
{kind=link}
{kind=link}
{kind=link}
遥感统计推断理论与应用初探
[朱渭宁 ]
]
]
|
|


作者简介: 朱渭宁, 1973年生, 浙江大学海洋学院副教授 e-mail: zhuwn@zju.edu.cn
提出一种新的介于遥感分类(定性分析)与遥感反演(定量分析)之间的遥感定性-定量分析方法, 即遥感统计推断。 遥感统计推断在理论上基于统计光学和概率分布变换, 主要研究在一定区域范围内的地物参数的概率分布特征(如土壤的湿度、 温度, 水体盐度、 叶绿素浓度等)如何改变和影响传感器所观测到的光学参数(如地表反射率、 水体的遥感反射率等)的概率分布特征(称之为光谱概率分布), 以及如何基于传感器观测到的光谱概率分布去反向推断地物参数在此区域内的统计分布特征, 从而为刻画地物参数提供相应的定性与定量信息。 相比于传统的遥感分类和反演, 遥感统计推断的优点在于: (1)能够快速地获取地物参数的全局统计特征, 如均值、 方差、 极值等等, 而不需要反演分析每一个像素光谱, 这一优点对于当前很多基于大数据、 高分辨率的遥感应用尤为重要, 因为有些应用部门的管理人员最感兴趣的往往是管理对象(如湖泊、 水库、 农田)的整体特征, 他们并不需要知道在每一个像素处的地物参数的大小; (2)地物的光谱概率分布可以直接用于地物的分类研究, 提供了一种有别于基于像素光谱签名特征的传统遥感分类的新分类方法, 这种方法提供的是研究区域的整体分类(如一个湖泊的分类)而不是每个像素的分类(如水质的分类); (3)遥感统计推断可以为遥感反演建模提供辅助信息, 基于这些信息调整反演模型的函数和/或参数, 使得反演模型结果的统计特征与遥感统计推断的结果相匹配。 该文简要介绍了遥感统计推断的一些基本概念、 原理以及其相较于遥感分类和反演的优势、 推断的适用对象和面向推断的遥感数据处理方法, 分析了国内主要湖泊水体的光谱概率分布特征, 并基于杭州西湖实地采测数据, 提出了一种基于自展法(bootstrap-based)的用于推断关键统计分布参数(例如西湖悬浮颗粒浓度的平均值)的简易遥感统计推断方法。
We propose a new qualitative-quantitative remote sensing analytical method, remote sensing statistical inference, which is different from the remote sensing classification (qualitative analysis) and remote sensing inversion (quantitative analysis). Theoretically based on statistical optics and probability distribution transformation, remote sensing statistical inference mainly studies how the probability distributions of the ground parameters (e. g., soil moisture and temperature, water salinity and chlorophyll concentration, etc.) within the interested area change and affect the probability distributions (called spectral probability distribution, SPD) of the optical parameters (e. g., surface reflectance, remote sensing reflectance of water bodies, etc.) observed by the remote sensors, and how to infer the statistical distributions of the ground parameters in this region based on the SPDs observed by the sensor, to provide the corresponding qualitative and quantitative information for characterizing the ground parameters. Compared with the traditional remote sensing classification and inversion, the advantages of remote sensing statistical inference are: (1) it can quickly obtain the global statistical characteristics of the ground parameters, such as mean, variance, max/min, etc., without inversion of each image pixels, which is especially important for many current remote sensing applications based on big data and high-resolution images, because some application department managers are most interested in the overall statistical distributions of the management objects (such as lakes and reservoirs); (2) the observed SPDs can be directly used in the classification study of ground objects, providing a new classification method different from the traditional remote sensing classification based on the signature features of each pixel, which provides the overall classification of the study object (such as the classification of a lake) rather than the classification of each pixel (e. g., the classification of water quality); (3) remote sensing statistical inference can provide auxiliary information for remote sensing inversion modeling, and based on the inferred information, the functions and/or parameters of inversion modelscan be adjusted so that the statistical characteristics of the inversed results match the inferred results. This paper briefly introduces some basic concepts and principles of remote sensing statistical inference, its advantages over remote sensing classification and inversion, the applicable objects of inference and remote sensing data processing methods for inference, analyzes the characteristics of the spectral probability distribution of major lakes in China, and proposes a bootstrap-based method for inference using the field measurement data of West Lake in Hangzhou. A simple inference method based on the bootstrap-based method is proposed to infer the key statistical distribution parameters, for example, the mean concentration of the suspended particles in West Lake.
传统的遥感图像分析方法有两种, 即分类和反演。 分类是一种定性方法, 它通常根据光谱信息, 获取地物的类别信息, 如土地利用类别、 水体营养化类别[1, 2]; 而反演是一种定量方法, 它通常根据光谱信息, 获取地物参数的数量信息, 如地表温度、 水体中的黄色物质浓度[3, 4, 5]。 这两种方法在遥感中都有大量的理论与应用研究[6, 7]。
本文提出一类介于分类和反演之间, 既含有定性分析, 也含有定量分析的遥感图像分析新方法, 称之为“ 遥感统计推断” (以下有时简称“ 遥感推断” 或“ 推断” )。 遥感推断的基本过程是根据地物对象的光学属性(如反射率)的统计信息(如均值、 方差、 概率分布函数), 去推断地物对象的非光学属性(如农田湿度、 水体浑浊度)的统计信息(如均值、 方差、 概率分布函数)。
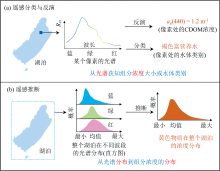
在更深入地介绍遥感推断之前, 先看一个例子。 如图1所示, 通过遥感分类, 可以将一个湖泊或者其部分水域划分为“ 寡营养水” 或“ 浑浊水” ; 通过遥感反演, 可以计算每个像素所对应的水体中含有的CDOM(黄色物质)的浓度大小; 而通过遥感推断, 则可以获取黄色物质浓度在湖体区域的统计和分布特征, 如均值、 方差以及对数正态分布。 由此可以看出, 遥感推断与传统反演和分类方法的最大区别在于, 它是基于研究地物对象的光谱分布, 去计算该对象其他属性的分布, 因此是一种从“ 分布” 到“ 分布” 的过程; 而反演和分类则是基于地物对象的光谱本身, 去计算该对象其他属性的类别或数值信息, 因此是一种从“ 光谱” 到“ 类别/数量” 的过程。 反演和分类是基于光谱的, 因此它们是一种基于像素(pixel-based)的方法, 也就是说, 即使对于一个像素, 也可以运用相应的分类或反演方法。 与之相反, 推断是一种基于对象(object-based)的方法, 对于一个像素(样本), 其分布或统计特征是没有意义的, 因此也无法使用遥感推断方法。
 | 图1 遥感统计推断与遥感传统分类和反演的区别(以湖泊水质研究为例)Fig.1 The difference between remote sensing statistical inference and the traditional remote sensing classification/inversion (an example of the study on lake water quality) |
从这三种方法的学科和理论基础上看, 遥感分类其实就是传统信息科学中的模式识别技术在遥感上的应用, 因此它涉及了较多统计学和数据科学的内容, 而相关的光学理论则涉及较少, 很多分类算法甚至不需要对地物光谱进行大气校正。 而遥感反演则相反, 它是以辐射传输和几何光学为基础的, 虽然有些反演算法也是经验统计性的(如简单线性回归或复杂神经网络), 但这些经验算法以及其他更多的半分析或分析算法在图像处理、 波段选择、 模型设计等方面都会涉及较多的诸如大气校正、 地物吸收与散射特征等辐射传输和几何光学的内容。 遥感推断所对应的物理和光学过程也是以辐射传输为基础的, 但是它更多涉及了统计光学的一些理论与方法[8], 即研究一个光场或一群光子参数的统计分布特性是如何形成和变化的。 如果感兴趣的某种地物参数(如水体中的叶绿素浓度)呈现出某种统计分布, 那么这种分布通过辐射传输后产生的光学变量(如遥感反射率)也会呈现出一种相应的分布。 举一个理想条件下的简单例子, 如果某个湖泊在所有像素点的水质参数都是常数, 那么在任一波段上, 在所有像素点观测到的遥感反射率也应该是一个常数。 可以想象, 从一个注满自来水的露天游泳池中提取的每个水体像素的光谱曲线都应该一模一样。 反之, 如果观测到遥感反射率呈现出某种分布, 那么说明一定是地物或者参与辐射传输的某些变量的属性具有某种分布, 而遥感统计推断就是研究这些分布是怎么在地物对象的非光学属性和光学属性之间进行传输和改变的, 其最终目的就是获知能够引起遥感光学变量产生分布的地物属性最有可能的分布特征。
既然已经有了分类和反演方法, 为什么还要研究和使用遥感统计推断呢? 这是需求决定的。 通过分类, 我们可以了解对象的一些定性性质, 获取其基本的属性信息, 如地表是土壤还是水体, 是红土还是黄土, 是清水还是浑水, 对于一些较为宏观的用户, 例如土地资源、 水资源的管理者、 决策者, 这些信息可能就足够了。 但是如果需要进一步深入地了解地物属性变化的机理机制, 就需要定量地分析其局部和细节特征与变化, 此时就需要运用遥感反演方法, 获取这些属性的数值信息, 提供给专业科研人员进一步分析和使用。 但是反演方法常会遇到两类难题: (1)反演准度问题, 即由于地物过于复杂、 病态反演等原因, 反演模型和算法自身存在一些缺陷, 反演准确性较低, 不确定性较高[7]; (2)反演效率问题, 即使反演算法较为准确, 但是如果算法自身过于复杂, 研究对象的数据量巨大且有实时性需求时, 反演效率较低[9]。 例如, 一个湖体在高分辨的影像上可能有上百万个像素, 对每个像素都运行一遍反演算法, 成本较高。 事实上, 对于很多诸如环境监测的用户来说, 不需要精确地知道在每个像素位置上水体或土壤的温度值, 他们更感兴趣的往往是对象的一些统计特征, 例如一个水库叶绿素分布的最大值、 最小值、 均值、 方差等等。 所以, 用常规的反演方法, 算出每个像素的叶绿素浓度值, 再统计出整个水库叶绿素的均值、 方差, 可能既不准又费时。 如果传统的反演方法是“ 先反演, 再统计” , 那么遥感统计推断则是反其道: “ 先统计、 再推断” 。 相比于复杂的反演, 做统计是相对简单和快速的过程, 与其对水体像素做几百万次反演, 再做一次统计, 不如直接先对光谱做一次统计, 再做一次推断。
遥感推断的另一个益处是为反演提供辅助信息, 这就如同分类给反演提供辅助信息。 由于地物和辐射传输的复杂性, 很多反演算法的局限性都较大。 在某种时空背景下针对某种地物特征的较为准确的算法, 当地物特征和时空背景转变时, 可能会变得不准确, 因此算法的参数、 模型、 甚至算法自身都需要做相应的调整。 而此时分类就可以发挥作用, 例如二类水体黄色物质的反演一直是一个难题, 近年来提出了先分类再反演的算法[10], 如先将水体分为清水和浑水两类, 对这两类水体分别运用有针对性的不同算法, 从而提高整个水体的反演准度[11]。 遥感推断扮演的也是类似的角色, 针对特别复杂的对象时, 可以采取“ 先分类、 再推断、 后反演” 的策略。 遥感反演一般遵从“ 实地采样” 、 “ 建模验证” 和“ 图像应用” 三个步骤。 实地采样获取的数据, 如在某水库采集的30个水样, 往往是对象(水库)的一个“ 样本集” 而不是“ 总体” , 第二步反演建模也是基于这个样本集的, 而将建立好的模型应用于遥感影像时, 输入的数据却是对象的“ 总体” , 即整个水库的所有像素, 因此当“ 样本集” 与“ 总体” 的统计和分布特征存在偏差时, 反演模型的结果也会产生相应的偏差。 而遥感推断正是对地物对象“ 总体” 的一种描述, 我们根据推断结果校正和调整反演算法的模型和参数, 使得将算法应用于总体时, 能够得到合理的、 与分布推断相吻合的、 没有统计偏差的准确结果。
遥感推断的第三个用途是对地物对象进行定性分析。 从分类和定性的角度看, 推断方法给出的是一个地物对象属性的统计和分布信息, 而这些信息可以为传统遥感分类分析提供一些新的视角, 也就是说, 不仅仅可以依据对象光谱自身的签名特征对像素分类, 也可以依据地物对象自身属性的分布特征对地物整体进行分类。 显然, 根据地物属性特征分类是更有指向性、 更为精确的分类方法, 因为根据辐射传输, 遥感所观测到的光谱签名在某种意义上是一种“ 二手” 信息, 它是由作为“ 第一手” 信息的地物属性特征所决定的。 根据叶绿素、 黄色物质、 悬浮泥沙的浓度分布特征直接给一个水体分类, 显然要比间接使用其光谱签名特征分类更为准确。 由于地物非光学属性的分布特征是通过其光学属性的分布特征推断而来, 因此有时甚至可以省略具体的推断过程, 直接将地物光学属性的分布特征与其类别相关联, 即在遥感分类时, 输入变量不是像素的光谱, 而是地物的光谱分布。
除了传统基于像素光谱的遥感分类, 面向对象遥感分类也是一种较常见的分类方法[12, 13, 14]。 需要说明的是, 面向对象遥感分类中的对象和遥感推断中的对象的语义往往不同。 面向对象遥感分类中的对象往往指具有一定相似性的像素集合, 生成这些集合的过程实质上是一种数字图像分割, 而基于图像像素亮度的统计分布特征(阈值)正是图像分割的一种常见方法[15], 如大津法[16]。 与之类似, 遥感统计推断也是基于像素亮度统计分布特征, 但是其目标不是分类和分割, 而是在已经确定地物对象或类别的前提下(即在一定的空间范围内), 利用像素亮度的统计分布特征去推断引起某种亮度统计分布的地物属性的分布特征。
遥感统计推断与传统统计推断也有所不同, 传统统计推断往往是根据样本集的统计特征去推断总体的统计特征[17, 18], 例如去一块农田或一个水库采集了30个土壤或水体样本, 根据这30个样本去推断整个农田或水库的状况, 这就是传统统计推断。 传统统计推断在成本和效率上显然更低, 而通过遥感统计推断, 则可以节省成本和提高效率。
表1总结了上面陈述的关于遥感分类、 反演和推断的特点和异同之处。 从分类, 到推断, 再到反演, 是一个由“ 质” 到“ 量” 逐渐变化的过程, 推断作为一种介于定性和定量之间的方法, 有其自身的特点和优势, 相比于分类, 推断在定性上的优势是更“ 准” 、 更“ 专” , 相比于反演, 推断在定量上的优势是更“ 快” 、 更“ 精” , 因此可以作为传统遥感分类与反演方法的一种有益补充。
| 表1 遥感分类、 反演与推断的特征与比较 Table 1 The features and comparisons of remote sensing classification, inversion, and inference |
遥感统计推断是一个在遥感理论和应用方面都有较多扩展空间的新方向。 本文旨在提出这一方法, 并做一些理论和应用上的初探工作, 引入与之相关的一些概念、 原理和技术, 展现一些简单示例, 以期抛砖引玉, 推动该领域进一步地深入研究和发展。
对于一个给定地物(研究对象), 假设其空间范围是A, A在图像上包含的像素数量是n, 传感器观测到的原始DN范围是R=[0, 255]。 我们有两种从概率统计的角度看待图像的方式: (1)将该地物所有可能生成图像的集合看作是一个样本空间S, 即对地物的观测是一种随机实验, 将某一时刻获取的一副图像作为这个集合的一个元素, 即该样本空间的一个样本点s, 对地物的一次观测是一次随机事件。 可知样本空间中的元素数量是一个极大的数值256n, 而每幅图像出现的概率基本都是1/256n, 即我们几乎不可能从两副图像上观测到每个像素的DN值都完全一样的地物A; (2)将所有可能的DN值看作一个样本空间, 即该空间中含有256种元素, 对地物的一次观测(成像)相当于对样本空间做了n次抽样(一种随机实验)。 将每次抽样当作一个随机事件, 该事件的结果即抽出的DN值, 因此n次抽样的结果为x1, x2, …, xn∈ R, 这些结果组成了一个随机变量X=(x1, x2, …, xn), 也就是说, 在观测对象的空间范围A内所有像素的DN值就是一个随机变量, 其值域是[0, 255]的离散整数, 且值域中每个值被抽中的次数(概率)是不一样的, 例如对于DN=0的元素, 其被抽中(在A范围被观测到)的次数是m0, 则其对应的概率就是P(0)=m0/n, 这样256个元素的概率就形成了一种概率密度为p(X)=(P(0), P(1), …, P(255))的离散型分布。
遥感推断的理论基础涉及较多光学(统计光学)和统计(推断方法)方面的内容。 统计光学是现代光学的一个分支, 其主要是应用概率统计来分析光学问题, 研究光场的统计性质(Goodman, 2015)。 传统统计光学中研究的光场主要包括自发辐射和受激辐射产生的热光和激光等, 其光场本身含有较为明显或细微的统计特征。 遥感成像本质上也是一个光学过程, 不过一般可以认为或假定, 在一定范围内(即感兴趣的地物对象区域), 大气顶端的太阳入射光场是一种均匀分布, 当入射光经与大气和地物的吸收和反射后, 在传感器上成像所形成的二维(如单波段图像)或三维(如多光谱或高光谱数据立方体)图像光场的分布会因此改变, 从而具有某些统计性质。 在给定时刻t, 传感器对空间范围A内的地物成像, 则图像像元ai接收的信号Li为
式(1)中, f是辐射传输方程, λ 是入射信号光谱, Θ 是入射和观测几何, p是极化, Ψ a和Ψ s分别是大气和地表特性的参数集(梁顺林等, 2019)。 假定在给定的时空范围(A, t)内, Θ i和pi不随ai变化, 并且如果进一步假设, 入射光(大气顶层)和大气参数(在A范围内的水平方向)也是均匀分布, 则入射辐射在近地表的入射值λ surf也是一个不随ai变化的均匀分布, 则有
所以, 在A范围内的n个Li则形成一个变量L=(L0, L1, …, Ln)。 将Li归一化到[0, 255]的范围内, 则L即等于上面从抽样角度描述过的地物随机变量X。
如果将地表特性参数Ψ s也看作是一个随机变量, 则从式(2)可以看出, L是Ψ s的函数, 且以λ surf, Θ , p和Ψ a为函数参数。 由随机变量函数的分布特性可知, 假设Ψ s的概率密度为gS(s), 且辐射传输函数f是单调函数, 则L的概率密度函数gL(l)为
若f是非单调函数, 则有
式(4)中, s1, s2, …, sn是方程l=f(sk)的所有n个解。
事实上, 求解式(3)或式(4)极为困难, 一是因为辐射传输过程f是一个极其复杂的迭代过程, 我们无法获知其反函数f-1的解析表达, 二是因为参与辐射传输的地表特性参数Ψ s可能不止一个, Ψ s是一个多元随机变量, 每个参数的概率分布都会对最终L的分布产生影响。
在遥感推断中, 我们已知的是Li的分布gL(l), 需要获知的是Ψ s的分布gS(s), 因此假设式(2)有反函数
其中l1, l2, …, ln是方程Ψ s=h(lk)的所有n个解。
由于函数h一般没有解析形式且L受多变量Ψ s决定, 式(5)和式(6)也较难求解。 但是如果针对某个单变量地物参数Ψ s, 如果能获取其与Li关系近似的解析表达, 则式(5)和式(6)可以相应地解出。 事实上, Ψ s与Li之间的近似关系h往往可以表达为反演所获取的算法或模型, 然而, 正向我们前面所指出的, 反演算法通常是基于几何光学的, 其在建模过程中, 受实地采样数据数量、 质量以及地物参数复杂性的影响, 具有一定的不确定性和误差; 再者, 很多表达近似关系h的反演模型也不是解析可导的, 因此根据式(5)或式(6)计算地物的概率分布函数gS往往有较大的不确定性或无法求解。
遥感统计推断需要做的就是在不建立反演模型的前提下, 直接建立gS与gL之间的关系, 以求达到准确且快捷地获取地物参数的统计分布特征。
原则上遥感推断可以应用于任意空间范围A, 但是在实际运用时, 对A有一定的要求和限制:
(1)A必须包含具有统计意义的像素数量, 如前所述, 如果A仅仅包含一个或几个像素, 则无法对A做出统计描述或统计意义不显著;
(2)A应当对应于图像中有共同大类属性的地物对象, 如土壤、 水体、 植被等, 显然不能将这些对象的光谱混为一体进行推断, 就如同一种反演算法往往是估算同一类地物的参数;
(3)在范围A内, 研究对象的属性往往具有某些统计分布特征, 如水体浑浊度、 土壤湿度、 农作物健康度等等。 有些人工地物, 如沥青、 水泥或石料铺设的路面、 场地等等, 由于面积较小、 材质均匀, 其属性一般情况下不会呈现较明显的统计分布特征;
(4)A一般需要有明确的、 有意义的边界, 即A对应于一个对象的整体, 而不是其局部。 例如A是一片森林或一个湖泊, 如果A仅仅是森林或湖泊的局部, 则对其推断出的结果缺乏指示研究对象整体分布特征的意义;
(5)A一般应是连通的区域, 即通常不将两个不连通的区域当作一个区域进行推断, 例如一副影像上有两个湖泊, 即使名称相同, 但如果水体不连通, 其某种属性的分布特征可能有较大差异, 将其混合后推断出一个单一的结果对两个湖泊都没有指示意义。 相反, 有时候两个湖泊可能名称不同, 但是如果存在宽阔的连通水道, 水体交换频繁, 此时反而须将其作为一个整体进行推断。
对地物光谱做统计描述, 首先要面临的问题是对何种级别的光谱信息进行统计描述。 这里的光谱信息可以是原始DN、 经过标定后TOA幅亮度、 经过大气校正后的地表反射率, 对于水体来说, 还可以是除去水面反射后的离水幅亮度或遥感反射率Rrs(remote sensing reflectance)。 事实上, 这些光谱信息在不同级别上进行转换时, 其对应的概率统计特征也会相应地改变, 因此最适合于遥感推断的光谱信息自然应该是刚离开地物且未受大气及其他干扰要素(如水面反射)影响, 如地表反射率或水体的遥感反射率。 但是, 这并不意味着其他级别的光谱信息不能用于遥感推断, 正如遥感分类可以基于地表反射率, 也可以基于未经大气校正的TOA反射率。 如前所述, 大气或其他干扰要素对区域A内地物光谱概率分布的影响可能是各向均匀的, 因此这些影响往往可以被统计消除。 例如, 如果区域A内DN呈现一个正态分布(μ , σ 2), 则DN× gain+offset标定后的变量仍然是一个正态分布, 只不过其均值和方差变为gain× μ +offset和(gain× σ )2。
在地物对象的空间范围A内, 并在给定的波长λ 上, 可以对其所包含的n个像素的光学属性L(如DN、 地表反射率R、 离水辐亮度Lw等)做出各种统计描述, 常见的参数有最大值、 最小值、 中值、 均值、 方差等等。 更为可视化的描述是根据L的数值绘制统计直方图, 从而可以观察和获取更多的分布特征与细节。 这一直方图可以看作是随机变量L的概率分布函数的近似, 我们称之为对象的“ 光谱概率分布” (spectral possibility distribution, SPD)。 基于SPD, 可以进一步计算诸如偏度(skewness)、 峰度(kurtosis)等统计变量。
当用统计直方图描述SPD特征时, 还需要有几点注意事项: (1)在计算SPD之前, 有时候需要从区域A对应的n个像素中减去部分(例如1%~4%)有可能引入不确定性的像素。 例如在水质遥感中, A中一些极亮或极暗的反射率是由水面的白帽或深色船舶引起, 此时可以将n中对应反射率最大和最小2%的像素排除后, 对剩余96%的像素进行统计描述; (2)当SPD用于定性/分类分析时, 有时还需要将其归一化, 以便比较不同研究对象之间的相对差异。 例如两个湖体在某个波段上的SPD看似不同的正态分布, 但是归一化后(即分布函数经某种放大、 缩小和平移后), 两者可能是几乎相同的; (3)除了描述单波段的SPD外, 还可以根据所研究地物参数的光学特征, 描述并计算不同波段的组合信息, 如NDVI已经可以直接指示研究区域的植被分布信息; 研究水体中的叶绿素时, 可以借鉴其两波段反演算法[19], 描述水体红和近红外波段比的统计分布特征。
入射分布的正向传输研究是指已知地表参数在区域A内的统计分布特征, 估算由此引起的地表反射光谱的分布特征。 这其中须假设A范围内的大气在水平方向上是各向同性的, 因此入射光在与地物交互之前是一个常数(均匀分布), 而需要估算的则是刚离地的、 未受大气影响的反射光谱的分布, 如离水幅亮度或遥感反射率, 即通过大气校正后从图像中获取的地表的光谱信息。
研究入射分布正向传输的主要方法是蒙特卡特模拟或基于辐射传输的数值模拟, 如涉及水体辐射传输的Hydrolight模型。 首先模拟各种地物参数可能的分布特征, 例如, 叶绿素呈某种正态分布, 黄色物质和非藻类颗粒物呈某种指数分布, 然后将这些参数输入模拟模型, 模型运算后输出与之对应的光谱分布, 从而有助于了解如果观测到某种光谱分布, 则其理论上可能对应于何种地物参数的统计分布形式。 注意, 把这种对应应用于推断时需谨慎, 因为它们可能并不是一一对应, 即不同的地物参数分布特征可能产生相同的光谱分布。 类似情况在反演中也常有出现, 特别是在水色遥感领域, 水色组分(叶绿素、 黄色物质、 非藻类颗粒物)浓度的不同组合可能会产生相同的水面光谱。 同理, 水色组分浓度分布的不同组合也可能会产生相同的水面光谱分布。
我们不但要研究地物参数由于概率分布函数形式(例如正态分布、 对数正态分布、 指数分布)的不同所引起的光谱分布形式的不同, 也要研究分布形式相同, 但分布参数不同所引起的光谱分布形式和参数的差异, 而这些分布参数正是我们感兴趣的, 是具有定量指示作用的关键参数。 例如, 当水体中悬浮颗粒呈现正态分布, 但分布的均值和方差发生变化时, 光谱是否也是正态分布? 如果是正态分布, 分布的均值和方差如何相应地变化。
当光谱与地物参数之间存在辐射传输的简化形式时, 如对于水体有水面反射率R∝ bb/a, 其中a和bb分别是水体的总吸收与总后向散射系数, 则可以利用式(5)或式(6), 理论上计算与分析入射分布的正向传输过程, 当理论计算过于复杂时, 也可以采用蒙特卡洛模拟法。
地物分布的反向推断过程是遥感统计推断的常规过程, 即通过观测到的光谱信息的统计特征和分布去推断地物参数的统计特征和分布, 其具体包含两类不同的推断情形: (1)统计特征推断: 仅仅推断地物参数的若干统计特征参数, 如均值、 方差、 最大最小值等; (2)统计分布推断: 推断地物参数在研究范围内完整的概率分布形式。 可以看出, 上面的情形(2)的结果是包含情形(1)的, 即如果获知了某地物参数的概率密度分布, 易知其相应的统计特征参数; 而反之则不行, 因为不同的概率分布形式可能具有相同的统计特征参数。
通过光谱的概率分布直接推断地物参数的概率分布, 即上面描述的情形(2), 是较为困难的过程, 其框架性、 系统性的方法有待于后续的深入研究。 情形(1)的推断则相对简单, 本文介绍一种简易方法, 即根据实测数据样本集的重采样法(bootstrap method)。 假设实地采样的样本集为S, 从S中抽取一个子集s1, 然后分别计算s1中光谱和地物参数的某个感兴趣的统计参数(如均值), 例如计算水体遥感反射率在670 nm的均值Rrs1和颗粒物浓度C1; 重复这一过程, 抽取子集s2, 计算Rrs2和C2; 将此过程重复n次, 形成一个光谱均值集合{Rrs1, Rrs2, …, Rrsn}以及与之对应的浓度均值集合{C1, C2, …, Cn}, 然后根据这两个集合拟合出遥感反射率均值和颗粒物浓度均值之间的推断模型。 地物参数的其他统计特征也可以用相同方法进行推断建模。 因此, 通过bootstrap方法建立的是一个推断算法集, 推断不同的统计参数需要使用算法集中的不同算法。 将推断算法应用于遥感影像时, 只需要计算地物空间范围A内的光谱统计参数(如均值), 然后代入其相对应的推断模型, 即可获得地物参数的某种统计特征(如颗粒物浓度均值)。
利用bootstrap推断还有一些注意事项: (1)从样本集S中抽取子集s时, 应适当选择s的大小, 使得其包含的光谱和地物参数的统计特征既有一定的统计意义, 也有一定的差异性。 抽样方式可以采用随机重采样, 使子集S和s的地物和光谱参数具有类似的统计分布特征; 如果S集包含的样本数较多, 也可以进行“ 重分布” 采样, 使得S和s中的地物和光谱参数具有不同的统计分布特征。 例如样本集S中地物和光谱参数呈现均匀分布, 我们从中抽取具有不同特征的正态、 对数正态以及指数分布的子集s, 从而可以研究当地物参数呈此类分布时, 相对应的光谱分布的特征, 使得生成的推断模型更为准确, 适用性更广; (2)遥感推断依据的光谱统计分布信息不仅仅是单波段的, 还可以是多个波段的, 或者使用不同的波段组合或模型, 即根据地物参数的光学性质, 利用以往反演建模的先验知识, 确定合适的光谱分布信息。 例如, 叶绿素反演的两波段模型是基于红绿波段的比值, 则可以依据红绿波段比的分布去推断叶绿素的分布; (3)很多常见的统计概率密度分布形式是由若干分布参数(如均值和方差)所确定的, 如果假设地物参数是已知的某种常见分布函数, 当通过bootstrap方法推断出该分布的参数后, 实际上该地物的完整分布就确定了, 即我们完成的是一个参数推断。 即使该地物的具体分布函数未知, 获取其均值、 方差等关键统计信息, 也可以大致描述其完整分布的主要信息。
实际的遥感推断还要面对一个问题: 如何结合实地采样获取的信息进行推断? 面向推断的采样和面向反演与分类的采样有一些异同, 并且针对不同的地物特征也要采取不同的策略。 如果将卫星观测到的地物参数在空间范围A内的光谱信息看作是一个总体(population), 则实地采样获取的仅仅是从总体中抽样的一个样本集。 这个样本集如果足够大且没有偏差, 例如采样点密集且在整个区域A内随机分布, 则可以利用传统统计推断方法, 根据地物参数及光谱在实测样本集中的分布推断出其在总体A中的各自分布。 由此可以看出, 对于面向推断的采样, 往往要求样本集对于总体是无偏的, 而对于面向遥感分类和反演的采样, 往往要求光谱特征的差异与多样性, 采样前须预估地物参数(类别)和光谱可能存在明显差异的子区域, 并在该区域内采集若干代表性样本, 但是这些代表性样本的数量往往不和其对应子区域的面积成正比, 因此根据样本集去推断总体的统计特征与分布往往会引起一定的偏差。
另外, 由于遥感影像是对地物的瞬间观测, 而实地采样不可能在短时间内采集较大空间范围内的数据, 因此地物参数的时变特征以及空间范围A也会对样本集的代表性有一定影响。 一些较为固定, 短时内(例如三五天内)变化不明显的地物(如农田作物)参数, 每天采集一些子区域, 三五天内的数据则可以覆盖整个研究区域, 然后将各个子区域的数据合并成整个区域的无偏样本集; 但是对于水体等流动性、 时变性较快的地物参数, 按照同样方式采集的样本集则可能存在一定偏差, 将其用于推断时可能会有一定的不确定性和偏差。
湖泊有明确的边界与范围, 是遥感统计推断理想的研究对象, 其水质参数, 如温度、 浊度、 叶绿素和黄色物质浓度等, 也往往具有一定的分布特征。 以往的一些观测表明, 一个生态系统中生物种群数量或个体年龄(生长或活动状态)有时呈正态或对数正态分布, 而叶绿素正是水体中浮游植物数量和生长状态的指示参数。 这些水质参数如果直接或间接影响水体内在光学属性的分布, 就会相应地改变遥感观测到的表观光学属性的分布。
我们利用Landsat-8卫星影像, 提取分析了国内130多个主要水体的SPD特征。 这些水体主要以湖泊为主, 也包含一些相对封闭的海岸带水体, 如胶州湾、 三都澳等。 Landsat-8原始数据从美国地质调查局USGS网站获取, 经由大气校正模块ACOLITE处理后, 可以直接提取水体区域在Landsat-8五个可见光/近红外波段(443、 483、 551、 655和865 nm)的遥感反射率Rrs, 除去所有像素中反射率最大及最小2%的像素, 然后计算剩余96%像素在每个波段的统计直方图。 为了便于在相同范围内比较不同水体的SPD特征, 设置bin数量为20, 并将Rrs归一化到0-1, 即
式(7)中, Rrs_norm是归一化后的遥感反射率, Rrs是像素处的观测值, Rrs_max和Rrs_min是水体区域中遥感反射率的最大与最小值, 其归一化后的Rrs_norm值分别对应1和0。
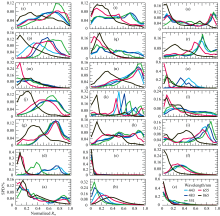
图2显示了我国一些主要水体基于Landsat-8影像的SPD特征。
 | 图2 国内主要水体在Landsat-8五个可见光/近红外波段上的光谱概率分布 (a): 鄱阳湖2014/10/8; (b): 赛里木湖2014/8/27; (c): 移山湖2014/10/22; (d): 扎陵湖2018/9/28; (e): 扎布耶错2017/10/10; (f): 洱海2013/10/11; (g): 兴凯湖2018/5/11; (h): 查干湖2014/9/24; (i): 巢湖2018/2/5; (j): 三都澳2013/10/23; (k): 日居错2014/10/22; (l): 胶州湾2013/4/7; (m): 青海湖2017/11/5; (n): 洪泽湖2013/8/27; (o): 冬给措纳湖2018/9/28; (p): 星云湖2015/2/21; (q): 纳木错2016/11/21; (r): 太湖2017/12/5; (s): 太湖2014/3/16; (t): 微山湖2014/3/14; (u): 微山湖2013/11/29Fig.2 The SPDs of Chinas main water bodies observed from the five visible/near-infrared bands of Landsat-8 (a): Poyang Lake 2014/10/8; (b): Sailimu Lake 2014/8/27; (c): Yishan Lake 2014/10/22; (d): Zhaling Lake 2018/9/28; (e): Zhabuyecuo 2017/10/10; (f): Erhai 2013/10/11; (g): Xingkai Lake 2018/5/11; (h): Chagan Lake 2014/9/24; (i): Cao Lake 2018/2/5; (j): Sanduao 2013/10/23; (k): Rijucuo 2014/10/22; (l): Jiaozhou Bay 2013/4/7; (m): Qinghai Lake 2017/11/5; (n): Hongze Lake 2013/8/27; (o): Dongjicuona Lake 2018/9/28; (p): Xingyun Lake 2015/2/21; (q): Namucuo 2016/11/21; (r): Taihu Lake 2017/12/5; (s): Taihu Lake 2014/3/16; (t): Weishan Lake 2014/3/14; (u): Weishan Lake 2013/11/29 |
(1)单一波长SPD的统计分布特征。 单一波长SPD不仅包含一些常见的概率分布形式, 如正态分布[图2(b)赛里木湖865 nm、 图2(f)洱海443 nm]、 对数正态分布[图2(d)扎陵湖655 nm、 图2(b)赛里木湖463 nm]、 指数分布[图2(c)移山湖865 nm、 图2(o)冬给措纳湖655 nm]、 均匀分布[图2(i)巢湖483 nm、 图2(h)查干湖655 nm]等, 而且包含很多有一定特征, 但无法归结为已知的常见概率分布形式, 如星云湖551 nm的平台状分布[图2(p)]、 日居错443、 483、 551 nm的双峰分布[图2(k)]、 巢湖865 nm的阶梯状分布[图2(i)]、 微山湖483 nm的鞍状分布[图2(u)]、 鄱阳湖551 nm的不规则分布等[图2(a)]。 有些SPD虽然具有相近的概率分布形式, 但是其统计参数却存在一定差异, 如都是正态或对数正态分布, 其参数均值μ 和方差σ 2不同(如赛里木湖、 洱海、 冬给措纳湖443 nm); 同是指数分布, 其参数斜率λ 不同(扎布耶错和青海湖865 nm); 一些分布具有一定对称性(如三都澳655 nm), 另一些分布则具有不同偏度(如兴凯湖655 nm); 一些分布较为平缓(如胶州湾483 nm), 另一些分布则具有较大峰度(如巢湖483 nm)。
(2)单一水体内不同波长SPD之间的组合特征。 单一水体内不同波长SPD之间的关系具有相似性和多样性。 在有些水体中, 不同波长的SPD曲线在形状(概率分布函数)和位置(分布函数的统计参数)都比较接近, 如在移山湖[图2(c)]和扎布耶错[图2(e)]中, 五条曲线都呈指数分布, 且形状和位置基本重合; 而在有些水体中, SPD的形状较为相似, 但位置存在差异, 例如在赛里木湖中[图2(b)], 各个波段的SPD都呈正态或对数正态分布, 但是从443到483 nm再到551 nm, 随着波长增加, SPD曲线的均值左移, 峰度增加, 但是从551到655 nm再到865 nm, SPD曲线的均值转而右移, 峰度降低, 形成一个以551、 483、 443、 655、 865 nm为顺序, 峰度依次降低, 均值逐渐右移的对数正态SPD组合, 在峡山水库、 阳宗海、 骆马湖等水体中也观测到类似的SPD组合。 还有一种常见的特征是五条SPD曲线形成不同的组, 组内SPD的形状和位置都相同, 而组外则不同。 例如在兴凯湖、 洪泽湖和三都澳中, SPD在443、 483、 551和655 nm的曲线较为相近, 形成一组, 偏度偏右, 而近红外865 nm的SPD则单独形成另一组, 形状虽与其他波长的SPD相近, 但是偏度偏左。 这种组合在洱海中也类似, 两组偏度都是偏左, 但是形状却不同, 865 nm呈指数分布, 而另一组中的4个SPD呈正态分布。 其他一些组合特征还包括: 扎陵湖中, 蓝波段(443和483 nm)一组, 绿波段(551 nm)一组, 而红和近红外波段(655和865 nm)一组; 巢湖和纳木错中, 蓝绿一组, 红/近红外一组; 冬给措纳湖中, 绿和近红外形成一组, 而红和两个蓝波段各自形成一组; 青海湖中, 红波段单独形成一组, 其余四个波段形成一组; 在日居错和星云湖中, 各个波段的SPD都存在较大差异;
(3)同一水体在不同时间的SPD特征。 同一水体在不同时间或季节, 也具有不同的SPD特征, 例如太湖在冬季[2017年12月5日, 图2(r)]和春季[2014年3月16日, 图2(s)], 微山湖在冬季[2013年11月29日, 图2(u)]和春季[2014年3月14日, 图2(t)]呈现的SPD都不尽相同。 太湖在冬季蓝绿形成一组, 峰度较高, 右偏, 红和近红外分别形成一组。 在春季, 绿色从蓝绿组中分离出来, 峰度有所降低, 单独形成一组; 而蓝红三个波段的峰度降低十分明显, 整个曲线较为平展, 而近红外波段的变化则不明显。 微山湖从2013年冬季到2014年春季, 各个波段的SPD特征都发生了较大变化, 冬季分布大致呈现一种两端突出, 中间平缓的鞍状曲线, 到了春季后, 突出的两端向中间移动, 且峰度降低。 太湖春季3月中旬SPD绿波段的分离可能是由于气温变暖后, 浮游植物和藻类活动增加, 浓度增高, 引起水体IOP发生变化, 从而造成SPD相应改变; 而微山湖未观测到类似变化, 可能是因为微山湖纬度较高, 3月中旬水温仍较低, 水生生物还处于非活跃期。
从上面结果可以看出, 不同水体或同一水体在不同时间单一波段SPD的分布特征以及不同SPD的组合特征不仅具有一定的相似性, 也具有一定的多样性。 我们推测, 这些相似性与多样性与水体及其周边的物理、 化学、 生物、 环境、 生态等属性或因素有一定关联, 如水体温度、 盐度、 深度、 集水区所处的气候带、 海拔、 植被、 土地利用与覆盖及人类活动强度等。 SPD特征可用于潜在地指示这些水质相关属性和因素, 无须推断出这些属性和因素统计分布的量化特征, 即前述所说的基于SPD的遥感推断可以像基于光谱的遥感分类一样对研究对象进行分类和定性分析。 当然, 如果进一步推断出这些属性的量化统计分布特征, 则可以对研究对象进行更深入更有针对性的定量分析。
本节仅仅是针对Landsat-8观测到的水体SPD做一些直观的描述性的初步分析, 以显示遥感统计推断潜在的定性分析功能。 我们建议将来收集更多数据, 对SPD的统计特征做一些定量描述, 量化其一些基本参数, 如均值、 方差、 偏度、 峰度等等, 使得基于这些参数的分类和定性分析结果更为准确。
我们利用在西湖采集的数据, 建立了一个简单的统计推断模型, 用于推断西湖悬浮颗粒物在412 nm的吸收系数aNAP(412)的主要统计参数--均值。 2017年-2019年期间, 我们在西湖各湖区采样十余次, 共采集可用样本108个, 在每个样本点测量了光谱、 透明度、 悬浮颗粒物和CDOM吸收系数等水质参数[20]。
样本点基本覆盖西湖的整个湖区, 实测数据大致呈指数衰减分布[见图3(a)], 推断建模采用前面介绍的Bootstrap方法, 即(1)从108个样本中随机抽取50个样本, 形成一个重采样样本集s, 计算s中aNAP(412)、 5个Landsat-8单波段以及这个5个单波段两两形成的10个波段比的均值; (2)重复过程(1)500次, 形成一个含有500条记录的建模集M; (3)基于建模集M, 在aNAP(412)均值和15个光谱均值之间分别做简单的线性回归, 形成15个推断模型; (4)根据推断模型的统计参数(如相关系数R2), 从15个模型选择一个最佳模型作为最终的推断模型。
 | 图3 西湖悬浮颗粒物吸收系数aNAP(412)均值的推断建模与验证 (a): 西湖实测aNAP(412)的分布; (b): aNAP(412)均值与波段比B2/B4均值的简易推断模型; (c): 模型的验证Fig.3 Inference modeling and validation of the mean aNAP(412) of the absorption coefficients of suspended particles in West Lake (a): The field-measured distribution of aNAP(412) in West Lake; (b): A simple inference model between the mean aNAP(412) and band ratio B2/B4; (c): The validation of the simple model |
基于实测数据获取的西湖悬浮颗粒物吸收系数aNAP(412)均值的Landsat-8推断模型为
式(8)中, 下标mean表示该变量在整个湖区像素的均值, 模型的R2=0.44, 见图3(b)。 我们仍然用实测数据进行验证: 从108个样本中随机抽取k(30≤ k≤ 80)个样, 由这k个样直接计算aNAP(412)的均值, 即aNAP(412)均值的真实值, 再根据k个样的光谱均值和推断模型式(8)计算aNAP(412)的推断值, 重复这一过程500次, 则可根据这500对aNAP(412)的真实值和推断值之间的误差获知推断模型的准确性。 验证结果显示, 推断模型即式(8)的相对误差仅7.1%, 见图3(c)。
建模结果显示, 波段比B2/B4是用于推断aNAP(412)均值的最佳变量, 其次是B1/B4(R2=0.36), 而其他14个单一波段或波段比变量所拟合的模型的推断准确性较差。 另外我们也测试了基于Bootstrap法, 用单波段或波段比的方差去推断aNAP(412)的方差, 但是发现建模效果很差, R2的最大值仅有0.027(以B4作为输入变量), 说明方差这一统计参数无法通过简单的单波段或波段比方差进行线性拟合推断。 由于我们只测试了单波段和波段比这两类变量, 在推断模型的拟合上也只用了最简单的线性回归, 所以推断结果并不是特别理想, 将来如果能借鉴相关的反演模型, 使用更为复杂的变量组合或拟合方式也许能进一步提高均值和方差的推断准确度。
影响推断准确性的还包括用于建模的实测数据的质量。 在本研究中, 实测数据的空间范围虽然覆盖了整个湖区, 但是却是在不同时间采集的。 另外, 西湖整个湖区包含中间大湖、 北面的北里湖, 西面的西里湖和茅家埠, 西南的小南湖等几个分湖区, 每个分湖区的水体虽然相通, 但是桥下连通的水道较为狭窄, 加之各个湖区上游船的活动强度也不同, 因此各个分湖区的水体有一定的独立性, 如果将其当作一个整体进行推断, 也可能会降低推断的准确性。
在对实测数据进行bootstrap重采样时, 由于实测数据数量有限, 我们也没有进行如1.5节所描述的带分布特征的重采样, 而只是进行随机采样, 使得每个重采样后的子集中数据的分布都与原始数据集的分布相类似, 这样可能会造成得到的推断模型准确度降低且具有一定的局限性。
遥感统计推断的一个特点是避免大量反演计算又能获取地物参数关键的定量信息, 即先快速获取地物的光谱信息的统计特征, 再输入推断模型中, 获取地物其他参数的统计特征。 注意, 我们不能将推断模型和反演模型相混淆, 虽然有时候两者在形式上有些类似。 对象的光谱统计信息不能输入到反演模型中, 而像素的光谱签名信息也不能输入到推断模型中。 反演模型往往是基于像素光谱, 如果我们根据区域A内所有像素生成一个“ 均值” 或“ 中值” 光谱, 然后将该光谱输入反演模型运行一次, 虽然速度也相对较快, 但这样只能获取地物参数的一个“ 均值” 或“ 中值” , 无法获知此参数在研究区域内的分布状况(如方差), 且反演模型对所谓的“ 均值” 或“ 中值” 光谱是否能正确响应, 获取的均值或中值与地物参数的实际统计值是否吻合, 或者其反演的准确度是否比推断的准确度高, 也是待进一步研究的问题。
本文提出了遥感统计推断的基本概念和原理, 即一种基于辐射传输、 统计光学和概率分布变换的, 兼顾定性与定量分析功能的遥感数据分析技术与方法。 与传统的遥感分类和反演相比, 遥感推断具有“ 快” 、 “ 准” 、 “ 精” 、 “ 专” 等优势。 基于Landsat-8提取的水体SPD特征表明, 研究对象的光谱概率分布是其非光学属性和环境因子的一种指示与表征, 很多水体的SPD既有多样性, 也有相似性。 基于西湖实测数据的简单推断模型则表明, 遥感统计推断能够较为快速地、 准确地估算出研究对象的一些关键的概要性的定量信息。
通过初步的理论探索和应用测试表明, 基于对象光谱统计分布特征的定性分析与定量推断是遥感科学领域一个有意义的新研究课题, 仍有很多基础理论工作以及一些具体的实用技术与应用实践还未涉及, 希望感兴趣的读者能深入研究, 在将来对这一课题做进一步的拓展与完善。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|