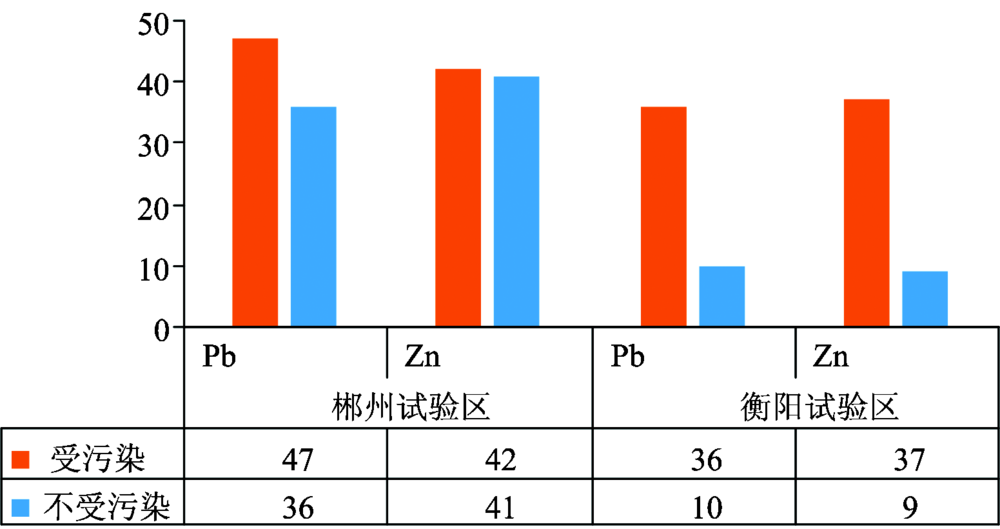 | 图4 基于Muller地质积累指数的重金属污染分组情况Fig.4 Heavy metal pollution grouping based on muller geological accumulation |
为选择最优特征, 分别验证一阶微分(
| 表3 不同光谱预处理下的分类精度 Table 3 Classification accuracy under different spectral pretreatment |
比较四种不同光谱预处理方式下的重金属分类精度, 发现光谱经过一阶微分预处理后分类精度最高, 这与国内外的相关研究结论保持一致, 说明微分处理技术是一种较好的反演土壤重金属含量的方式。 重金属在土壤组分中含量偏低, 且无明显吸收峰, 对光谱进行微分变换后, 容易找到相关性高的波段[11], 因此得到的分类精度较高。 通过一阶微分进行光谱特征增强后, 重金属Pb和Zn的最高分类精度分别达到了87.50%和100.00%; 说明SVM能充分利用高光谱波段数量多, 波谱信息精细的优势, 有效提取土壤重金属光谱特征, 从而分类出受重金属污染和不受重金属污染的土壤样本; 进一步证明受重金属污染的样本和不受重金属污染的样本存在较大的光谱差异, 并能够利用差异性进行有效分类。
为验证SVM分类器的推广迁移能力, 将郴州地区的83个样本作为训练集, 衡阳地区的46个样本作为测试集, 统计结果如表4所示。
| 表4 模型预测精度统计 Table 4 Model prediction accuracy statistics |
上述两个实验结果表明: (
以湖南省郴州市和衡阳市两地区的铅锌矿区为研究区, 针对土壤重金属高光谱反演模型能否在不同地域具有可迁移能力的问题, 进行定量回归建模和定性分类的对比实验, 实验结论如下:
(1)基于PLSR的定量反演模型可迁移能力较差。 定量反演能够建立具有较高统计精度的回归模型, 但将模型应用于预测衡阳试验区重金属Pb, Zn含量时, 出现重金属含量为负值的异常情况。 且分别经过四种光谱预处理方式构建的模型, 预测的可决系数R2, 均方根误差RMSE精度较低, 难以正确反演异地试验区的重金属含量。
(2)基于SVM分类的定性反演模型具有一定的可迁移能力。 基于郴州试验区的训练样本建立的SVM分类模型能有效判定衡阳试验区重金属Pb和Zn的污染状况, 分类精度分别达到84.78%和86.96%, 对异地样品的预测能力表现良好。 说明分类模型能够充分利用土壤高光谱受重金属污染带来的差异性, 有效判别土壤是否受到重金属污染的影响, 并能够将模型应用于不同的试验区。
(3)定性分类的模型构建过程比定量回归更简单。 定性分类能简化光谱预处理的方式, 避免了筛选波段的过程, 更加充分利用高光谱波段数量多, 波谱信息精细的优势, 并能从整体上判断研究区的重金属污染状况, 为大面积快速检测土壤状况提供一种更加切实可行的方式。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|