
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
改进遗传算法嵌入经典分类算法实现润滑油添加剂微小量多种类同步识别
[夏延秋1  , 谢培元
, 谢培元1 , NAY MIN AUNG1 , 张涛1 , 冯欣1, 2, * ]
, 谢培元]
|
|


作者简介: 夏延秋, 1964年生, 华北电力大学能源动力与机械工程学院教授 e-mail: xiayq@ncepu.edu.cn
在润滑油中加入微少量添加剂就能使润滑油获得某种新的特性或改善润滑油中已有的某些特性的性质。 针对机械设备润滑油中微小量添加剂多种类识别问题, 基于python语言进行模型建立, 采用基础油PAO-10和三种商用润滑油添加剂T321、 T534、 T307按照不同比例配制了8种不同样本。 采用Thermo Scientific Nicolet iS5型傅里叶变换红外光谱仪采集了样本4 000~400 cm-1范围附近的中红外光谱信息, 并对样本中红外光谱数据采用Min-Max归一化进行预处理。 使用两种经典分类算法, 包括一对多支持向量机(OVR SVMs)、 随机森林(RF), 嵌入遗传算法(GA)实现中红外光谱特征波段筛选。 为避免GA收敛过快和易陷入局部最优解, 对GA的选择算子进行了改进, 形成基于局部搜索算子的遗传算法(LGA), 从而建立多类别分类模型的构建方法。 结果显示: 嵌入GA筛选波段后的新模型的种类识别准确率从利用经典分类算法对原始波长数据的OVR SVMs(83.33%)、 RF(87.50%)提升至OVR SVMs+GA(100%)、 RF+GA(100%); 而嵌入LGA的新模型在保持原模型高准确率的情况下, RF+LGA筛选得到的特征区间长度为原光谱数据长度的36.7%, 并且与添加剂物质的红外吸收峰有很好的对应情况。 新模型不仅适用于只含单一添加剂的情况, 对含有两种及两种以上添加剂的同步识别仍然具有近100%的较高识别率。 表明所构建模型可以有效实现微小量润滑油添加剂的快速、 准确、 多种类同步识别。
Adding a small amount of additives to the lubricating oil can make the lubricating oil obtain some new characteristics or improve the properties of some existing characteristics in the lubricating oil. Aiming at the problem of identifying various kinds of tiny additives in lubricating oil of mechanical equipment. Based on Python, eight different samples were prepared with Base Oil PAO-10 and three Commercial lubricating oil additives, T321, T534, and T307, in different proportions. Thermo Scientific Nicolet IS5 Fourier collected the mid-infrared spectra of the samples transform infrared spectrometer in the range of 4 000~400 cm-1, and the infrared spectra of the samples were normalized by Min-Max. For nearly category mechanical equipment of tiny amount of additive in lubricating oil variety identification, four classical classification algorithms are studied, including the Support Vector Classifier (OVR SVMs), Random Forests Classifier (RF), embedded in the Genetic Algorithm (GA), and Local search Genetic Algorithm (LGA) optimization technologies, infrared spectrum characteristic band many category classification model building methods are established. Example test results show that the accuracy of the new model improves the original classical algorithm's OVR SVMs (91.67%) and RF (79.17%) to OVR SVMs (100%) and RF (100%). With the new models embedded in LGA, the length of the characteristic band was shortened to 36.7% of the length of the original band. The new model applies to the case with only one additive and has a high recognition rate of 100% for the simultaneous identification of two or more additives. The results show that the model can effectively realize the rapid, accurate, and multi-type synchronous recognition of small amounts of lubricanting oil additives.
随着各种高精尖设备的广泛应用, 设备对润滑油品的性能要求不断提高。 添加剂作为润滑油的精髓, 多种类添加剂协同作用, 改善了润滑油物理化学性能、 满足了特殊工况润滑需求[1]。 虽然油品添加剂的种类繁多, 但其含量通常只占润滑油质量极小的部分, 仅从油品外观上难以区分使用类别, 一旦标签失效或丢失, 将造成油品的管理和使用混乱, 并且带来经济损失; 对运转设备的残油、 废油、 漏油中添加剂的种类识别, 可以及时分析油品健康状态、 精准定位并预测不良状态部件, 达到对设备的监测及维护提供前期预警目的。 研究一种快速且准确的微小量、 多品种润滑油添加剂的同步识别方法具有现实意义。
红外光谱分析法具有方便、 快捷、 精确等特点, 结合现代模式识别技术、 计算机技术, 被越来越多地应用于各种物质的定性及定量分析[2]。 人工智能、 机器学习的发展带动了诸多行业与智能算法的关联, 为人类鉴别、 区分物质提供了快捷的方法。 如近红外光谱与支持向量机(SVM)结合进行水稻类型识别[3], 近红外光谱和中红外光谱结合偏最小二乘分析法对意大利初榨橄榄油进行分类[4], 采用偏最小二乘法[5]、 区间最小二乘法[6]、 最小二乘支持向量机[7]等方法预测某种成分的含量。 有一部分学者使用拉曼光谱[8]、 气相-色谱、 太赫兹光谱、 阻抗谱等获取数据, 不过中红外光谱测量的波数范围为4 000~400 cm-1, 其含有润滑油丰富的分子结构信息, 可通过直接或间接关联的方法测定润滑油的族组成、 添加剂的含量等。 研究人员致力于尝试在高维的数据中选择某些特征, 来提高求解效率[9]。 这些方法与技术在设备润滑油领域的研究, 多数仍仅限于针对某一特定物质含量的检测来评估润滑油的老化程度等质量问题[10], 或者是润滑油的种类识别、 品牌识别[11]。
基本遗传算法(GA)是一种经典的仿生算法, 具有群体搜索特性并被广泛应用于各种领域, GA具有过早收敛和易于陷入局部最优的问题。 为了保证GA的计算效率和全局搜索的准确性, 对于遗传操作的研究一直是GA算法中最活跃的领域之一。 Zhou等[12]对比了普通遗传算法、 粒子群算法和一种嵌入免疫算法思想作为选择算子的遗传算法再解决无人飞行器返回基地的路径选择问题上的表现, 发现嵌入免疫思想选择算子的遗传算法成功搜索目标的次数更多。 Diana等[13]探索了可变下降领域VND作为局部搜索算子改进了包括遗传算法在内的三种启发式算法解决经典问题的表现, 发现其在三种算法的评价中都超过了目前最先进的改进方式。 对于润滑油添加剂种类识别的问题, 夏延秋等使用极限学习机结合遗传算法和贪心算法建立了模型, 但是仅识别了含单一添加剂的润滑油[14]。 夏延秋等使用遗传算法与二进制粒子群算法混合优化基于随机森林(RF)和K近邻(KNN)两种经典分类算法的光谱全波段筛选, 但是筛选的光谱特征波段与表征润滑油添加剂的特征峰所在波段对应较差[15]。
本工作选用一对多支持向量机(OVR SVMs)[16, 17]、 加随机森林(RF)[18]两种典型分类算法, 分别嵌入基本遗传算法(GA)和一种基于免疫算法改进局部搜索算子的遗传算法(LGA)优选中红外光谱特征波段, 构建多类别分类模型, 解决设备润滑油中微小量添加剂多种类同步识别问题。
设备润滑油测试样本所用基础油为PAO-10, 油品添加剂选用硫化异丁烯T321、 烷基二苯胺T534、 硫代磷酸铵盐T307三种较常见使用的润滑油添加剂。 按照油品中同时添加品种的种类数目构成的8类样本如表1所示, 每种添加剂均选取1%含量加入油样中, 1表示含有该种添加剂, 0则表示不含有。 每种样本采集10条光谱数据, 样品数据共计80条, 训练集与测试集按7:3的比例均匀划分, 即每种样品采集的10条光谱数据中随机选择7条作为训练集, 3条作为测试集。 56条光谱数据, 每条谱线1 868个谱特征, 经min-max标准归一化后, 被导入各模型开始进行训练。 训练结束后, 将剩余的24条光谱数据导入训练好的模型中, 获得各模型对每一种类添加剂的模型识别准确率。
| 表1 添加剂组合方式 Table 1 Additive combination mode |
试验样本数据采集仪器为Thermo Scientific Nicolet iS5傅里叶变换红外光谱仪, 光谱范围: 7 800~350 cm-1, 采用KBr(溴化钾)窗片, 透过波长7 800~400 cm-1, (1~25 μ m)透过率大于92%。 采集设置: 扫描次数16次, 分辨率4, 数据间隔1 928 cm-1(扫描速度: 0.10~2 cm· s-1)。 每个样本重新装样后采集10次光谱数据, 模拟不同采集人员在红外光谱采集过程中产生的人工误差, 最终获得80个光谱数据。
为避免测量仪器零点漂移和数据数值差距过大, 采用式(1)min-max标准化方法对原始红外光谱数据进行归一化处理, 将数据映射到[0, 1]之间。
式(1)中, xi为原始的光谱数据, xmin为原始光谱数据的最小值, xmax为原始光谱数据的最大值。
接收者操作特征(ROC)曲线能有效反映分类器分类的准确性, 曲线的横纵坐标分别为真正利率(TPR)和假正例率(FPR), 定义如式(2)和式(3)
式(2)和式(3)中, TP为预测为真正例的个数; TN为预测为真负例的个数; FP为预测为假正例的个数; FN为预测为假负例的个数。 曲线下面积(AUC)值定义为以ROC曲线下的坐标轴为边界的面积。 该区域不能大于1。 由于ROC曲线始终在Y=X线上, AUC在0.5到1之间。 AUC值越接近1.0, 分类器的可靠性越高。
识别准确率, 即模型预测正确数量所占总量的比例, 计算公式如式(4)
式(4)中, TP+TN为识别准确的总数, P+N为总识别数。
各添加剂官能团在红外光谱上的位置: 经过查阅红外光谱谱图资料[14]得到各添加剂所含基团对应吸收峰在红外光谱上的位置: T321在657 cm-1处出现因C-S-C振动产生的吸收峰, 以及在1 178 cm-1处出现因C-S振动产生的吸收峰; T534在885~805 cm-1处出现苯环对位双取代烷基峰和1 500和1 600 cm-1位置苯环骨架振动; T307在930~1 110 cm-1处出现因P-N振动产生的吸收峰。 所筛选的波段若能同时包含以上三个吸收峰位置的波段, 则认为种类识别模型建立成功。
原始的中红外光谱数据在采集的过程中难免会存在诸多环境与人为因素的影响及干扰, 出现数据掺杂高噪声和高冗余。 因此对光谱波段进行特征优化筛选, 有效剔除原特征集中的弱相关信息和掺杂的干扰信息, 不仅可以确保模型的稳健性和精确性, 而且对提高模型识别效率尤为重要。 基本遗传算法是一种模拟生命演化的仿生算法, 从一个随机的初始种群开始, 不断进行选择、 杂交和变异的过程, 使种群逐渐向一个设定好的方向进化。 将种群中的每个个体基因型表示为一个n位的0-1编码组合, 对应的将经过归一化处理的光谱(1 868个数据点)划分为n个子区间。 计算识别准确率时, 若基因编码为1, 则计算时包含此波段; 若基因编码为0, 则计算时不包含此波段。 由此, 波段筛选的问题就转换成选择一个识别准确率更高的0-1数字串, 可以认为最终得到的0-1数字串中1所在的位置组合代表的波段即为光谱的波段筛选结果。
GA初始种群数设置为50, 个体基因型长度n经测试后设置为19, 最大迭代次数为100, 使用轮盘赌方法进行选择, 使用两点交叉以概率pc=0.6进行交叉, 以概率pm=0.01进行行位点随机变异, 以种类识别模型输出的识别准确率作为适应度函数值, 若到达最大迭代次数或识别准确率达到100%则停止迭代。
使用局部搜索算子改进GA的选择步骤, 能显著增加GA的全局搜索能力以避免过早收敛和陷入局部最优的问题。 采用了文献[19]中的一种基于优良模式的局部搜索算子, 首先从种群中选取适应度值高于平均值的一部分个体提取出一个“ 优良模式” , 然后基于优良模式生成优良模式附近的局部最优解, 并利用生成的局部最优解与当前最优解进行对比, 若生成解的适应度值和样本长度均优于当前种群最优解, 则用生成解替代最优解。 局部搜索算子的设计如下:
步骤1 生成“ 优良模式” : 从当前种群中选取α · n个个体, 其中α 为比例系数, 实际选择0.14, n为群体规模。 将这些个体作为较优个体, 记为: x1, x2, …, x(α · n)前其中较优群体的长度记为l。
(1) 首先统计较优群体中每个基因位置上的0和1的个数ni
式(5)中, i=1~l, xij表示第j个较优个体的第i个基因位上的值。
(2) 采用一下规则产生优良模式: 若ni≥ β · α · n则yi=1; 若ni≤ β · α · n则yi=0; 若(1-β )· α · n< ni< β · α · n则yi=2。 产生优良模式记为: y1, y2, …, yl, yi={0, 1, 2}, i=1~l。 其中β ∈ [0, 1]为系数, 一般取值为0.8~1, β 越大产生的优良群体越依赖于较优群体, 为了增加搜索空间, 实际β 取值为0.8。
步骤2 生成局部最优解: 以优良模式y1, y2, …, yα · n, yi={0, 1, 2}, i=1~l为基础, 在其附近采用贪婪接受的思想搜索局部最优解z1, z2, …, zi, i=1~l。 搜索方法如下:
① z=bestpop其中bestpop为较优种群中的最优解, 令k=0;
② 随机产生一个优良模式附近的最优解h={h1, h2, …, hi}, i=1~l, 其中hi的生成规则如下: 若yi=0则ki=0; 若yi=1则hi=1; 若yi=2则hi以均匀分布的随机数取0或者1;
③ 若个体h的适应度大于个体z的适应度, 则z=h;
④ 若k≥ n, 结束, 并输出局部最优解z, 否则k=k+1, 转②。 m为搜索次数, 实际设置m=10。
步骤3 代替: 用局部最优解代替当前群体中适应度值最小的个体。
由于采用了局部最优个体保留的机制, 在迭代过程中容易出现多个相同0/1数字串的问题, 从而导致“ 早熟” 现象的出现。 因此在选择过程中利用了免疫算法中基于适应度和浓度的混合选择机制, 由此需要先给出每个数字串的相似度和浓度的定义:
定义1 相似度: 在二进制遗传算法中, 两个长度为l的个体x=(x1, x2, …, xl), y=(y1, y2, …, yl ), i=1~l之间的相似度定义为式(6)
定义2 浓度: 在二进制遗传算法中, 种群规模为n, 任意一个个体x的浓度定义为式(7)
式(7)中, Q(x, y)表示群体中和个体x之间的相似度大于阈值λ 的个体的总数, 实际计算时阈值λ =0.8。 显然, s(x, y)∈ [0, 1]越大, 个体(x, y)就越相似, 当s(x, y)=1时, x和y是相同的个体; c(x)越大表示群体中和个体x相似的个体越多。
设群体中个体为x1, x2, …, xn, 每个个体的适应度为F(xi), 个体xi的浓度为c(xi)。 则基于适应度和浓度的混合选择机制步骤如下:
步骤1 分别计算群体中每个个体基于适应度值的选择概率, 见式(8)
每个个体基于浓度值的选择概率, 见式(9)
当
步骤2 计算群体中每个个体基于适应度值和浓度值的混合选择概率
式(10)中, μ ∈ [0, 1]为浓度和适应度在选择中的重要程度调节系数, 实际设置μ =0.8。
步骤3 用p(xi )作为概率指导轮盘赌选择并产生新个体。
本研究对比了GA、 LGA分别嵌入两种经典机器学习分类器算法: 一对多支持向量机(OVR SVMs)、 随机森林(RF)进行波段筛选的效果, 以下是对2种经典分类器算法的简要介绍:
(1)支持向量机(SVM)的主要思想是在特征空间中寻找间隔最大化的分离超平面以解决二分类问题, 一对多支持向量机(OVR SVMs)则是由多个二分类SVM组成, 以解决多分类问题。 本文中SVM的主要参数如下: C=1; gamma=1/1 868; kernel=‘ poly’ 。
(2)随机森林(RF)属于集成学习方法, 采用多颗决策树对样本进行训练并预测。 通过Bootstrap技术, 从原始训练集样本集中有放回地重复随机抽取k个样本生成新的训练样本集合, 根据样本集生成若干个决策树, 并且随机组合得到随机森林, 新数据的分类结果按决策树投票多少形成的分数而定。 RF的主要参数如下: n_estimators=238; max_depth=3。
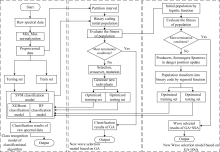
所有算法代码均由Pyuhon语言编写, 使用的编译器为Spyder, 其中SVM以及RF分类由Scikit_learn学习库完成, GA、 LGA等其余部分均由作者自行编写。 以OVR SVMs/RF种类识别分类模型为基础, 分别嵌入GA和LGA进行润滑油样品中红外光谱特征波段筛选, 构建了润滑油添加剂种类识别分类模型, 其工作流程见图1。
 | 图1 经典分类算法种类识别模型与GA/ESGA/LGA优选波段嵌入过程流程图Fig.1 Class recognition model of classical classification algorithm and its process flow chart of band embedding with GA/ESGA/LGA optimization |
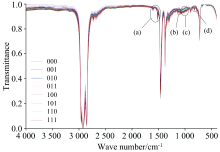
图2为经预处理后的原始光谱图像; 图3为图2中较易辨认的各微小量添加剂的特征峰局部放大图片。 其中(a)为T321的C-S振动吸收峰; (b)、 (c)分别为T534的苯环对位双取代烷基峰和苯环骨架震动吸收峰; (d)为T307的P-N振动吸收峰。
 | 图2 原始红外光谱数据归一化图像Fig.2 Normalized image of original infrared spectral data |
 | 图3 各添加剂特征峰及其位置 (a): T534的苯环骨架振动; (b): T321的C-S振动; (c): T307的P-N振动; (d): T534的苯环对位双取代烷基峰Fig.3 Characteristic peaks and positions of additives (a): Benzene ring skeleton vibration of T534; (b): C-S vibration of T321; (c): P-N vibration of T307; (d): Benzene ring para disubstituted alkyl of T534 |
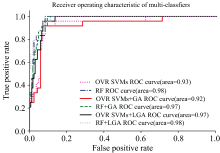
按照图1中所示的流程, 分别采用原波段数据作为输入, 获得经OVR SVMs+GA, RF+GA优选的特征波段数据; OVR SVMs+GA, RF+GA优选的特征波段数据, 导入各模型训练并测试, 多种类润滑油添加剂的同步识别结果见表2; 使用原始数据及各被选波段输入各分类器的ROC曲线见图3; 各模型的波段筛选结果见表3、 图4。
| 表2 各模型对多种类润滑油添加剂的同步识别准确率 Table 2 Accuracy of identification of various lubricant additives by each models |
| 表3 各算法模型波段筛选结果 Table 3 Band screening results of each model |
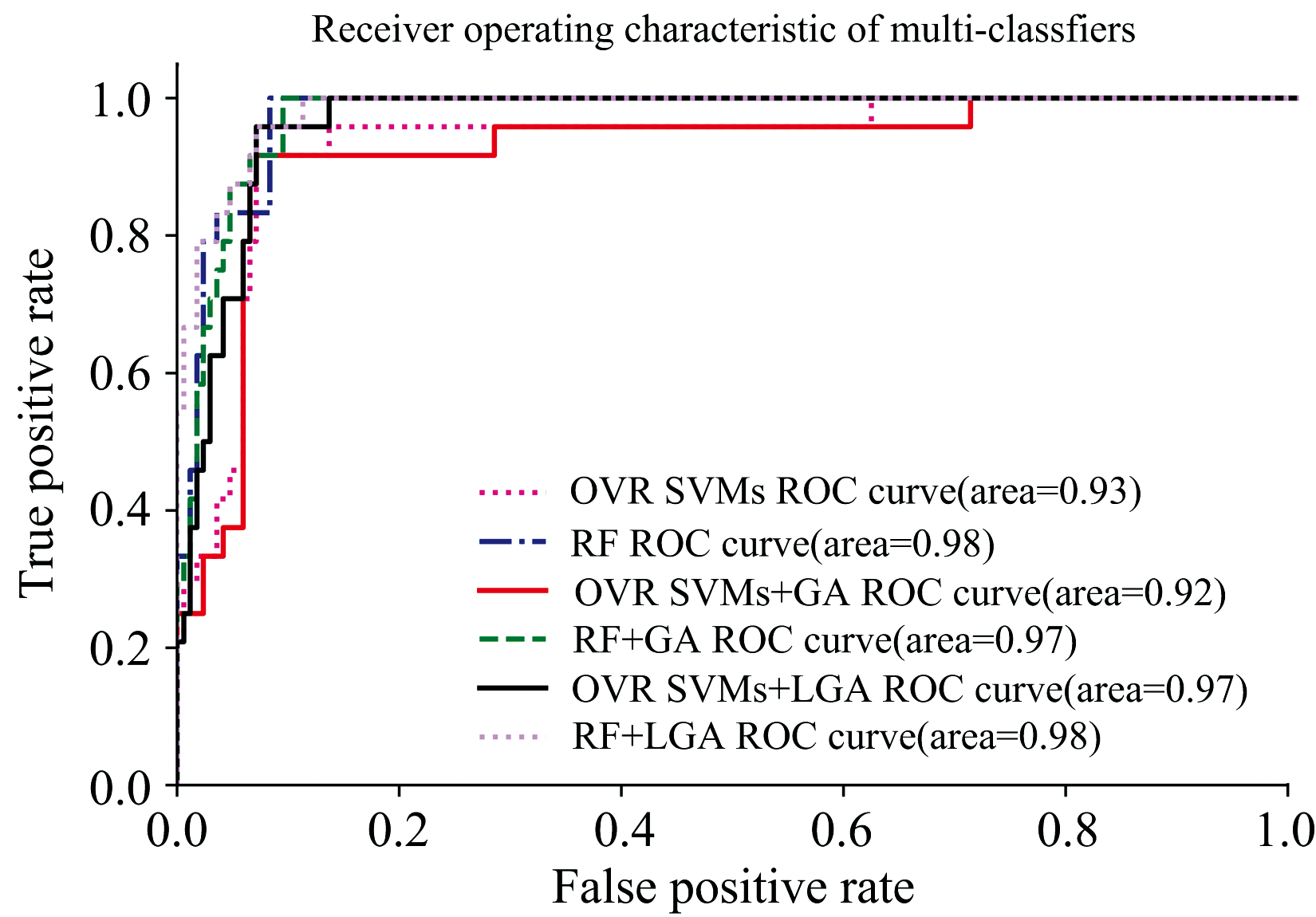 | 图4 各被选波段在不同分类器模型下的ROC曲线Fig.4 ROC curves of selected bands under different classifier models |
图4显示, 在OVR SVMs分类器模型下, 嵌入GA优选波段后ROC曲线的AUC值虽有略微下降, 但仍维持在0.92的较高值; 而嵌入LGA后ROC曲线的AUC值达到了0.97。 可认为其具有较优的分类效果。 在RF分类器模型下, 嵌入GA和LGA优选波段后, 虽然AUC值都有小幅度下降, 但均大于0.97, 具有很好的分类效果。
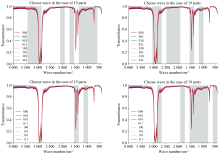
图5(a-d)显示: 图5(a)优选波段中包括了代表T321的657 cm-1处的C-S-C振动; 图5(d)还包含了T321在1 178 cm-1处的C-S振动; OVR SVMs+GA及RF+GA均选择到了代表T534在1 500 cm-1附近的N-H伸缩振动, 且选择到了在930~1 110 cm-1处代表T307的P-N振动; 图5(c)优选波段显示OVR SVMs+LGA能有效缩短波段筛选的长度, 但是筛选出的波段仅包含了位于930~1 110 cm-1处代表T307的P-N振动以及位于1 178 cm-1处的代表T321的C-S振动, 并未选择到代表T534的波段; 图5(d)中RF+LGA优选波段成功选取了代表全部三种添加剂的波段, 且选取波段的长度为原长度的36.7%。 其中, OVR SVMs+GA及RF+LGA优选波段既包含了三种添加剂的特征峰, 又达到了100%的识别准确率, 可认为其成功同步识别三种润滑油添加剂, 且RF+LGA筛选波段的长度更短, 为原波段长度的36.7%; 而拥有更少特征点数的RF+GA及OVR SVMs+LGA并未选中代表T534的特征波段, 因此认为该两种模型虽然在算法上达到了识别准确率100%, 但不能认为其能成功识别三种添加剂。
 | 图5 嵌入GA优选光谱特征波段的新模型测试结果 (a): OVR SVMs+GA; (b): RF+GA; (c): OVR SVMs+LGA; (d): RF+LGAFig.5 Test results of a new model for optimizing spectral feature bands by embedding GA (a): OVR SVMs+GA; (b): RF+GA; (c): OVR SVMs+LGA; (d): RF+LGA |
(1) 采用经典的分类算法结合红外光谱法能够实现对未知微小量多品种添加剂的同步种类识别, 不仅摆脱了传统方法的一些弊端, 也有效地提高了模型识别效率和识别准确率, 可以大大降低成本。
(2) 嵌入GA优选技术对原始光谱全波段进行特征区间筛选, 能够快速剔除冗余的特征波段, 从而提升经典分类算法的识别准确率、 减少计算量、 缩短模型运行时间。
(3) LGA作为GA的改进算法, 提高了GA的全局搜索能力, 能有效防止GA在搜索中陷入局部最优, RF+LGA建立的种类识别模型不但种类识别准确率达到了100%, 而且选出的波段与添加剂特征峰的对应性最好, 且波段长度仅为原波段长度的36.7%。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|