


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
核密度估计算法结合近红外光谱技术鉴别三叶青产地
引用本文
赖添悦, 蔡逢煌, 彭昕, 柴琴琴, 李玉榕, 王武. 核密度估计算法结合近红外光谱技术鉴别三叶青产地[J]. 光谱学与光谱分析, 2018,38(3): 794-799.
LAI Tian-yue, CAI Feng-huang, PENG Xin, CHAI Qin-qin, LI Yu-rong, WANG Wu. Identification of Tetrastigma hemsleyanum from Different Places with FT-NIR Combined with Kernel Density Estimation Algorithm [J]. Spectroscopy and Spectral Analysis, 2018,38(3): 794-799.
Doi:10.3964/j.issn.1000-0593(2018)03-0794-06
Permissions
LAI Tian-yue, CAI Feng-huang, PENG Xin, CHAI Qin-qin, LI Yu-rong, WANG Wu. Identification of Tetrastigma hemsleyanum from Different Places with FT-NIR Combined with Kernel Density Estimation Algorithm [J]. Spectroscopy and Spectral Analysis, 2018,38(3): 794-799.
Doi:10.3964/j.issn.1000-0593(2018)03-0794-06
Copyright©2018, 《光谱学与光谱分析》期刊社
《光谱学与光谱分析》期刊社 所有
核密度估计算法结合近红外光谱技术鉴别三叶青产地
作者简介: 赖添悦, 1992年生, 福州大学电气工程与自动化学院硕士研究生 e-mail: 229698121@qq.com
摘要
三叶青是我国珍稀中药材, 具有多种疗效, 但不同产地的三叶青有效成分含量差异悬殊, 为防止三叶青以次充好, 其产地鉴别尤为重要。 以浙江、 云南、 安徽、 广西和湖北五个产地的三叶青为研究对象, 利用傅里叶变换近红外光谱分析仪(Fourier transform near infrared spectroscopy, FT-NIR)收集4 000~10 000 cm-1范围内的近红外光谱, 由于三叶青近红外光谱数据还未完善, 因此在其产地鉴别上, 应对鉴别算法提出更高的要求, 即在实现三叶产地鉴别的同时, 还要能够有效地识别出其他或未知新产地的三叶青。 针对这一问题, 本文结合三叶青近红外光谱数据的特点, 对算法共做了三方面改进: ①从距离的角度估计样本的概率密度; ②以训练样本可信度的方式计算带宽参数; ③在未知新产地的识别上, 提出一种基于训练集样本的概率密度函数的识别方法。 结果表明, 该算法对训练集样本的识别精度达到了100%, 且在140组预测集样本中, 只有3组样本识别出错, 并能够100%地识别出未知新产地的三叶青, 说明基于核密度估计的改进算法在三叶青产地鉴别上, 不仅鉴别精度高, 且能够有效识别出其他或未知新产地的三叶青。
关键词:
三叶青; 产地鉴别; 核密度估计; 未知新产地; 近红外光谱
中图分类号:O657.3
文献标志码:A
Identification of Tetrastigma hemsleyanum from Different Places with FT-NIR Combined with Kernel Density Estimation Algorithm
Abstract
Tetrastigma hemsleyanum, a rare medicinal herbs in China, contains many kinds of curative effects. However, the content of active ingredients of T. hemsleyanum from different places is remarkablely different. So, it is necessary to discriminate this promising medicinal T. hemsleyanum from different places. In this work, spectra of T. hemsleyanum collected from Zhejiang, Yunnan, Anhui, Guangxi and Hubei provinces were recorded with Fourier transform near infrared spectroscopy, ranging from 10 000 to 4 000 cm-1. And the identification algorithm was applied to effectively identify the T. hemsleyanum from the known origin and other new places because the spectral data of T. hemsleyanum is not sufficient. Hence, in this study, three improvements of kernel density estimation algorithm have been achieved to identify T. hemsleyanum: (1) estimate the probability density of the samples via the perspective of distance; (2) calculate the bandwidth parameters by training the credibility of samples; (3) propose a recognition method based on probability density function of training set samples to recognize unknown origin. The identifying accuracy of training set sample and prediction set by the algorithm were reached 100% and 97.8%, respectively. Additionally, the new places of T. hemsleyanum can be accurately identified used the algorithm. The results show that the improved algorithm based on kernel density estimation can effectively identify T. hemsleyanum, and recognize the unknown origin samples.
Keyword:
Tetrastigma hemsleyanum; Original identification; Kernel density estimation; Unknown origin; Near infrared spectroscopy
引言
三叶青是我国特有的珍稀中草药材, 其含有酚类、 氨基酸类、 黄酮类、 萜类、 等成分[1]。 研究表明其具有保护肝脏、 抗病毒、 抗炎镇痛[2]等功效, 临床上对麻疹并发肺炎、 小儿高热等多种疾病也有显著疗效[3]。 由于三叶青特殊的药用价值, 需求量越来越大。 然而, 三叶青资源十分短缺, 野生三叶青稀少, 人工栽培难度大, 具有药用价值的地下块根需要3~5年的时间才能达到商品药材要求, 而且其不同产地、 不同种质的植物学特征特性、 地下块根产量以及有效成分含量存在明显差异[4]。 据报道, 三叶青中黄酮类成分含量不同产地差异悬殊, 如浙江和广西产地间黄酮类成分含量差异最大可达到7倍[5]。 现阶段, 主要对三叶青的药用价值及其化学成分进行研究, 针对其产地鉴别却鲜有报导, 而一种针对三叶青产地鉴别的有效方法, 对规范三叶青市场、 保护消费者利益具有非常重要的现实意义。
近红外光谱分析技术作为一种新型实用分析技术, 反映给定样品的物理和化学信息, 不仅适用于固体、 液体、 气体样品分析, 与传统的方法相比, 具有快速、 非破坏性、 廉价和样品用量少等优点。 近年来, 近红外光谱分析技术结合主成分分析法(principal component analysis, PCA)[6]、 支持向量机(support vector machine, SVM)[7]、 相关向量机(relevance vector machine, RVM)[8, 9]等分析方法, 在食品、 生物、 药品、 石化、 环境等方面得到广泛应用。 如Luna等[10]利用SVM结合近红外光谱技术对转基因大豆进行快速鉴别, 结果表明这种方法在转基因大豆的鉴别上, 具有较高的识别率; 朱哲燕等在香菇产地的鉴别中, 将近红外光谱分析技术和RVM算法相结合, 鉴别的准确率高于90%, 相比于SVM等算法表现出了更高的鉴别精度; 栢凤女等[11]采集了大肠杆菌、 单增李斯特菌、 金黄色葡萄球三种对食源性致病菌的近红外光谱, 然后用SVM算法建立三种细菌的分类器模型, 且研究了核函数和参数的选取对鉴别准确率的影响; 上述分类器的工作框图如图1所示, 必须事先利用训练集中的各类样本数据对模型本身进行训练, 才能够对训练集中的各类实现鉴别, 在分类过程中, 不同分类器按照其各自的分类机制, 将待测样本匹配为训练集中的某一类, 从而实现分类, 这就要求待测样本必须属于训练样本中的其中一类, 分类器才能做出正确的鉴别, 而当待测样本属于训练集样本之外的其他类时, 则无法做出正确的鉴别。
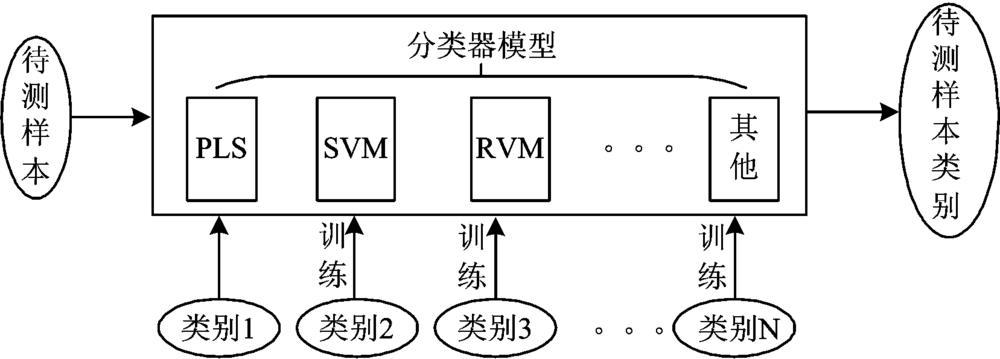 | 图1 分类器的工作框图Fig.1 The framework of the classifier |
在三叶青产地鉴别上, 虽然不同产地的三叶青有效成分含量差异悬殊, 但是其近红外光谱数据差异仍很小, 因此其产地的高精度鉴别十分困难。 由于三叶青的近红外光谱数据库还未完善, 如果按照上述的鉴别方法, 单纯建立一个分类器, 如PLS, SVM和RVM分类器, 则无法有效地确定待测样本是否属于已知数据库中的某一产地, 因为它也有可能来自于数据库之外的其他或未知新产地。 针对三叶青产地鉴别所面临的问题, 本研究提出了一种基于核密度估计框架的改进算法, 结合了簇类中心点聚集密度高的样本分布思想[13], 分别建立了针对训练样本中每一类概率密度函数, 并以离各簇类中心的距离估计待测样本属于各类的概率密度函数值, 进而比较其属于各类概率的大小实现分类。 而对于未知产地的鉴别, 则是通过建立针对训练样本全集的概率密度函数, 同样以概率的形式说明其是否属于已知类, 当属于已知类的概率过小时, 则将其判别为未知新类。 研究中还提出以训练样本可信度的形式来计算模型的带宽参数, 结果表明, 这种带宽参数的计算方法可以很好地适应基于近红外光谱技术的三叶青产地鉴别。
1 实验部分
1.1 样品制备
采集浙江、 云南、 安徽、 广西和湖北5个产地的三叶青样本, 每个产地收集5份, 每份样品不少于30 g。 每份样本均用中药粉碎机粉碎, 过200目筛, 充分混匀, 置于烘箱65 ℃干燥, 存放于自封袋, 备用。
1.2 近红外光谱的采集和处理
实验采用美国Thermo公司生产的ANTARIS II型傅里叶变换近红外光谱分析仪, 配有InGaAs检测器、 积分球漫反射采样系统和旋转石英样品杯, 扫描范围4 000~10 000 cm-1, 分辨率为8 cm-1, 扫描64次。 每次称取样品约10 g, 置于近红外旋转样品杯扫描光谱。 在Matlab(R2013b)上编写程序对光谱数据进行分析。
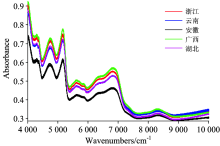
浙江、 云南、 安徽、 广西和湖北5个产地的三叶青的近红外光谱图, 如图2所示。 不同产地的三叶青近红外光谱吸收峰的位置大致一致, 吸收峰强度存在较小差异。 三叶青主要含有黄酮、 多酚、 多糖以及氨基酸等生理活性物质。
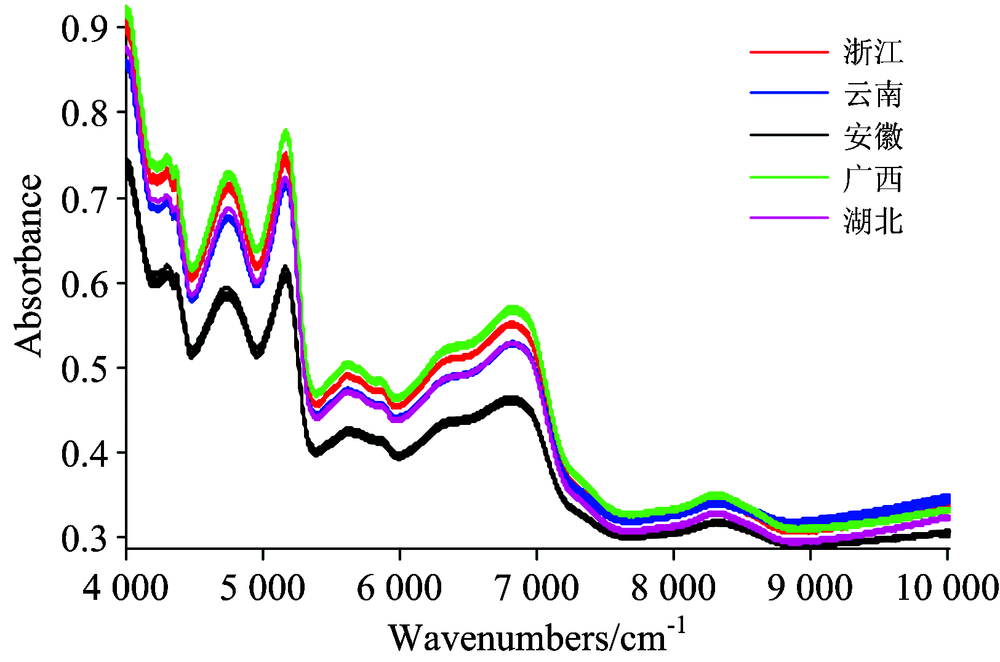 | 图2 三叶青近红外光谱图Fig.2 The near infrared spectroscopy of the Tetrastigma hemsleyanum. |
谱图中8 000~8 600 cm-1附近是C— H的二级倍频, 6 800~7 000 cm-1附近的吸收峰是N— H三级倍频, 5 000~5 200 cm-1的吸收峰是C=0二级倍频, 4 500~5 000 cm-1为N— H的组合频。 总体而言, 不同产地的三叶青近红外光谱图相似性较高。
1.3 基于核密度估计的分类原理
1.3.1 分类器模型的构建
2014, Rodriguez等[12]提出了一种假设, 簇类中心被具有较低局部密度的邻居点包围, 且与具有更高局部密度的其他数据对象有相对较大的距离。 将这种思想结合到基于核密度估计的分类算法中, 可以提出如下假设:
簇类中心处具有较高的概率密度, 当样本点离其簇类中心点越近时, 其概率密度值越大(这里指欧式距离)。 利用核函数的形式, 第k类样本离该类的簇类中心点的距离r的概率密度函数可定义如式(1)
其中K(* )为核函数; k指训练样本中的第k类样本, 且k=1, 2, …, c, c为总类别数; nk为训练集样本中第k类的样本数; h(k)为核函数K(* )的带宽参数。 本研究取第k类训练集样本的均值作为簇类中心, 记为u(k)。
根据假设, 取K(* )取指数核, 如式(2)所示
即有式(3)
1.3.2 带宽参数h(k)的计算
从概率密度式(3)可分析出, 当带宽参数h(k)较大时, 则第k类样本分布比较密集, 其较小时, 则分布比较分散, 说明了h(k)的取值与样本的分布情况有关, 因此可以通过分析训练样本的分布情况, 实现对带宽参数h(k)的计算。 在式(3)中, r的取值范围为[0, +∞ ), 而在有限的训练集样本中, 总能找一个距簇类中心点最远的样本点, 记为
式(4)中P(0< r≤ rmax)指待测样本落在区间[0, rmax]上的概率。
式(3)为第k类的概率密度函数, 则其样本的可信度α (k)
将式(3)带入式(7), 可得
即式(6)
h(k)计算完毕。
1.3.3 分类的实现与未知新类的鉴别方法
根据式(5)可知, 对于训练样本中的每一类都对应一个概率密度函数, 当有c个类别时, 则有c个概率密度函数, 如式(7)所示
现构造针对训练样本中所有类的概率密度函数如式(8)
式(8)满足
按式(7)中各个函数占函数式(8)比重ρ 不同来实现分类, 则有
其中
分类原则1:
如果:
则: 待测样本属于第k类
这里未考虑未知新类的情况。
当考虑未知新类时, 函数式(8)是针对训练样本集分布的概率密度函数, 若待测样本属于未知新类, 其对应的
分类原则2:
当
当
为了保证训练样本中所有的样本点不会被误识别为未知新类, 这里将训练样本对应的所有
到此, 分类算法设计完毕。
2 结果与讨论
在三叶青产地的鉴别过程中, 一共采集了浙江、 云南、 安徽、 广西和湖北五个产地的三叶青近红外光谱数据各60组, 样本分配情况如表1所示。
| 表1 样本分配情况 Table 1 The allocation of sample |
分别随机选取浙江、 云南、 安徽和广西产地的样本各40组, 共160组, 作为训练集样本; 剩下的80组作为预测集样本。 选取湖北产地的三叶青作为未知产地样本, 不参与分类器模型的训练过程, 即这类样本不属于训练集中的任何产地, 将其归为预测集的一部分, 用于测试分类器对未知产地的识别。
2.1 已知产地的鉴别
按照传统分类器鉴别的思路, 分析在不考虑未知产地的情况, 分类器对已知产地的鉴别情况。 对于每个三叶青样本, 其近红外光谱的采集过程是一致的, 因此, 为了公平起见, 样本的可信度统一取α =0.98。
按式(6)计算模型的四个带宽参数h(1), h(2), h(3), h(4), 结果如下
由式(3)可知, 训练集样本的每一个子类对应一个函数模型
| 表2 函数 |
函数
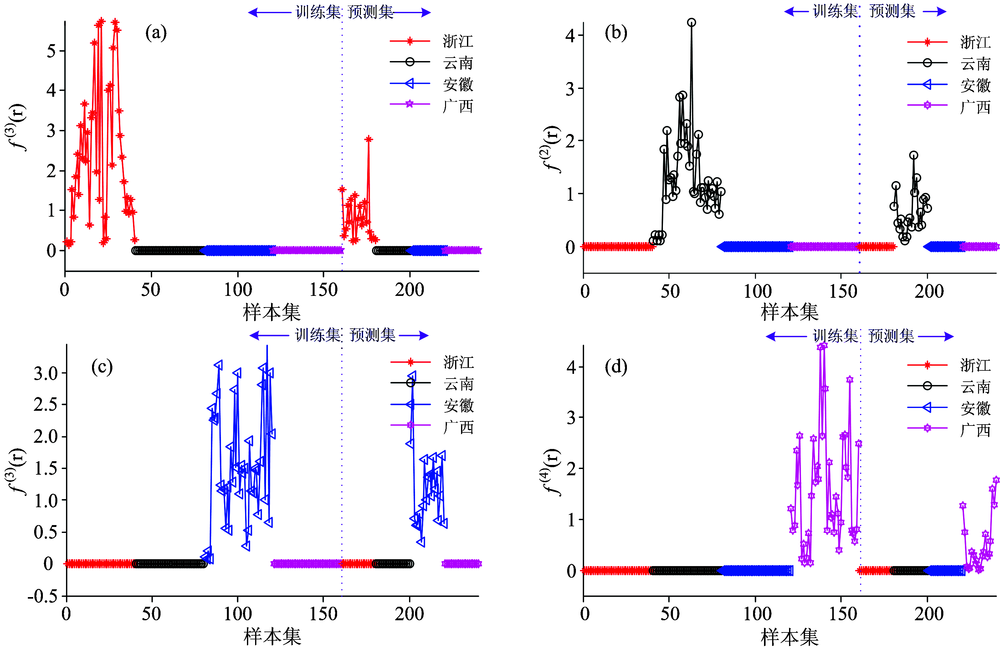 | 图3 训练集与预测集样本的 (a), (b), (c), (d)分别为三叶青函数值Fig.3 The value of (a), (b), (c), (d) the value of Tetrasleynum |
图3(a)中, 函数
再分析训练集和预测集的样本数据对应的
从以下两个角度去分析图4, 可以更加清晰看出其所表示的结果: ①以图4(a)为例, 在ρ (1)所表示的权重中, 只有浙江产地的三叶青所占的比重接近于1, 而其他的产地的三叶青所占的比重接近于0, 说明了ρ (1)可以很好表示出浙江产地的三叶青; ②以浙江产地的三叶青为例, 比较ρ (1), ρ (2), ρ (3)和ρ (4)中浙江产地的三叶青所占的比重, 可以看出, 只有在ρ (1)中, 浙江产地的三叶青的比重值接近于1, 而在ρ (2), ρ (3)和ρ (4)中, 浙江产地的三叶青的比重值接近于0, 说明按照分类原则1, 可以很好地得到待测样本的类别。 且按照权重的形式, 各类边缘点与其簇类中心邻近点都能保持在一个相同水平, 这样能够进一步提高分类器的分类效果。
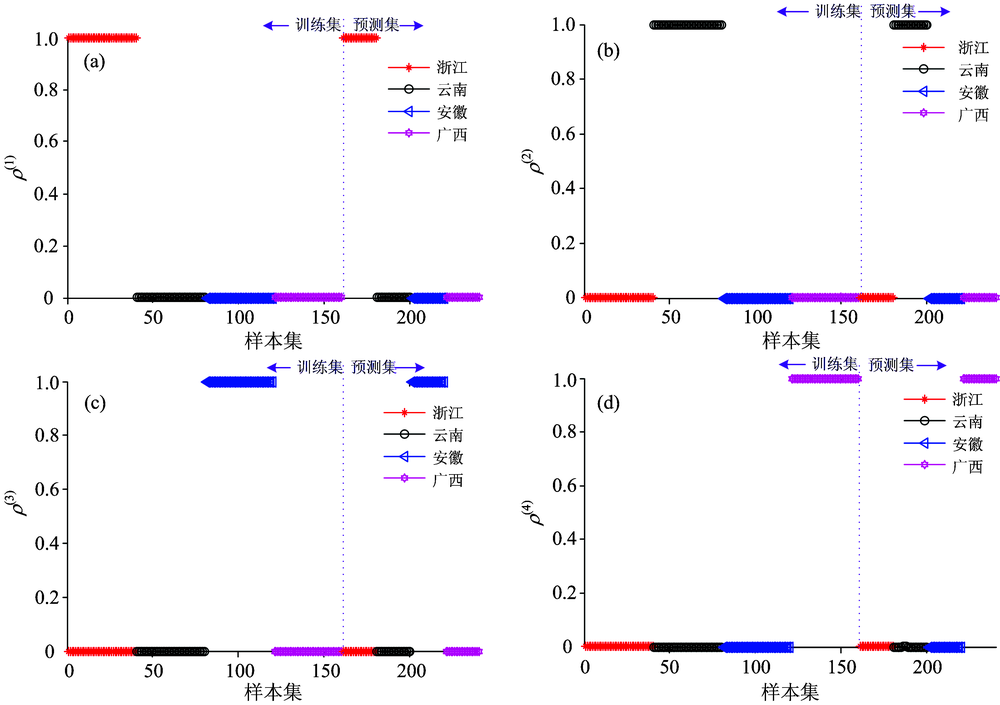 | 图4 训练集预测集样本的权重ρ (k)值 (a), (b), (c), (d)分别为三叶青函数值Fig.4 The value of ρ (k) of training set and prediction set (a), (b), (c), (d) the value of Tetrasleynum |
2.2 未知产地的鉴别
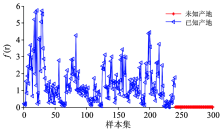
针对未知产地的三叶青进行鉴别分析, 在鉴别过程中, 如表1所示, 假设湖北产地的三叶青为未知产地, 浙江、 云南、 安徽和广西为已知产地。 根据分类原则2可知, 对未知新类的判别原则是依据当训练集样本所对应的概率密度函数
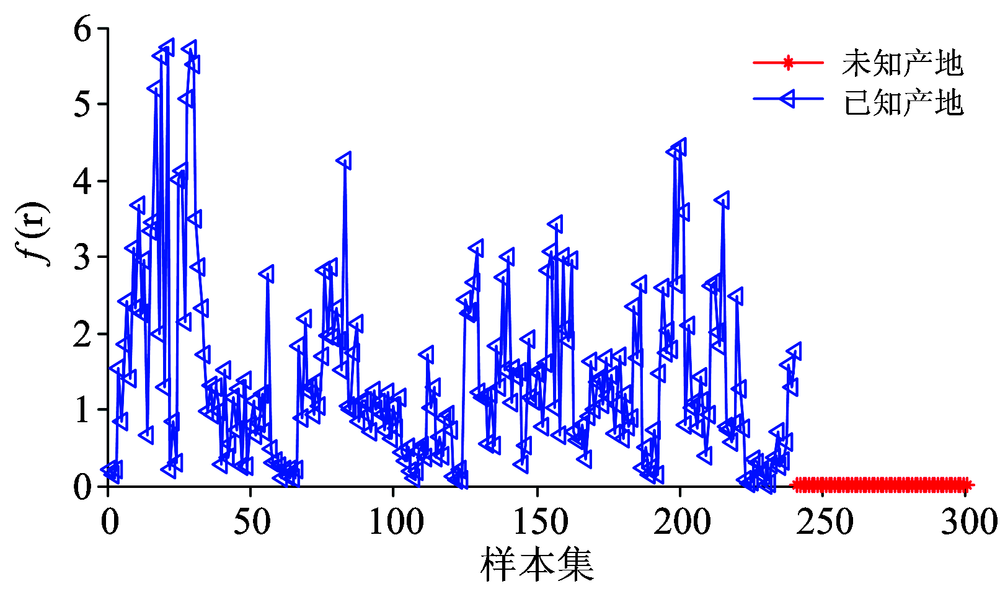 | 图5 已知产地与未知产地的概率密度函数值Fig.5 The probability density function values of known and unknown place of origin |
从图5中可以很明显地看出, 当使用训练集样本的概率密度函数去计算未知产地的样本时, 其概率密度函数值很小, 说明了这些未知产地三叶青近红外光谱与训练集中已知产地的三叶青的近红外光谱差异比较大, 则可以得到这些未知产地的三叶青不属于训练集中任何一种已知的三叶青。 然后利用分类原则2鉴别未知产地的三叶青时, 可以100%得出湖北产地的三叶青不属于训练集中的任何一种产地。
2.3 三叶青产地鉴别
2.1节分析本研究分类方法在不考虑未知产地时的分类效果, 2.2节主要分析了对未知产地的鉴别效果。 这一节, 综合地去考虑上述两种情况, 在预测集样本不仅有已知产地的三叶青, 还有未知产地的三叶青, 测试是否在完成分类的同时, 还能否有效地鉴别出未知产地, 只有这样才能有效地解决三叶青产地间的掺假问题。
模型训练完成后, 先用训练集中的样本数据对模型的鉴别精度进行检验, 结果如表3所示, 不管选取哪一产地的三叶青为未知产地, 分类器对训练集中样本数据的鉴别精度均可以达到100%。
| 表3 训练集的鉴别精度 Table 3 The discrimination accuracy of training set |
三叶青产地的鉴别模型建立完成之后, 最重要的是其预测精度是否能到要求, 表4展示了其对预测集样本的鉴别精度, 从表4可知, 分类器对浙江产地的三叶青的预测精度为100%; 对云南产地的三叶青的预测精度为100%; 对安徽产地的三叶青的预测精度为90%(20组数据中有2组被误识别为未知产地); 对广西产地的三叶青的预测精度为95%(20组数据中有1组被误识别为未知产地); 且可以100%识别出为未知产地(湖北产地)。 从表4得出, 有三组已知产地的样本的数据被误识别为未知产地, 分析其原因, 主要是由于在已知产地的预测集样本中, 少数边缘点其概率密度函数值较小, 容易被误识别为未知产地, 这与未知产地的判别阈值β 有很大的关系, 但整体上, 按式(10)所表示的阈值选取原则, 可以很好的保证鉴别精度。
| 表4 预测集的鉴别结果 Table 4 Identification results of prediction sets |
综合上述实验结果, 本研究所提的算法在三叶青的产地鉴别上, 不仅可以实现三叶青的产地鉴别, 同时还能够有效地识别出其他或未知产地的三叶青。 这对防范三叶青产地间的掺假、 防止不法商人以次充好有着重要的意义。
3 结论
三叶青是我国珍稀中药材, 具有多种疗效, 但研究表明, 不同产地的三叶青, 其有效成分含量差异悬殊, 因此为了更好地防止市场上三叶青以次充好的现象, 其产地的有效鉴别尤为重要。 近红外光谱分析技术作为一种新型实用分析技术, 在物质鉴别方面, 具有快速、 非破坏性、 廉价和样品量少等优点。 但现阶段三叶青的近红外光谱数据还未完善, 且传统的分类算法过度依赖于训练集样本, 难以对已知数据库之外的种类作出有效的识别。 因此对基于核密度估计的分类算法进行改进, 提出一种针对三叶青产地鉴别的近红外光谱分析技术, 结果表明, 本方法不仅鉴别精度高, 且能够有效识别出其他或未知新产地的三叶青, 可以很好地解决三叶青产地鉴别问题。
The authors have declared that no competing interests exist.
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|