
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
直接校正算法的柑橘溃疡病高光谱模型传递
[翁海勇 , 岑海燕
, 岑海燕* , 何勇]
, 岑海燕, 何勇]
|
|


作者简介: 翁海勇, 1989年生, 浙江大学生物系统工程与食品科学学院博士研究生 e-mail: Hyweng@zju.edu.cn
针对目前所建立的柑橘溃疡病高光谱模型普适性差、 预测精度低的问题, 提出了基于不同仪器间高光谱模型传递来提高模型稳健性的方法。 以脐橙52和卡拉卡拉红肉脐橙为研究对象, 利用实验室高光谱成像平台(System 1, S1)和便携式高光谱成像仪(System 2, S2)采集了健康和染病柑橘的高光谱图像, 建立了独立的柑橘溃疡病判别模型, 并分析了不同预处理方法和判别模型对模型预测性能的影响。 将S1和S2分别作为源机和目标机, 利用直接校正算法对目标机获取的高光谱图像进行校正, 分析模型传递前后的模型判别能力。 结果表明, 采用二阶导数预处理, 极限学习机预测性能最佳, 基于S1和S2检测的预测集识别率分别为97.5%和98.3%; 以S1数据建立主模型, 对经直接校正算法校正后的S2高光谱图像进行识别, 预测集的识别率从校正前的38.1%提高到了86.2%。 说明该方法可用于不同型号高光谱成像仪之间的定标模型传递, 对于建立稳健可靠的柑橘溃疡病判别模型具有重要意义。
There is existence of poor universality and low prediction precision in citrus canker hyperspectral models in previous research. It is necessary to investigate an approach to improve the robustness of hyperspetral model transfer between different instruments which proposed to improve the robustness of the calibration model. Hyperspectral images of two different varieties including Navel Orange 52andCaraCarawere acquired using a laboratory hyperspectral imaging system (System 1, S1) and a portable hyperspectral imaging system (System 2, S2). The discriminant models for the citrus canker detection were developed based on the images from S1 and S2, respectively, and different pretreatment and classification methods were also investigated. Meanwhile, direct standardization (DS) algorithm was used to calibrate hyperspectral images collected by S2 which was considered as the slave while S1 as the master, and the performance of the discriminant model were evaluated before and after the model transfer. It was shown that the best discriminant results were achieved by the extreme learning machine (ELM) combined with the second-order derivative with the classification accuracies of 97.5% by S1 and 98.3% by S2, respectively. By using DS, the classification accuracy increased from 38.1% to 86.2% after the model transfer. It is demonstrated that the DS algorithm is useful for the calibration model transfer between different instruments, which would be helpful for developing a robust method for the citrus canker detection.
柑橘溃疡病是一种世界性柑橘细菌性病害[1], 由Xanthomonascitripv.citri (Xcc)细菌引起, 通过气孔或者伤口侵入柑橘组织[2], 引发柑橘顶梢枯死甚至落叶、 果实表面受损, 严重影响了柑橘的产量和品质[3], 在商业贸易活动中被列为强制性检疫疾病。 目前, 柑橘溃疡病的检测手段主要是基于植物生理学和分子生物学等[4], 或者通过有经验的专家人工识别, 劳动强度大、 成本高。 因此, 需要一种快速准确的检测手段, 以便更加有效地控制柑橘溃疡病疫情。
高光谱成像技术因其快速、 无损、 高效等优点逐渐被应用在柑橘种植领域。 李江波等[5, 6]应用高光谱成像技术实现了不同柑橘果实病害与溃疡病的识别, 提出了一种基于主成分分析与波段比值相结合的算法, 建模集和预测集的识别率为99.5%和84.5%。 Qin等[7, 8]采用高光谱成像技术结合光谱信息散度(spectral information divergence, SID)分类算法对葡萄柚溃疡病和其他柑橘病害进行检测, 模型识别率可达90%以上。 Balasundaram等[9]比较了溃疡病和其他柑橘果实病害的光谱特征, 应用统计学方法筛选出能够识别不同柑橘病害的波长, 最后得到的有效波长分布在可见-近红外波段范围之内, 模型的识别率为100%。 上述对柑橘溃疡病识别模型的研究只适用于某一特定型号的仪器, 对不同型号高光谱成像仪之间柑橘溃疡病识别模型的传递研究较少。 在实际生产实践中, 若针对不同型号的高光谱成像仪所测的光谱分别建模, 不仅效率低, 而且需要收集更多的样品, 实用性不高。 因此需要进行不同仪器间的模型传递, 以提高模型的泛化能力[10]。
目前, 模型传递最常用的算法主要包括直接校正(direct standardization, DS)[11]和分段直接校正(piecewise direct standardization, PDS)[12], 一些研究者也对这些方法进行了优化与改进。 Liu等[13]提出了一种分段直接校正结合线性插值(piecewise direct standardization combine with linear interpolation, PDS-LI)的传递算法, 研究了不同品种猪肉含水率高光谱模型的传递。 校正之后, 主模型对从品种的预测决定系数
鉴于不同型号的高光谱成像仪之间柑橘溃疡病识别模型的传递研究较少, 本工作以脐橙52和卡拉卡拉红肉脐橙为研究对象, 以实验室高光谱成像平台作为源机采集光谱信息并建立主模型, 应用直接校正算法对便携式高光谱成像仪采集的光谱图像进行校正, 并研究了不同预处理方法、 判别模型、 标样数以及模型参数对判别模型预测性能的影响。
脐橙样品采于福建省福州市闽侯柑橘基地。 柑橘品种为脐橙52和卡拉卡拉红肉脐橙。 选择大小相当青果期的脐橙52正常样本和感染溃疡病样本分别为58个和48个, 卡拉卡拉红肉脐橙的正常样本和感染溃疡病样本各75个, 总共256个样本。 采摘后的样品编号后装在自封袋中, 并保存在4~8 ℃的冷藏箱。
用两种不同型号的高光谱成像仪采集脐橙高光谱图像。 实验室高光谱成像系统(System1, S1)主要包括分辨率为672× 512 pixels的CCD相机(C8484-05, Hamamatsu Photonics, Hamamatsu City, Japan)、 波长范围为379~1 023 nm、 分辨率为2.8 nm光谱仪(ImSpector V10E, Spectral Imaging Ltd., Oulu, Finland)、 线光源(Fiber-Lite DC950, Dolan Jenner Industries Inc., Boxborough, MA)、 电控移动平台、 暗箱和电脑。 电控移动平台移动速度为2.2 mm· s-1, 物镜距离为32 cm, 曝光时间45 ms。 便携式高光谱成像仪(System2, S2) 采用美国SOC公司的SOC710VP (Surface Optics Corporation, San Diego, CA), 参数设置为: 积分时间35 ms, 被测样品表面与镜头的距离31cm, 相机分辨率为696× 520 pixels, 光谱仪波长范围为373~1 043 nm、 分辨率为4.69 nm。 高光谱图像采集前, 首先获取暗电流和参考板的高光谱图像数据, 用于数据处理前对原始高光谱图像的校正, 校正公式为
式中: R为校正后的图像, Iraw为原始图像, Idark为暗电流图像, Iref为参考板图像。
运用MATLAB 7.12.0 读入校正后的高光谱图像数据。 为了获取目标区域的光谱反射率, 首先建立掩膜文件, 得到目标区域。 对于正常样品, 把整个样品作为感兴趣区域; 对于染病样品, 把染病区域作为感兴趣区域。 提取感兴趣区域的平均光谱反射率。 通过MATLAB对S1采集到的高光谱图像进行像素2× 2 binning, 以便得到与S2相同的波段数和分辨率。
由于光谱的前后波段信噪比较低, 选取了403~1 021 nm波长范围内的118个波段进行光谱分析。 选择标准正态变量变换(standard normal variate transformation, SNV)、 二阶导数(2nd derivative)以及多元散射校正(multiplicative scatter correction, MSC)和原始光谱(Raw)四种类型预处理方法, 分析不同的预处理方法对模型预测性能的影响。 采用Kennard/Stone(KS)算法将样本按2:1的比例分成建模集和预测集。
判别模型的性能直接影响数据的分析结果。 选择最邻近节点算法(K-nearest neighbor algorithm, KNN)、 簇类独立模式识别(soft independent modeling of class analogy, SIMCA)和极限学习机(extreme learning machine, ELM)建立三种判别模型。 比较分析不同判别模型的预测性能, 根据模型的识别效果, 选择最佳的模型用于后续的模型传递分析。
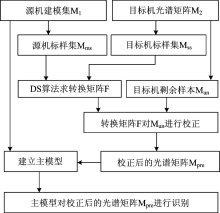
利用不同型号的高光谱成像仪对同一批样品进行测量, 由于仪器的响应不同, 得到的高光谱图像会有所差异, 为了使所建立的模型具有普适性, 需要对其中一台仪器采集到的光谱信息进行校正。 被校正的仪器作为目标机, 用来建模的仪器称作为源机。 采用直接校正算法[16], 建立目标机和源机之间的关系。 直接校正算法流程图如图1所示。
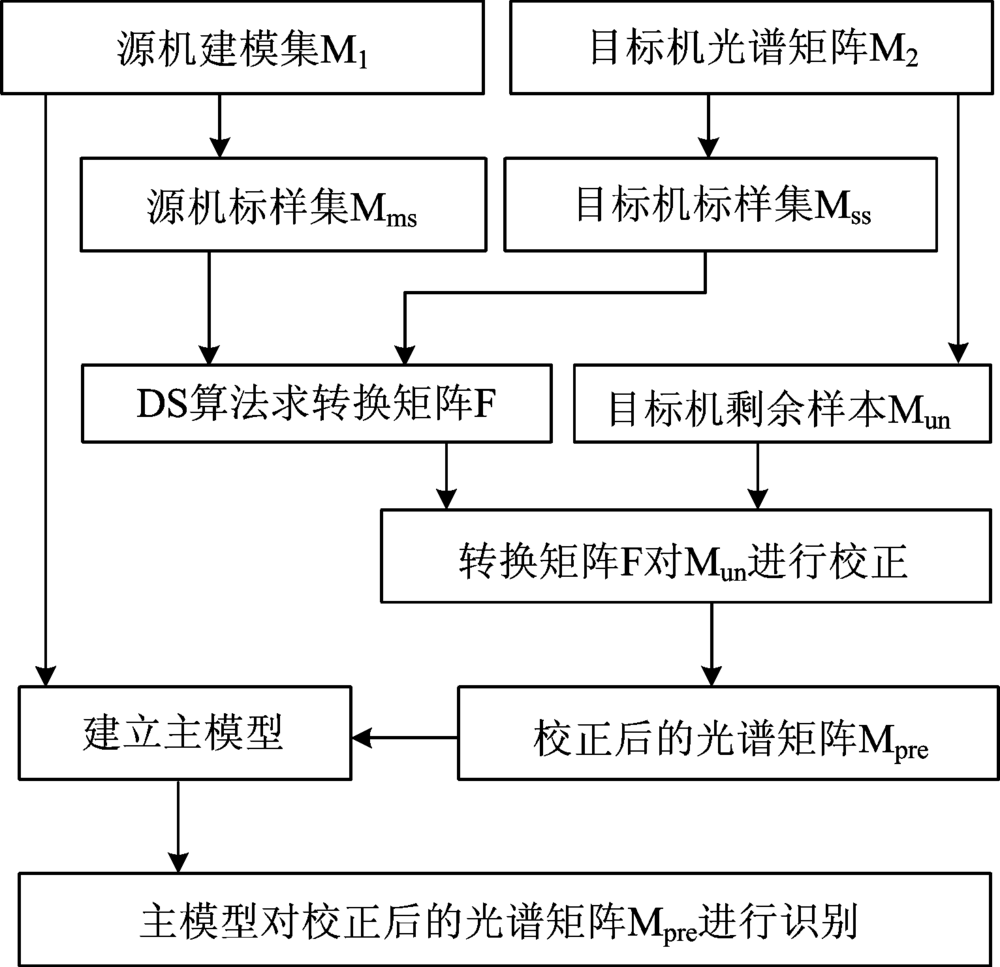 | 图1 直接校正算法流程图Fig.1 Procedure of direct standardization algorithm |
基于直接校正算法的模型传递, 首先从源机和目标机中选择标样数, 计算转换矩阵F; 然后将校正后的光谱输入到判别模型; 最后, 分析模型的判别结果。 在此过程中, 标样数和算法参数的选取均会影响模型的识别结果。 选择标样数范围为[15, 30], 隐含层节点数范围为[4, 52], 步长均为3, 试验不同的组合参数以便获得最佳的预测结果。
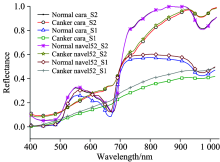
两台不同型号的高光谱成像仪所测得的柑橘平均光谱反射率曲线如图2所示。 分析图2, 可以看出两台仪器的响应存在较大的差异。 同一品种柑橘, S2测得的光谱反射率大于S1。 对于健康样本, 在680~750 nm波长范围内的反射率急剧上升, 均出现了“ 红边” 效应。 在970 nm位置均存在波谷, 这与果实内部的水分有关; 对于染病样本, 在680~750 nm波长范围内没显现出“ 红边” 效应, 说明病斑区域的叶绿素含量较少。 而在970 nm处仍存在由于水分吸收而形成的波谷。
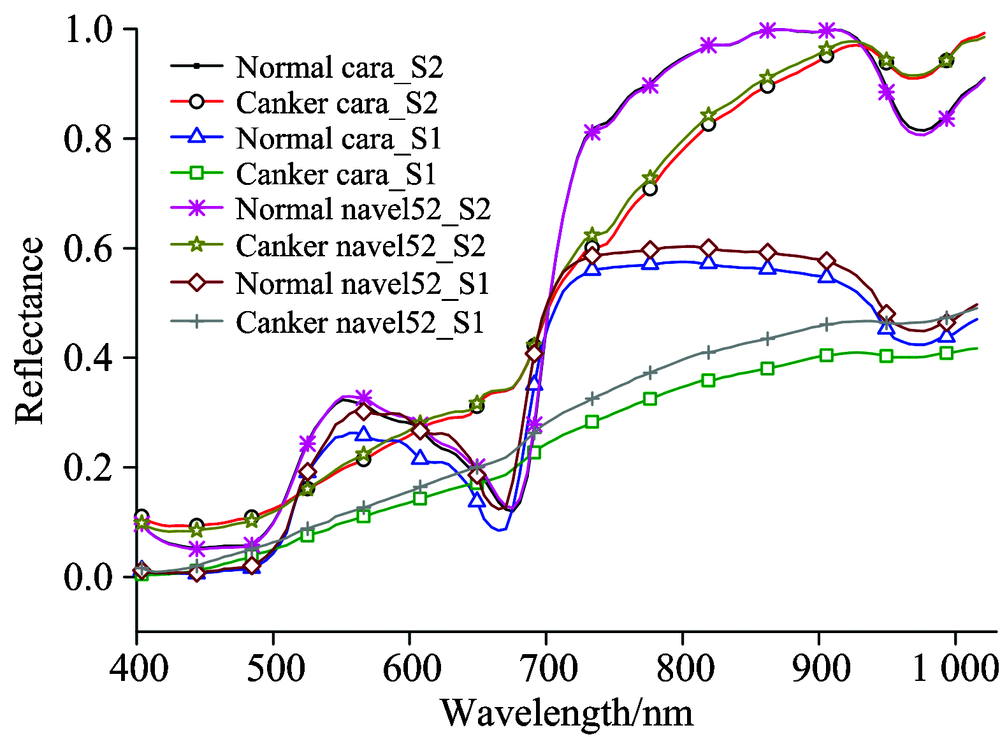 | 图2 两台不同高光谱成像系统采集到的健康和溃疡病样品平均光谱图 S1: 高光谱成像平台; S2: 便携式高光谱成像仪Fig.2 Mean spectra of normal and cankerous citrus samples obtained by two different systems S1: system 1; S2: system 2 |
选择标准正态变量变换、 二阶导数以及多元散射校正和原始光谱四种预处理方法。 判别模型选择最邻近节点算法、 簇类独立模式识别和极限学习机。 在极限学习机建模中, 通过预实验选择sigmoid函数作为激活函数, 隐含层节点数选为44。 运行10次, 平均值作为模型最终的识别效果, 如表1所示。
| 表1 基于不同预处理方法和判别模型的对两台高光谱成像系统获取到的高光谱图像对柑橘溃疡病的分类结果 Table 1 Classification results of normal and cankerous citrus samples based on different pretreatments and discriminant models of hyperspectral images acquired by two systems |
由表1可知, 基于四种不同的预处理方法建立的极限学习机模型, 两台仪器的建模集和预测别率均大于90%。 极限学习机模型的识别效果优于另外两种判别模型。 其中, 采用2nd Derivative-ELM的建模方法, 建模集和预测识别率最佳, 均大于95%。 所以, 选择二阶导数结合极限学习机作为脐橙52和卡拉卡拉红肉脐橙正常和染病样本的判别模型是可行的。
为了对比验证S1建立的主模型对S2所测样品的预测效果, 根据表1的分析结果, 选择二阶导数算法对光谱进行预处理, 选择极限学习机的激活函数为sigmoid函数, 设定隐含层节点数范围为[4, 52], 步长为3, 模型的识别结果如图3所示。
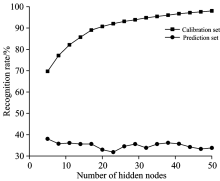
 | 图3 不同隐含层节点数的极限学习机模型对柑橘溃疡病的分类结果(S1的高光谱图像作为建模集, S2的高光谱图像作为预测集)Fig.3 Classification results of normal and cankerous citrus samples using extreme learning machine (ELM) with different number of hidden nodes by the calibration model transfer (System 1 as the master for calibration set and System 2 as the slave for prediction set) |
分析图3, 在节点数范围为[4, 52]内, 二阶导数预处理后建立的极限学习机判别模型建模集的识别率随着隐含层节点数的增加而增加, 节点数为4时, 建模的识别率最低, 为69.2%; 当节点数增加至52时, 建模的识别率达到98.1%, 提高了28.9%。 预测集的识别率均小于40%, 在节点数为4时最大, 为38.1%, 增加隐含层的节点数无法进一步提高预测集的识别率, 模型的识别效果较差。 因此, S1建立的模型无法对S2采集到的高光谱图像进行识别, 需要对模型进行传递修正, 提高模型的泛化能力。
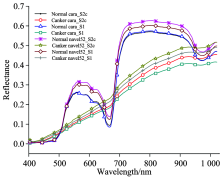
以S1作为源机, 以S2作为目标机。 图4可以看出, 经过直接校正算法校正之后, 源机与目标机同类样品的平均光谱趋势一致, 有效地消除了两个系统所测得的高光谱图像的差异。
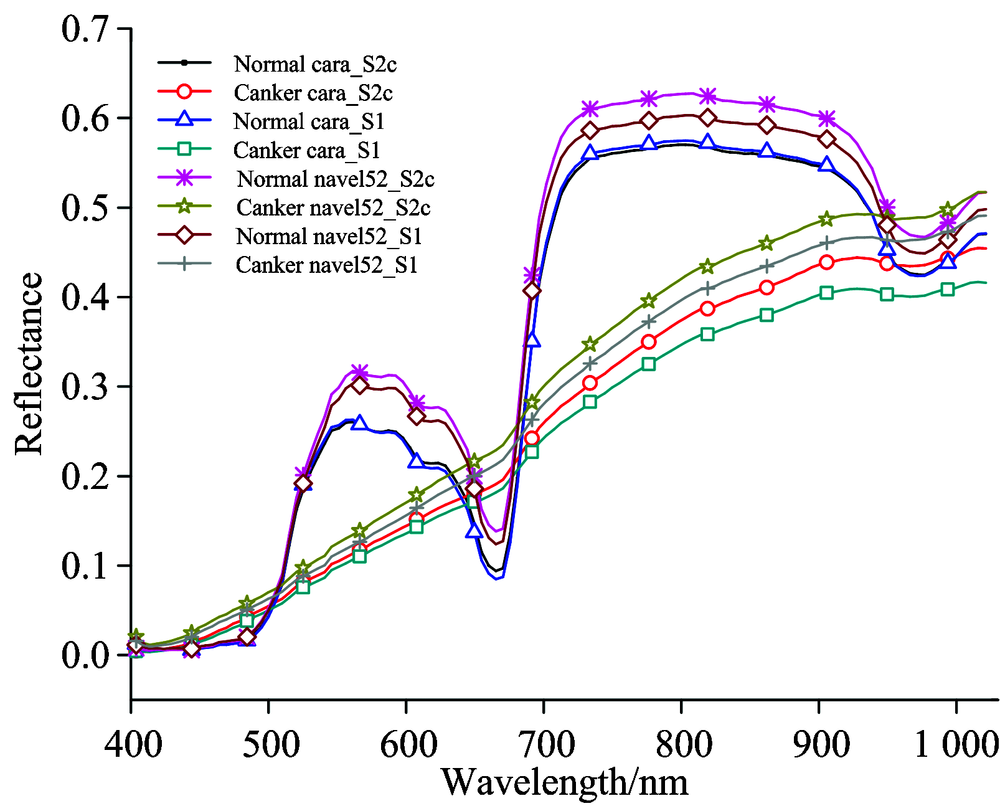 | 图4 源机S1和经直接校正算法校正后的目标机S2得到的健康和染病样品的平均光谱图Fig.4 Mean spectra of normal and cankerous citrus samples obtained by System 1 and System 2 with the direct standardization |
针对不同的参数组合, 建立了极限学习机判别模型, 并计算各自建模集和预测集的识别率, 结果以蛛网图 (Spider plots) 的形式表示。 表示隐含层节点数为25, S15表示标样数为15, 依此类推。 模型的识别效果如图5所示。
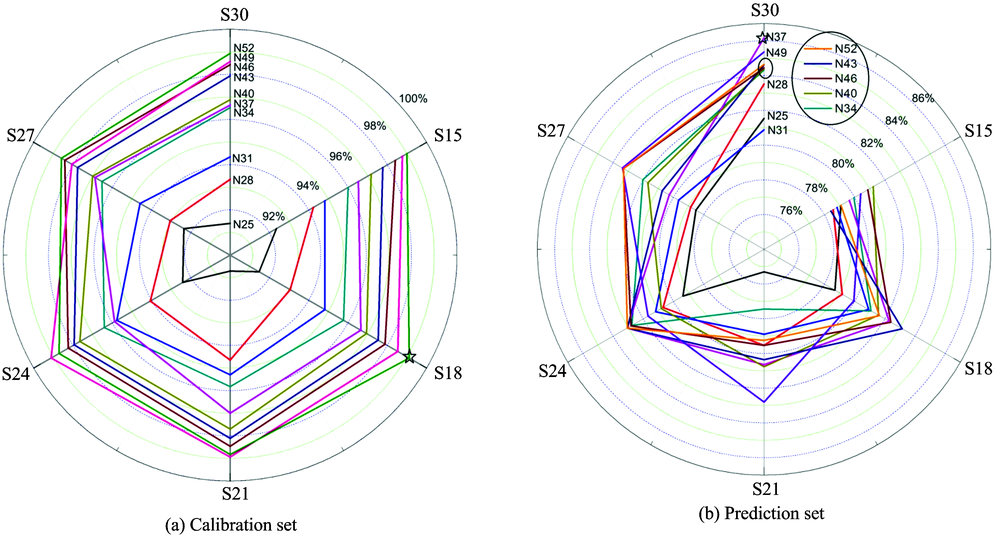 | 图5 标样数和隐含层节点数对传递结果的影响Fig.5 Effect of number of standard samples and number of hidden nodes on transfer results |
分析蛛网图5, 标样数和隐含层节点数对2nd Derivative-ELM模型预测性能有不同程度的影响。 总的来说, 标样数相同时, 建模集识别率随着隐含层节点数增加而增大; 隐含层节点数相同时, 增加标样数对建模蒋的识别率提高不显著。 建模集的识别率最高点为(18, 52, 99.1%), 依次代表标样数、 隐含层节点数和识别率, 对应的预测集识别率81.6%; 预测集的识别率最高点为(30, 37, 86.2%), 对应的建模集识别率96.6%(图5星号标注点)。 与校正之前的预测集识别率的最大值38.1%相比, 提高了48.1%。 当隐含层节点数和标样数分别大于34和24时, 建模集和预测集的识别率均大于80%。 上述结果表明, 经过直接校正算法校正之后, S1建立的主模型适用于对S2未知样品的判别。
利用S1和S2采集同一批脐橙的高光谱图像, 建立了独自的判别模型, 并分析了不同预处理方式和判别模型对模型预测性能的影响。 结果显示, 采用2nd Derivative-ELM的建模方法, 建模集和预测识别率最佳, 均大于95%。 表明二阶导数结合极限学习机建立的模型可以实现脐橙52和卡拉卡拉红肉脐橙正常和染病样品识别。 由于不同型号仪器的响应函数不同, S1建立的主模型无法直接用于预测S2采集到的高光谱图像。 因此, 以S1作为源机和S2作为目标机, 利用直接校正算法对目标机获取的高光谱图像进行校正。 当标样数30, ELM的隐含层节点数37时, 2nd Derivative-ELM模型的预测性能最佳, 建模集和预测集的识别率分别为96.6%和86.2%。 说明基于直接校正算法的二阶导数结合极限学习机判别模型可实现不同型号高光谱成像仪之间柑橘溃疡病高光谱模型的传递。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|