
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于近红外光谱数据的一维卷积神经网络模型研究
[唐杰1  , 罗彦波
, 罗彦波2 , 李翔宇2 , 陈云璨1 , 王鹏1 , 卢天3 , 纪晓波4 , 庞永强2, * , 朱立军1, * ]
, 罗彦波, 朱立军]
|
|


作者简介: 唐 杰, 1985年生, 烟叶资源科学利用重庆市重点实验室工程师 e-mail: tangjie1022@qq.com
近红外光谱技术已被广泛应用于各种检测行业, 但传统方法难以汇集光谱关键信息, 导致模型预测误差较大。 为减少误差, 基于452个茄科植物, 以化学成分为目标, 探索了一维卷积神经网络(1DCNN)在近红外数据上的回归模型研究。 经参数优化, 总结了一套兼顾精度与训练效率的1DCNN模型参数, 为后续模型研究提供参考。 模型测试集的均方根误差为0.02~0.49, 平均相对误差为0.8%~1.7%, 远小于历史文献。 相比传统方法, 1DCNN可充分利用全部近红外谱图数据, 且建模简单, 模型预测能力强。 该工作能为近红外光谱相关研究提供新的数据处理思路, 也能促进该技术的应用与发展。
, LUO Yan-bo, ZHU Li-jun
Near-infrared spectroscopy technology has been widely applied for detection in various industries. However, traditional methods struggle to gather key information from the spectral data, leading to significant model prediction errors. This study explores the regression modeling of one-dimensional convolutional neural networks (1DCNN) on near-infrared data, focusing on the chemical composition of 452 plants from the Solanaceae family. Through parameter optimization, the study suggests that the optimal settings for the model include 64 channels in the intermediate convolutional layer, a maximum pooling layer of 1, 6 convolutional layers, and 5 channels in the final convolutional layer. These findings can serve as a reference for future model research. The root mean square error of the model's test set ranges from 0.02 to 0.49, with an average relative error of 0.8%~1.7%, significantly lower than previous literature. Compared to traditional methods, 1DCNN can fully utilize all of the near-infrared spectral data while maintaining a simple model structure and strong predictive capabilities. This work provides new insights for data processing in near-infrared spectroscopy research and promotes the application and development of this technology.
近红外光谱(near-infrared spectroscopy, NIRS)是近年来发展较为快速的分析方法之一, 用于研究物质在近红外波段的吸收和散射特性, 可以做到快速、 无损、 绿色的检测。 近红外光谱可以记录到样品中的分子化学键的振动信息, 如C-H、 O-H、 N-H等, 可涵盖绝大部分有机组成与结构信息, 十分适合用于有机样品的无损检测[1]。
近年来已出现不少应用在植物上的近红外技术相关的工作, 研究内容主要涉及到植物中重要化学成分的回归预测问题, 比如预测总植物碱、 总氮、 还原糖等的含量, 同时也涵盖了分类问题, 譬如预测植物属地、 植物部位等。 由于近红外光谱的高维度特点, 上千维度的光谱数据难以直接应用到机器学习模型中, 通常需要先大幅减少数据的维度, 而针对高维光谱数据的处理方法较为有限, 因此绝大部分植物近红外工作思路都是先求导平滑、 再降维、 最后基于降维主成分来构建机器学习模型。 其中求导与平滑步骤一般采用二阶求导与Savitzky-Golay平滑, 降维方法通常是偏最小二乘法(partial linear square, PLS)或主成分分析(principle component analysis, PCA), 机器学习算法则以选用PLS回归、 支持向量机(support vector machine, SVM)居多。 蒋宏霖等[2]采用PLS方法降维了500多个不同地区、 不同等级的烟叶样本的近红外光谱数据, 并用全部降维主成分构建PLS回归模型来预测还原糖等烟叶中的5个化学成分含量, 其测试集的平均相对误差(mean relative error, MRE)为2.76%~4.35%。 Liu等[3]利用PLS降维成分构建了SVM模型, 用于预测同种烟叶的部位, 其测试集准确率为81.67%。 罗琼等[4]用PLS回归模型预测烟叶的淀粉的含量; Omar等[5]用SVM预测烟叶的公司品牌。 为提升模型的预测能力, 李明等[6]用组合区间偏最小二乘法确定了三段最优光谱区间, 使得模型的变量数降低了2/3, 且预测集的均方误差(mean squared error, MSE)从1.188降低到0.963。 蔡峰等[7]用遗传算法(genetic algorithm, GA)筛选PCA主成分个数, 使得SVM模型的测试集相关系数从0.90提升至0.95。
由于PCA与PLS等常规降维方法的局限性, 仍然较难获取到信息丰度较高的光谱数据, 模型预测能力也难以进一步提升。 比如, 文献[8]模型对还原糖、 总氮、 总植物碱的测试集平均相对误差MRE为3%~5%, 模型能力仍然还有较大的提升空间。 为探索新的建模思路, 有研究采用二维的卷积神经网络(2-dimensional convolutional neural network, 2DCNN)预测烟叶的属地, 测试集的分类准确率达到95%。 2DCNN的训练成本较大, 当近红外光谱含有1609个数据点且训练样本数量有400个时, 模型训练时间需要6.85个小时。 Jiang等[9]尝试用循环神经网络(residual neural network, RNN)来预测4个归属地, 但测试集准确率仅比SVM高出7%。 Kesu等[10]探索了2DCNN对化学成分含量的建模结果, 测试集的相关系数也达到0.85~0.95。 从模型复杂度来看, 2DCNN与RNN属于容量较大的模型, 即网络结构中的待优化参数较多, 需要大量的训练样本及较大的计算成本进行训练, 因此这两类模型也难有出众的表现。 从近红外光谱是高维向量这一数据特点来考虑, 一维卷积神经网络(1-dimensional, convolutional neural network, 1DCNN)可能更加贴合输入数据的形式。 相比于2DCNN和RNN, 1DCNN模型本身复杂度较低, 对样本需求量不高, 因而计算成本较低, 且无需对数据作二维矩阵变换。 相比于传统的降维建模过程, 1DCNN无需对光谱降维处理, 也不需要对光谱区域进行优化或选择, 而是在模型训练过程中调整光谱数据点对应的权重系数, 从而调整每个光谱数据点的贡献度。
本研究收集了来源于全国各地的452个同种茄科植物样本, 以该茄科植物的近红外光谱为输入数据, 以茄科植物的化学成分为目标值, 分别构建1DCNN回归模型。 针对不同1DCNN模型, 分别讨论了模型重要参数对建模结果的影响情况, 为1DCNN后续研究提供建模思路上的指导。 经参数优化后, 1DCNN模型测试集的MRE为0.8%~2.3%, MSE为0.001~0.238, 相关系数为0.93~0.97, 均优于文献的模型结果。 因此认为1DCNN在处理近红外光谱数据(甚至其他类似的高维向量数据)上具有十分大的潜力, 希望能为类似的光谱工作提供新的思路方向和数据处理手段。
样本: 茄科植物样本收集于各地复烤厂典型样品, 共计452个, 分别采集其近红外光谱。
仪器: Antaris Ⅱ 近红外光谱仪(美国Thermo公司); FD115 电热鼓风干燥箱(德国BINDER公司); 3100粉碎磨(瑞典PERTEN公司); XSR204型电子天平(感量0.000 1 g, 瑞士MettlerToledo公司); DK20消化器(意大利VELP公司); SKALAR SAN++连续流动分析仪(荷兰SKALAR公司)。
1.2.1 样品处理与化学指标检测
所有茄科植物样品均采用YC/T 31-1996方法制成粉末, 并过0.250 mm(60目)分样筛, 混匀后装入密封袋。 采用YC/T 159-2019方法测定样品中还原糖的含量; 采用YC/T 161-2002方法测定样品中总氮的含量; 采用YC/T 468-2021方法测定样品总植物碱含量。
1.2.2 近红外光谱采集
将粉末样品置于样品杯中, 在近红外光谱仪上进行漫反射采集, 扫描范围为4 000~10 000 cm-1, 分辨率为8 cm-1, 扫描次数为64。
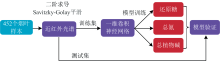
数据处理过程如图1所示, 在汇总452个茄科植物样本的近红外光谱数据后, 为了消除不同样本之间的噪声信息, 先对452条近红外光谱作了二阶求导以及Savitzky-Golay平滑处理。 按4:1的比例随机划分训练集与测试集, 分别得到362个训练样本与90个测试样本。 训练样本用于训练1DCNN模型, 测试样本用于训练好的模型评估。 不同的化学成分目标值, 如还原糖、 总氮、 总植物碱, 采用不同模型分别进行训练。
 | 图1 数据处理过程Fig.1 The workflow of this work |
采用1DCNN构建回归模型, 基准模型的结构如图2所示, 包含输入层、 一维卷积层、 池化层与全连接层。 其中, 中间卷积层通道数、 卷积层数、 池化层数、 末端卷积层通道数都将作为模型参数进行优化调整与讨论。 1DCNN的结构说明:
 | 图2 1DCNN结构示意图Fig.2 The structure of 1DCNN model |
(1)以单个样本为例, 其通道数为1, 构成(1, 1 500)维度的张量, 输入到1DCNN中;
(2)样本经过n/2(n∈ [2, 4, 6, 8])层的一维卷积层, 样本通道数从1卷积至d(d∈ [12, 24, 48, 64, 128]), 样本维度从(1, 1 500)卷积至(d, 1 500);
(3)样本经过m(m∈ [0, 1])层的池化层, 样本维度从(d, 1 500)卷积至(d, 1 500/(m+1));
(4)样本经过剩下的n/2(n∈ [2, 4, 6, 8])层的一维卷积层, 最后一层的一维卷积层的输出通道数设定为l(l∈ [1, 2, 3, 5, 7, 10]), 样本维度从(d, 1 500/(m+1))卷积至(l, 1 500/(m+1));
(5)将(l, 1 500/(m+1))维度的样本展开平铺, 得到长度为l× 1 500/(m+1)的向量;
(6)输入到3层的全连接层中, 先后转换为长度为1 024与512的向量, 最后得到标量作为输出值;
(7)上述卷积层均配有ReLu激活函数, 前2个全连接层均配有ReLu激活函数与Dropout函数。
以还原糖为例说明构建1DCNN模型的过程。 首先考虑对模型影响较大的中间卷积层通道数以及最大池化层数。 如表1所示为不同中间卷积层通道数对1DCNN建模结果的影响, 此时控制卷积层数为6, 最大池化层数为1, 末端卷积层通道数为1, 训练轮数为1 000。 模型性能指标采用训练损失(Loss)、 训练集MSE、 训练集决定系数(R2)、 测试Loss、 测试集MSE、 测试集R2。
| 表1 不同中间卷积层通道数对1DCNN模型结果(还原糖)的影响情况 Table 1 The impact of different channel numbers in the intermediate convolutional layer on the results (reducing sugars) of the 1DCNN model |
中间卷积层通道数直接影响着1DCNN的容量大小, 当通道数从12增加至64时, 模型的训练Loss与测试Loss整体处于降低的趋势, 测试集的MSE与R2分别处于降低与增大的趋势。 而通道数从64增至128时, 此时由于网络容量太大, 训练与测试结果均有所下降, 此时模型拟合效果变差。 因此中间卷积层通道数应控制在64个。 如表2所示, 当最大池化层数为0时, 1DCNN基于不同中间卷积层通道数的建模结果。 模型的误差整体大于最大池化层数为1时的建模结果, 说明添加最大池化层有助于减少噪音信息, 并减少模型误差, 增强模型的稳定性。 综合表1与表2的结果, 可以确定1DCNN的中间层卷积通道数与最大池化层数分别为64与1。
| 表2 不同中间卷积层通道数对1DCNN模型结果(还原糖)的影响情况 Table 2 The impact of different channel numbers in the intermediate convolutional layer on the results (reducing sugars) of the 1DCNN model |
考虑了不同卷积层数对建模的影响(表3), 此时控制中间卷积层通道数为64, 最大池化层为1, 末端卷积层通道数为1。 当卷积层数从2分别提升至6和8时, 明显看到模型的训练Loss在不断减少, 而测试Loss先降低后增加。 当卷积层数为2时, 模型处于欠拟合状态, 而卷积层为8时, 模型处于过拟合状态, 因此选择卷积层为6比较合适。 卷积层数为4时, 模型可能陷入了局部优点, 难以收敛, 不作考虑。
| 表3 不同卷积层数对1DCNN模型结果(还原糖)的影响情况 Table 3 The impact of different numbers of convolutional layers on the results (reducing sugars) of the 1DCNN model |
进一步考虑末端卷积层通道数对建模的影响情况(表4), 此时控制中间卷积层通道数为64, 最大池化层为1, 卷积层数为6。 当末端卷积层通道数从1提升至20时, 训练Loss呈现波动式的变化, 训练集MSE主要呈现先下降后上升的趋势, 而测试Loss、 测试集MSE主要呈现下降趋势。 综合考虑训练集与测试集, 末端卷积层通道数选择15较为合适, 此时训练集MSE比通道数为1的情况降低了0.027, 测试集MSE降低了0.063。
| 表4 不同末端卷积层通道数对1DCNN模型结果(还原糖)的影响情况 Table 4 The impact of different numbers of channels in the final convolutional layer on the results (reducing sugars) of the 1DCNN model |
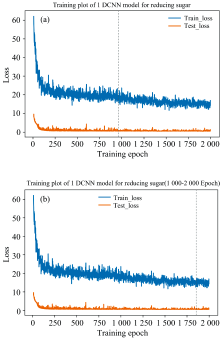
根据表1-表4的模型参数对比, 确定中间卷积层通道数为64, 最大池化层为1, 卷积层数为6, 末端卷积层通道数为15。 如图3(a)所示为1DCNN还原糖模型的训练过程, 训练轮数为1 000轮, 962轮时模型达到最佳。 1 000轮训练时长约为156.45 s, 远少于以前工作中的6.85 h。 图3(a)中的训练Loss与测试Loss随着训练轮数增大而下降, 且200轮之后就处于较小的波动状态, 说明模型训练较为稳定。 图3(b)是1DCNN模型继续训练至2 000轮的情况, 训练Loss略有下降, 但测试Loss基本不变, 说明1DCNN再继续训练可能会陷入过拟合状态。 因此从图3中可得出结论, 1DCNN模型在1 000轮以内基本已收敛, 且在约200轮已达到较高的准度。
 | 图3 1DCNN(还原糖)模型的训练结果 (a): 前1 000轮; (b): 后1 000轮Fig.3 The training results of the 1DCNN model for reducing sugars (a): The first 1 000 epochs; (b): The latter 1 000 epochs |
采用图3(a)中收敛的1DCNN还原糖模型, 其详细性能评价指标如表5所示。 测试集的RMSE为0.487, 低于文献[8, 12-13]的1.06、 0.83与0.92, 与文献[14]的0.443持平。 测试集MRE为1.7%, 低于文献[3, 9]的3.05%与3.37%。 其他性能评价指标决定系数(R2)为0.915、 MSE为0.238、 MAE为0.379、 相关系数CORR为0.957, 也均处于较好的水准。
| 表5 1DCNN的评价指标结果 Table 5 The evaluation metrics of 1DCNN models |
采用类似的方法同样可确定总氮与总植物碱的模型参数, 其中间卷积层通道数、 最大池化层、 卷积层数、 末端卷积层通道数分别为128、 1、 4、 5与32、 1、 4、 5。 模型的性能指标见表5, 测试集RMSE分别为0.024与0.067, 测试集MRE为0.8%与2.3%, 低于文献中误差。
结合三个模型的训练结果, 1DCNN的中间卷积层通道数可设为64或128, 最大池化层应该选择开启, 卷积测层数可设为4/6层, 末端卷积通道数选择5~15较为合适, 训练轮数的上限可设定为1 000。
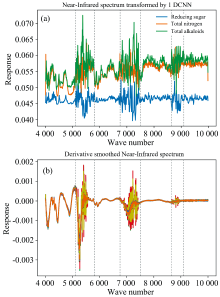
分别提取三个模型的一维卷积特征向量, 该向量是原始输入光谱数据经由多个卷积与池化操作后得到, 可以视为是原始输入近红外光谱的转换后数据。 向量中元素值的大小对应着该波数位置的数据点对模型的贡献度大小。 向量结果如图3(a)所示, 蓝色、 橙色、 绿色分别对应还原糖、 总氮、 总植物碱的转换后的近红外光谱数据。 图中可看出, 光谱响应值较大的谱图区域分别为5 100~5 800、 6 750~7 500、 8 650~9 100 cm-1, 与求导平滑的近红外光谱图[图4(b)]中波动较大的谱图区域较为一致。 说明在1DCNN模型中, 传统上认为信号较强的谱图区域对模型贡献度也较大。 但值得注意的是, 图3(b)中较为平缓的谱图区域, 如5 800~6 750、 7 500~8 650、 9 100~10 000 cm-1等, 在传统机器学习中可能会被作为噪声或者冗余特征去除, 但这些区域在1DCNN网络中的仍然存在着较大的建模贡献度, 说明这些平时被视为信息丰度较小的区域仍然隐藏有对建模有用的信息, 而这些信息较难以常规机器学习手段挖掘得到。
 | 图4 (a)经1DCNN转换后的近红外光谱; (b)求导平滑后的近红外光谱Fig.4 (a) The near-infrared spectrogram transformed by 1DCNN; (b) The near-infrared spectrogram smoothed after derivative calculation |
基于452个同种茄科植物的近红外光谱, 以该植物的还原糖、 总氮、 总植物碱为目标值, 分别构建了三个1DCNN回归模型。 经过三个模型的训练过程, 1DCNN的中间卷积层通道数可设为64或128, 最大池化层可设为1, 卷积测层数可设为4或6层, 末端卷积通道数可设为5~15层, 训练轮数上限可小于1 000, 可为后续基于近红外光谱的1DCNN研究提供模型的案例参考。 三个1DCNN回归模型的测试集的RMSE为0.024~0.487, MRE为0.8~1.7%, 均小于历史文献的误差范围, 验证了1DCNN在近红外光谱建模可行性。 进一步提取了1DCNN中的卷积特征向量, 结果表明信号较弱的谱图区域对建模结果仍然有较大的贡献度。 相比于传统机器学习方法, 1DCNN模型不仅可充分利用全部的近红外光谱数据, 还具备较好的预测能力, 可以作为近红外光谱领域内新的数据处理手段。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|