
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Y-梯度广义最小二乘加权校正的土壤速效氮野外原位光谱预测
[齐海军1, 2  , KarnieliArnon
, KarnieliArnon2 , 李绍稳1, * ]
, KarnieliArnon]
|
|


作者简介: 齐海军, 1991年生, 安徽农业大学信息与计算机学院与本古里安大学雅各布·布劳斯汀沙漠研究所联合培养博士研究生e-mail: haijun.qi0418@qq.com
土壤速效氮是影响作物生长发育的重要养分指标。 野外原位可见近红外光谱(VIS-NIR)分析技术具有快速无损等特点, 对速效氮的定量预测具有较好的应用前景。 野外条件下进行原位光谱采集更节省人力物力, 且为土壤养分实时传感器的开发提供了数据基础。 但由于野外原位光谱中通常存在大量的无关环境因子干扰信息, 易导致回归模型预测精度降低, 达不到实用要求。 针对位于以色列中部和北部的两个试验点共76个样本开展研究, 提出利用Y-梯度广义最小二乘加权算法(Y-GLSW)对样本的野外原位VIS-NIR反射率光谱(350~2 500 nm)进行滤波校正, 以提高回归模型的预测能力。 首先使用SG平滑、 一阶导数变换、 标准正态变换等常规方法对原始光谱进行预处理和变换; 在此基础上再使用Y-GLSW构建滤波模型对变换后的光谱进行滤波校正; 最后使用偏最小二乘回归算法(PLS-R)分别结合原始光谱RW、 预处理变换后的光谱PPT和滤波校正后的光谱Y-GLSW建立回归分析模型对速效氮进行定量预测。 结果表明: 利用RW光谱建立的回归预测模型是不可靠的; 利用PPT光谱建立的回归模型在测试集的相对分析误差(RPD)为1.41, 解释总方差占实际总方差之比(SSR/SST)为0.57, 模型具有一定的可靠性; Y-GLSW光谱建立的回归模型在测试集的RPD和SSR/SST分别为2.07和0.69, 相对于PPT模型分别提高了46.81%和21.05%。 因此, 利用Y-GLSW对野外原位VIS-NIR光谱进行滤波校正, 能够有效去除光谱中的无关信息数据, 提高模型的预测精度和解释能力。
Soil available nitrogen is supposed to be an important nutrient constituent for the growth and development of crops. In-situ field visible-near infrared (VIS-NIR, 350~2 500 nm) spectroscopic analysis is a rapid and non-destructive method that has the potential to predict nitrogen. Further, it is cost-effective method compared with traditional laboratory analysis and can be used to provide a database for the development of real-time soil nutrient sensors. However, prediction accuracy was greatly reduced due to unexpected environmental factors under field condition. In the current research, field work contained 76 samples from two sites located in the center and north parts of Israel. Y-gradient general least squares weighting (Y-GLSW) algorithm was investigated to filtering correct the field VIS-NIR spectra for improving the prediction ability of nitrogen. Firstly, Savitzky-Golay (SG) smoothing algorithm, first derivative transformation and standard normal variate were sequentially conducted to preprocess and transform the raw field spectra (RS). Then, a filtering model was established based on the Y-GLSW algorithm to correct the preprocessed and transformed spectra (PPT). After that, partial least square - regression (PLS-R) algorithm was applied to build regression models with RS, PPT, and Y-GLSW corrected spectra, respectively. As a result, the regression model based on RS was proved to be unfeasible. The ratio of performance to deviation (RPD) and the ratio between interpretable sum squared deviation and real sum squared deviation (SSR/SST) of the test set of the PPT-based regression model were found to be 1.41 and 0.57, respectively. The results of Y-GLSW-based regression model were RPD = 2.07 and SSR/SST=0.69 that significantly increased by 46.81% and 21.05% compared with PPT-based regression model. The results indicated that Y-GLSW was suitable to remove some unexpected variations (like the effect of environmental factors) of field spectra and improved the prediction accuracy and explanation ability of PLS-R model for predicting nitrogen.
速效氮(available nitrogen, AN)是土壤中的重要营养成分, 通常包括铵态氮和硝态氮, 会直接影响作物的生长发育和最终产量。 其精确测量或估算对测土配方施肥、 作物高产稳产以及资源节约利用等都具有重要意义。 而传统的实验室理化测试方法由于耗时、 费力、 低效等缺陷, 已不适应精准农业的发展要求。 可见近红外光谱(VIS-NIR)分析技术具有快速、 无损、 高效等特点, 目前已被广泛应用于土壤成分检测中[1]。
利用室内近红外光谱对土壤AN的预测, 国内外均有相关文献报道。 吴茜等[2]建立的局部神经网络回归模型, 估测的相关系数达到了0.90。 Shao等[3]利用偏最小二乘支持向量机建立了回归模型, 估测的相关系数也达到了0.90。 Paz-Kagan等[1]以及Ji等[4]利用近红外光谱对AN进行定量回归分析, 均取得了较高的预测精度。 野外原位光谱检测作为一种更加便携、 快速的检测方法, 已被成功的应用于土壤有机质、 有机碳以及总氮等养分指标的检测中。 土壤AN含量低, 且在近红外光谱区域(350~2 500 nm)没有明显的吸收带。 自然光、 温度、 土壤水分等外界环境影响因子[4], 以及不同土壤的表面属性和内部成分差异等因素也加大了AN的野外检测难度。 Kodaira等[5]开发并改进了一套传感系统能够在田间实时采集地下土壤反射率, 并利用整个VIS-NIR反射率和PLS-R进行铵态氮和硝态氮的预测, R2分别为0.69和0.45。 Liu等[6]对AN的野外预测相对分析误差RPD值超过1.4, Ji等[4]的预测R2和RPD 分别达到了0.76和1.91。
可以看出, 土壤AN的野外预测效果相对于室内环境下还有较大差距。 如何去除环境因子等无关信息的影响, 提高野外预测精度, 已成为相关领域的研究重点。 目前, 野外原位光谱的环境因子去除算法主要包括基于室内光谱库的Spiking算法、 光谱预处理与变换(preprocessing and transformation, PPT)以及光谱滤波校正(filtering correction)等。 Spiking算法结合室内光谱库和野外代表性光谱建立校正模型, 能够显著提高模型的泛化性能[7]。 但工作量较大, 短期难以实现。 光谱预处理与变换如求导、 多元散射校正及其他数学方法处理, 常被用于去除系统噪声影响, 对于野外环境因子的去除效果欠佳。 光谱滤波校正算法如正交信号校正(OSC)[8], 额外参数正交化(EPO)[9], 广义最小二乘加权(GLSW)[10]等, 能够针对光谱中的无关影响因素建立特定的滤波模型, 实现对原始光谱的校正, 从而提高野外预测精度, 已被广泛应用于去除光谱水分影响的研究[7, 11, 12]。
我们提出利用Y-梯度广义最小二乘加权算法(Y-GLSW)对野外原位光谱进行滤波校正, 以去除光谱中无关的环境因子等信息数据, 再结合偏最小二乘回归(PLS-R)建立土壤AN的定量分析模型, 从而提高土壤AN的野外原位光谱预测精度。
野外试验在以色列内盖夫沙漠北部的Migda实验农场和加利利地区东部的Karei-Deshe实验农场开展, 土壤类型分别为沙质黄壤土和玄武岩基棕壤土。 不同的土地利用方式, 如小麦种植、 放牧、 休耕等使土壤的AN含量有较大差异。 分别在两个农场随机选取了48和28个采样点, 共76个。 野外光谱试验时间选在干旱季节的末期, 能够最大程度减小环境因子如水分、 植被和云层对试验的影响[13]。
采用美国ASD公司的Field Spec® 便携式光谱仪进行野外原位土壤光谱的测量。 为了减小自然光的影响, 利用自带光源的高密度接触式反射探头直接垂直紧贴土壤表面进行光谱测量。 每个采样点采集4次用以得到平均光谱, 同时每次测量均利用标准白板校正, 得到采样点的反射率。 该光谱仪波长范围为350~2 500 nm, 光谱分辨率在350~1 000 nm为3 nm, 在1 001~2 500 nm波段为8~10 nm, 经重采样后, 得到分辨率为1 nm的反射率光谱。
光谱采集后, 利用土钻在每个采样点0~15 cm深处进行土壤采样, 并封存送到实验室进行风干、 研磨和过筛。 利用称重法测量土壤水分, 所有的样本含水率均不超过0.2%, 因此可以忽略水分对光谱的影响。 最后使用氯化钾溶液提取法对土壤AN的含量进行测量, 测量结果统计数据如表1所示。
| 表1 土壤速效氮的描述统计量 Table 1 Descriptive statistics of soil AN (mg· 100 gr-1) |
在两组数据集中各随机选取70%的样本(共54个)作为训练集结合建模, 以提高预测模型的适用性; 剩余的22个样本作为测试集, 验证模型的泛化效果。
光谱反射率曲线在首尾区域有较低的信噪比, 影响建模预测精度, 因此仅使用400~2 400 nm的光谱作为原始光谱 (raw spectra, RS)进行进一步分析。 使用以下组合方法对光谱进行预处理与变换: (1)首先使用2阶15点多项式Savitzky-Golay卷积平滑算法(SG)对光谱曲线进行平滑去噪; (2)再对光谱进行一阶导数(FD)变换去除基线和背景的影响; (3)然后使用标准正态变换(SNV)来消除固体颗粒大小、 表面散射以及光程变化对光谱的影响; (4)建立与应用滤波模型或回归模型之前, 分别对光谱矩阵和AN浓度向量做均值中心化处理, 以保持相同标度。 预处理变换后的光谱称为PPT光谱。
浓度相似或相同的样品, 在外界因子的影响下, 光谱会出现一定的差异。 GLSW以差异矩阵为参考, 建立加权滤波模型, 用以消除外界因子对光谱的影响[10]。 但当样品的浓度差异较大时, 差异光谱矩阵会携带与被测对象(即AN含量)相关的特征信息, 而不应该被滤掉。 为此, Zorzetti等[14]提出了基于Y-梯度变化的广义最小二乘加权算法(Y-gradient general least square weighting, Y-GLSW)。 算法主要思路如下:
(1)按照被测对象浓度y梯度递增的顺序同时对y和光谱矩阵X进行排序, 数据每1行代表1个样本;
(2)利用1阶5点多项式的SG滤波1阶求导, 对X矩阵的每1列(即每个光谱特征)进行导数变换, 得到光谱差异矩阵Xd, 该矩阵每1行(即每个样本)代表了它与邻近4个样本的平均差异, 同时y也执行类似操作, 得到被测对象差异向量yd;
(3)将yd转化为对角再加权矩阵W, 其第i个对角元素计算如下: log2(wi)=-yd, isyd, 其中yd, i是yd中的第i个元素, syd是yd的标准差;
(4)利用W对Xd再加权, 并计算协方差矩阵: C=
(5)协方差矩阵奇异值分解: C=VS2VT, 其中V是左特征向量, S是奇异值的对角矩阵;
(6)计算加权和变换脊后的对角矩阵: Sw=
(7)利用特征值和加权奇异值的逆来计算滤波矩阵: G=V
(8)利用滤波矩阵对需要校正的光谱即输入光谱Xinput进行投影滤波: Xoutput=XinputG。
正则化参数α 为标量, 可以用来控制奇异值的增益大小, 进而调节滤波程度。 α 越小(如0.000 1等), Sw趋近于0, 滤波程度越大。 反之, α 越大, Sw趋近于1, 滤波程度越小。
偏最小二乘回归(PLS-R)算法利用对自变量和因变量系统中的数据信息进行分解和筛选的方式, 提取对因变量的解释性最强的综合变量, 辨识系统中的有用信息和无关信息, 克服变量多重相关性的影响, 从而建立适当的预测模型。 建模过程中, 潜在变量(又称主成分)个数是模型优化的关键, 本工作采用10-折交叉验证的方式, 以训练集最小平均误差为标准确定最佳潜在变量个数。
模型预测性能使用相对分析误差RPD(标准偏差除以均方根误差, SD/RMSE), 作为评价标准; 同时利用解释总方差占实际总方差之比SSR/SST(计算方式为:
使用MATLAB R2016a (MathWorks, Natick, Massachusetts, USA)和PLS-Toolbox 8.0 (Eigenvector Research Incorporated)进行数据处理分析。
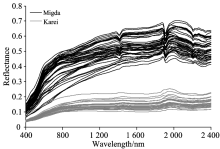
两个实验农场的原始土壤光谱如图1所示, 可以看出两组光谱均有随着波长的增加反射率逐渐增加的趋势, 但Migda农场的土壤反射率明显高于Karei农场。 Migda农场的沙质黄壤土成分主要包括20%的黏土, 38%的壤土和42%的沙土, 而Karei农场的玄武岩基棕壤土却是65%的黏土, 11%的壤土和24%的沙土。 不同的土壤成分使光谱反射率特征产生了较大差异, 且黏土矿物成分及其含量的不同, 使1 400, 1 900和2 200 nm的水分吸收峰差生了形状和深度上的差异。
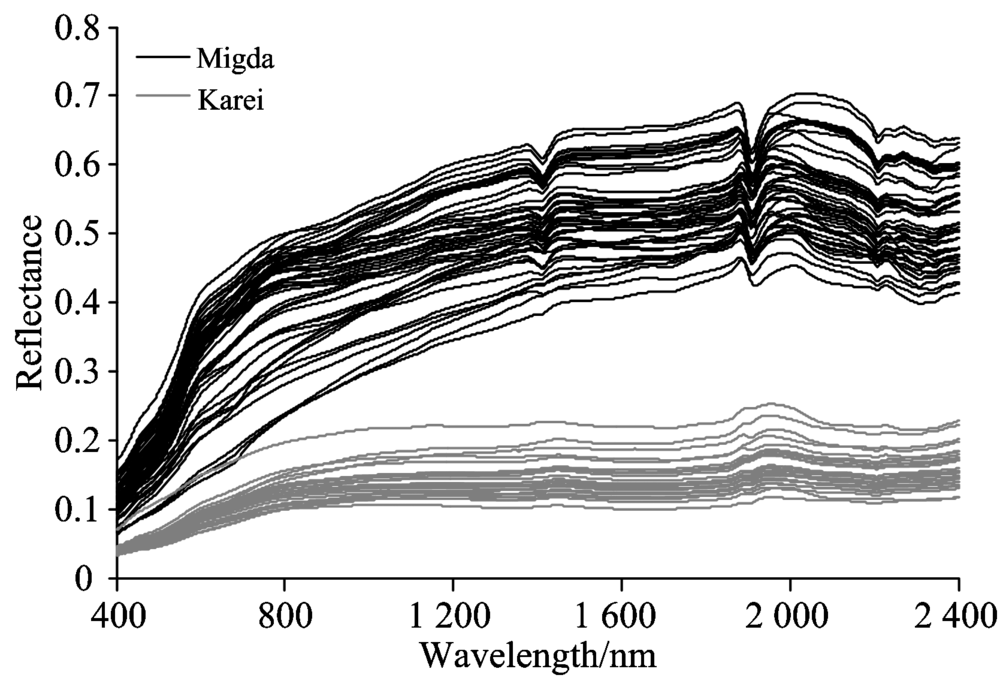 | 图1 土壤样本的反射率光谱Fig.1 Spectral reflectance of soil samples |
使用欧氏距离法, 在训练集中选择20个代表性样品进行梯度排序, 按照1.3节中的方法建立滤波模型。 正则化参数α 直接控制滤波程度, 对建模效果有较大影响。 为了选择最优的滤波参数, 先依次从[10-4, 10-3, …, 103]中取值分别建立滤波模型, 对光谱矩阵进行滤波校正, 再使用PLS-R建立回归模型, 测试集的预测结果如图2所示。
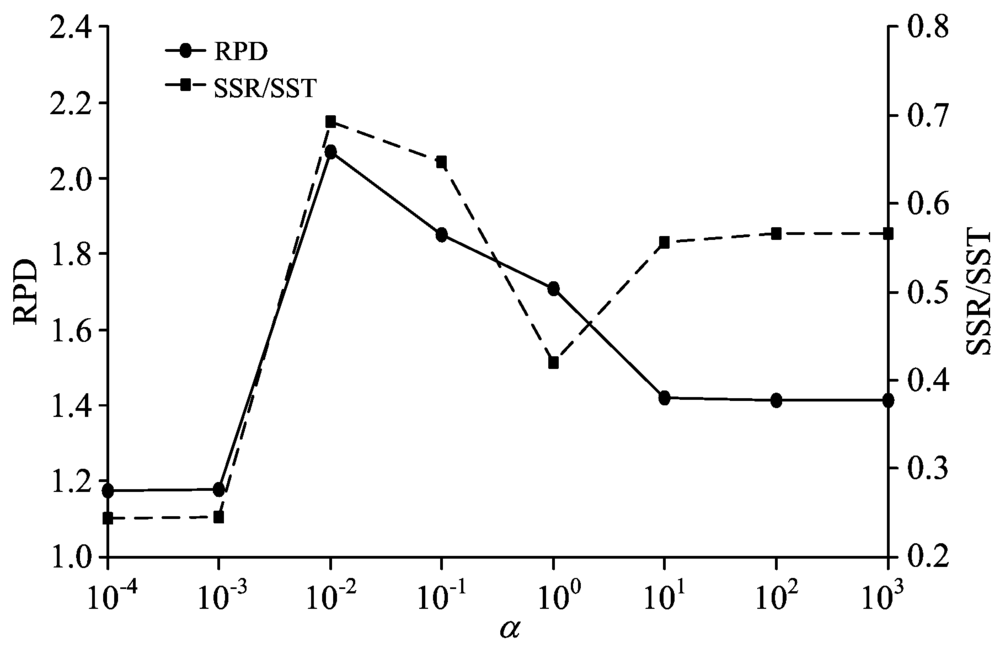 | 图2 不同α 取值下的模型性能Fig.2 Model performance with various α |
从图2可以看出, 随着α 的增加, 即滤波程度的从强到弱, 回归模型的预测精度呈现先增高再降低的趋势, 模型解释能力总体也有类似的结果。 这是因为, 当滤波程度太强的时候也会将一些与土壤AN含量相关的重要特征信息过滤掉, 从而严重影响模型的性能。 当滤波程度太小时, 一些噪声信号依然存在, 对模型产生一定的干扰。 因此选择α =0.01建立滤波模型, 对光谱进行校正处理。
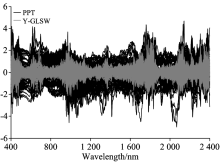
预处理变换后的光谱和利用Y-GLSW滤波校正后的光谱如图3所示。 可以看出, Y-GLSW可以有效的对光谱数据进行滤波, 原始光谱信号中的数据被一定程度上加权收缩[10], 一些特征峰被移除, 并生成了新的特征峰。
 | 图3 预处理变换后的光谱和滤波校正后的光谱Fig.3 Preprocessing and transformed spectra and filtering corrected spectra |
基于PLS-R算法分别使用原始光谱RW、 预处理变换后的光谱PPT和滤波校正后的光谱Y-GLSW对土壤AN含量建立回归模型, 训练集和测试集的结果如表2所示。 从训练集结果可以看出, 经预处理和变换后, 模型的RPD值和SSR/SST值, 都得到了显著提高, 再经过Y-GLSW滤波校正处理, 两个数值都进一步增加。 在测试集中, RW模型RPD值为1.64, 甚至超出了训练集的结果, 但SSR/SST仅为0.46, 因此预测模型是不可靠的。 PPT模型的测试集RPD值降低较多, 仅为1.41, SSR/SST值却达到了0.57, 因此PPT模型具有一定的可靠性。 利用Y-GLSW滤波变换后的光谱数据进行建模预测, RPD值达到了2.07, 按照文献[1]中的标准, Y-GLSW模型预测能力等级达到了A类。 且模型解释能力也相对于预处理变换光谱模型也得到了明显提高。 因此, 可以确定图3中Y-GLSW滤波去除的信息数据为环境中或系统中的无关噪声信号数据。
| 表2 不同建模方法的模型性能 Table 2 Model performance of different methods |
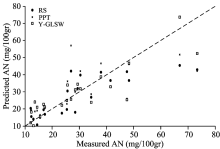
图4为22个测试集样本的土壤AN实际理化测量值与三种光谱模型预测值的对比散点图。 从图4可以看出, 三种模型在AN含量较低的时候预测结果差异不大, 但当AN含量增加时, RS模型和PPT模型的预测结果就明显变差。 相对来说, Y-GLSW模型的预测数据较为均匀的分布在y=x这条直线的两侧, 说明Y-GLSW模型具有更稳健的预测能力。 这与表2中的结果也是相符合的。
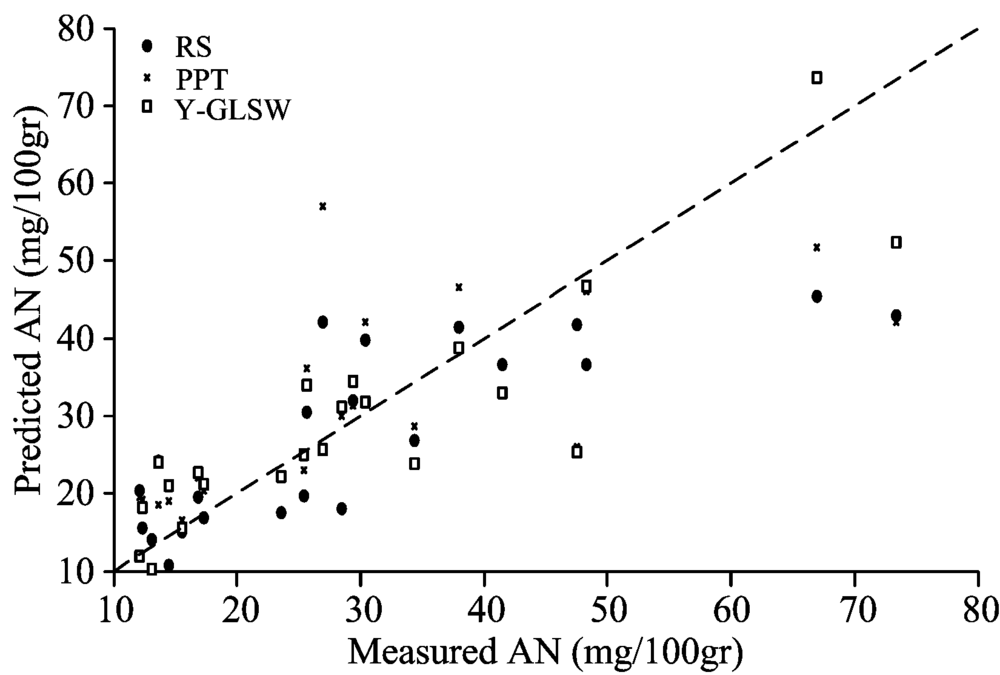 | 图4 不同建模方法实测值与预测值的散点图Fig.4 Scatter plot of measured values versus predicted value of different methods |
表2中Y-GLSW模型使用了11个潜在变量, 这可能是由于AN在土壤中以无机态氮为主, 而氮素在VIS-NIR光谱的直接响应波段主要是有机态的N— H键发生能级跃迁的倍频峰和合频峰; 且AN的含量较低, 一般仅占总氮的5%[4], 因此确实需要更多的间接光谱数据信息来反应AN的光谱特征, 这也就解释了模型解释能力不够强, 即SSR/SST值不是很高的原因。 在PPT模型中, 由于噪声信号的存在对模型的训练产生了影响, 虽然仅使用7个潜在变量, 训练集就达到了较好的效果, 但模型在测试集的泛化能力却相对Y-GLSW模型降低了很多。
采用Y-GLSW算法对野外原位VIS-NIR光谱进行滤波校正, 再使用PLS-R建立了土壤AN的回归预测模型, 并与常规预处理变换对比分析。 结果表明, Y-GLSW算法能够有效去除光谱中环境及系统的干扰信号数据, 在预处理变换的基础上将RPD值和SSR/SST值分别提高了46.81%和21.05%, 从而显著提高模型的预测能力和解释能力。 本研究为野外原位VIS-NIR光谱影响因素的去除提供了一种有效的解决方案, 后期将重点以农田潮湿土壤为对象开展预测模型的研究。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|