


{kind=link}
{kind=link}
{kind=link}
{kind=link}
一个预测紫叶生菜花青素含量的高光谱深度学习模型
[张美玲 , 陈勇杰, 王敏娟, 李民赞, 郑立华
, 陈勇杰, 王敏娟, 李民赞, 郑立华* ]
, 陈勇杰, 王敏娟, 李民赞, 郑立华]
|
|


作者简介: 张美玲, 女, 1999年生, 中国农业大学信息与电气工程学院硕士研究生 e-mail: zhangmeiling0110@163.com
紫叶生菜叶片内富含花青素、 胡萝卜素、 维生素、 矿物质等元素, 其中花青素作为叶片组织中的主要色素对植物提供多种修复及保护功能, 其含量可反应紫叶生菜的生理状态, 因此其高精度预测具有现实意义。 为了高效、 准确地估算紫叶生菜的花青素含量, 采集了紫叶生菜的高光谱数据并开展了高精度建模研究。 对原始平均反射光谱数据进行了一阶导数(FD)、 二阶导数(SD)、 标准正态变换(SNV)、 S-G滤波和多元散射校正(MSC)五种预处理操作, 基于不同预处理光谱建立紫叶生菜花青素含量的偏最小二乘回归(PLSR)模型并进行性能对比, 确定MSC为理想的光谱预处理方法。 针对原始光谱及经MSC预处理的光谱, 使用竞争自适应重加权采样(CARS)算法分别选择特征波段, 基于全波段(原始光谱、 经MSC预处理光谱)和特征波段(基于原始光谱的特征波段、 基于MSC预处理光谱的特征波段)分别构建PLSR模型, 表现最佳的MSC-CARS-PLSR在验证集上的决定系数( R2)和均方根误差(RMSE)分别为0.872和0.070 mg·L-1, 剩余预测偏差(RPD)为2.862。 为进一步提高预测精度, 本文提出一种融合深度卷积特征和极限学习机(ELM)的回归分析框架Ensemble, 基于改进的Inception模块设计了与输入光谱信号匹配的一维卷积神经网络(1DCNN)作为特征提取器, 采用ELM代替全连接层作为高级回归器对提取的特征进行计算。 通过对比分析, Ensemble性能优于单独的1DCNN模型、 ELM模型以及基于预处理光谱构建的最佳PLSR模型, 其在验证集上的 R2和RMSE分别为0.905和0.060 mg·L-1, RPD为3.319, 表现出较高预测精度以及极佳的稳定性。 进一步分析了预处理操作对Ensemble预测精度的影响, 实验结果显示Ensemble对于预处理操作的依赖程度远小于PLSR, 表明该模型同时继承了1DCNN的深度特征表示和ELM的高泛化性, 能够实现基于原始光谱进行端到端的高精度花青素含量预测, 为及时、 准确掌握紫叶生菜长势情况提供了理论支撑。
The leaves of purple leaf lettuce are rich in anthocyanins, carotene, vitamins, minerals and other elements. Among them, anthocyanin, as the main pigment in the leaf tissue, provides a variety of repair and protection functions for the plants, and its content can reflect the physiological state of purple leaf lettuce, so that the high-accuracy prediction of anthocyanin content has practical significance. In order to efficiently and accurately estimate the anthocyanin content of purple-leaf lettuce, this paper collected hyperspectral data from purple-leaf lettuce and carried out high-precision modeling research. Five preprocessing operations, first derivative (FD), second derivative (SD), standard normal variate transformation (SNV), S-G filter and multiple scattering correction (MSC), were performed on the original average reflectance spectral data. Based on different pretreatment spectra, the partial least squares regression (PLSR) model of anthocyanin content in purple leaf lettuce was established, five preprocessing performances were compared, and MSC was illustrated as the ideal spectral pretreatment method. The competitive Adaptive Reweighted Sampling (CARS) algorithm was used to select characteristic wavebands for the original spectra and the spectra preprocessed by MSC. Based on the full band (original spectra, MSC preprocessed spectra) and characteristic wavebands based on the original spectraand the MSC preprocessed spectra separately), the PLSR model was constructed respectively, the coefficient of determination ( R2) and root mean square error (RMSE) of the best-performing MSC-CARS-PLSR on the validation set were 0.872 and 0.070 mg·L-1, respectively, and the residual prediction deviation (RPD) was 2.862. In order to improve the prediction accuracy further, this paper proposes a regression analysis framework marked as Ensemble that integrates deep convolutional features and extreme learning machines (ELM). Based on the improved Inception module, a one-dimensional convolutional neural network (1DCNN) matching the input spectral signal is designed as a feature extractor. ELM is used as an advanced regressor to replace a fully connected layer to calculate the extracted features. Through comparative analysis, the performance of Ensemble is better than that of a single 1DCNN model, ELM model and the best PLSR model based on preprocessed spectra, and its R2 and RMSE on the validation set were 0.905 and 0.060 mg·L-1, respectively, and the RPD was 3.319, showing high prediction accuracy and excellent stability. The impact of preprocessing operations on the prediction accuracy of Ensemble is further analyzed. The experimental results show that Ensemble is much less dependent on preprocessing operations than PLSR, indicating that the model inherits the deep feature representation of 1DCNN and the high generalization of ELM at the same time, and can realize end-to-end high-precision prediction of anthocyanin content based on the original spectrum, which provides theoretical support for timely and accurate grasp of the growth situation of purple leaf lettuce.
紫叶生菜具有丰富的营养价值, 其叶片中富含花青素、 胡萝卜素、 维生素、 矿物质等, 它们的含量可以有效反应植物的生理状态[1]。 有研究表明花青素可以修复叶片光环境、 提升植物的抗冰冻及抗干旱胁迫能力[2]。 因此, 准确地监测紫叶生菜的花青素含量, 有利于及时掌握其长势情况, 为施肥、 灌溉及生产管理等提供指导。
随着仪器测量技术和化学计量方法的不断完善, 高光谱技术被认为是最具有前景的无损分析技术之一[3]。 在大多数先前的工作中[4, 5, 6], 基于高光谱反射率估算各种植物的生化特征使用偏最小二乘回归(partial least squares regression, PLSR)方法, 如田潇瑜等[4]研究了紫薯贮藏期间花青素的PLSR反演模型, 在验证集上的决定系数(coefficient of determination, R2)和均方根误差(root mean square error, RMSE)为0.91和7.24 m· /(100 g)-1; Gabrielli等[5]对葡萄果实高光谱数据进行预处理后, 建立基于特征波长的花青素PLSR模型, 验证集R2和RMSE达到0.98和33 mg· kg-1; Tian等[6]研究了紫薯在对流风和微波两种干燥方式下花青素含量的变化, 将光谱特征和纹理特征结合建立PLSR模型, 验证集R2和RMSE为0.862和0.079。 上述工作表明高光谱反射率建立的PLSR模型可以在良好的控制环境下以高通量的方式分析相关物种的生化性状。 然而, 这种建模方式在实际应用中较依赖领域专家的输入特征或基于人工操作的预处理技术, 预处理技术的合理运用可以实现对数据的科学优化, 但仍不可避免存在对相关方法的误用及过分使用。 预处理方法误用及过分使用会使原始信号失真, 损失数据中原本有价值的信息, 降低频谱分析精度; 在增加计算量的同时又引入许多可调参数, 使得建立一个良好的量化模型需要用户熟练掌握特定的领域知识[7]; 且不同的预处理方法通常仅适用于其特定的数据集, 方法确定过程较为繁复[8]。 因此, 寻找一种不依赖于人工预处理操作的高精度估算模型至关重要。
卷积神经网络(convolutional neural networks, CNN)是一种可以用于回归任务的强大模型, 其对不同数据结构的高级表示能力使之成为主流的特征提取方法[9]。 近年来, 由于神经网络[10]在无专家端到端学习实现自动化特征提取方面的通用性, 在许多数据分析任务中发挥了重要作用。 已有一些里程碑式的研究开发了基于神经网络的光谱分析方法[11, 12, 13], 其中Xiang等[11]提出了一种基于ResNet的回归模型对番茄果实的可溶性固形物含量进行估算, 与PLSR相较精度提高了26.4%, 稳定性提高了33.7%; Yu等[12]提出了基于层叠式自动编码器和全连通神经网络的深度学习方法成功预测了梨果实的可溶性固形物含量, 验证集的R2和RMSE分别达到了0.921和0.22%; Zhang等[13]建立了基于神经网络的深度学习模型DeepSpectra, 结果表明DeepSpectra可以有效地从原始光谱中学习特征。 上述工作显示了深度学习在植物生化特征值反演中的巨大潜力, 然而目前基于深度学习估算植物生化特征值的研究总体来说还比较欠缺, 精度尚未达到较高水平, 其中利用高光谱反射率对紫叶生菜中花青素含量的估算研究仍为空白。 模型的预测性能很大程度上取决于所提取特征的有效性。 有研究表明Inception模块由于其特定结构使得相应的神经网络在保持计算复杂度的情况下在光谱分析中具有更大的宽度和深度优势[14]。 因此基于改进的Inception模块[15]设计了与输入光谱信号匹配的一维CNN(记为1DCNN)作为特征提取器, 采用极限学习机(extreme learning machine, ELM)代替全连接层作为高级回归器对提取的特征进行估算。 以紫叶生菜为研究对象, 提出了一种融合深度卷积特征和ELM的回归分析框架用以估算紫叶生菜的花青素含量, 创新性的融合方式使其同时继承了CNN的深度特征表示和ELM的高泛化性。
试验对象为紫叶生菜, 2021年4月于中国农业大学(北纬40° 0' , 东经116° 21')信息与电气工程学院植物工厂, 在严格的环境控制下使用1/2Hoagland营养液进行水培种植。 设置光照时间为每日上午八时至下午十八时, 温度保持在25 ℃左右。 在植株生长的第20至30日期间, 每日采集植株带回实验室, 使用北京卓立汉光仪器有限公司的GaiaSorter室内高光谱影像系统进行扫描, 该成像系统配备了V10E型光谱仪、 OL23型镜头、 LT365型侦测器、 两个溴钨灯光源以及电控载物移动平台。 采集的光谱范围为382~1 026 nm, 光谱分辨率为2.8 nm, 采样间隔为0.65 nm, 共728个波段。 成像系统的曝光时间为15 ms, 载物平台的移动速度为2.5 mm· s-1。 将紫叶生菜上部三处均匀分布的叶片剪下, 分别称取0.2 g, 移至离心管中加入10 mL 2%盐酸甲醇溶液密封, 将离心管放入离心机进行离心操作5 min, 再将其放入避光环境下两小时至花青素全部析出。 之后使用分光光度计[16]分别测量花青素溶液在波长为530和600 nm时的吸光度值, 重复三次取平均值作为该株样本的真实花青素含量, 共采集了108株紫叶生菜的高光谱图像和花青素含量实测数据。 表1显示了用于模型构建的测量性状值的数据统计分布, 基于随机选取的方式划分数据集, 其中建模集86个样本, 验证集22个样本。
| 表1 花青素含量样本统计 Table 1 Sample statistics of anthocyanin content |
1.2.1 光谱反射率计算
在建立紫叶生菜花青素含量的估算模型前需从高光谱图像中提取紫叶生菜的光谱反射率数据。 使用基于Python编程语言的Spectral软件包对高光谱图像进行处理, 获取图像中紫叶生菜植株的掩膜进而提取植株的平均反射率数据, 提取过程如图1所示。 读取紫叶生菜高光谱图像后将其转换为归一化植被指数(normalized difference vegetation index, NDVI)图像, 如图1(a)所示。 NDVI图像可以增强植株的特性便于生成掩膜图像, 如图1(b)所示。 最后计算高光谱掩膜图像中非0像素点位置反射率的平均值, 得到紫叶生菜植株的平均反射光谱数据, 如图1(c)所示。
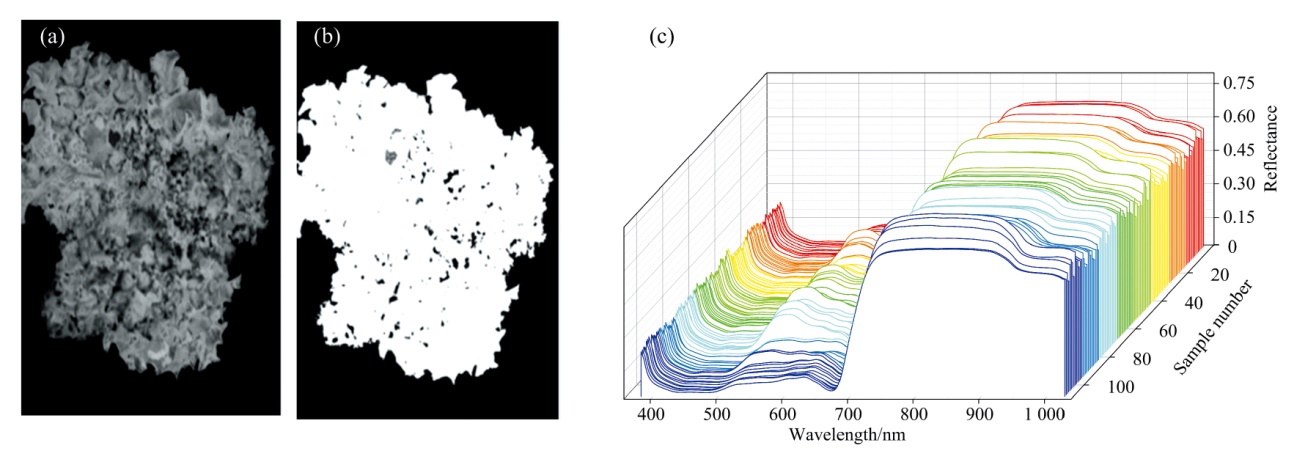 | 图1 (a)归一化植被指数图像; (b)掩膜图像; (c)平均反射率数据Fig.1 (a)Normalized vegetation index image; (b)Mask image; (c)Average reflectance data |
1.2.2 数据预处理
对原始平均反射光谱数据进行了一阶导数(first derivative, D1)、 二阶导数(second derivative, D2)、 标准正态变换(standard normal variate, SNV)、 SG滤波(savitzk-golay filter, SG)和多元散射校正(multivariate scatter correction, MSC)五种预处理操作, 基于预处理后的光谱建立紫叶生菜花青素含量的PLSR估算模型, 用以确定最佳的预处理方案。 之后对经过最佳预处理后的数据使用竞争性自适应重加权采样(competitive adaptive reweighted sampling, CARS)算法进行特征波段筛选以解决相邻波段间存在的共线性问题, 通过将偏最小二乘回归的回归系数和蒙特卡洛抽样方法相结合进行冗余信息的消除, 进而提高回归模型的性能[17], 这项工作使用Matlab 8.1 (The Math Works, Natick, USA)的libPLS工具箱(www.libpls.net)实现, 关于各预处理操作更为详细的信息可以在文献[18]中找到。
1.3.1 PLSR模型
PLSR是一种广泛用于光谱数据建模分析的化学计量方法。 该方法在建模过程中会对样本的光谱数据矩阵和花青素含量矩阵进行主成分分析, 求解隐含变量后根据隐含变量的贡献率建立回归模型[19]。 本文构建了基于高光谱反射数据的PLSR估算模型, 并将其作为紫叶生菜花青素含量估算的基准模型。
1.3.2 Ensemble模型
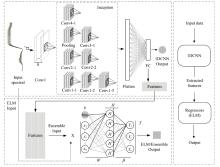
为进一步提高预测精度, 设计了一种基于CNN和ELM的融合模型(记为Ensemble)。 通过结合多个方法来完成学习任务的模型融合一直以来是进一步提升模型学习效果的重要手段[20], Ensemble创新性的融合方式使其兼具CNN高效的特征挖掘能力和ELM优异的泛化性能, 其模型结构如图2所示。
 | 图2 Ensemble模型结构Fig.2 Ensemble model structure |
首先使用8个大小为1× 7的卷积核构建了Conv1卷积层用于初步提取特征, 其中在Inception模块的结构设计中使用四个并行分支对卷积层Conv1输出的8个特征图进行卷积操作, 不同大小的并行卷积核可以提取不同层次的局部特征, 其中卷积核大小为1× 1的卷积层(Conv1-1、 Conv2-1、 Conv3-1、 Conv4-1)通过降低维度、 控制网络容量和向特征图引入非线性在架构中发挥重要的作用, 最后扁平层(Flatten)将Inception模块输出的特征图拉平得到一维向量并将其与全连接层(FC)连接。 然而CNN中作为回归器的FC通常不够健壮, 由于反向传播过程中易陷入局部极小值的问题, 致使其作为处理深度卷积特征的回归器泛化性能有限。
而ELM作为一种特殊的前馈神经网络[21], 具有近似最优的泛化能力且能够保证较高的训练效率。 该方法输入层和隐藏层之间的权重矩阵W和偏置矩阵b在训练前进行随机初始化, 隐藏层和输出层之间的权值β 如式(1)不需要进行迭代求解, 通过计算隐含层的输出矩阵H如式(2), 之后解方程组即可一次求解, 避免了学习过程中的分层调优, 从而保证了优异的泛化性能。 式(1)、 式(2)中T为输出矩阵, H+为H的广义逆矩阵, T'为T的转置, g为激活函数, X为样本光谱矩阵, Y为样本标签矩阵。
采用的损失函数为均方误差(MSE), 并对损失函数添加L2正则化, 损失函数如式(3)。 式中yi为第i个样本的实测花青素含量,
使用网格搜索对卷积核大小、 卷积步长、 激活函数、 优化器类别及学习率进行调优, 最终用于训练的超参数如表2所示。
| 表2 神经网络参数设置 Table 2 Parameter settings of neural network |
为了提高模型性能, 使用网格搜索进行5折交叉验证对模型参数调优, 其中最大潜变量数量为20。 原始平均光谱(无预处理, 记为Original) 先经过五种预处理操作, 从中得到最佳的预处理方案, 对经过最佳预处理后的数据进行CARS操作。 表3列出了PLSR模型基于多种预处理方法及特征选择方法CARS估算花青素含量的模型性能。
| 表3 经过不同预处理的花青素反射光谱估算模型结果 Table 3 Results of anthocyanin estimation model using reflection spectra after different pretreatments |
对比各模型, 发现MSC为最佳预处理方法, MSC可以将光谱数据中的散射光信号分离, 有效消除由于散射水平不同带来的基线漂移和平移现象, 进而增强光谱与数据之间的相关性。 分析可见, 预处理对于PLSR估算模型的效果十分显著, 是影响PLSR估算精度的重要因素。 使用CARS算法对数据进行特征波长选择的分析结果如图3所示。 在MSC的基础上进行CARS特征波长选择, 之后基于特征波长建立PLSR模型, 可见经过MSC预处理后, CARS有效的剔除了全光谱两端易受噪声影响的波段, 且特征波长的数量明显减少。 MSC-CARS-PLSR模型在验证集上的R2和RMSE分别为0.872和0.070 mg· L-1, RPD为2.862, 预测精度优于Original-PLSR、 MSC-PLSR模型, 略低于Original-CARS-PLSR模型, 然而MSC-CARS-PLSR模型仅使用了46个特征波长, 相较于全波长降低了93.6%。 上述结果证实了光谱预处理可以显著提高传统多元模型的预测性能和稳健性。
 | 图3 花青素特征波长选择结果 S表示筛选出的特征波长的个数Fig.3 Results of anthocyanin characteristic wavelength selection S represents the number of selected wavelengths |
利用紫叶生菜完整原始反射光谱的性状数据和反射率信息, 未经任何预处理和特征提取操作, 比较了1DCNN、 ELM以及Ensemble的建模效果, 各模型性能见表4; 预测和验证结果分别如图4(a)、 (b)和(c)所示。 分析表明, 直接使用原始光谱作为输入数据的Ensemble在花青素含量估算的任务中取得了最优的预测效果, 且性能优于经过预处理后最佳的PLSR模型。 其决定系数R2达到0.9以上, 表明Ensemble可以提供很好的预测能力; 其RPD大于3.0, 表明模型具有较好的稳定性。 之后进一步分析了预处理操作和特征选择算法CARS对Ensemble预测精度的影响, 其中使用Ensemble对MSC处理后的全波长反射光谱数据进行建模, 建模结果如表4所示。
| 表4 神经网络模型性能 Table 4 Performance of neural network model |
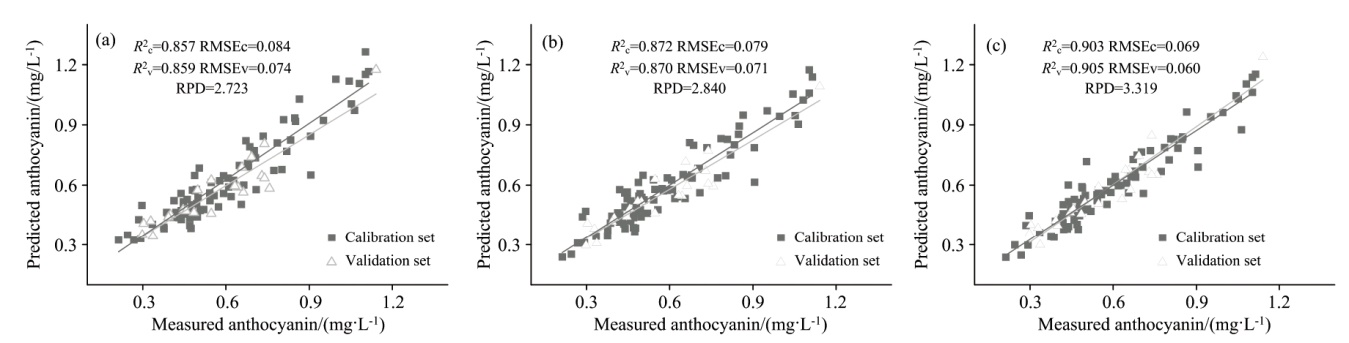 | 图4 基于全波长的神经网络模型对花青素含量估算结果 (a): 1DCNN模型估算结果; (b): ELM模型估算结果; (c): Ensemble模型估算结果Fig.4 Estimation results of anthocyanin content based on full-wavelength neural network model (a): 1DCNN model; (b): ELM model; (c): Ensemble model |
分析表明, 经MSC处理后, Ensemble在建模集和验证集上的精度均有少许下降, 因此之后基于Ensemble使用原始光谱进行CARS后的数据进行建模, 建模结果见表4。 其建模集和验证集上的误差均有上升, 说明基于原始光谱建立的Ensemble已经可以取得较高的预测精度, 预处理和特征选择操作对Ensemble的正向效用并不显著。
对比本文提出的融合模型Ensemble和单独模型1DCNN、 ELM以及传统方法PLSR, 由于Ensemble是两个模型的级联, 它使用深度学习模型作为隐式特征提取工具, 将提取出的局部空间模式传输给下游进行基于特征的模型构建, 相较于直接使用1DCNN模型或ELM模型输出的特征进行估算, Ensemble相当于在粗特征提取上考虑了精确匹配特征, 而精确匹配特征的提取恰好是提升模型精度的关键。 同时1DCNN擅长学习不变的特征, 但并不总是具有良好的泛化性能。 相反, ELM擅长以极快的速度逼近任何目标连续函数, 但不善于学习复杂的不变量, 而两类估算方法的融合则为提高整体模型性能提供了一种有效的途径。
基于端到端的深度学习方法及集成的建模思路对紫叶生菜花青素含量进行高精度估算方法研究, 通过设计实验以及对比分析, 证明了新模型架构的有效性, 并获得以下结论:
(1)利用紫叶生菜反射光谱建立的PLSR模型可以用于快速准确地估算花青素含量值。 相较基于原始光谱建立的PLSR预测模型, 在MSC的基础上进行CARS特征波长选择后建立的PLSR估算模型的精度有所提升, 其验证集的R2和RMSE为0.872和0.070 mg· L-1, RPD为2.862。 经过处理后的输入数据仅使用46个特征波段, 模型具有较低的计算负担, 但较为依赖于专家领域的知识, 且需要额外的人工预处理和特征选择操作, 不能实现自动化特征提取。
(2)基于改进Inception模块的1DCNN, 提出了一种融合深度卷积特征和ELM的端到端回归分析框架Ensemble, 其在验证集上的R2和RMSE为0.905和0.060 mg· L-1, RPD达到了3.319, 该模型直接使用原始光谱作为输入数据, 无需根据先验知识进行特征提取即可获得高精度估算结果, 且模型具有较好的鲁棒性, 便利于希望通过简化模型和减少建模负担来实现自动化特征提取的研究者和从业者。 但同时由于原始数据作为输入这一特点使得模型在一定程度上增加了计算成本。
(3)加入MSC预处理和CARS特征选择操作并不能显著改善Ensemble模型的性能, 说明Ensemble对于数据预处理操作的依赖程度要远低于PLSR。
本工作旨在基于高光谱构建紫叶生菜花青素含量模型, 实现针对原始光谱的端到端高精度花青素含量的高效预测。 在未来的研究中, 有必要对模型的可解释性进行探讨, 同时在实际环境中, 模型在不同应用条件的适用性往往存在差异, 使模型的实用性降低, 今后有望开展相关的普适性研究, 使得构建的参数估算模型在不同环境条件下均有所用。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|