



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
拉普拉斯约束低秩表示的高光谱图像异常检测
[王杰超1, 2, 3  , 孙大鹏
, 孙大鹏1, 2, 3 , 张长兴1 , 谢锋1 , 王建宇1, * ]
, 孙大鹏]
|
|


作者简介: 王杰超, 1992年生, 中国科学院上海技术物理研究所硕士研究生 e-mail: 15002125138@163.com
伴随高光谱图像的广泛使用, 高光谱图像技术得到长足的发展, 其中高光谱图像异常检测技术越发受到重视。 为了解决传统高光谱图像异常检测技术的实用性和检测效果不佳的问题, 提出一种新颖的低秩表示检测算法。 对于高光谱图像, 大部分背景像元均可以被少量主要的背景像元组合近似地表示, 且它们的表示系数将会位于低秩的空间中。 在剩下无法被主要背景像元表示的稀疏部分中存在着异常像元, 则可以被检测算法提取出来。 在低秩表示中, 背景像元字典的构建将会影响高光谱图像中背景像元的表示。 如直接从现有高光谱图像中提取背景像元构建字典, 会导致异常像元对背景像元字典的污染。 而利用待检测高光谱图像观测数据和由光谱组成原理可合成的潜在未观测数据来构建背景像元字典, 提取出背景像元的主要特征, 有利于更好地分离出稀疏异常像元的信息。 并且高光谱图像数据存在高维几何结构特点, 通过引入拉普拉斯矩阵来约束空间中局部相似的像元对于待检测像元的表示作用, 获得更接近于真实的表示系数。 实验结果分别在仿真数据和真实数据上验证, 与传统方法相比, 提出的方法通过有效地突出异常像元提高了检出率和抑制了背景像元, 降低了误检率。
With the widespread use of hyperspectral images, hyperspectral image technology has made considerable progress, of which hyperspectral image anomaly detection technology has received more and more attention. In order to solve the problem of poor practicability and poor detection effect of traditional hyperspectral image anomaly detection techniques, this paper presents a novel low rank representation detection algorithm. For hyperspectral images, most of the background pixels can be approximated by a small number of major background pixel combinations, and their representation coefficients will be located in a low-rank space. While the remaining anomalous pixels in the sparse part that can not be represented by the main background pixels can be extracted by the detection algorithm. In low-rank representations, the construction of the background pixel dictionary will affect the representation of the background pixels in the hyperspectral image. When extracting the background pixels directly from the existing hyperspectral image to construct the dictionary, this process will lead to the contamination of the background pixel dictionary by the abnormal pixels. So in this paper, the background pixel dictionary is constructed by using the observed data on the hyperspectral image to be detected and the potential unobserved data that can be synthesized by the principle of spectral composition, and the main features of the background pixels are extracted, helping to better separate the sparse anomalous pixel Information. Hyperspectral image data is characterized by high-dimensional geometry. In this paper, we introduce a Laplacian matrix to constrain the representation of locally similar pixels in the space to be detected, and get a closer representation of the true representation coefficients. The experimental results are validated respectively on the simulation data and the real data, showing that the proposed method reduces the false detection rate by effectively highlighting the abnormal pixels and improves the detection rate by suppressing the background pixels.
与传统多光谱遥感数据相比, 高光谱遥感数据具有波段多、 光谱分辨率高、 空间分辨率低等特点, 这使得高光谱遥感图像面临着诸多问题, 例如:像元内部地物混杂、 噪声干扰、 目标探测虚警率高等[1]。 光谱特征能够反应目标本质属性, 从而使利用光谱特征进行目标检测更加可靠[2]。 高光谱中蕴含的丰富光谱信息, 就成为了光谱维目标探测的重要信息支持, 使得位于图中更细小的目标能够被检测出来, 这也是高光谱目标探测近些年来迅速发展的原因所在[3]。
高光谱目标探测算法可简单的分为异常检测和光谱匹配[4]两类。 在实际中, 由于缺少光谱匹配所需要完备光谱数据库和准确的反射率反演算法, 异常检测算法则不需要任何先验知识, 通过找出与图中大部分像元分布规律不同的离群点即可, 更符合实际需求。 异常检测算法在多个领域具有重要作用, 比如战场侦察、 海域搜救救援、 探索稀有矿石以及诊断癌细胞等。
异常检测算法中最著名的是RX(Reed-Xiaoli)算法, RX算法假设背景服从多元高斯分布, 利用概率密度函数进行预测检测点属于背景的概率, 等同于求解背景和检测点的马氏距离。 然而由于多元高斯分布无法表示复杂背景, 且噪声和异常点的存在导致背景协方差矩阵求逆过程出现不平稳的解等问题。 因此更多的RX改进型算法被提出, 比如解决求逆过程不平稳问题的Reg-RX(Regularized RX)[5]; 通过先聚类再进行RX检测来解决背景复杂问题的Seg-RX(Segmented-Based RX); 通过核函数来解决像元分布非线性的KRX(Kernal-RX)等等。 由于RX固有的限制, 也提出不同于RX的算法, 比如基于协作表达的异常检测算法CRD(collaborative-representation-based detector)[6], 对异常像元难以被检测外框内的像元即背景像元进行表示; 基于对窗理论的DWEST(dual window-based eigen separation transform)假设异常像元处在检测内外窗协方差之差的特征空间中等等。 其中基于低秩表示的方法受到更多的关注。 RPCA-RX(robust principle component analysis based Reed-Xiaoli)利用鲁棒性主成份分析和RX算法结合进行检测; LRaSMD(low-rank and sparse matrix decomposition)[7]利用低秩和稀疏矩阵分解将数据分为低秩部分和稀疏部分, 假设背景数据位于单一的低秩子空间中, 而稀疏部分是异常像元; LRASR(low-rank and sparse representation)[8]基于混合像元的存在假设背景数据位于多个低秩子空间中, 通过训练背景字典来恢复潜在的多个子空间, 并提出了背景字典训练的方法。
在此, 提出了一种拉普拉斯约束低秩表示的高光谱异常检测算法LRLRR(laplacian regularized low-rank representation)。 利用高光谱图像上的观测像元和未观测到的像元即由光谱组成原理可合成的潜在像元, 这两类像元作为背景字典。 进行低秩表示提取出背景像元的主要特征和显著特征, 从而分离出稀疏的异常部分。 并利用拉普拉斯限制像元的局部信息相似性, 降低误检程度的同时提高异常像元的检出率。 新算法分别在仿真数据和真实数据中获得明显的提升。
假设高光谱图像的波段数为B和像元数为N, 则可以使用Xo={xi
假设背景像元可以用其他的背景像元来线性组合表示, 且在实际中用于表示的组合系数往往会是低秩的。 因此引入Latent LRR(latent low-rank representation)[9]模型解决该问题, 可以得到如下的表达式(1)
这里[Xo, Xh]表示字典, Z∈ RN× N是表示矩阵, Xh表示不存在于待检测高光谱图像上的像元, 而是通过光谱组成原理可合成的潜在像元即未观测像元, rank(· )表示矩阵的秩。 通过Liu的理论3.1[9]可知观测像元和未观测像元同样来自于低秩的空间。 并推导出通过利用两者的信息获得更准确的背景表示, 获得表达式(2)
这里简化方程X=Xo, T∈ RB× B。 其中XZ为背景信息的主要特征, TX为背景信息中的显著特征。 通过Liu的论文[9]可以证明rank(Z)和rank(T)这两部分是自动平衡的, 无需进行参数调整。 对于高光谱图像, 这意味着同时利用光谱相似的像元和光谱维度上典型波段进行背景像元表示。
由于异常像元属于无法用线性组合表示的部分, 通过l2, 1范数引入异常项‖ E‖ 2, 1=
这里τ 作为平衡异常像元部分的系数, 通过调整它的大小来控制异常的概率。
尽管Latent LRR模型通过引入观测数据和未观测数据[Xo, Xh]作为字典, 以全局的信息对数据样本进行表示。 但是在实际中, 空间中的数据样本往往可以由全局中某些典型的数据样本线性组合而成, 而大部分的数据样本在表示中仅仅占据少量成分。 对应于高光谱图像, 像元光谱特征往往是由少数典型的像元近似地表示[8]。 所以引入l0范数约束背景表示矩阵Z, 这会使系数矩阵在所有列上都表现出稀疏的特性, 将l0范数放松到l1范数近似求解。
这里β 作为平衡背景表示矩阵Z的稀疏性。
当假设邻近像元邻近关系为线性的时候, 高光谱像元上的每个像元都来自潜在的子流形M中。 这些像元的局部几何结构可以用他周围邻近像元重构而成。 本工作将会构造一个带有n个顶点的k最邻近图G, 高光谱每个像元表示顶点。 通过构造对称的权重矩阵Wij, 他的值表示第i像元同第j像元的相连的权重系数。 构成一个无向图G=(V, E; W), 其中V表示顶点的集合, E表示边的集合, 权重矩阵W的取值如式(5)。
这里Nknn(xi)表示像元xi的最近的knn个邻像元。
根据高光谱像元在数据分布的内部几何体越靠近, 则它们在重新投影到新的空间中也将会相互靠近的。 所以通过保护顶点对之间的仿射变换的低维向量来描述图G的顶点, 他们之间的相似性可以通过边的权重来衡量, 可以表示为
这里zi和zj表示像元xj和xj通过某些变换的投影。 拉普拉斯矩阵可以通过L=D-W得到, 其中度矩阵D是一个对角矩阵, 它的对角线上的值为dij=
将拉普拉斯正则项加入模型中
其中α 为控制拉普拉斯约束的权重。 称该模型为拉普拉斯约束低秩表示。 运用该模型进行高光谱图像异常检测。
从数据中恢复低秩信息的优化问题有很多解决方法, 交替方向方法ADM(alternating direction method)[11]是其中最有效的工具。 为了高效解决该模型, 运用自适应惩罚的线性交替方向算法LADMAP(linearized alternating direction method with adaptive penalty)[12]来解目标方程。
在这个目标方程中, 引入辅助变量来帮助分离目标。 优化问题可以重新表述为
该方程是约束优化问题, 引入两个拉格朗日乘子Y1和Y2将这两个线性等式约束移除。
其中μ 作为惩罚参数, 根据策略进行调整。 主要通过固定其他变量求解一个变量, 交替迭代进行。
(1)固定J, E, 求解Z, T
其中定义
算法1 高光谱异常检测算法
输入: X, 参数β > 0, τ > 0, α > 0, knn> 0
输出: 异常程度分布图D(· )
初始化: Z0=J0=Y1, 0=0∈ RN× N, E0=Y2, 0=0∈ RB× N, T0=0∈ RB× B, μ 0=0.05, μ max=1010, ρ 0=1.2, ε 1=2× 10-4, ε 2=1× 10-5, k=0, η Z=η T=‖ X
1. 通过计算每个xi的knn最近邻来构造W, 得到拉普拉斯L=D-W。
2. 循环开始, 当‖ X-XZk-TkX-Ek‖ F/‖ X‖ F≥ ε 1或者μ kmax(‖ Zk-Zk+1‖ F, ‖ Tk-Tk+1‖ F, ‖ Jk-Jk+1‖ F, ‖ Ek-Ek+1‖ F)/‖ X‖ F≥ ε 2。
3. 根据式(17)更新Zk+1
4. 根据式(18)更新Tk+1
5. 根据式(19)更新Jk+1
6. 根据式(21)更新Ek+1
7. 更新拉格朗日乘子Y1, k+1和Y2, k+1
8. 更新μ k+1
9. μ k+1=min(μ max, ρ μ k)这里
10. 更新迭代次数k=k+1
11. 结束循环
12. 输出
该问题可以分成两个问题求解
其中qZ, qT为跟Z和T相关的子梯度。
使用奇异值阈值算子(SVT)Θ (· )可以获得闭合解。
(2)固定Z, T, E, 求解J。
同样固定其余变量, 来优化求解
求这个子问题可以有如下近似解。 其中S(· )是收缩算子(shrinkage)。
(3)固定Z, T, J, 求解E。
同样固定其余变量, 来优化求解
求这个子问题可以有如式(21)近似解
其中Ω (· )是l2, 1最小化X算子。
算法1总结了本方法的步骤, 其中初始化参数时, Z0, J0, Y1, 0, E0, Y2, 0以及T0矩阵作为优化问题的初始点, 可以设为零矩阵或者随机矩阵。 μ 0和μ max是控制拉格朗日算子更新的速率, ρ 0则是控制μ 的变化, 这三个参数根据迭代速度设置。 ε 1和ε 2决定迭代的误差的大小, 根据需要检出异常的量级来设置大小。 k表示算法迭代的次数。 η Z和η T是归一化数。 算法1将会输出图像中异常程度分布图。
使用仿真数据和真实数据来验证方法。
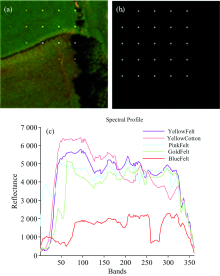
仿真数据来自于罗切斯特理工大学(RIT)在美国纽约大都会区罗切斯特市附近飞行采集的实验数据集, 波长为400~2 500 nm, 共360个波段, 全部波段用于实验。 空间分辨率为1 m。 用于合成仿真图像的数据分为背景数据和异常数据:背景数据取长为100像元, 宽为100像元, 波段为360的图像块, 如图1(a)所示; 异常数据为五种材料, 分别是黄色的毛毡(Yellow Felt), 黄色的棉布(Yellow Cotton), 粉色的毛毡(Pink Felt), 金色的毛毡(Gold Felt)和蓝色的毛毡(Blue Felt)的光谱, 如图1(c)所示。 合成仿真数据过程中, 将利用异常的光谱以不同的成分大小同背景数据进行线性融合, 如式(22)
如图1(b)所示, 以每行对应不同的材料光谱Sa和图中从左到右的(i, j)位置光谱的Sb, 按每列为异常占的比重f的大小, 从小到大进行合成S(i, j)后放置于同一位置(i, j)。
 | 图1 (a)仿真数据的伪彩图; (b)真实分布图; (c)异常的光谱曲线Fig.1 (a) False color image of the simulation data; (b) Ground-truth map; (c) The spectral profile of anomaly |
第一份真实数据同样来自罗切斯特理工大学(RIT)数据。 取其中长宽为100像元, 波段360的图像块, 如图2(a)。 图中的异常目标为事先铺设好的布, 异常点占所有像元的1.35%, 他的真实分布图如图2(b); 第二份真实数据是来自AVRIS上采集的美国加利福尼亚州的圣地亚哥市飞机场。 图像块由波长为370~2 510 nm采集的224个波段组成的。 空间分辨率为3.5 m。 在去除掉对应的水汽吸收区域、 信噪比低和损坏的波段后(1— 9, 101— 115, 151— 179和217— 224), 剩余183个波段用于实验。 空间上取长为100像元, 宽为100像元的图像块进行测试, 如图3(a)所示。 图中飞机作为异常数据进行检测, 异常点占所有像元的0.62%, 它的真实分布图如图3(b); 第三份真实数据是来自机载的HYDICE光谱数据。 该数据的空间分辨率为每像元1米。 波长分辨率为10 nm的210个波段数据, 去除水汽吸收区域、 低信噪比以及损坏的波段(1— 4, 76, 87, 101— 111, 136— 153, 198— 210)后剩下的长宽分别为100像元、 80像元的162个波段, 如图4(a)所示。 图中的异常为汽车, 占全部像元的0.21%, 他的真实分布图如图4(b)。
 | 图2 (a)罗切斯特理工大学数据的伪彩图和(b)真实分布图Fig.2 (a) False color image of the RIT data; (b) Ground-truth map |
 | 图3 (a)圣地亚哥数据的伪彩图和(b)真实分布图Fig.3 (a) False color image of the Sandiego data; (b) Ground-truth map |
 | 图4 (a)都市数据的伪彩图和(b)真实分布图Fig.4 (a) False color image of the Urban data; (b) Ground-truth map |
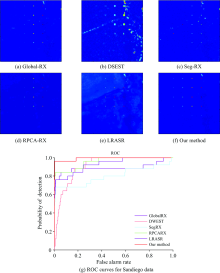
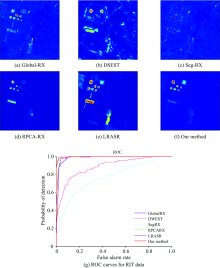
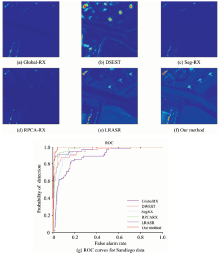
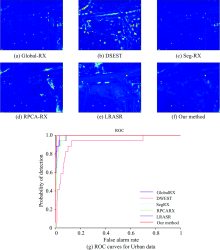
实验将分析和对比不同的六种算法在四类数据中的检测性能。 由检测的目视结果图定性的评价算法的效果。 图5中色彩条表明在目视结果图中, 色彩越接近蓝色端判定为背景概率越高, 而色彩越接近红色端则意味着判定为异常概率越高。 除此之外, 还分别绘制出Global-RX(Global Reed-Xiaoli), DWEST, Seg-RX, RPCA-RX, LRASR和本算法在各个数据集上的ROC(receiver operating characteristic)曲线, 并统计出各自AUC(area under the curve)值进行定量的对比。 结果表明提出的算法明显突出异常像元的分布, 且在同样的误检率(false alarm rate)下, 将获得更高的检测率(probability of detection)。
 | 图5 异常色彩条Fig.5 Colorbar for anomaly |
对于仿真数据, 算法对比的目视结果图如6(a)— (f)所示。 可以看出随着异常成分所占比率的升高, 本算法在准确的位置检出更高的异常值, 这表明异常更显著。 并且本算法在异常值低于0.3以下时依然可以检出异常, 较其他的五种算法相比明显效果更佳。 不同算法的ROC曲线如图6(g)所示, 可以看出本算法的ROC曲线包裹住其他方法的曲线即说明新算法在性能上更加优异。 特别是在0.01~0.3的误检率之间, 本方法获得了更好的检测率, 远远高于另外五种算法。 新算法在误检率为0.2左右时, 能检出所有的异常值。
 | 图6 不同方法的对仿真数据的检测结果和ROC曲线Fig.6 The detection results and ROC curves by different methods for simulation data |
对于罗切斯特理工大学的数据, 图7(a)— (f)所示为六种算法对于他的目视结果图。 相较于Global-RX, DWEST, Seg-RX传统算法, 基于低秩原理的另外其他三种方法获得更好的检测效果; 本算法通过未观测数据表示和低维流形的约束, 对于罗切斯特理工大学的数据中房子部分的抑制获得更好的效果。 减少房子的检出将会在同样误检率下提高检测率。 ROC曲线如图7(g)所示也表明了本算法的效果。
 | 图7 不同方法的对RIT数据的检测结果和ROC曲线Fig.7 The detection results and ROC curves by different methods for RIT data |
圣地亚哥数据集中, 六种算法的目视结果图如图8(a)— (f)所示。 由于地物背景种类很多导致RPCA-RX效果不明显, 是因为RPCA-RX本身是基于单一子空间的算法, 对于位于多子空间上的数据无法获得较好的检测率。 而LRASR和本算法是基于低秩表示的, 对于多子空间中的数据能更好的检测出异常。 LRASR和本算法在目视结果中没有太多的差别。 通过他们的ROC曲线分析, 如图8(g)所示。 在0.02~0.14误检率之间新算法检测率明显较LRASR更高。 主要因为LRASR依赖于字典的构建, 他无法避免字典构建过程中, 异常的意外引入导致的字典污染, 致使不正确的表示。 而新算法通过全部高光谱图像上观测数据和潜在的未观测数据表示, 无需进行额外的字典训练过程, 并引入拉普拉斯约束限制异常像元参与待检测像元的表示, 所以效果更好。
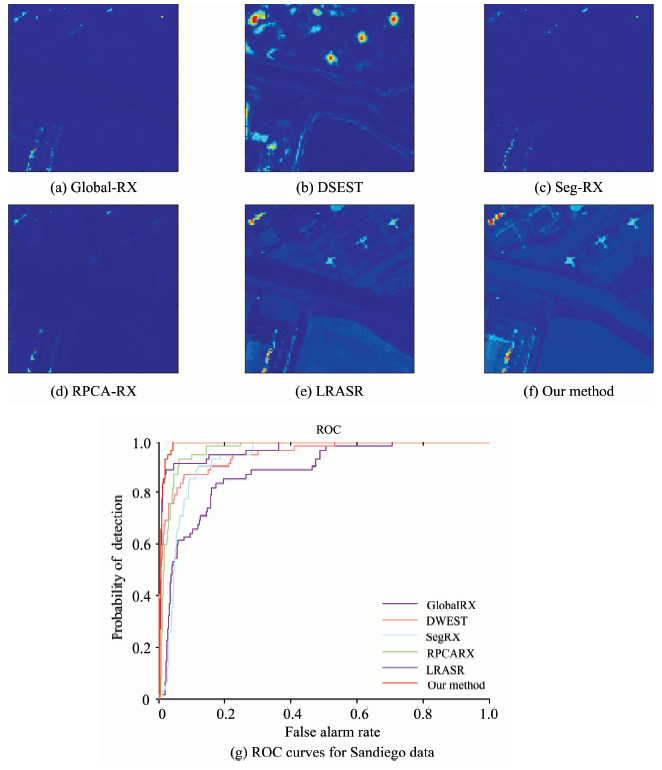 | 图8 不同方法的对圣地亚哥数据的检测结果和ROC曲线Fig.8 The detection results and ROC curves by different methods for Sandiego data |
图9(a)— (f)所示的是六种算法对于城市数据的效果图和图9(g)所示是其ROC曲线图。 图中异常的比例较低, 本算法依然有效的提高了异常的检出率。 图中可以看出公路与草地等背景均具有低秩的特点, 在新算法中将会抑制具有低秩属性背景来突出图中异常像元。
 | 图9 不同方法的对城市数据的检测结果和ROC曲线Fig.9 The detection results and ROC curves by different methods for Urban data |
表1是对六种算法对不同数据在ROC曲线下的面积AUC对比。 其中AUC的值越接近百分百, 说明检测器的性能更加优异。 本算法将检测率稳定在99%以上, 几乎达到了100%的程度, 相对于其他的算法提高了大约1%2%的AUC。 本检测算法比其他五个传统算法优异。
| 表1 对于不同数据用不同算法获得的AUC(%) Table 1 AUC obtained by different methods for different datasets(%) |
从高光谱图像异常检测问题中背景像元处在低秩空间和异常像元则具有稀疏特点出发, 提出利用低秩和稀疏理论解决问题。 根据实际应用中表示字典难以提前训练, 运用Latent Low-Rank Representation的理论, 利用获取高光谱图像中观测像元和未观测像元即根据现有像元结构推断出来的像元信息, 来构建背景像元字典。 同时将拉普拉斯约束和稀疏约束引入检测算法中。 拉普拉斯限制距离对表示权重影响。 稀疏约束限制对待检测像元低秩表示起作用的像元个数。 最终得到的更接近真实数据的表示系数。 通过提出利用拉普拉斯约束低秩表示的高光谱异常检测算法, 无需用训练字典算法, 有利于运用到实际中。 并且本方法获得准确的表示系数, 与传统方法相比在同样的条件下获得更好的检测率。 由于低秩稀疏理论的特点, 可以预见未来会有更多基于低秩稀疏理论在高光谱图像异常检测上的运用, 有望获得更好的效果。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|