
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于荧光光镊与机器学习的单细胞血液分类方法
[周哲海 , 熊涛, 赵爽, 张帆, 朱桂贤]
, 熊涛, 赵爽, 张帆, 朱桂贤]
, 熊涛, 赵爽, 张帆, 朱桂贤]
|
|


作者简介: 周哲海, 1978年生, 北京信息科技大学光电测试技术及仪器教育部重点实验室教授 e-mail: zhouzhehai@bistu.edu.cn
利用物种间血液成分的差异来识别物种, 对生物医学、 医疗健康、 海关、 刑侦、 食品安全、 野生动物保护等工作十分重要。 但目前的研究都是针对群体细胞展开, 忽略了单细胞的异质性, 开展基于单细胞的血液光谱分类方法研究非常迫切。 在此提出了一种基于荧光光镊和机器学习的单细胞血液分类方法, 利用光镊实现了单细胞捕获, 通过荧光光谱检测系统获得了单细胞荧光光谱数据, 并基于机器学习方法实现了准确分类。 首先, 设计并搭建了一套荧光光镊系统, 实现了单细胞捕获和荧光光谱检测。 然后, 制备了马、 猪、 犬、 鸡四种动物的红细胞稀释液, 以440 nm激光作为荧光激发光源, 获得了四个物种每种100条、 共计400条荧光光谱数据, 并进行了背景去除、 平滑、 归一化的预处理, 消除了信号中的噪声干扰。 随后, 建立了随机森林分类模型, 分析了当抽取特征数 k=20时, 模型中树的棵数与预测准确率之间的关系, 当决策树 m=500时, 分类正确率趋于稳定, 有很高的分类正确率和运行效率。 进一步地, 设定样本数据的30%作为测试集、 70%为训练集, 计算不同波长与特征重要性之间的关系, 得到了10个分类准确率, 并取平均值作为模型分类的准确率, 测试集最终准确率达到93.1%, 方差为0.31%。 最后, 计算了混淆矩阵, 对模型预测精度进行了评价, 鸡的分类正确率最高, 马的分类正确率最低。 分析表明, 对分类有重要贡献的物质分别是卟啉类物质、 血红素和黄素腺嘌呤二核苷酸。 总之, 研究表明, 将荧光光镊与机器学习方法相结合, 可实现单细胞水平的血液分类, 较高的分类正确率验证了这种方法的可行性和有效性。 同时, 该方法不需要过多样品就能满足建模需求, 避免了因浓度低带来的荧光自吸收强度过低等问题, 具有快速、 准确分类的优点, 具有非常重要的潜在应用价值。
It is very important to use the differences in blood components between species to identify species in biomedicine, medical health, customs, criminal investigation, food safety, wildlife protection and so on. However, the current research is carried out on population cells, ignoring the heterogeneity of single cells. Therefore, it is very urgent to develop a single-cell-based blood fluorescence spectral classification method. A single-cell blood classification method is proposed based on fluorescence optical tweezers and machine learning. The optical tweezers are used to achieve single-cell capture, and the single-cell fluorescence spectrum data is obtained through the fluorescence spectrum detection system. The accurate classification is realized based on the machine learning method. First, a fluorescent optical tweezers system was designed and built to realize single-cell capture, fluorescence imaging and spectral detection were obtained. Then, the whole blood solutions of horses, pigs, dogs and chickens were prepared, and using 440 nm laser light as the fluorescence excitation light source, 100 pieces of fluorescence spectrum data for each of 4 species, including horse, pig, dog and chicken, totalling 400 pieces of fluorescence spectrum data were obtained, and the preprocessing of background removal, smoothing and normalization was carried out to eliminate instrument noise and environmental interference in the signal. Subsequently, a classification model of the random forest was established, and the relationship between the number of trees in the model and the prediction accuracy was analyzed when the number of extracted features k=20, and it was found that when the decision tree was m=500, the classification accuracy tended to be stable, and at the same time obtaining a high classification accuracy and operating efficiency. Further, 30% of the sample data was set as the test set and the rest as the training set. The relationship between different wavelengths and feature importance was calculated, 10 classification accuracy rates were obtained, and the average as the model classification accuracy rate was taken. The final average accuracy rate of the test set reaches 93.1%, and the variance is 0.31%. Finally, the confusion matrix was calculated, and the model's prediction accuracy was evaluated. Chickens had the highest classification accuracy, and horses had the lowest accuracy. The analysis showed that the important contributions to the classification were porphyrins, heme and flavin adenine dinucleotide. In conclusion, the study shows that the combination of fluorescent optical tweezers and machine learning methods can achieve blood classification at the single-cell level, and the high classification accuracy validates the feasibility and efficiency of the optical tweezers-based single-cell fluorescence spectroscopy detection method. At the same time, this method can meet the modeling needs without too many samples and can avoid problems such as low fluorescence self-absorption intensity caused by low concentration. It has the advantages of fast and accurate classification and has very important potential application value.
血液承担着运输人体废物和分泌物的任务, 对血液的分析可以反映出人或动物器官或组织的健康情况, 因此关于血液的研究一直是生物医学领域的研究热点。 传统血液鉴别方法有高效液相色谱法、 质谱法、 定量PCR法和DNA分析法等[1]。 以上几种方法都需要添加试剂, 不但耗时, 而且操作流程复杂, 对样品具有破坏性。 相比之下, 荧光光谱分析法操作简单、 准确性高, 因此更适合作为一种血液分类的研究手段, 特别是与机器学习算法相结合, 极大提高了检测分类的精度[2, 3, 4]。 血液中存在许多受激后可产生自体荧光的分子, 如卟啉、 氨基酸、 色氨酸等, 因此血液的荧光光谱能反映内部物质吸收光能量后产生的能量转移情况, 而利用这些信息可以对一些血液疾病进行诊断与病理研究。
Devanesan等利用荧光光谱技术对地中海贫血、 缺铁性贫血两种疾病进行了分类研究, 结果表明, 血浆荧光光谱的某些信息能够对这两种疾病进行可靠且简单的分类[5]。 糖尿病是一种常见疾病, 王磊等将糖尿病大鼠的红细胞与健康大鼠红细胞的荧光光谱进行对比, 通过光谱信息之间的差异, 分析了糖尿病对老鼠血液的影响[3]。 高斌等获取了四种动物不同浓度(1%和3%)的全血与红细胞荧光光谱数据, 建立了对不同动物血液荧光光谱的BP神经网络分类器, 实现了不同动物、 不同浓度的血液荧光光谱100%的准确分类[2]。 同时, 基于血液分类的荧光光谱分析法作为一种灵敏度高、 非侵入的检测手段, 也已经成为鉴别癌变组织的一种很好的方法[6, 7, 8]。
利用物种间血液成分的差异来识别物种, 不仅对生物医学, 对海关、 刑侦、 食品安全、 野生动物保护等工作也十分重要, 因此设计一种能够依据血液对不同物种实现快速、 准确分类的方法是十分必要的。 但上述研究都是针对群体细胞展开的, 忽略了单细胞的异质性, 在肿瘤细胞中, 少数的基因变异需要用单细胞的瘤内异质性来阐述, 这样可以更深入的研究癌症及治疗[9]。 单细胞荧光光谱的研究可以更好地揭示细胞的运作机理和细胞间的相互作用; 同时, 对于针对群体细胞的分类研究, 若将光谱数据作为数据集建立分类模型, 需要大量实验样品进行重复测试, 若样品本身较少或较为珍贵, 则这种群体测试手段可能并不适用。 因此, 开展基于单细胞的血液荧光光谱分类方法研究非常迫切。
同时, 光镊技术提供了一种独特微粒操控手段[10], 相比于应用较多的拉曼检测技术, 荧光信号强度约比拉曼信号高5~7个量级, 如何发挥荧光检测的高灵敏度特性, 对单分子和单细胞领域的相关研究具有重要意义。 将光镊与荧光光谱技术相结合, 为开展单细胞的荧光光谱检测提供了解决方案。
本工作提出一种基于荧光光镊和机器学习的单细胞血液分类方法, 利用光镊实现了单细胞捕获, 通过荧光光谱测量系统获得了光谱数据, 并基于机器学习方法实现了准确分类。 这种方法不需要过多样品就能满足建模需求, 而且能够避免因浓度低带来的荧光自吸收强度过低等问题, 具有快速、 准确分类的优点。
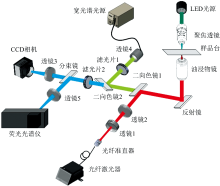
设计并搭建了一种基于光镊的单细胞荧光光谱检测系统, 即荧光光镊, 图1给出了系统结构示意图。 系统主要由两个模块组成, 即光镊模块和荧光检测模块。 首先组建光镊模块, 光纤激光器发出的光束经过光纤准直器后变为准直光束, 然后通过透镜1和透镜2扩束, 再经过二向色镜1和反射镜反射进入油浸物镜, 形成聚焦光斑, 将放置在平移台上的溶液器皿中的细胞捕获住; 为了能够观察到捕获的细胞, 用LED光源照射捕获的细胞, 并成像在CCD相机上。 为了能够在CCD相机上观察到捕获的细胞图像, 二向色镜1、 二向色镜2、 滤光片2要能够透射全部或部分LED光束到CCD相机上, 这需要使LED光束的光谱范围在二向色镜1、 二向色镜2、 滤光片2各个器件的透射光谱范围内。 在这个基础上, 继续组建荧光检测模块, 选用一宽光谱光源作为荧光激发光源, 由导光管将光引入准直透镜4, 准直后的光束先经过一个滤光片1, 使特定波段的激发光透过, 并经过二向色镜2反射, 经过二向色镜1透射和反射镜反射, 被油浸物镜聚焦照射到捕获的细胞上, 激发出荧光信号。 此时反射的荧光信号和激发光束经过油浸物镜原路返回, 经过反射镜反射, 穿过二向色镜1和二向色镜2, 此时返回的光束是荧光信号和激发光束的混合, 其中的激发光束强度要比荧光信号高出很多, 因此使用滤光片2滤除激发光束, 只让荧光信号透过, 然后再用一分束镜将荧光信号分为两束, 一路经过透镜3成像到CCD相机上, 一路经过透镜5射入荧光光谱仪中, 并在连接的计算机上获得了荧光光谱。 需要说明的是, LED光源仅在细胞捕获阶段用于观测捕获细胞状态时开启, 在进行荧光光谱检测时, 要关闭LED光源, 此时在CCD相机上观察到仅有细胞的荧光成像。
 | 图1 荧光光镊的系统结构示意图Fig.1 Structure diagram of fluorescent optical tweezers |
基于以上的设计原理和系统结构, 搭建了一套荧光光镊系统, 所用的主要器件类型及主要性能如表1所示。 光镊所用的光源为波长为976 nm的单模光纤激光器, 光束具有较大功率且对细胞伤害较小。 使用的油浸物镜有较大的数值孔径, 可以获得更大的细胞捕获力。 激发光源覆盖整个可见光波段, 有非常大的激光功率。 二向色镜和滤光片则根据具体的应用需求进行选用。
| 表1 搭建荧光光镊所用的主要器件及性能参数 Table 1 Key elements and their parameters for fluorescent optical tweezers |
从北京波尔西科技有限公司采购了马、 猪、 犬、 鸡的全血溶液(加入抗凝剂EDTA), 所有血液样品在运输和储存过程中均保存在4~8 ℃的无菌冷藏环境中。 制备红细胞样品时, 用离心机处理全血样品, 经1 600转· min-1的转速离心10 min, 去除上清液和部分白细胞及杂质, 然后用磷酸盐缓冲溶液(10 mmol· L-1)重悬和洗涤红细胞, 上述过程重复2次。 红细胞经过离心过程后沉淀在离心管底部, 从离心管中提取一定体积的红细胞, 通过加入适量磷酸盐缓冲溶液, 最终配置成浓度为1%的红细胞悬液, 在这种浓度下的红细胞悬液更易于单细胞捕获和荧光光谱检测。 实验时先利用光镊系统将待测红细胞捕获, 使其在溶液中处于稳定状态, 然后开启荧光检测模块, 采集红细胞受激后的荧光光谱。
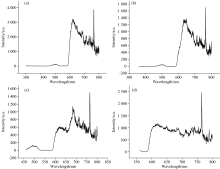
由于荧光分子对不同波长的光吸收程度不同, 所发射的荧光信号强度受到激发波长的影响, 因此有必要在实验前测试激发波长对荧光强度的影响[11]。 实验使用马的红细胞进行测试, 设置300、 340、 440和546 nm四个不同激发波长。 每个激发波长对应的荧光光谱重复测量5次, 取5次测量的平均作为最终数据光谱。 图2展示了在四个不同波长光的激发下得到的四条荧光光谱。
 | 图2 不同波长的激发光对应的红细胞荧光光谱 (a): 激发光波长300 nm; (b): 激发光波长340 nm; (c): 激发光波长440 nm; (d): 激发光波长546 nmFig.2 The fluorescence spectra of red blood cells corresponding to excitation lights with different wavelengths (a): Excitation light wavelength 300 nm; (b): Excitation light wavelength 340 nm; (c): Excitation light wavelength 440 nm; (d): Excitation light wavelength 546 nm |
图2中可看出, 不同波长的激发光所对应的波形分布、 发射荧光强度是不同的。 图2(a)中曲线在500、 625和764 nm附近存在明显荧光峰, 图2(b)中曲线在500、 634和764 nm附近存在荧光峰, 图2(c)中曲线在625、 690、 506、 733和764 nm附近存在荧光峰, 图2(d)中曲线在622和714 nm附近存在荧光峰。 这些差异表明不同波长光在红细胞中引起的能量转移不同, 所以在荧光光谱上表现出差异。 通过对比发现, 当激发波长为440 nm时, 得到的荧光光谱效果最好, 荧光峰较为明显, 因此实验采用440 nm的激发光来激发荧光信号, 选用的荧光发射滤光片中心波长是440 nm、 半带宽为10 nm。
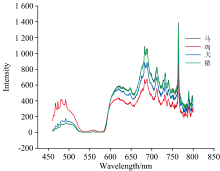
实验前将每个物种的全血溶液进行稀释, 得到1%浓度的红细胞稀释液。 取稀释好的红细胞溶液200 μ L加入石英器皿中, 调节位移平台使得物镜与石英器皿逐渐接近, 直至在CCD相机中出现清晰的红细胞图像。 此时打开激发光源, 记录荧光信号。 每个物种共5轮测试, 每轮血液样品采集20次荧光光谱, 每个物种共采集100次荧光光谱, 最终得到四个物种共400条荧光光谱。 利用Origin软件对每个物种的100条光谱做平均处理, 可得到带有标准差的平均化后的马、 猪、 犬、 鸡的荧光光谱, 图3是四种动物的红细胞荧光光谱平均后的结果对比。 从图中可以发现, 鸡的荧光光谱在500 nm附近的荧光峰强度最高, 猪的最低。 但在622、 690、 730和764 nm附近, 鸡的荧光峰最低, 马和猪相当。 通过四种动物的红细胞荧光光谱对比可见, 不同动物在某些荧光峰存在强度差异, 但峰的位置基本相同。
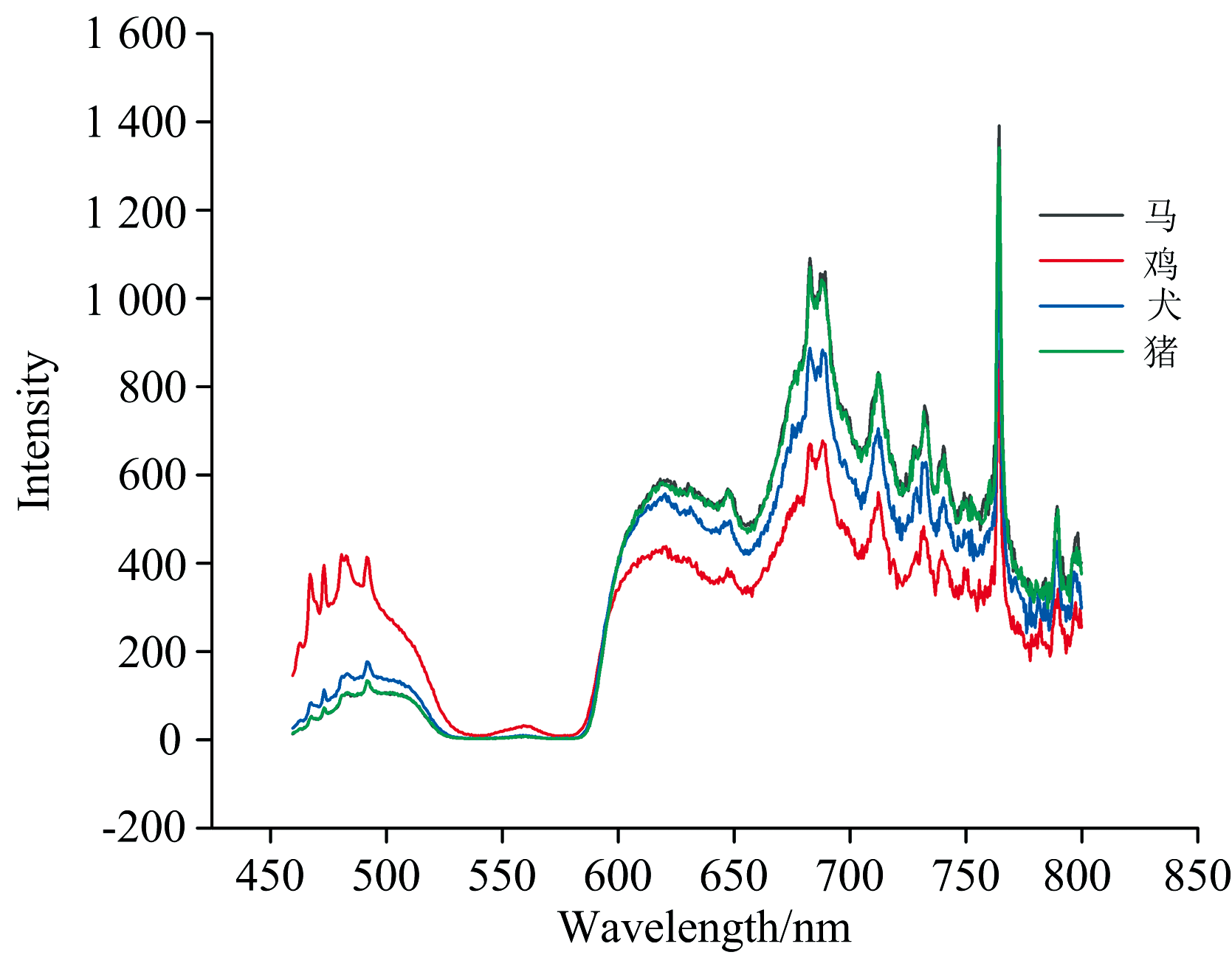 | 图3 四个动物(马、 鸡、 犬、 猪)的红细胞荧光光谱平均后的结果对比Fig.3 Comparison of average fluorescence spectra of the red blood cells of four animals (horses, chickens, dogs, and pigs) |
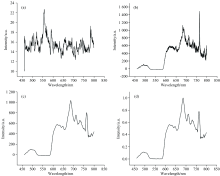
另外, 由于光谱可能受到外界噪声干扰, 这样会影响荧光光谱分类的准确性, 因此需要对获取的荧光光谱进行预处理, 预处理的目的是消除仪器噪声和环境干扰。 本实验中数据预处理主要包括去除背景、 平滑、 归一化。 为了消除石英基底和磷酸盐缓冲溶液所带来的背景荧光干扰, 实验前先测试石英基底加入磷酸盐缓冲溶液后的荧光光谱, 重复测试3次, 最终取平均值作为背景荧光。 利用Origin软件中自带的Sacitzky-Golay方法对光谱进行平滑去噪处理, 这样能够提高光谱的信噪比。 最后, 为了使不同物种的光谱获得统一的强度, 因此有必要将每条光谱进行归一化, 归一化的目的是将光谱的纵坐标(强度) 统一转换为0~1区间内。 图4给出了马的红细胞荧光光谱进行预处理的结果。
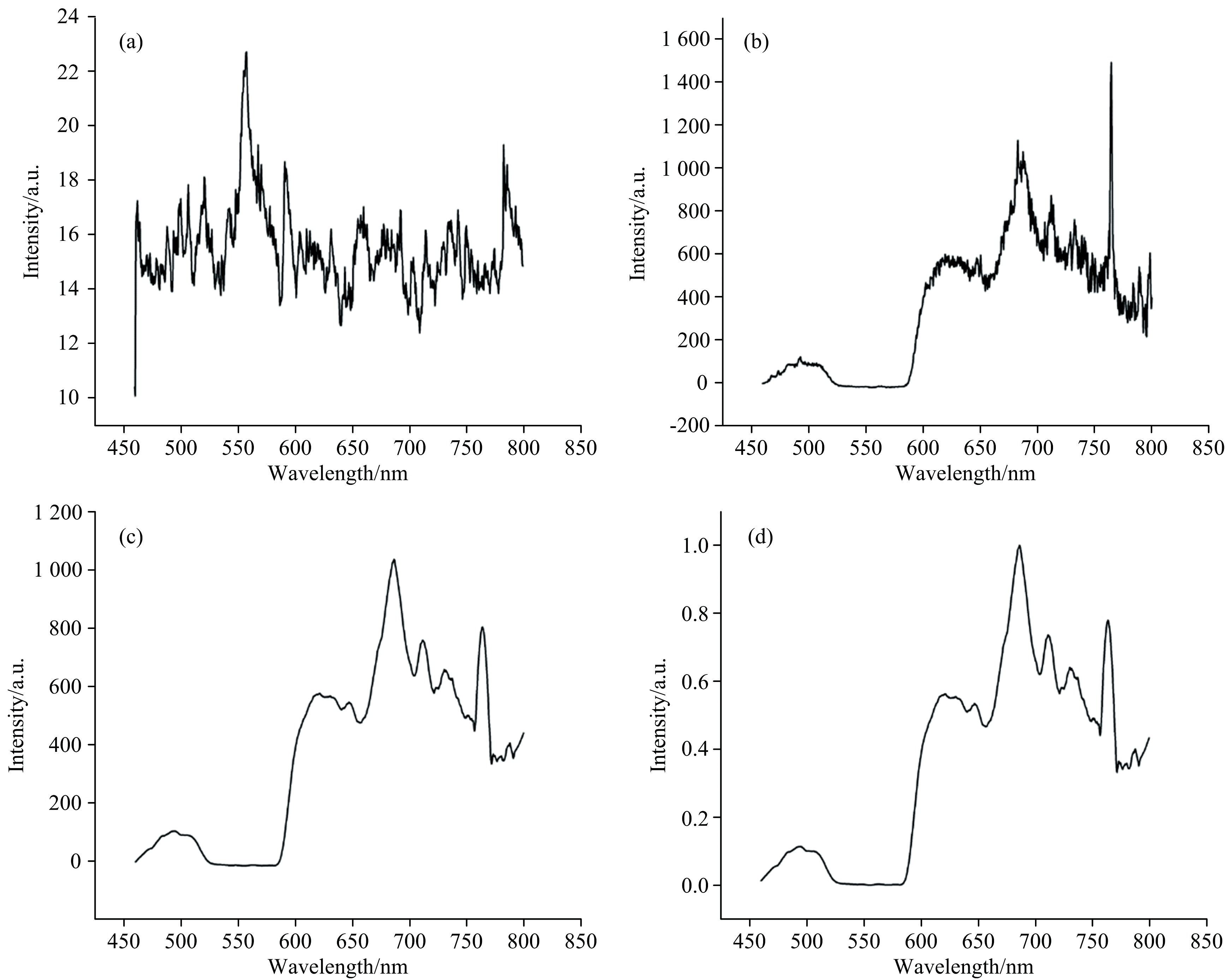 | 图4 荧光光谱的预处理 (a): 荧光背景; (b): 减去背景后的光谱; (c): 平滑后的光谱; (d): 归一化后的光谱Fig.4 Preprocessing of fluorescence spectrum (a): The fluorescence background; (b): The spectrum after subtracting the background; (c): The smoothed spectrum; (d): The normalized spectrum |
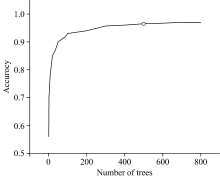
随机森林算法是最常用也是最强大的机器学习算法之一, 它由决策树构成, 随机地从数据集中采样以训练模型中的每棵决策树, 决策树的数量影响着模型的精度及鲁棒性[12, 13]。 随机森林训练过程包括: 预设超参数, 随机采样, 训练决策树, 输入待测样本到每棵树中, 再将每棵树的结果进行整合。 得益于该算法随机在数据集中进行采样, 随机森林模型随机性较强, 不易过拟合, 抗噪性强。 对于每次采样, 只选取原数据集中的一小部分, 这就使得随机森林算法训练高维数据的速度要比传统决策树快。 而且, 由于是树状结构, 模型可解释度高, 可以输出每个特征的重要性。 这些优点非常适合用于对光谱数据进行处理, 因此本实验采用随机森林算法构建分类模型对荧光光谱数据进行物种间的分类及预测。 随机森林模型建立机理是先从数据集中有放回的随机抽取n个样本, 再从所有特征中随机抽取k个特征, 用这些特征对抽取的样本建立决策树, 最后重复上面两个步骤m次, 生成m颗决策树, 这m颗决策树就构成了随机森林。 由此可见, 随机森林模型中最重要的两个参数是k和m, 假设样本数为X, 随机森林通常将k的值设为$\sqrt{X}$[12]。 本实验样本数为400, 则取k=20。 此时不断改变m的值并记录模型正确率, 最终得到图5, 从图中可知当m=500时, 正确率趋于稳定。 所以此时的m值既能保证较高的正确率, 又能保证模型的运行效率。
 | 图5 当k=20时基于随机森林模型的树的棵树与预测准确率之间的关系Fig.5 Relationship between the number of trees and the prediction accuracy based on the random forest model when k=20 |
利用已经测出的共400个光谱数据(四个物种, 每个物种100条光谱)来构建随机森林模型, 首先要进行测试集与训练集的划分, 设定样本数据的30%作为测试集, 70%为训练集。 设定随机森林模型参数k=20、 m=500, 计算得到不同波长与特征重要性之间的关系, 如图6所示。 由计算结果可知, 对红细胞荧光光谱分类起重要作用的五个波长分别是523、 683、 656、 710和519 nm。 对照图3可以看出, 四种动物在这五个波长附近光谱有明显差异, 因此算法主要依据这五个波长的差异来对光谱进行区分。 由于动物血液中存在一些光敏物质, 其中卟啉所占比重较大, 在不同环境下, 细胞内荧光物质存在漂移现象。 卟啉通常在630、 690和710 nm附近存在特征峰[14, 15], 因此这三个特征峰可能为卟啉类物质。 而523与519 nm附近可能是血红素或者黄素腺嘌呤二核苷酸引起的[16], 因此本实验结果表明, 在四种动物红细胞自体荧光光谱中, 对物种红细胞荧光光谱分类起确定性作用的物质分别是卟啉类物质、 血红素或者黄素腺嘌呤二核苷酸, 这几种物质最能够体现物种间的差异性。
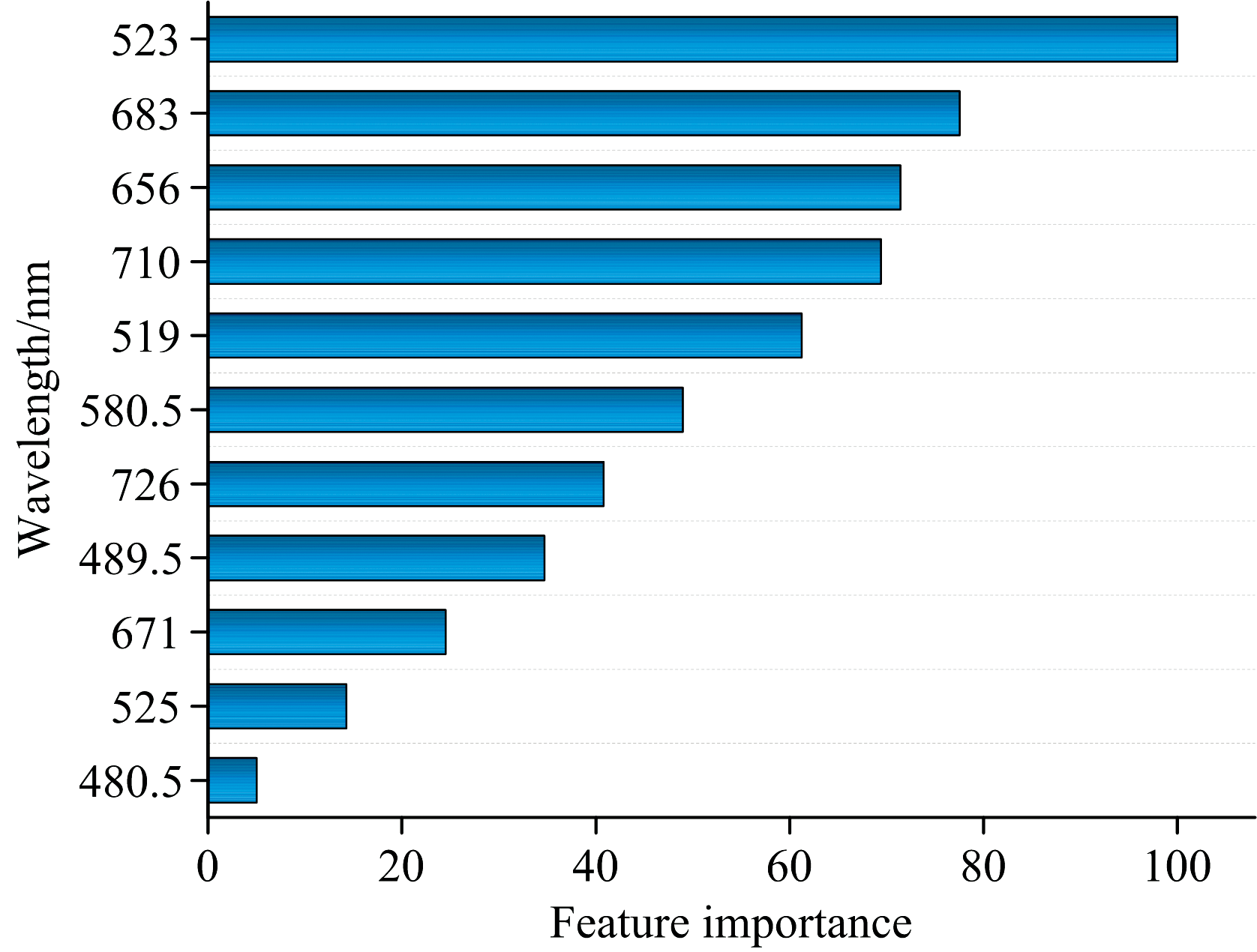 | 图6 基于随机森林模型的不同波长与特征重要性之间的关系Fig.6 Relationship between different wavelengths and feature importance based on random forest model |
然后, 运行模型代码10次并得到10个分类准确率, 取这十个数值的平均作为模型分类的准确率, 如表2所示, 测试集最终平均后的准确率达到93.1%, 方差为0.31%, 表明达到了非常高的分类准确率。
| 表2 随机森林模型运行10次的准确率及平均后的准确率(%) Table 2 Accuracies rate of random forest model running 10 times and the average accuracies (%) |
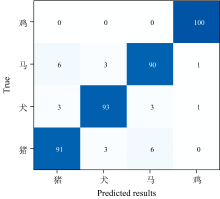
进一步计算了混淆矩阵, 它是一种对模型预测精度进行评价的一种可视化工具, 可以反映出预测结果与实际结果的差异。 在本次实验中, 任意选一次运行结果(这里以第8次为例)做混淆矩阵来描述对每个物种的分类情况, 如图7所示。 从图中可看到, 鸡的分类正确率最高, 马的分类正确率最低。 从图3可以看出, 猪与马的红细胞荧光光谱的谱型十分相似, 两者的光谱数据差异很小, 这是导致猪与马最终分类效果较差的主要原因。
 | 图7 通过混淆矩阵表示的随机森林模型预测结果Fig.7 Predicted results by random forest model represented by confusion matrix |
为克服传统群体细胞荧光光谱检测难以体现单细胞异质性的不足, 在小样本量下实现快速、 准确的血液分类, 提出了一种基于荧光光镊和机器学习的单细胞血液分类方法, 设计并搭建了一套荧光光镊系统, 并建立了随机森林分类模型, 测试了马、 猪、 犬、 鸡4种血液的单细胞荧光光谱, 分类准确率达到93.1%, 方差为0.31%, 验证了方法的可行性和有效性。 若进一步提高光谱测试的数量, 增加随机森林模型中训练集和测试集的数据量, 分类准确率有望进一步提高。
相比于传统的基于群体细胞的荧光光谱分析手段, 这种基于光镊的单细胞分析手段能够以无损、 非侵入式的方式在单细胞水平上揭示细胞的异质性, 更重要的是该方法能够与一些机器学习算法结合, 展示出其在未来拥有强大的应用前景。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|