


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于特征光谱参数的叶片和冠层尺度茶多酚含量估算
[段丹丹1, 2  , 刘仲华
, 刘仲华1, * , 赵春江2, 3 , 赵钰2, 3 , 王凡2, 3 ]
, 刘仲华, 赵春江|
|


作者简介: 段丹丹, 女, 1984年生, 国家农业信息化工程技术研究中心高级工程师 e-mail: duandd@nercita.org.cn
茶多酚具有很强的生理活性和抗氧化性, 是茶品质的重要属性之一。 相比传统茶多酚含量的测定方法, 遥感技术监测茶多酚含量具有高效、 精确及实时的优势, 但如何利用遥感数据监测不同时期的茶多酚含量研究较少。 该研究以广东省英德市的5个茶园的茶叶为研究对象, 对春茶、 夏茶和秋茶的叶片与冠层两个尺度的茶多酚含量及对应高光谱数据进行测定, 利用标准正态变量变换(SNV)对叶片和冠层的高光谱反射率数据进行预处理; 然后, 分别采用连续投影算法(SPA)和竞争性自适应重加权采样算法(CARS)筛选不同生长季节叶片和冠层两个尺度茶多酚的敏感波段; 最后, 通过偏最小二乘法(PLS)、 随机森林(RF)和多元线性回归(MLR)分别构建不同时期的茶多酚含量模型并进行验证。 结果表明: (1)茶多酚的含量随着季节推移显著增加, 春茶茶多酚含量(15.37%)最低, 夏茶茶多酚含量次之(18.29%), 秋茶茶多酚含量(秋茶20.77%)最高; (2)不同敏感波段筛选的茶多酚含量的光谱特征波段主要为2 100~2 200 nm附近、 1 300~1 400 nm附近、 红波-红边波段及绿波段; (3)基于春茶、 夏茶和秋茶冠层光谱特征构建的茶多酚模型中CARS-PLS、 SPA-MLR和CARS-PLS模型精度最高, 建模集 R2分别为0.56、 0.45和0.52, RMSE分别为1.15、 1.68和1.77; 验证集 R2分别为0.43、 0.40和0.41, RMSE分别为1.60、 1.91和1.91; 基于春茶、 夏茶和秋茶冠层叶片光谱特征构建的茶多酚模型中SPA-PLS、 CARS-PLS和SPA-MLR模型精度最高, 建模集 R2分别为0.50、 0.42和0.42, RMSE分别为1.25、 1.70和1.66; 验证集 R2分别为0.43、 0.36和0.38, RMSE分别为1.44、 1.96和2.49。 研究结果表明, 基于遥感数据进行不同季节的叶片和冠层两个尺度的茶多酚含量估算是可行的, 在大面积实时监测茶品质特征方面具有较大的潜力。
The content of tea polyphenols has strong physiological activity and antioxidant properties, which are important attributes of tea quality, and play an important role in human body fat metabolism and scavenging free radicals. Compared with the assay method of tea polyphenol content, although monitoring the content of tea polyphenols based on remote sensing technology has the advantages of high efficiency, accuracy and real-time, there are few studies on how to use remote sensing data to monitor the content of tea polyphenols. This study took tea leaves from five tea gardens in Yingde City, Guangdong Province, as the research object, and measured the content of tea polyphenols and the corresponding hyperspectral data at two scales of leaf and canopy of spring tea, summer tea and autumn tea. Standard normal variate transformation (SNV) was used to preprocess leaf and canopy hyperspectral reflectance data; then, Successive projections algorithm (SPA) and competitive adaptive weighted sampling algorithm (CARS) to select the sensitive bands of tea polyphenols at two scales of leaf and canopy in different growing seasons; Finally, the tea polyphenol content models in different periods were constructed and verified by partial least squares (PLS), random forest (RF) and multiple linear regression (MLR). The results showed that: (1) The tea polyphenols content increased significantly with the passage of seasons, the content of tea polyphenols in spring tea (15.37%) was the lowest, the content of tea polyphenols in summer tea was the second (18.29%), and the content of tea polyphenols in autumn tea (20.77% in autumn tea) was the highest; (2) The characteristic bands of tea polyphenols are mainly concentrated in the short-wave near-infrared band (around 2 100~2 200 nm), near-infrared (around 1 300~1 400 nm), red wave-red edge band and green band; (3) The CARS-PLS, SPA-MLR and CARS-PLS have the highest precision among the tea polyphenol models constructed based on the spectral characteristics from spring, summer and autumn canopy, with R2 of 0.56, 0.45 and 0.52 respectively, and RMSE of 1.15, 1.68 and 1.77 respectively; The validation set R2 was 0.43, 0.40 and 0.41 respectively, and the RMSE was 1.60, 1.91 and 1.91 respectively; The SPA-PLS, CARS-PLS and SPA-MLR models based on the spectral characteristics of spring tea, summer tea and autumn tea canopy leaves have the highest precision, with R2 of 0.50, 0.42 and 0.42 respectively, and RMSE of 1.25, 1.70 and 1.66 respectively; The validation set R2 was 0.43, 0.36 and 0.38 respectively, and the RMSE was 1.44, 1.96 and 2.49 respectively. The results showed that it is feasible to measure the content of tea polyphenols at two scales of leaf and canopy in different seasons based on remote sensing data and has great potential for real-time monitoring of tea quality characteristics in large areas.
茶鲜叶内含物质的丰富程度, 直接影响到成品茶品质的上限。 因此从源头开始监测茶树生长态势, 尤其茶鲜叶中茶多酚含量, 是茶产业发展的重要环节。 影响红茶品质的理化成分有茶多酚、 咖啡碱及氨基酸, 茶黄素、 芳香物质等在红茶品质的评定中也发挥着重要作用[1]。 目前茶叶品质的评定只能在茶叶采摘、 加工之后进行, 存在严重的滞后性, 所以利用遥感数据从源头监测茶树不同生长时期生长态势, 探究不同时期的茶鲜叶内含物, 对于实时指导茶业生产、 及时实施精细化和科学化的管理等具有重要意义。
关于茶叶品质量化评估的研究主要有以下2个方面: (1)实验室理化分析量化茶叶品质[2, 3]是传统的茶品质监测方法, 时效性差且需要大量的人力物力。 (2)无损检测技术以高效、 便捷且成本低等优势在茶品质监测方面得到了广泛的关注。 利用茶光谱信息为自变量, 结合不同的估测方法快速对茶多酚、 茶氨酸、 茶叶氮磷钾、 叶绿素含量等进行了大量的测试。 Wang等[4]利用HSI与化学计量学相结合, 预测了五个栽培品种的茶叶中的P和K含量, 预测相关系数R达到0.942 3(P)和0.916 8(K)。 Lin等[5]揭示了近红外光谱在茶叶质量评价中的主导地位, 回归模型在茶叶的定量分析中得到了广泛的应用, 如酚类、 黄酮类物质、 色素、 感官评价和农药残留, 而分类模型则有助于区分地理产地、 品种和发酵程度。 Jia等[6]基于近红外光谱技术建立了岳州龙井茶不同品质等级的感官品质评分、 总儿茶素和咖啡因的定量预测模型, 感官评分、 总儿茶素和咖啡因的最佳预测模型为VCPA-IRIV+SVR、 VCPA-IRIV+RF和CARS+SVR, 相对百分比偏差(RPD)分别为2.485、 2.584和2.873。 Ren等[7]采用偏最小二乘(partial least squares, PLS)算法对不同地理来源的红茶咖啡因、 水提取物、 总多酚和游离氨基酸水平的模型进行校准成功地用于快速确定红茶的主要化学成分和地理起源。 Wang等[8]结合高光谱成像(HSI)使用变量选择算法预测在不同氮处理水平下茶叶中的叶绿素a(Chl a), 叶绿素b(Chl b), 总叶绿素(总Chl)和类胡萝卜素(Car)含量。 Yamashita等[9]研究发现在1 325~1 575 nm处可用于叶片氮和叶绿素(Chl)含量的无损估计。 茶叶近红外光谱[10]、 荧光高光谱[11]、 高光谱[12]等信息已被用于不同种类茶叶品质与等级及产地的量化判别模型。 光谱监测技术在大田作物上已经得到广泛应用, 茶叶因其结构特性以及采摘部位与大田作物有着较大区别。 目前, 基于遥感技术在茶叶内含物质方面的研究以单个生育期的叶片作为检测对象为主, 叶片光谱特性被广泛应用于茶叶品质监测, 但叶片尺度遥感信息将限制大区域茶品质监测研究。 茶树主要采茶季(春茶、 夏茶、 秋茶)茶树冠层结构以及茶叶内含物质的含量均存在较大差异, 且对冠层尺度和叶片尺度光谱响应上具有较大差异。 不同尺度光谱特征在不同生育时期茶品质监测方面仍缺乏系统、 全面的研究。
本研究以茶鲜叶为研究对象, 基于叶片和冠层光谱特征对5个茶园不同生育时期茶鲜叶茶多酚含量进行监测, 并利用不同的深度学习算法[偏最小二乘法(partial least squares, PLS)、 随机森林(random forest, RF)和多元线性回归(multiple linear regression, MLR)]构建了基于光谱特征的茶鲜叶原位茶多酚估算模型, 最后用于独立样本验证。
本实验于2020年3月-11月在广东省英德市茶叶生产示范基地进行。 该区域位于北纬24.24° , 东经113.79° , 平均海拔为181 m(见图1)。 英德市处于南亚热带向中亚热带的过渡地区, 属亚热带季风气候, 夏季盛行偏南的暖湿气流, 冬季盛行干冷的偏北风。 全年平均气温变化在20.10~22.00 ℃之间。 实验品种涵盖英红九号、 金萱、 鸿雁十二号、 黄旦、 金牡丹、 英州一号、 梅占、 云南大叶、 黄玫瑰和软枝乌龙共计10个品种, 均为10年树龄。 春茶从立春开始进行春茶观测周期, 选取清明节前一周、 谷雨前一周。 夏茶采摘期在小满前一周、 芒种前一周。 从立秋开始, 选取秋分前一周、 寒露前一周, 每组样本设置5个重复。 共抽取了198个样本点, 获取春茶共计82个样本, 夏茶共计67个样本, 秋茶共计49个样本。
 | 图1 研究区域Fig.1 Study area |
将检测过高光谱信息的茶鲜叶, 采用国标法GB/T8305-2013测茶多酚的含量。 采用70%的甲醇水溶液在70 ℃水浴上进行提取, 福林酚试剂氧化茶多酚中-OH基团并显蓝色, 在波长765 nm处测得吸收值, 同时用没食子酸作校正标准定量茶多酚。
1.3.1 冠层光谱测定
实验包含5个茶园, 每个茶园选取约10个样本点进行测量, 每个样本点测量10次获取茶鲜叶冠层光谱数据, 10次光谱的平均值作为该样点的最终光谱曲线。 本研究光谱测量采用美国ASD的光谱仪FieldSpec4, 波段范围为350~2 500 nm, 在350~1 000 nm光谱区的分辨率为1.40 nm, 在1 000~2 500 nm间分辨率为2 nm, 采样间隔为1 nm。 测定选择在天气晴朗、 无风或风速很小的天气条件下, 10:00-14:00进行。 每次测量前用标准白板校正, 将传感器探头垂直向下, 距树冠层顶垂直高度约1 m, 传感器视场角为25° , 如图2(a)。
 | 图2 茶鲜叶冠层光谱数据获取(a), 茶鲜叶叶片光谱数据获取(b)Fig.2 Acquisition of canopy spectral data of fresh tea leaves (a), Acquisition of leaf spectral data of fresh tea leaves (b) |
1.3.2 叶片光谱测定
在对应取样位置测定整体冠层光谱信息之后采摘一芽二叶茶鲜叶, 在实验室采用叶片夹和光谱仪测量叶片光谱信息[同步采摘每份样品约200 g, 在每份样品中取10片茶叶(约3 g)进行光谱测量]。 每个叶片样本进行10次光谱重复测量, 将测得的叶片反射光谱异常值剔除后, 取其平均值作为该样本的反射率, 如图2(b)。
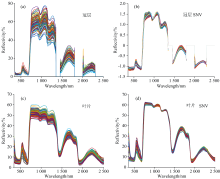
对于冠层反射光谱, 剔除水分噪音较大的1 400~1 500、 1 800~2 000以及2 300~2 500 nm之间的波段。 叶片光谱的获取因为在控制环境下, 因此没有进行波段删除。 利用标准正态变量变换(standard normal variate transformation, SNV)算法主要是用来消除因固体颗粒大小不均、 物体表面散射、 光程改变等一些因素产生的对光谱的不利影响。 采用SNV对茶鲜叶叶片和冠层的光谱反射率进行预处理, 结果如图3(a-d)所示。
 | 图3 基于SNV预处理的冠层和叶片光谱反射率Fig.3 Spectral reflectance with SNV pre-processing methods of leaf and canopy |
1.5.1 特征波段筛选方法
拟运用连续投影算法(successive projections algorithm, SPA)和竞争性自适应加权采样算法(competitive adaptive weighted sampling algorithm, CARS)筛选出有效光谱信息。 连续投影算法(SPA)作为一种变量选择技术, 通过最小化校准数据集中的共线性优化模型构建条件。 竞争性自适应重加权采样算法(CARS)基于频谱的应用中用于关键变量筛选的新开发算法。 基于自适应加权采样(CARS)和达尔文进化论中的“ 适者生存” 的原理。 这两种方法是选择基于全光谱波长中存在的最佳特征变量的有效方法, 并展示出良好的性能[13]。 基于SPA和CARS从茶鲜叶的光谱数据中提取具有最小共线性冗余度和最大投影矢量的波段变量, 以减少变量的数量并提高模型的速度和效率。
1.5.2 建模方法
偏最小二乘回归(partial least squares, PLS)主要研究多因变量或单因变量对多自变量的回归建模, 最简单的形式是因变量y与自变量x之间的线性回归模型。
随机森林(random forest, RF)是一个包含多个决策树的分类器, 其输出类别是由个别树输出的类别的众数而定, 采用袋外数据集(out-of-bag data, OOB)重要性原则, 对数据进行降维。
多元线性回归(multiple linear regression, MLR)是包括两个或两个以上自变量对一个因变量的回归模型。
所有的实验数据随机按照2:1选择出需要的校正集样本数目。 根据茶多酚含量估算模型的构建, 选取决定系数(coefficient of determination, R2)、 均方根误差(root mean squared error, RMSE)作为模型精度的验证。 R2反映模型建立和验证的稳定性, R2越接近于1, 说明模型的稳定性越好、 拟合程度越高。 RMSE用来检验模型的误差, RMSE越小模型估算能力越好。
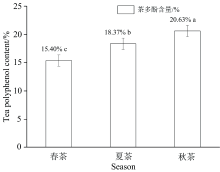
如图4所示, 通过实验室理化分析检测以上10种茶树鲜叶的茶多酚含量(干重15%~20%), 不同季节茶多酚含量存在较大差异。 (1)秋茶的茶多酚含量显著高于春茶和夏茶。 春茶茶多酚平均含量最低(15.40%), 夏茶茶多酚平均含量次之(18.37%), 秋茶茶多酚平均含量最高(20.63%)。 (2)春茶、 夏茶和秋茶茶多酚平均含量分别为8.84%~21.87%, 13.22%~23.71%和13.55%~23.36%。
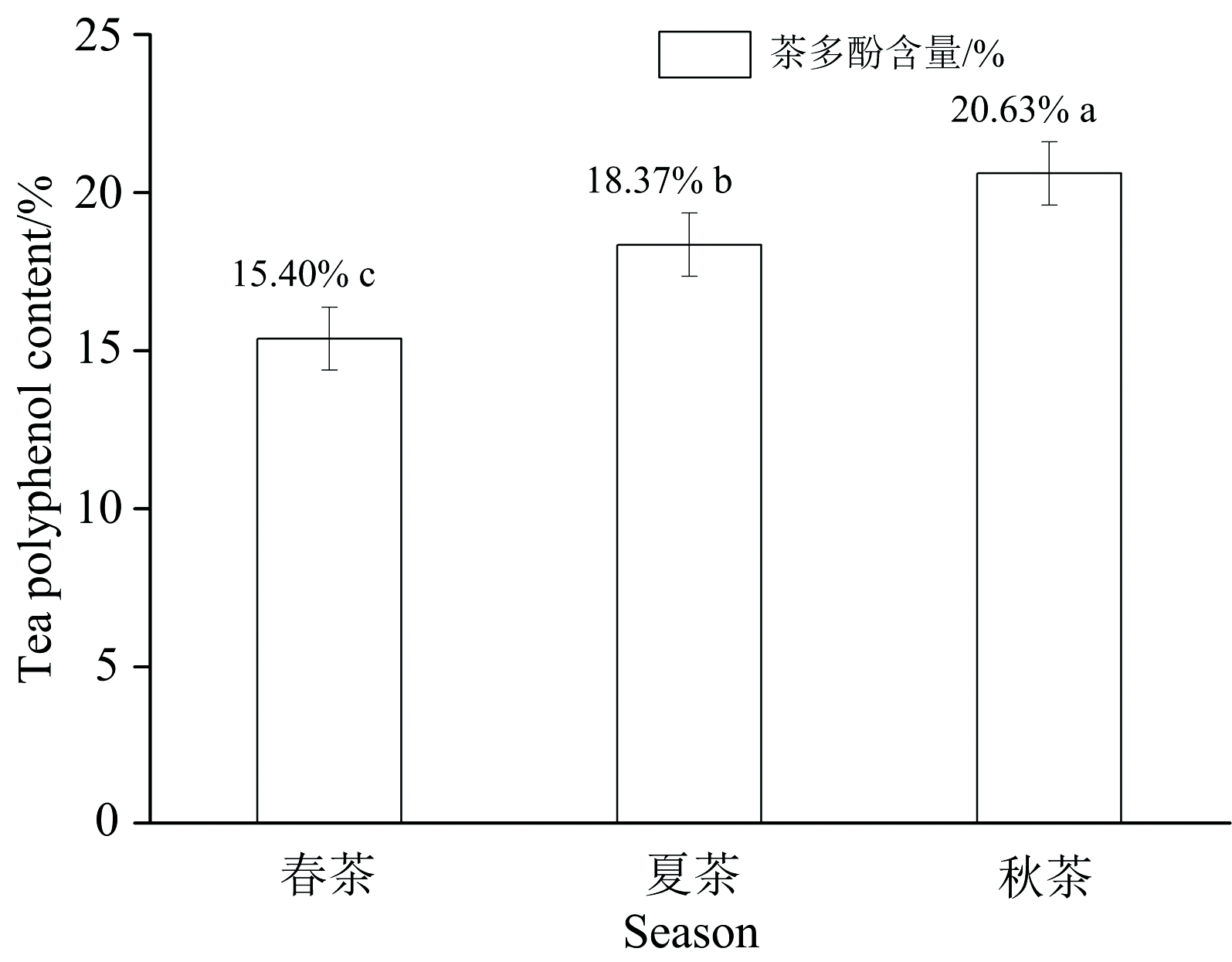 | 图4 不同生育时期茶多酚含量(%)Fig.4 Tea Polyphenols content of fresh tea leaves in different season |
特征波段的选择是建立茶鲜叶品质成分预测模型的关键, 冠层尺度光谱特征和叶片尺度光谱特征筛选结果见表1。 茶多酚的特征波段主要集中在短波近红外波段(2 100~2 200 nm附近)、 近红外(1 300~1 400 nm附近)、 红波-红边波段及绿波段。
| 表1 茶多酚的特征波段筛选结果 Table 1 Results of featured wavelength of tea polyphenols |
表1叶片与冠层两种尺度不同的波段筛选结果, 分别采用偏最小二乘回归(PLS), 随机森林回归(RF)以及多元线性回归(MLR)方法对春茶、 夏茶、 秋茶的鲜叶的茶多酚含量进行估算。 茶多酚含量估算模型结果如表2所示。
| 表2 茶多酚含量估算模型 Table 2 Models of tea polyphenols in calibration set |
表2中, 基于叶片光谱特征构建的茶多酚模型普遍高于基于冠层尺度构建的模型, 且PLS和MLR模型的精度普遍高于RF模型精度。 以春茶、 夏茶和秋茶叶片尺度运用SPA筛选的特征波段所建模型为例, MLR建模精度最高, R2分别为0.53、 0.42和0.42, RMSE分别为1.25、 1.70和1.66。 在于春茶、 夏茶和秋茶冠层光谱特征构建的茶多酚模型中CARS-MLR、 SPA-MLR和CARS-MLR模型精度最高, R2分别为0.57、 0.45和0.57, RMSE分别为1.34、 1.68和1.69。
利用验证集数据对所构建的模型进行验证, 茶多酚含量验证结果如表3所示。 基于春茶、 夏茶和秋茶叶片光谱特征的验证模型中SPA-PLS模型、 SPA-MLR和SPA-MLR模型精度较高, R2分别为0.43、 0.36和0.38, RMSE分别为1.44、 1.96和2.49。 在春茶、 夏茶和秋茶冠层光谱特征的验证模型中CARS-MLR模型、 SPA-MLR和CARS-MLR模型精度较高, R2分别为0.39、 0.40和0.23, RMSE分别为1.91、 1.91和2.25。
| 表3 茶多酚含量验证模型 Table 3 Models of tea polyphenols in prediction set |
结果如图5(a-f)所示, 展示了叶片和冠层两个尺度, 两种波段提取方法下三种模型的预测效果, 春、 夏、 秋茶三个季节的最优茶多酚预测模型1:1拟合图。
 | 图5 茶多酚最优模型1:1拟合图Fig.5 1:1 fitting diagram of the optimal model of tea polyphenols |
采用叶片与冠层两个尺度的光谱特征对春、 夏、 秋三个生长时期的10个品种进行茶多酚含量监测。 不同季节茶多酚含量存在明显差异, 并呈现出从春茶到秋茶显著递增的趋势。 茶多酚是光合作用等一系列生理活动的产物, 随着光合作用累积的同化产物的增加, 茶多酚的含量也逐步增加。 同时, 春茶滋味鲜爽, 苦涩味少, 秋茶风味醇厚, 经久耐泡也从侧面反映了不同季节茶多酚对茶叶风味的影响。 所筛选的茶多酚的重要光谱区域主要集中在1 300~1 400和2 100~2 200 nm附近, 主要归因于O-H拉伸的第二泛音和第三泛音, 与王凡等[14]研究也得到了相同的结果。 该结果区别与作物在生物量、 叶绿素及叶面积指数等方面以红波段和近红外波段为主的敏感波段, 由于茶多酚属于微量矿物质。 在研究过程中发现: (1)SPA已被证实为一种非常有效的变量选择方法, 可以将变量之间的共线性降到最低。 与之相比, CARS作为一种较新的变量选择理论, 研究证明该方法在变量选择的过程中, 可以同时对共线性变量进行有效压缩以及无信息变量进行有效的去除, SPA筛选出来的波段总体比CARS数量少, 说明原始波段中可能存在大量共线性变量; (2)尽管CARS可以有效压缩共线性变量, 但压缩后的变量仍然存在部分集中共线性; (3)较少的特征波段, 有利于降低开发在线检测设备的成本, 更有利于仪器的开发。 SPA更适宜茶多酚的敏感波段的筛选。
基于三种建模方法(PLS、 RF、 MLR)得到的实验结果中发现, 通过MLR进行建模精度较好, 而RF实验结果均较差, 与陶惠林等[15]研究结果相似。 可能RF模型对小样本数据, 虽然学习能力强, 但预测能力弱, 并且在验证模型中表现出欠拟合的现象。 综合模型的适用性, 以及空间尺度和时间尺度, MLR方法模型更适合茶多酚含量的估算。 相比冠层尺度的茶多酚模型, 本工作在叶片尺度构建的模型具有更高的精度。 一方面, 叶片光谱是直接对茶叶样本进行的测定, 而冠层光谱测定范围比样本采集范围更大; 另一方面, 冠层光谱受非观测茶叶目标及土壤等因素影响。 冠层尺度的茶多酚模型的精度虽然低于叶片尺度的模型精度, 但其为大尺度进行茶叶品质监测提供了科学依据。
相比于传统的茶叶品质的感官评审和化学检测, 本研究进行的原位、 快速、 大面积、 无损伤性品质分析避免主观判断的影响。 另外, 将高光谱数据有效降维, 可降低检测茶多酚含量仪器的开发成本。 对于茶农进行茶园精准化栽培, 茶企针对茶青品质进行标准化加工, 提高成品茶的质量具有重要意义。
(1)采用国标法对茶树叶片与冠层两个尺度春茶、 夏茶、 秋茶三个关键生育期的连续实验室理化检测。 检测到从春茶到秋茶鲜叶茶多酚含量逐步增加的变化趋势(春茶茶多酚含量占干重15.37%< 夏茶茶多酚含量占干重18.29%< 秋茶茶多酚含量占干重20.77%)。
(2)茶多酚的特征波段主要集中在2 100~2 200 nm附近、 1 300~1 400 nm附近以及红波-红边波段及绿波段。
(3)在春茶、 夏茶和秋茶冠层光谱特征构建的茶多酚模型中CARS-PLS、 SPA-MLR和CARS-PLS模型精度最高, 建模集R2分别为0.56、 0.45和0.52, RMSE分别为1.15、 1.68和1.77; 验证集R2分别为0.43、 0.40和0.41, RMSE分别为1.60、 1.91和1.91; 对春茶、 夏茶和秋茶冠层叶片光谱特征构建的茶多酚模型中SPA-PLS、 CARS-PLS和SPA-MLR模型精度最高, 建模集R2分别为0.50、 0.42和0.42, RMSE分别为1.25、 1.70和1.66; 验证集R2分别为0.43、 0.36和0.38, RMSE分别为1.44、 1.96和2.49。
(4)综合比较, 基于冠层的光谱数据来源构建的茶多酚预测模型精度较高, 可以有效预测茶多酚含量。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|